Modulo -estructura_de_datos_i
0 recomendaciones782 vistas

Este documento presenta información sobre los sistemas de información. Describe las cuatro actividades básicas de un sistema de información: entrada, almacenamiento, procesamiento y salida de información. También explica tres tipos principales de sistemas de información - sistemas transaccionales, sistemas de apoyo a la toma de decisiones y sistemas estratégicos - y sus características clave.







![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
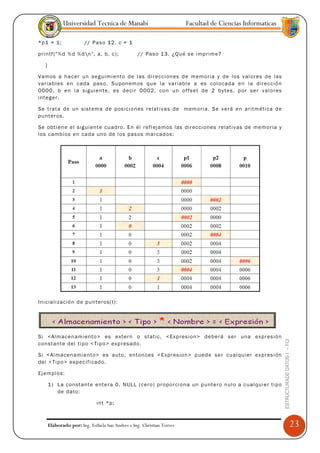
La i nstr ucc ió n n = 9+10 de un p r og ram a d ond e = es el o pe ra do r d e asig nac ió n ,
el co nte ni do de la l oca l idad de al mac en ami e nt o da do p o r n ser á e l va l or 19.
Cad a tip o d e datos : es rec on oc ido p or l os e l e ment os de d atos qu e p ued e tom a r y po r
las o pe ra ci on es asoc ia das a é l. (su dom in io ) E jem p lo : en p asca l
Dom ini o ent e r o D= {0, 1, 2….ma x }
O pe r aci on es
Los T D As so n ge n er al i zac io nes de los ti p os de dat os bás ic os y d e las o p e rac io nes
p rim iti vas . U n TD A en caps ul a ti p os d e dat o s en el s e ntid o qu e e s pos ibl e p on e r l a
def in ici ón de l ti p o y todas las o pe ra ci on es con es e ti p o e n u n a secc ió n d e u n
p ro gr ama .
P or ej em pl o, s e p ue de def in ir un ti p o de d ato s abstra cto C O NJ UNT O [ Ah o198 8] c on e l
cua l se p u ed en d ef in i r l as sig ui ent es o pe r aci o nes:
AN UL A ( A )
Hac e v ací o a l c on ju nto A
UNI ON ( A, B, C )
Co nstr u y e el c o nju nt o C a p art i r d e la un ió n de los co nj unt os A y
B.
T A M AÑ O( A )
Ent r eg a l a ca nti dad de el em ent os d e l co nj unt o A.
El co mp o ne nt e bás ico de una est r uctu ra de d atos es la c el da.
La c eld a a lma ce na un v al or tom ad o d e a lgú n t i po d e dat o s im pl e o c o mpu est o
El m eca nism o de ag r e gaci ón d e c el das ll am ado a r re gl o es una c o lec ci ón de
el em ent os d e t ip o hom og én eo .
A r re gl o b idim e nsi on al en C/ C++
int w[5][3]
w[ i ] [j ] = b [ i * n + j]
n es la c ant ida d d e
col umn as d el a r re gl o
ESTRUCTURADE DATOS I -- FCI
w[ 2] [0 ] = b [6 ]
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 7](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-8-320.jpg)



![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Estructuras
Supongamos que queremos hacer una agenda con los números de teléfono de nuestros amigos.
Necesitaríamos un array de Cadenas para almacenar sus nombres, otro para sus apellidos y otro para sus
números de teléfono. Esto puede hacer que el programa quede desordenado y difícil de seguir. Y aquí es
donde vienen en nuestro auxilio las estructuras.
Para definir una estructura usamos el siguiente formato:
struct nombre_de_la_estructura {
campos de estructura;
};
NOTA: Es importante no olvidar el ';' del final, si no a veces se obtienen errores extraños.
Para nuestro ejemplo podemos crear una estructura en la que almacenaremos los datos de cada persona.
Vamos a crear una declaración de estructura llamada amigo:
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
char edad;
};
A cada elemento de esta estructura (nombre, apellido, teléfono) se le llama campo o miembro. (NOTA: He
declarado edad como char porque no conozco a nadie con más de 127 años.
Ahora ya tenemos definida la estructura, pero aun no podemos usarla. Necesitamos declarar una variable
con esa estructura.
struct estructura_amigo amigo;
Ahora la variable amigo es de tipo estructura_amigo. Para acceder al nombre de amigo usamos:
amigo.nombre. Vamos a ver un ejemplo de aplicación de esta estructura. (NOTA: En el siguiente ejemplo
los datos no se guardan en disco así que cuanda acaba la ejecución del programa se pierden).
#include <stdio.h>
struct estructura_amigo {/* Definimos la estructura estructura_amigo */
char nombre[30];
char apellido[40];
char telefono[10];
char edad;
};
struct estructura_amigo amigo;
void main()
{
ESTRUCTURADE DATOS I -- FCI
printf( "Escribe el nombre del amigo: " );
fflush( stdout );
scanf( "%s", &amigo.nombre );
printf( "Escribe el apellido del amigo: " );
fflush( stdout );
scanf( "%s", &amigo.apellido );
printf( "Escribe el número de teléfono del amigo: " );
fflush( stdout );
scanf( "%s", &amigo.telefono );
printf( "El amigo %s %s tiene el número: %s.n", amigo.nombre,
amigo.apellido, amigo.telefono );
}
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 11](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-12-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Este ejemplo estaría mejor usando gets que scanf, ya que puede haber nombres compuestos que scanf no
cogería por los espacios.
Se podría haber declarado directamente la variable amigo:
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
} amigo;
Arrays de estructuras
Supongamos ahora que queremos guardar la información de varios amigos. Con una variable de estructura
sólo podemos guardar los datos de uno. Para manejar los datos de más gente (al conjunto de todos los
datos de cada persona se les llama REGISTRO) necesitamos declarar arrays de estructuras.
¿Cómo se hace esto? Siguiendo nuestro ejemplo vamos a crear un array de ELEMENTOS elementos:
struct estructura_amigo amigo[ELEMENTOS];
Ahora necesitamos saber cómo acceder a cada elemento del array. La variable definida es amigo, por lo
tanto para acceder al primer elemento usaremos amigo[0] y a su miembro nombre: amigo[0].nombre.
Veamoslo en un ejemplo en el que se supone que tenemos que meter los datos de tres amigos:
#include <stdio.h>
#define ELEMENTOS 3
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
int edad;
};
struct estructura_amigo amigo[ELEMENTOS];
void main()
{
int num_amigo;
for( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ )
{
printf( "nDatos del amigo número %i:n", num_amigo+1 );
printf( "Nombre: " ); fflush( stdout );
gets(amigo[num_amigo].nombre);
printf( "Apellido: " ); fflush( stdout );
ESTRUCTURA DE DATOS I -- FCI
gets(amigo[num_amigo].apellido);
printf( "Teléfono: " ); fflush( stdout );
gets(amigo[num_amigo].telefono);
printf( "Edad: " ); fflush( stdout );
scanf( "%i", &amigo[num_amigo].edad );
while(getchar()!='n');
}
/* Ahora imprimimos sus datos */
for( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ )
{
printf( "El amigo %s ", amigo[num_amigo].nombre );
printf( "%s tiene ", amigo[num_amigo].apellido );
12 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-13-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
printf( "%i años ", amigo[num_amigo].edad );
printf( "y su teléfono es el %s.n" , amigo[num_amigo].telefono );
}
}
IMPORTANTE: Quizás alguien se pregunte qué pinta la línea esa de while(getchar()!='n');. Esta línea se usa
para vaciar el buffer de entrada. Para más información consulta Qué son los buffer y cómo funcionan.
Inicializar una estructura
A las estructuras se les pueden dar valores iniciales de manera análoga a como hacíamos con los arrays.
Primero tenemos que definir la estructura y luego cuando declaramos una variable como estructura le
damos el valor inicial que queramos. Recordemos que esto no es en absoluto necesario. Para la estructura
que hemos definido antes sería por ejemplo:
struct estructura_amigo amigo = {
"Juanjo",
"Lopez",
"592-0483",
30
};
NOTA: En algunos compiladores es posible que se exiga poner antes de struct la palabra static.
Por supuesto hemos de meter en cada campo el tipo de datos correcto. La definición de la estructura es:
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
int edad;
};
por lo tanto el nombre ("Juanjo") debe ser una cadena de no más de 29 letras (recordemos que hay que
reservar un espacio para el símbolo '0'), el apellido ("Lopez") una cadena de menos de 39, el teléfono una
de 9 y la edad debe ser de tipo char.
Vamos a ver la inicialización de estructuras en acción:
#include <stdio.h>
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
int edad;
ESTRUCTURADE DATOS I -- FCI
};
struct estructura_amigo amigo = {
"Juanjo",
"Lopez",
"592-0483",
30
};
int main()
{
printf( "%s tiene ", amigo.apellido );
printf( "%i años ", amigo.edad );
printf( "y su teléfono es el %s.n" , amigo.telefono );
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 13](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-14-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
}
También se puede inicializar un array de estructuras de la forma siguiente:
struct estructura_amigo amigo[] =
{
"Juanjo", "Lopez", "504-4342", 30,
"Marcos", "Gamindez", "405-4823", 42,
"Ana", "Martinez", "533-5694", 20
};
En este ejemplo cada línea es un registro. Como sucedía en los arrays si damos valores iniciales al array de
estructuras no hace falta indicar cuántos elementos va a tener. En este caso la matriz tiene 3 elementos,
que son los que le hemos pasado.
Paso de estructuras a funciones
Las estructuras se pueden pasar directamente a una función igual que hacíamos con las variables. Por
supuesto en la definición de la función debemos indicar el tipo de argumento que usamos:
int nombre_función ( struct nombre_de_la_estructura nombre_de_la variable_estructura )
En el ejemplo siguiente se usa una función llamada suma que calcula cual será la edad 20 años más tarde
(simplemente suma 20 a la edad). Esta función toma como argumento la variable estructura arg_amigo.
Cuando se ejecuta el programa llamamos a suma desde main y en esta variable se copia el contenido de la
variable amigo.
Esta función devuelve un valor entero (porque está declarada como int) y el valor que devuelve (mediante
return) es la suma.
#include <stdio.h>
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
int edad;
};
ESTRUCTURA DE DATOS I -- FCI
struct estructura_amigo amigo = {
"Juanjo",
"Lopez",
"592-0483",
30
};
int suma( struct estructura_amigo arg_amigo )
{
return arg_amigo.edad+20;
}
int main()
14 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-15-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Estructuras dentro de estructuras (Anidadas)
Es posible crear estructuras que tengan como miembros otras estructuras. Esto tiene diversas utilidades,
por ejemplo tener la estructura de datos más ordenada. Imaginemos la siguiente situación: una tienda de
música quiere hacer un programa para el inventario de los discos, cintas y cd's que tienen. Para cada título
quiere conocer las existencias en cada soporte (cinta, disco, cd), y los datos del proveedor (el que le vende
ese disco). Podría pensar en una estructura así:
struct inventario {
char titulo[30];
char autor[40];
int existencias_discos;
int existencias_cintas;
int existencias_cd;
char nombre_proveedor[40];
char telefono_proveedor[10];
char direccion_proveedor[100];
};
Sin embargo utilizando estructuras anidadas se podría hacer de esta otra forma más ordenada:
struct estruc_existencias {
int discos;
int cintas;
int cd;
};
struct estruc_proveedor {
char nombre[40];
char telefono[10];
char direccion[100];
};
struct estruc_inventario {
char titulo[30];
char autor[40];
struct estruc_existencias existencias;
struct estruc_proveedor proveedor;
} inventario;
Ahora para acceder al número de cd de cierto título usaríamos lo siguiente:
inventario.existencias.cd
y para acceder al nombre del proveedor:
ESTRUCTURA DE DATOS I -- FCI
inventario.proveedor.nombre
16 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-17-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Ahora, nuestros nuevos tipos de datos, aparte de definir el tipo de variable nos dan información adicional
de las variables. Sabemos que x0, y0, x1, y1, x, y son coordenadas y que i es un contador sin necesidad de
indicarlo con un comentario.
Realmente no estamos creando nuevos tipos de datos, lo que estamos haciendo es darles un nombre más
cómodo para trabajar y con sentido para nosotros.
Punteros
También podemos definir tipos de punteros:
int *p, *q;
Podemos convertirlo en:
typedef int *ENTERO;
ENTERO p, q;
Aquí p, q son punteros aunque no lleven el operador '*', puesto que ya lo lleva ENTERO incorporado.
Arrays
También podemos declarar tipos array. Esto puede resultar más cómodo para la gente que viene de BASIC
o PASCAL, que estaban acostumbrados al tipo string en vez de char:
typedef char STRING[255];
STRING nombre;
donde nombre es realmente char nombre[255];.
Estructuras
También podemos definir tipos de estructuras. Antes, sin typedef:
struct _complejo {
double real;
double imaginario;
};
ESTRUCTURA DE DATOS I -- FCI
struct _complejo numero;
Con typedef:
typedef struct {
double real;
double imaginario;
} COMPLEJO;
COMPLEJO numero;
18 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-19-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Asignación de Memoria Dinámica
Métodos de Asignación de Memoria
¿Cuáles son los métodos de asignación de memoria utilizados por el S.O.?
Cabe destacar que el almacenamiento y procesamiento de todos los datos es realizado en memoria RAM,
en un segmento destinado a ello (DS), por ello, es importante conocer los métodos de asignación de
memoria utilizados para su almacenamiento. Por un lado, se tiene la asignación estática de memoria en
donde se reserva la cantidad necesaria para almacenar los datos de cada estructura en tiempo de
compilación. Esto ocurre cuando el compilador convierte el código fuente (escrito en algún lenguaje de alto
nivel) a código objeto y solicita al S.O. la cantidad de memoria necesaria para manejar las estructuras que
el programador utilizó, quien según ciertos algoritmos de asignación de memoria, busca un bloque que
satisfaga los requerimientos de su cliente. Por otro lado se tiene la asignación dinámica en donde la
reserva de memoria se produce durante la ejecución del programa (tiempo de ejecución). Para ello, el
lenguaje Pascal cuenta con dos procedimientos: NEW() y DISPOSE() quienes realizan llamadas al S.O.
solicitándole un servicio en tiempos de ejecución. El procedimiento NEW ,por su parte, solicita reserva de
un espacio de memoria y DISPOSE la liberación de la memoria reservada a través de una variable especial
que direccionará el bloque asignado o liberado según sea el caso.
Ejemplo : Cuando se compilan las sgtes. Líneas de código se produce una asignación estática de memoria:
var linea: string [80];
(*Se solicita memoria para 80 caracteres --> 80 bytes)
operatoria: Array[1..100,1..100] of real;
(*Se solicita memoria para 100x100 reales -> 100 x 100 x 4 bytes)
interes : integer;
ESTRUCTURADE DATOS I -- FCI
(*Se solicita memoria para 1 entero --> 2 bytes)
¿Cuántos bytes se reservarían para:?
datos: array [1..25] of double;
Para explicar con mayor detalle el concepto de memoria dinámica es necesario conocer el concepto ¡PUNTEROS!
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 19](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-20-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Un a v ar iab l e p unt e ro s e dec la r a com o tod as l as va r iab les. D eb e se r del m ismo t ip o qu e
la va r iab le a pu ntad a. S u id e ntif ica do r va p r ec edi do de un ast e risc o ( *):
i nt * p u nt;
Es un a v ar iab l e pu nt er o q ue a pu nta a va ri ab le qu e c o nti en e un d a to d e ti po ent e ro
lla mad a pu nt.
ch a r *c ar:
Es un p unt e ro a va ri abl e d e ti p o c ar áct er .
l o ng f lo at *n um;
f lo at * mat[ 5] ; // . . .
Es d eci r: ha y ta ntos tip os d e p unt e ros c omo t ip os d e dat os, aun q u e tambi é n
pu ed en de cla r ars e pu nt er os a estruct ur as más c om p le jas ( func i on es, st r uct ,
fich e ros ... ) e i ncl uso p u nte r os vac íos ( v oid ) y pu nt er os nu los (N ULL ).
Dec la rac ió n d e v ar iab le s pu nt er o: S ea un f rag ment o d e p r og ram a e n C:
cha r dat o; // v a riab l e q ue al mac en a rá un c a r ácte r.
cha r * p unt; //d ec la r aci ón de p unt e ro a c ar ácte r.
pu nt = & dat o; // e n l a va r iab le p unt gu ar dam o s la d i re cci ón
// d e m em o ria d e l a va r iab le dat o; pu nt a p u nta
// a d ato . Ambas so n del mism o t ip o, ch ar.
int * p unt = N ULL, va r = 14;
pu nt = & va r;
p ri ntf (“ %# X, %# X ”, pu nt, & va r ) // la m ism a s ali da: di r ecci ón
p ri ntf (“ n% d, %d ”, * pu nt, va r ); //sa lid a: 1 4, 14
H a y qu e t en e r c uid ad o c on las di r ecci on es a pu ntad as:
p ri ntf (“ %d, %d ”, * ( pu n t+1), v a r+1 );
*( pu nt + 1 ) r e pes e nta el v al o r co nt en ida e n la d i rec ci ón de m em o ri a a um enta da en
una p osi ci ón ( int=2 by tes) , qu e s e rá un v al or n o d ese ad o. Si n emb ar go v ar +1
r ep r es enta e l va lo r 15.
pu nt + 1 r e p r ese nta l o m ism o qu e &v a r + 1 ( a van ce en la d ir ecc i ón d e m em o ria d e
va r ).
Al tr aba ja r c on p unt e r o s se em pl ea n d os o pe r ado r es esp ec íf icos :
ESTRUCTURADE DATOS I -- FCI
O pe r ado r d e d i r ecci ón : & R e p r ese nta la di r ecc ió n de m em o ri a de la va r iab le
qu e l e sig u e:
&fn um r e p res en ta la di r ecc ió n d e f num .
O p er ad o r d e c o nte nid o o i nd ir ecc i ón: *
El o p er ad o r * a pl ic ado al nomb r e d e u n pu nt er o i nd ica el va l or de la va r iab le
ap unt ada:
flo at alt ur a = 2 6.92, *ap unt a;
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 21](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-22-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
p = NUL L; // actu al iz aci ó n
2) El no mb re d e un a r ra y d e a lma ce nam i ent o stati c o ext e rn s e t r ansf o rma s eg ún la
ex p r esi ón:
a ) f l oat m at [12 ];
fl oat * p unt = mat;
b) fl o at mat [12 ];
f lo at * p unt = & mat [0 ];
3) U n “ cast ” pu nt er o a pu nt er o:
int *p unt = ( int *) 123. 456;
Inic ia li za e l pu nte r o c o n e l ent e ro .
4) U n punt e r o a ca ráct e r pu ed e i nic ia li za rs e e n l a f or ma:
cha r *c ad en a = Est o e s un a cad e na ”;
5) S e p u ede n suma r o r esta r v al o res e nt er os a las dir ecc io n es de m e mo ria en l a fo rma :
(a rit mét ica de p unt e r os)
st atic int x;
int * pu nt = & x+2, *p = & x-1;
6) E qu i va le nci a: D os ti pos de fi nid os c omo p u nte r os a o bj eto P y pu n ter o a obj et o Q so n
e qu iv al e ntes s ó lo s i P y Q s on de l m ism o ti p o. A pl ica do a m atr ic es:
nomb r e_ pu nte r o = nom br e_m atr i z;
ESTRUCTURA DE DATOS I -- FCI
24 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-25-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
PUNTEROS Y ARRAYS
Se a el a rr a y d e una di mens ió n:
i nt mat [ ] = { 2, 16 , - 4, 29, 234, 1 2, 0, 3 };
en e l qu e c ada e le me nt o, po r s e r t ip o int, oc u p a dos b ytes de me mo ri a.
Su p on em os qu e la di re cció n d e m em o ri a d el p rim e r el em ent o, es 1 50 0:
& mat [0 ] es 1 500
& mat [1 ] s er á 1502
& mat [7 ] s er á 1514
int mat [ ] = {2 , 16, -4 , 29, 2 34, 12 , 0, 3} ;
En tot al los 8 el em ent o s ocu p an 16 b yt es.
P ode mos r e p res ent a r l as di r ecci o nes de mem or ia q u e oc u pa n l os el e ment os d e l a r ra y ,
los dat os qu e c ont ie n e y las p osic io n es d el a rr ay e n l a f o rma:
Di rec ci ón 1 500 1 502 1 504 1506 1 508 1510 151 2 1514
El em e nto
mat [0 ] mat [1 ] mat [2 ] mat [3 ] mat [4 ] mat [5 ] mat [6 ] m at[ 7]
El acc es o po dem os hac e rl o m edi ant e el ín dic e:
x = mat [3 ]+m a t[5 ]; // x = 2 9 + 1 2
pa ra sum ar l os el em ent os d e l a c ua rta y s e xta pos ic io nes .
C om o h em os d ich o q ue p od em os acc ede r p or pos ici ón y p or di r ec ció n: ¿ Es lo mism o
&mat [0 ] y mat?
Y &mat [1 ] = mat ++ ?
Veam os el có dig o d e un ej em p lo:
#inc lu de <stdi o.h >
#inc lu de <co ni o.h >
int m at[ 5] ={ 2, 16 , -4, 2 9, 234, 12, 0 , 3 }, i; // d ecl a rad as c omo gl oba l e s
vo id mai n () {
p ri ntf (" n% d", &mat [0 ] ); // res ult ad o: 15 00 ( di r ecci ón d e m em )
ESTRUCTURADE DATOS I -- FCI
p ri ntf (" n% p ", m at ); / /r es ulta do: 1 500 ( " " " " " )
i ++; //i =1
p ri ntf (" n% p ", m at+ i); // r esu ltad o: 1 502 ( " " " " " )
p ri ntf (" n% d", * (ma t+i) ); // r esu ltad o: 16 ( va lo r de mat [1 ] o val o r
g etch ( ); }
Ej em p lo
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 25](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-26-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Pa r ec e d edu ci rs e qu e a cced em os a l os e l em en tos d el a rr a y d e d os f o r mas:
- m ed iant e e l sub índ ice.
- m ed iant e s u d ir ecc ió n d e m em or ia.
El em e nto mat[ 0] mat [1 ] mat [2 ] m at[ 3] mat [4 ] mat [ 5] mat [6 ] m at[ 7]
Analizando las direcciones de memoria del array:
De lo ant e ri o r s e obt i en en v ar ias co ncl usi on es:
- Es lo mism o &m at[ 0] q ue mat, & mat [2 ] q ue mat + 2
- Pa r a pasa r de un e l em ent o a l si gu ie nte , es lo mism o:
Qu e el có dig o:
ESTRUCTURA DE DATOS I -- FCI
A esta fo rm a d e d es pl a za rs e e n m em o ria se l e ll ama
26 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-27-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Uti li za nd o la aritmética de punteros nos despl az am os de u nas p osic io n es de
mem or ia a ot r as. Pe r o. ¿c óm o ac ce de r a l os co nt en idos de es a s pos ic io nes
util iz an do n otac ió n d e pu nt er os?
Em p le amos el o pe ra do r *, indirección que n os da e l co nt en ido d e la di r ecci ón d e
mem or ia a pu ntad a.
Y... ¿c óm o s e a pl ica la a rit mét ica d e pu nte r os pa r a d es pl az ar nos e n un a r ra y
bidim e nsi on al ?:
f lo a t mat[ 2] [4 ]; //d ecl a rac ió n d e l a r ra y
Uti li za nd o pu nte r os, la dec la rac ió n s e rá:
fl o at ( *mat ) [4 ]; / /a r ra y b idim e nsi on al
En d ond e mat es u n p unt e ro a u n g r up o co ntig u o d e a r r a ys mon od ime nsi o nal es
( ve cto r es) d e 4 el em en tos ca da un o.
E xist e, p or tant o un a e qu i va le nci a:
Rec o rd emos que *mat
r ep r es enta un puntero a la
primera fila. A la se gund a
fil a n os r ef e ri mos m e dia nte
*(m at+1 )+j p a ra las
dir ec ci on es y con
ESTRUCTURA DE DATOS I -- FCI
*(* (m at+1 )+j ) p ar a los
cont en id os. El
segu nd o subíndi ce actua
sob re la co lu mna .
Si en x[ 10 ][ 20 ] q u ie r o acc ed e r al e le me nto d e l a fi la 3 y la c ol umn a 6, l o h ag o
esc rib ie nd o x [2 ][ 5]. C o n n otac ió n d e p unt e ros , es e qu i va le nte a
* ( * ( x + 2 ) +5 )
28 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-29-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
ya qu e x + 2 es un pu nt er o a l a fi la 3. P or t ant o. E l co nt en ido de dich o pu nte r o,
*( x+2 ), es la fi la 3. Si m e d esp la z o 5 p os ici on es e n es a fi la l l e go a l a p osi ci ón
*( x+2 )+5, cu y o c ont en i do es * (* ( x+2 )+5 ). V e r dibu jo:
Si en x[ 10 ][ 20 ] q u ie r o acc ed e r al e le me nto d e l a fi la 3 y la c ol umn a 6, l o h ag o
esc rib ie nd o x [2 ] [5 ]. C on n otac ió n de punt e r os, lo qu e hac em os es co nsid e ra r qu e es
un a r ra y fo rm ad o p o r 10 ar ra ys u ni dim ens i o nal es (v ect o res ) d e 2 0 el em ent os cad a
un o, d e m od o qu e acc e do a x [2 ] [5 ] m ed iant e l a e x p res ió n:
* ( * ( x + 2 ) + 5)
ya qu e x + 2 es un pu nt er o a l a fi la 3. P or t ant o. E l co nt en ido de dich o pu nte r o,
*( x+2 ), es la fi la 3. Si m e d esp la z o 5 p os ici on es e n es a fi la l l e go a l a p osi ci ón
*( x+2 )+5, cu y o c ont en i do es * (* (x +2 )+5 ). L as sigu ie nt es e x p res io n es con p unt e ros s o n
vá lid as:
**x x [0 ] [0 ] ; *( *( x+1 ) ) x [1 ] [0 ]
*(* x+1 ) x [0 ] [1 ]; ** (x +1 ) x [1] [0 ]
Si e n
int a rr a y[ fi las ] [c ol umn as] ;
Qu i er o acc ed e r a l el e ment o a r ra y [ y ][ z ] p a ra asign a rl e un va l or , lo qu e e l com p il ad or
hac e es :
*(*array +columnas x y + z)) = 129; / /asig nac ió n
Si f ue r a int a r ra y [2 ] [5 ] y q uisi e ra as ig na r 12 9 al e le me nto d e l a fi l a 1 y co lu mna 2 ,
po nd rí a:
ESTRUCTURADE DATOS I -- FCI
* (a r ra y + 5x1 + 1 )) = 129 ;
es d eci r, des de e l or ig e n d el ar r a y a va n za 6 po sici on es d e m em o ri a:
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 29](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-30-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
PUNTEROS A ARRAYS MATRICES
Un a r ra y m ult idim e nsi on al es, en r e ali dad, una co l ecci ón d e vect or es. S eg ún est o,
po de mos d ef in ir un ar ra y b idi me nsi on al c o mo u n p unt e r o a u n g ru p o co nti gu o d e
ar ra ys un id ime nsi o nal e s. Las d ec la rac io n es si gui ent es s on e q ui va l en tes:
int dat [fi l ] [co l ] i nt (*d at) [c ol ]
En g en e ra l:
tip o_d ato no mb re [d im1 ] [dim 2] . . . . . [di mp ]; e q ui va le a:
tip o_d ato (* no mb re ) [di m2] [d im3 ]. . . . . [d im p ];
El a r ra y: i nt va l or [ x ][ y ] [z ];
Pu ed e s e r re p r ese nta d o en la fo rm a:
i nt (* va lo r ) [y ] [ z] ;
O c om o u n AR R A Y D E P UN T ER O S:
int * v al or [ x ][ y ];
s in p a r ént esis
En su nu e va dec la r aci ó n d esa pa r ec e l a ú ltim a de s us di me nsi on es.
Veam os m ás d ecl a rac io nes de a rr a ys d e p unt e ros :
ESTRUCTURA DE DATOS I -- FCI
int x [10 ] [20 ]; int * x[ 10 ];
flo at p [10 ] [20 ] [30 ]; int * p[ 10 ][ 20 ];
30 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-31-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Punteros a CADENAS DE CARACTERES
Un a c ad ena d e c ar act e r es es u n ar r ay d e c ar a cte res . La f or ma de d e fin i r u n pu nt er o a
una cad e na d e c a ract e r es:
c ha r *ca de na;
El id ent if icad o r d el ar ra y es l a di r ecc ió n d e comi e nz o d el a rr a y. Pa r a sab e r dó nd e
ter mi na la c ad en a, el c om pi lad o r a ñad e el ca r ácte r ‘ 0’ ( A SCI I 0, N UL L):
cha r * nomb r e = “ P E P E P ER E Z ”;
ARRAYS DE PUNTEROS A CADENAS DE CARACTERES
En un a r ra y d e pu nte r o s a cade nas d e ca r acte r es cad a el em e nto a p u nta a u n ca ráct e r.
La d ecl a rac ió n s er á:
cha r *c ad [10 ]; // po r e jem p lo
Grá fic am ent e p od ría se r:
ESTRUCTURADE DATOS I -- FCI
- si l as di me nsi on es no son c o noc idas , sab r em os d ónd e c om ie n zan l a s cad en as,
p er o no d ó nde t e rm ina n. Pa ra el l o se ef ect úa la l la mad a reserva dinámica de
memoria (funci o nes ma ll oc, c al loc ( ), r ea ll oc ( ) y fr e e () de stdl ib.h ó al l oc.h ):
cha r c ad[ 10 ][ 80 ];
E qu i va le a ch ar **ca d r es er v and o 8 00 b yt es
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 31](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-32-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
La d ecl a rac ió n:
c ha r ca d[10 ] [80 ];
Res e rv a me mo ri a p ar a 10 cade nas de c ar ac ter es d e80 ca ra cte r es cada un a.
P er o en l a d ecl ar ac ió n com o a r ra y d e p unt e ros :
c ha r * cad [10 ];
El co mp il ad or d esco n oc e el t ama ño de l as cad en as: ¿ cuá nta me mo ri a r ese r va ?
- si e l a r ra y es stat ic y s e i nic ia li za n l as c ade nas e n e l p ro pi o códi go , e l
com pi lad o r c alc ul a l a d ime nsi ón n o ex p lic itad a (a r ra ys s in dim e nsi ón ex p líc ita ).
OTRAS CLASES DE PUNTEROS:
P unt e ros ge n ér ic os: S on t i po v oi d:
v oid *g en e ric o;
Los p unt e r os ti po v oid pu ed en a pu nta r a ot r o tip o d e dat os. Es un a op e rac ió n
del ica da q u e d e pe nd e d el ti p o d e c om pi la do r. Es c o nv e ni ent e em pl ea r e l
“cast in g” pa ra l a c on v e rsi ón. Aú n as í, n o tod a s las c on v e rsi on es están
p er miti das.
P unt e ro nu lo: En C u n pu nte r o qu e a pu nte a un o bj et o vá li do n un ca tend rá un
va lo r ce r o. E l va lo r c e r o s e ut il iz a pa ra i ndic a r qu e ha oc ur r id o a lgú n e r r or (e s
dec ir , qu e a lg un a o p e ra ció n n o s e h a po did o r e ali za r )
int * p = N UL L; // int * p =0;
Pu nte r os c onst ant es : U na d ec la ra ci ón de p u nte r o pr ec ed ida de co n st hac e
qu e e l ob j eto a pu ntad o sea un a c onst ant e (a u nq u e n o el p unt e ro ):
co nst ch a r * p = “V al lad ol id ”;
p [0 ] = ‘f’ // e r ro r. La c ad ena a pu nta da po r + es cte .
p = “ Puc el a ” //Ok . p a p unta a ot ra cade na .
Si l o qu e qu e r emos es dec la ra r un p unt e ro co nstant e;
cha r *co nst p = “ M edi na ”;
p [0 ] = ‘s’; // e rr o r: el ob jet o “ Me di n a”, es cte.
ESTRUCTURA DE DATOS I -- FCI
p = “ P eñ af ie l ”; //e r ro r: e l pu nte r o p e s const ant e.
Punt e r os a p unt e ros:
Ve r ej em p4.c p p, ej e mp11 .c pp y ej em p12.c p p
int ** pu nte r o; // pu nt er o a punt e r o a un obj eto i nt.
El ti p o de ob jet o a pu ntad o des pu és d e un a dobl e in d i re cci ón pu e de se r de
cua lq ui e r c las e.
32 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-33-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
P er mit e ma ne ja r a r ra ys d e mú lti p les d im e nsi on es c on n otac io ne s d el t i p o
***mat, d e múlt i pl e ind i re cci ón q ue pu ed en g en e ra r p r obl e mas si el
trat ami ent o no es el adec ua do. O j o a los “ p unt er os lo cos ”.
Punt e r os a dat os c o mp le jos: S e pu ed en d ecl a ra pu nte r os a d at os de fi nid os
po r e l us ua ri o (t y pe de f( ) ), a dat os st ruct, a fun ci on es, c om o a rg u ment os d e
func i on es...
Dec la rac io n es c om pl ej as:
U na d ec la rac ió n c om pl ej a es un id ent ifi cad o r con más d e d e u n op e r ado r. P ar a
int er p r eta r estas d ecl a rac io nes hac e f a lta sab e r qu e los c o r chet es y
pa r ént esis (o p e rad o r es a la de r ech a de l ide n tific ad or ti en e n p ri or i dad sob re
los aste ris cos (o p e ra do res a l a iz q ui e rda d el id e ntif ica do r. L os p ar ént es is y
co rch etes ti en e n l a m i sma p ri or id ad y s e e va lúa n d e i z qui e rd a a d e r echa . A la
iz q ui er da de l t od o el t ip o d e dat o. Em pl e and o p ar é ntes is s e pu ed e cambi ar el
or de n d e p ri o ri dad es. Las e x pr esi o nes ent r e pa r ént esis s e e v al úan p rim e ro , de
más i nte r nas a más e xt e rnas .
Pa r a i nte r p r eta r d ecl a r aci on es c om pl ej as p od em os se gu ir e l or de n:
1) Em p ez ar c on e l i dent if icad o r y ve r si haci a la d er ec ha ha y co rch etes o
pa r ént esis .
2) I nte r p r eta r es os c or ch etes o p ar é ntes is y v e r si ha cia la i z q ui er da h ay
aste risc os.
3 ) D ent ro de cad a ni v el d e pa r ént esis , d e más int e rn os a má s ext e rn os,
ap lic a r pu ntos 1 y 2.
Veam os un ej em p lo:
cha r *(* (* va r ) ( ) )[ 10 ]
La i nte r p r etac ió n es:
1. La v ar iab l e va r es d e cla rad a c om o
2. u n punt e r o a
3. u na f un ci ón q ue d ev ue l ve
4. u n punt e r o a
ESTRUCTURADE DATOS I -- FCI
5. u n a r ra y d e 1 0 el em ent os, los cua l es so n
6. p unt e ros a
7. ob jet os d e t i po cha r.
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 33](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-34-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Punteros a estructuras
Cómo no, también se pueden usar punteros con estructuras. Vamos a ver como funciona esto de los
punteros con estructuras. Primero de todo hay que definir la estructura de igual forma que hacíamos antes.
La diferencia está en que al declara la variable de tipo estructura debemos ponerle el operador '*' para
indicarle que es un puntero.
Creo que es importante recordar que un puntero no debe apuntar a un lugar cualquiera, debemos darle
una dirección válida donde apuntar. No podemos por ejemplo crear un puntero a estructura y meter los
datos directamente mediante ese puntero, no sabemos dónde apunta el puntero y los datos se
almacenarían en un lugar cualquiera.
Y para comprender cómo funcionan, nada mejor que un ejemplo. Este programa utiliza un puntero para
acceder a la información de la estructura:
#include <stdio.h>
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
int edad;
};
struct estructura_amigo amigo = {
"Juanjo",
"Lopez",
"592-0483",
30
};
struct estructura_amigo *p_amigo;
int main()
{
p_amigo = &amigo;
printf( "%s tiene ", p_amigo->apellido );
printf( "%i años ", p_amigo->edad );
printf( "y su teléfono es el %s.n" , p_amigo->telefono );
}
Has la definición del puntero p_amigo vemos que todo era igual que antes. p_amigo es un puntero a la
estructura estructura_amigo. Dado que es un puntero tenemos que indicarle dónde debe apuntar, en este
caso vamos a hacer que apunte a la variable amigo:
p_amigo = &amigo;
No debemos olvidar el operador & que significa 'dame la dirección donde está almacenado...'.
ESTRUCTURA DE DATOS I -- FCI
Ahora queremos acceder a cada campo de la estructura. Antes lo hacíamos usando el operador '.', pero,
como muestra el ejemplo, si se trabaja con punteros se debe usar el operador '->'. Este operador viene a
significar algo así como: "dame acceso al miembro ... del puntero ...".
Ya sólo nos queda saber cómo podemos utilizar los punteros para introducir datos en las estructuras. Lo
vamos a ver un ejemplo:
#include <stdio.h>
struct estructura_amigo {
char nombre[30];
34 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-35-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
char apellido[40];
int edad;
};
struct estructura_amigo amigo, *p_amigo;
void main()
{
p_amigo = &amigo;
/* Introducimos los datos mediante punteros */
printf("Nombre: ");fflush(stdout);
gets(p_amigo->nombre);
printf("Apellido: ");fflush(stdout);
gets(p_amigo->apellido);
printf("Edad: ");fflush(stdout);
scanf( "%i", &p_amigo->edad );
/* Mostramos los datos */
printf( "El amigo %s ", p_amigo->nombre );
printf( "%s tiene ", p_amigo->apellido );
printf( "%i años.n", p_amigo->edad );
}
NOTA: p_amigo es un puntero que apunta a la estructura amigo. Sin embargo p_amigo->edad es una
variable de tipo int. Por eso al usar el scanf tenemos que poner el &.
ESTRUCTURADE DATOS I -- FCI
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 35](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-36-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Punteros a Arrays de estructuras
Por supuesto también podemos usar punteros con arrays de estructuras. La forma de trabajar es la misma,
lo único que tenemos que hacer es asegurarnos que el puntero inicialmente apunte al primer elemento,
luego saltar al siguiente hasta llegar al último.
#include <stdio.h>
#define ELEMENTOS 3
struct estructura_amigo {
char nombre[30];
char apellido[40];
char telefono[10];
int edad;
};
struct estructura_amigo amigo[] =
{
"Juanjo", "Lopez", "504-4342", 30,
"Marcos", "Gamindez", "405-4823", 42,
"Ana", "Martinez", "533-5694", 20
};
struct estructura_amigo *p_amigo;
void main()
{
int num_amigo;
p_amigo = amigo; /* apuntamos al primer elemento del array */
/* Ahora imprimimos sus datos */
for( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ )
{
printf( "El amigo %s ", p_amigo->nombre );
printf( "%s tiene ", p_amigo->apellido );
printf( "%i años ", p_amigo->edad );
printf( "y su teléfono es el %s.n" , p_amigo->telefono );
/* y ahora saltamos al siguiente elemento */
p_amigo++;
}
}
En vez de p_amigo = amigo; se podía usar la forma p_amigo = &amigo[0];, es decir que apunte al primer
elemento (el elemento 0) del array. La primera forma creo que es más usada pero la segunda quizás indica
más claramente al lector principiante lo que se pretende.
Ahora veamos el ejemplo anterior de cómo introducir datos en un array de estructuras mediante punteros:
ESTRUCTURA DE DATOS I -- FCI
#include <stdio.h>
#define ELEMENTOS 3
struct estructura_amigo {
char nombre[30];
char apellido[40];
int edad;
};
struct estructura_amigo amigo[ELEMENTOS], *p_amigo;
void main()
36 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-37-320.jpg)














![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
eficientemente los trabajos que deben ser enviados a una impresora (o a casi cualquier dispositivo
conectado a un ordenador). De esta manera, el ordenador controla el envio de trabajos al dispositivo, no
enviando un trabajo hasta que la impresora no termine con el anterior.
Análogamente a las pilas, es necesario definir el conjunto de operaciones básicas para especificar
adecuadamente una estructura cola. Estas operaciones serían:
• Crear una cola vacía.
• Determinar si la cola está vacía, en cuyo caso no es posible eliminar elementos.
• Acceder al elemento inicial de la cola.
• Insertar elementos al final de la cola.
• Eliminar elementos al inicio de la cola.
Para determinar correctamente cada una de estas operaciones, es necesario especificar un tipo de
representación para las colas.
Representacion de las colas
Hay diferentes formas de implementar las operaciones relacionadas con colas, una de las más eficientes
es representar el array Cola[1..n] como si fuese circular, es decir, cuando se dé la condición de cola llena
se podrá continuar por el principio de la misma si esas posiciones no estan ocupadas.
Con este esquema de representación, se puede pasar a especificar el conjunto de operaciones necesarias
para definir una cola circular. Para nuestro erstudio partiremos de la creación sin arrays.
Crear cola:
Esta operación consistirá en definir la variable que permitirá almacenar la información y las variables que
apuntarán a los extremos de la estructura. Además, hay que indicar explícitamente que la cola, trás la
creación, está vacía.
typedef struct nodo
{
int dato;
struct nodo * sig;
}tipoNodo;
typedef tipoNodo * pNodo;
typedef tipoNodo * Cola;
Comprobar si la cola está vacía:
Con las condiciones establecidas, basta comprobar si inicio = fin:
boolean Cola_vacia Cola c)
{
boolean r=false;
If ( (*cola)==Null) r=true;
return r;
}
ESTRUCTURADE DATOS I -- FCI
Acceder al elemento inicial o al final de la cola:
Es importante poder acceder fácilmente al inicio o al final de la cola; para ello se puede usar un puntero
llamado primero, y otro llamado ultimo.
Insertar un elemento en la cola:
Debido a la implementación estática de la estructura cola es necesario determinar si existen huecos libres
donde poder insertar antes de hacerlo. Esto puede hacerse de varias formas:
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 51](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-52-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Void Añadir (Cola * primero, Cola *Ultimo, int V)
{
pNuevo nuevo;
nuevo=(pNodo)malloc(sizeof(tipoNodo)); /* crear un nuevo nodo*/
nuevo->dato=v;
nuevo->siguiente=Null; /*este será el ultimo nodo, no debetener siguiente*/
/*Si la cola no estaba vacia, añadimo el nuevo a continuacion de ultimo*/
If(Cola_vacia(ultimo)) (*ultimo)->siguiente=nuevo;
*ultimo=nuevo; /*Ahora, el ultmioelemento de la cola es el nuevo nodo*/
/*Si primero es Null, la cola estaba vacia, ahora primero apuntara también al nuevo nodo */
}
O incrementando antes y luego comparando que 'Cola.inicio' sea igual a 'Cola.fin'.
Eliminar un elemento de la cola:
Sirve exclusivamente para extarer los elementos de una cola, se debe recordar que en cada movimiento de
contenido de la cola los punteros primero y último deben actualizarse debidamente.
Int Leer(Cola * primero, Cola *ultimo)
{
pNodo nodo;/* variable para manipular nodo*/
int v; /*variable auxiliar para retorno*/
nodo=*primero; /*Nodo apunta al primer elemento de la cola*/
if(Cola_vacia(nodo)) return 0; /* Si no hay nodos en la pila retornamos*/
*primero=nodo->siguiente; /*Asignmam,os a primero la dirección del segundo nodo*/
v=nodo->valor; /*Guardamos el valor de retorno*/
free(nodo); /*Borra el nodo*/
if(Cola_vacia(primero))*ultimo=NULL; /*Si la cola quedo vacia, ultimo debe ser NULL*/
return v;
}
Conclusión
De todo esto puede sorprender que la condición de cola llena sea la misma que la de cola vacía. Sin
embargo, en el caso de la inserción de elementos cuando Cola.inicio = Cola.fin es cierto, no es verdad que
la cola esté llena, en realidad hay un espacio libre, ya que Cola.inicio apunta a una posición libre, la
anterior al primer elemento real de la cola. Pero si se decide insertar un elemento en esa posición, no sería
posible distinguir si Cola.inicio = Cola.fin indica que la cola está llena o vacía. Se podría definir alguna
variable lógica que indicase cual de las dos situaciones se está dando en realidad. Esta modificación
implicaría introducir alguna nueva operación en los métodos de inserción y borrado, lo que, en general,
resultaría peor solución que no utilizar un elemento del array. Suele ser mejor solución utilizar siempre 'n-1'
elementos de la cola, y no 'n', que complicar dos operaciones que se tendrán que repetir múltiples veces
durante la ejecución de un programa.
Pilas y colas múltiples
Hasta ahora se ha tratado solamente con la representación en memoria y manipulación de una única pila
ESTRUCTURA DE DATOS I -- FCI
o cola. Se han visto dos representaciones secuenciales eficientes para dichas estructuras. Sin embargo, en
ocasiones, es preciso representar varias estructuras utilizando el mismo espacio de memoria.
Supongamos que seguimos transformando las estructuras de datos en representaciones secuenciales,
tipo array. Si sólo hay que representar dos pilas sobre un mismo array A[1..n], la solución puede resultar
simple. Se puede hacer crecer las dos pilas partiendo desde los extremos opuestos del array, de forma que
A[1] será el elemento situado en el fondo de la primera pila y A[n] el correspondiente para la segunda pila.
Entonces, la pila 1 crecerá incrementando los índices hacia A[n] y la pila 2 lo hará decrementando los
índices hacia A[1]. De esta manera, es posible utilizar eficientemente todo el espacio disponible.
52 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-53-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Si se plantea representar más de dos pilas sobre ese mismo array A, no es posible seguir la misma
estrategia, ya que un array unidimensional sólo tiene dos puntos fijos, A[1] y A[n], y cada pila requiere un
punto fijo para representar el elemento más profundo.
Cuando se requiere representar secuencialmente más de dos pilas, por ejemplo m pilas, es necesario
dividir en m segmentos la memoria disponible, A[1..n], y asignar a cada uno de los segmentos a una pila.
La división inicial de A[1..n] en segmentos se puede hacer en base al tamaño esperado de cada una de las
estructuras. Si no es posible conocer esa información, el array A se puede dividir en segmentos de igual
tamaño. Para cada pila i, se utilizará un índice f(i) para representar el fondo de la pila i y un índice c(i) para
indicar dónde está su cima. En general, se hace que f(i) esté una posición por debajo del fondo real de la
pila, de forma que se cumpla la condición f(i)=c(i) si y solamente si la pila i está vacía.
La discusión realizada para el caso de pilas múltiples sirve de base para poder establecer estrategias de
manipulación de varias colas en un mismo array, incluso la combinación de estructuras pilas y colas sobre
la misma localización secuencial.
ESTRUCTURADE DATOS I -- FCI
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 53](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-54-320.jpg)
















![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
LA PILA DE RECURSION
La m em or ia d el o rd en a do r s e d i vid e (d e ma ne ra l ógi ca, n o f ísic a ) en va r ios seg me ntos
(4 ):
Se gm ent o de c ód igo : Pa rt e de la m emo r ia don de s e gu ar dan las instr ucc io n es de l
p ro gr ama e n c od. Má q u ina .
Se gm ent o d e dat os: Pa rt e d e la m em or ia dest in ada a al mac e na r las v ar iab l es
estát icas.
Mo ntí cu lo: P a rte de la mem or ia dest in ada a la s va r iab les di nám icas.
Pi la d el p r og ram a: P art e d esti na da a las v ar ia bles l oca l es y p a rám et ros d e la fu nci ón
qu e está si end o ej ec ut ada.
Llam ada a u na fu nci ó n:
• Se res e r va es pac i o e n la pi la pa ra los p ar ámet r os d e la f unc ió n y sus va r iab les
loc al es.
• S e gua rd a en la p il a la di r ecc ió n d e la lí n ea de cód ig o d esd e d o nde se ha ll ama do
a la fu nc ió n.
• S e alm ac ena n los p ar ámet r os d e la fu nci ó n y sus v al o res e n l a pi la.
• Al t e rmi na r l a fu n ció n, s e li be ra la m em or ia asig nad a en l a pi l a y s e vu el v e a la
inst ruc . Actu al.
Llam ada a u na fu nci ó n r ecu rsi v a:
En e l cas o r ecu rs i vo, cada lla mad a ge n er a u n nu e vo ej em p la r d e l a fu nci ón c on s us
co rr es p ond ie nt es o bj et os l oca l es:
• La f unc ió n s e e jec uta rá n o rma lm ent e hast a la ll ama da a sí m isma. En es e
mom ent o s e c r ean e n l a p il a n u ev os p ar ám etr os y va ri abl es lo cal es.
• El nu e vo e je mp la r de f un ci ón c om ie n za a ej ecut a rse .
• Se c re an más co p ias hast a ll ega r a l os cas os b ases , d ond e se res ue l ve
dir ect am ent e el va l or, y s e va sa li e ndo li be r and o m emo r ia hasta ll ega r a l a pr im er a
lla mad a (ú ltim a e n c e r r ars e )
EJ E RC ICI O S
a). To r r es de Ha no i: P rob l ema d e sol uc ió n rec u rsi va, c ons iste e n mo ve r to dos l os
discos ( de dif e r ent es tamañ os ) d e u na ag uj a a otr a, us an do un a agu ja au xi lia r, y
sabi end o qu e u n di sco n o
pu ed e esta r s ob r e otr o m en o r
qu e ést e.
/* S ol uc ió n:
1- M o v er n-1 disc os d e A a B
A B C 2- M o v er 1 d isco de A a C
3- M o v er n-1 disc os d e B a C
*/
vo id H an oi ( n, i ni cia l, a ux, fi na l )
{
if ( n> 0 )
{
Ha no i (n- 1, i nic ia l, f in al , au x );
p ri ntf (" M o ve r %d d e %c a %c ", n, in ici al, fi na l ) ;
Ha no i (n -1, a u x, i ni cia l, fin al );
b). Ca lcu la r e le v ad o a n d e f o rma r ec urs i va:
ESTRUCTURA DE DATOS I -- FCI
flo at x el e vn ( fl oat b as e, int e x p )
{
if (e x p == O ) r etu rn (1 );
r etu rn ( b as e*x e le v n (b ase, e x p-1 )) ;
c). M ult ip lic a r 2 n°s c o n sum as suc es iv as r ec urs:
int m ult i ( i nt a, i nt b )
{
if (b == O ) r etu r n (0) ; re tur n ( a + mu lti (a , b-1 ) );
d). ¿ Qu é h ac e este p r o gra ma ?:
vo id c os a ( ch ar *ca d, i nt i ) if ( ca d[ i ] '= ' O ' )
cosa (c ad,i +1 );
70 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-71-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
p ri ntf (" %c ", ca d[ i ] );
ESTRUCTURADE DATOS I -- FCI
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 71](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-72-320.jpg)


![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Definición (2): un árbol binario con n nodos y profundidad k se dice que es completo si y sólo si sus
nodos se corresponden con los nodos numerados de 1 a n en el árbol binario lleno de profundidad k.
Cuando un árbol no es lleno pero es completo, también es posible la representación secuencial eficiente
de la estructura de nodos que lo componen.
En l os a p art ad os qu e sigu en se co nsid e ra rá n ú nic am e nt e á rb ol es bina r ios y , po r l o
tanto , s e ut il iz ar á l a p alab r a á rb ol p ar a r ef er i rs e a ár bo l bi na r io. Los árb o les de g rad o
sup e ri o r a 2 re cib en e l nomb r e d e árb o les mu l ticam in o.
Á rb ol b in ar io de bús q ued a.- L os á rb o les b i na ri os s e ut ili z an f r e cue nt eme nt e pa ra
r ep r es enta r co nj unt os de d atos cu y os e l em en tos se id ent if ica n po r u na c la v e ú nic a. Si
el á rbo l está o rga ni za d o d e ta l m an e ra q ue la cla v e d e c ada n odo es ma yo r q ue tod as
las c la v es s u sub á rbo l i z qu ie rd o, y me n or qu e todas las cl a ves d el s u bárb o l d e rec ho se
dic e qu e este á rb ol es un árb o l bi na ri o d e b ús qu ed a.
Ej em p lo:
Representación de los árboles binarios
Como hemos visto, si el árbol binario que se desea representar cumpla las condiciones de árbol lleno o
árbol completo, es posible encontrar una buena representación secuencial del mismo. En esos casos, los
nodos pueden ser almacenados en un array unidimensional, A, de manera que el nodo numerado como i
se almacena en A[i]. Esto permite localizar fácilmente las posiciones de los nodos padre, hizo izquierdo e
hijo derecho de cualquier nodo i en un árbol binario arbitrario que cumpla tales condiciones.
• Lema 3: si un árbol binario completo con n nodos se representa secuencialmente, se cumple que
para cualquier nodo con índice i, entre 1 y n, se tiene que:
• (1) El padre del nodo i estará localizado en la posición [i div 2]
• si i <> 1. Si i=1, se trata del nodo raíz y no tiene padre.
•
• (2) El hijo izquierdo del nodo estará localizado en la posición [2i]
• si 2i <= n. Si 2i>n, el nodo no tiene hijo izquierdo.
•
• (3) El hijo derecho del nodo estará localizado en la posición [2i+1] si
• 2i+1 <= n. Si (2i+1) > n, el nodo no tiene hijo derecho.
Evidentemente, la representación puramente secuencial de un árbol se podría extender inmediatamente a
ESTRUCTURA DE DATOS I -- FCI
cualquier árbol binario, pero esto implicaría, en la mayoría de los casos, desaprovechar gran cantidad del
espacio reservado en memoria para el array. Así, aunque para árboles binarios completos la
representación es ideal y no se desaprovecha espacio, en el peor de los casos para un árbol lineal (una
lista) de profundidad k, se necesitaría espacio para representar (2^k) - 1 nodos, y sólo k de esas posiciones
estarían realmente ocupadas.
Además de los problemas de eficiencia desde el punto de vista del almacenamiento en memoria, hay que
tener en cuenta los problemas generales de manipulación de estructuras secuenciales. Las operaciones
de inserción y borrado de elementos en cualquier posición del array implican necesariamente el
movimiento potencial de muchos nodos. Estos problemas se pueden solventar adecuadamente mediante
la utilización de una representación enlazada de los nodos.
74 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-75-320.jpg)


![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Grafica un Arbol
vo id Gmu est ra A BJ ( nod o arb ol * p, i nt ni v el, int c ol, int p os, int i )
{
s etli n est yl e (0,1, 0) ;
if ( ! P ) )
{
Gmu estr a AB J ( p->i z qu i e rda ,n iv e l+1,c ol - pos/ 2, p os/2,c ol );
s[0 ]= p->d ato ;
setco l or (4 );
lin e (i ,( ni v el -1 )*45, co l,n iv e l*45 ) ;
cir cl e (co l, ni v el*4 5,10 );
setco l or (1 0) ;
outt ext x y (c ol-5 ,n iv e l*4 5-5,s );
Gmu estr a AB J ( p->d e re c ha,n i ve l+1 ,co l + p os/2, p os/2,c ol );
s etl in est yl e (0, 1,0 ) ;
}
}
Operaciones básicas
Un a ta r ea mu y co mún a re al iz ar c on un á rb ol es ej ec uta r un a d et er min ada o p er aci ó n
con cad a un o d e los e l em ent os d el á rb ol. Est a o p e rac ió n s e c ons id e ra e nto nc es c om o
un pa rám et r o de una t ar é más g e ne r al qu e e s la v isit a de t od os l os nod os o, c om o se
den om in a us ua lme nt e, del r ec o r rid o d el á rb ol.
Si s e c onsi de r a la t ar e a com o u n pr oc eso s ec ue nci al, ent o nces los n odos in di vi dua l es
se visit an e n u n o rd en es pec íf ico , y p u ed en c ons id er a rse c om o o r ga ni zad os s egú n u na
estr uct ur a l in ea l. D e h ech o, s e sim p li fic a co n side r abl em ent e la d esc ri pc ió n d e mu ch os
alg o ritm os si p u ed e ha bla rs e de l p r oces o d el sigu ie nt e el em ent o e n el á rb ol, s eg ún u n
cie rt o or de n sub y ac ent e.
Recorrido de árboles binarios
Ha y d os f o rmas bás ic as d e r ec or r e r un á rb ol: El
r eco r ri do en am pl itud y el r eco r ri do e n p r of un dida d.
Rec o r rid o e n am pl itud. - Es a qu el r eco r ri do q ue rec o r re el
árb ol p o r ni v el es, en e l últ imo e je mp l o se r ía:
12 - 8, 17 - 5 ,9,15
Rec o r rid o e n p r of und id ad.- R ec or r e el á rb ol p or s ubá rb ol es. Ha y t res fo rmas: P r eo rd en ,
ESTRUCTURADE DATOS I -- FCI
In o rd e n y post o rd en.
P re o rd en: Ra i z, sub á rb ol iz q ui e rd o y sub á rbo l de re ch o.
In O rde n: S uba rb ol iz q u ie rd o, ra iz , sub á rbo l d e r ech o.
P osto rd en : Suba rb o l i z qu i er do, sub arb o l d er e cho, r ai z.
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 77](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-78-320.jpg)








![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
MATRIZ
#include<stdio.h>
#include<iostream.h>
#include<conio.h>
#define fil 15
#define col 15
void ingresar(int matriz1[fil][col], int f1 ,int c1)
{
int i, j;
for (i=1;i<=f1;i++)
for(j=1;j<=c1;j++)
{
cout<<"ingrese valor para la posicion "<<i<<j<<" ";
cin>>matriz1[i][j];
}
}
void imprimir(int matriz1[fil][col], int f1 ,int c1)
{int i,j;
for(i=1;i<=f1;i++)
{
for(j=1;j<=c1;j++)
{
cout<<matriz1[i][j]<<'t';
}
cout<<endl;
}
}
void limite(int &f,int &c)
{
do
{cout<<"ingrese el limite de fila ";
cin>>f;
}while(f<0&&f>fil);
do
{cout<<"ingrese el limite columna ";
cin>>c;
}while(c<0&&c>col);
}
void restar(int matriz1[fil][col],int matriz2[fil][col],int mresta[fil][col],int f,int c)
{
int i,j;
for(i=1;i<=f;i++)
for(j=1;j<=c;j++)
mresta[i][j]=matriz1[i][j]-matriz2[i][j];
}
void sumar(int matriz1[fil][col],int matriz2[fil][col],int msuma[fil][col],int f,int c)
{
int i,j;
for(i=1;i<=f;i++)
ESTRUCTURA DE DATOS I -- FCI
for(j=1;j<=c;j++)
msuma[i][j]=matriz1[i][j]+matriz2[i][j];
}
void multiplicar(int matriz1[fil][col],int matriz2[fil][col],int mat_pro[fil][col],int f,int f1,int c1)
{
int i,aux,j,k,produc,suma;
for(i=1;i<=f;i++)
{
for(j=1;j<=c1;j++)
{
aux=0;
86 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-87-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
for(k=1;k<=f1;k++)
{
produc=matriz1[i][k]*matriz2[k][j];
aux+=produc;
}
mat_pro[i][j]=aux;
}
}
}
void main ()
{
clrscr();
int matriz1[fil][col],matriz2[fil][col];
int msuma[fil][col],mresta[fil][col];
int matmul[fil][col];
int f,c,f2,c2,opcion,llena=0;
limite(f,c);
limite(f2,c2);
do
{
if(llena==1)
{
cout<<"MATRICES";
cout<<endl;
imprimir(matriz1,f,c);
cout<<endl;
cout<<endl;
imprimir(matriz2,f2,c2);
getch();
}
do
{
gotoxy(15,8);cout<<"1)INGRESE MATRICES ";
gotoxy(15,9);cout<<"2)SUMA MATRICES ";
gotoxy(15,10);cout<<"3)RESTA MATRICES";
gotoxy(15,11);cout<<"4)MULTIPLICA MATRICES";
gotoxy(15,12);cout<<"5)SALIR";
gotoxy(15,13);cout<<"Digite la opcion :";
gotoxy(30,14);cin>>opcion;
}while(opcion<0||opcion>5);
switch(opcion)
{
case 1:
{
clrscr();
limite(f,c);
cout<<"Datos para la primera matriz"<<endl;
ingresar(matriz1,f,c);
limite(f2,c2);
cout<<"Datos para la segunda matriz"<<endl;
ESTRUCTURADE DATOS I -- FCI
ingresar(matriz2,f2,c2);
llena=1;
getch();
clrscr();
break;
}
case 2:
{
clrscr();
if(f==f2&&c==c2)
{
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 87](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-88-320.jpg)




![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
• Insertar datos al Inicio de una lista, al final , y de forma ordenada en una lista abierta
• Borrar datos de una lista abierta uno o toda la lista.
• Mostrar una lista
Propuesta:
• Construir una función para poder insertar un nuevo elemento a la lista antes de un elemento
determinado
• Construir una función para poder insertar un nuevo elemento a la lista después de un elemento
determinado
#include<conio.h>
#include<stdio.h>
#include<iostream.h>
#include<stdlib.h>
#include<string.h>
#include<stdlib.h>
typedef struct nodo
{int codigo; char nombre[30]; float sueldo;
struct nodo * siguiente;
}tipoNodo;
typedef tipoNodo * pNodo;
typedef tipoNodo *Lista;
// Funciones Prototipos
int ListaVacia(Lista l);
void Insertar(Lista *l,int v); // insertar al inicio o cabecera de la lsiat
void InsertarC(Lista *l,int v); // insertar al inico de una lista
void InsertarF(Lista *l,int v); // insertar al final de una lista
void Borrar(Lista *l,int v); // borrar un elemento de la lista
void BorrarLista(Lista *l); // borrar toda las lista
void MostrarLista(Lista l);
void main()
{clrscr();
Lista lista=NULL;
pNodo p;
InsertarC (&lista,1);
InsertarC (&lista,2);
InsertarC (&lista,4);
InsertarC (&lista,3);
MostrarLista(lista);
getch();
system("PAUSE");
}
int ListaVacia(Lista lista)
{return(lista==NULL);
ESTRUCTURA DE DATOS I -- FCI
}
void Insertar(Lista *lista,int v)
{pNodo nuevo, anterior;
nuevo=(pNodo)malloc(sizeof(tipoNodo));
nuevo->codigo=v;
printf("Ingrese Nombre del Empleado :");
scanf("%s",&nuevo->nombre);
printf("Ingrese el sueldo :");
scanf("%f",&nuevo->sueldo);
if(ListaVacia(*lista)||(*lista)->codigo>v){
92 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-93-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Implementaciones de Funciones para manipular: Listas Abiertas y Pilas
Usando cadenas de caracteres
#include<stdlib.h>
#include<iostream.h>
#include<conio.h>
#include<stdio.h>
#include<string.h>
typedef struct nodo
{char nombre[40]; char apellido[30]; char fono[25];
int edad;
struct nodo * sig;
}tipoNodo;
typedef tipoNodo * pNodo;
typedef tipoNodo * Pila;
typedef tipoNodo *Lista;
char n[40], ap[40], fo[40];
void InsertarPila(Pila *pila, char n[],char ap[],char fo[], int v)
{pNodo nuevo;
nuevo=(pNodo)malloc(sizeof(tipoNodo));
strcpy(nuevo->nombre,n);
strcpy(nuevo->apellido,ap);
strcpy(nuevo->fono,fo);
nuevo->edad=v;
nuevo->sig=*pila;
*pila=nuevo;
}
int Pop(Pila *pila, char n[],char ap[],char fo[])
{pNodo nodo=*pila;
int v=0;
if(!nodo) cout<< "Pila Vacias...n";
else
{*pila=nodo->sig;
strcpy(n,nodo->nombre);
strcpy(ap,nodo->apellido);
strcpy(fo,nodo->fono);
v=nodo->edad;
free(nodo);
}
return v;
}
ESTRUCTURA DE DATOS I -- FCI
void MostrarPila(Pila pila)
{pNodo nodo=pila;
int c;
while(nodo)
{c=Pop(&nodo,n,ap,fo);
cout<<n<<"tt"<<ap<<"t"<<fo<<"tt"<<c<<"n";
}
}
void InsertarC(Lista *lista, char n[],char ap[],char fo[], int v)
{pNodo nuevo;
94 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-95-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
nuevo=(pNodo)malloc(sizeof(tipoNodo));
strcpy(nuevo->nombre,n);
strcpy(nuevo->apellido,ap);
strcpy(nuevo->fono,fo);
nuevo->edad=v;
nuevo->sig=*lista;
*lista=nuevo;
}
void MostrarLista(Lista lista)
{ pNodo nodo=lista;
if(!lista) printf("Lista vacia n");
else
while(nodo)
{ cout<<nodo->nombre<<"t"<<nodo->apellido<<"t"<<nodo->fono<<"t"<<nodo->edad<<"n";
nodo=nodo->sig;
}
}
void introducirDespues(Lista *lista,char cl[],char no[],char ap[],char fo[],int dd)
{pNodo nuevo, aux=*lista;
while (aux && strcmp(aux->nombre,cl)!=0)
aux=aux->sig;
if (aux && strcmp(aux->nombre,cl)==0)
{ nuevo=(pNodo)malloc(sizeof(tipoNodo));
strcpy(nuevo->nombre,no);
strcpy(nuevo->apellido,ap);
strcpy(nuevo->fono,fo);
nuevo->edad=dd;
nuevo->sig=aux->sig;
aux->sig=nuevo;
} else
cout <<"no se inserto... dato"<<cl<<" no encontradon";
}
void introducirAntes(Lista *lista,char cl[],char no[],char ap[],char fo[],int dd)
{pNodo nuevo, aux=*lista;
nuevo=(pNodo)malloc(sizeof(tipoNodo));
strcpy(nuevo->nombre,no);
strcpy(nuevo->apellido,ap);
strcpy(nuevo->fono,fo);
nuevo->edad=dd;
if (strcmp(aux->nombre,cl)==0)
{nuevo->sig=*lista;
*lista=nuevo;
}
else
{ while (aux && strcmp(aux->sig->nombre,cl)!=0)
aux=aux->sig;
ESTRUCTURADE DATOS I -- FCI
if (aux && strcmp(aux->sig->nombre,cl)==0)
{ nuevo->sig=aux->sig;
aux->sig=nuevo;
}
else
cout <<"no se inserto... dato"<<cl<<" no encontradon";
}
}
void eliminar(Lista *lista,char cl[])
{pNodo aux=*lista;
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 95](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-96-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
REGISTRO DE PACIENTES USANDO LISTAS ABIERTAS
#include<string.h>
#include<conio.h>
#include<stdio.h>
#include<iostream.h>
#include<stdlib.h>
typedef struct nodo
{int historia;
char nombre[45];
double cedula;
int edad;
char direccion[40];
char sexo[15];
struct nodo * siguiente;
}tipoNodo;
typedef tipoNodo * pNodo;
typedef tipoNodo *Lista;
// Funciones Prototipos
int ListaVacia(Lista l);
void InsertarC(Lista *l,int hc,char n[],double c,int e,char d[],char s[]);
void InsertarF(Lista *l,int hc,char n[],double c,int e,char d[],char s[]);
void InsertarO(Lista *l,int hc,char n[],double c,int e,char d[],char s[]);
void Crea_NLista(Lista l1,Lista *l2);
void Borrar(Lista *l,int hc);
void BorrarLista(Lista *l);
void MostrarLista(Lista l);
void main()
{clrscr();
Lista lista=NULL, lista2=NULL;
pNodo p;
char n[45], d[40] ,s[15];
int i,h, e;
double c;
for(i=0;i<5;i++)
{ cout<<"n Ingrese un numero de historia clinica :"; cin>> h;
cout<<"n Ingrese los nombres del paciente :"; gets(n);
cout<<"n Ingrese la cedula del paciente :"; cin>>c;
cout<<"n Ingrese la edad del paciente :"; cin>> e;
cout<<"n Ingrese la direccion del paciente :"; gets(d);
cout<<"n Ingrese el sexo del paciente :"; cin>>s;
InsertarC (&lista,h,n,c,e,d,s);
}
clrscr();
cout<<" Lista Inicial n";
MostrarLista(lista);
getch();
ESTRUCTURADE DATOS I -- FCI
//Generar la nueva lista
Crea_NLista(lista,&lista2);
cout<<"n NUEVA LISTA n";
MostrarLista(lista2);
getch();
}
int ListaVacia(Lista lista)
{return(lista==NULL);
}
void InsertarC(Lista *lista, int hc, char n[],double c,int e,char d[],char s[])
{pNodo nuevo;
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 97](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-98-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
nuevo=(pNodo)malloc(sizeof(tipoNodo));
nuevo->historia=hc;
strcpy(nuevo->nombre,n);
nuevo->cedula=c;
nuevo->edad=e;
strcpy(nuevo->direccion,d);
strcpy(nuevo->sexo,s);
nuevo->siguiente=*lista;
*lista=nuevo;
}
void InsertarF(Lista *lista, int hc, char n[],double c,int e,char d[],char s[])
{pNodo nuevo, anterior;
nuevo=(pNodo)malloc(sizeof(tipoNodo));
nuevo->historia=hc;
strcpy(nuevo->nombre,n);
nuevo->cedula=c;
nuevo->edad=e;
strcpy(nuevo->direccion,d);
strcpy(nuevo->sexo,s);
if(ListaVacia(*lista)){
nuevo->siguiente=*lista;
*lista=nuevo;
}
else
{anterior=*lista;
while(anterior->siguiente!=NULL)
anterior=anterior->siguiente;
anterior->siguiente=nuevo;
nuevo->siguiente=NULL;
}
}
void InsertarO(Lista *lista, int hc, char n[],double c,int e,char d[],char s[])
{pNodo nuevo, anterior;
nuevo=(pNodo)malloc(sizeof(tipoNodo));
nuevo->historia=hc;
strcpy(nuevo->nombre,n);
nuevo->cedula=c;
nuevo->edad=e;
strcpy(nuevo->direccion,d);
strcpy(nuevo->sexo,s);
if(ListaVacia(*lista)||(*lista)->historia>hc){
nuevo->siguiente=*lista;
*lista=nuevo;
}
else
{anterior=*lista;
ESTRUCTURA DE DATOS I -- FCI
while(anterior->siguiente && anterior->historia <=hc)
anterior=anterior->siguiente;
nuevo->siguiente=anterior->siguiente;
anterior->siguiente=nuevo;
}
}
void Crea_NLista(Lista l1,Lista *l2)
{pNodo nodo=l1;
if(ListaVacia(l1)) printf("Lista vacia...No se genero la otra lista n");
while(nodo)
{if (nodo->edad <20 )
98 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-99-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
Manejo de Arboles
#include<stdio.h>
#include<conio.h>
#include<stdlib.h>
#include<math.h>
#include<ctype.h>
#include<string.h>
#include<graphics.h>
#include "interface.h"
#include "arbol.h"
void main(void){
int gdriver = DETECT, gmode;
int elemento, valor, opcion, i;
char *dato;
NODOARBOL *raiz=NULL;
clrscr();
for(;;){
nuevo:
valor=0;
opcion=menu();
if((opcion>=8 && opcion<=16) && raiz==NULL){
window(52,8,80,12);
textattr(YELLOW + BLINK);
textbackground(BLACK);
cprintf("nr nr No hay nodos nr en el rbol ");
window(1,1,80,25);
ESTRUCTURA DE DATOS I -- FCI
getch(); continue;
}
switch(opcion){
case 6:
clrscr();
printf("nIngrese elemento a insertar [0 : 99]: "); gets(dato);
100 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-101-320.jpg)
![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
for(i=0;i<strlen(dato);i++)
if(!isdigit(dato[i])){ printf("nDato inv lido"); getch(); goto nuevo;}
elemento=atoi(dato);
if(elemento<0 || elemento>99){
printf("nDato desbordado"); getch(); break;}
insertar(&raiz, elemento);
break;
case 8:
clrscr();
printf("nIngrese elemento a eliminar [0 : 99]: "); gets(dato);
for(i=0;i<strlen(dato);i++)
if(!isdigit(dato[i])){ printf("nDato inv lido"); getch(); goto nuevo;}
elemento=atoi(dato);
if(elemento<0 || elemento>99){
printf("nDato desbordado"); getch(); break;}
buscar(raiz, elemento, &valor);
if(valor==1){ raiz=eliminar( raiz, elemento);
printf("nNodo eliminadon"); getch(); }
break;
case 10:
clrscr();
printf("El rbol inorder es: "); inorder(raiz);
getch();
break;
case 12:
clrscr();
ESTRUCTURADE DATOS I -- FCI
printf("El rbol preorder es: "); preorder(raiz);
getch();
break;
case 14:
clrscr();
printf("El rbol postorder es: "); postorder(raiz);
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 101](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-102-320.jpg)



![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
p1->izq=cabeza->izq;
free(cabeza);
return(p2);
}
}
if(cabeza->dato<elemento) cabeza->der=eliminar(cabeza->der, elemento);
else cabeza->izq=eliminar(cabeza->izq, elemento);
return(cabeza);
}
void dibujar(NODOARBOL *cabeza, int a, int b, int c, int d){
char value[3];
if(cabeza!=NULL){
itoa(cabeza->dato,value,10);
circle(300+a,75+b,14);
setcolor(YELLOW); outtextxy(295+a,75+b,value); setcolor(WHITE);
if(d==1) line(300+a+pow(2,c+1),b+14,300+a,61+b);
else if(d==2) line(300+a-pow(2,c+1),b+14,300+a,61+b);
dibujar(cabeza->izq,a-pow(2,c)-pow(2,d-4),b+75,c-1,1);
dibujar(cabeza->der,a+pow(2,c)+pow(2,d-4),b+75,c-1,2);}
}
ESTRUCTURADE DATOS I -- FCI
Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 105](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-106-320.jpg)










![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
UNIVERSIDAD TECNICA DE MANABI
CIENCIAS INFORMATICAS
PERIODO SEPTIEMBRE 2007 – MARZO 2008
EXAMEN DE ESTRUCTURA DE DATOS
NOMBRE:
SEMESTRE: Tercero “_______” PARCIAL: Primero
FECHA: ____________________ PROFESOR: Ing. ___________________________
Se tiene una lista abierta con los campos:
int codigo:
char nombre[35];
float sueldo;
1) Implemente una función para pasar los datos de la lista a una pila
2) Eliminar a los empleados que tienen sueldo menor a $ 125
3) Ingrese un nuevo nodo, pero justo antes del codigo=150.
2) Escriba la función que utilice una cola con elementos (solo dos campos: valor y siguiente) y
que pueda pasar estos datos a una lista abierta de forma ordenada
3) En el siguiente procedimiento llamado examen UD deberá identificar gráficamente lo que
realiza este procedimiento, cual seria el verdadero nombre de este procedimiento y para que
serviría este procedimiento
void EXAMEN(Nuevo_dato *va, int v)
{pNodo nodo;
nodo=*va;
do{
if ((*va)->siguiente->valor !=v) *va=(*va)->siguiente;
}while (*va)-siguiente->valor!=v && *va!=nodo);
If((*va)->siguiente->valor==v)
If (*va==(*va)->siguiente{
ESTRUCTURA DE DATOS I -- FCI
free(*va);
*va=NULL;
}
else
{nodo=(*va)->siguiente;
(*va)->siguiente=nodo->siguiente;
}
}
}
116 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-117-320.jpg)

![Universidad Tecnica de Manabí Facultad de Ciencias Informaticas
UNIVERSIDAD TECNICA DE MANABI
CIENCIAS INFORMATICAS
EXAMEN DE RECUPERACIÓN DE ESTRUCTURA DE DATOS
NOMBRE:
SEMESTRE: Tercero “C”
PROFESOR: Ing. Christian Torres FECHA: jueves 16 de agosto del
2007
typedef struct nodo typedef tipoNodo * pNodo;
{char nombre[40]; typedef tipoNodo *Lista;
char apellido[30];
char fono[15];
int edad;
struct nodo * sig;
}tipoNodo;
1. Teniendo la presente estructura y definición de tipos de datos, implemente una función
para insertar nodos al inicio de una lista abierta. (1.5 pts)
2. Implemente una función para poder insertar un nuevo nodo antes del nodo con el campo
nombre= “Ximena”. Para la estructura ya indicada. Asuma que los datos son pasado
como argumentos de la función. ( 4.0pts)
ESTRUCTURA DE DATOS I -- FCI
3. Escriba una función para eliminar el primer nodo de una lista doblemente enlazada
circular. Realice las modificaciones respectivas en la estructura y tipo de datos dados
para que pueda trabajar en esta pregunta.( 1.5 pts)
4. Construya una pila utilizado la estructura propuesta, e implemente una función que
permita invertir una pila. ( 3.0pts)
118 Manual de Estructura de Datos](https://image.slidesharecdn.com/modulo-estructuradedatosi-120928123001-phpapp02/85/Modulo-estructura_de_datos_i-119-320.jpg)

Modulo -estructura_de_datos_i
- 1. UNIVERSIDAD TECNICA DE MANABÍ FACULTAD DE CIENCIAS INFORMATICAS ESTRUCTURA DE DATOS I PROGRAMACIÓN EN C++ “Lo importante en un individuo, no es lo que piensa, sino lo que hace” J. Watson FACULTAD DE CIENCIAS INFORMATICAS FCI - 2008 Autores: Ing. Esthela San Andres Ing. Christian Torres
- 2. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas ESTRUCTURA DE DATOS I PROGRAMACIÓN EN C++ Sistema de Información Introducción.- Un sistema de información es un conjunto de elementos que interactúan entre sí con el fin de apoyar las actividades de una empresa o negocio. El equipo computacional: el hardware necesario para que el sistema de información pueda operar. El recurso humano que interactúa con el Sistema de Información, el cual está formado por las personas que utilizan el sistema. Un sistema de información realiza cuatro actividades básicas: entrada, almacenamiento, procesamiento y salida de información. Entrada de Información: Es el proceso mediante el cual el Sistema de Información toma los datos que requiere para procesar la información. Las entradas pueden ser manuales o automáticas. Las manuales son aquellas que se proporcionan en forma directa por el usuario, mientras que las automáticas son datos o información que provienen o son tomados de otros sistemas o módulos. Esto último se denomina interfases automáticas. Las unidades típicas de entrada de datos a las computadoras son las terminales, las cintas magnéticas, las unidades de diskette, los códigos de barras, los escáners, la voz, los monitores sensibles al tacto, el teclado y el mouse, entre otras. Almacenamiento de información: El almacenamiento es una de las actividades o capacidades más importantes que tiene una computadora, ya que a través de esta propiedad el sistema puede recordar la información guardada en la sección o proceso anterior. Esta información suele ser almacenada en estructuras de información denominadas archivos. La unidad típica de almacenamiento son los discos magnéticos o discos duros, los discos flexibles o diskettes y los discos compactos (CD-ROM). Procesamiento de Información: Es la capacidad del Sistema de Información para efectuar cálculos de acuerdo con una secuencia de operaciones preestablecida. Estos cálculos pueden efectuarse con datos introducidos recientemente en el sistema o bien con datos que están almacenados. Esta característica de los sistemas permite la transformación de datos fuente en información que puede ser utilizada para la toma de decisiones, lo que hace posible, entre otras cosas, que un tomador de decisiones genere una ESTRUCTURADE DATOS I -- FCI proyección financiera a partir de los datos que contiene un estado de resultados o un balance general de un año base. Salida de Información: La salida es la capacidad de un Sistema de Información para sacar la información procesada o bien datos de entrada al exterior. Las unidades típicas de salida son las impresoras, terminales, diskettes, cintas magnéticas, la voz, los graficadores y los plotters, entre otros. Es importante aclarar que la salida de un Sistema de Información puede constituir la entrada a otro Sistema de Información o módulo. En este caso, también existe una interfase automática de salida. Por ejemplo, el Sistema de Control de Clientes tiene una interfase automática de salida con el Sistema de Contabilidad, ya que genera las pólizas contables de los movimientos procesales de los clientes. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 1
- 3. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas A continuación se muestran las diferentes actividades que puede realizar un Sistema de Información de Control de Clientes: Actividades que realiza un Sistema de Información: Entradas: • Datos generales del cliente: nombre, dirección, tipo de cliente, etc. • Políticas de créditos: límite de crédito, plazo de pago, etc. • Facturas (interfase automático). • Pagos, depuraciones, etc. Proceso: • Cálculo de antigüedad de saldos. • Cálculo de intereses moratorios. • Cálculo del saldo de un cliente. Almacenamiento: • Movimientos del mes (pagos, depuraciones). • Catálogo de clientes. • Facturas. Salidas: • Reporte de pagos. • Estados de cuenta. • Pólizas contables (interfase automática) • Consultas de saldos en pantalla de una terminal. Las diferentes actividades que realiza un Sistema de Información se pueden observar en el diseño conceptual ilustrado en la en la figura 1.1. ESTRUCTURA DE DATOS I -- FCI Actividades que realiza un Sistema de Información, figura 1.1 2 Manual de Estructura de Datos
- 4. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Tipos y Usos de los Sistemas de Información Durante los próximos años, los Sistemas de Información cumplirán tres objetivos básicos dentro de las organizaciones: 1. Automatización de procesos operativos. 2. Proporcionar información que sirva de apoyo al proceso de toma de decisiones. 3. Lograr ventajas competitivas a través de su implantación y uso. Los Sistemas de Información que logran la automatización de procesos operativos dentro de una organización, son llamados frecuentemente Sistemas Transaccionales, ya que su función primordial consiste en procesar transacciones tales como pagos, cobros, pólizas, entradas, salidas, etc. Por otra parte, los Sistemas de Información que apoyan el proceso de toma de decisiones son los Sistemas de Soporte a la Toma de Decisiones, Sistemas para la Toma de Decisión de Grupo, Sistemas Expertos de Soporte a la Toma de Decisiones y Sistema de Información para Ejecutivos. El tercer tipo de sistema, de acuerdo con su uso u objetivos que cumplen, es el de los Sistemas Estratégicos, los cuales se desarrollan en las organizaciones con el fin de lograr ventajas competitivas, a través del uso de la tecnología de información. Los tipos y usos de los Sistemas de Información se muestran en la figura 1.2. A continuación se mencionan las principales características de estos tipos de Sistemas de Información. Sistemas Transaccionales. Sus principales características son: • A través de éstos suelen lograrse ahorros significativos de mano de obra, debido a que automatizan tareas operativas de la organización. ESTRUCTURADE DATOS I -- FCI • Con frecuencia son el primer tipo de Sistemas de Información que se implanta en las organizaciones. Se empieza apoyando las tareas a nivel operativo de la organización. • Son intensivos en entrada y salid de información; sus cálculos y procesos suelen ser simples y poco sofisticados. • Tienen la propiedad de ser recolectores de información, es decir, a través de estos sistemas se cargan las grandes bases de información para su explotación posterior. • Son fáciles de justificar ante la dirección general, ya que sus beneficios son visibles y palpables. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 3
- 5. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Sistemas de Apoyo de las Decisiones. Las principales características de estos son: • Suelen introducirse después de haber implantado los Sistemas Transaccionales más relevantes de la empresa, ya que estos últimos constituyen su plataforma de información. • La información que generan sirve de apoyo a los mandos intermedios y a la alta administración en el proceso de toma de decisiones. • Suelen ser intensivos en cálculos y escasos en entradas y salidas de información. Así, por ejemplo, un modelo de planeación financiera requiere poca información de entrada, genera poca información como resultado, pero puede realizar muchos cálculos durante su proceso. • No suelen ahorrar mano de obra. Debido a ello, la justificación económica para el desarrollo de estos sistemas es difícil, ya que no se conocen los ingresos del proyecto de inversión. • Suelen ser Sistemas de Información interactivos y amigables, con altos estándares de diseño gráfico y visual, ya que están dirigidos al usuario final. • Apoyan la toma de decisiones que, por su misma naturaleza son repetitivos y de decisiones no estructuradas que no suelen repetirse. Por ejemplo, un Sistema de Compra de Materiales que indique cuándo debe hacerse un pedido al proveedor o un Sistema de Simulación de Negocios que apoye la decisión de introducir un nuevo producto al mercado. • Estos sistemas pueden ser desarrollados directamente por el usuario final sin la participación operativa de los analistas y programadores del área de informática. • Este tipo de sistemas puede incluir la programación de la producción, compra de materiales, flujo de fondos, proyecciones financieras, m od el os d e si mul aci ón de n eg oci os, mod el os d e in v enta r ios, etc . Sistemas Estratégicos. Sus principales características son: • Su función primordial no es apoyar la automatización de procesos operativos ni proporcionar información para apoyar la toma de decisiones. • Suelen desarrollarse in house, es decir, dentro de la organización, por lo tanto no pueden adaptarse fácilmente a paquetes disponibles en el mercado. • Típicamente su forma de desarrollo es a base de incrementos y a través de su evolución dentro de la organización. Se inicia con un proceso o función en particular y a partir de ahí se van agregando nuevas funciones o procesos. • Su función es lograr ventajas que los competidores no posean, tales como ventajas en costos y servicios diferenciados con clientes y proveedores. En este contexto, los Sistema Estratégicos son creadores de barreras de entrada al negocio. Por ejemplo, el uso de cajeros automáticos en los bancos en un Sistema Estratégico, ya que brinda ventaja sobre un banco que no posee tal servicio. Si un banco nuevo decide abrir sus puertas al público, tendrá que dar este servicio para tener un nivel similar al de sus competidores. ESTRUCTURA DE DATOS I -- FCI • Apoyan el proceso de innovación de productos y proceso dentro de la empresa debido a que buscan ventajas respecto a los competidores y una forma de hacerlo en innovando o creando productos y procesos. 4 Manual de Estructura de Datos
- 6. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Tipos de datos Bit. U nid ad de in fo rm ac ió n más s e nci ll a en el s istem a bi na r io. B yte. Un idad d e i nf o r maci ón qu e c onst a d e 8 bits e qu i va le nt e a u n ú ni co car áct er , c omo un a let r a, n úm er o o si gn o d e p untu aci ó n. Ca ráct e r. Es u n el em ent o to mad o d e u n con ju nto d e s ímb ol os . E jem p lo : a,b,c,0 ,1,%= … Pa lab r a. C o nju nt o d e bi ts q ue p ue de n s e r ma ni pu lad o s p o r u na c om pu tado ra . La l o ngit ud de u na p a lab ra e n un a c om put a do ra p ue de se r: 8, 16 , 31, etc. De p end e d e l Mic r op r oc esad o r Manipulación de bits Digit al iz aci ó n de la in f or mac ió n. Se c o nv i ert e te xt o, so ni do o imág e nes e n f o rmat o q ue p ue de s e r ent e ndid o p or l a PC. Los m ic ro p ro ces ad or es ent ie nd en e l f o rmat o d e 0,1´s . Los m ic ro p r oc esad o res det ect an cu and o un b it s e c ar ga y su va lo r es igu al a 1 Se p u ed en r e pr es ent a r u na g ran di v e rsid ad de va l or es: ve rd a d y fa lso, fem en in o y m ascu li n o, etc. La e fic i enc ia d e las pc´ s no se basa e n l a c om pl ej id ad d e s u l óg ica La e fic i enc ia d e las pc´ s se b asa en la v e loc id ad d e t rab aj o. Ej em p lo de co mbi nac io nes p osib l es: 2 bits , 8 bits Si s e uti li zan 8 bits pa ra re p r ese nta r u n ca rá cte r, se pu ed en re p r es ent ar h asta 256 ca ract e res d if e re n tes, p u esto qu e ex iste n 256 p at ro n es o co m bina ci on es dif e re ntes d e 8 b its. Los com p utad o res d if i e re n co n r es pe cto a l núm er o d e bits uti li zad os p a ra r ep r es enta r un ca ráct e r Clasificación de los tipos de datos En fu nc ió n d e qu i en los def in e: o Ti p os d e d atos está nd a r. o Ti p os d e d atos de fi nid o s p or e l us ua r io En fu nc ió n d e l a r ep r es ent aci ón int e rn a: Ti p os d e d atos esc al ar es o sim p les ESTRUCTURADE DATOS I -- FCI o o Ti p os d e d atos est ruct u rad os. Los ti p os d e d atos sim pl es s on l os si gui e ntes : ◦ Numé r ic os ( Int eg e r, R e al ) · ◦ Lóg icos ( B oo le an ) · ◦ Ca ráct e r (C ha r, St ri ng ) · Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 5
- 7. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Representación de datos simples Dato. R e pr es ent aci ón f or ma d e hec hos , c onc e ptos o inst r ucci o nes Ti p o de dat o. Un co nj u nto d e va l or es, a q ue ll o s qu e p ue de to ma r cua lq ui e r dat o de d ich o t ip o. Las va r iab les y co nsta ntes qu e fo rm an pa rte de un p r og ram a p e rte nec e n a u n ti p o de d a t os d et er mi nad o. De esta f or ma, los va l or es as oci ad o s a dichas va r iab les (o co nsta ntes ) p ue de n o pe r ar c on ot r os d e ac ue rd o a s u nat ur al ez a ( p . e. d os nú me r os e nte r o s pu ed en s e r mu lti pl ic ados p er o n o ti e ne s e ntid o ha ce r esa o pe r aci ón co n c ad e nas d e c a ract e res ). NU M ER O S EN T ER O S Si ut ili za mos 32 bits pa ra re p r ese nta r nú me ro ent e ros, dis p on em o s d e 2^32 c ombi nac io n es d i fe r ent es d e 0 y 1`s: 4294967 296 va l or es. C omo te n em os qu e r ep r es enta r núm e ro n egat i vos y e l c e ro: -2 147 483 6 48 a l +2 147 483 647 NU M ER O S R E A L ES . (+|-) mantisa x 2 e x p o n e n t e En l a not aci ó n d el pu nto fl ota nt e u n nú me r o r eal es tá r e p res e nta do p o r u na hil e ra d e 32 bits f o rma da p o r un a ma ntisa d e 24 bits seg uid a de un ex p on ent e de 8 bits. La bas e se f ij a com o 10. Ta nt o la m ant isa como el e x po ne nt e son ent e ro s bina r ios de co mp l em en to d obl e. Tipos de datos abstractos Un tipo de datos abstracto – TDA defi n e u na nu e va c las e de ob j eto o c onc e pt o qu e p ue de ma ne ja rs e co n i nd e pe nd enc ia de la est ruct u ra de datos p a ra r ep r es enta r lo . Pa r a e ll o es nec es ar io es pec if ica r: Las o p e rac io n es qu e s e pu ed e r ea li za r c on l os obj etos . El e fe cto q ue se p r odu c e a l a ctua r c o n l as o p e rac io n es so br e los mis mos. . U n TD A enc a psu la la d efi ni ci ón de l ti p o y t oda s l as o pe r aci on es c o n e ste ti p o. ESTRUCTURA DE DATOS I -- FCI Los l en gua j es de p ro gr amac ió n e ntr eg an al pr og ram ad or c ie rt os ti po s de dat o s básic os o pr imit i vos, e sp ecif ic and o e l co nj unt o de va lo r es q u e un a v ar iab le d e un o d e es os t i pos p u e de t om ar y el c on ju nto de o p e rac io n es r ea li z abl es s ob re los m ism os. P or e je mp l o, si s e dec l ar a e n C/ C++ unsigned int x, y; 6 Manual de Estructura de Datos
- 8. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas La i nstr ucc ió n n = 9+10 de un p r og ram a d ond e = es el o pe ra do r d e asig nac ió n , el co nte ni do de la l oca l idad de al mac en ami e nt o da do p o r n ser á e l va l or 19. Cad a tip o d e datos : es rec on oc ido p or l os e l e ment os de d atos qu e p ued e tom a r y po r las o pe ra ci on es asoc ia das a é l. (su dom in io ) E jem p lo : en p asca l Dom ini o ent e r o D= {0, 1, 2….ma x } O pe r aci on es Los T D As so n ge n er al i zac io nes de los ti p os de dat os bás ic os y d e las o p e rac io nes p rim iti vas . U n TD A en caps ul a ti p os d e dat o s en el s e ntid o qu e e s pos ibl e p on e r l a def in ici ón de l ti p o y todas las o pe ra ci on es con es e ti p o e n u n a secc ió n d e u n p ro gr ama . P or ej em pl o, s e p ue de def in ir un ti p o de d ato s abstra cto C O NJ UNT O [ Ah o198 8] c on e l cua l se p u ed en d ef in i r l as sig ui ent es o pe r aci o nes: AN UL A ( A ) Hac e v ací o a l c on ju nto A UNI ON ( A, B, C ) Co nstr u y e el c o nju nt o C a p art i r d e la un ió n de los co nj unt os A y B. T A M AÑ O( A ) Ent r eg a l a ca nti dad de el em ent os d e l co nj unt o A. El co mp o ne nt e bás ico de una est r uctu ra de d atos es la c el da. La c eld a a lma ce na un v al or tom ad o d e a lgú n t i po d e dat o s im pl e o c o mpu est o El m eca nism o de ag r e gaci ón d e c el das ll am ado a r re gl o es una c o lec ci ón de el em ent os d e t ip o hom og én eo . A r re gl o b idim e nsi on al en C/ C++ int w[5][3] w[ i ] [j ] = b [ i * n + j] n es la c ant ida d d e col umn as d el a r re gl o ESTRUCTURADE DATOS I -- FCI w[ 2] [0 ] = b [6 ] Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 7
- 9. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Estructuras de datos So n datos elementales aquellos que se consideran indivisibles en unidades más simples. Un a est ru ctu ra d e dat os es u na c las e de d atos qu e s e pu ed e ca ract e ri za r po r s u or ga ni zac ió n y o pe r aci on es d ef in idas s ob r e e lla . Al gun as v eces a es tas est ru ctu ras s e les ll ama ti pos d e dat o s. Los ti pos d e d atos más fr ec u ent es uti li z ados en los d if er e nt es l eng ua jes de p ro gr amac i ón s on : Lógicas de datos.- En un p r og ram a, c ada v a r iabl e p e rt en ec e a al gu na es t ruct u ra d e datos e xp líc ita o im p líc itam ent e d ef in ida, la c ual det e rmi na el c o nju nto d e op e rac i on e s va lid as pa ra e ll a. Primitivas y simples.- A qu e ll as q ue no está n com p uest as p o r ot r as est ruct u ras d e datos p o r ej em pl o, ent e ros, bo ol ea n os y ca r ac ter es. Lineales: pilas , c olas y listas li gad as l in ea l es. No lineales incluyen grafos y á rb ol es. Organización de archivos.- Las técnic as de estr uctu ra ci ón d e datos a pl ica das a con ju ntos de dat os qu e los s iste mas o p e rati v os ma n eja n c o mo ca jas ne g ras comú nm ent e s e lla ma n O rg a ni za c i ón de A rc h iv o s. CLASIFICACIÓN DE LAS ESTRUCTURAS DE DATOS Se clasifican en: a) Por su almacenamiento b) Por su organización c) Por su comportamiento a) Por su almacenamiento.- Se clasifican en: Internas Externas Internas.- Son aquellas cuyas estructuras se almacena en la memoria principal. Externas.- Son aquellas que se almacenan en las memorias secundarias de un sistema de computadoras. b) Por su organización.- Se clasifican en: Estáticas Dinámicas Estáticas.- son aquellas cuya agrupación de memoria no se disminuye o aumenta estas son: cadenas, conjuntos, escalares, entre otros. Dinámicas.- Son aquellas cuya agrupación de memoria pueden aumentar o disminuir durante la ejecución del programa, estas son: pila, colas, listas. ESTRUCTURA DE DATOS I -- FCI d) Por su comportamiento.- Se clasifican en: Simples Compuesto o Estructurados Simples.-Son aquellas que almacenan un valor y son: Enteros Escalares Real Lógicos Caracteres 8 Manual de Estructura de Datos
- 10. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Compuesto.- Son aquellos que almacenan múltiples valores en su estructura y son los siguientes: Cadenas Arreglos Conjuntos Registros Listas Pilas Colas Árboles Archivos Base de datos Enteros Reales Clasificación de las estructuras de Datos Simples Caracteres Cadena Booleano Arreglo Estático Conjunto Registro Listas Estructurados Lineales Pilas Colas Dinámicos No Lineales Árboles Grafos Los ti pos d e dat os sim pl es pu ed en s er o rga ni zad os e n di fe r ent es est ruct u ras d e dat os : estát icas y di nám icas. ESTRUCTURADE DATOS I -- FCI Las estructuras de datos estáticas: So n a q ue ll as en las q ue el t ama ño oc u pad o en m em o ri a se d e fin e a ntes de q ue e l p ro gr ama se ej ecut e y n o pu ed e m od if ica rs e dic ho tam añ o d u rant e la e j ecuc ió n de l p ro gr ama . Est as est r uctu ras est á n im p le me ntad as en c a si tod o s los l en gua j es. Su pr inc i pa l c a ract e rís tica es qu e ocu p an so lo u na casi ll a de m em or ia, po r l o t ant o una v a ria bl e sim p l e h ace r ef e re nc ia a u n ú n ico v al o r a la v ez , d en tro de est e g r up o Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 9
- 11. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas de d atos s e en cu ent ra : ent e ros , re al es, c a ract e res, bo lé an os, en um e r ados y s ub ra ng os (l os últi mos n o e x iste n en al gu nos l eng ua jes d e p rog r amac ió n ) Las estructuras de datos dinámicas: No ti en e n las lim itac io nes o r est ri cci on es en el ta ma ño d e m em or ia ocu p ada qu e s o n p ro p ias d e las est ruct u ras estát icas . M edi ant e el us o de u n ti p o d e dat os es pe cifi co, d en omi na do p u nte r o, es p osib l e const r ui r est ru ctu ras d e dat os di nám icas qu e no s on so p o rtad as p o r la ma y o ría d e l os le ngu aj es, p er o qu e en aq u el los q ue s i ti en en estas c ar act er ístic as o f r ece n so lu ci on es efi cac es y ef ect iv as en la s ol uci ón d e pr ob lem as co mp l ej os. Se c a ract e ri za po r el h ech o d e q ue c o n un n omb re s e ha ce r ef er e n cia a u n g ru p o de casi llas d e m emo r ia. E s dec i r u n dat o est ruct ur ad o ti en e va r ios com po n ent es. VARIABLES ESTRUCTURADAS O ARREGLOS CONJUNTO DE DATOS DEL MISMO DEL MISMO TIPO AGRUPADOS BAJO UN SOLO NOMBRE Pa r a r ef e ri r nos a un o de el los s e ha ce r ef er enc ia a la p osic ió n qu e oc u pa el d at o r esp ect o a los ot ros. Pu ed en s e r u ni dems io na les ( v ecto r es ) mu ltid ime nsi o nal es ( matr ic es ) Ej : vo ca l= {a, e,i ,o, u } La l ista d e c las e c o n n otas VECTORES A r re gl os u ni dim ens in al es: Ej em p lo: • Lista d e Cl ase • Co la p ar a c om p ra r ti ck est • Voca les d el abe ce da ri o . OPERACIONES CON VECTORES P ode mos hac e r c on un v ecto r: ESTRUCTURA DE DATOS I -- FCI • Lle na r • Most r ar • O rd en ar • Busc a r: • Se cu enc ia l • Bi na ri a 10 Manual de Estructura de Datos
- 12. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Estructuras Supongamos que queremos hacer una agenda con los números de teléfono de nuestros amigos. Necesitaríamos un array de Cadenas para almacenar sus nombres, otro para sus apellidos y otro para sus números de teléfono. Esto puede hacer que el programa quede desordenado y difícil de seguir. Y aquí es donde vienen en nuestro auxilio las estructuras. Para definir una estructura usamos el siguiente formato: struct nombre_de_la_estructura { campos de estructura; }; NOTA: Es importante no olvidar el ';' del final, si no a veces se obtienen errores extraños. Para nuestro ejemplo podemos crear una estructura en la que almacenaremos los datos de cada persona. Vamos a crear una declaración de estructura llamada amigo: struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; char edad; }; A cada elemento de esta estructura (nombre, apellido, teléfono) se le llama campo o miembro. (NOTA: He declarado edad como char porque no conozco a nadie con más de 127 años. Ahora ya tenemos definida la estructura, pero aun no podemos usarla. Necesitamos declarar una variable con esa estructura. struct estructura_amigo amigo; Ahora la variable amigo es de tipo estructura_amigo. Para acceder al nombre de amigo usamos: amigo.nombre. Vamos a ver un ejemplo de aplicación de esta estructura. (NOTA: En el siguiente ejemplo los datos no se guardan en disco así que cuanda acaba la ejecución del programa se pierden). #include <stdio.h> struct estructura_amigo {/* Definimos la estructura estructura_amigo */ char nombre[30]; char apellido[40]; char telefono[10]; char edad; }; struct estructura_amigo amigo; void main() { ESTRUCTURADE DATOS I -- FCI printf( "Escribe el nombre del amigo: " ); fflush( stdout ); scanf( "%s", &amigo.nombre ); printf( "Escribe el apellido del amigo: " ); fflush( stdout ); scanf( "%s", &amigo.apellido ); printf( "Escribe el número de teléfono del amigo: " ); fflush( stdout ); scanf( "%s", &amigo.telefono ); printf( "El amigo %s %s tiene el número: %s.n", amigo.nombre, amigo.apellido, amigo.telefono ); } Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 11
- 13. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Este ejemplo estaría mejor usando gets que scanf, ya que puede haber nombres compuestos que scanf no cogería por los espacios. Se podría haber declarado directamente la variable amigo: struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; } amigo; Arrays de estructuras Supongamos ahora que queremos guardar la información de varios amigos. Con una variable de estructura sólo podemos guardar los datos de uno. Para manejar los datos de más gente (al conjunto de todos los datos de cada persona se les llama REGISTRO) necesitamos declarar arrays de estructuras. ¿Cómo se hace esto? Siguiendo nuestro ejemplo vamos a crear un array de ELEMENTOS elementos: struct estructura_amigo amigo[ELEMENTOS]; Ahora necesitamos saber cómo acceder a cada elemento del array. La variable definida es amigo, por lo tanto para acceder al primer elemento usaremos amigo[0] y a su miembro nombre: amigo[0].nombre. Veamoslo en un ejemplo en el que se supone que tenemos que meter los datos de tres amigos: #include <stdio.h> #define ELEMENTOS 3 struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; int edad; }; struct estructura_amigo amigo[ELEMENTOS]; void main() { int num_amigo; for( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ ) { printf( "nDatos del amigo número %i:n", num_amigo+1 ); printf( "Nombre: " ); fflush( stdout ); gets(amigo[num_amigo].nombre); printf( "Apellido: " ); fflush( stdout ); ESTRUCTURA DE DATOS I -- FCI gets(amigo[num_amigo].apellido); printf( "Teléfono: " ); fflush( stdout ); gets(amigo[num_amigo].telefono); printf( "Edad: " ); fflush( stdout ); scanf( "%i", &amigo[num_amigo].edad ); while(getchar()!='n'); } /* Ahora imprimimos sus datos */ for( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ ) { printf( "El amigo %s ", amigo[num_amigo].nombre ); printf( "%s tiene ", amigo[num_amigo].apellido ); 12 Manual de Estructura de Datos
- 14. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas printf( "%i años ", amigo[num_amigo].edad ); printf( "y su teléfono es el %s.n" , amigo[num_amigo].telefono ); } } IMPORTANTE: Quizás alguien se pregunte qué pinta la línea esa de while(getchar()!='n');. Esta línea se usa para vaciar el buffer de entrada. Para más información consulta Qué son los buffer y cómo funcionan. Inicializar una estructura A las estructuras se les pueden dar valores iniciales de manera análoga a como hacíamos con los arrays. Primero tenemos que definir la estructura y luego cuando declaramos una variable como estructura le damos el valor inicial que queramos. Recordemos que esto no es en absoluto necesario. Para la estructura que hemos definido antes sería por ejemplo: struct estructura_amigo amigo = { "Juanjo", "Lopez", "592-0483", 30 }; NOTA: En algunos compiladores es posible que se exiga poner antes de struct la palabra static. Por supuesto hemos de meter en cada campo el tipo de datos correcto. La definición de la estructura es: struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; int edad; }; por lo tanto el nombre ("Juanjo") debe ser una cadena de no más de 29 letras (recordemos que hay que reservar un espacio para el símbolo '0'), el apellido ("Lopez") una cadena de menos de 39, el teléfono una de 9 y la edad debe ser de tipo char. Vamos a ver la inicialización de estructuras en acción: #include <stdio.h> struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; int edad; ESTRUCTURADE DATOS I -- FCI }; struct estructura_amigo amigo = { "Juanjo", "Lopez", "592-0483", 30 }; int main() { printf( "%s tiene ", amigo.apellido ); printf( "%i años ", amigo.edad ); printf( "y su teléfono es el %s.n" , amigo.telefono ); Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 13
- 15. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas } También se puede inicializar un array de estructuras de la forma siguiente: struct estructura_amigo amigo[] = { "Juanjo", "Lopez", "504-4342", 30, "Marcos", "Gamindez", "405-4823", 42, "Ana", "Martinez", "533-5694", 20 }; En este ejemplo cada línea es un registro. Como sucedía en los arrays si damos valores iniciales al array de estructuras no hace falta indicar cuántos elementos va a tener. En este caso la matriz tiene 3 elementos, que son los que le hemos pasado. Paso de estructuras a funciones Las estructuras se pueden pasar directamente a una función igual que hacíamos con las variables. Por supuesto en la definición de la función debemos indicar el tipo de argumento que usamos: int nombre_función ( struct nombre_de_la_estructura nombre_de_la variable_estructura ) En el ejemplo siguiente se usa una función llamada suma que calcula cual será la edad 20 años más tarde (simplemente suma 20 a la edad). Esta función toma como argumento la variable estructura arg_amigo. Cuando se ejecuta el programa llamamos a suma desde main y en esta variable se copia el contenido de la variable amigo. Esta función devuelve un valor entero (porque está declarada como int) y el valor que devuelve (mediante return) es la suma. #include <stdio.h> struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; int edad; }; ESTRUCTURA DE DATOS I -- FCI struct estructura_amigo amigo = { "Juanjo", "Lopez", "592-0483", 30 }; int suma( struct estructura_amigo arg_amigo ) { return arg_amigo.edad+20; } int main() 14 Manual de Estructura de Datos
- 16. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas { printf( "%s tiene ", amigo.apellido ); printf( "%i años ", amigo.edad ); printf( "y dentro de 20 años tendrá %i.n", suma(amigo) ); } Si dentro de la función suma hubiésemos cambiado algún valor de la estructura, dado que es una copia no hubiera afectado a la variable amigo de main. Es decir, si dentro de 'suma' hacemos arg_amigo.edad = 20; el valor de arg_amigo cambiará, pero el de amigo seguirá siendo 30. También se pueden pasar estructuras mediante punteros o se puede pasar simplemente un miembro (o campo) de la estructura. Si usamos punteros para pasar estructuras como argumentos habrá que hacer unos cambios al código anterior (en negrita y subrrayado): int suma( struct estructura_amigo *arg_amigo ) { return arg_amigo->edad+20; } int main() { printf( "%s tiene ", amigo.apellido ); printf( "%i años ", amigo.edad ); printf( "y dentro de 20 años tendrá %i.n", suma(&amigo) ); } Lo primero será indicar a la función suma que lo que va a recibir es un puntero, para eso ponemos el * (asterisco). Segundo, como dentro de la función suma usamos un puntero a estructura y no una variable estructura debemos cambiar el '.' (punto) por el '->'. Tercero, dentro de main cuando llamamos a suma debemos pasar la dirección de amigo, no su valor, por lo tanto debemos poner '&' delante de amigo. Si usamos punteros a estructuras corremos el riesgo (o tenemos la ventaja, según cómo se mire) de poder cambiar los datos de la estructura de la variable amigo de main. Pasar sólo miembros de la estructura Otra posibilidad es no pasar toda la estructura a la función sino tan sólo los miembros que sean necesarios. Los ejemplos anteriores serían más correctos usando esta tercera opción, ya que sólo usamos el miembro 'edad': int suma( char edad ) { return edad+20; } ESTRUCTURADE DATOS I -- FCI int main() { printf( "%s tiene ", amigo.apellido ); printf( "%i años ", amigo.edad ); printf( "y dentro de 20 años tendrá %i.n", suma(amigo.edad) ); } Por supuesto a la función suma hay que indicarle que va a recibir una variable tipo char (amigo->edad es de tipo char). Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 15
- 17. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Estructuras dentro de estructuras (Anidadas) Es posible crear estructuras que tengan como miembros otras estructuras. Esto tiene diversas utilidades, por ejemplo tener la estructura de datos más ordenada. Imaginemos la siguiente situación: una tienda de música quiere hacer un programa para el inventario de los discos, cintas y cd's que tienen. Para cada título quiere conocer las existencias en cada soporte (cinta, disco, cd), y los datos del proveedor (el que le vende ese disco). Podría pensar en una estructura así: struct inventario { char titulo[30]; char autor[40]; int existencias_discos; int existencias_cintas; int existencias_cd; char nombre_proveedor[40]; char telefono_proveedor[10]; char direccion_proveedor[100]; }; Sin embargo utilizando estructuras anidadas se podría hacer de esta otra forma más ordenada: struct estruc_existencias { int discos; int cintas; int cd; }; struct estruc_proveedor { char nombre[40]; char telefono[10]; char direccion[100]; }; struct estruc_inventario { char titulo[30]; char autor[40]; struct estruc_existencias existencias; struct estruc_proveedor proveedor; } inventario; Ahora para acceder al número de cd de cierto título usaríamos lo siguiente: inventario.existencias.cd y para acceder al nombre del proveedor: ESTRUCTURA DE DATOS I -- FCI inventario.proveedor.nombre 16 Manual de Estructura de Datos
- 18. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Tipos de datos definidos por el usuario Typedef Ya conocemos los tipos de datos que nos ofrece C: char, int, float, double con sus variantes unsigned, arrays y punteros. Además tenemos las estructuras. Pero existe una forma de dar nombre a los tipos ya establecidos y a sus posibles variaciones: usando typedef. Con typedef podemos crear nombres para los tipos de datos ya existentes, ya sea por capricho o para mejorar la legibilidad o la portabilidad del programa. Por ejemplo, hay muchos programas que definen muchas variables del tipo unsigned char. Imaginemos un hipotético programa que dibuja una gráfica: unsigned char x0, y0; /* Coordenadas del punto origen */ unsigned char x1, y1; /* Coordenadas del punto final */ unsigned char x, y; /* Coordenadas de un punto genérico */ int F; /* valor de la función en el punto (x,y) */ int i; /* Esta la usamos como contador para los bucles */ La definición del tipo unsigned char aparte de ser larga no nos da información de para qué se usa la variable, sólo del tipo de dato que es. Para definir nuestros propios tipos de datos debemos usar typedef de la siguiente forma: typedef tipo_de_variable nombre_nuevo; En nuestro ejemplo podríamos hacer: typedef unsigned char COORD; typedef int CONTADOR; typedef int VALOR; y ahora quedaría: COORD x0, y0; /* punto origen */ ESTRUCTURADE DATOS I -- FCI COORD x1, y1; /* punto final */ COORD x, y; /* punto genérico */ VALOR F; /* valor de la función en el punto (x,y) */ CONTADOR i; Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 17
- 19. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Ahora, nuestros nuevos tipos de datos, aparte de definir el tipo de variable nos dan información adicional de las variables. Sabemos que x0, y0, x1, y1, x, y son coordenadas y que i es un contador sin necesidad de indicarlo con un comentario. Realmente no estamos creando nuevos tipos de datos, lo que estamos haciendo es darles un nombre más cómodo para trabajar y con sentido para nosotros. Punteros También podemos definir tipos de punteros: int *p, *q; Podemos convertirlo en: typedef int *ENTERO; ENTERO p, q; Aquí p, q son punteros aunque no lleven el operador '*', puesto que ya lo lleva ENTERO incorporado. Arrays También podemos declarar tipos array. Esto puede resultar más cómodo para la gente que viene de BASIC o PASCAL, que estaban acostumbrados al tipo string en vez de char: typedef char STRING[255]; STRING nombre; donde nombre es realmente char nombre[255];. Estructuras También podemos definir tipos de estructuras. Antes, sin typedef: struct _complejo { double real; double imaginario; }; ESTRUCTURA DE DATOS I -- FCI struct _complejo numero; Con typedef: typedef struct { double real; double imaginario; } COMPLEJO; COMPLEJO numero; 18 Manual de Estructura de Datos
- 20. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Asignación de Memoria Dinámica Métodos de Asignación de Memoria ¿Cuáles son los métodos de asignación de memoria utilizados por el S.O.? Cabe destacar que el almacenamiento y procesamiento de todos los datos es realizado en memoria RAM, en un segmento destinado a ello (DS), por ello, es importante conocer los métodos de asignación de memoria utilizados para su almacenamiento. Por un lado, se tiene la asignación estática de memoria en donde se reserva la cantidad necesaria para almacenar los datos de cada estructura en tiempo de compilación. Esto ocurre cuando el compilador convierte el código fuente (escrito en algún lenguaje de alto nivel) a código objeto y solicita al S.O. la cantidad de memoria necesaria para manejar las estructuras que el programador utilizó, quien según ciertos algoritmos de asignación de memoria, busca un bloque que satisfaga los requerimientos de su cliente. Por otro lado se tiene la asignación dinámica en donde la reserva de memoria se produce durante la ejecución del programa (tiempo de ejecución). Para ello, el lenguaje Pascal cuenta con dos procedimientos: NEW() y DISPOSE() quienes realizan llamadas al S.O. solicitándole un servicio en tiempos de ejecución. El procedimiento NEW ,por su parte, solicita reserva de un espacio de memoria y DISPOSE la liberación de la memoria reservada a través de una variable especial que direccionará el bloque asignado o liberado según sea el caso. Ejemplo : Cuando se compilan las sgtes. Líneas de código se produce una asignación estática de memoria: var linea: string [80]; (*Se solicita memoria para 80 caracteres --> 80 bytes) operatoria: Array[1..100,1..100] of real; (*Se solicita memoria para 100x100 reales -> 100 x 100 x 4 bytes) interes : integer; ESTRUCTURADE DATOS I -- FCI (*Se solicita memoria para 1 entero --> 2 bytes) ¿Cuántos bytes se reservarían para:? datos: array [1..25] of double; Para explicar con mayor detalle el concepto de memoria dinámica es necesario conocer el concepto ¡PUNTEROS! Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 19
- 21. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Punteros Son tipos de datos simples capaces de almacenar la posición de una variable en memoria principal. Se dice que ellos direccionan a otras variables. Ejemplo: Se dice que las variables ubicadas en las posiciones 1003 y 1006 son punteros, pues direccionan o "apuntan a" las posiciones 1000 y 1007 respectivamente. Otra explicación.- Un pu nte r o es u n obj et o q ue a p unta a otr o ob jet o. Es d eci r, u na va ri abl e cu yo va lo r es la d i rec ci ón de mem o ri a d e ot ra va ri abl e. No h a y qu e c o nfu ndi r una di r ecc ió n d e m em or ia co n el co nte ni do d e esa d i re cci ón d e mem or ia . i nt x = 2 5; D i rec ci ón 15 02 1504 1 506 1508 La di r ecc ió n d e la va r ia ble x ( & x) es 1502 El co nt en ido d e l a va ri a ble x es 2 5 Las di rec ci on es de m e mo ria d e p end en d e l a ar q uit ectu r a de l o rd en ado r y de l a gest ió n qu e e l sist ema o p e rati v o h aga de e ll a. ESTRUCTURA DE DATOS I -- FCI En l en gua j e e nsam bla d or se deb e ind ica r num é ric ame nt e l a pos ici ón físic a d e m em or i a en qu e qu e re mos a lma cen a r un d ato. D e a hí qu e est e l en gu aj e de p end a tant o d e l a má qui na e n l a qu e s e a pl i qu e. En C n o d eb em os, n i p od emos , i nd ica r num é r icam ent e la di r ecc ió n de m em o ri a, s i n o qu e ut il iz amos una eti qu et a q ue c on oc em os com o va r iab le ( en su día d efi ni mos l as va r iab les com o di r ecci on es d e m em o ri a) . L o qu e n os i nte r esa es al mace na r un dat o, y no la l oca li zac ió n ex act a d e es e d ato e n m em o ri a. 20 Manual de Estructura de Datos
- 22. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Un a v ar iab l e p unt e ro s e dec la r a com o tod as l as va r iab les. D eb e se r del m ismo t ip o qu e la va r iab le a pu ntad a. S u id e ntif ica do r va p r ec edi do de un ast e risc o ( *): i nt * p u nt; Es un a v ar iab l e pu nt er o q ue a pu nta a va ri ab le qu e c o nti en e un d a to d e ti po ent e ro lla mad a pu nt. ch a r *c ar: Es un p unt e ro a va ri abl e d e ti p o c ar áct er . l o ng f lo at *n um; f lo at * mat[ 5] ; // . . . Es d eci r: ha y ta ntos tip os d e p unt e ros c omo t ip os d e dat os, aun q u e tambi é n pu ed en de cla r ars e pu nt er os a estruct ur as más c om p le jas ( func i on es, st r uct , fich e ros ... ) e i ncl uso p u nte r os vac íos ( v oid ) y pu nt er os nu los (N ULL ). Dec la rac ió n d e v ar iab le s pu nt er o: S ea un f rag ment o d e p r og ram a e n C: cha r dat o; // v a riab l e q ue al mac en a rá un c a r ácte r. cha r * p unt; //d ec la r aci ón de p unt e ro a c ar ácte r. pu nt = & dat o; // e n l a va r iab le p unt gu ar dam o s la d i re cci ón // d e m em o ria d e l a va r iab le dat o; pu nt a p u nta // a d ato . Ambas so n del mism o t ip o, ch ar. int * p unt = N ULL, va r = 14; pu nt = & va r; p ri ntf (“ %# X, %# X ”, pu nt, & va r ) // la m ism a s ali da: di r ecci ón p ri ntf (“ n% d, %d ”, * pu nt, va r ); //sa lid a: 1 4, 14 H a y qu e t en e r c uid ad o c on las di r ecci on es a pu ntad as: p ri ntf (“ %d, %d ”, * ( pu n t+1), v a r+1 ); *( pu nt + 1 ) r e pes e nta el v al o r co nt en ida e n la d i rec ci ón de m em o ri a a um enta da en una p osi ci ón ( int=2 by tes) , qu e s e rá un v al or n o d ese ad o. Si n emb ar go v ar +1 r ep r es enta e l va lo r 15. pu nt + 1 r e p r ese nta l o m ism o qu e &v a r + 1 ( a van ce en la d ir ecc i ón d e m em o ria d e va r ). Al tr aba ja r c on p unt e r o s se em pl ea n d os o pe r ado r es esp ec íf icos : ESTRUCTURADE DATOS I -- FCI O pe r ado r d e d i r ecci ón : & R e p r ese nta la di r ecc ió n de m em o ri a de la va r iab le qu e l e sig u e: &fn um r e p res en ta la di r ecc ió n d e f num . O p er ad o r d e c o nte nid o o i nd ir ecc i ón: * El o p er ad o r * a pl ic ado al nomb r e d e u n pu nt er o i nd ica el va l or de la va r iab le ap unt ada: flo at alt ur a = 2 6.92, *ap unt a; Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 21
- 23. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas ap unt a = &a ltu r a; // in i cia li zac ió n d el p unt e ro flo at alt ur a = 2 6.92, * ap unt a; ap unt a = &a ltu r a; // in i cia li zac ió n d el p unt e ro .p ri ntf ( “n %f ”, a ltu r a) ; //sa li da 2 6.92 .p ri ntf ( “n %f ”, * a punt a ); No s e d eb e co nf und i r e l o p e rad o r * en l a d ecl ar aci ón de l pu nt er o: int * p; Co n el o pe r ad or * en la s inst ru cci on es: * p = 27; p ri ntf ( “ n Co nte ni do = %d ”, *p ); Veam os c on u n e j em pl o en C la dif e r enc ia e ntr e to dos est os c onc e pt o s Veam os el a rch i vo - p unt0 .c pp - p unt1 .c pp Es d ec i r: int x = 25, *p int; pi nt = & x; La va ri abl e p int c onti e ne l a d ir ecc ió n de m em or ia d e la v ar iab l e x. L a ex p r esi ón: * pi nt r ep r es enta el va lo r de la v a riab l e ( x) a p unt ad a, es dec i r 25. La v a ri abl e p int tamb ié n tie ne su p ro p ia di r ecci ó n: & pi nt Veam os c on ot r o ej em p lo e n C la di fe r enc ia e n tre tod os est os c onc e pt os vo id mai n ( vo id ) { int a, b, c , * p1, *p 2; vo id *p ; p1 = & a; // P aso 1. La di r ecci ó n d e a es asig nad a a p 1 *p1 = 1; // P as o 2. p1 (a ) es i gu al a 1. E qu i va le a a = 1; p2 = & b; / / Pas o 3. La d i re cci ón de b es asig nad a a p2 *p2 = 2; // P aso 4. p 2 (b) es ig ua l a 2. E qu i va le a b = 2; ESTRUCTURA DE DATOS I -- FCI p1 = p 2; // Pas o 5. El va l or de l p1 = p2 *p1 = 0; // P aso 6. b = 0 p2 = & c; / / Pas o 7 . La d i rec ci ón de c es a sign ada a p2 *p2 = 3; // Pas o 8 . c = 3 p ri ntf (" %d % d %d n ", a, b, c ); / / Pas o 9. ¿Q u é se im p rim e ? p = p1 ; / / Pas o 1 0. p co nti e ne la di r ecci ón de p1 p = p2 ; // Pas o 11. p1= p2; 22 Manual de Estructura de Datos
- 24. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas *p1 = 1; / / Pas o 12. c = 1 p ri ntf (" %d % d %d n ", a, b, c ); // Pas o 13 . ¿ Qu é s e i mp r im e? } Vamos a h ac er un se g uim ie nto de las di r ecc i on es d e m em o ria y de los v al or es d e las va r iab les e n cad a pas o. Su p on em os qu e l a va r iab le a es co lo cad a e n l a di r ecc ió n 0000, b e n l a sig ui e n te, es d eci r 0 002, co n u n o ffs et d e 2 b yt e s, p o r se r v al o res int eg er . Se t rat a d e un sist em a de pos ici o nes re lat i va s de mem o ri a. S e v e rá e n ar itm étic a d e pu nt er os. Se obti en e e l s igu i ent e cu ad ro. En él r ef l eja m os las di r ecci o nes re lat iv as d e me mo r ia y los c amb ios e n ca da un o d e l os pas os m a rcad o s: Inic ia li zac ió n d e pu nt er os( I) : Si < Alm ac en ami ent o> es e xte r n o stat ic, <E x p res io n> deb e rá s e r u na e x p res ió n ESTRUCTURADE DATOS I -- FCI const ant e d el ti p o < Ti p o> ex p r esad o. Si < Al mac en ami e nto> es aut o, ent on ces < E x p res io n> p u ed e s er cu al qu i er e x p res i ón del < Ti p o> esp ec if icad o. Ej em p los: 1) La co nstant e ent e ra 0, NULL (c er o ) p r o po rc io n a un pu nte r o nu l o a cu al qu i er ti p o de d ato: int *p; Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 23
- 25. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas p = NUL L; // actu al iz aci ó n 2) El no mb re d e un a r ra y d e a lma ce nam i ent o stati c o ext e rn s e t r ansf o rma s eg ún la ex p r esi ón: a ) f l oat m at [12 ]; fl oat * p unt = mat; b) fl o at mat [12 ]; f lo at * p unt = & mat [0 ]; 3) U n “ cast ” pu nt er o a pu nt er o: int *p unt = ( int *) 123. 456; Inic ia li za e l pu nte r o c o n e l ent e ro . 4) U n punt e r o a ca ráct e r pu ed e i nic ia li za rs e e n l a f or ma: cha r *c ad en a = Est o e s un a cad e na ”; 5) S e p u ede n suma r o r esta r v al o res e nt er os a las dir ecc io n es de m e mo ria en l a fo rma : (a rit mét ica de p unt e r os) st atic int x; int * pu nt = & x+2, *p = & x-1; 6) E qu i va le nci a: D os ti pos de fi nid os c omo p u nte r os a o bj eto P y pu n ter o a obj et o Q so n e qu iv al e ntes s ó lo s i P y Q s on de l m ism o ti p o. A pl ica do a m atr ic es: nomb r e_ pu nte r o = nom br e_m atr i z; ESTRUCTURA DE DATOS I -- FCI 24 Manual de Estructura de Datos
- 26. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas PUNTEROS Y ARRAYS Se a el a rr a y d e una di mens ió n: i nt mat [ ] = { 2, 16 , - 4, 29, 234, 1 2, 0, 3 }; en e l qu e c ada e le me nt o, po r s e r t ip o int, oc u p a dos b ytes de me mo ri a. Su p on em os qu e la di re cció n d e m em o ri a d el p rim e r el em ent o, es 1 50 0: & mat [0 ] es 1 500 & mat [1 ] s er á 1502 & mat [7 ] s er á 1514 int mat [ ] = {2 , 16, -4 , 29, 2 34, 12 , 0, 3} ; En tot al los 8 el em ent o s ocu p an 16 b yt es. P ode mos r e p res ent a r l as di r ecci o nes de mem or ia q u e oc u pa n l os el e ment os d e l a r ra y , los dat os qu e c ont ie n e y las p osic io n es d el a rr ay e n l a f o rma: Di rec ci ón 1 500 1 502 1 504 1506 1 508 1510 151 2 1514 El em e nto mat [0 ] mat [1 ] mat [2 ] mat [3 ] mat [4 ] mat [5 ] mat [6 ] m at[ 7] El acc es o po dem os hac e rl o m edi ant e el ín dic e: x = mat [3 ]+m a t[5 ]; // x = 2 9 + 1 2 pa ra sum ar l os el em ent os d e l a c ua rta y s e xta pos ic io nes . C om o h em os d ich o q ue p od em os acc ede r p or pos ici ón y p or di r ec ció n: ¿ Es lo mism o &mat [0 ] y mat? Y &mat [1 ] = mat ++ ? Veam os el có dig o d e un ej em p lo: #inc lu de <stdi o.h > #inc lu de <co ni o.h > int m at[ 5] ={ 2, 16 , -4, 2 9, 234, 12, 0 , 3 }, i; // d ecl a rad as c omo gl oba l e s vo id mai n () { p ri ntf (" n% d", &mat [0 ] ); // res ult ad o: 15 00 ( di r ecci ón d e m em ) ESTRUCTURADE DATOS I -- FCI p ri ntf (" n% p ", m at ); / /r es ulta do: 1 500 ( " " " " " ) i ++; //i =1 p ri ntf (" n% p ", m at+ i); // r esu ltad o: 1 502 ( " " " " " ) p ri ntf (" n% d", * (ma t+i) ); // r esu ltad o: 16 ( va lo r de mat [1 ] o val o r g etch ( ); } Ej em p lo Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 25
- 27. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Pa r ec e d edu ci rs e qu e a cced em os a l os e l em en tos d el a rr a y d e d os f o r mas: - m ed iant e e l sub índ ice. - m ed iant e s u d ir ecc ió n d e m em or ia. El em e nto mat[ 0] mat [1 ] mat [2 ] m at[ 3] mat [4 ] mat [ 5] mat [6 ] m at[ 7] Analizando las direcciones de memoria del array: De lo ant e ri o r s e obt i en en v ar ias co ncl usi on es: - Es lo mism o &m at[ 0] q ue mat, & mat [2 ] q ue mat + 2 - Pa r a pasa r de un e l em ent o a l si gu ie nte , es lo mism o: Qu e el có dig o: ESTRUCTURA DE DATOS I -- FCI A esta fo rm a d e d es pl a za rs e e n m em o ria se l e ll ama 26 Manual de Estructura de Datos
- 28. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Aritmética de punteros - A un a va ri abl e pu nt er o se l e p ue de asi gna r la dir ec ci ón d e cua l qu i er obj eto . - A un a v ar iab l e pu nt er o se le pu ed e asi gna r l a dir ec ci ón d e otr a v ar ia ble pu nte r o (si em p re qu e l as d os s eñ al en e l m ismo ob jet o ) - A un p unt e ro s e le p u e de in ici al iz ar co n el v al or N ULL - Un a v a riab l e p unt e ro pu ed e se r rest ada o com pa ra da c on ot ra si amba s ap unt an a el em ent os d e u n m ismo a r ra y. - Se p ue de s uma r o rest ar va l or es ent e ros : p + +, p v+3 , te ni en do e n c ue nta qu e el des pl az ami e nto ( offs et ) de p end e d e l ti p o d e d a to a pu nta do: p++; // p a pu nta a l a sigu ie nt e di r ecc ió n p v+=3 // p v a p unta 3* nº b ytes de l d ato a pu nt ado ( of fset) Si t e nem os: flo at *d ec ima l; / /su po nem os q ue a pu nta a 0 000 dec ima l++; //a p un ta a 0 004 - Obs e rv a r l as si gui e ntes inst ru cci on es: i nt * p; d oub l e * q; ESTRUCTURADE DATOS I -- FCI v oid *r ; // p un ter o ge né r ic o p = & 34; / / l a s const ant es no t i en en dir ec ci ón p = & ( i+1 ); / / las ex p r esi on es no ti en en di r ecci ón &i = p; // l as d ir ecc io n es n o s e pu ed e n camb ia r p = q; // il e gal p = ( int *) q; // l ega l Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 27
- 29. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Uti li za nd o la aritmética de punteros nos despl az am os de u nas p osic io n es de mem or ia a ot r as. Pe r o. ¿c óm o ac ce de r a l os co nt en idos de es a s pos ic io nes util iz an do n otac ió n d e pu nt er os? Em p le amos el o pe ra do r *, indirección que n os da e l co nt en ido d e la di r ecci ón d e mem or ia a pu ntad a. Y... ¿c óm o s e a pl ica la a rit mét ica d e pu nte r os pa r a d es pl az ar nos e n un a r ra y bidim e nsi on al ?: f lo a t mat[ 2] [4 ]; //d ecl a rac ió n d e l a r ra y Uti li za nd o pu nte r os, la dec la rac ió n s e rá: fl o at ( *mat ) [4 ]; / /a r ra y b idim e nsi on al En d ond e mat es u n p unt e ro a u n g r up o co ntig u o d e a r r a ys mon od ime nsi o nal es ( ve cto r es) d e 4 el em en tos ca da un o. E xist e, p or tant o un a e qu i va le nci a: Rec o rd emos que *mat r ep r es enta un puntero a la primera fila. A la se gund a fil a n os r ef e ri mos m e dia nte *(m at+1 )+j p a ra las dir ec ci on es y con ESTRUCTURA DE DATOS I -- FCI *(* (m at+1 )+j ) p ar a los cont en id os. El segu nd o subíndi ce actua sob re la co lu mna . Si en x[ 10 ][ 20 ] q u ie r o acc ed e r al e le me nto d e l a fi la 3 y la c ol umn a 6, l o h ag o esc rib ie nd o x [2 ][ 5]. C o n n otac ió n d e p unt e ros , es e qu i va le nte a * ( * ( x + 2 ) +5 ) 28 Manual de Estructura de Datos
- 30. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas ya qu e x + 2 es un pu nt er o a l a fi la 3. P or t ant o. E l co nt en ido de dich o pu nte r o, *( x+2 ), es la fi la 3. Si m e d esp la z o 5 p os ici on es e n es a fi la l l e go a l a p osi ci ón *( x+2 )+5, cu y o c ont en i do es * (* ( x+2 )+5 ). V e r dibu jo: Si en x[ 10 ][ 20 ] q u ie r o acc ed e r al e le me nto d e l a fi la 3 y la c ol umn a 6, l o h ag o esc rib ie nd o x [2 ] [5 ]. C on n otac ió n de punt e r os, lo qu e hac em os es co nsid e ra r qu e es un a r ra y fo rm ad o p o r 10 ar ra ys u ni dim ens i o nal es (v ect o res ) d e 2 0 el em ent os cad a un o, d e m od o qu e acc e do a x [2 ] [5 ] m ed iant e l a e x p res ió n: * ( * ( x + 2 ) + 5) ya qu e x + 2 es un pu nt er o a l a fi la 3. P or t ant o. E l co nt en ido de dich o pu nte r o, *( x+2 ), es la fi la 3. Si m e d esp la z o 5 p os ici on es e n es a fi la l l e go a l a p osi ci ón *( x+2 )+5, cu y o c ont en i do es * (* (x +2 )+5 ). L as sigu ie nt es e x p res io n es con p unt e ros s o n vá lid as: **x x [0 ] [0 ] ; *( *( x+1 ) ) x [1 ] [0 ] *(* x+1 ) x [0 ] [1 ]; ** (x +1 ) x [1] [0 ] Si e n int a rr a y[ fi las ] [c ol umn as] ; Qu i er o acc ed e r a l el e ment o a r ra y [ y ][ z ] p a ra asign a rl e un va l or , lo qu e e l com p il ad or hac e es : *(*array +columnas x y + z)) = 129; / /asig nac ió n Si f ue r a int a r ra y [2 ] [5 ] y q uisi e ra as ig na r 12 9 al e le me nto d e l a fi l a 1 y co lu mna 2 , po nd rí a: ESTRUCTURADE DATOS I -- FCI * (a r ra y + 5x1 + 1 )) = 129 ; es d eci r, des de e l or ig e n d el ar r a y a va n za 6 po sici on es d e m em o ri a: Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 29
- 31. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas PUNTEROS A ARRAYS MATRICES Un a r ra y m ult idim e nsi on al es, en r e ali dad, una co l ecci ón d e vect or es. S eg ún est o, po de mos d ef in ir un ar ra y b idi me nsi on al c o mo u n p unt e r o a u n g ru p o co nti gu o d e ar ra ys un id ime nsi o nal e s. Las d ec la rac io n es si gui ent es s on e q ui va l en tes: int dat [fi l ] [co l ] i nt (*d at) [c ol ] En g en e ra l: tip o_d ato no mb re [d im1 ] [dim 2] . . . . . [di mp ]; e q ui va le a: tip o_d ato (* no mb re ) [di m2] [d im3 ]. . . . . [d im p ]; El a r ra y: i nt va l or [ x ][ y ] [z ]; Pu ed e s e r re p r ese nta d o en la fo rm a: i nt (* va lo r ) [y ] [ z] ; O c om o u n AR R A Y D E P UN T ER O S: int * v al or [ x ][ y ]; s in p a r ént esis En su nu e va dec la r aci ó n d esa pa r ec e l a ú ltim a de s us di me nsi on es. Veam os m ás d ecl a rac io nes de a rr a ys d e p unt e ros : ESTRUCTURA DE DATOS I -- FCI int x [10 ] [20 ]; int * x[ 10 ]; flo at p [10 ] [20 ] [30 ]; int * p[ 10 ][ 20 ]; 30 Manual de Estructura de Datos
- 32. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Punteros a CADENAS DE CARACTERES Un a c ad ena d e c ar act e r es es u n ar r ay d e c ar a cte res . La f or ma de d e fin i r u n pu nt er o a una cad e na d e c a ract e r es: c ha r *ca de na; El id ent if icad o r d el ar ra y es l a di r ecc ió n d e comi e nz o d el a rr a y. Pa r a sab e r dó nd e ter mi na la c ad en a, el c om pi lad o r a ñad e el ca r ácte r ‘ 0’ ( A SCI I 0, N UL L): cha r * nomb r e = “ P E P E P ER E Z ”; ARRAYS DE PUNTEROS A CADENAS DE CARACTERES En un a r ra y d e pu nte r o s a cade nas d e ca r acte r es cad a el em e nto a p u nta a u n ca ráct e r. La d ecl a rac ió n s er á: cha r *c ad [10 ]; // po r e jem p lo Grá fic am ent e p od ría se r: ESTRUCTURADE DATOS I -- FCI - si l as di me nsi on es no son c o noc idas , sab r em os d ónd e c om ie n zan l a s cad en as, p er o no d ó nde t e rm ina n. Pa ra el l o se ef ect úa la l la mad a reserva dinámica de memoria (funci o nes ma ll oc, c al loc ( ), r ea ll oc ( ) y fr e e () de stdl ib.h ó al l oc.h ): cha r c ad[ 10 ][ 80 ]; E qu i va le a ch ar **ca d r es er v and o 8 00 b yt es Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 31
- 33. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas La d ecl a rac ió n: c ha r ca d[10 ] [80 ]; Res e rv a me mo ri a p ar a 10 cade nas de c ar ac ter es d e80 ca ra cte r es cada un a. P er o en l a d ecl ar ac ió n com o a r ra y d e p unt e ros : c ha r * cad [10 ]; El co mp il ad or d esco n oc e el t ama ño de l as cad en as: ¿ cuá nta me mo ri a r ese r va ? - si e l a r ra y es stat ic y s e i nic ia li za n l as c ade nas e n e l p ro pi o códi go , e l com pi lad o r c alc ul a l a d ime nsi ón n o ex p lic itad a (a r ra ys s in dim e nsi ón ex p líc ita ). OTRAS CLASES DE PUNTEROS: P unt e ros ge n ér ic os: S on t i po v oi d: v oid *g en e ric o; Los p unt e r os ti po v oid pu ed en a pu nta r a ot r o tip o d e dat os. Es un a op e rac ió n del ica da q u e d e pe nd e d el ti p o d e c om pi la do r. Es c o nv e ni ent e em pl ea r e l “cast in g” pa ra l a c on v e rsi ón. Aú n as í, n o tod a s las c on v e rsi on es están p er miti das. P unt e ro nu lo: En C u n pu nte r o qu e a pu nte a un o bj et o vá li do n un ca tend rá un va lo r ce r o. E l va lo r c e r o s e ut il iz a pa ra i ndic a r qu e ha oc ur r id o a lgú n e r r or (e s dec ir , qu e a lg un a o p e ra ció n n o s e h a po did o r e ali za r ) int * p = N UL L; // int * p =0; Pu nte r os c onst ant es : U na d ec la ra ci ón de p u nte r o pr ec ed ida de co n st hac e qu e e l ob j eto a pu ntad o sea un a c onst ant e (a u nq u e n o el p unt e ro ): co nst ch a r * p = “V al lad ol id ”; p [0 ] = ‘f’ // e r ro r. La c ad ena a pu nta da po r + es cte . p = “ Puc el a ” //Ok . p a p unta a ot ra cade na . Si l o qu e qu e r emos es dec la ra r un p unt e ro co nstant e; cha r *co nst p = “ M edi na ”; p [0 ] = ‘s’; // e rr o r: el ob jet o “ Me di n a”, es cte. ESTRUCTURA DE DATOS I -- FCI p = “ P eñ af ie l ”; //e r ro r: e l pu nte r o p e s const ant e. Punt e r os a p unt e ros: Ve r ej em p4.c p p, ej e mp11 .c pp y ej em p12.c p p int ** pu nte r o; // pu nt er o a punt e r o a un obj eto i nt. El ti p o de ob jet o a pu ntad o des pu és d e un a dobl e in d i re cci ón pu e de se r de cua lq ui e r c las e. 32 Manual de Estructura de Datos
- 34. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas P er mit e ma ne ja r a r ra ys d e mú lti p les d im e nsi on es c on n otac io ne s d el t i p o ***mat, d e múlt i pl e ind i re cci ón q ue pu ed en g en e ra r p r obl e mas si el trat ami ent o no es el adec ua do. O j o a los “ p unt er os lo cos ”. Punt e r os a dat os c o mp le jos: S e pu ed en d ecl a ra pu nte r os a d at os de fi nid os po r e l us ua ri o (t y pe de f( ) ), a dat os st ruct, a fun ci on es, c om o a rg u ment os d e func i on es... Dec la rac io n es c om pl ej as: U na d ec la rac ió n c om pl ej a es un id ent ifi cad o r con más d e d e u n op e r ado r. P ar a int er p r eta r estas d ecl a rac io nes hac e f a lta sab e r qu e los c o r chet es y pa r ént esis (o p e rad o r es a la de r ech a de l ide n tific ad or ti en e n p ri or i dad sob re los aste ris cos (o p e ra do res a l a iz q ui e rda d el id e ntif ica do r. L os p ar ént es is y co rch etes ti en e n l a m i sma p ri or id ad y s e e va lúa n d e i z qui e rd a a d e r echa . A la iz q ui er da de l t od o el t ip o d e dat o. Em pl e and o p ar é ntes is s e pu ed e cambi ar el or de n d e p ri o ri dad es. Las e x pr esi o nes ent r e pa r ént esis s e e v al úan p rim e ro , de más i nte r nas a más e xt e rnas . Pa r a i nte r p r eta r d ecl a r aci on es c om pl ej as p od em os se gu ir e l or de n: 1) Em p ez ar c on e l i dent if icad o r y ve r si haci a la d er ec ha ha y co rch etes o pa r ént esis . 2) I nte r p r eta r es os c or ch etes o p ar é ntes is y v e r si ha cia la i z q ui er da h ay aste risc os. 3 ) D ent ro de cad a ni v el d e pa r ént esis , d e más int e rn os a má s ext e rn os, ap lic a r pu ntos 1 y 2. Veam os un ej em p lo: cha r *(* (* va r ) ( ) )[ 10 ] La i nte r p r etac ió n es: 1. La v ar iab l e va r es d e cla rad a c om o 2. u n punt e r o a 3. u na f un ci ón q ue d ev ue l ve 4. u n punt e r o a ESTRUCTURADE DATOS I -- FCI 5. u n a r ra y d e 1 0 el em ent os, los cua l es so n 6. p unt e ros a 7. ob jet os d e t i po cha r. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 33
- 35. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Punteros a estructuras Cómo no, también se pueden usar punteros con estructuras. Vamos a ver como funciona esto de los punteros con estructuras. Primero de todo hay que definir la estructura de igual forma que hacíamos antes. La diferencia está en que al declara la variable de tipo estructura debemos ponerle el operador '*' para indicarle que es un puntero. Creo que es importante recordar que un puntero no debe apuntar a un lugar cualquiera, debemos darle una dirección válida donde apuntar. No podemos por ejemplo crear un puntero a estructura y meter los datos directamente mediante ese puntero, no sabemos dónde apunta el puntero y los datos se almacenarían en un lugar cualquiera. Y para comprender cómo funcionan, nada mejor que un ejemplo. Este programa utiliza un puntero para acceder a la información de la estructura: #include <stdio.h> struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; int edad; }; struct estructura_amigo amigo = { "Juanjo", "Lopez", "592-0483", 30 }; struct estructura_amigo *p_amigo; int main() { p_amigo = &amigo; printf( "%s tiene ", p_amigo->apellido ); printf( "%i años ", p_amigo->edad ); printf( "y su teléfono es el %s.n" , p_amigo->telefono ); } Has la definición del puntero p_amigo vemos que todo era igual que antes. p_amigo es un puntero a la estructura estructura_amigo. Dado que es un puntero tenemos que indicarle dónde debe apuntar, en este caso vamos a hacer que apunte a la variable amigo: p_amigo = &amigo; No debemos olvidar el operador & que significa 'dame la dirección donde está almacenado...'. ESTRUCTURA DE DATOS I -- FCI Ahora queremos acceder a cada campo de la estructura. Antes lo hacíamos usando el operador '.', pero, como muestra el ejemplo, si se trabaja con punteros se debe usar el operador '->'. Este operador viene a significar algo así como: "dame acceso al miembro ... del puntero ...". Ya sólo nos queda saber cómo podemos utilizar los punteros para introducir datos en las estructuras. Lo vamos a ver un ejemplo: #include <stdio.h> struct estructura_amigo { char nombre[30]; 34 Manual de Estructura de Datos
- 36. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas char apellido[40]; int edad; }; struct estructura_amigo amigo, *p_amigo; void main() { p_amigo = &amigo; /* Introducimos los datos mediante punteros */ printf("Nombre: ");fflush(stdout); gets(p_amigo->nombre); printf("Apellido: ");fflush(stdout); gets(p_amigo->apellido); printf("Edad: ");fflush(stdout); scanf( "%i", &p_amigo->edad ); /* Mostramos los datos */ printf( "El amigo %s ", p_amigo->nombre ); printf( "%s tiene ", p_amigo->apellido ); printf( "%i años.n", p_amigo->edad ); } NOTA: p_amigo es un puntero que apunta a la estructura amigo. Sin embargo p_amigo->edad es una variable de tipo int. Por eso al usar el scanf tenemos que poner el &. ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 35
- 37. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Punteros a Arrays de estructuras Por supuesto también podemos usar punteros con arrays de estructuras. La forma de trabajar es la misma, lo único que tenemos que hacer es asegurarnos que el puntero inicialmente apunte al primer elemento, luego saltar al siguiente hasta llegar al último. #include <stdio.h> #define ELEMENTOS 3 struct estructura_amigo { char nombre[30]; char apellido[40]; char telefono[10]; int edad; }; struct estructura_amigo amigo[] = { "Juanjo", "Lopez", "504-4342", 30, "Marcos", "Gamindez", "405-4823", 42, "Ana", "Martinez", "533-5694", 20 }; struct estructura_amigo *p_amigo; void main() { int num_amigo; p_amigo = amigo; /* apuntamos al primer elemento del array */ /* Ahora imprimimos sus datos */ for( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ ) { printf( "El amigo %s ", p_amigo->nombre ); printf( "%s tiene ", p_amigo->apellido ); printf( "%i años ", p_amigo->edad ); printf( "y su teléfono es el %s.n" , p_amigo->telefono ); /* y ahora saltamos al siguiente elemento */ p_amigo++; } } En vez de p_amigo = amigo; se podía usar la forma p_amigo = &amigo[0];, es decir que apunte al primer elemento (el elemento 0) del array. La primera forma creo que es más usada pero la segunda quizás indica más claramente al lector principiante lo que se pretende. Ahora veamos el ejemplo anterior de cómo introducir datos en un array de estructuras mediante punteros: ESTRUCTURA DE DATOS I -- FCI #include <stdio.h> #define ELEMENTOS 3 struct estructura_amigo { char nombre[30]; char apellido[40]; int edad; }; struct estructura_amigo amigo[ELEMENTOS], *p_amigo; void main() 36 Manual de Estructura de Datos
- 38. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas { int num_amigo; /* apuntamos al primer elemento */ p_amigo = amigo; /* Introducimos los datos mediante punteros */ for ( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ ) { printf("Datos amigo %in",num_amigo); printf("Nombre: ");fflush(stdout); gets(p_amigo->nombre); printf("Apellido: ");fflush(stdout); gets(p_amigo->apellido); printf("Edad: ");fflush(stdout); scanf( "%i", &p_amigo->edad ); /* vaciamos el buffer de entrada */ while(getchar()!='n'); /* saltamos al siguiente elemento */ p_amigo++; } /* Ahora imprimimos sus datos */ p_amigo = amigo; for( num_amigo=0; num_amigo<ELEMENTOS; num_amigo++ ) { printf( "El amigo %s ", p_amigo->nombre ); printf( "%s tiene ", p_amigo->apellido ); printf( "%i años.n", p_amigo->edad ); p_amigo++; } } Es importante no olvidar que al terminar el primer bucle for el puntero p_amigo apunta al último elemento del array de estructuras. Para mostrar los datos tenemos que hacer que vuelva a apuntar al primer elemento y por eso usamos de nuevo p_amigo=amigo; (en negrita). ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 37
- 39. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Introducción: Una de las aplicaciones más interesantes y potentes de la memoria dinámica y los punteros son las estructuras dinámicas de datos. Las estructuras básicas disponibles en C y C++ tienen una importante limitación: no pueden cambiar de tamaño durante la ejecución. Los arreglos están compuestos por un determinado número de elementos, número que se decide en la fase de diseño, antes de que el programa ejecutable sea creado. En muchas ocasiones se necesitan estructuras que puedan cambiar de tamaño durante la ejecución del programa. Por supuesto, podemos hacer 'arrays' dinámicos, pero una vez creados, tu tamaño también será fijo, y para hacer que crezcan o diminuyan de tamaño, deberemos reconstruirlas desde el principio. Las estructuras dinámicas nos permiten crear estructuras de datos que se adapten a las necesidades reales a las que suelen enfrentarse nuestros programas. Pero no sólo eso, como veremos, también nos permitirá crear estructuras de datos muy flexibles, ya sea en cuanto al orden, la estructura interna o las relaciones entre los elementos que las componen. Las estructuras de datos están compuestas de otras pequeñas estructuras a las que llamaremos nodos o elementos, que agrupan los datos con los que trabajará nuestro programa y además uno o más punteros autoreferenciales, es decir, punteros a objetos del mismo tipo nodo. Una estructura básica de un nodo para crear listas de datos seria: struct nodo { int dato; struct nodo *otronodo; }; El campo "otronodo" puede apuntar a un objeto del tipo nodo. De este modo, cada nodo puede usarse como un ladrillo para construir listas de datos, y cada uno mantendrá ciertas relaciones con otros nodos. Para acceder a un nodo de la estructura sólo necesitaremos un puntero a un nodo. Durante el presente curso usaremos gráficos para mostrar la estructura de las estructuras de datos dinámicas. El nodo anterior se representará asi: ESTRUCTURA DE DATOS I -- FCI Las estructuras dinámicas son una implementación de TDAs o TADs (Tipos Abstractos de Datos). En estos tipos el interés se centra más en la estructura de los datos que en el tipo concreto de información que almacenan. Dependiendo del número de punteros y de las relaciones entre nodos, podemos distinguir varios tipos de estructuras dinámicas. Enumeraremos ahora sólo de los tipos básicos: • Listas abiertas: cada elemento sólo dispone de un puntero, que apuntará al siguiente elemento de la lista o valdrá NULL si es el último elemento. 38 Manual de Estructura de Datos
- 40. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas • Pilas: son un tipo especial de lista, conocidas como listas LIFO (Last In, First Out: el último en entrar es el primero en salir). Los elementos se "amontonan" o apilan, de modo que sólo el elemento que está encima de la pila puede ser leído, y sólo pueden añadirse elementos encima de la pila. • Colas: otro tipo de listas, conocidas como listas FIFO (First In, First Out: El primero en entrar es el primero en salir). Los elementos se almacenan en fila, pero sólo pueden añadirse por un extremo y leerse por el otro. • Listas circulares: o listas cerradas, son parecidas a las listas abiertas, pero el último elemento apunta al primero. De hecho, en las listas circulares no puede hablarse de "primero" ni de "último". Cualquier nodo puede ser el nodo de entrada y salida. • Listas doblemente enlazadas: cada elemento dispone de dos punteros, uno a punta al siguiente elemento y el otro al elemento anterior. Al contrario que las listas abiertas anteriores, estas listas pueden recorrerse en los dos sentidos. • Arboles: cada elemento dispone de dos o más punteros, pero las referencias nunca son a elementos anteriores, de modo que la estructura se ramifica y crece igual que un árbol. • Arboles binarios: son árboles donde cada nodo sólo puede apuntar a dos nodos. • Arboles binarios de búsqueda (ABB): son árboles binarios ordenados. Desde cada nodo todos los nodos de una rama serán mayores, según la norma que se haya seguido para ordenar el árbol, y los de la otra rama serán menores. • Arboles AVL: son también árboles de búsqueda, pero su estructura está más optimizada para reducir los tiempos de búsqueda. • Arboles B: son estructuras más complejas, aunque también se trata de árboles de búsqueda, están mucho más optimizados que los anteriores. • Tablas HASH: son estructuras auxiliares para ordenar listas. • Grafos: es el siguiente nivel de complejidad, podemos considerar estas estructuras como árboles no jerarquizados. • Diccionarios. Al final del curso también veremos estructuras dinámicas en las que existen nodos de distintos tipos, en realidad no es obligatorio que las estructuras dinámicas estén compuestas por un único tipo de nodo, la flexibilidad y los tipos de estructuras sólo están limitados por tu imaginación como programador. ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 39
- 41. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Listas Fundamentos Las listas son secuencias de elementos, donde estos elementos pueden ser accedidos, insertados o suprimidos en cualquier posición de la lista. No existe restricción alguna acerca de la localización de esas operaciones. Se trata de estructuras muy flexibles puesto que pueden crecer o acotarse como se quiera. Matemáticamente, una lista es una secuencia de cero o más elementos de un tipo determinado (que por lo general denominaremos T). A menudo se representa una lista como una sucesión de elementos separados por comas: a(1), a(2), a(3), ... , a(n) donde a "n" (n >= 0) se le llama longitud de la lista. Al suponer n>=1, se dice que a (1) es el primer elemento de la lista y a(n) el último elemento. Si n=0, se tiene una lista vacía. Una propiedad importante de una lista es que sus elementos pueden estar ordenados en forma lineal de acuerdo con sus posiciones en la lista. Se dice que a(i) precede a a(i+1), para i=1,2, .., n-1, y que a(i) sucede a a(i-1), para i=2, 3, .., n. También se dice que el elemento a(i) está en la posición i de la lista. Por lo que se ve, las estructuras pila y cola, estudiadas en el capítulo anterior, no son más que casos particulares de la estructura lista generalizada. Al igual que en los casos anteriores, se puede pensar en representar una lista mediante un array unidimensional, lo que permite un acceso eficiente a cada uno de los componentes de la estructura, lo que, en principio, parece proporcionar un esquema adecuado para representar las operaciones que normalmente se desean realizar sobre la lista: acceder a un elemento (nodo) arbitrario de la lista, insertar y borrar nodos, etc. Sin embargo, si bien todas estas consideraciones eran ciertas para las pilas y las colas, cuando se trata de otro tipo de listas, las operaciones a realizar sobre el array resultan bastante más costosas. Por ejemplo, supongamos la siguiente lista: (Antonio, Bartolomé, Carlos, David, Emilio, Germán, Jaime, José, Luis, Manuel) Si se desea añadir el valor 'Fernando' a esta lista ordenada de nombres, la operación se debe realizar en la sexta posición de la lista, entre los valores 'Emilio' y 'Germán'. Cuando la lista está representada con un array, dicha inserción implicará tener que desplazar una posición hacia la derecha todos los elementos situados ya en la lista a partir de la posición seis (Germán,...Manuel), para de esta forma dejar una posición libre en el array y poder insertar allí el nuevo valor. Por otro lado, si suponemos que lo que se desea es borrar de la lista el elemento 'Carlos', de nuevo es necesario desplazar elementos para mantener la estructura secuencial de la lista. En este caso es preciso mover una posición hacia la izquierda todos los elementos situados a partir de la cuarta posición. Cuando el problema es manipular diferentes listas de tamaño variable, la representación secuencial prueba ser, de nuevo, poco apropiada. Si se decide almacenar en distintos arrays cada una de las listas, se ESTRUCTURA DE DATOS I -- FCI tendrán grandes necesidades de almacenamiento. Si, por el contrario, se toma la decisión de usar un único array, se necesitará una cantidad mucho mayor de desplazamientos de información. Una solución elegante al problema del desplazamiento de información en el almacenamiento secuencial se logra mediante la utilización de representaciones enlazadas (o ligadas). A diferencia de la representación secuencial, en la representación enlazada los elementos se pueden situar en cualquier posición de memoria, y no necesariamente igualmente distantes dentro de ella. También se puede decir que, si bien en la representación con arrays el orden de los elementos es el mismo que el orden en la lista, en una representación enlazada la secuencia de orden de la lista no tiene porque coincidir con la secuencia de almacenamiento en memoria. 40 Manual de Estructura de Datos
- 42. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Listas abiertas o Simples La forma más simple de estructura dinámica es la lista abierta. En esta forma los nodos se organizan de modo que cada uno apunta al siguiente, y el último no apunta a nada, es decir, el puntero del nodo siguiente vale NULL. En las listas abiertas existe un nodo especial: el primero. Normalmente diremos que nuestra lista es un puntero a ese primer nodo y llamaremos a ese nodo la cabeza de la lista. Eso es porque mediante ese único puntero podemos acceder a toda la lista. Cuando el puntero que usamos para acceder a la lista vale NULL, diremos que la lista está vacía. El nodo típico para construir listas tiene esta forma: struct nodo { int dato; struct nodo *siguiente; }; En el ejemplo, cada elemento de la lista sólo contiene un dato de tipo entero, pero en la práctica no hay límite en cuanto a la complejidad de los datos a almacenar. Una lista lineal simplemente enlazada es una estructura en la que el cada elemento enlaza con el siguiente. El recorrido se inicia a partir de un puntero ubicado al comienzo de la lista. El último elemento (nodo) de la lista apunta a una dirección vacía que indica el fin de la estructura. Donde p=^Nodolista (apunta al sgte. nodo de la lista) Declaraciones de tipos para manejar listas en C: Normalmente se definen varios tipos que facilitan el manejo de las listas, en C, la declaración de tipos puede tener una forma parecida a esta: typedef struct _nodo { int dato; struct _nodo *siguiente; } tipoNodo; typedef tipoNodo *pNodo; ESTRUCTURADE DATOS I -- FCI typedef tipoNodo *Lista; tipoNodo es el tipo para declarar nodos, evidentemente. pNodo es el tipo para declarar punteros a un nodo. Lista es el tipo para declarar listas, como puede verse, un puntero a un nodo y una lista son la misma cosa. En realidad, cualquier puntero a un nodo es una lista, cuyo primer elemento es el nodo apuntado. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 41
- 43. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Es muy importante que nuestro programa nunca pierda el valor del puntero al primer elemento, ya que si no existe ninguna copia de ese valor, y se pierde, será imposible acceder al nodo y no podremos liberar el espacio de memoria que ocupa. Localizar elementos en una lista abierta: Muy a menudo necesitaremos recorrer una lista, ya sea buscando un valor particular o un nodo concreto. Las listas abiertas sólo pueden recorrerse en un sentido, ya que cada nodo apunta al siguiente, pero no se puede obtener, por ejemplo, un puntero al nodo anterior desde un nodo cualquiera si no se empieza desde el principio. Para recorrer una lista procederemos siempre del mismo modo, usaremos un puntero auxiliar como índice: 1. Asignamos al puntero índice el valor de Lista. 2. Abriremos un bucle que al menos debe tener una condición, que el índice no sea NULL. 3. Dentro del bucle asignaremos al índice el valor del nodo siguiente al índice actual. Por ejemplo, para mostrar todos los valores de los nodos de una lista, podemos usar el siguente bucle en C: typedef struct _nodo { int dato; struct _nodo *siguiente; } tipoNodo; typedef tipoNodo *pNodo; typedef tipoNodo *Lista; ... pNodo indice; ... indice = Lista; while(indice) { printf("%dn", indice->dato); indice = indice->siguiente; } ... Supongamos que sólo queremos mostrar los valores hasta que encontremos uno que sea mayor que 100, podemos sustituir el bucle por: ... ESTRUCTURA DE DATOS I -- FCI indice = Lista; while(indice && indice->dato <= 100) { printf("%dn", indice->dato); indice = indice->siguiente; } ... Si analizamos la condición del bucle, tal vez encontremos un posible error: ¿Qué pasaría si ningún valor es mayor que 100, y alcancemos el final de la lista?. Podría pensarse que cuando indice sea NULL, si intentamos acceder a indice->dato se producirá un error. 42 Manual de Estructura de Datos
- 44. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas En general eso será cierto, no puede accederse a punteros nulos. Pero en este caso, ese acceso está dentro de una condición y forma parte de una expresión "and". Recordemos que cuando se evalúa una expresión "and", se comienza por la izquierda, y la evaluación se abandona cuando una de las expresiones resulta falsa, de modo que la expresión "indice->dato <= 100" nunca se evaluará si indice es NULL. Si hubiéramos escrito la condición al revés, el programa nunca funcionaría bien. Esto es algo muy importante cuando se trabaja con punteros. Operaciones básicas con listas: Con las listas tendremos un pequeño repertorio de operaciones básicas que se pueden realizar: • Añadir o insertar elementos. • Buscar o localizar elementos. • Borrar elementos. • Moverse a través de una lista, anterior, siguiente, primero. Cada una de estas operaciones tendrá varios casos especiales, por ejemplo, no será lo mismo insertar un nodo en una lista vacía, o al principio de una lista no vacía, o la final, o en una posición intermedia. Insertar elementos en una lista abierta: Veremos primero los casos sencillos y finalmente construiremos un algoritmo genérico para la inserción de elementos en una lista. Insertar un elemento en una lista vacía: Este es, evidentemente, el caso más sencillo. Partiremos de que ya tenemos el nodo a insertar y, por supuesto un puntero que apunte a él, además el puntero a la lista valdrá NULL: El proceso es muy simple, bastará con que: 1. nodo->siguiente apunte a NULL. 2. Lista apunte a nodo. Insertar un elemento en la primera posición de una lista: Podemos considerar el caso anterior como un caso particular de éste, la única diferencia es que en el caso anterior la lista es una lista vacía, pero siempre podemos, y debemos considerar una lista vacía como una lista. De nuevo partiremos de un nodo a insertar, con un puntero que apunte a él, y de una lista, en este caso no vacía: ESTRUCTURADE DATOS I -- FCI El proceso sigue siendo muy sencillo: 1. Hacemos que nodo->siguiente apunte a Lista. 2. Hacemos que Lista apunte a nodo. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 43
- 45. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Insertar un elemento en la última posición de una lista: Este es otro caso especial. Para este caso partiremos de una lista no vacía: El proceso en este caso tampoco es excesivamente complicado: 1. Necesitamos un puntero que señale al último elemento de la lista. La manera de conseguirlo es empezar por el primero y avanzar hasta que el nodo que tenga como siguiente el valor NULL. 2. Hacer que nodo->siguiente sea NULL. 3. Hacer que ultimo->siguiente sea nodo. Insertar un elemento a continuación de un nodo cualquiera de una lista: De nuevo podemos considerar el caso anterior como un caso particular de este. Ahora el nodo "anterior" será aquel a continuación del cual insertaremos el nuevo nodo: Suponemos que ya disponemos del nuevo nodo a insertar, apuntado por nodo, y un puntero al nodo a continuación del que lo insertaremos. El proceso a seguir será: 1. Hacer que nodo->siguiente señale a anterior->siguiente. 2. Hacer que anterior->siguiente señale a nodo. ESTRUCTURA DE DATOS I -- FCI 44 Manual de Estructura de Datos
- 46. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Funciones Prototipos int ListaVacia(Lista l); void Insertar(Lista *l,int v); void InsertarC(Lista *l,int v); void InsertarF(Lista *l,int v); void Borrar(Lista *l,int v); void BorrarLista(Lista *l); void MostrarLista(Lista l); Implementacion de las funciones Prototipos.- Verificar si una lista abierta esta vacia int ListaVacia(Lista lista) {return(lista==NULL); } Insertar un elemento de forma ordenada en una lista abierta void Insertar(Lista *lista, int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->dato=v; if(ListaVacia(*lista)||(*lista)->dator>v){ nuevo->siguiente=*lista; *lista=nuevo; } else {anterior=*lista; while(anterior->siguiente && anterior->dator <=v) anterior=anterior->siguiente; nuevo->siguiente=anterior->siguiente; anterior->siguiente=nuevo; } } Insertar un elemento al inicio de una lista abierta void InsertarC(Lista *lista, int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->dato=v; nuevo->siguiente=*lista; *lista=nuevo; } ESTRUCTURADE DATOS I -- FCI Insertar un elemento al final de una lista abierta void InsertarF(Lista *lista, int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->dato=v; if(ListaVacia(*lista)){ nuevo->siguiente=*lista; *lista=nuevo; } else Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 45
- 47. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas {anterior=*lista; while(anterior->siguiente!=NULL) anterior=anterior->siguiente; anterior->siguiente=nuevo; nuevo->siguiente=NULL; } } Borrar un elemento específico de una lista abierta void Borrar (Lista *lista, int v) {pNodo nodo, anterior; nodo*lista; anterior=NULL; while (nodo && nodo->dato < v) { anterior =nodo; nodo= nodo->siguiente; } If (!nodo || nodo->dato !=v) return; else { /* borra el nodo*/ If(!anterior) /* primer elemento*/ *lista=nodo->siguiente; else /* un elemeto cualquiera*/ anterior->siguiente=nodo->siguiente; free(nodo); } } Borrar un una lista abierta void Borrar_Lista(Lista *lista) { pNodo nodo; While(*lista) { nodo=*lista; *lista=nodo->siguiente; free(nodo); } } Mostrar la información de una lista abierta void MostrarLista(Lista lista) {pNodo nodo=lista; if(ListaVacia(lista)) printf("Lista vacia n"); else{ while(nodo) { printf("%d-> ",nodo->dato); nodo=nodo->siguiente; } ESTRUCTURA DE DATOS I -- FCI } } 46 Manual de Estructura de Datos
- 48. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas PILAS Y COLAS Las pilas y las colas son dos de las estructuras de datos más utilizadas. Se trata de dos casos particulares de las estructuras lineales generales (secuencias o listas) que, debido a su amplio ámbito de aplicación, conviene ser estudiadas de manera independiente. PILAS. FUNDAMENTOS La pila es una lista de elementos caracterizada porque las operaciones de inserción y eliminación se realizan solamente en un extremo de la estructura. El extremo donde se realizan estas operaciones se denomina habitualmente 'cima' (top en nomenclatura inglesa). Dada una pila P=(a,b,c,...k), se dice que a, que es el elemento más inaccesible de la pila, está en el fondo de la pila (bottom) y que k, por el contrario, el más accesible, está en la cima. Las restricciones definidas para la pila implican que si una serie de elementos A,B,C,D,E se añaden, en este orden a una pila, entonces el primer elemento que se borre de la estructura deberá ser el E. Por tanto, resulta que el último elemento que se inserta en una pila es el primero que se borra. Por esta razón, se dice que una pila es una lista LIFO (Last In First Out, es decir, el último que entra es el primero que sale). Un ejemplo típico de pila lo constituye un montón de platos, cuando se quiere introducir un nuevo plato, éste se pone en la posición más accesible, encima del último plato. Cuando se coge un nuevo plato, éste se extrae, igualmente, del punto más accesible, el último que se ha introducido. Otro ejemplo natural de la aplicación de la estructura pila aparece durante la ejecución de un programa de ordenador, en la forma en que la máquina procesa las llamadas a los procedimientos. Cada llamada a un procedimiento (o función) hace que el sistema almacene toda la información asociada con ese procedimiento (parámetros, variables, constantes, dirección de retorno, etc..) de forma independiente a otros procedimientos y permitiendo que unos procedimientos puedan invocar a otros distintos (o a si mismos) y que toda esa información almacenada pueda ser recuperada convenientemente cuando corresponda. Como en un procesador sólo se puede estar ejecutando un procedimiento, esto quiere decir que sólo es necesario que sean accesibles los datos de un procedimiento (el último activado que está en la cima). De ahí que la estructura pila sea muy apropiada para este fin. Como en cualquier estructura de datos, asociadas con la estructura pila existen una serie de operaciones necesarias para su manipulación, éstas son: • Crear la pila. • Comprobar si la pila está vacia. Es necesaria para saber si es posible eliminar elementos. • Acceder al elemento situado en la cima. • Añadir elementos a la cima. • Eliminar elementos de la cima. La especificación correcta de todas estas operaciones permitirá definir adecuadamente una pila. ESTRUCTURADE DATOS I -- FCI Representacion de las pilas Los lenguajes de programación de alto nivel no suelen disponer de un tipo de datos pila. Aunque por el contrario, en lenguajes de bajo nivel (ensamblador) es posible manipular directamente alguna estructura pila propia del sistema. Por lo tanto, en general, es necesario representar la estructura pila a partir de otros tipos de datos existentes en el lenguaje. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 47
- 49. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas La forma más simple, y habitual, de representar una pila es mediante un vector unidimensional. Este tipo de datos permite definir una secuencia de elementos (de cualquier tipo) y posee un eficiente mecanismo de acceso a la información contenida en él. El hecho de utilizar un vector para almacenar los elementos, puede conducir a la situación en que la pila esté llena, es decir, que no quepa ningún elemento más. Esto se producirá cuando el índice que señala la cima de la pila sea igual al tamaño del vector. Al definir un array hay que determinar el número de índices válidos y, por lo tanto, el número de componentes definidos. Entonces, la estructura pila representada por un array tendrá limitado el número de posibles elementos. Se puede definir una pila como una variable, sin usar array: typedef struct nodo { int dato; struct nodo * sig; }tipoNodo; typedef tipoNodo * pNodo; typedef tipoNodo * Pila; Como todas las operaciones se realizan sobre la cima de la pila, es necesario tener correctamente localizada en todo instante esta posición. Es necesaria una variable, cima, que apunte al último elemento (ocupado) de la pila. Con estas consideraciones prácticas, se puede pasar a definir las operaciones que definen la pila. Crear pila: Es necesario definir la variable que permitirá almacenar la información, indicando que la creación implica que la pila está vacía, por lo que deberá ser igual a NULL. Comprobar si la pila está vacía: Esta operación permitirá determinar si es posible eliminar elementos. boolean Pila_vacia (Pila p) { boolean r=false; If ( (*pila)==Null) r=true; return r; } ESTRUCTURA DE DATOS I -- FCI Operación de inserción La operación de inserción normalmente se conoce por su nombre inglés push. La operación aplicada sobre una pila y un valor x, inserta x en la cima de la pila. Esta operación está restringida por el tipo de representación escogido. En el caso, la utilización de un array implica que se tiene un número máximo de posibles elementos en la pila, por lo tanto, es necesario comprobar, previamente a la inserción, que realmente hay espacio en la estructura para almacenar un nuevo elemento. Con esta consideración el algoritmo de inserción sería: 48 Manual de Estructura de Datos
- 50. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Algoritmo Apilar void InsertarPila(Pila *pila, int v) { pNodo nuevo; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->dato=v; nuevo->sig=*pila; *pila=nuevo; } Operación de eliminación La operación de borrado elimina de la estructura el elemento situado en la cima. Normalmente recibe el nombre de pop en la bibliografía inglesa. El algoritmo de borrado sería: Algoritmo Desapilar int Pop(Pila *pila) { pNodo nodo=*pila; int v=0; if(!nodo) cout<< "Pila Vacias...n"; else { *pila=nodo->sig; v=nodo->dato; free(nodo); } return v; } (Recordemos que la función Pila_vacia nos devuelve un valor lógico (cierto o falso) que en este caso nos sirve como condición para el si) En todos los algoritmos se podría suponer que las variables Pila y cima, lo mismo que n, son globales y, por lo tanto, no sería necesario declararlas como entradas o salidas. Pilas Notación Prefija, Infija y Postfija • Expresión aritmética: – Formada por operandos y operadores: A*B / (A+C) – Operandos: variables que toman valores enteros o reales ESTRUCTURADE DATOS I -- FCI – Operadores: – En caso de igualdad de prioridad • Son evaluados de izquierda a derecha (se evalúa primero el que primero aparece) 5*4/2 = (5*4)/2 = 10 Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 49
- 51. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas • Cuando aparecen varios operadores de potenciación juntos la expresión se evalúa de derecha a izquierda 2^3^2 = 2^(3^2) = 2^9 = 512 • Notación Infija – Es la notación ya vista que sitúa el operador entre sus operandos. – Ventaja: Es la forma natural de escribir expresiones aritméticas – Inconveniente: Muchas veces necesita de paréntesis para indicar el Orden de evaluación: A*B/(A+C) ¹ A*B/A+C • Notación Prefija o Polaca – En 1920 un matemático de origen polaco, Jan Lukasiewicz, desarrollo un sistema para especificar expresiones matemáticas sin paréntesis. – Esta notación se conoce como notación prefija o polaca (en honor a la nacionalidad de Lukasiewicz) y consiste en situar al operador ANTES que los operandos. – Ejemplo: la expresión infija A*B / (A+C) se representaría en notación prefija como: /*AB+AC • Notación Postfija o Polaca Inversa – La notación postfija o polaca inversa es una variación de la notación prefija de forma que el operador de pone DESPUÉS de los operandos. – Ejemplo: la expresión infija A*B / (A+C) se representaría en notación postfija como: AB*AC+/ – Ventajas: • La notación postfija (como la prefija) no necesita paréntesis. • La notación postfija es más utilizada por los computadores ya que permite una forma muy sencilla y eficiente de evaluar expresiones aritméticas (con pilas). Colas. Fundamentos Las colas son secuencias de elementos caracterizadas porque las operaciones de inserción y borrado se realizan sobre extremos opuestos de la secuencia. La inserción se produce en el "final" de la secuencia, mientras que el borrado se realiza en el otro extremo, el "inicio" de la secuencia. Las restricciones definidas para una cola hacen que el primer elemento que se inserta en ella sea, igualmente, el primero en ser extraido de la estructura. Si una serie de elementos A, B, C, D, E se insertan en una cola en ese mismo orden, entonces los elementos irán saliendo de la cola en el orden en que entraron. Por esa razón, en ocasiones, las colas se conocen con el nombre de listas FIFO (First In First Out, el primero que entra es el primero que sale). Teniendo en cuenta que las operaciones de lectura y escritura en una cola hacen siempre en extremos ESTRUCTURA DE DATOS I -- FCI distintos, lo más fácil será insertar nodos por el final, a continuación del nodo que no tiene nodo siguiente, y leer desde el principio, hay que recordar que leer un nodo implica elimarlo de la cola. Las colas, al igual que las pilas, resultan de aplicación habitual en muchos problemas informáticos. Quizás la aplicación más común de las colas es la organización de tareas de un ordenador. En general, los trabajos enviados a un ordenador son "encolados" por éste, para ir procesando secuencialmente todos los trabajos en el mismo orden en que se reciben. Cuando el ordenador recibe el encargo de realizar una tarea, ésta es almacenada al final de la cola de trabajos. En el momento que la tarea que estaba realizando el procesador acaba, éste selecciona la tarea situada al principio de la cola para ser ejecutada a continuación. Todo esto suponiendo la ausencia de prioridades en los trabajos. En caso contrario, existirá una cola para cada prioridad. Del mismo modo, es necesaria una cola, por ejemplo, a la hora de gestionar 50 Manual de Estructura de Datos
- 52. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas eficientemente los trabajos que deben ser enviados a una impresora (o a casi cualquier dispositivo conectado a un ordenador). De esta manera, el ordenador controla el envio de trabajos al dispositivo, no enviando un trabajo hasta que la impresora no termine con el anterior. Análogamente a las pilas, es necesario definir el conjunto de operaciones básicas para especificar adecuadamente una estructura cola. Estas operaciones serían: • Crear una cola vacía. • Determinar si la cola está vacía, en cuyo caso no es posible eliminar elementos. • Acceder al elemento inicial de la cola. • Insertar elementos al final de la cola. • Eliminar elementos al inicio de la cola. Para determinar correctamente cada una de estas operaciones, es necesario especificar un tipo de representación para las colas. Representacion de las colas Hay diferentes formas de implementar las operaciones relacionadas con colas, una de las más eficientes es representar el array Cola[1..n] como si fuese circular, es decir, cuando se dé la condición de cola llena se podrá continuar por el principio de la misma si esas posiciones no estan ocupadas. Con este esquema de representación, se puede pasar a especificar el conjunto de operaciones necesarias para definir una cola circular. Para nuestro erstudio partiremos de la creación sin arrays. Crear cola: Esta operación consistirá en definir la variable que permitirá almacenar la información y las variables que apuntarán a los extremos de la estructura. Además, hay que indicar explícitamente que la cola, trás la creación, está vacía. typedef struct nodo { int dato; struct nodo * sig; }tipoNodo; typedef tipoNodo * pNodo; typedef tipoNodo * Cola; Comprobar si la cola está vacía: Con las condiciones establecidas, basta comprobar si inicio = fin: boolean Cola_vacia Cola c) { boolean r=false; If ( (*cola)==Null) r=true; return r; } ESTRUCTURADE DATOS I -- FCI Acceder al elemento inicial o al final de la cola: Es importante poder acceder fácilmente al inicio o al final de la cola; para ello se puede usar un puntero llamado primero, y otro llamado ultimo. Insertar un elemento en la cola: Debido a la implementación estática de la estructura cola es necesario determinar si existen huecos libres donde poder insertar antes de hacerlo. Esto puede hacerse de varias formas: Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 51
- 53. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Void Añadir (Cola * primero, Cola *Ultimo, int V) { pNuevo nuevo; nuevo=(pNodo)malloc(sizeof(tipoNodo)); /* crear un nuevo nodo*/ nuevo->dato=v; nuevo->siguiente=Null; /*este será el ultimo nodo, no debetener siguiente*/ /*Si la cola no estaba vacia, añadimo el nuevo a continuacion de ultimo*/ If(Cola_vacia(ultimo)) (*ultimo)->siguiente=nuevo; *ultimo=nuevo; /*Ahora, el ultmioelemento de la cola es el nuevo nodo*/ /*Si primero es Null, la cola estaba vacia, ahora primero apuntara también al nuevo nodo */ } O incrementando antes y luego comparando que 'Cola.inicio' sea igual a 'Cola.fin'. Eliminar un elemento de la cola: Sirve exclusivamente para extarer los elementos de una cola, se debe recordar que en cada movimiento de contenido de la cola los punteros primero y último deben actualizarse debidamente. Int Leer(Cola * primero, Cola *ultimo) { pNodo nodo;/* variable para manipular nodo*/ int v; /*variable auxiliar para retorno*/ nodo=*primero; /*Nodo apunta al primer elemento de la cola*/ if(Cola_vacia(nodo)) return 0; /* Si no hay nodos en la pila retornamos*/ *primero=nodo->siguiente; /*Asignmam,os a primero la dirección del segundo nodo*/ v=nodo->valor; /*Guardamos el valor de retorno*/ free(nodo); /*Borra el nodo*/ if(Cola_vacia(primero))*ultimo=NULL; /*Si la cola quedo vacia, ultimo debe ser NULL*/ return v; } Conclusión De todo esto puede sorprender que la condición de cola llena sea la misma que la de cola vacía. Sin embargo, en el caso de la inserción de elementos cuando Cola.inicio = Cola.fin es cierto, no es verdad que la cola esté llena, en realidad hay un espacio libre, ya que Cola.inicio apunta a una posición libre, la anterior al primer elemento real de la cola. Pero si se decide insertar un elemento en esa posición, no sería posible distinguir si Cola.inicio = Cola.fin indica que la cola está llena o vacía. Se podría definir alguna variable lógica que indicase cual de las dos situaciones se está dando en realidad. Esta modificación implicaría introducir alguna nueva operación en los métodos de inserción y borrado, lo que, en general, resultaría peor solución que no utilizar un elemento del array. Suele ser mejor solución utilizar siempre 'n-1' elementos de la cola, y no 'n', que complicar dos operaciones que se tendrán que repetir múltiples veces durante la ejecución de un programa. Pilas y colas múltiples Hasta ahora se ha tratado solamente con la representación en memoria y manipulación de una única pila ESTRUCTURA DE DATOS I -- FCI o cola. Se han visto dos representaciones secuenciales eficientes para dichas estructuras. Sin embargo, en ocasiones, es preciso representar varias estructuras utilizando el mismo espacio de memoria. Supongamos que seguimos transformando las estructuras de datos en representaciones secuenciales, tipo array. Si sólo hay que representar dos pilas sobre un mismo array A[1..n], la solución puede resultar simple. Se puede hacer crecer las dos pilas partiendo desde los extremos opuestos del array, de forma que A[1] será el elemento situado en el fondo de la primera pila y A[n] el correspondiente para la segunda pila. Entonces, la pila 1 crecerá incrementando los índices hacia A[n] y la pila 2 lo hará decrementando los índices hacia A[1]. De esta manera, es posible utilizar eficientemente todo el espacio disponible. 52 Manual de Estructura de Datos
- 54. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Si se plantea representar más de dos pilas sobre ese mismo array A, no es posible seguir la misma estrategia, ya que un array unidimensional sólo tiene dos puntos fijos, A[1] y A[n], y cada pila requiere un punto fijo para representar el elemento más profundo. Cuando se requiere representar secuencialmente más de dos pilas, por ejemplo m pilas, es necesario dividir en m segmentos la memoria disponible, A[1..n], y asignar a cada uno de los segmentos a una pila. La división inicial de A[1..n] en segmentos se puede hacer en base al tamaño esperado de cada una de las estructuras. Si no es posible conocer esa información, el array A se puede dividir en segmentos de igual tamaño. Para cada pila i, se utilizará un índice f(i) para representar el fondo de la pila i y un índice c(i) para indicar dónde está su cima. En general, se hace que f(i) esté una posición por debajo del fondo real de la pila, de forma que se cumpla la condición f(i)=c(i) si y solamente si la pila i está vacía. La discusión realizada para el caso de pilas múltiples sirve de base para poder establecer estrategias de manipulación de varias colas en un mismo array, incluso la combinación de estructuras pilas y colas sobre la misma localización secuencial. ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 53
- 55. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Listas Circulares Una lista circular es una lista lineal en la que el último elemento enlaza con el primero. Entonces es posible acceder a cualquier elemento de la lista desde cualquier punto dado. Las listas circulares evitan excepciones en las operaciones que se realicen sobre ellas. No existen casos especiales, cada nodo siempre tiene uno anterior y uno siguiente. En algunas listas circulares se añade un nodo especial de cabecera, de ese modo se evita la única excepción posible, la de que la lista esté vacía. El nodo típico es el mismo que para construir listas abiertas: struct nodo { int dato; struct nodo *siguiente; }; Donde p=^Nodolista (apunta al sgte. nodo de la lista) La definición de tipo es equivalente a la anterior sólo se debe modificar la dirección a la que apunta el enlace ubicado en el último nodo. Las operaciones sobre una lista circular resultan más sencillas. Cuando recorremos una lista circular, diremos que hemos llegado al final de la misma cuando nos encontremos de nuevo en el punto de partida; suponiendo que en este punto se deja un puntero fijo. Otra solución al problema anterior sería ubicar en cada lista circular un elemento especial identificable, como lugar de parada. Este elemento especial recibe el nombre de cabeza de la lista. Esto presenta la ventaja de que la lista circular no estará nunca vacía. Declaraciones de tipo para manejar listas: Los tipos que definiremos normalmente para manejar listas cerradas son los mismos que para para manejar listas abiertas: typedef struct _nodo { int dato; struct _nodo *siguiente; } tipoNodo; typedef tipoNodo *pNodo; typedef tipoNodo *Lista; tipoNodo es el tipo para declarar nodos, evidentemente. ESTRUCTURA DE DATOS I -- FCI pNodo es el tipo para declarar punteros a un nodo. Lista es el tipo para declarar listas, tanto abiertas como circulares. En el caso de las circulares, apuntará a un nodo cualquiera de la lista. A pesar de que las listas circulares simplifiquen las operaciones sobre ellas, también introducen algunas complicaciones. Por ejemplo, en un proceso de búsqueda, no es tan sencillo dar por terminada la búsqueda cuando el elemento buscado no existe.Por ese motivo se suele resaltar 54 Manual de Estructura de Datos
- 56. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas un nodo en particular, que no tiene por qué ser siempre el mismo. Cualquier nodo puede cumplir ese propósito, y puede variar durante la ejecución del programa.Otra alternativa que se usa a menudo, y que simplifica en cierto modo el uso de listas circulares es crear un nodo especial de hará la función de nodo cabecera. De este modo, la lista nunca estará vacía, y se eliminan casi todos los casos especiales. Operaciones básicas con listas circulares: A todos los efectos, las listas circulares son como las listas abiertas en cuanto a las operaciones que se pueden realizar sobre ellas: • Añadir o insertar elementos. • Buscar o localizar elementos. • Borrar elementos. • Moverse a través de la lista, siguiente. Cada una de estas operaciones podrá tener varios casos especiales, por ejemplo, tendremos que tener en cuenta cuando se inserte un nodo en una lista vacía, o cuando se elimina el único nodo de una lista. Añadir elemento en una lista circular vacía: Partiremos de que ya tenemos el nodo a insertar y, por supuesto un puntero que apunte a él, además el puntero que define la lista, que valdrá NULL: El proceso es muy simple, bastará con que: 1. lista apunta a nodo. 2. lista->siguiente apunte a nodo. Añadir elemento en una lista circular no vacía: De nuevo partiremos de un nodo a insertar, con un puntero que apunte a él, y de una lista, en este caso, el puntero no será nulo: ESTRUCTURADE DATOS I -- FCI El proceso sigue siendo muy sencillo: 1. Hacemos que nodo->siguiente apunte a lista->siguiente. 2. Después que lista->siguiente apunte a nodo. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 55
- 57. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Añadir elemento en una lista circular, caso general: Para generalizar los dos casos anteriores, sólo necesitamos añadir una operación: 1. Si lista está vacía hacemos que lista apunte a nodo. 2. Si lista no está vacía, hacemos que nodo->siguiente apunte a lista->siguiente. 3. 4. Después que lista->siguiente apunte a nodo. Buscar o localizar un elemento de una lista circular: A la hora de buscar elementos en una lista circular sólo hay que tener una precaución, es necesario almacenar el puntero del nodo en que se empezó la búsqueda, para poder detectar el caso en que no exista el valor que se busca. Por lo demás, la búsqueda es igual que en el caso de las listas abiertas, salvo que podemos empezar en cualquier punto de la lista. Eliminar un elemento de una lista circular: Para ésta operación podemos encontrar tres casos diferentes: 1. Eliminar un nodo cualquiera, que no sea el apuntado por lista. 2. Eliminar el nodo apuntado por lista, y que no sea el único nodo. 3. Eliminar el único nodo de la lista. En el primer caso necesitamos localizar el nodo anterior al que queremos borrar. Como el principio de la lista puede ser cualquier nodo, haremos que sea precisamente lista quien apunte al nodo anterior al que queremos eliminar.Esto elimina la excepción del segundo caso, ya que lista nunca será el nodo a eliminar, salvo que sea el único nodo de la lista.Una vez localizado el nodo anterior y apuntado por lista, hacemos que lista- >siguiente apunte a nodo->siguiente. Y a continuación borramos nodo.En el caso de que sólo exista un nodo, será imposible localizar el nodo anterior, así que simplemente eliminaremos el nodo, y haremos que lista valga NULL. Eliminar un nodo en una lista circular con más de un elemento: Consideraremos los dos primeros casos como uno sólo. ESTRUCTURA DE DATOS I -- FCI 1. El primer paso es conseguir que lista apunte al nodo anterior al que queremos eliminar. Esto se consigue haciendo que lista valga lista->siguiente mientras lista->siguiente sea distinto de nodo. 56 Manual de Estructura de Datos
- 58. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas 2. Hacemos que lista->siguiente apunte a nodo->siguiente. 3. Eliminamos el nodo. Eliminar el único nodo en una lista circular: Este caso es mucho más sencillo. Si lista es el único nodo de una lista circular: 1. Borramos el nodo apuntado por lista. 2. Hacemos que lista valga NULL. Otro algoritmo para borrar nodos: Existe un modo alternativo de eliminar un nodo en una lista circular con más de un nodo. Supongamos que queremos eliminar un nodo apuntado por nodo: 1. Copiamos el contenido del nodo->siguiente sobre el contenido de nodo. 2. Hhacemos que nodo->siguiente apunte a nodo->siguiente->siguiente. 3. Eliminamos nodo->siguiente. 4. Si lista es el nodo->siguiente, hacemos lista = nodo. Este método también funciona con listas circulares de un sólo elemento, salvo que el nodo a borrar es el único nodo que existe, y hay que hacer que lista apunte a NULL. ESTRUCTURADE DATOS I -- FCI Ejemplo de lista circular en C: Construiremos una lista cerrada para almacenar números enteros. Haremos pruebas insertando varios valores, buscándolos y eliminándolos alternativamente para comprobar el resultado. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 57
- 59. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Algoritmo de la función "Insertar": 1. Si lista está vacía hacemos que lista apunte a nodo. 2. Si lista no está vacía, hacemos que nodo->siguiente apunte a lista->siguiente. 3. Después que lista->siguiente apunte a nodo. void Insertar(Lista *lista, int v) { pNodo nodo; // Creamos un nodo para el nuvo valor a insertar nodo = (pNodo)malloc(sizeof(tipoNodo)); nodo->valor = v; // Si la lista está vacía, la lista será el nuevo nodo // Si no lo está, insertamos el nuevo nodo a continuación del apuntado // por lista if(*lista == NULL) *lista = nodo; else nodo->siguiente = (*lista)->siguiente; // En cualquier caso, cerramos la lista circular (*lista)->siguiente = nodo; } Algoritmo de la función "Borrar": 1. ¿Tiene la lista un único nodo? 2. SI: 1. Borrar el nodo lista. 2. Hacer lista = NULL. 3. NO: 1. Hacemos lista->siguiente = nodo->siguiente. 2. Borramos nodo. void Borrar(Lista *lista, int v) { pNodo nodo; nodo = *lista; // Hacer que lista apunte al nodo anterior al de valor v do { if((*lista)->siguiente->valor != v) *lista = (*lista)->siguiente; } while((*lista)->siguiente->valor != v && *lista != nodo); // Si existe un nodo con el valor v: if((*lista)->siguiente->valor == v) { // Y si la lista sólo tiene un nodo ESTRUCTURA DE DATOS I -- FCI if(*lista == (*lista)->siguiente) { // Borrar toda la lista free(*lista); *lista = NULL; } else { // Si la lista tiene más de un nodo, borrar el nodo de valor v nodo = (*lista)->siguiente; (*lista)->siguiente = nodo->siguiente; free(nodo); } 58 Manual de Estructura de Datos
- 60. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas } } Código del ejemplo: Tan sólo nos queda escribir una pequeña prueba para verificar el funcionamiento: #include <stdio.h> typedef struct _nodo { int valor; struct _nodo *siguiente; } tipoNodo; typedef tipoNodo *pNodo; typedef tipoNodo *Lista; // Funciones con listas: void Insertar(Lista *l, int v); void Borrar(Lista *l, int v); void BorrarLista(Lista *); void MostrarLista(Lista l); int main() { Lista lista = NULL; pNodo p; Insertar(&lista, 10); Insertar(&lista, 40); Insertar(&lista, 30); Insertar(&lista, 20); Insertar(&lista, 50); MostrarLista(lista); Borrar(&lista, 30); Borrar(&lista, 50); MostrarLista(lista); BorrarLista(&lista); getchar(); return 0; } void Insertar(Lista *lista, int v) { pNodo nodo; // Creamos un nodo para el nuvo valor a insertar nodo = (pNodo)malloc(sizeof(tipoNodo)); nodo->valor = v; // Si la lista está vacía, la lista será el nuevo nodo // Si no lo está, insertamos el nuevo nodo a continuación del apuntado // por lista if(*lista == NULL) *lista = nodo; ESTRUCTURADE DATOS I -- FCI else nodo->siguiente = (*lista)->siguiente; // En cualquier caso, cerramos la lista circular (*lista)->siguiente = nodo; }void Borrar(Lista *lista, int v) { pNodo nodo; nodo = *lista; // Hacer que lista apunte al nodo anterior al de valor v do { if((*lista)->siguiente->valor != v) *lista = (*lista)->siguiente; } while((*lista)->siguiente->valor != v && *lista != nodo); Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 59
- 61. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas // Si existe un nodo con el valor v: if((*lista)->siguiente->valor == v) { // Y si la lista sólo tiene un nodo if(*lista == (*lista)->siguiente) { // Borrar toda la lista free(*lista); *lista = NULL; } else { // Si la lista tiene más de un nodo, borrar el nodo de valor v nodo = (*lista)->siguiente; (*lista)->siguiente = nodo->siguiente; free(nodo); } } } void BorrarLista(Lista *lista) { pNodo nodo; // Mientras la lista tenga más de un nodo while((*lista)->siguiente != *lista) { // Borrar el nodo siguiente al apuntado por lista nodo = (*lista)->siguiente; (*lista)->siguiente = nodo->siguiente; free(nodo); } // Y borrar el último nodo free(*lista); *lista = NULL; }void MostrarLista(Lista lista) { pNodo nodo = lista; do { printf("%d -> ", nodo->valor); nodo = nodo->siguiente; } while(nodo != lista); printf("n"); } ESTRUCTURA DE DATOS I -- FCI 60 Manual de Estructura de Datos
- 62. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Listas doblemente enlazadas Hasta ahora hemos estado trabajando exclusivamente con listas simplemente enlazadas. Dependiendo del problema, este tipo de estructura puede resultar ciertamente restrictiva. La dificultad de manejo de estas listas, como hemos visto, viene dada por el hecho de que dado un nodo específico, solamente es posible moverse dentro de la lista en el sentido del único enlace existente para ese nodo, es decir, es fácil pasar al sucesor pero no es igualmente fácil pasar al antecesor de ese mismo nodo. La única manera de encontrar el predecesor de un nodo es volver a recorrer la lista desde el principio. Por lo tanto, cuando se tiene un problema donde es necesario moverse en ambos sentidos, es recomendable representar la lista con dos enlaces (doblemente enlazada). En este tipo de representación, cada nodo tiene dos campos de enlace, uno que enlaza con el nodo predecesor y otro que enlaza con el nodo sucesor. Un nodo en una lista doblemente enlazada tiene, al menos tres campos, uno o más de información y dos campos de enlace. En ocasiones, para facilitar aún más los movimientos dentro de la lista, es conveniente recurrir a una estructura circular de la misma, de forma que desde el último elemento de la lista se pueda pasar al primero y viceversa. Entonces se habla de una lista circular doblemente enlazada. La estructura circular se puede utilizar igualmente aunque la lista sea simplemente enlazada. Para facilitar las operaciones de manipulación de las estructuras circulares, sobre todo la inserción, y evitar en lo posible la consideración de casos especiales (lista vacia) se suele añadir un nodo inicial (cabeza), que no contiene ninguna información útil, y que existe aunque la lista esté vacía. De modo que, incluso la lista vacía tiene una estructura circular. Una lista doblemente enlazada es una lista lineal en la que cada elemento tiene dos enlaces, uno al elemento siguiente y otro al elemento anterior. Esto permite recorrer la lista en cualquier dirección. Implementacion de Principales operaciones con Listas Circulares Doblemente enlazadas Insertar al inicio. void insertar_final(pnododoble *lista,int n) { pnododoble nodo,aux; nodo=(pnododoble)malloc(sizeof(tiponododoble)); if (*lista==NULL) { *lista=nodo; nodo->sig=*lista; nodo->ant=nodo; } else { aux=(*lista)->ant; nodo-Sig=*lista, ESTRUCTURADE DATOS I -- FCI *lista=nodo; *lista->ant=aux; aux->sig=*lista; aux->ant=nodo; } } Insertar al inicio. void insertar_final(pnododoble *lista,int n) { pnododoble nodo; Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 61
- 63. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas nodo=(pnododoble)malloc(sizeof(tiponododoble)); if (*lista==NULL) *lista=nodo; else { (*lista)->ant->sig=nodo; nodo->ant=(*lista)->ant; } (*lista)->ant=nodo; Nodo->sig=*lista; f(*lista!=nodo) *lista=nodo; } Insertar al final. void insertar_final(pnododoble *lista,int n) { pnododoble ult,nodo; nodo=(pnododoble)malloc(sizeof(tiponododoble)); nodo->dato=n; if (*lista==NULL) { *lista=nodo; nodo->sig=*lista; nodo->ant=nodo; } else { ult=(*lista)->ant; ult->sig=nodo; nodo->ant=ult; (*lista)->ant=nodo; nodo->sig=*lista; } Eliminar al inicio. void insertar_inicio(pnododoble *lista,int n) { pnododoble ult,prt=*lista; if (*lista!=NULL) { if (prt->sig!=*lista) { ult=(*lista)->ant; lista=(lista)->sig; (*lista)->ant=ult; ult->sig=*lista; } else *lista=NULL free(prt); } } Eliminar al final. ESTRUCTURA DE DATOS I -- FCI void eliminar_final(pnododoble *lista) {pnododoble ult; if (*lista!=NULL) { ult=(*lista)->ant; if((*lista)->sig!=*lista) { ult->ant->sig=*lista; (*lista)->ant=nodo; } else *lista=NULL; free(ult); } 62 Manual de Estructura de Datos
- 64. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Insertar en cualquier parte. void i_c_p(pnododoble *lista,int num,int n) { pnododoble nodo,aux,ult; nodo=(pnododoble)malloc(sizeof(tiponododble)); nodo->dato=num; if (*lista!=NULL) { aux=*lista; if(aux->dato!=n) {while(aux->sig!=*lista && aux->sig->dato!=n) { aux=aux->sig;} if(aux->sig!=*lista) {nodo->sig=aux->sig; aux->sig->ant=nodo; aux->sig=nodo; nodo->ant=aux;} else {aux->sig=nodo; nodo->ant=aux; (*lista)->ant=nodo; nodo-sig=*lista, } } else {ult=(*lista)->ant; (*lista)->ant=nodo; nodo->sig=*lista; *lista=nodo; (*lista)->ant=ult; ult->sig=*lista; } } else {*lista=nodo; nodo->sig=*lista; (*lista)->ant=nodo; } } Imprimir la lista void imprimir(pnodoble *lista) { pnododoble aux=*lista; if(*lista!=NULL) { do { cout<<aux->dato<<” “; ESTRUCTURADE DATOS I -- FCI aux=aux->sig; } while(aux!=*lista); } } Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 63
- 65. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Pilas y colas enlazadas Se ha visto ya cómo representar pilas y colas de manera secuencial. Ese tipo de representación prueba ser bastante eficiente, sobretodo cuando se tiene sólo una pila o una cola. Cuando sobre el mismo array se tiene que representar más de una estructura, entonces aparecen problemas para poder aprovechar de manera eficiente toda la memoria disponible. Vamos a presentar en esta sección una nueva representación de las pilas y las colas mediante la estructura de lista enlazada. En la representación de estas estructuras vamos a hacer que los enlaces entre los elementos de la misma sea tal que faciliten las operaciones de inserción y borrado de elementos. Además, hay que tener en cuenta que, como en cualquier otro tipo de representación, es necesario mantener variables que indiquen dónde están los extremos de las estructuras (dónde se realizan las operaciones), pero en este caso dichas variables ya no pueden ser índices de un array sino referencias a localizaciones de elementos, es decir, punteros. Pilas enlazadas Comenzando por la estructura pila, enlazando los elementos con punteros las operaciones de inserción y borrado resultan muy simples. A continuación definiremos la estructura pila con esta nueva representación. Crear pila: Declaramos los tipos de datos necesarios para representar un nodo e inicializamos la pila como vacia. (1) Declaraciones: Nodo_pila: registro (informacion: T, enlace: puntero a Nodo_pila) cima: puntero a Nodo_pila (2)Asignación de pila vacía cima <-- NULO Comprobar si la pila está vacía: La pila estará vacía si y solamente si el puntero cima no hace referencia a ninguna dirección de memoria. si cima = NULO entonces devolver(cierto) sino devolver(falso) Acceder al elemento situado en la cima: Al elemento "visible" de la pila se puede acceder fácilmente a través del puntero que le referencia, cima, que siempre debe existir y ser adecuadamente actualizado. Operación de inserción: Con la representación enlazada de la pila, la estructura tiene una menor limitación en cuanto al posible número de elementos que se pueden almacenar simultáneamente. Hay que tener en cuenta que la representación de la pila ya no requiere la especificación de un tamaño máximo, por lo que mientras exista memoria disponible se va a poder reservar espacio para nuevos elementos. Por esa razón, se va a suponer en el siguiente algoritmo que la condición de pila llena no se va a dar y, por lo tanto, no será necesaria su comprobación. Algoritmo Apilar Entrada x: T (* elemento que se desea insertar *) Inicio p <-- crear_espacio p^.informacion <-- x ESTRUCTURA DE DATOS I -- FCI p^.enlace <-- cima cima <-- p Fin Como se puede observar el algoritmo de inserción utilizando esta nueva representación continua siendo muy simple, siendo el coste del mismo constante (cuatro pasos). Operación de eliminación: Lo único que hay que tener en cuenta a la hora de diseñar un algoritmo para esta operación es la utilización eficiente de la memoria, de forma que el espacio ocupado por el nodo borrado vuelva a estar disponible para el sistema. 64 Manual de Estructura de Datos
- 66. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Algoritmo Desapilar Salida x: T Variable p: puntero a Nodo_pila Inicio si Pila_vacia entonces "Error: pila vacia" sino p <-- cima x <-- p^.informacion cima <-- p^.enlace liberar_espacio(p) fin_sino Fin La solución dada se puede extender a "m" pilas, de hecho como los enlaces entre elementos son establecidos por el programador, no por el método de representación, es como si las pilas siempre compartiesen espacios diferentes, no interfieren unas con otras. Se trata de una solución conceptual y computacionalmente simple. No existe necesidad de desplazar unas pilas para proporcionar más espacio a otras. El incremento de espacio de almacenamiento que implica la representación enlazada se ve compensada por la capacidad de representación de listas complejas de una forma simple y por la disminución del tiempo de cómputo asociado a la manipulación de listas, respecto a la representación secuencial. Colas enlazadas Análogamente al desarrollo hecho para las pilas se puede pasar a definir las operaciones requeridas para especificar una cola de forma enlazada. Crear cola: Declaramos los tipos de datos necesarios para representar un nodo e inicializamos la cola como vacia. (1) Declaraciones: Nodo_cola: registro (informacion: T, enlace: puntero a Nodo_cola) inicio, final: puntero a Nodo_cola (2)Asignación de cola vacía inicio <-- NULO final <-- NULO Comprobar si la cola está vacía: De nuevo, la estructura estará vacía si y sólo si el puntero inicio no hace referencia a ningún nodo de la cola. si inicio = NULO entonces devolver(cierto) sino devolver(falso) Acceso al primer elemento de la cola: ESTRUCTURADE DATOS I -- FCI Se puede acceder a este elemento de la cola mediante el puntero inicio que lo referencia. Operación de inserción: Algoritmo InsertarCola Entrada x: T Variable Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 65
- 67. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas p: puntero a Nodo_cola Inicio p <-- crear_espacio p^.informacion <-- x p^.enlace <-- nulo si Cola_vacia entonces inicio <-- p sino final^.enlace <-- p final <-- p Fin Operación de borrado: Algoritmo BorrarCola Salida x: T Variable p: puntero a Nodo_cola Inicio si Cola_vacia entonces "Error: cola vacia." sino p <-- inicio inicio <-- p^.enlace (* si tras borrar se vacia la cola, hay que poner final a nulo *) si Cola_vacia entonces final <-- NULO x <-- p^.informacion liberar_espacio(p) fin_sino Fin Listas Múltiplemente Enlazadas Este tipo de listas contiene más de dos enlaces por nodo, los que tienen la posibilidad de apuntar a más de dos listas enlazadas. Vista gráfica de un nodo p ESTRUCTURA DE DATOS I -- FCI p Dato p p 66 Manual de Estructura de Datos
- 68. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas RECURSIVIDAD El c onc e pt o d e r ec ur siv ida d va l iga do a l de r e pet ic ió n. S on re curs i vos a q ue ll o s alg o ritm os q ue , esta nd o enc a psu lad os de nt ro de un a fu nci ón, s on l la mados d esd e el la misma una y ot ra v ez, en c ont r ap os ici ón a l os alg o ritm os it e rati v os, qu e h ac en uso d e bucl es wh il e, d o- wh il e, fo r, etc. Características. Un alg o ritm o r ecu rsi v o const a de un a pa rte r ecu rs iv a, otr a it e rati v a o n o r ec urs i va y una c ond ici ó n d e t e r min aci ón. La pa rt e r e curs i va y l a c o ndic ió n d e t e rmi nac i ón siem p r e e xist e n. E n ca mbio la pa rt e n o r ec ur siv a p u ede c o inc idi r c o n la c on dic ió n de ter mi nac ió n. Al go mu y i mp o rta nte a te ne r en c u enta cu and o us em os l a r ec ur siv ida d es q ue e s nec esa r io as egu r ar n os q ue l le ga un m om en to en q ue n o h ace mo s más l la mad as r ecu rsi v as. Si n o se cu mp le esta co nd ici ón e l p ro gr ama n o pa ra rá n u nca. Ventajas e inconvenientes. La p r inc i pal v ent aj a es la sim p lic ida d de com p r ensi ó n y s u g ra n p ot en cia, f a vo r eci e ndo la r es ol uci ón d e p r obl emas d e man e ra n atu r al, se nci ll a y e l ega nt e ; y faci li dad pa ra com p rob a r y c on v enc e r se d e qu e la s ol uc ió n d el p r obl em a es co r r ecta . El p rin ci pa l inc on v e ni e nte es l a i n efi ci enc ia t ant o en t i em po co mo en me mo r ia, dad o qu e p ar a p erm iti r s u uso es nec es ar io tr an sfo rma r el pr og ra ma r ecu rs iv o en ot r o ite rat i vo, qu e ut il iz a Bu cles y p il as pa ra a lmac en ar las va ri abl es. Vent ajas : efic i ent es y r áp id os. Inco n v eni e ntes : P ar a cada el em ent o de la lista s e deb e res e r va r un es pac i o p ar a pu nt er os lo q u e sig ni fic a u n d esa p ro v ech ami e n to d e m em or ia e n e l "m an ej o d e l ista ". Zona de Overflow. Se r es e r va es pac io e n cie rt a z on a d e ext e rn a a la p r o pi a tab la, de a p ro x imad am ent e el 10% de su ta ma ño, pa ra i nt rod uc ir l as co lis i on es. C ada si n óni mo s e alm ac en a en la p rim e ra ce lda dis p on ibl e d e l a zo na de o v er fl o w. Inco n v eni e nte : Des ap r ov ec ham ie nt o de m em or ia ( poc o ). Es p oc o e f ici ent e cu and o se han p r odu cid o c ol isi on es, ya qu e l a bús q u eda en la z on a d e o ve rf l ow es s ecu e nci al. Vent ajas : O cu pa m e no s mem or ia q ue el an ter i or . E l a lg or itm o d e bús q ue da y d e ins er ci ón es m ás s enc il lo. ESTRUCTURADE DATOS I -- FCI Almacenamiento interno Cua nd o e l esp aci o us a do pa ra a lm ace na r las col isi on es esta d ent r o de l os l ímit es d e l a tabla . Dent r o de l a lmac en am i ent o int e rn o est án: E n cade na mi ent o di r ecto y e nca de nam i ent o vac í o. Encadenamiento directo. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 67
- 69. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Se usa de nt ro d e la t abla un c am p o de t i p o p unt e r o p a ra qu é a pu nt e al s ig ui ent e col isi on ad o, qu e esta r á de nt ro de la t abl a. En es e c am po s e g ua r da l a di r ecc ió n d el sigu ie nt e c olis i ona do. En e l e nca de nam i ent o dir ect o c on zo na d e ov e rf lo w p ode mos s o br edim e nsi on ar la tabla pa ra al mac en a r l as c ol isi on es, e n esta z on a l as c asi ll as esta rá n enc ad en adas con un a v ar iab l e qu e a pu nt e al p rim e r esp aci o li br e d e l a z on a d e o v er fl ow . C ons iste en en la za r to dos los el em ent os cu y as cla v es gen e ra n i gua l Ín dic e pr ima ri o po r m ed i o de en lac es d e ntr o d e la tabl a a las nu e vas p os ici on es ocu p adas p o r e stos e l em ent os. Inco n v eni e ntes : Es pac i o res e r vad o en cad a el em ent o pa ra e l en lac e. Vent ajas : Más rá p ido qu e el e xt er n o co n zo na d e o ve rf l ow y a qu e e vit a l a bús q ue da secu e nci al. Oc up aci ó n de me mo ri a: D ep e nd e d el m ét o do us ad o. El p ri me r caso ocu p a m en os mem or ia , y e l s eg und o es más r á pid o. Forma de Interpretación Al go es r ecu rs iv o si se defi n e en t ér mi nos d e sí mism o (c ua nd o p ar a def in i rse h ac e men ci ón a s í mism o ). Pa r a q ue un a de fi nic ió n r ecu rs i va se a v ál ida , la r ef e r enc ia a sí misma deb e s e r re lat i v ame nte más s e nci ll a qu e el c aso co nsi de ra do . Ej em p lo: d efi nic i ón d e n° n atu ra l: -> El N ° 0 es natu r al -> El N ° n es nat ur al s i n-1 lo es. En u n a lg or itm o rec u rsi vo dist in gui mos com o mín imo 2 pa rt es: Cas o t ri vi al, bas e o d e fin de r ec urs i ón: Es u n cas o d on de e l p r obl em a p u ede r es ol v er se si n te n er q ue hac e r uso d e u na nu e v a lla mad a a s í m ismo . E vi ta la co nti nu aci ón i nd e fin id a de l as pa rtes r ec urs i vas. b). P art e p ur am ent e re curs i va: Re lac io na el res ult ado del a lg or itm o co n r es ulta dos d e cas os más simp l es. S e ha ce n nu e vas ll amad as a la f unc ió n, p er o está n m ás p ró x imas al cas o bas e. EJEMPLO ITERATIVO: Int F act or ia l ( i nt n ) { int i , r es=l; ESTRUCTURA DE DATOS I -- FCI fo r ( i = l; i<= n; i++ ) r es = r es* i; ret ur n ( res ) ; } RECURSIVO: int Fact o ri al ( int n ) { if (n = = 0 ) r etu rn (1 ); r etu rn ( n* Fact o ria l (n -1 ) ) ; } 68 Manual de Estructura de Datos
- 70. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas TIPOS DE RECURSION Recursividad simple: A qu e ll a e n cu y a d efi ni ció n só lo a pa r ec e un a lla mad a r ec u rsi va. S e pu ed e t ra nsf or ma r con fac il ida d e n alg o rit mos it e rat i vos. Recursividad múltiple: Se d a cua nd o ha y más de una l lam ada a sí misma d ent r o de l cue r po d e la f unc ió n, r esult an do más d if íci l d e h ace r de f orm a ite rat iv a. int Fib ( i nt n ) /* e j : Fi bo nacc i */ { if (n< =l ) r etu rn ( 1 ) ; r etu r n (F ib (n- 1) + Fib ( n-2 ) ); } Rec u rsi vi dad an ida da: En a lgu n os d e los a rg. de la l lam ada r ec u rsi va ha y un a nu e va lla mad a a s í m isma. int Ack ( int n, int m ) / * e j : Ack e rma n */ { if (n = = 0 ) r etu r n (m+1 ); els e if (m= = 0 ) ret ur n ( Ack ( n-1 , 1 ) ); r etu rn ( Ack ( n-1 , Ack ( n,m- l) ) ) ; } • R ec urs i vid ad c r uz ada o ind i rect a: S on al go ritm os d o nde u na fu nci ón p r o voc a u na lla mad a a s í m isma de fo rma in di r ecta, a t ra v é s de ot ras fu nci on es. E j : P ar o Im pa r: int p a r ( i nt n um p ) { if (n um p= = 0) r et u rn ( l) ; r etu rn ( im pa r ( nu mp-1 ) ) ; int im pa r ( i nt num i ) { if (n umi= =0 ) ret ur n (0 ); r etu rn ( p ar ( nu mi- 1) ) ; } ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 69
- 71. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas LA PILA DE RECURSION La m em or ia d el o rd en a do r s e d i vid e (d e ma ne ra l ógi ca, n o f ísic a ) en va r ios seg me ntos (4 ): Se gm ent o de c ód igo : Pa rt e de la m emo r ia don de s e gu ar dan las instr ucc io n es de l p ro gr ama e n c od. Má q u ina . Se gm ent o d e dat os: Pa rt e d e la m em or ia dest in ada a al mac e na r las v ar iab l es estát icas. Mo ntí cu lo: P a rte de la mem or ia dest in ada a la s va r iab les di nám icas. Pi la d el p r og ram a: P art e d esti na da a las v ar ia bles l oca l es y p a rám et ros d e la fu nci ón qu e está si end o ej ec ut ada. Llam ada a u na fu nci ó n: • Se res e r va es pac i o e n la pi la pa ra los p ar ámet r os d e la f unc ió n y sus va r iab les loc al es. • S e gua rd a en la p il a la di r ecc ió n d e la lí n ea de cód ig o d esd e d o nde se ha ll ama do a la fu nc ió n. • S e alm ac ena n los p ar ámet r os d e la fu nci ó n y sus v al o res e n l a pi la. • Al t e rmi na r l a fu n ció n, s e li be ra la m em or ia asig nad a en l a pi l a y s e vu el v e a la inst ruc . Actu al. Llam ada a u na fu nci ó n r ecu rsi v a: En e l cas o r ecu rs i vo, cada lla mad a ge n er a u n nu e vo ej em p la r d e l a fu nci ón c on s us co rr es p ond ie nt es o bj et os l oca l es: • La f unc ió n s e e jec uta rá n o rma lm ent e hast a la ll ama da a sí m isma. En es e mom ent o s e c r ean e n l a p il a n u ev os p ar ám etr os y va ri abl es lo cal es. • El nu e vo e je mp la r de f un ci ón c om ie n za a ej ecut a rse . • Se c re an más co p ias hast a ll ega r a l os cas os b ases , d ond e se res ue l ve dir ect am ent e el va l or, y s e va sa li e ndo li be r and o m emo r ia hasta ll ega r a l a pr im er a lla mad a (ú ltim a e n c e r r ars e ) EJ E RC ICI O S a). To r r es de Ha no i: P rob l ema d e sol uc ió n rec u rsi va, c ons iste e n mo ve r to dos l os discos ( de dif e r ent es tamañ os ) d e u na ag uj a a otr a, us an do un a agu ja au xi lia r, y sabi end o qu e u n di sco n o pu ed e esta r s ob r e otr o m en o r qu e ést e. /* S ol uc ió n: 1- M o v er n-1 disc os d e A a B A B C 2- M o v er 1 d isco de A a C 3- M o v er n-1 disc os d e B a C */ vo id H an oi ( n, i ni cia l, a ux, fi na l ) { if ( n> 0 ) { Ha no i (n- 1, i nic ia l, f in al , au x ); p ri ntf (" M o ve r %d d e %c a %c ", n, in ici al, fi na l ) ; Ha no i (n -1, a u x, i ni cia l, fin al ); b). Ca lcu la r e le v ad o a n d e f o rma r ec urs i va: ESTRUCTURA DE DATOS I -- FCI flo at x el e vn ( fl oat b as e, int e x p ) { if (e x p == O ) r etu rn (1 ); r etu rn ( b as e*x e le v n (b ase, e x p-1 )) ; c). M ult ip lic a r 2 n°s c o n sum as suc es iv as r ec urs: int m ult i ( i nt a, i nt b ) { if (b == O ) r etu r n (0) ; re tur n ( a + mu lti (a , b-1 ) ); d). ¿ Qu é h ac e este p r o gra ma ?: vo id c os a ( ch ar *ca d, i nt i ) if ( ca d[ i ] '= ' O ' ) cosa (c ad,i +1 ); 70 Manual de Estructura de Datos
- 72. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas p ri ntf (" %c ", ca d[ i ] ); ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 71
- 73. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Árboles Fundamentos y terminología básica Hasta ahora hemos visto estructuras de datos lineales, es decir, los datos estaban estructurados en forma de secuencia. Sin embargo, las relaciones entre los objetos no siempre son tan simples como para ser representadas mediante secuencias (incluso, en muchas ocasiones, es conveniente que no sea así), sino que la complejidad de las relaciones entre los elementos puede requerir otro tipo de estructura. En esas situaciones se pasaría a tener estructuras de datos no lineales. Este es el caso de la estructura de datos conocida como árbol. Un árbol es una estructura no lineal en la que cada nodo puede apuntar a uno o varios nodos. También suele dar una definición recursiva: un arbol es una estructura compuesta por un dato y varios arboles. Los árboles establecen una estructura jerárquica entre los objetos. Los árboles genealógicos y los organigramas son ejemplos comunes de árboles. Un árbol es una colección de elementos llamados nodos, uno de los cuales se distingue del resto como raíz, junto con una relación que impone una estructura jerárquica entre los nodos. Formalmente, un árbol se puede definir de manera recursiva como sigue: Definición: una estructura de árbol con tipo base T es: • (i) Bien la estructura vacía. • (ii) Un conjunto finito de uno o más nodos, tal que existe un nodo especial, llamado nodo raiz, y donde los restantes nodos están separados en n >= 0 conjuntos disjuntos, cada uno de los cuales es a su vez un árbol (llamados subárboles del nodo raíz). La definición implica que cada nodo del árbol es raíz de algún subárbol contenido en el árbol principal. El índice de un libro es un buen ejemplo de representación en forma de árbol. Ejemplos de estructuras arborescentes: Antes de continuar avanzando en las características y propiedades de los árboles, veamos algunos términos importantes asociados con el concepto de árbol: • Grado de un nodo: es el número de subárboles que tienen como raíz ese nodo (cuelgan del nodo). • Nodo terminal u hoja: nodo con grado 0. No tiene subárboles. • Grado de un árbol: grado máximo de los nodos de un árbol. • Hijos de un nodo: nodos que dependen directamente de ese nodo, es decir, las raíces de sus subárboles. ESTRUCTURA DE DATOS I -- FCI • Padre de un nodo: antecesor directo de un nodo del cual depende directamente. • Nodos hermanos: nodos hijos del mismo nodo padre. • Camino: sucesión de nodos del árbol: n(1), n(2), .. n(k), tal que n(i) es el padre de n(i+1). • Antecesores de un nodo: todos los nodos en el camino desde la raíz del árbol hasta ese nodo. • Nivel de un nodo: longitud del camino desde la raíz hasta el nodo. El nodo raíz tiene nivel 1. • Altura o profundidad de un árbol: nivel máximo de un nodo en un árbol. • Longitud de camino de un árbol: suma de las longitudes de los caminos a todos sus componentes. • Bosque: conjunto de n >= 0 árboles disjuntos. 72 Manual de Estructura de Datos
- 74. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas La representación de un árbol general dependerá de su grado, es decir, del número de relaciones máximo que puede tener un nodo del árbol. Resulta más simple la representación y manipulación de una estructura árbol cuando el grado de éste es fijo e invariable. Por esa razón, para introducir los aspectos más concretos de la manipulación de árboles nos vamos a centrar en un tipo particular de los mismos, los llamados árboles binarios o de grado dos. Árboles binarios Los árboles binarios constituyen un tipo particular de árboles de gran aplicación. Estos árboles se caracterizan porque no existen nodos con grado mayor a dos, es decir, un nodo tendrá como máximo dos subárboles. Definición: un árbol binario es un conjunto finito de nodos que puede estar vacío o consistir en un nodo raíz y dos árboles binarios disjuntos, llamados subárbol izquierdo y subárbol derecho. En general, en un árbol no se distingue entre los subárboles de un nodo, mientras que en un árbol binario se suele utilizar la nomenclatura subárbol izquierdo y derecho para identificar los dos posibles subárboles de un nodo determinado. De forma que, aunque dos árboles tengan el mismo número de nodos, puede que no sean iguales si la disposición de esos nodos no es la misma: Antes de pasar a la representación de los árboles binarios, vamos a hacer algunas observaciones relevantes acerca del número y características de los nodos en este tipo de árboles. • Lema 1: el número máximo de nodos en el nivel i de un árbol binario es 2^(i-1), con i >= 1, y el número máximo de nodos en un árbol binario de altura k es (2^k) - 1, con k >= 1. • Lema 2: para cualquier árbol binario no vacío, si m es el número de nodos terminales y n es el número de nodos de grado dos, entonces se cumple que m = n + 1. Igualmente, para poder entender alguna de las formas de representación de los árboles binarios, vamos a introducir dos nuevos conceptos, lo que se entiende por árbol binario lleno y por árbol binario completo. Definición: se dice que un árbol binario está lleno si es un árbol binario de profundidad k que tiene (2^k) - 1 nodos. Un árbol binario lleno es aquel que contiene el número máximo de posibles nodos. Como en estos casos no existen subárboles vacíos excepto para los nodos terminales, es posible realizar una representación secuencial eficiente de este tipo de árboles. Esta representación suele implicar la numeración de los nodos. La numeración se realiza por niveles y de izquierda a derecha. Este proceso de numeración ESTRUCTURADE DATOS I -- FCI (etiquetado) de los nodos permite una identificación elegante de las relaciones de parentesco entre los nodos del árbol y se verá más adelante. Definición(1): Los ár bol es d e gr ad o 2 tie n e n un a es p eci al im p o rta nci a. S e l es co no ce con el n omb r e de á rb ol es bin a ri os. S e de fi ne un á rb ol bi na ri o co mo un co nj unt o fi nit o de el em ent os (n od os ) q ue b i en está va ci ó o es tá fo rm ad o po r u na r aí z co n d os á rb ol es bina r ios dis ju ntos, l lam ados s ubá rb ol i z qu ie rd o y d e rec ho d e l a raí z. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 73
- 75. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Definición (2): un árbol binario con n nodos y profundidad k se dice que es completo si y sólo si sus nodos se corresponden con los nodos numerados de 1 a n en el árbol binario lleno de profundidad k. Cuando un árbol no es lleno pero es completo, también es posible la representación secuencial eficiente de la estructura de nodos que lo componen. En l os a p art ad os qu e sigu en se co nsid e ra rá n ú nic am e nt e á rb ol es bina r ios y , po r l o tanto , s e ut il iz ar á l a p alab r a á rb ol p ar a r ef er i rs e a ár bo l bi na r io. Los árb o les de g rad o sup e ri o r a 2 re cib en e l nomb r e d e árb o les mu l ticam in o. Á rb ol b in ar io de bús q ued a.- L os á rb o les b i na ri os s e ut ili z an f r e cue nt eme nt e pa ra r ep r es enta r co nj unt os de d atos cu y os e l em en tos se id ent if ica n po r u na c la v e ú nic a. Si el á rbo l está o rga ni za d o d e ta l m an e ra q ue la cla v e d e c ada n odo es ma yo r q ue tod as las c la v es s u sub á rbo l i z qu ie rd o, y me n or qu e todas las cl a ves d el s u bárb o l d e rec ho se dic e qu e este á rb ol es un árb o l bi na ri o d e b ús qu ed a. Ej em p lo: Representación de los árboles binarios Como hemos visto, si el árbol binario que se desea representar cumpla las condiciones de árbol lleno o árbol completo, es posible encontrar una buena representación secuencial del mismo. En esos casos, los nodos pueden ser almacenados en un array unidimensional, A, de manera que el nodo numerado como i se almacena en A[i]. Esto permite localizar fácilmente las posiciones de los nodos padre, hizo izquierdo e hijo derecho de cualquier nodo i en un árbol binario arbitrario que cumpla tales condiciones. • Lema 3: si un árbol binario completo con n nodos se representa secuencialmente, se cumple que para cualquier nodo con índice i, entre 1 y n, se tiene que: • (1) El padre del nodo i estará localizado en la posición [i div 2] • si i <> 1. Si i=1, se trata del nodo raíz y no tiene padre. • • (2) El hijo izquierdo del nodo estará localizado en la posición [2i] • si 2i <= n. Si 2i>n, el nodo no tiene hijo izquierdo. • • (3) El hijo derecho del nodo estará localizado en la posición [2i+1] si • 2i+1 <= n. Si (2i+1) > n, el nodo no tiene hijo derecho. Evidentemente, la representación puramente secuencial de un árbol se podría extender inmediatamente a ESTRUCTURA DE DATOS I -- FCI cualquier árbol binario, pero esto implicaría, en la mayoría de los casos, desaprovechar gran cantidad del espacio reservado en memoria para el array. Así, aunque para árboles binarios completos la representación es ideal y no se desaprovecha espacio, en el peor de los casos para un árbol lineal (una lista) de profundidad k, se necesitaría espacio para representar (2^k) - 1 nodos, y sólo k de esas posiciones estarían realmente ocupadas. Además de los problemas de eficiencia desde el punto de vista del almacenamiento en memoria, hay que tener en cuenta los problemas generales de manipulación de estructuras secuenciales. Las operaciones de inserción y borrado de elementos en cualquier posición del array implican necesariamente el movimiento potencial de muchos nodos. Estos problemas se pueden solventar adecuadamente mediante la utilización de una representación enlazada de los nodos. 74 Manual de Estructura de Datos
- 76. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Representación enlazada Se podría simular una estructura de enlaces, como la utilizada para las listas, mediante un array. En ese caso, los campos de enlace de unos nodos con otros no serían más que índices dentro del rango válido definido para el array. La estructura de esa representación enlazada pero ubicada secuencialmente en la memoria correspondería al siguiente esquema para cada nodo: donde el campo informacion guarda toda la información asociada con el nodo y los campos hijo izquierdo e hijo derecho guardan la posición dentro del array donde se almacenan los respectivos hijos del nodo. Ejemplo: Los problemas de esta representación están asociados con la manipulación de la misma. En el caso de la inserción de nuevos nodos, el único problema que puede aparecer es que se supere el espacio reservado para el array, en cuyo caso no se podrán insertar más nodos. Sin embargo, la operación de borrado implica ESTRUCTURADE DATOS I -- FCI mayores problemas de manipulación. Al poder borrar cualquier nodo del árbol, se van a dejar "huecos" en la estructura secuencial del array, esto se podría solucionar, como siempre, mediante el desplazamiento de elementos dentro del vector. Sin embargo, si de por sí esa operación no resulta recomendable, en este caso mucho menos, ya que implica a su vez modificar los enlaces que hayan podido variar con el desplazamiento. Otra solución, podría consistir en almacenar las posiciones del array que están libres y que se pueden ocupar en la inserción de nodos. Esto podría resultar más eficiente, pues no implica el desplazamiento de información, pero requiere de la utilización de otra estructura de datos auxiliar que maneje esa información. La mejor solución, de nuevo, para evitar los problemas asociados con la manipulación de arrays, es la representación de los árboles binarios mediante estructuras dinámicas "puras", en el sentido de la Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 75
- 77. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas creación en tiempo de ejecución de los nodos que sean necesarios (no más) y la utilización de punteros para enlazar estos nodos. La estructura de cada nodo en esta representación coincide con la estructura de tres campos vista anteriormente. La única diferencia reside en la naturaleza de los campos de enlace, en este caso se trata de punteros y no de índices de un array. La implementación, sería: #inc lu de <co ni o.h > #inc lu de <stdi o.h > #inc lu de <stdl ib.h > ty pe de f st ruct n odo { int d ato; struct n od o *i z q; struct n od o *d e r; }n od oa rb ol ; Se puede comprobar como la representación en memoria de la estructura, en cuanto a definición de tipos de datos, coincide exactamente con la de, por ejemplo, una lista doblemente ligada, sin que ello implique que se esté hablando de la misma estructura de datos. De nuevo hay que dejar muy claro que es la interpretación que hacemos de la representación en memoria la que define una estructura de datos, no la representación en sí misma. Nodo Dato *izq *der La representación enlazada tiene como principal desventaja que no resulta inmediato la determinación del padre de un nodo. Es necesario buscar el camino de acceso al nodo dentro del árbol para poder obtener esa información. Sin embargo, en la mayoría de las aplicaciones es la representación más adecuada. En el caso en que la determinación del padre de un nodo sea una operación importante y frecuente en una aplicación concreta, se puede modificar ligeramente la estructura de cada nodo añadiendo un cuarto campo, también de tipo enlace, que guarde la posición del padre de cada nodo. Al igual que en la representación enlazada de las listas, es necesario mantener un puntero al primer elemento de la estructura, en este caso el nodo raíz del árbol, que permita acceder a la misma. Insertar Nodos vo id ins e rta r (n od oa rb ol **r ai z, int ind ic e ) Función {// p ro ces o d e ins e rta r el e lem e nto e n el ar bo l if (* ra iz= =N ULL ){ recursiva *r ai z= (n od oa rb ol *) m all oc (si z eo f (n odo a rbo l ) ) ; (* ra iz )- >dat o= ind ic e; (* ra iz )- >i z q=N ULL; (* ra iz )- >d er =NU LL; ESTRUCTURA DE DATOS I -- FCI } e lse // r ec o rr e a la i z qu ie rd a if (i ndi ce< (* r ai z) ->dat o )i nse rt ar ( & (* ra iz )-> iz q, in dic e ); Els e // r ec o rr e a la d e r echa if ( ind ic e> (* r aiz )- >dat o )i nse rt ar ( & (* ra iz )-> de r, in dic e ); e lse {( p r intf ( "n No s e pu ed e i ns ert a r i ndi ce du pl icad o n n" ) ); g etch ( ); } } 76 Manual de Estructura de Datos
- 78. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Grafica un Arbol vo id Gmu est ra A BJ ( nod o arb ol * p, i nt ni v el, int c ol, int p os, int i ) { s etli n est yl e (0,1, 0) ; if ( ! P ) ) { Gmu estr a AB J ( p->i z qu i e rda ,n iv e l+1,c ol - pos/ 2, p os/2,c ol ); s[0 ]= p->d ato ; setco l or (4 ); lin e (i ,( ni v el -1 )*45, co l,n iv e l*45 ) ; cir cl e (co l, ni v el*4 5,10 ); setco l or (1 0) ; outt ext x y (c ol-5 ,n iv e l*4 5-5,s ); Gmu estr a AB J ( p->d e re c ha,n i ve l+1 ,co l + p os/2, p os/2,c ol ); s etl in est yl e (0, 1,0 ) ; } } Operaciones básicas Un a ta r ea mu y co mún a re al iz ar c on un á rb ol es ej ec uta r un a d et er min ada o p er aci ó n con cad a un o d e los e l em ent os d el á rb ol. Est a o p e rac ió n s e c ons id e ra e nto nc es c om o un pa rám et r o de una t ar é más g e ne r al qu e e s la v isit a de t od os l os nod os o, c om o se den om in a us ua lme nt e, del r ec o r rid o d el á rb ol. Si s e c onsi de r a la t ar e a com o u n pr oc eso s ec ue nci al, ent o nces los n odos in di vi dua l es se visit an e n u n o rd en es pec íf ico , y p u ed en c ons id er a rse c om o o r ga ni zad os s egú n u na estr uct ur a l in ea l. D e h ech o, s e sim p li fic a co n side r abl em ent e la d esc ri pc ió n d e mu ch os alg o ritm os si p u ed e ha bla rs e de l p r oces o d el sigu ie nt e el em ent o e n el á rb ol, s eg ún u n cie rt o or de n sub y ac ent e. Recorrido de árboles binarios Ha y d os f o rmas bás ic as d e r ec or r e r un á rb ol: El r eco r ri do en am pl itud y el r eco r ri do e n p r of un dida d. Rec o r rid o e n am pl itud. - Es a qu el r eco r ri do q ue rec o r re el árb ol p o r ni v el es, en e l últ imo e je mp l o se r ía: 12 - 8, 17 - 5 ,9,15 Rec o r rid o e n p r of und id ad.- R ec or r e el á rb ol p or s ubá rb ol es. Ha y t res fo rmas: P r eo rd en , ESTRUCTURADE DATOS I -- FCI In o rd e n y post o rd en. P re o rd en: Ra i z, sub á rb ol iz q ui e rd o y sub á rbo l de re ch o. In O rde n: S uba rb ol iz q u ie rd o, ra iz , sub á rbo l d e r ech o. P osto rd en : Suba rb o l i z qu i er do, sub arb o l d er e cho, r ai z. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 77
- 79. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Ej em p lo: P re o rd en: 20 - 12 - 5 - 2 - 7 - 13 - 15 - 40 - 30 - 35 - 47 In O rd en: 2 - 5 - 7 - 12 - 13 - 15 - 20 - 30 - 35 - 40 - 47 P osto rd en : 2 - 7 - 5 - 15 - 13 - 12 - 35 - 30 - 47 - 40 - 20 Ej em p lo: P re o rd en: / + a b * c d O rd en I n O rd en: a + b / c * d P osto rd en : a b + c d * / Si se desea manipular la información contenida en un árbol, lo primero que hay que saber es cómo se puede recorrer ese árbol, de manera que se acceda a todos los nodos del mismo solamente una vez. El recorrido completo de un árbol produce un orden lineal en la información del árbol. Este orden puede ser útil en determinadas ocasiones. Cuando se recorre un árbol se desea tratar cada nodo y cada subárbol de la misma manera. Existen entonces seis posibles formas de recorrer un árbol binario. • (1) nodo - subárbol izquierdo - subárbol derecho • (2) subárbol izquierdo - nodo - subárbol derecho • (3) subárbol izquierdo - subárbol derecho - nodo • (4) nodo - subárbol derecho - subárbol izquierdo • (5) subárbol derecho - nodo - subárbol izquierdo • (6) subárbol derecho - subárbol izquierdo - nodo Si se adopta el convenio de que, por razones de simetría, siempre se recorrera antes el subárbol izquierdo que el derecho, entonces tenemos solamente tres tipos de recorrido de un árbol, los tres primeros en la lista anterior. Estos recorridos, atendiendo a la posición en que se procesa la información del nodo, reciben, respectivamente, el nombre de recorrido prefijo, infijo y posfijo y dan lugar a algoritmos eminentemente recursivos: ESTRUCTURA DE DATOS I -- FCI Algoritmo Prefijo (Pre Orden) void preorder(NODOARBOL *cabeza){ if(cabeza!=NULL){ printf("%d ", cabeza->dato); preorder(cabeza->izq); preorder(cabeza->der); } } 78 Manual de Estructura de Datos
- 80. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Algoritmo Infijo (in Orden) void inorder(NODOARBOL *cabeza){ if(cabeza!=NULL){ inorder(cabeza->izq); printf("%d ",cabeza->dato); inorder(cabeza->der); } } Algoritmo Posfijo void postorder(NODOARBOL *cabeza){ if(cabeza!=NULL){ postorder(cabeza->izq); postorder(cabeza->der); printf("%d ",cabeza->dato); } } Ejemplo de recorrido de un árbol: ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 79
- 81. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Operaciones con árboles binarios La primera operación a considerar sobre árboles binarios será su generación. En este caso, no vamos a entrar a considerar todos los casos que pueden aparecer al insertar un nuevo nodo en un árbol, la problemática puede ser amplia y el proceso de generación de un árbol dependerá de las reglas impuestas por una aplicación particular. Vamos a ver, sin embargo, algún ejemplo concreto que permita ilustrar esta operación. Al manipular la estructura árbol, la situación más habitual es que el problema imponga una serie de reglas para la construcción del árbol en función de los datos de entrada. Estos datos, en principio, serán desconocidos antes de la ejecución del programa. El procedimiento de generación del árbol deberá, por tanto, reproducir de la manera más eficiente posible esas reglas de generación. Ejemplo 1: Supongamos que se desea generar en memoria una estructura de árbol binario con unos datos cuyas relaciones se conocen previamente. Es decir, el usuario va a trasladar al ordenador una estructura de árbol conocida. Para hacer esto, se establece una notación secuencial que permita la interpretación simple de las relaciones. Ésta notación es similar a la representación secuencial que se comentó para árboles binarios completos, y que se extendió a cualquier árbol arbitrario. La notación consiste en una secuencia de caracteres que indica la información de cada nodo en el árbol completo asociado, de manera que se indica también si algún subárbol está vacío y se supone que la información del subárbol izquierdo va siempre antes que la del subárbol derecho. En realidad se trata de una representación secuencial del recorrido prefijo del árbol. Se considerará, para simplificar, que la información asociada con cada nodo es simplemente un carácter y que los subárboles vacíos se representan con un '.'. Entonces la entrada al algoritmo de generación puede ser simplemente una cadena de caracteres, donde cada uno de ellos se interpreta como un nodo del árbol. En este caso, las reglas de generación del árbol binario a partir de su representación secuencial serían: (1) Leer carácter a carácter la secuencia de entrada. (2) Si el carácter que se lee es '.' no hay que crear ningún nodo, el subárbol está vacío. (3) Si se lee un carácter distinto de '.' entonces se crea un nuevo nodo con la información leída y se pasa a generar los subárboles izquierdo y derecho de ese nodo, según los mismos criterios y en ese mismo orden. Un algoritmo que implemente estas reglas de generación podría ser: Algoritmo Generar_Arbol Entrada p: arbol (por referencia) Inicio leer(caracter) si (caracter <> '.') entonces p <-- crear_espacio p^.info <-- caracter ESTRUCTURA DE DATOS I -- FCI Generar_Arbol(p^.Izq) Generar_Arbol(p^.Der) fin_si sino p <-- NULO Fin Se puede observar como la recursividad permite definir de una manera simple y elegante el proceso de generación. 80 Manual de Estructura de Datos
- 82. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Ejemplo 2: Generar el árbol binario de representación de una expresión aritmética. Para ello se realizan las siguientes consideraciones: (1) La entrada del programa deberá ser una expresión escrita en notación infija. (2) En las expresiones sólo se tendrán en cuenta los cuatro operadores binarios básicos: +, -, *, / y no se considerarán paréntesis. (3) Los operandos serán exclusivamente caracteres. La generación del árbol se facilita considerablemente si se traduce la expresión a notación posfija y se almacenan los elementos de la expresión en una pila, según el algoritmo que vimos en el tema 3. Algoritmo Generar_Arbol Entrada p: arbol (por referencia) pila: TipoPila Inicio si (NO Pila_vacia(pila)) entonces p <-- crear_espacio p^.info <-- Desapilar(pila) si (p^.info ES operador) entonces Generar_Arbol(p^.Der) Generar_Arbol(p^.Izq) fin_si sino p^.der <-- NULO p^.izq <-- NULO fin_sino fin_si Fin Ejemplo 3: función que se encarga de copiar un árbol. Algoritmo Copiar Entrada arb: arbol Variable p: arbol ESTRUCTURADE DATOS I -- FCI Inicio si (arb <> NULO) entonces p <-- crear_espacio p^.info <-- arb^.Info p^.Izq <-- Copiar(arb^.Izq) p^.Der <-- Copiar(arb^.Der) devolver(p) fin_si sino p <-- NULO Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 81
- 83. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas devolver(p) fin_sino Fin Ejemplo 4: función que mire si dos árboles son equivalentes. Algoritmo Equivalentes Entradas arb1, arb2: arbol Salida eq: (cierto, falso) Inicio eq <-- FALSO si (arb1 <> NULO) Y (arb2 <> NULO) entonces si (arb1^.Info = arb2^.Info) entonces eq <-- Equivalentes(arb1^.Izq, arb2^.Izq) Y Equivalentes(arb1^.Der, arb2^.Der) fin_si sino si (arb1 = NULO) Y (arb2 = NULO) entonces eq <-- CIERTO Fin Ejemplo 5: eliminación de nodos. El borrado de nodos es otra operación habitual de manipulación de árboles binarios. Hay que tener en cuenta que esta operación debe mantener la estructura del árbol y, por tanto, dependerá del orden que se haya establecido dentro del árbol. Esto hace que la eliminación de nodos se pueda convertir en una operación más compleja y que no se pueda hablar de un algoritmo general de borrado, más bien se podrá hablar de algoritmos para borrar nodos para un determinado orden dentro del árbol. Si por ejemplo, un árbol ha sido generado teniendo en cuenta que sus nodos están correctamente ordenados si se recorre el árbol en orden infijo, se debe considerar un algoritmo de borrado que no altere ese orden. La secuencia de orden a que da lugar el recorrido infijo se debe mantener al borrar cualquier nodo del árbol. Existen dos casos a considerar cuando se borra un nodo del árbol. El primer caso, el más simple, implica borrar un nodo que tenga al menos un subárbol vacío. El segundo caso, más complejo, aparece cuando se desea borrar un nodo cuyos dos subárboles son no vacíos. En este último caso, hay que tener en cuenta que el nodo borrado debe ser sustituido por otro nodo, de manera que se mantenga la estructura inicial del árbol. Cuando el nodo a borrar posee dos subárboles no vacíos, el proceso de reestructuración de las relaciones dentro del árbol resulta más complejo, ya que cuando el nodo es terminal, eliminar ese nodo es ESTRUCTURA DE DATOS I -- FCI tan simple como eliminar el enlace que le mantiene unido al árbol desde su nodo padre, y si el nodo posee un único subárbol no vacío, el nodo debe ser sustituido por su nodo hijo. Estas dos últimas situaciones no implican una reestructuración importante del árbol. Suponiendo que el árbol debe mantener el orden establecido entre los nodos por un recorrido particular del mismo, el problema es determinar qué nodo debe sustituir al nodo que se va a borrar. Si volvemos al ejemplo anterior, el orden establecido por el recorrido infijo del árbol sería: 82 Manual de Estructura de Datos
- 84. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas (In Orden) Si se desea borrar el nodo C, que tiene dos nodos hijos, el nodo que debería sustituirle sería el nodo G, ya que es su sucesor en el orden establecido por el recorrido infijo. En general, sea cuál sea el orden establecido entre los nodos, el sustituto de un nodo que se va a borrar deberá ser su sucesor en dicho orden. De esta manera se mantiene la estructura global del árbol. Los diferentes criterios de ordenación de los nodos van a dar lugar a distintos algoritmos para determinar el sucesor de un nodo, según el orden establecido, y para modificar los enlaces entre nodos. Hace falta especificar los algoritmos que permitirán encontrar el padre y el sucesor infijo de un nodo del árbol. Representación de árboles generales como árboles bi narios Vamos a ver en este apartado que cualquier árbol se puede representar como un árbol binario. Esto es importante porque resulta más complejo manipular nodos de grado variable (número variable de relaciones) que nodos de grado fijo. Una posibilidad evidente de fijar un límite en el número de relaciones sería seleccionar un número k de hijos para cada nodo, donde k es el grado máximo para un nodo del árbol. Sin embargo, esta solución desaprovecha mucho espacio de memoria. • Lema 4:para un árbol k-ario (es decir, de grado k) con n nodos, cada uno de tamaño fijo, el número de enlaces nulos en el árbol es (n * (k-1) + 1) de los (n*k) campos de tipo enlace existentes. Esto implica que para un árbol de grado 3, más de 2/3 de los enlaces serán nulos. Y la proporción de enlaces nulos se aproxima a 1 a medida que el grado del árbol aumenta. La importancia de poder utilizar árboles binarios para representar árboles generales reside en el hecho de que sólo la mitad de los enlaces son nulos, además de facilitar su manipulación. Para representar cualquier árbol por un árbol binario, vamos a hacer uso implícito de que el orden de los hijos de un nodo en un árbol general no es importante. La razón por la cual, para representar un árbol general, se necesitarían nodos con muchos enlaces es que, hemos pensado en una representación basada en la relación padre-hijo dentro del árbol, y un nodo puede tener un gran número de hijos. Sin embargo, se puede encontrar una forma de representación donde cada nodo sólo necesite tener dos relaciones, una que lo una con el hijo que tenga más a la izquierda y otra que ESTRUCTURADE DATOS I -- FCI lo una con el siguiente nodo hermano por la derecha. Estrictamente hablando, como el orden de los hijos en un árbol no es importante, cualquiera de los hijos de un nodo podría ser el hijo que está más a la izquierda, el nodo padre y cualquiera de los nodos hermanos podría ser el siguiente hermano por la derecha. Por lo tanto, la elección de estos nodos no dejará de ser, hasta cierto punto, arbitraria. Podemos basarnos para esta elección en la representación gráfica del árbol que se desea almacenar. Veamos el siguiente ejemplo, el árbol binario correspondiente al árbol de la figura se obtiene conectando juntos todos los hermanos de un nodo y eliminando los enlaces de un nodo con sus hijos, excepto el enlace con el hijo que tiene más a la izquierda. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 83
- 85. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Este tipo de representación se puede identificar con los árboles binarios que ya hemos visto, asociando el enlace izquierdo del árbol con el enlace al hijo de la izquierda y el enlace derecho con el enlace al nodo hermano. Se observa que de esta manera el nodo raíz nunca tendrá un subárbol derecho, ya que no tiene ningún hermano. Pero esto nos permite representar un bosque de árboles generales como un único árbol binario, obteniendo primero la transformación binaria de cada árbol y después uniendo todos los árboles binarios considerando que todos los nodos raíz son hermanos. Ver el ejemplo de la figura: ESTRUCTURA DE DATOS I -- FCI En todas estas representaciones de árbol general a árbol binario hay que tener en cuenta la interpretación que se deben hacer de las relaciones, no es lo mismo que un nodo esté a la izquierda o a la derecha de otro, ya que los enlaces izquierdos unen un nodo con su hijo mientras que los enlaces derechos unen dos nodos hermanos. De cualquier forma, teniendo en cuenta este aspecto, es posible aplicar los algoritmos de manipulación de árboles binarios que se han visto hasta ahora. De hecho, en todos estos algoritmos se diferenciaba claramente entre el tratamiento del subárbol izquierdo y el del subárbol derecho 84 Manual de Estructura de Datos
- 86. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas ANEXOS ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 85
- 87. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas MATRIZ #include<stdio.h> #include<iostream.h> #include<conio.h> #define fil 15 #define col 15 void ingresar(int matriz1[fil][col], int f1 ,int c1) { int i, j; for (i=1;i<=f1;i++) for(j=1;j<=c1;j++) { cout<<"ingrese valor para la posicion "<<i<<j<<" "; cin>>matriz1[i][j]; } } void imprimir(int matriz1[fil][col], int f1 ,int c1) {int i,j; for(i=1;i<=f1;i++) { for(j=1;j<=c1;j++) { cout<<matriz1[i][j]<<'t'; } cout<<endl; } } void limite(int &f,int &c) { do {cout<<"ingrese el limite de fila "; cin>>f; }while(f<0&&f>fil); do {cout<<"ingrese el limite columna "; cin>>c; }while(c<0&&c>col); } void restar(int matriz1[fil][col],int matriz2[fil][col],int mresta[fil][col],int f,int c) { int i,j; for(i=1;i<=f;i++) for(j=1;j<=c;j++) mresta[i][j]=matriz1[i][j]-matriz2[i][j]; } void sumar(int matriz1[fil][col],int matriz2[fil][col],int msuma[fil][col],int f,int c) { int i,j; for(i=1;i<=f;i++) ESTRUCTURA DE DATOS I -- FCI for(j=1;j<=c;j++) msuma[i][j]=matriz1[i][j]+matriz2[i][j]; } void multiplicar(int matriz1[fil][col],int matriz2[fil][col],int mat_pro[fil][col],int f,int f1,int c1) { int i,aux,j,k,produc,suma; for(i=1;i<=f;i++) { for(j=1;j<=c1;j++) { aux=0; 86 Manual de Estructura de Datos
- 88. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas for(k=1;k<=f1;k++) { produc=matriz1[i][k]*matriz2[k][j]; aux+=produc; } mat_pro[i][j]=aux; } } } void main () { clrscr(); int matriz1[fil][col],matriz2[fil][col]; int msuma[fil][col],mresta[fil][col]; int matmul[fil][col]; int f,c,f2,c2,opcion,llena=0; limite(f,c); limite(f2,c2); do { if(llena==1) { cout<<"MATRICES"; cout<<endl; imprimir(matriz1,f,c); cout<<endl; cout<<endl; imprimir(matriz2,f2,c2); getch(); } do { gotoxy(15,8);cout<<"1)INGRESE MATRICES "; gotoxy(15,9);cout<<"2)SUMA MATRICES "; gotoxy(15,10);cout<<"3)RESTA MATRICES"; gotoxy(15,11);cout<<"4)MULTIPLICA MATRICES"; gotoxy(15,12);cout<<"5)SALIR"; gotoxy(15,13);cout<<"Digite la opcion :"; gotoxy(30,14);cin>>opcion; }while(opcion<0||opcion>5); switch(opcion) { case 1: { clrscr(); limite(f,c); cout<<"Datos para la primera matriz"<<endl; ingresar(matriz1,f,c); limite(f2,c2); cout<<"Datos para la segunda matriz"<<endl; ESTRUCTURADE DATOS I -- FCI ingresar(matriz2,f2,c2); llena=1; getch(); clrscr(); break; } case 2: { clrscr(); if(f==f2&&c==c2) { Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 87
- 89. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas if(llena==1) {sumar(matriz1,matriz2,msuma,f,c); cout<<"Suma :"<<endl; imprimir(msuma,f,c); } else { cout<<"Datos para la primera matriz"<<endl; ingresar(matriz1,f,c); cout<<"Datos para la segunda matriz"<<endl; ingresar(matriz2,f2,c2); clrscr(); sumar(matriz1,matriz2,msuma,f,c); cout<<"Suma :"<<endl; imprimir(msuma,f,c); llena=1; } } else cout<<"No se pueden sumar"; getch(); clrscr(); break; } case 3: { clrscr(); if(f==f2&&c==c2) { if(llena==1) {restar(matriz1,matriz2,mresta,f,c); cout<<"Resta :"<<endl; imprimir(mresta,f,c); } else { cout<<"Datos para la primera matriz"<<endl; ingresar(matriz1,f,c); cout<<"Datos para la segunda matriz"<<endl; ingresar(matriz2,f2,c2); clrscr(); restar(matriz1,matriz2,mresta,f,c); cout<<"Resta:"<<endl; imprimir(mresta,f,c); llena=1; } } else cout<<"No se pueden restar"; ESTRUCTURA DE DATOS I -- FCI getch(); clrscr(); break; } case 4: { clrscr(); if(c==f2) {if(llena==1) { multiplicar(matriz1,matriz2,matmul,f,f2,c2); cout<<"Multiplicacion:"<<endl; 88 Manual de Estructura de Datos
- 90. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas imprimir(matmul,f,c2); } else { cout<<"Datos para la primera matriz"<<endl; ingresar(matriz1,f,c); cout<<"Datos para la segunda matriz"<<endl; ingresar(matriz2,f2,c2); clrscr(); multiplicar(matriz1,matriz2,matmul,f,f2,c2); cout<<"Multiplicacion:"<<endl; imprimir(matmul,f,c); llena=1; } } else cout<<"No se pueden multiplicar"; getch(); clrscr(); break; } case 5: break; } }while(opcion!=5); getch(); } ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 89
- 91. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas LISTA ABIERTA #include<conio.h> #include<stdio.h> #include<iostream.h> #include<stdlib.h> typedef struct nodo {int valor; struct nodo * siguiente; }tipoNodo; typedef tipoNodo * pNodo; typedef tipoNodo *Lista; // Funciones Prototipos int ListaVacia(Lista l); void Insertar(Lista *l,int v); void InsertarC(Lista *l,int v); void InsertarF(Lista *l,int v); void Borrar(Lista *l,int v); void BorrarLista(Lista *l); void MostrarLista(Lista l); void main() {clrscr(); Lista lista=NULL; pNodo p; InsertarF (&lista,20); InsertarF (&lista,10); InsertarF (&lista,40); InsertarF (&lista,30); MostrarLista(lista); getch();//sytem("PAUSE"); } int ListaVacia(Lista lista) {return(lista==NULL); } void Insertar(Lista *lista, int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->valor=v; if(ListaVacia(*lista)||(*lista)->valor>v){ nuevo->siguiente=*lista; *lista=nuevo; } else {anterior=*lista; while(anterior->siguiente && anterior->valor <=v) anterior=anterior->siguiente; nuevo->siguiente=anterior->siguiente; anterior->siguiente=nuevo; ESTRUCTURA DE DATOS I -- FCI } } void InsertarC(Lista *lista, int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->valor=v; nuevo->siguiente=*lista; *lista=nuevo; } void InsertarF(Lista *lista, int v) 90 Manual de Estructura de Datos
- 92. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->valor=v; if(ListaVacia(*lista)){ nuevo->siguiente=*lista; *lista=nuevo; } else {anterior=*lista; while(anterior->siguiente!=NULL) anterior=anterior->siguiente; anterior->siguiente=nuevo; nuevo->siguiente=NULL; } } void MostrarLista(Lista lista) {pNodo nodo=lista; if(ListaVacia(lista)) printf("Lista vacia n"); else{ while(nodo) { printf("%d-> ",nodo->valor); nodo=nodo->siguiente; } } } ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 91
- 93. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas • Insertar datos al Inicio de una lista, al final , y de forma ordenada en una lista abierta • Borrar datos de una lista abierta uno o toda la lista. • Mostrar una lista Propuesta: • Construir una función para poder insertar un nuevo elemento a la lista antes de un elemento determinado • Construir una función para poder insertar un nuevo elemento a la lista después de un elemento determinado #include<conio.h> #include<stdio.h> #include<iostream.h> #include<stdlib.h> #include<string.h> #include<stdlib.h> typedef struct nodo {int codigo; char nombre[30]; float sueldo; struct nodo * siguiente; }tipoNodo; typedef tipoNodo * pNodo; typedef tipoNodo *Lista; // Funciones Prototipos int ListaVacia(Lista l); void Insertar(Lista *l,int v); // insertar al inicio o cabecera de la lsiat void InsertarC(Lista *l,int v); // insertar al inico de una lista void InsertarF(Lista *l,int v); // insertar al final de una lista void Borrar(Lista *l,int v); // borrar un elemento de la lista void BorrarLista(Lista *l); // borrar toda las lista void MostrarLista(Lista l); void main() {clrscr(); Lista lista=NULL; pNodo p; InsertarC (&lista,1); InsertarC (&lista,2); InsertarC (&lista,4); InsertarC (&lista,3); MostrarLista(lista); getch(); system("PAUSE"); } int ListaVacia(Lista lista) {return(lista==NULL); ESTRUCTURA DE DATOS I -- FCI } void Insertar(Lista *lista,int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->codigo=v; printf("Ingrese Nombre del Empleado :"); scanf("%s",&nuevo->nombre); printf("Ingrese el sueldo :"); scanf("%f",&nuevo->sueldo); if(ListaVacia(*lista)||(*lista)->codigo>v){ 92 Manual de Estructura de Datos
- 94. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas nuevo->siguiente=*lista; *lista=nuevo; } else {anterior=*lista; while(anterior->siguiente && anterior->codigo <=v) anterior=anterior->siguiente; nuevo->siguiente=anterior->siguiente; anterior->siguiente=nuevo; } } void InsertarC(Lista *lista,int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->codigo=v; printf("Ingrese Nombre del Empleado :"); cin>>nuevo->nombre; printf("Ingrese el sueldo :"); cin>>nuevo->sueldo; nuevo->siguiente=*lista; *lista=nuevo; } void InsertarF(Lista *lista,int v) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->codigo=v; printf("Ingrese Nombre del Empleado :"); scanf("%s",&nuevo->nombre); printf("Ingrese el sueldo :"); scanf("%f",&nuevo->sueldo); if(ListaVacia(*lista)){ nuevo->siguiente=*lista; *lista=nuevo; } else {anterior=*lista; while(anterior->siguiente!=NULL) anterior=anterior->siguiente; anterior->siguiente=nuevo; nuevo->siguiente=NULL; } } void MostrarLista(Lista lista) {pNodo nodo=lista; if(ListaVacia(lista)) printf("Lista vacia n"); else{ printf("nCODIGO EMPLEADO SUELDOn"); while(nodo) { ESTRUCTURADE DATOS I -- FCI printf("%d t %s t %3.1f n ",nodo->codigo,nodo->nombre,nodo->sueldo); nodo=nodo->siguiente; } } } Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 93
- 95. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Implementaciones de Funciones para manipular: Listas Abiertas y Pilas Usando cadenas de caracteres #include<stdlib.h> #include<iostream.h> #include<conio.h> #include<stdio.h> #include<string.h> typedef struct nodo {char nombre[40]; char apellido[30]; char fono[25]; int edad; struct nodo * sig; }tipoNodo; typedef tipoNodo * pNodo; typedef tipoNodo * Pila; typedef tipoNodo *Lista; char n[40], ap[40], fo[40]; void InsertarPila(Pila *pila, char n[],char ap[],char fo[], int v) {pNodo nuevo; nuevo=(pNodo)malloc(sizeof(tipoNodo)); strcpy(nuevo->nombre,n); strcpy(nuevo->apellido,ap); strcpy(nuevo->fono,fo); nuevo->edad=v; nuevo->sig=*pila; *pila=nuevo; } int Pop(Pila *pila, char n[],char ap[],char fo[]) {pNodo nodo=*pila; int v=0; if(!nodo) cout<< "Pila Vacias...n"; else {*pila=nodo->sig; strcpy(n,nodo->nombre); strcpy(ap,nodo->apellido); strcpy(fo,nodo->fono); v=nodo->edad; free(nodo); } return v; } ESTRUCTURA DE DATOS I -- FCI void MostrarPila(Pila pila) {pNodo nodo=pila; int c; while(nodo) {c=Pop(&nodo,n,ap,fo); cout<<n<<"tt"<<ap<<"t"<<fo<<"tt"<<c<<"n"; } } void InsertarC(Lista *lista, char n[],char ap[],char fo[], int v) {pNodo nuevo; 94 Manual de Estructura de Datos
- 96. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas nuevo=(pNodo)malloc(sizeof(tipoNodo)); strcpy(nuevo->nombre,n); strcpy(nuevo->apellido,ap); strcpy(nuevo->fono,fo); nuevo->edad=v; nuevo->sig=*lista; *lista=nuevo; } void MostrarLista(Lista lista) { pNodo nodo=lista; if(!lista) printf("Lista vacia n"); else while(nodo) { cout<<nodo->nombre<<"t"<<nodo->apellido<<"t"<<nodo->fono<<"t"<<nodo->edad<<"n"; nodo=nodo->sig; } } void introducirDespues(Lista *lista,char cl[],char no[],char ap[],char fo[],int dd) {pNodo nuevo, aux=*lista; while (aux && strcmp(aux->nombre,cl)!=0) aux=aux->sig; if (aux && strcmp(aux->nombre,cl)==0) { nuevo=(pNodo)malloc(sizeof(tipoNodo)); strcpy(nuevo->nombre,no); strcpy(nuevo->apellido,ap); strcpy(nuevo->fono,fo); nuevo->edad=dd; nuevo->sig=aux->sig; aux->sig=nuevo; } else cout <<"no se inserto... dato"<<cl<<" no encontradon"; } void introducirAntes(Lista *lista,char cl[],char no[],char ap[],char fo[],int dd) {pNodo nuevo, aux=*lista; nuevo=(pNodo)malloc(sizeof(tipoNodo)); strcpy(nuevo->nombre,no); strcpy(nuevo->apellido,ap); strcpy(nuevo->fono,fo); nuevo->edad=dd; if (strcmp(aux->nombre,cl)==0) {nuevo->sig=*lista; *lista=nuevo; } else { while (aux && strcmp(aux->sig->nombre,cl)!=0) aux=aux->sig; ESTRUCTURADE DATOS I -- FCI if (aux && strcmp(aux->sig->nombre,cl)==0) { nuevo->sig=aux->sig; aux->sig=nuevo; } else cout <<"no se inserto... dato"<<cl<<" no encontradon"; } } void eliminar(Lista *lista,char cl[]) {pNodo aux=*lista; Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 95
- 97. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas if (strcmp(aux->nombre,cl)==0) { *lista=(*lista)->sig; } else { while (aux && strcmp(aux->sig->nombre,cl)!=0) aux=aux->sig; if (aux && strcmp(aux->sig->nombre,cl)==0) aux->sig=aux->sig->sig; else cout <<"no se borro... dato"<<cl<<" no encontradon"; } } void main() {clrscr(); Lista lista=NULL; Pila pila=NULL; int op=2; if (op==1) {cout<<"n***OPERACIONES CON LA LISTA ABIERTA***n"; InsertarC (&lista,"Mariela","Martinez","236421",22); InsertarC (&lista,"Julio","Guillen","2012514",10); InsertarC (&lista,"Gladis","Alvarado","23025",40); InsertarC (&lista,"Ximena","Laz","223025",21); InsertarC (&lista,"Marcos","Kon","246920",30); MostrarLista(lista); getch(); cout<<"nLISTA CON UN NUEVO DATO INCLUIDO ANTES DE XIMENA***n"; introducirAntes(&lista,"Ximena","NEGRO","LAMPARK","12354",30); MostrarLista(lista); } else if (op==2) { cout<<"n***operaciones con pila invertida***n"; InsertarPila (&pila,"Mariela","Martinez","236421",22); InsertarPila (&pila,"Julio","Guillen","2012514",10); InsertarPila (&pila,"Gladis","Alvarado","223025",40); InsertarPila (&pila,"Ximena","Laz","223025",21); InsertarPila (&pila,"Marcos","Kon","246920",30); cout<<"nPIla Originaln" ; MostrarPila(pila); getch(); InvertirPila(pila); }else { cout<<"n***Error***n"; getch(); } ESTRUCTURA DE DATOS I -- FCI } 96 Manual de Estructura de Datos
- 98. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas REGISTRO DE PACIENTES USANDO LISTAS ABIERTAS #include<string.h> #include<conio.h> #include<stdio.h> #include<iostream.h> #include<stdlib.h> typedef struct nodo {int historia; char nombre[45]; double cedula; int edad; char direccion[40]; char sexo[15]; struct nodo * siguiente; }tipoNodo; typedef tipoNodo * pNodo; typedef tipoNodo *Lista; // Funciones Prototipos int ListaVacia(Lista l); void InsertarC(Lista *l,int hc,char n[],double c,int e,char d[],char s[]); void InsertarF(Lista *l,int hc,char n[],double c,int e,char d[],char s[]); void InsertarO(Lista *l,int hc,char n[],double c,int e,char d[],char s[]); void Crea_NLista(Lista l1,Lista *l2); void Borrar(Lista *l,int hc); void BorrarLista(Lista *l); void MostrarLista(Lista l); void main() {clrscr(); Lista lista=NULL, lista2=NULL; pNodo p; char n[45], d[40] ,s[15]; int i,h, e; double c; for(i=0;i<5;i++) { cout<<"n Ingrese un numero de historia clinica :"; cin>> h; cout<<"n Ingrese los nombres del paciente :"; gets(n); cout<<"n Ingrese la cedula del paciente :"; cin>>c; cout<<"n Ingrese la edad del paciente :"; cin>> e; cout<<"n Ingrese la direccion del paciente :"; gets(d); cout<<"n Ingrese el sexo del paciente :"; cin>>s; InsertarC (&lista,h,n,c,e,d,s); } clrscr(); cout<<" Lista Inicial n"; MostrarLista(lista); getch(); ESTRUCTURADE DATOS I -- FCI //Generar la nueva lista Crea_NLista(lista,&lista2); cout<<"n NUEVA LISTA n"; MostrarLista(lista2); getch(); } int ListaVacia(Lista lista) {return(lista==NULL); } void InsertarC(Lista *lista, int hc, char n[],double c,int e,char d[],char s[]) {pNodo nuevo; Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 97
- 99. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->historia=hc; strcpy(nuevo->nombre,n); nuevo->cedula=c; nuevo->edad=e; strcpy(nuevo->direccion,d); strcpy(nuevo->sexo,s); nuevo->siguiente=*lista; *lista=nuevo; } void InsertarF(Lista *lista, int hc, char n[],double c,int e,char d[],char s[]) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->historia=hc; strcpy(nuevo->nombre,n); nuevo->cedula=c; nuevo->edad=e; strcpy(nuevo->direccion,d); strcpy(nuevo->sexo,s); if(ListaVacia(*lista)){ nuevo->siguiente=*lista; *lista=nuevo; } else {anterior=*lista; while(anterior->siguiente!=NULL) anterior=anterior->siguiente; anterior->siguiente=nuevo; nuevo->siguiente=NULL; } } void InsertarO(Lista *lista, int hc, char n[],double c,int e,char d[],char s[]) {pNodo nuevo, anterior; nuevo=(pNodo)malloc(sizeof(tipoNodo)); nuevo->historia=hc; strcpy(nuevo->nombre,n); nuevo->cedula=c; nuevo->edad=e; strcpy(nuevo->direccion,d); strcpy(nuevo->sexo,s); if(ListaVacia(*lista)||(*lista)->historia>hc){ nuevo->siguiente=*lista; *lista=nuevo; } else {anterior=*lista; ESTRUCTURA DE DATOS I -- FCI while(anterior->siguiente && anterior->historia <=hc) anterior=anterior->siguiente; nuevo->siguiente=anterior->siguiente; anterior->siguiente=nuevo; } } void Crea_NLista(Lista l1,Lista *l2) {pNodo nodo=l1; if(ListaVacia(l1)) printf("Lista vacia...No se genero la otra lista n"); while(nodo) {if (nodo->edad <20 ) 98 Manual de Estructura de Datos
- 100. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas { //Utilizamos cualquierra de las funciones para insertar el nodo en la nueva lista InsertarF(l2,nodo->historia,nodo->nombre,nodo->cedula,nodo->edad,nodo->direccion,nodo->sexo); } nodo=nodo->siguiente; } } void MostrarLista(Lista lista) {pNodo nodo=lista; if(ListaVacia(lista)) printf("Lista vacia n"); else{ cout<<"n Hist. Clinc Paciente Cedula Edad Direccion Sexon"; while(nodo) { cout<<" "<< nodo->historia<<" t " << nodo->nombre<<" t " <<nodo->cedula<<" t " <<nodo- >edad<<" t " <<nodo->direccion<<" t " <<nodo->sexo<<"n"; nodo=nodo->siguiente; } } } ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 99
- 101. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Manejo de Arboles #include<stdio.h> #include<conio.h> #include<stdlib.h> #include<math.h> #include<ctype.h> #include<string.h> #include<graphics.h> #include "interface.h" #include "arbol.h" void main(void){ int gdriver = DETECT, gmode; int elemento, valor, opcion, i; char *dato; NODOARBOL *raiz=NULL; clrscr(); for(;;){ nuevo: valor=0; opcion=menu(); if((opcion>=8 && opcion<=16) && raiz==NULL){ window(52,8,80,12); textattr(YELLOW + BLINK); textbackground(BLACK); cprintf("nr nr No hay nodos nr en el rbol "); window(1,1,80,25); ESTRUCTURA DE DATOS I -- FCI getch(); continue; } switch(opcion){ case 6: clrscr(); printf("nIngrese elemento a insertar [0 : 99]: "); gets(dato); 100 Manual de Estructura de Datos
- 102. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas for(i=0;i<strlen(dato);i++) if(!isdigit(dato[i])){ printf("nDato inv lido"); getch(); goto nuevo;} elemento=atoi(dato); if(elemento<0 || elemento>99){ printf("nDato desbordado"); getch(); break;} insertar(&raiz, elemento); break; case 8: clrscr(); printf("nIngrese elemento a eliminar [0 : 99]: "); gets(dato); for(i=0;i<strlen(dato);i++) if(!isdigit(dato[i])){ printf("nDato inv lido"); getch(); goto nuevo;} elemento=atoi(dato); if(elemento<0 || elemento>99){ printf("nDato desbordado"); getch(); break;} buscar(raiz, elemento, &valor); if(valor==1){ raiz=eliminar( raiz, elemento); printf("nNodo eliminadon"); getch(); } break; case 10: clrscr(); printf("El rbol inorder es: "); inorder(raiz); getch(); break; case 12: clrscr(); ESTRUCTURADE DATOS I -- FCI printf("El rbol preorder es: "); preorder(raiz); getch(); break; case 14: clrscr(); printf("El rbol postorder es: "); postorder(raiz); Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 101
- 103. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas getch(); break; case 16: clrscr(); initgraph(&gdriver, &gmode, "c:borlandcbgi"); dibujar(raiz, 15, 3, 7, 0); getch(); cleardevice(); closegraph(); break; case 18: exit(0); } } } /****************************************************************/ /* ARBOLES.H */ /****************************************************************/ typedef struct nodo{ int dato; struct nodo *izq; struct nodo *der; } NODOARBOL; void insertar(NODOARBOL **cabeza, int elemento){ if(*cabeza==NULL){ *cabeza= (NODOARBOL *) malloc(sizeof(NODOARBOL)); ESTRUCTURA DE DATOS I -- FCI if(*cabeza==NULL){ printf("No hay memorian"); return; } (*cabeza)->dato=elemento; 102 Manual de Estructura de Datos
- 104. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas (*cabeza)->izq=NULL; (*cabeza)->der=NULL; } else if(elemento< (*cabeza)->dato) insertar(& (*cabeza)->izq, elemento); else if(elemento> (*cabeza)->dato) insertar(& (*cabeza)->der, elemento); else{ printf("nNo puede insertar: valor duplicadonn"); getch(); } } void inorder(NODOARBOL *cabeza){ if(cabeza!=NULL){ inorder(cabeza->izq); printf("%d ",cabeza->dato); inorder(cabeza->der); } } void preorder(NODOARBOL *cabeza){ if(cabeza!=NULL){ printf("%d ", cabeza->dato); preorder(cabeza->izq); preorder(cabeza->der); } } ESTRUCTURADE DATOS I -- FCI void postorder(NODOARBOL *cabeza){ if(cabeza!=NULL){ postorder(cabeza->izq); postorder(cabeza->der); printf("%d ",cabeza->dato); } } Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 103
- 105. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas void buscar(NODOARBOL *cabeza, int elemento, int *valor){ if(cabeza!=NULL){ if((cabeza)->dato==elemento) *valor=1; else{ if(elemento<(cabeza)->dato) buscar((cabeza)->izq, elemento, valor); else buscar((cabeza)->der, elemento, valor); } } else{ printf("nDato no encontradon"); getch(); } } NODOARBOL *eliminar(NODOARBOL *cabeza, int elemento){ NODOARBOL *p1, *p2; if(elemento==cabeza->dato){ if(cabeza->izq==cabeza->der){ free(cabeza); return(NULL); } else if(cabeza->izq==NULL){ p1=cabeza->der; free(cabeza); return(p1); } else if(cabeza->der==NULL){ p1=cabeza->izq; ESTRUCTURA DE DATOS I -- FCI free(cabeza); return(p1); } else{ p2=cabeza->der; p1=cabeza->der; while(p1->izq) p1=p1->izq; 104 Manual de Estructura de Datos
- 106. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas p1->izq=cabeza->izq; free(cabeza); return(p2); } } if(cabeza->dato<elemento) cabeza->der=eliminar(cabeza->der, elemento); else cabeza->izq=eliminar(cabeza->izq, elemento); return(cabeza); } void dibujar(NODOARBOL *cabeza, int a, int b, int c, int d){ char value[3]; if(cabeza!=NULL){ itoa(cabeza->dato,value,10); circle(300+a,75+b,14); setcolor(YELLOW); outtextxy(295+a,75+b,value); setcolor(WHITE); if(d==1) line(300+a+pow(2,c+1),b+14,300+a,61+b); else if(d==2) line(300+a-pow(2,c+1),b+14,300+a,61+b); dibujar(cabeza->izq,a-pow(2,c)-pow(2,d-4),b+75,c-1,1); dibujar(cabeza->der,a+pow(2,c)+pow(2,d-4),b+75,c-1,2);} } ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 105
- 107. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas /****************************************************************/ /* INTERFACE.H */ /****************************************************************/ int menu(void); int acerca_de(void); void poner_recuadro(void); void barra(void); /****************************************************************/ /* MENU PRINCIPAL */ /****************************************************************/ int menu(){ int pos=6; char aux; poner_recuadro(); for( ; ; ){ switch(pos){ case 6 : gotoxy(28,pos); textcolor(YELLOW); textbackground(BLACK); cprintf(" Insertar "); aux=getch(); textcolor(15); textbackground(4); gotoxy(28,pos); cprintf(" Insertar "); break; case 8 : gotoxy(28,pos); textcolor(YELLOW); textbackground(BLACK); ESTRUCTURA DE DATOS I -- FCI cprintf(" Eliminar "); aux=getch(); textcolor(15); textbackground(4); gotoxy(28,pos); cprintf(" Eliminar "); break; 106 Manual de Estructura de Datos
- 108. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas case 10 : gotoxy(28,pos); textcolor(YELLOW); textbackground(BLACK); cprintf(" Inorder "); aux=getch(); textcolor(15); textbackground(4); gotoxy(28,pos); cprintf(" Inorder "); break; case 12 : gotoxy(28,pos); textcolor(YELLOW); textbackground(BLACK); cprintf(" Preorder "); aux=getch(); textcolor(15); textbackground(4); gotoxy(28,pos); cprintf(" Preorder "); break; case 14 : gotoxy(28,pos); textcolor(YELLOW); textbackground(BLACK); cprintf(" Postorder "); aux=getch(); textcolor(15); textbackground(4); gotoxy(28,pos); cprintf(" Postorder "); ESTRUCTURADE DATOS I -- FCI break; case 16 : gotoxy(28,pos); textcolor(YELLOW); textbackground(BLACK); cprintf(" Graficar "); aux=getch(); textcolor(15); Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 107
- 109. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas textbackground(4); gotoxy(28,pos); cprintf(" Graficar "); break; case 18 : gotoxy(28,pos); textcolor(YELLOW); textbackground(BLACK); cprintf(" Salir "); aux=getch(); textcolor(15); textbackground(4); gotoxy(28,pos); cprintf(" Salir "); break; } switch(aux){ case 0x48 : pos=pos-2; if(pos==4) pos=18; break; case 0x50 : pos=pos+2; if(pos==17) pos=3; break; case 0x0d : return pos; case 0x44 : exit(0); case 0x3b : break; case 0x3c : acerca_de(); } } } ESTRUCTURA DE DATOS I -- FCI /****************************************************************/ /* ACERCA DE ... */ /****************************************************************/ int acerca_de(void){ window(10,6,70,18); textcolor(BLACK); 108 Manual de Estructura de Datos
- 110. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas textbackground(WHITE); clrscr(); cprintf("nr ESCUELA POLIT CNICA NACIONAL"); cprintf("nnr CARRERA DE INGENIERÖA DE SISTEMASnrnr"); cprintf(" PROGRAMACIàN IInrnr"); cprintf(" Autor: Adri n Fernando Vaca C rdenasnr"); cprintf(" Curso: GR1nrnr"); cprintf(" Semestre: Octubre/2000 - Marzo/2001nr"); window(1,1,80,25); getch(); poner_recuadro(); return(0); } /****************************************************************/ /* PONER RECUADRO */ /****************************************************************/ void poner_recuadro(void){ int i; textbackground(6); clrscr(); clrscr(); textcolor(BLACK); textbackground(CYAN); gotoxy(23,4); cprintf("****** Men£ Principal ******"); for(i=0;i<16;i++){ gotoxy(23,i+5); textbackground(CYAN); cprintf("* *"); ESTRUCTURADE DATOS I -- FCI } gotoxy(23,20); cprintf("******* Arboles 1.0 ********"); textcolor(WHITE); textbackground(RED); gotoxy(28,6); cprintf(" Insertar "); Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 109
- 111. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas gotoxy(28,8); cprintf(" Eliminar "); gotoxy(28,10); cprintf(" Inorder "); gotoxy(28,12); cprintf(" Preorder "); gotoxy(28,14); cprintf(" Postorder "); gotoxy(28,16); cprintf(" Graficar "); gotoxy(28,18); cprintf(" Salir "); barra(); } /****************************************************************/ /* BARRA INFERIOR */ /****************************************************************/ void barra(void){ gotoxy(1,25); textattr(WHITE); textbackground(BLUE); cprintf(" F2 -> ACERCA DE ... F10 -> SALIR "); gotoxy(49,25); textcolor(WHITE); cprintf(" ARBOL 1.0 (C)opyright 2000"); gotoxy(1,1); textcolor(WHITE); textbackground(RED); cprintf(" Utilize las flechas del cursor para desplazarse."); ESTRUCTURA DE DATOS I -- FCI gotoxy(50,1); textcolor(WHITE); cprintf(" Enter para aceptar su opci¢n."); } 110 Manual de Estructura de Datos
- 112. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS APORTE DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “__” PARCIAL: Primero FECHA: PROFESOR: Ing. ______________ La empresa eléctrica Emelmanabi desea mejorar su servicio a los usuarios, Se esta pensando usar una lista abierta, en la cual se pueda almacenar la siguiente información sobre los clientes: Ruta ( entero) Secuencia(entero) n_medidor(entero) propietario(cadena) dirección (cadena) Se solicita Implementar: 1. Una función para insertar los datos digitados en la lista abierta de forma ordenada con respecto al n_medidor. 2. Una función para Mostar la lista abierta. 3. Una función que permita Eliminar datos específicos de un X n_medidor de la lista abierta. 4. Crear la estructura del nodo, implemente el programa principal, y registre 20 clientes. UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS APORTE DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “__” PARCIAL: Primero FECHA: PROFESOR: Ing. _______________ La empresa eléctrica Emelmanabi desea mejorar su servicio a los usuarios, Se esta pensando usar una lista abierta, en la cual se pueda almacenar la siguiente información sobre los clientes: Ruta ( entero) Secuencia(entero) n_medidor(entero) propietario(cadena) dirección (cadena) Se solicita Implementar: 1. Una función para insertar los datos digitados al final de la lista abierta. 2. Una función para Mostar la lista abierta. 3. Una función que permita ordenar los datos de la lista abierta. 4. Crear la estructura del nodo, implemente el programa principal, y registre 20 clientes. UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS APORTE DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “________” PARCIAL: Primero FECHA: PROFESOR: Ing. __________ La empresa eléctrica Emelmanabi desea mejorar su servicio a los usuarios, Se esta pensando usar una lista abierta, en la cual se pueda almacenar la siguiente información sobre los clientes: ESTRUCTURADE DATOS I -- FCI Ruta ( entero) Secuencia(entero) n_medidor(entero) propietario(cadena) dirección (cadena) Se solicita Implementar: 1. Una función para insertar los datos digitados al inicio de la lista abierta. 2. Una función para Mostar la lista abierta. 3. Una función que permita insertar a la lista abierta un nuevo cliente y poderlo ingresar justo antes del medidor numero 20. 4. Crear la estructura del nodo, implemente el programa principal, y registre 20 clientes. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 111
- 113. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS EXAMEN DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “C” PARCIAL: Segundo FECHA: jueves 9 de agosto del 2007 PROFESOR: Ing. Christian Torres 1. Con el siguiente recorrido en In Orden llenar el siguiente árbol, y responder las siguientes incógnitas Recorrido en In Orden D-E-C-G-F-H-I-B-J-K-M-L-A-N-Q-R-P a) Grado : _________ b) Altura:_________ c) Nodos Ramas:____________________ d) Nodo Raíz: ____________ 2. Escriba una función recursiva que permita calcular el factorial de un número cualquiera. ESTRUCTURA DE DATOS I -- FCI 3. Diseñe una estructura que permita almacenar los nombres y las notas de los estudiantes de un curso (N1 y N2), para poder ser almacenados en una lista doblemente enlazada, los estudiantes que sumado las 2 notas completaran 14 puntos o mas, deberán ser almacenados en una pila, sus nombres y promedio (N1 + N2) y de la lista doblemente enlazados deberán ser. Finalmente imprima la lista y luego la pila. Implemente las funciones necesarias Recuerde que los datos que pasan a la pila no deben quedarse en la lista. 112 Manual de Estructura de Datos
- 114. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS APORTE DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “__” PARCIAL: Segundo FECHA: ____________________ PROFESOR: Ing. _______________ 1.- Dado el siguiente árbol encuentre: (2.5pts.) A a) Numero de Hojas_______________________ b) Nodos Hojas __________________________ c) Nodo Raíz ____________________________ B N d) Nodos Ramas__________________________ C J P e) Profundidad___________________________ f) Altura________________________________ D F K g) Grado________________________________ Q h) Recorrido en In Orden____________________ E G I L R i) Recorrido en Post Orden __________________ j) Recorrido en Pre Orden ___________________ H M 2) Escriba la estructura de una lista doblemente enlazada e implemente una función para Ingresar la información (usted elija la información que maneja la estructura) (2.0) 3) Asumir que a usted la entregan un árbol lleno de datos y una lista circular (lista cerrada) (5.5pts) Y se desea hacer una comparación de los datos que están en el árbol con los que están en la lista cerradas, para generar una pila que almacene los datos del árbol que no están en la ESTRUCTURADE DATOS I -- FCI lista cerrada, y finalmente imprimir los datos de la lista y los de la pila generada. La información que maneja tanto el árbol como la lista cerrada es un número entero. Cree las funciones: - generar la pila - imprimir lista, y - imprimir pila Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 113
- 115. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas Universidad Técnica de Manabí Facultad de Ciencias Informáticas Aporte 2 de Estructura de Datos I Nombre:____________________________________________________________________ Semestre: 3ero “__” Fecha: ________________ 1) Del siguiente árbol calcule: a. Grado______ b. Nodo hijo__________________________________ c. Nodos Hojas________________________________ d. Nodos Rama_________________________________ e. Nivel del nodo E_______ f. Orden_______ g. Altura del árbol___________ 2) Escriba cual sería la forma de recorrer el siguiente árbol de acuerdo a su recorrido: a. In Orden_____________________________________________ b. Post Orden___________________________________________ c. Nivel del Árbol:_______ / 3) Recorra el siguiente árbol en : a. Pre Orden____________________________________________ + G b. Post Orden___________________________________________ c. Nodos Ramas:_____________________________________ * ↑ ESTRUCTURA DE DATOS I -- FCI + / E F 4) Con los siguientes Datos construya un árbol binario A B C D 83 - 69 – 13 – 2 - 8 – 56 - 21 - 34 114 Manual de Estructura de Datos
- 116. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS EXAMEN DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “__” PARCIAL: Primero FECHA: ___________________ PROFESOR: Ing. _____________________ Se desea implementar un sistema para la Clínica San Antonio, el cual utilice listas abiertas. El mismo deberá almacenar la siguiente información sobre los pacientes: historia_clinica, nombres, cedula, edad, dirección, sexo Se solicita Implementar: 1. Defina el tipo de dato para cada campo y cree la estructura del nodo, para que pueda almacenar 100 pacientes. (1.0 pts) 2. Cree una función para insertar los datos digitados en la lista abierta de forma ordenada con respecto al historia_clinica. (1.0pts) 3. Cree una función que llene otra lista con los datos de los pacientes que tengan menos de 20 años. Por ejemplo (1.5pts) LISTA INGRESADA 001 CARLOS MATA 1305642153 28 CALDERON MASCULINO 002 MERCEDES SOTO 1314264303 18 PORTOVIEJO FEMENINO 003 AMARILIS ZAMORA 1312526241 15 PORTOVIEJO FEMENINO 004 XAVIER PLUA 1301114302 20 PORTOVIEJO MASCULINO 005 MERCEDES SOTO 1312023421 19 PORTOVIEJO FEMENINO LISTA QUE SE GENERARIA 002 MERCEDES SOTO 1314264303 18 PORTOVIEJO FEMENINO 003 AMARILIS ZAMORA 1312526241 15 PORTOVIEJO FEMENINO 005 MERCEDES SOTO 1312023421 19 PORTOVIEJO FEMENINO ESTRUCTURADE DATOS I -- FCI 4. Una función para Mostar la lista abierta creada. (0.5pts) 5. Implemente el programa principal, pueda registrar pacientes, mostrarlos y eliminar. (1.0pts) Nota: Mostar la lista cuando sufra cambios y también la nueva lista generada con los menores a 20 años. Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 115
- 117. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS PERIODO SEPTIEMBRE 2007 – MARZO 2008 EXAMEN DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “_______” PARCIAL: Primero FECHA: ____________________ PROFESOR: Ing. ___________________________ Se tiene una lista abierta con los campos: int codigo: char nombre[35]; float sueldo; 1) Implemente una función para pasar los datos de la lista a una pila 2) Eliminar a los empleados que tienen sueldo menor a $ 125 3) Ingrese un nuevo nodo, pero justo antes del codigo=150. 2) Escriba la función que utilice una cola con elementos (solo dos campos: valor y siguiente) y que pueda pasar estos datos a una lista abierta de forma ordenada 3) En el siguiente procedimiento llamado examen UD deberá identificar gráficamente lo que realiza este procedimiento, cual seria el verdadero nombre de este procedimiento y para que serviría este procedimiento void EXAMEN(Nuevo_dato *va, int v) {pNodo nodo; nodo=*va; do{ if ((*va)->siguiente->valor !=v) *va=(*va)->siguiente; }while (*va)-siguiente->valor!=v && *va!=nodo); If((*va)->siguiente->valor==v) If (*va==(*va)->siguiente{ ESTRUCTURA DE DATOS I -- FCI free(*va); *va=NULL; } else {nodo=(*va)->siguiente; (*va)->siguiente=nodo->siguiente; } } } 116 Manual de Estructura de Datos
- 118. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS EXAMEN DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “__” PARCIAL: Segundo FECHA: _______________________ PROFESOR: Ing. ________________ 4. Construya un árbol binario a partir del siguiente árbol valor: 1.00pts 5. De su respuesta en la pregunta anterior: valor: 1.00pts a. Realizar el recorrido en Post Orden. b. Grado : _________ c. Altura:_________ 6. Diseñe una estructura que permita almacenar los nombres y las notas de los estudiantes de un curso (N1 y N2), para poder ser almacenados en una lista doblemente enlazada. Funciones a crear: • Ingreso de datos a la lista doble valor: 0.75pts ESTRUCTURADE DATOS I -- FCI • Cree una función que escriba la observación del estudiante junto a su nombre en una lista simple; es decir, los estudiantes que sumado las 2 notas completaran 14 puntos o mas “Aprueba” y los menores a 14 “Reprueba”. valor: 1.00pts Esto significara que debe usar dos estructuras •.Finalmente imprima la lista doble y luego la lista simple. valor: 1.00pts • Llamado a las funciones(Programa principal) valor: 0.25pts Implemente las funciones necesarias Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 117
- 119. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS EXAMEN DE RECUPERACIÓN DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “C” PROFESOR: Ing. Christian Torres FECHA: jueves 16 de agosto del 2007 typedef struct nodo typedef tipoNodo * pNodo; {char nombre[40]; typedef tipoNodo *Lista; char apellido[30]; char fono[15]; int edad; struct nodo * sig; }tipoNodo; 1. Teniendo la presente estructura y definición de tipos de datos, implemente una función para insertar nodos al inicio de una lista abierta. (1.5 pts) 2. Implemente una función para poder insertar un nuevo nodo antes del nodo con el campo nombre= “Ximena”. Para la estructura ya indicada. Asuma que los datos son pasado como argumentos de la función. ( 4.0pts) ESTRUCTURA DE DATOS I -- FCI 3. Escriba una función para eliminar el primer nodo de una lista doblemente enlazada circular. Realice las modificaciones respectivas en la estructura y tipo de datos dados para que pueda trabajar en esta pregunta.( 1.5 pts) 4. Construya una pila utilizado la estructura propuesta, e implemente una función que permita invertir una pila. ( 3.0pts) 118 Manual de Estructura de Datos
- 120. Universidad Tecnica de Manabí Facultad de Ciencias Informaticas UNIVERSIDAD TECNICA DE MANABI CIENCIAS INFORMATICAS EXAMEN DE RECUPERACIÓN DE ESTRUCTURA DE DATOS NOMBRE: SEMESTRE: Tercero “__” PROFESOR: Ing. __________________ FECHA: __________________________ 1. Una empresa de correos, desea implementar un programa que permita mejorar el manejo de la entrega de encomiendas, en la cual registre el número de envió, peso, destino, el remitente y el costo del envió. Por razones de no contar con el suficiente personal de entrega, la empresa envía a despachar los paquetes cuyo peso sea inferior a 500Kg, para ser entregado en el transcurso de la semana (de lunes a viernes), y los que sean superiores a 500 Kg serán despachados en el fin de semana (sábado y domingo). Se solicita que utilice una lista doblemente enlazada en la que registre todas las entregas y elabore con ello una lista simple, para almacenar las entregas de los paquetes para la semana (de lunes a viernes), y otra lista para los de fin de semana (sábado y domingo) (5pts) 2. Explique teóricamente o gráficamente, como poder entregar a las personas que tienen varios paquetes por recibir de diferente tamaño (en la semana, y fin de semana), para entregarle en el mismo viaje todo a la vez en el primer viaje y así ahorrar combustible. (2 puntos) 3. Construya un árbol binario a partir del siguiente grafico. ( 3.0pts) • Recorrer en In Orden. El árbol generado • Nodos Hojas del árbol binario________________________________ ESTRUCTURADE DATOS I -- FCI Elaborado por: Ing. Esthela San Andres e Ing. Christian Torres 119