Évaluation
Chap 0 2
ExamenIntra (2h): 25% (le 25 octobre)
Examen Final (3h) 45% (le 13
décembre)
Examens à livre fermé – aucun doc permis
Le final sera sur toute la matière
Devs. théoriques et de programm. 30%
2-3 devs de programmation: 20% tous
3 devs théoriques: 10% tous
3.
Contenu du cours
Chap0 3
PARTIE 0: INTRODUCTION
Revue des principales composantes d'un ordinateur.
Structure générale des systèmes d'exploitation.
PARTIE 1: PROCESSUS et GESTION d’UNITÉ CENTRALE
Description et contrôle des processus.
Fils (threads).
Parallélisme: exclusion mutuelle et synchronisation.
Ordonnancement des processus sur un uniprocesseur.
Parallélisme: interblocage et famine.
PARTIE 2: GESTION DE MÉMOIRE
Adressage et gestion de la mémoire.
Mémoire virtuelle.
PARTIE 3: FICHIERS, E/S ET PROTECTION
Systèmes de fichiers, systèmes d’E/S
Protection
4.
Accent en classesur les concepts théoriques de
longue durée de vie
La programmation, l’application seront dans les
sessions exercices
Chap 0 4
5.
Manuel:
Chap 0 5
Silberschatz,Galvin, Gagne.
Principes appliqués des systèmes d’exploitation, Vuibert
Avantages:
très clair dans la présentation
utilise Java
beaucoup de notions intéressantes et utiles
Désavantages:
beaucoup plus gros que nécessaire
Je le suivrai, mas pas toujours
Cependant la lecture du manuel est indispensable pour une
bonne compréhension de la matière.
Les examens et les devoirs contiendront des questions
prises du manuel
Livres de Stallings et Tanenbaum en réserve a la
bibliothèque
6.
Les labos etJava
Chap 0 6
1er labo la semaine prochaine sur Unix
Les devoirs de programmation se feront en Java
Pas un langage utilisé dans les SE d ’aujourd ’hui
Mais un langage qui facilite la programmation
parallèle
Il commence à être utilisé utilisé dans les SE
répartis expérimentaux
Les labos fourniront une introduction a Java, et
de l’aide dans la programmation Java
Java ne sera pas utilisé en classe: pseudocode
sera utilisé au lieu
Le test et l ’examen contiendront des
questions sur Unix et Java
7.
Labos et devoirs
Chap0 7
Les devoirs seront constitués de:
20%: 3 travaux de programmation (Unix
et Java) sur:
Parallélisme
Synchronisation de processus
10%: Exercices écrits sur la théorie vue
en classe (probabl. 3 ensembles d’exercices)
Concepts importants duChapitre 1
Ch. 1 2
Que c’est que un SE
Évolution historique
Par lots
Multiprogrammés – balance de travaux
À partage de temps (time-sharing)
Parallèles:
Fortement couplés
• Symétriques,
• Asymétriques: maître-esclave
Faiblement couplés:
• Répartis
• Réseaux
Caractéristiques de matériel et logiciel requises pour cette
évolution
Systèmes à temps réel: durs, souples
10.
Système d’exploitation (SE)
Ch.1 3
Fournit l’interface usager/machine:
Masque les détails du matériel aux applications
Le SE doit donc traiter ces détails
Contrôle l’exécution des applications
Le fait en reprenant périodiquement le
contrôle de l’UCT
Dit à l’UCT quand exécuter tel programme
Il doit optimiser l`utilisation des ressources pour
maximiser la performance du système
Ressources et leurgestion
Ch. 1 5
Ressources:
physiques: mémoire, unités E/S, UCT...
Logiques = virtuelles: fichiers et bases de
données partagés, canaux de
communication logiques, virtuels...
les ressources logiques sont bâties par
le logiciel sur les ressources physiques
Allocation de ressources: gestion de
ressources, leur affectation aux usagers
qui les demandent, suivant certains
critères
13.
Pourquoi étudier lesSE?
Ch. 1 6
Logiciel très important…
tout programme roule sur un SE
interface usager-ordinateur
Les SE utilisent beaucoup d ’algorithmes
et structures de données intéressants
Les techniques utilisées dans les SE sont
aussi utilisées dans nombreuses autres
applications informatiques
il faut les connaître
14.
Développement de lathéorie des SE
Ch. 1 7
La théorie des SE a été développée surtout dans
les années 1960 (!!)
A cette époque, il y avait des machines très peu
puissantes avec lesquelles on cherchait à faire
des applications comparables à celles
d’aujourd’hui (mémoire typique: 100-500K!)
Ces machines devaient parfois desservir des
dizaines d’usagers!
Dont le besoin de développer des principes pour
optimiser l’utilisation d ’un ordinateur.
Principes qui sont encore utilisés
15.
Évolution historique desSE
Ch. 1 8
Le début: routines d`E/S, amorçage système
Systèmes par lots simples
Systèmes par lots multiprogrammés
Systèmes à partage de temps
Ordinateurs personnels
SE en réseau
SE répartis
Les fonctionnalités des systèmes simples se retrouvent
dans les systèmes complexes.
Les problèmes et solutions qui sont utilisés dans les
systèmes simples se retrouvent souvent dans les
systèmes complexes.
16.
Phase 1: Lesdébuts
Ch. 1 9
Au début, on a observé qu`il y avait des
fonctionnalités communes à tous les
programmes
il fallait les pré-programmer et les fournir
au programmeur à moyen d`instructions
d` appel:
amorçage du système
entrée/sortie
17.
Phase 2: Systèmesde traitement par lots (batch)
simples
Ch. 1 10
Sont les premiers SE (mi-50)
L’usager soumet une job à un opérateur
Programme suivi par données
L’opérateur place un lot de plusieurs jobs sur le
dispositif de lecture
Un programme, le moniteur, gère l'exécution
de chaque programme du lot
Le moniteur est toujours en mémoire et prêt à être
exécuté
Les utilitaires du moniteur sont chargés au
besoin
Un seul programme à la fois en mémoire,
programmes sont exécutés en séquence
La sortie est normalement sur un fichier, imprimante, ruban
magnétique…
18.
Ch. 1 11
Unordinateur principal
(mainframe) du milieu des annnées ‘60
Musée de l’histoire de l’informatique http://www.computerhistory.org/
lecteur de cartes
rubans
disques
UCT
(mémoire probablem.
autour de 250-500K)
console opérateur
19.
Ch. 1 12
Oui,cartes perforées…
Une ligne de données ou de programme était
codée dans des trous qui pouvaient être lus par
la machine
20.
Ch. 1 13
Opérateurlisant un paquet de cartes
perforées
Source:
http://www.tietokonemuseo.saunalahti.fi/eng/kuva_32_
21.
Ch. 1 14
Langagede contrôle des travaux
(JCL)
Utilisé pour contrôler l ’exec d ’une
job
le compilateur à utiliser
indiquer où sont les données
Exemple d’une job:
paquet de cartes comme suit:
$JOB début
$FTN charge le compilateur
FORTRAN et initie son exécution
$LOAD charge le pgm objet (à
la place du compilateur)
$RUN transfère le contrôle
au programme usager
les données sont lues par le
moniteur et passées au progr.
usager
$JOB
$FTN
...
Programme
FORTRAN
...
$LOAD
$RUN
...
Données
...
$END
$JOB
...
(job
suivant)
22.
Ch. 1 15
Langagede contrôle des travaux (JCL)
L’E/S est déléguée au moniteur
Chaque instruction d’E/S dans pgm usager
invoque une routine d’E/S dans le moniteur:
s’assure de ne pas lire une ligne JCL
un usager ne peu pas interférer avec les E/S
d`un autre usager…
Quand le programme usager se termine, la
prochaine ligne de JCL est lue et exécutée par
le moniteur.
23.
Ch. 1 1
Lemoniteur par lots
Lecture de cartes perforées
Interprétation de commandes JCL
Lecture (load) d’une job (du lecteur de
cartes)
Chargement en mémoire (dans la région
de l’usager) de cette job
Transfère le contrôle au programme
usager (job sequencing)
Exécution du programme usager
jusqu’à:
fin du programme
E/S
erreur
À ce point, le moniteur reprend le
contrôle
Pour le redonner plus tard au
même programme ou à un autre
Stallings
24.
Caractéristiques désirables dumatériel
(1)
Ch. 1 17
Protection de la mémoire
ne pas permettre aux pgms usager
d’altérer la région de la mémoire où se
trouve le moniteur
Minuterie
limite le temps qu`une job peut exécuter
produit une interruption lorsque le
temps est écoulé
25.
Caractéristiques désirables dumatériel
(2)
Ch. 1 18
Instructions privilégiées
exécutables seulement par le moniteur
une interruption se produit lorsqu’un programme usager
tente de les exécuter
UCT peut exécuter en mode moniteur ou mode usager
Les instructions privilégiées ne peuvent être exécutées
que en mode moniteur
l ’usager ne peut exécuter que en mode usager
seulement le SE ou une interruption peuvent changer de
mode
Interruptions
facilitent le transfert de contrôle entre le système
d ’exploitation, les opérations d`E/S et les
programmes usagers
Le mode moniteur sera plus souvent appelé
mode superviseur
26.
Les systèmes parlots
Ch. 1 19
Ont été les premiers systèmes d`exploitation.
Ils sont associés aux concepts suivants:
langage de contrôle de travaux (JCL)
système d ’exploitation résident en mémoire
kernel = noyau
protection de mémoire
instructions privilégiées
modes usager-moniteur
interruptions
minuterie
Toutes ces caractéristiques se retrouvent dans les systèmes
d’aujourd’hui
Encore aujourd’hui on parle de jobs ‘par lots’ quand ils sont
exécutés séquentiellement sans intervention humaine
P.ex. salaires, comptabilité d’une compagnie
27.
Phase 2.5: Traitementpar lots
multiprogrammé
[Stallings]
Ch. 1 20
Les opérations E/S sont extrêmement lentes
(comparé aux autres instructions)
P. ex. une boucle de programme pourrait durer 10
microsecondes, une opération disque 10
millisecondes
C’est la différence entre 1 heure et un mois et demi!
Même avec peu d’E/S, un programme passe la
majorité de son temps à attendre
Donc: pauvre utilisation de l’UCT lorsqu’un seul
pgm usager se trouve en mémoire
28.
Traitement par lotsmultiprogrammé
Si la mémoire peut contenir +sieurs pgms,
l’UCT peut exécuter un autre pgm
lorsqu’un pgm attend après E/S
C’est la multiprogrammation
[Stallings]
Ch. 1 21
Exigences pour
multiprogrammation
Ch. 123
Interruptions
afin de pouvoir exécuter d’autres jobs
lorsqu’un job attend après E/S
Protection de la mémoire: isole les jobs
Gestion du matériel
plusieurs jobs prêts à être
exécutées demandent des
ressources:
• UCT, mémoire, unités E/S
Langage pour gérer l’exécution des
travaux: interface entre usager et OS
jadis JCL, maintenant shell, command
prompt
ou semblables
31.
Spoule ou spooling
Ch.1 24
Au lieu d ’exécuter les travaux au fur et à
mesure qu’ils sont lus, les stocker sur une
mémoire secondaire (disque)
Puis choisir quels programmes exécuter et
quand
Ordonnanceur à long terme, à discuter
32.
Équilibre de travaux
Ch.1 25
S`il y a un bon nombre de travaux à exécuter, on peut
chercher à obtenir un équilibre
Travaux qui utilisent peu l`UCT, beaucoup l ’E/S, sont
appelés tributaires de l`E/S
Nous parlons aussi de travaux tributaires de l ’UCT
Le temps d`UCT non utilisé par des travaux trib. de l ’E/S
peut être utilisé par des travaux trib. de l ’UCT et vice-
versa.
L ’obtention d`un tel équilibre est le but des ordonnanceurs
à long terme et à moyen terme (à discuter).
Dans les systèmes de multiprog. on a souvent coexistence
de travaux longs et pas urgents avec travaux courts et
urgents
Le SE donne priorité aux deuxièmes et exécute les
premiers quand il y a du temps de machine disponible.
33.
Phase 3: Systèmesà temps partagé (TSS)
ordinateur principal
(mainframe)
Terminaux
‘stupides’
Ch. 1 26
Systèmes à tempspartagé (TSS)
Ch. 1 28
Le traitement par lots multiprogrammé ne
supporte pas l’interaction avec les usagers
excellente utilisation des ressources mais frustration des
usagers!
TSS permet à la multiprogrammation de desservir
plusieurs usagers simultanément
Le temps d ’UCT est partagé par plusieurs
usagers
Les usagers accèdent simultanément et
interactivement au système à l’aide de terminaux
36.
Systèmes à tempspartagé (TSS)
Ch. 1 29
Le temps de réponse humain est lent: supposons
qu`un usager nécessite, en moyenne, 2 sec du
processeur par minute d’utilisation
Environ 30 usagers peuvent donc utiliser le
système sans délais notable du temps de réaction
de l’ordinateur
Les fonctionnalités du SE dont on a besoin sont
les mêmes que pour les systèmes par lots, plus
la communication avec usagers
le concept de mémoire virtuelle pour faciliter la
gestion de mémoire
traitement central des données des usagers
(partagées ou non)
37.
MULTICS et UNIX
Ch.1 30
MULTICS a été un système TSS des
années 60, très sophistiqué pour son
époque
Ne réussit pas à cause de la faiblesse du
matériel de son temps
Quelques unes de ses idées furent
reprises dans le système UNIX
38.
Ordinateurs Personnels (PCs)
Ch.1 31
Au début, les PCs étaient aussi simples
que les premiers ordinateurs
Le besoin de gérer plusieurs applications
en même temps conduit à redécouvrir la
multiprogrammation
Le concept de PC isolé évolue maintenant
vers le concept d ’ordinateur de réseau
(network computer), donc extension des
principes des TSS.
Retour aux conceptsde TSS
Plusieurs PC (clients) peuvent être
desservis par un ordi plus puissant
(serveur) pour des services qui sont trop
complexes pour eux (clients/serveurs,
bases de données, telecom)
Les grands serveurs utilisent beaucoup
des concepts développés pour les
systèmes TSS
Ch. 1 33
41.
Et puis…
Ch. 134
Systèmes d’exploitation répartis:
Le SE exécute à travers un ensemble
de machines qui sont reliées par un
réseau
Pas discutés dans ce cours
Ch. 1 36
Unesynthèse historique
Ordinateurs Personnels
Mainframes et grands serveurs
Multics et beaucoup d`autres
(1960s)
Unix
(1970)
MS-DOS
(1981)
Windows
(1990)
Linux
(1991)
Windows NT
(1988)
Windows 2000
Windows XP
Solaris
(1995)
Mac/OS
(1984)
Systèmes parallèles (tightlycoupled)
Ch. 1 38
Le petit coût des puces rend possible leur
composition dans systèmes
multiprocesseurs
Les ordinateurs partagent mémoire,
horloge, etc.
Avantages:
plus de travail fait (throughput)
plus fiable:
dégradation harmonieuse (graceful
degradation)
46.
Systèmes parallèles
Ch. 139
Symétriques
Tous les UCTs exécutent le même SE
Elles sont fonctionnellement identiques
Asymétrique
Les UCTs ont des fonctionnalités
différentes, par exemple il y a un maître et
des esclaves.
Aujourd’hui, tout ordinateur puissant est
un système parallèle.
47.
Systèmes distribués (= répartis)
Ch. 1 40
Les réseaux d ’ordinateurs sont en pleine
émergence...
Systèmes multiprocesseurs faiblement
couplés (loosely coupled)
consistent d ’ordinateurs autonomes,
qui communiquent à travers lignes de
communication
48.
Systèmes distribués (= répartis)
Ch. 1 41
SE répartis
il y a un SE qui fonctionne entre ordinateurs
l ’usager voit les ressources éloignées
comme si elles étaient locales
SE en réseau (network operating systems)
fournissent:
partage de fichiers (systèmes client-
serveur)
patrons de communication (protocoles)
autonomie des ordinateurs
49.
Systèmes à tempsréel
Doivent réagir à ou contrôler des événements
externes (p.ex. contrôler une usine). Les délais de
réaction doivent être bornés
systèmes temps réel souples:
les échéances sont importantes, mais ne sont
pas critiques (p.ex. systèmes téléphoniques)
systèmes temps réel rigides (hard):
le échéances sont critiques, p.ex.
contrôle d’une chaîne d`assemblage
graphiques avec animation
(ma déf. de souple n’est pas la même que dans
le livre)
Ch. 1 42
50.
Concepts importants duChapitre 1
Ch. 1 43
Que c’est que un SE
Évolution historique
Par lots
Multiprogrammés – balance de travaux
À partage de temps (time-sharing)
Parallèles:
Fortement couplés
• Symétriques,
• Asymétriques: maître-esclave
Faiblement couplés:
• Répartis
• Réseaux
Caractéristiques de matériel et logiciel requises pour cette
évolution
Systèmes à temps réel: durs, souples
51.
Dans le livre,pour ce chapitre, vous devez
Ch. 1 44
Étudier le chapitre entier
52.
Terminologie: mémoire centraleet auxiliaire
Ch. 1 45
La mémoire centrale est la mémoire RAM sur
laquelle le CPU exécute les instructions
Le cache est étroitement lié à la mémoire centrale,
donc il est considéré partie de cette dernière
Mémoires auxiliaires sont toutes les autres
mémoires dans le système
Disques
Flash-memory
Rubans…
Les m. aux. sont des périphériques
53.
Terminologie
Ch. 1 46
Opérationsd’E/S: Entrée ou Sortie, Input/Output
Les opérations de lecture ou écriture en ou de mémoire
centrale
Peuvent être directement ou indirectement demandées
par le programme
Exemple d’indirectement: E/S occasionnées par la pagination
Entrée:
Read dans un programme
• Lecture de disque
• Caractères lu du clavier
• Click du souris
• Lecture de courriel
• Lecture de page web (à être affichée plus tard, p.ex.)
Sortie:
Write dans un programme
• Affichage sur l’écran
• Impression
• Envoi de courriel
• Sortie de page web demandée par une autre machine
54.
Terminologie
Ch. 1 47
Travaux‘en lots’ (batch)
Travaux non-urgents qui sont soumis au système
pour ramasser la réponse plus tard
Tri de fichier, calcul d’une fonction complexe,
grosses impressions, sauvegarde régulière de
fichiers usagers
Pour plus d’efficacité, peuvent être groupés et
exécutés les uns après les autres
Interactifs
Sont les travaux qui demandent une
interaction continue avec l’ordinateur:
Édition de documents ou d’un programme
Les premiers ordinateurs n’avaient pas de
mécanismes de communication aisée entre
usager et machine, donc normalement les travaux
étaient ‘par lots’
55.
Annexe historique surles techniques de
programmation
Les informaticiens d’aujourd’hui sont
souvent surpris du fait qu’on pouvait faire
quelque chose d’utile avec des ordinateurs
aussi petits que ceux qui existaient dans
les années ’60
Un exemple pourra aider à comprendre...
Ch. 1 48
56.
Un programme HelloWorld du début des
années ‘60
Ch. 1 49
110016#T
OXXXXXX0
HELLO WORLD
Ce programme consiste en 27 octets (en langage
machine) Son adresse initiale est 0.
La première ligne dit d’imprimer à partir de l’adresse 16 pour
longueur 11.
La deuxième ligne est l’instruction
STOP. La 3ème ligne est la constante
à imprimer
57.
50
Programmes Hello Worldd’aujourd’hui
class HelloWorld {
public static void printHello( ) {
System.out.println("Hello,
World");
}
}
class UseHello {
public static void main(String[ ] args)
{ HelloWorld myHello = new
HelloWorld( ); myHello.printHello( );
}
}
Dans l’article:
C. Hu. Dataless objects considered harmful.
Comm. ACM 48 (2), 99-101
http://portal.acm.org/citation.cfm?id=1042091.1042126#
l’auteur présente deux versions orientées objet de
programmes ‘Hello World’. Il critique la version ci-
dessous disant qu’elle n’est pas vraiment orientée
objet
et qu’il faudrait vraiment utiliser la version à droite.
Quelle est la mémoire demandée par ces
class Message {
String messageBody;
public void setMessage(String
newBody) { messageBody =
newBody;
}
public String getMessage(
) { return messageBody;
}
public void printMessage( )
{ System.out.println(messageBo
dy);
}
}
public class MyFirstProgram {
public static void main(String[ ]
args) { Message mine = new
Message ( );
mine.setMessage("Hello, World");
Message yours = new Message
( );
yours.setMessage("This is my first
program!"); mine.printMessage( );
System.out.println(yours.getMessage( ) +
"—" +
mine.getMessage( ) );
Ch.2 2
Concepts importantsdu Chapitre 2
Registres d’UCT, tampons en mémoire, vecteurs
d’interruption
Interruption et polling
Interruptions et leur traitement
Méthodes d’E/S avec et sans attente, DMA
Tableaux de statut de périphériques
Hiérarchie de mémoire
Protection et instructions privilégiées, modes
d’exécution
Registres bornes
Appels de système
60.
Ch.2 3
Architecture d’ordinateurs
Dansbeaucoup de systèmes, ce n ’est que l`UCT qui peut adresser
la mémoire: les infos transférées entre les périphériques et la
mémoire (ou même entre mémoire et mémoire) doivent passer à
travers l ’UCT, dont le concept de `vol de cycles` (cycle stealing).
61.
Registres de l’UCT(mémoire rapide dans
UCT)
Ch.2 4
Registres de contrôle et statut
Généralement non disponibles aux programmes
de l’usager
l’UCT en utilise pour contrôler ses opérations
Le SE en utilise pour contrôler l’exécution
des programmes
Registres Visibles (aux usagers)
disponibles au SE et programmes de
l’usager
visibles seulement en langage machine ou
assembleur
contient données, adresses etc.
62.
Exemples de registresde contrôle et
statut
Ch.2 5
Le compteur d’instruction (PC)
Contient l’adresse de la prochaine
instruction à exécuter
Le registre d’instruction (IR)
Contient l’instruction en cours d’exécution
Autres registres contenant, p.ex.
bit d’interruption activé/désactivé
bit du mode d’exécution superviseur/usager
bornes de mémoire du programme en exec.
Registres de statut des périphériques
63.
Opération d`ordinateurs pourE/S
Ch.2 6
Unités d’E/S et UCT peuvent exécuter en
même temps
Chaque type d`unité a un contrôleur
Chaque contrôleur a un tampon ou registre
en mémoire principale (buffer)
UCT transfère l ’information entre
contrôleur et tampon (vol de cycles)
Le contrôleur informe l ’UCT que
l’opération a terminé
L’UCT a des registres qui contiennent le
statut des différentes unités E/S.
64.
Deux façons différentesde traiter la
communication entre UCT et unités E/S
Ch.2 7
Polling (E/S programmée, interrogation,
scrutation): le programme interroge
périodiquement les regs statut et
détermine le statut de l ’unité E/S: pour
les unités E/S lentes
Interruption: l ’UCT est interrompue entre
instructions quand un événement
particulier se produit (fin d ’E/S, erreur...)
les interruptions peuvent être inhibées
pendant l ’exécution de certaines parties
critiques du programme (il y a une
instruction pour faire ça).
65.
Exemple
Ch.2 8
Courriel…
J’utilise l’interruptionsi j’ai une sonnerie
qui m’avertit quand un courriel arrive
J’utilise la scrutation (polling) si au lieu je
regarde le courriel périodiquement de
mon initiative
66.
Registres, vecteurs d’interruptions,tampons
Unité centrale
Registre
s
Mémoir
e
Vect.
interrupt
Registre imprimante
Registre disque
Registre clavier
E/S
inuteri
e
xceptio
n
M
E
Les registres en mémoire
sont aussi appelés
tampons (buffers)
Ch.2 9
67.
Le cycle d’instructionde base
[Stallings]
Ch.2 10
• L’UCT extrait l’instruction de la mémoire.
• Ensuite l’UCT exécute cette instruction
•Le compteur d’instruction (PC) contient l’adresse de la
prochaine instruction à extraire
• Le PC est incrémenté automatiquement après chaque extraction
68.
Le cycle d’instructionavec interruptions
[Stallings]
Après chaque instruction, si les interruptions sont habilitées, l’UCT
examine s’il y a eu une interruption
S’il n’y en a pas, il extrait la prochaine instruction du programme
S’il y en a, il suspend le pgm en cours et branche l’exécution à une
position fixe de mémoire (déterminée par le type d ’interruption)
une partie de la mémoire et réservée pour ça
Ch.2 11
Le pgm degestion de
l’interruption
Ch.2 13
(interrupt
handler)
Est un pgm qui détermine la nature d’une
interruption et exécute les actions requises
L’exécution est transférée à ce pgm...
…et doit revenir au programme initial au point
d’interruption pour que celui-çi continue
normalement ses opérations
Le point d’interruption peut se situer n’importe
où dans le pgm (excepté où les interruptions ne
sont pas habilitées).
L’on doit donc sauvegarder l’état du programme
Registres UCT et autres infos nécessaires
pour reprendre le programme après
71.
Interruptions causées parles périphériques
ou par le matériel
Ch.2 14
E/S
lorsq’une opération E/S est
terminée
Bris de matériel (ex: erreur de parité)
72.
Interruptions causées parle programme
usager
Ch.2 15
Exception
Division par 0, débordement
Tentative d’exécuter une instruction
protégée
Référence au delà de l’espace mémoire
du progr.
Appels du Système
Demande d’entrée-sortie
Demande d’autre service du SE
Minuterie établie par programme lui-
même
73.
Interruptions causées parle SE
Ch.2 16
Minuterie établie par le SE
Préemption: processus doit céder l’UCT à
un autre processus
74.
Terminologie d`interruptions
Ch.2 17
Pasnormalisée, d’ailleurs les mécanismes
de traitement sont pareils…
C’est une bonne idée de distinguer entre:
trappes: causées par le pgm en
exécution: division par 0, accès illégal,
appels du système...
interruptions: causées par
événements indépendants:
minuterie, fin d` E/S
fautes: ce mot est utilisé surtout par
rapport à la pagination et la segmentation.
75.
Ordre séquentiel desinterruptions [Stallings]
Interruption désactivée durant l’exécution d’un IH
Les interruptions sont en attente jusqu’à ce que l’UCT active les
interruptions (file d’attente en matériel).
L’UCT examine s’il y a des interruptions en attente après avoir
terminé d’exécuter l’IH
Ch.2 18
76.
Interruptions avec priorités
L’IHd’une interruption de priorité faible peut se faire interrompre
par une interruption de priorité élevée
Exemple: les données arrivant sur une ligne de communication
doivent-être absorbées rapidement pour ne pas causer de
retransmissions
Ch.2 19
La Multiprogrammation estpossible dans le
cas de méthode (b)
Ch.2 21
Après l’initiation d’une op d’E/S, le
contrôle retourne à l’UCT
Qui peut utiliser le temps d’attente
E/S pour exécuter un autre
programme
79.
Ch.2 22
Pour gérererles unités d’E/S (plus. E/S peuvent être en
cours)
Tableau de statut des unités
E/S
Erreur dans la figure: imprimante devrait
être
80.
Accès direct àla mémoire (DMA)
Ch.2 23
Sans DMA, tous les accès de mémoire passent à
travers l’UCT
Donc les E/S occupent une certaine portion du
temps de l’UCT, même si l’UCT pourrait en même
temps exécuter un processus (vol de cycles)
Avec DMA, les unités d’E/S transfèrent
les données directement avec la mémoire
L’UCT est impliquée seulement pour initier et
terminer les E/S
L’UCT est complètement libre d’exécuter
d’autres processus (pas de vol de cycles)
Hiérarchie de mémoire
Ch.225
Différentes types de mémoire
Constituent une hiérarchie
vitesse (de plus vite à moins vite)
coût (de plus cher à moins cher)
permanence ou non
Important pour lacompréhension du concept
de mémoire virtuelle
Ch.2 27
L’UCT ne peut pas accéder à une
instruction ou à une donnée que s’ils se
trouvent
En cache dans les ordinateurs où il y a
de cache
Ou sinon en mémoire centrale (RAM)
Donc ces données doivent être apportées
en RAM ou cache au besoin
85.
Protection
Ch.2 28
Plusieurs processuset le S/E partagent la
mémoire, exécutant parfois les mêmes
instructions
Il faut empêcher que l ’un fasse des choses
réservées à l ’autre
Il faut les protéger les uns des autres
Protection d ’instructions
Protection de mémoire
86.
Instructions protégées =privilégiées
Ch.2 29
Ne peuvent être exécutées que par le S/E, en
mode superviseur
Exemples:
Les instructions d’E/S
Instructions pour traiter les registres non-
visibles d’UCT
Instructions pour la minuterie
Instructions pour changer les limites de
mémoire
Instructions pour changer de mode
d’exécution (superviseur,usager)
Le programme usager peut demander au SE que
ces opérations soient exécutées, mais il ne peut
pas les exécuter directement
87.
Fonctionnement double mode
superviseu
r
usage
r
setuser mode
Un registre d’UCT contient un bit qui dit si l ’UCT
exécute couramment en mode superviseur ou en mode
usager
ce bit est changé automatiquement à mode superviseur
lors d’une interruption
certaines instructions ne peuvent être exécutées que
en mode superviseur (instructions privilégiées):
des tentatives de les exécuter en mode usager causeront
une interruption, et retour à mode superviseur
le mode superviseur peut être changé à mode usager par
une instruction privilégiée
ces deux modes ont aussi des autres noms, v. livre
Ch.2 30
Interrupt/
fault
88.
Protection de mémoire:chaque processus
doit rester dans ses propres bornes de
mémoire
Solution typique: deux registres dans l ’UCT
quand l ’UCT exécute un processus, elle sait quelle est la
borne inférieure et supérieure de la zone de mémoire
de ce processus
l ’adresse de chaque instruction est comparée à ces
deux adresses avant l ’exécution
si un processus cherche à dépasser ses limites:
interruption
Ch.2 31
89.
Protection de mémoire
l’adressede chaque instruction est comparée à ces
deux adresses avant l’exécution
seulement si le processus exécute en mode usager
si un processus cherche à dépasser ses bornes:
Interruption mode superviseur
les instructions pour affecter les registres bornes sont
privilégiées
Ch.2 32
90.
Appels du système(system
calls)
Ch.2 33
Quand un processus usager a besoin d ’un
service du SE, par ex. E/S, il exécute un appel du
système
C’est une instruction qui cause une interruption
(trap) et changement de mode (mode superviseur)
Est associée à des paramètres qui indiquent le
type de service désiré
Le S/E prend la relève et exécute le service, il
retourne puis au processus appelant avec des
params qui indiquent le type de résultat
changement de mode (mode usager)
91.
Concepts importants duChapitre 2
Ch.2 34
Registres d’UCT, tampons en mémoire, vecteurs
d’interruption
Interruption et polling
Interruptions et leur traitement
Méthodes d’E/S avec et sans attente, DMA
Tableaux de statut de périphériques
Hiérarchie de mémoire
Protection et instructions privilégiées, modes
d’exécution
Registres bornes ou limites
Appels de système
92.
Dans le livre,pour ce chapitre, vous devez
Ch.2 35
Étudier le chapitre entier
La section 2.3 n’a pas été discutée en
classe, cependant son contenu est
important pour la compréhension du
fonctionnement des systèmes
informatiques et sûrement elle est
enseignée dans d’autres cours…
SVP réviser
à discuter plus tard (Chap. 13)
93.
Informations additionnelles
Ch.2 36
Pourdes explics claires sur comment
différents parties d’un ordinateur
fonctionnent, je vous recommande
hautement
http://computer.howstuffworks.com/
Un site qui contient des explications très
claires sur un grand nombre de sujets
(malheureusement, aussi beaucoup de publicité)
94.
1
Structure des Systèmes
d’Exploitation
Chapitre3
Beaucoup de choses dans ce chap. sont faciles à lire
et je vais pas les discuter en classe.
Nous reviendrons sur plusieurs de ces concepts.
Section 3.7 sera discutée dans le lab.
http://w3.uqo.ca/luigi/
95.
Concepts importants duChapitre 3
Ch.3 2
Responsabilités et services d’un SE
Le noyau
Appels du système (system calls)
Communication entre processus
Messagerie et mémoire partagée
Structure à couches
Machines virtuelles
96.
Gestion de processuset UCT
Ch.3 3
Un processus=tâche est un programme en
exécution
il a besoin de ressources pour exécuter (UCT,
mémoire, unités E/S...)
Le SE est responsable pour:
allocation de ressources aux processus
création, terminaison des processus
suspension, reprise des processus
synchronisation, communication entre processus
97.
Gestion de mémoireprincipale (RAM)
Ch.3 4
Le SE est responsable pour:
savoir quels processus utilisent quelles
parties de la mémoire
savoir quels processus en demandent,
et combien
allouer la mémoire quand elle
devient disponible
libérer la mémoire
98.
Ch.3 5
Gestion demémoire virtuelle
mag n etic tapes
optical disk
ma g n etic disk
electro n ic disk
cache
ma i n m em o r y
registers
La mémoire principale est souvent trop petite pour
contenir tous les processus en exécution
La mémoire secondaire (disques, flash) est
normalement utilisée pour contenir les parties
d`un processus qui ne sont pas actives à l ’instant
La mémoire principale et la mémoire secondaire
forment donc une unité logique appelée mémoire
virtuelle
Pour implanter la mémoire virtuelle, le SE doit
gérer de façon conjointe mémoire RAM et
mémoire disque
Mécanisme de va-et-vient (swap)
Hiérarchie de mémoire!
99.
Services primaires desSystèmes
d’exploitation
Ch.3 6
Exécution de programmes: chargement,
exécution (load, run)
Opérations E/S
Manipulation fichiers
Communication et synchronisation entre
processus
Détection et traitement d’erreurs
Le noyau (kernel)du SE
Ch.3 8
La partie résidente (toujours en RAM) du SE est appelée
Kernel = noyau
Les autres parties sont amenées en RAM au besoin
Contient les fonctionnalités critiques du SE: elles doivent
toujours être prêtes à l ’utilisation
traitement d ’interruptions
gestion de UCT
gestion mémoire
communication entre processus
etc.
À part ça, quoi exactement mettre dans le kernel est une
question pour les concepteurs des SE
La plupart des fonctionnalités discutées dans ce cours sont
normalement dans le kernel
102.
Appels du système
Ch.39
L’interface entre un processus et le SE
directement disponibles dans les langages
de programmation `bas niveau`
(assembleur, C, C++)
ils sont cachés dans les langages a
haut niveau (Java, Ada...)
Utilisent des paramètres pour
transmettre
la définition exacte des besoins de l
’usager
le résultat de l`appel
(successful, unsuccessful...)
103.
Interpréteur de commandesen UNIX
Le command interpreter (shell) peut démarrer et charger
différents processus en mémoire, exécutant des appels de
système appropriés (fork, exec). Lire détails dans le livre, aussi
v. sessions exercices.
Ch.3 10
104.
Deux modèles decommunication entre
processus par appels de système
a) transfert de messages entre processus (message
passing)
- utilisant le service de messagerie offert par le noyau
b) à travers mémoire partagée entre processus (shared
Ch.3 11
105.
Messagerie et mémoirepartagéé
Messagerie:
il faut établir une connexion entre processus (appels
de système open connection, accept connection, close
connection, read/send message)
les processus s ’envoient des messages utilisant
des identificateurs préalablement établis
Mémoire partagée
il est nécessaire d ’établir une zone de
communication entre processus
les processus doivent mutuellement synchroniser
leur accès a cette zone
Pour ceci, il font appel au SE (Chap. 7)
v. chap. 7: synchro de proc.
Ch.3 12
106.
Programmes système
Pas partiedu kernel, en augmentent la fonctionnalité.
Voir discussion et exemples dans le livre
Ch.3 13
107.
Partage de responsabilitésentre programmes
de systèmes et noyau
Ch.3 14
C’est en partie une décision de conception de SE
de décider quelles fonctionnalités doivent être
implémentées dans le kernel, et quelles dans les
programmes de système.
Dans l ’évolution des SE il y a eu un transfert de
fonctionnalités vers l ’extérieur de la figure
précédente
Dans les SE modernes, les programmes de
système sont l`interface entre usager et noyau
108.
Structure en couchesdans les SE modernes
Ch.3 15
Un SE est divisé dans un certain nombre
de couches, bâties les unes sur les
autres
la couche la plus basse est le matériel
la plus élevée est l ’interface usagers
Les couches supérieures utilisent les
fonctionnalités fournies par les niveaux
inférieurs
109.
Structure à couches
opérationscréées dans une couche pour les couches extérieures
opérations fournies par une couche, utilisées par la prochaine
couche, et cachées aux couches extérieures
opérations d ’une couche intérieure rendues disponibles à une
couche extérieure
à éviter en principe, mais… v. après
Ch.3 16
110.
Structure à couchesdans le système THE
(1968)
Ch.3 17
La structure à couches fut inventée dans le système
THE (E.W. Dijkstra) qui avait les couches suivantes:
Interface usager
programmes usagers
gestion E/S
pilotage console opérateur
gestion mémoire et tampons
gestion UCT
matériel
111.
L’autre possibilité seraitla structure réseau
Plus difficile à gérer, à cause des
nombreuses interfaces possibles
À
couches
Ch.3 18
Réseau
112.
Avantages, désavantages desuivre fidèlement une
structure en couches
Ch.3 19
Avantages:
Chaque couche ne doit connaître que les
fonctionnalités fournies par la couche
immédiatement sous-jacente
Chaque couche ajoute ses propres fonctionnalités
Les erreurs peuvent plus facilement être isolés
dans une couche spécifique
Maison construite un étage à la fois… poser
l’étage n seulement quand l’n-1 est solide
Désavantages:
Pas efficace car un appel des programmes
usager à des ressources du matériel implique
autant d’appels qu’il y a des couches
intermédiaires
Excellent principe, pas toujours fidèlement
suivi
113.
Structure de système- Approche simple
Ch.3 20
MS-DOS - cherchait à obtenir une fonctionnalité
maximale avec des ressources limitées
mono-tâche, mono-usager
pas très modularisé
manque de séparation claire entre couches
accès direct aux périphériques (écran, etc.) permis
aux programmes d`application
manque de contrôles, vulnerabilité
malheureusement, il fut adapté à des
fonctionnalités plus complexes...
Fut la prémière base de Windows et une grande partie
de l’histoire de Windows a été un effort de dépasser
les limitations de MS-DOS
Structure UNIX
Ch.3 22
Multi-tâches,multi-usagers depuis le début
Le système UNIX initial était aussi préoccupé par
les limitation du matériel
Distinction entre:
programmes du système
noyau
tout ce qu’il y a entre l ’interface des appels de
système et le matériel
fournit dans une seule couche un grand
nombre de fonctionnalités
• système fichiers, ordonnancement UCT, gestion
mémoire...
Plus modulaire et protégé que MS-DOS
Micronoyaux (microkernels)
Ch.3 24
Dansles premiers SE, aussi UNIX, tout
était dans le noyau
Après, un effort fut fait pour laisser dans le
noyau UNIX seulement les fonctionnalités
absolument nécessaires
Une des fonctionnalités du micronoyau
UNIX est la communication par échange de
messages
utilisé pour la communication entre
programme client et service
118.
25
Structure à couchesdans OS/2 (IBM)
suit les idées d’unix
L ’OS/2 était beaucoup mieux organisé que MS-DOS, et donc
moins vulnérable. Cependant il était peu performant.
Win-NT a cherché à utiliser des principes semblables, mais
avec une
119.
Structure client-serveur dansnoyau Win-NT
Win-NT a un petit noyau qui fournit une structure client-
serveur
, enutilisant échanges de messages
Supporte différents SE: Win, OS/2, Posix
Ch.3 26
120.
Machines virtuelles: leproblème et la
solution
Ch.3 27
Comment permettre de rouler différents SE
sur une seule machine physique?
Pas évident, car chaque SE demande
accès direct au matériel
SOLUTION: Un programme qui crée une
couche qui met à disposition plusieurs
machines physiques virtuelles
Chaque machine se comporte comme une
machine physique séparée
Sur chacune, nous pouvons rouler un SE
différent
121.
Machines Virtuelles
Ch.3 28
Virtuelen informatique dénote quelque chose qui
n ’est pas réel, n ’est pas du matériel: il est
construit par le logiciel sur la base des
ressources fournies par le matériel
Une machine virtuelle est une machine créée
par des couche de logiciel
Elle peut avoir des caractéristiques identiques à la
machine physique du système:
mêmes instructions, etc.
Ou elle peut ‘simuler’ une autre machine physique
p.ex.pour exécuter Microsoft sur Apple
Plusieurs machines virtuelles peuvent être créées
sur une machine physique donnée!
122.
(a) Une seulemach. réelle et un seul
noyau
Ch.3 29
(b) plus. mach. virtuelles et plus.
noyaux
123.
Fonctionnement typique
Le systèmeVM laisse exécuter normalement les
instructions non privilégiées
Les appels au système sont exécutés par le
système VM et les résultats sont passés à la
machine virtuelle sur laquelle le processus
exécute
Ch.3 30
124.
Avantages
Chaque machine virtuellepeut utiliser un
SE différent!
En théorie, on peut bâtir des machines
virtuelles sur des machines virtuelles!
Protection complète, car les machines
virtuelles sont complètement isolées les
unes des autres
Un nouveau SE peut être développé sur
une machine virtuelle sans déranger les
autres
Ch.3 31
125.
Implémentations
Ch.3 32
Le conceptde VM est très utilisé pour
permettre de rouler un SE sur un autre
P.ex. SUN, Apple, Linux permettent de
rouler Windows sur leur plateforme,
Ils doivent fournir à Windows un
environnement que Windows reconnaît
comme son environnement Intel usuel
126.
Concepts importants duChapitre 3
Ch.3 33
Responsabilités et services d’un SE
Le noyau
Appels du système (system calls)
Communication entre processus
Messagerie et mémoire partagée
Structure à couches
Machines virtuelles
127.
Par rapport aumanuel…
Ch.3 34
Étudier sections 3.1 jusqu’à 3.6.
La section 3.7 n’a pas été discutée en
classe mais elle contient des concepts
importants concernant Java donc c’est une
excellente idée de la lire
Les sections 3.8 et 3.9 ne sont pas sujet
d’examen cependant il est utile de les
lire.
Concepts importants duChapitre 4
Ch.4 2
Processus
Création, terminaison, hiérarchie
États et transitions d’état des processus
Process Control Block
Commutation de processus
Sauvegarde, rechargement de PCB
Files d’attente de processus et PCB
Ordonnanceurs à court, moyen, long terme
Processus communicants
Producteurs et consommateurs
130.
Processus et
terminologie
Ch.4 3
(aussiappelé job, task, user program)
Concept de processus: un programme en
exécution
Possède des ressources de mémoire,
périphériques, etc
Ordonnancement de processus
Opérations sur les processus
Processus coopérants
Processus communicants
131.
Création de processus
Ch.44
Les processus peuvent créer d’autres
processus, formant une hiérarchie
(instruction fork ou semblables)
132.
Terminaison de processus
Ch.45
Un processus exécute sa dernière
instruction
pourrait passer des données à son
parent
ses ressources lui sont enlevées
Le parent termine l’exécution d’un fils
(avortement) pour raisons différentes
le fils a excédé ses ressources
le fils n`est plus requis
etc.
État de processusIMPORTANT
Ch.4 7
Au fur et a mesure qu’un processus
exécute, il change d’état
nouveau: le processus vient d ’être
créé
exécutant-running: le processus est en
train d ’être exécuté par l ’UCT
attente-waiting: le processus est en train
d ’attendre un événement (p.ex. la fin d
’une opération d ’E/S)
prêt-ready: le processus est en attente
d’être exécuté par l ’UCT
terminated: fin d ’exécution
États Nouveau,
Terminé:
Nouveau
LeSE a créé le processus
a construit un identificateur pour le processus
a construit les tableaux pour gérer le processus
mais ne s’est pas encore engagé à exécuter
le processus (pas encore admis)
pas encore alloué des ressources
La file des nouveaux travaux est souvent
appelée spoule travaux (job spooler)
Terminé:
Le processus n ’est plus exécutable, mais ses
données sont encore requises par le SE
(comptabilité, etc.)
Ch.4 9
137.
Transitions entre processus
Prêt Exécution
Lorsque l ’ordonnanceur UCT choisit
un processus pour exécution
Exécution Prêt
Résultat d’une interruption causée par
un événement indépendant du
processus
Il faut traiter cette interruption,
donc le processus courant perd
l’UCT
• Cas important: le processus à épuisé son intervalle
de temps (minuterie)
Ch.4 10
138.
Transitions entre processus
Exécution Attente
Lorsqu’un processus fait un appel de
système
(interruption causée par le processus lui-même)
initie une E/S: doit attendre le résultat
a besoin de la réponse d’un autre processus
Attente Prêt
lorsque l'événement attendu se produit
Ch.4 11
139.
Sauvegarde d’informations processus
Ch.412
En multiprogrammation, un processus exécute
sur l ’UCT de façon intermittente
Chaque fois qu’un processus reprend l ’UCT
(transition prêt exécution) il doit la reprendre
dans la même situation où il l’a laissée (même
contenu de registres UCT, etc.)
Donc au moment où un processus sort de l’état
exécution il est nécessaire de sauvegarder ses
informations essentielles, qu’il faudra récupérer
quand il retourne à cet état
140.
PCB = ProcessControl Block:
Représente la situation actuelle d ’un processus,
pour le reprendre plus tard
Registres
UCT
Ch.4 13
141.
Process Control Block(PCB) IMPORTANT
pointeur: les PCBs sont rangés dans des
listes enchaînées (à voir)
état de processus: ready, running, waiting…
compteur programme: le processus
doit reprendre à l ’instruction
suivante
autres registres UCT
bornes de mémoire
fichiers qu’il a ouvert
etc., v. manuel
Ch.4 14
142.
Commutation de
processeur
Ch.4 15
Aussiappélé commutation de contexte ou context
switching
Quand l’UCT passe de l’exécution d ’un
processus 0 à l ’exécution d`un proc 1, il
faut
mettre à jour et sauvegarder le PCB de
0
reprendre le PCB de 1, qui avait
été sauvegardé avant
remettre les registres d ’UCT tels que le
compteur d ’instructions etc. dans la
même situation qui est décrite dans le
PCB de 1
143.
Ch.4 16
Commutation deprocesseur (context
switching)
Il se peut que beaucoup de temps passe avant le
retour au processus 0, et que beaucoup d’autres proc
soient exécutés entre temps
144.
Le PCB n’est pas la seule
information à sauvegarder... (le manuel n’est
pas clair ici)
Ch.4 17
Il faut aussi sauvegarder l ’état des
données du programme
Ceci se fait normalement en gardant
l ’image du programme en mémoire
primaire ou secondaire (RAM ou
disque)
Le PCB pointera à cette image
145.
La pile d’unprocessus (v. Stallings App.
1B) aussi à sauvegarder
Ch.4 18
Quand un processus fait appel à une procédure, à une
méthode, etc., il est nécessaire de mettre dans une pile
l’adresse à laquelle le processus doit retourner après
avoir terminé cette procédure, méthode, etc.
Aussi on met dans cette pile les variables locales de
la procédure qu’on quitte, les paramètres, etc., pour
les retrouver au retour
Chaque élément de cette pile est appelé stack frame
ou cadre de pile
Donc il y a normalement une pile d’adresses de retour après
interruption et une pile d’adresses de retour après appel de
procédure
Ces deux piles fonctionnent de façon semblable, mais
sont indépendantes
Les informations relatives à ces piles (base, pointeur…)
doivent aussi être sauvegardées au moment de la
commutation de contexte
146.
La Pile d’unprocessus
Appel
A
Appel
B
Ch.4 19
P
A
B
Données B
Données A
Données P
PIL
E
147.
Ch.4
Pointeurs de pileprocessus à sauvegarder:
base et borne
cadre 4
cadre 3
cadre 2
cadre 1
pointeur de
base
pointeur de
borne
La pile fait normal. partie de l’image du programme, mais les
pointeurs sont normal. des registres d’UCT donc il sont
148.
Ch.4 21
Rôle dumatériel et du logiciel dans le
traitement
d’interruptions
MATÉRIEL LOGICIEL
Signal d’interruption généré
UCT termine l’instruction
courante et détecte
interruption
Registres d’UCT sont
sauvegardés dans une
pile
UCT saute à l’adresse trouvée
dans le vecteur
d’interruption
Infos mises à jour et
sauvegardées dans
PCB
Le code de traitement
de l’interruption est
exécuté
L’ordonnanceur choisit
un processus dans la file
prêt
Les registres d’UCT sont
rechargés avec ce qu’on avait
sauvegardé dans PCB pour ce
processus,
Les infos relatives à ce
processus sont rétablies à partir
de son PCB
dispatche
r
149.
Files d’attente IMPORTANT
Ch.422
Les ressources d ’ordinateur sont souvent
limitées par rapport aux processus qui en
demandent
Chaque ressource a sa propre file de processus
en attente
À un moment donné, un proc ne peut se trouver
que dans une seule des différentes files du SE
En changeant d’état, les processus se déplacent
d ’une file à l`autre
File prêt: les processus en état prêt=ready
Files associés à chaque unité E/S
etc.
150.
Ce sont lesPCBs qui sont dans les
files d’attente (dont le besoin d ’un pointeur
dans le PCB)
file prêt
Nous ferons l’hypothèse que le premier processus dans une file
est celui qui utilise la ressource: ici, proc7 exécute, proc3 utilise
disque 0, etc.
Ch.4 23
151.
Ch.4
Cet ensemble defiles inclut donc la table de
statut périphériques (fig. au Chap. 2)
2 fois la même erreur ici: imprimante devrait être
152.
Une façon plussynthétique de décrire la
mêmesituation (pour les devoirs et les examens)
prêt 7
2
bandmag0
bandmag1
Ch.4 25
153.
Les PCBs nesont pas déplacés en
mémoire
pour être mis dans les différentes
files: ce sont les pointeurs qui
changent.
ready
disk unit 0
. . . . . .
PCB2 PCB3 PCB4 PCB5 PCB6 PCB7 PCB14
term. unit 0
Ch.4 26
154.
Ordonnanceurs (schedulers)
Ch.4 27
Programmesqui gèrent l ’utilisation de
ressources de l`ordinateur
Trois types d`ordonnanceurs :
À court terme = ordonnanceur
processus: sélectionne quel processus
doit exécuter la transition prêt
exécution
À long terme = ordonnanceur travaux:
sélectionne quels processus peuvent
exécuter la transition nouveau prêt
(événement admitted) (de spoule travaux à file
prêt)
À moyen terme: nous verrons
155.
Ordonnanceur travaux =long terme
et ordonnanceur processus = court terme
Ch.4 28
Ordonnanceur
travaux
Ordonnanceur
processus
156.
Ordonnanceurs
Ch.4 29
L`ordonnanceur àcourt terme est exécuté
très souvent (millisecondes)
doit être très efficace
L`ordonnanceur à long terme doit être
exécuté beaucoup plus rarement: il
contrôle le niveau de multiprogrammation
Un des ses critères pourrait être la
bonne utilisation des ressources de
l’ordinateur
P.ex. établir une balance entre travaux liés
à l’UCT et ceux liés à l ’E/S
Ordonnanceur à moyenterme
Ch.4 31
Le manque de ressources peut parfois
forcer le SE à suspendre des processus
ils seront plus en concurrence avec les
autres pour des ressources
ils seront repris plus tard quand les
ressources deviendront disponibles
Ces processus sont enlevés de mémoire
centrale et mis en mémoire secondaire,
pour être repris plus tard
`swap out`, `swap in` , va-et-vien
États de processusdans UNIX SVR4
(Stallings) Un exemple de diagramme de transitions d’états pour
un SE réel
Kernel, user
mode =monitor
,
user mode 3
Ch.4 3
161.
Processus coopérants
Ch.4 34
Lesprocessus coopérants peuvent
affecter mutuellement leur exécution
Avantages de la coopération entre
processus:
partage de l ’information
efficacité en faisant des tâches en
parallèle
modularité
la nature du problème pourrait le
demander
P.ex. gestion d’événements
indépendants
162.
Ch.4 35
Le pbdu producteur - consommateur
Un problème classique dans l ’étude des
processus communicants
un processus producteur produit des
données (p.ex.des enregistrements d ’un
fichier) pour un processus consommateur
un pgm d’impression produit des
caractères -- consommés par une
imprimante
un assembleur produit des modules objet
qui seront consommés par le chargeur
Nécessité d’un tampon pour stocker les
items produits (attendant d’être
163.
Ch.4 36
Tampons decommunication
Prod
1 donn
Cons
Prod
Cons
1 donn 1 donn 1 donn
Si le tampon est de longueur 1, le producteur et
consommateur doivent forcement aller à la même vitesse
Des tampons de longueur plus grandes permettent une
certaine indépendance. P
.ex. à droite le
164.
Le tampon borné(bounded
buffer)
une structure de données fondamentale dans les
SE
b[0] b[1]
b[7] b[2]
b[6] b[3]
b[5] b[4]
ou
in: 1ère
pos. libre
out: 1ère
pos. pleine
Le tampon borné se trouve dans la mémoire partagée
entre consommateur et usager
b[0] b[1] b[2] b[3] b[4] b[5] b[6] b[7]
in: 1ère
pos. libre
Ch.4 37
out: 1ère
pos.
pleine
bleu: plein, blanc:
libre
À l’écriture d’une nouvelle info dans le tampon, le producteur
met à jour le pointeur in
Si le tampon est plein, le prod devra s’endormir, il sera plus
tard réveillé par le consommateur
Le rôle du consommateur est symétrique (v. Chap. 7)
165.
Utilisation du conceptdu tampon borné
Ch.4 38
Les tampons bornés sont partout en informatique,
et partout dans les SE
Les files utilisées dans un SE sont des tampons
bornés:
‘pipes’ dans Unix
files d’attente pour ressources: file prêt, files
pour imprimante, pour disque, etc.
Les protocoles de communications utilisent des
tampons bornés: TCP, et autres
Un client communique avec un serveur par des
tampons bornés, etc.
166.
Concepts importants duChapitre 4
Ch.4 39
Processus
Création, terminaison, hiérarchie
États et transitions d’état des processus
Process Control Block PCB
Commutation de processus
Sauvegarde, rechargement de PCB
Files d’attente de processus et PCB
Ordonnanceurs à court, moyen, long terme
Processus communicants
Producteurs et consommateurs
167.
Par rapport aumanuel…
Ch.4 40
Tout à étudier à l’exception des sections
4.5.1, 4.5.2, 4.5.3, 4.5.6 et 4.5.7
Les exemples contenant du code Java et C
seront expliqués aux sessions d’exercices
168.
Threads et Lightweight
Processes
Chapitre5
En français on utilise parfois ‘flots’
ou ‘fils’ pour ‘threads’.
Votre manuel préfère le mot anglais
http://w3.uqo.ca/lui
gi/
169.
Concepts importants duChap. 5
Ch.5 2
Threads et processus: différence
Threads de noyau et d’usager: relations
LWP: lightweight processes, threads
légers
170.
Flots = threads= lightweight processes
Ch.5 3
Un thread est une subdivision d`un
processus
Un fil de contrôle dans un
processus
Les différents threads d ’un processus
partagent l’espace adressable et les
ressources d’un processus
lorsqu’un thread modifie une
variable (non locale), tous les autres
threads voient la modification
un fichier ouvert par un thread est
accessible aux autres threads (du même
processus)
171.
Exemple
Ch.5 4
Le processusMS-Word implique plusieurs
threads:
Interaction avec le clavier
Rangement de caractères sur la page
Sauvegarde régulière du travail fait
Contrôle orthographe
Etc.
Ces threads partagent tous le même
document
Processu
s
Ch.5 7
Possède samémoire, ses fichiers, ses
ressources, etc.
Accès protégé à la mémoire, fichiers,
ressources d’autres processus
175.
Thread
Ch.5 8
Possède unétat d’exécution (prêt, bloqué…)
Possède sa pile et un espace privé pour
variables locales
A accès à l’espace adressable, fichiers et
ressources du processus auquel il
appartient
En commun avec les autres threads du
même proc
176.
Pourquoi les threads
Ch.59
Reactivité: un processus peut être
subdivisé en plusieurs threads, p.ex. l’un
dédié à l’interaction avec les usagers,
l’autre dédié à traiter des données
L’un peut exécuter tant que l’autre est
bloqué
Utilisation de multiprocesseurs: les
threads peuvent exécuter en parallèle sur
des UCT différentes
177.
La commutation entrethreads est
moins
dispendieuse que la commutation
entre processus
Un processus possède mémoire, fichiers,
autres ressources
Changer d`un processus à un autre
implique sauvegarder et rétablir l’état de
tout ça
Changer d’un thread à un autre dans le
même proc est bien plus simple, implique
sauvegarder les registres de l ’UCT, la pile,
et peu d ’autres choses
Ch.5 10
178.
La communication aussiest moins
dispendieuse entre threads que entre
processus
Ch.5 11
Étant donné que les threads partagent leur
mémoire,
la communication entre threads dans un
même processus est plus efficace
que la communication entre processus
179.
La création estmoins dispendieuse
Ch.5 12
La création et terminaison de nouveaux
threads dans un proc existant est aussi
moins dispendieuse que la création d’un
proc
180.
Threads de noyau(kernel) et d’utilisateur
Ch.5 13
Où implémenter les threads:
Dans les bibliothèques
d’usager
contrôlés par l’usager
Dans le noyau du SE:
contrôlés par le noyau
Solutions mixtes
181.
Threads d’utilisateur etde noyau
(kernel)
Ch.5 14
threads d’utilisateur: supportés par des
bibliothèques d’usager ou langage de prog
efficace car les ops sur les threads ne demandent
pas des appels du système
désavantage: le noyau n ’est pas capable de
distinguer entre état de processus et état des
threads dans le processus
blocage d ’un thread implique blocage du processus
threads de noyau: supportés directement par le
noyau du SE (WIN NT, Solaris)
le noyau est capable de gérer directement les états
des threads
Il peut affecter différents threads à différentes UCTs
182.
Solutions mixtes: threadsutilisateur et noyau
Ch.5 15
Relation entre threads utilisateur et threads noyau
plusieurs à un
un à un
plusieurs à plusieurs
Nous devons prendre en considération plusieurs
niveaux:
Processus
Thread usager
Thread noyau
Processeur (UCT)
183.
Plusieurs threads utilisateurpour un thread
noyau:
l’usager contrôle les threads
Ch.5 16
usage
r
noya
u
Le SE ne connaît pas les threads utilisateur
v. avantages et désavantages mentionnés avant
184.
Un vers un:le SE contrôle les threads
Les ops sur les threads sont des appels du
système
Permet à un autre thread d’exécuter lorsqu’un
thread exécute un appel de système
bloquant
Win NT, XP, OS/2
usage
r
noya
u
Ch.5 17
185.
Plusieurs à plusieurs:solution mixte
Ch.5 18
usager
noyau
Flexibilité pour l ’usager d ’utiliser la technique qu’il préfère
Si un thread utilisateur bloque, son kernel thread peut être affecté à
un autre
Si plus. UCT sont disponibles, plus. kernel threads peuvent
exécuter en même temps
Quelques versions d’Unix, dont Solaris
186.
Ch.5 19
Threads dansSolaris 2 (une version de
Unix)
Plusieurs à
plusieurs, usager et
Tâche =
processus
187.
Processus légers (lightweight,LWP)
Fonctionnent comme des UCT virtuelles, pouvant
exécuter des threads niveau usager
Sont entre les threads usager et les threads
noyau
Il y a un thread noyau pour chaque LWP, chaque
LWP est lié à son propre thread noyau
Chaque processus doit contenir au moins un
LWP
La bibliothèque des threads exécute les threads
utilisateur sur les LWP disponibles
Seulement les threads qui sont associés à un LWP
peuvent exécuter, les autres sont en attente
d ’exécuter (bloqués)
similarité avec ordonnancement UCT
Ch.5 20
188.
Threads à niveauusager: liés et libres
Ch.5 21
Un thread à niveau usager est lié s’il est
attaché à un LWP de façon permanente
Est non lié sinon
189.
Utilisation des L
WP
Ch.522
Les LWP sont demandés quand un thread usager
a besoin de communiquer avec le noyau
Appel système (E/S…)
car dans ce cas un nouveau thread peut exécuter
tant que l’autre est bloqué en attente
Il y a besoin d ’un LWP pour chaque thread qui
devient bloqué pour un appel de système
p.ex. s ’il y a 5 threads qui demandent de l ’E/S,
nous avons besoin de 5 LWP
s`il y a seul. 4 LWP, une des demandes d ’E/S
doit attendre qu ’un LWP devienne libre ou soit
créé
190.
Exécution des L
WP
Lesthreads de noyau qui implémentent les LWP exécutent
sur les UCT qui deviennent disponibles
Si un thread noyau se bloque, son LWP se bloque aussi,
mais un processus (tâche) peut en obtenir un
autre, ou un nouveau LWP peut être créé
Si un LWP devient bloqué, l’UCT qui l’exécute peut être
affectée à un autre thread
Ch.5 23
191.
Création et terminaisondynamique de L
WP
Ch.5 24
La biblio. de threads à niveau usager crée
automatiquement des nouveaux LWP au
besoin
Termine les LWP qui ne sont plus
demandés
192.
Structures de données:Solaris
Une tâche=processus Solaris peut être associée à
plusieurs LWP
Un LWP contient un ensemble de registres, des
infos de mémoire et de comptabilisation
Les structures des données sont essentiellement
des PCBs enchaînés
Ch.5 25
193.
Les Java threadsimplémentent ces
idées
Ch.5 26
Il y aura discussion sur les Java
threads dans le lab
194.
Multithreads et monothreads
Ch.527
MS-DOS supporte un processus usager à
monothread
UNIX SVR4 supporte plusieurs processus à
monothread
Solaris, Widows NT, XP et OS2 supportent
plusieurs processus multithreads
195.
Concepts importants duChap. 5
Ch.5 28
threads et processus: différence
threads de noyau et d’usager: relations
LWP: lightweight processes, threads
légers
Implémentation en utilisant UCT
physiques
196.
Quoi lire dansle
livre
Ch.5 29
En classe, nous avons vu seulement
5.1- 5.5
Mais pendant les sessions exercices vous
verrez la partie Java
Donc tout le chapitre…
Files d’attente deprocessus
pour ordonnancement
Ch. 6 4
file prêt
Nous ferons l’hypothèse que le premier processus dans une file
est celui qui utilise la ressource: ici, proc7 exécute
201.
Concepts de base
Ch.6 5
La multiprogrammation vise à obtenir une
utilisation optimale des ressources, surtout l’UCT
et aussi à un bon temps de réponse pour l’usager
L`ordonnanceur UCT est la partie du SE qui décide
quel processus dans la file ready/prêt obtient
l ’UCT quand elle devient libre
L ’UCT est la ressource la plus précieuse dans un
ordinateur, donc nous parlons d’elle
Cependant, les principes que nous verrons
s ’appliquent aussi à l ’ordonnancement des
autres ressources (unités E/S, etc).
202.
Les cycles d’unprocessus
Cycles (bursts) d’UCT et E/S: l’exécution d’un processus
consiste de séquences d’exécution sur UCT et d’attentes
E/S
Ch. 6 6
203.
Ch. 6 7
Observationexpérimentale:
dans un système typique, nous observerons un grand
nombre de court cycles, et un petit nombre de long cycles
Les programmes tributaires de l ’UCT auront normalm. un
petit nombre de long cycles UCT
Les programmes tributaires de l’E/S auront normalm. un
grand nombre de court cycles UCT
Histogramme de durée des cycles UCT
204.
Quand invoquer l’ordonnanceur
UCT
L’ordonnanceur UCT doit prendre sa décision chaque fois que le
processus exécutant est interrompu, c’e-à.-d.
1. un processus se se présente en tant que nouveau ou se
termine
2. un processus exécutant devient bloqué en attente
3. un processus change d’exécutant/running à prêt/ready
4. un processus change de attente à prêt/ready
•
• en conclusion, tout événement dans un système cause
une interruption de l’UCT et l’intervention de
l’ordonnanceur,
qui devra prendre une décision concernant quel proc ou thread
aura l’UCT après
Préemption: on a préemption si on enlève l’UCT à un processus
qui l’avait et ne l’a pas laissée de propre initiative
P.ex. préemption dans le cas 3, pas de préemption dans le
cas 2
Plusieurs pbs à résoudre dans le cas de préemption, v. manuel
Ch. 6 8
205.
Dispatcheur
Ch. 6 9
Leprocessus qui donne le contrôle au
processus choisi par l’ordonnanceur. Il
doit se préoccuper de:
changer de contexte
changer à mode usager
réamorcer le processus choisi
Attente de dispatcheur (dispatcher
latency)
le temps nécessaire pour exécuter
les fonctions du dispatcheur
il est souvent négligé, il faut supposer qu’il
soit petit par rapport à la longueur d’un
cycle
206.
Critères d’ordonnancement
Ch. 610
Il y aura normalement plusieurs processus
dans la file prêt
Quand l’UCT devient disponible, lequel
choisir?
Critères généraux:
Bonne utilisation de l’UCT
Réponse rapide à l’usager
Mais ces critères peuvent être jugés
différemment...
207.
Critères spécifiques d’ordonnancement
Ch.6 11
Utilisation UCT: pourcentage d ’utilisation
Débit = Throughput: nombre de processus
qui complètent dans l ’unité de temps
Temps de rotation = turnaround: le temps
pris par le proc de son arrivée à sa termin.
Temps d’attente: attente dans la file prêt
(somme de tout le temps passé en file prêt)
Temps de réponse (pour les systèmes
interactifs): le temps entre une demande et
la réponse
208.
Critères d’ordonnancement: maximiser/minimiser
Ch.6 12
Utilisation UCT: pourcentage d’utilisation
ceci est à maximiser
Débit = Throughput: nombre de processus qui
complètent dans l ’unité de temps
ceci est à maximiser
Temps de rotation (turnaround): temps
terminaison moins temps arrivée
à minimiser
Temps d’attente: attente dans la file
prêt
à minimiser
Temps de réponse (pour les systèmes interactifs):
le temps entre une demande et la réponse
209.
Examinons maintenant plusieursméthodes
d’ordonnancement et voyons comment elles
se comportent par rapport à ces critères
Ch. 6 13
nous étudierons des cas spécifiques
l’étude du cas général demanderait recours à techniques probabilistes ou
de simulation
210.
Premier arrive, premierservi (First come, first serve,
FCFS)
Ch. 6 14
Exemple
:
Processu
s P1
P2
P
3
Temps de
cycle 24
3
3
Si les processus arrivent au temps 0 dans l’ordre: P1 ,
P2 , P3Le diagramme Gantt est:
P1 P2 P3
30
0 24
27
Temps d’attente pour P1= 0; P2= 24;
P3= 27Temps attente moyen: (0
+ 24 + 27)/3 = 17
211.
Premier arrive, premierservi
Ch. 6 15
Utilisation UCT = 100%
Débit = 3/30 = 0,1
3 processus complétés en 30 unités de temps
Temps de rotation moyen: (24+27+30)/3 = 27
P1 P2 P3
24 27 30
0
212.
Tenir compte dutemps d’arrivée!
Dans le cas où les processus arrivent à moment
différents, il faut soustraire les temps d’arrivée
Exercice: répéter les calculs si:
P1 arrive à temps 0 et dure 24
P2 arrive à temps 2 et dure 3
P3 arrive à temps 5 et dure 3
Donc P1 attend 0 comme avant
Mais P2 attend 24-2, etc.
P1 P2 P3
24 27 30
0
arrivée
P2
Ch. 6 16
213.
FCFS Scheduling (Cont.)
Ch.6 17
Si les mêmes processus arrivent à 0 mais dans l’ordre
P2 , P3 , P1 .
Le diagramme de Gantt est:
Temps moyen d’attente: (6 + 0 + 3)/3 = 3
Temps de rotation moyen: (3+6+30)/3 = 13
Beaucoup mieux!
Donc pour cette technique, les temps peuvent varier
grandement par rapport à l’ordre d’arrivée de différent
processus
Exercice: calculer aussi le débit, etc.
P2 P3 P1
30
0 3 6
Temps d’attente pour P1 = 6 P2 = 0 P3 = 3
214.
Effet d’accumulation (convoyeffect) dans FCFS
Ch. 6 18
Supposons un processus tributaire de l’UCT et plusieurs
tributaires de l`E/S (situation assez normale)
Les processus tributaires de l’E/S attendent pour l ’UCT: E/S sous-
utilisée (*)
Le processus tributaire de l’UCT fait une E/S: les autres proc
exécutent rapidement leur cycle UCT et retournent sur l’attente E/S:
UCT sous-utilisée
Processus tributaire de l’UCT fini son E/S, puis les autres procs
aussi : retour à la situation (*)
Donc dans ce sens FCFS favorise les procs tributaires de l’UCT
Et peut conduire à une très mauvaise utilisation des ressources
Tant d’UCT que de périphériques
Une possibilité: interrompre de temps en temps les proc tributaires
de l’UCT pour permettre aux autres procs d’exécuter (préemption)
215.
Plus Court d’abord= Shortest Job First (SJF)
Le processus qui demande moins
d’UCT part le premier
Optimal en principe du point de vue
du temps d’attente moyen
(v. le dernier exemple)
Mais comment savons-nous quel
processus demande moins d’UCT!
Ch. 6 19
216.
SJF avec préemptionou non
Ch. 6 20
Avec préemption: si un processus qui dure moins
que le restant du processus courant se présente
plus tard, l’UCT est enlevée au proc courant et
donnée à ce nouveau processus
SRTF: shortest remaining-time first
Sans préemption: on permet au processus
courant de terminer son cycle
Observation: SRTF est logique pour l’UCT car le processus
exécutant sera interrompu par l’arrivée du nouveau
processus
Il est retourné à l’état prêt
Il est impossible pour les unités qui ne permettent
pas de préemption
p.ex. une unité disque, imprimante…
Ch. 6 22
Exemplede SJF avec préemption
Processus Arrivée Cycle
P1 0 7
P2 2 4
P3 4 1
P4 5 4
SJF (préemptive)
Temps moyen d`attente = (9 + 1 + 0 +2)/4 = 3
P1 attend de 2 à 11, P2 de 4 à 5, P4 de 5 à 7
Temps de rotation moyen = 16+ (7-2) + (5-4) + (11-5) = 7
11
0 4 5
7
P1 P2 P3 P2 P4 P1
16
2
P2 arr. P3 arr. P4 arr
219.
Comment déterminer lalongueur des cycles à
l’avance?
Ch. 6 23
Quelques méthodes proposent de
déterminer le comportement futur d
’un processus sur la base de son passé
p.ex. moyenne exponentielle
220.
Estimation de ladurée du prochain cycle
Ch. 6 24
Ti : la durée du ième cycle de l’UCT pour ce
processus
Si : la valeur estimée du le ième cycle de l’UCT
pour ce processus. Un choix simple est:
S n+1 = (1/n) _{i=1 to n} Ti (une simple
moyenne)
Nous pouvons éviter de recalculer la somme en
récrivant:
Sn+1 = (1/n) Tn + ((n-1)/n) Sn
Ceci donne un poids identique à chaque cycle
221.
Estimation de ladurée du prochain
cycle
Ch. 6 25
Mais les cycles récents peuvent être plus
représentatifs des comportements à venir
La moyenne exponentielle permet de donner
différents poids aux cycles plus ou moins
récents:
Sn+1 = Tn+ (1-) Sn ; 0 <=
<= 1
Par expansion, nous voyons que le poids de
chaque cycle décroît exponentiellement
Sn+1 = Tn + (1-)Tn-1 + ... (1-)i Tn-i +
... + (1-)n S1
la valeur estimée S1 du 1er cycle peut être
fixée à 0 pour donner priorité max. aux
nouveaux processus
222.
Importance de différentsvaleurs de coefficients
[Stallings]
Peu d’import. aux cycles
récents
Beaucoup d’import aux cycles
récs
Ch. 6 26
Stallings
223.
Importance de différentsvaleurs de coefficients
[Stallings]
S1 = 0 (priorité aux nouveaux processus)
Un coefficient plus élevé réagit plus rapidement aux
changements de comportement
Ch. 6 27
Stallings
Comment choisir lecoefficient
Ch. 6 29
Un petit coefficient est avantageux quand un
processus peut avoir des anomalies de
comportement, après lesquelles il reprend son
comportement précédent (il faut ignorer son
comportement récent)
cas limite: = 0 on reste sur l ’estimée initiale
Un coefficient élevé est avantageux quand un
processus est susceptible de changer rapidement
de type d’activité et il reste sur ça
cas limite: S n+1 = Tn
Le dernier cycle est le seul qui compte
226.
Le plus courtd’abord SJF:
critique
Ch. 6 30
Difficulté d’estimer la longueur à l’avance
Plus pratique pour l’ordonnancement travaux que
pour l’ordonnancement processus
on peut plus facilement prévoir la durée d’un travail
entier que la durée d’un cycle
Il y a assignation implicite de priorités: préférences
aux travaux plus courts
227.
Difficultés majeures avecles méthodes
discutées
Ch. 6 31
Un processus long peut monopoliser
l’UCT s’il est le 1er à entrer dans le
système et il ne fait pas d’E/S
Dans le cas de SJF, les processus longs
souffriront de famine lorsqu’il y a un
apport constant de processus courts
228.
Tourniquet = Round-Robin
(RR)
P[0]P[1]
P[7] P[2]
P[6] P[3]
P[5] P[4]
Le plus utilisé en pratique
Chaque processus est alloué une tranche de
temps (p.ex. 10-100 millisecs.) pour exécuter
Tranche aussi appelée quantum
S’il exécute pour tranche entière sans autres
interruptions, il est interrompu par la minuterie
et l ’UCT est donnée à un autre processus
Le processus interrompu redevient prêt (à la fin de
la file)
Méthode préemptive
La file prêt est un
cercle (dont RR)
Ch. 6 32
229.
Performance de tourniquet
Ch.6 33
S ’il y a n processus dans la file prêt et la
tranche est t, alors chaque processus
reçoit 1/n du temps UCT dans unités de
durée max. t
Si t grand FIFO
Si t petit... nous verrons
230.
Ch. 6 34
Exemple:Tourniquet tranche =
20
Processus Cycle
P1 53
P2 17
P3 68
P4 24
0 20 37 57 77 97 117 121 134
154 162
Observez
temps de rotation et temps d’attente moyens beaucoup
plus élevés que SJF
mais aucun processus n’est
P1 P2 P3 P4 P1 P3 P4 P1 P3 P3
231.
Une petite trancheaugmente les
commutations de contexte (temps de SE)
Ch. 6 35
232.
Exemple pour voirl’importance d’un bon
choix de tranche (à développer comme exercice)
Ch. 6 36
Trois cycles:
A, B, C, toutes de 10
Essayer avec:
t=1
t=10
Dans ce deuxième cas, tourniquet
fonctionne comme FIFO et le temps
de rotation moyen est meilleur
233.
Ch. 6 37
Letemps de rotation (turnaround) varie avec
la tranche
Exemple qui montre que le temps de rotation moyen n
’améliore pas nécessairement en augmentant la tranche (sans
considérer les temps de commutation contexte)
= FIFO
234.
Ch. 6 38
Choixde la tranche pour le tourniquet
[Stallings]
doit être beaucoup plus grande que le temps requis pour
exécuter le changement de contexte
doit être un peu plus grand que le cycle typique (pour donner
le temps à la plupart des proc de terminer leur cycle, mais pas trop pour éviter
de pénaliser les processus courts)
Stallings
v. ex. prec. où les point optimaux sont 6 et 7, et il y a deux cycles
235.
Priorités
Ch. 6 39
Affectationd’une priorité à chaque
processus (p.ex. un nombre entier)
souvent les petits chiffres dénotent des
hautes priorités
0 la plus haute
L’UCT est donnée au processus prêt avec
la plus haute priorité
avec ou sans préemption
il y a une file prêt pour chaque priorité
236.
Problème possible avecles priorités
Ch. 6 40
Famine: les processus moins prioritaires
n’arrivent jamais à exécuter
Solution: vieillissement:
modifier la priorité d ’un processus en
fonction de son âge et de son historique d
’exécution
le processus change de file d`attente
Plus en général, la modification dynamique
des priorités est une politique souvent
utilisée (v. files à rétroaction ou retour)
237.
Files à plusieursniveaux (multiples)
Ch. 6 41
La file prêt est séparée en plusieurs files, p.ex.
travaux `d’arrière-plan` (background - batch)
travaux `de premier plan` (foreground - interactive)
Chaque file a son propre algorithme
d ’ordonnancement, p.ex.
FCFS pour arrière-plan
tourniquet pour premier plan
Comment ordonnancer entre files?
Priorité fixe à chaque file famine
possible, ou
Chaque file reçoit un certain pourcentage de temps
UCT, p.ex.
80% pour arrière-plan
20% pour premier plan
Files multiples età retour
Ch. 6 43
Un processus peut passer d ’une file à
l ’autre, p.ex. quand il a passé trop de
temps dans une file
À déterminer:
nombre de files
algorithmes d ’ordonnancement pour chaque
file
algorithmes pour décider quand un proc doit
passer d ’une file à l`autre
algorithme pour déterminer, pour un proc qui
devient prêt, sur quelle file il doit être mis
Exemple de filesmultiples à retour
Trois files:
Q0: tourniquet, tranche = 8 msecs
Q1: tourniquet, tranche = 16 msecs
Q2: FCFS
Ordonnancement:
Un nouveau processus entre dans Q0, il reçoit 8
msecs d ’UCT
S ’il ne finit pas dans les 8 msecs, il est mis dans Q1,
il reçoit 16 msecs additionnels
S ’il ne finit pas encore, il est interrompu et mis
dans Q2
Si plus tard il commence à avoir des cycles plus
courts, il pourrait retourner à Q0 ou Q1
Ch. 6 45
242.
En pratique...
Ch. 646
Les méthodes que nous avons vu sont toutes
utilisées en pratique (sauf plus court servi pur qui
est impossible)
Les SE sophistiqués fournissent au gérant du
système une librairie de méthodes, qu’il peut
choisir et combiner au besoin après avoir observé
le comportement du système
Pour chaque méthode, plusieurs params sont
disponibles: p.ex. durée des tranches,
coefficients, etc.
Ces méthodes évidemment sont importantes
seulement pour les ordis qui ont des fortes
charges de travail
243.
Aussi…
Ch. 6 47
Notreétude des méthodes d’ordonnancement est théorique,
ne considère pas en détail tous les problèmes qui se
présentent dans l’ordonnancement UCT
P.ex. les ordonnanceurs UCT ne peuvent pas donner l’UCT à
un processus pour tout le temps dont il a besoin
Car en pratique, l’UCT sera souvent interrompue par
quelque événement externe avant la fin de son cycle
Cependant les mêmes principes d’ordonnancement
s’appliquent à unités qui ne peuvent pas être interrompues,
comme une imprimante, une unité disque, etc.
Dans le cas de ces unités, on pourrait avoir des
infos complètes concernant le temps de cycle prévu,
etc.
Aussi, cette étude ne considère pas du tout les temps
d’exécution de l’ordonnanceur, du dispatcheur, etc.
244.
Ordonnancement avec plusieurs
UCT
s
identiques:homogénéité
Méthodes symétriques:
chaque UCT peut exécuter
l’ordonnancement et la
répartition
Une seule liste prêt
pour toutes les UCTs
(division travail =
load sharing)
Méthodes asymétriques:
certaines fonctions sont
réservées à une seule UCT
Files d’attentes
séparées pour chaque
UCT
UCT
UCT
UCT
UCT
UCT
UCT
UCT
UCT
Ch. 6 48
245.
Systèmes temps réel
systèmestemps réel rigides (hard):
les échéances sont critiques (p.ex. contrôle d’une
chaîne d`assemblage, animation graphique)
il est essentiel de connaître la durée des
fonctions critiques
il doit être possible de garantir que ces fonctions
sont effectivement exécutées dans ce temps
(réservation de ressources)
ceci demande une structure de système très
particulière
systèmes temps réel souples (soft):
les échéances sont importantes, mais ne sont
pas critiques (p.ex. systèmes téléphoniques)
les processus critiques reçoivent la
priorité
Ch. 6 49
246.
Systèmes temps réel:
Problèmesd’attente dans plus. systèmes (ex.
UNIX)
Ch. 6 50
Dans UNIX ‘classique’ il n ’est pas permis
d ’effectuer changement de contexte pendant un
appel du système - et ces appels peuvent être longs
Pour le temps réel il est nécessaire de permettre la
préemption des appels de systèmes ou du noyau
en général
Donc ce système n’est pas considéré approprié
pour le temps réel
Mais des variétés appropriées de UNIX ont été
conçues (p.ex. Solaris)
247.
Inversion de prioritéet héritage de priorités
Ch. 6 51
Quand un processus de haute priorité doit
attendre pour des processus de moindre
priorité (p.ex. a besoin de données produites par
ces derniers)
Pour permettre à ces derniers de finir
rapidement, on peut lui faire hériter la
priorité du processus plus prioritaire
248.
Ordonnancement de threads
Ch.6 52
Local: la librairie des threads pour une
application donnée décide quel thread
usager obtient un LWP disponible
Global: le noyau décide quel thread de
noyau exécute sur l’UCT
Solaris 2: liredans le manuel pour voir l’application
pratique de plusieurs concepts discutés
Ch. 6 54
Priorités et préemption
Files multiniveau à retour avec
changement de priorité
Tranches plus grandes pour les processus
moins prioritaires
Les procs interactifs sont plus prioritaires
que les les procs tributaires de l’UCT
La plus haute priorité aux procs temps
réel
Tourniquet pour les fils de priorités
égales
Modélisation déterministe
Ch. 656
Essentiellement, ce que nous avons déjà
fait en étudiant le comportement de
plusieurs algorithmes sur plusieurs
exemples
253.
Utilisation de lathéorie des files (queuing
th.)
Ch. 6 57
Méthode analytique basée sur la théorie
des probabilités
Modèle simplifié: notamment, les temps du
SE sont ignorés
Cependant, elle rend possibles des
estimées
254.
Théorie des files:la formule de
Little
Ch. 6 58
Un résultat important:
n = W
n: longueur
moyenne de la file
d ’attente
: débit d
’arrivée de travaux
dans file
W: temps d
’attente moyen
dans la file (temps
de service)
P. ex.
si les travaux
arrivent 3 par sec.
W et il restent
dans la file 2 secs
255.
Simulation
Ch. 6 59
Construireun modèle (simplifié...) de la
séquence d’événements dans le SE
Attribuer une durée de temps à chaque
événement
Supposer une certaine séquence
d’événements extérieurs (p.ex. arrivée de
travaux, etc.)
Exécuter le modèle pour cette séquence
afin d’obtenir des stats
Tableau de
comparaison
Ch. 661
Le tableau suivant fait une comparaison
globale des différentes techniques
étudiées
258.
62
Critère
sélection
Préempt Motivation Tempsde
rotat. et att.
Temps de
système
Effect sur
processus
Famine
FCFS Max [w] non Simplicité Variable Minim. Favor. proc.
trib. UCT
Non
Tourniq. Tour fixe oui
Equité
Variable selon
tranche,
Normalement
élevé
Élevé
pour
tranche
courte
Équitable Non
SJF Min[s] non
Optimisatio
n des
temps
Optimal, mais
souffre si des
procs longs
arrivent au début
Peut être
élevé (pour
estimer les
longs. des
trames)
Bon pour
proc.
courts,
pénalise
proc. longs
Possible
SJF
préemp.
Min[s-e] oui
Évite le problème
de procs longs au
début
Meilleur, même si
des procs longs
arrivent au début
Peut être
élevé
Pénalise
plus encore
proc. longs
Possible
Files
multiniv.
v. détails oui
Varie la longueur
des tranches en
fonction des
besoins
Variable
Peut être
élévé
Variable
Possible
w: temps total dans système jusqu’à
présent;
Chs. :6temps
e: temps en exec jusqu’à
présent
Famine est ‘renvoi
259.
Ch. 6 63
Pointsimportants dans ce chapitre
Files d ’attente pour UCT
Critères d ’ordonnancement
Algorithmes d ’ordonnancement
FCFS: simple, non optimal
SJF: optimal, implantation difficile
moyennage exponentiel
Priorités
Tourniquet: sélection du quantum
Évaluation des méthodes, théorie des files,
formule de Little
260.
Chap. 7 1
Synchronisationde
Processus
(ou threads, ou fils ou tâches)
Chapitre 7
http://w3.uqo.ca/lui
gi/
261.
Problèmes avec concurrence= parallélisme
Chap. 7 2
Les threads concurrents doivent parfois partager
données (fichiers ou mémoire commune) et
ressources
On parle donc de tâches coopératives
Si l’accès n’est pas contrôlé, le résultat de
l’exécution du programme pourra dépendre de
l’ordre d’entrelacement de l’exécution des
instructions (non-déterminisme).
Un programme pourra donner des résultats
différents et parfois indésirables de fois en fois
262.
Un exemple
Chap. 73
Deux threads exécutent
cette même procédure et
partagent la même base de
données
Ils peuvent être
interrompus n’importe où
Le résultat de l ’exécution
concurrente de P1 et P2
dépend de l`ordre de leur
entrelacement
M. X demande une
réservation
d’avion
Base de données
dit que fauteuil
A est disponible
Fauteuil A est
assigné à X et
marqué occupé
263.
Vue globale d’uneexécution possible
M. Guy demande une
réservation d’avion
Base de données dit
que fauteuil 30A est
disponible
Fauteuil 30A est
assigné à Guy et
marqué occupé
M. Leblanc demande une
réservation d’avion
Base de données dit
que fauteuil 30A est
disponible
Fauteuil 30A est
assigné à Leblanc et
marqué occupé
Interrupti
on ou
retard
P1 P2
Chap. 7 4
264.
5
Deux opérations enparallèle sur une var a
partagée (b est privé à chaque processus)
P1
b=
a b=a
b++
a=b
P2
b++
a=b
Supposons que
a soit 0 au
début (il pourrait
être un compteur
d’accès à une page
web)
interrupti
on
265.
3ème exemple
cin >>a;
Thread P1 Thread P2
static char a; static char a;
void echo()
{
void echo()
{
cin >> a;
cout << a;
}
cout << a;
}
Si la var a est partagée, le premier a est
effacé Si elle est privée, l’ordre d’affichage
est renversé
Chap. 7 6
266.
Autres exemples
Chap. 77
Des threads qui travaillent en simultanéité sur une
matrice, par ex. un pour la mettre à jour, l`autre
pour en extraire des statistiques
Problème qui affecte le programme du tampon
borné, v. manuel
Quand plusieurs threads exécutent en parallèle, nous ne
pouvons pas faire d’hypothèses sur la vitesse d’exécution
des threads, ni leur entrelacement
Peuvent être différents à chaque exécution du
programme
267.
Section Critique
Chap. 78
Partie d’un programme dont l’exécution de
doit pas entrelacer avec autres
programmes
Une fois qu’un tâche y entre, il faut lui permettre
de terminer cette section sans permettre à autres
tâches de jouer sur les mêmes données
La section critique doit être verrouillée
268.
Le problème dela section critique
Lorsqu’un thread manipule une donnée (ou ressource)
partagée, nous disons qu’il se trouve dans une section
critique (SC) (associée à cette donnée)
Le problème de la section critique est de trouver un
algorithme d`exclusion mutuelle de threads dans l`exécution
de leur SCs afin que le résultat de leurs actions ne
dépendent pas de l’ordre d’entrelacement de leur
exécution (avec un ou plusieurs processeurs)
L’exécution des sections critiques doit être mutuellement
exclusive: à tout instant, un seul thread peut exécuter
une SC pour une var donnée (même lorsqu’il y a plusieurs
processeurs)
Ceci peut être obtenu en plaçant des instructions spéciales
dans les sections d`entrée et sortie
Pour simplifier, dorénavant nous faisons l’hypothèse qu’il
n’y a q’une seule SC dans un programme.
Chap. 7 9
269.
Structure du programme
Chap.7 10
Chaque thread doit donc demander une permission
avant d’entrer dans une section critique (SC)
La section de code qui effectue cette requête est la
section d’entrée
La section critique est normalement suivie d’une section de
sortie
Le code qui reste est la section restante (SR): non-critique
repeat
section d’entrée
section critique
section de sortie
section restante
forever
270.
Application
M. X demandeune
réservation d’avion
Section d’entrée
Base de données dit que
fauteuil A est disponible
Fauteuil A est assigné à X et
marqué occupé
Section de sortie
Sectio
n
critiqu
e
Chap. 7 11
271.
Critères nécessaires poursolutions valides
Chap. 7 12
Exclusion Mutuelle
À tout instant, au plus un thread peut être
dans une section critique (SC) pour une
variable donnée
Non interférence:
Si un thread s’arrête dans sa section
restante, ceci ne devrait pas affecter les
autres threads
Mais on fait l ’hypothèse qu’un thread qui
entre dans une section critique, en sortira.
272.
Critères nécessaires poursolutions valides
Chap. 7 13
Progrès:
absence d`interblocage (Chap 8)
si un thread demande d`entrer dans une
section critique à un moment où aucun
autre thread en fait requête, il devrait être
en mesure d’y entrer
Donc si un thread veut entrer dans la SC à
répétition, et les autres ne sont pas
intéressés, il doit pouvoir le faire
273.
Aussi nécessaire
Chap. 714
Absence de famine: aucun thread
éternellement empêché d’atteindre sa SC
Difficile à obtenir, nous verrons…
274.
Types de solutions
Chap.7 15
Solutions par logiciel
des algorithmes dont la validité ne s’appuie pas
sur l’existence d`instruction spéciales
Solutions fournies par le matériel
s’appuient sur l’existence de certaines instructions
(du processeur) spéciales
Solutions fournies pas le SE
procure certains appels du système au
programmeur
Toutes les solutions se basent sur l’atomicité de l’accès à la
mémoire centrale: une adresse de mémoire ne peut être
affectée que par une instruction à la fois, donc par un
thread à la fois.
Plus en général, toutes les solutions se basent sur
l ’existence d’instructions atomiques, qui fonctionnent
comme SCs de base
Atomicité =
275.
Solutions par logiciel
(paspratiques, mais intéressantes pour comprendre le
pb)
Chap. 7 16
Nous considérons d’abord 2 threads
Algorithmes 1 et 2 ne sont pas valides
Montrent la difficulté du problème
Algorithme 3 est valide (algorithme de
Peterson)
Notation
Débutons avec 2 threads: T0 et T1
Lorsque nous discutons de la tâche Ti,
Tj dénotera toujours l’autre tâche (i !=
j)
276.
Algorithme 1: threadsse donnent mutuellement le
tour
La variable partagée turn est
initialisée à 0 ou 1
La SC de Ti est exécutée ssi
turn = i
Ti est occupé à attendre si Tj
est dans SC.
Fonctionne pour l’exclusion
mutuelle!
Mais critère du progrès n’est
pas satisfait car
l’exécution des SCs doit
strictement alterner
Thread Ti:
repeat
while(turn!=i);
SC
turn = j;
SR
forever
Rien
fair
e
T0T1T0T1…même si l’un des deux n’est pas intéressé
du tout
Chap. 7 17
277.
Thread T0:
repeat
while(turn!=0);
SC
turn =1;
SR
forever
Thread T1:
repeat
while(turn!=1);
SC
turn = 0;
SR
forever
Algorithme 1 vue globale
Ex 2: Généralisation à n threads: chaque fois, avant qu’un thread puisse
rentrer dans sa section critique, il lui faut attendre que tous les autres
aient eu cette chance!
initialisation de turn à 0 ou 1
Rien
fair
e
Chap. 7 18
278.
Exemple: supposez queturn=0 au début
Thread T0:
while(turn!=0);
// premier à entrer
SC
turn = 1;
SR
while(turn!=0);
// entre quand T1
finit
SC
turn = 1;
SR
etc...
Thread T1:
while(turn!=1);
// entre
quand T0
finit
SC
turn = 0;
SR
while(turn!=1);
// entre
quand T0
finit
SC
turn = 0;
SR
Chap. 7 19
279.
Algorithme 2 oul’excès de
courtoisie...
Une variable Booléenne par
Thread: flag[0] et flag[1]
Ti signale qu’il désire exécuter
sa SC par: flag[i] =vrai
Mais il n’entre pas si l’autre
est aussi intéressé!
Exclusion mutuelle ok
Progrès pas satisfait:
Considérez la séquence:
T0: flag[0] = vrai
T1: flag[1] = vrai
Chaque thread attendra
indéfiniment pour
exécuter sa SC: on a un
interblocage
Thread Ti:
repeat
flag[i] = vrai;
while(flag[j]);
SC
flag[i] = faux;
SR
forever rien
faire
Chap. 7 20
Algorithme 3 (ditde Peterson):
bon!
Chap. 7 22
combine les deux idées: flag[i]=intention d’entrer; turn=à qui le
tour
Initialisation:
flag[0] = flag[1] =
faux
turn = i ou j
Désire d’exécuter SC est
indiqué par flag[i] = vrai
flag[i] = faux à la section de
sortie
Thread Ti:
repeat
flag[i] = vrai;
// je veux entrer
turn = j;
// je donne une chance à l’autre
do while
(flag[j] && turn==j);
SC
flag[i] = faux;
SR
forever
282.
Entrer ou attendre?
Chap.7 23
Thread Ti attend si:
Tj veut entrer est c’est la chance à Tj
flag[j]==vrai et turn==j
Un thread Ti entre si:
Tj ne veut pas entrer ou c’est la chance à Ti
flag[j]==faux ou turn==i
Pour entrer, un thread dépend de l’autre qu’il lui
donne la chance!
283.
Thread T0:
repeat
flag[0] =vrai;
// T0 veut entrer
turn = 1;
// T0 donne une chance à T1
while
(flag[1]&&turn=1);
SC
flag[0] = faux;
// T0 ne veut plus
entrer
SR
forever
Thread T1:
repeat
flag[1] = vrai;
// T1 veut entrer
turn = 0;
// T1 donne une chance à 0
while
(flag[0]&&turn=0);
SC
flag[1] = faux;
// T1 ne veut plus
entrer
SR
forever
Algorithme de Peterson vue
globale
Chap. 7 24
284.
Scénario pour lechangement de contrôle
Thread T0:
…
SC
flag[0] = faux;
// T0 ne veut plus entrer
SR
…
Thread T1:
…
flag[1]
= vrai;
// T1
veut
entrer
turn =
0;
// T1
donne
une
chance à
T0
while
(flag[0]&&turn=0) ;
//test faux, entre
(F&&V)
T1 prend la relève, donne une chance à T0 mais
T0 a dit qu’il ne veut pas entrer.
T1 entre donc dans la SC
Chap. 7 25
285.
Autre scénario dechangem. de
contrôle
Thread T0:
SC
flag[0] = faux;
// T0 ne veut plus entrer
SR
flag[0] = vrai;
// T0 veut entrer
turn = 1;
// T0 donne une chance à T1
while
(flag[1]==vrai&&turn=1) ;
// test vrai, n’entre pas
(V&&V)
Thread T1:
flag[1] = vrai;
// T1 veut entrer
turn = 0;
// T1 donne une chance à T0
// mais T0 annule cette action
while
(flag[0]&&turn=0) ;
//test faux, entre
(V&&F)
T0 veut rentrer mais est obligé de donner une chance à T1,
qui entre
Chap. 7 26
286.
Chap. 7 27
Maisavec un petit décalage, c’est encore
T0!
Thread T0:
SC
flag[0] = faux;
// 0 ne veut plus entrer
RS
flag[0] = vrai;
// 0 veut entrer
turn = 1;
// 0 donne une chance à 1
// mais T1 annule cette action
while
(flag[1] && turn=1) ;
// test faux, entre (V&&F)
Thread T1:
flag[1] = vrai;
// 1 veut entrer
turn = 0;
// 1 donne une chance à 0
while
(flag[0]&&turn=0);
// test vrai,
n’entre pas
Si T0 et T1 tentent simultanément d’entrer dans SC, seule une valeur pour
turn survivra:
non-déterminisme (on ne sait pas qui gagnera), mais l’exclusion
287.
Donc cet algo.n’oblige pas une tâche
d’attendre
pour d’autres qui pourraient ne pas avoir besoin de la SC
Supposons que T0 soit le seul à avoir besoin de la SC, ou que
T1 soit
lent à agir: T0 peut rentrer de suite
(flag[1]==faux
est sorti)
la dernière fois que
T1
flag[0] = vrai // prend l’initiative
turn = 1 // donne une chance à
l’autre while flag[1] && turn=1 //test faux, entre
SC
flag[0] = faux // donne une chance à
l’autre
Cette propriété est désirable, mais peut causer famine pour
Chap. 7 28
288.
Algorithme 3: preuvede
validité
Chap. 7 29
(pas matière d’examen, seulement pour les
intéressés…)
Exclusion mutuelle est assurée car:
T0 et T1 sont tous deux dans SC seulement si
turn est simultanément égal à 0 et 1
(impossible)
Démontrons que progrès et attente limitée
sont satisfaits:
Ti ne peut pas entrer dans SC seulement si
en attente dans la boucle while() avec
condition: flag[ j] == vrai and turn = j.
Si Tj ne veut pas entrer dans SC alors flag[ j]
= faux et Ti peut alors entrer dans SC
289.
Algorithme 3: preuvede validité (cont.)
Chap. 7 30
Si Tj a effectué flag[ j]=vrai et se trouve dans
le while(), alors turn==i ou turn==j
Si
turn==i, alors Ti entre dans SC.
turn==j alors Tj entre dans SC mais il
fera
flag[ j] =false à la sortie: permettant à Ti
d’entrer CS
mais si Tj a le temps de faire
flag[ j]=true, il devra aussi faire turn=i
Puisque Ti ne peut modifier turn lorsque
dans le while(), Ti entrera SC après au plus
une entrée dans SC par Tj (attente limitée)
290.
A propos del’échec des threads
Chap. 7 31
Si une solution satisfait les 3 critères (EM, progrès
et attente limitée), elle procure une robustesse
face à l’échec d’un thread dans sa section
restante (SR)
un thread qui échoue dans sa SR est comme
un thread qui ne demande jamais d’entrer...
Par contre, aucune solution valide ne procure une
robustesse face à l'échec d’un thread dans sa
section critique (SC)
un thread Ti qui échoue dans sa SC n’envoie
pas de signal aux autres threads: pour eux Ti
est encore dans sa SC...
291.
Extension à >2threads
Chap. 7 32
L ’algorithme de Peterson peut être
généralisé au cas de >2 threads
Cependant, dans ce cas il y a des
algorithmes plus élégants, comme
l’algorithme du boulanger, basée sur l’idée
de ‘prendre un numéro au comptoir’...
Pas le temps d’en parler…
292.
Une leçon àretenir…
Chap. 7 33
À fin que des threads avec des variables
partagées puissent réussir, il est
nécessaire que tous les threads impliqués
utilisent le même algorithme de
coordination
Un protocole commun
293.
Critique des solutionspar logiciel
Chap. 7 34
Difficiles à programmer! Et à comprendre!
Les solutions que nous verrons dorénavant sont
toutes basées sur l’existence d’instructions
spécialisées, qui facilitent le travail.
Les threads qui requièrent l’entrée dans leur SC
sont occupés à attendre (busy waiting);
consommant ainsi du temps de processeur
Pour de longues sections critiques, il serait
préférable de bloquer les threads qui doivent
attendre...
294.
Solutions matérielles: désactivationdes
interruptions
Chap. 7 35
Sur un uniprocesseur:
exclusion mutuelle est
préservée mais l’efficacité
se détériore: lorsque dans
SC il est impossible
d’entrelacer l’exécution
avec d’autres threads
dans une SR
Perte d’interruptions
Sur un multiprocesseur:
exclusion mutuelle n’est
pas préservée
Pas bon en général
Process Pi:
repeat
désactiver interrupt
section critique
rétablir interrupt
section restante
forever
295.
Solutions matérielles: instructionsmachine
spécialisées
Chap. 7 36
Normal: pendant qu’un thread ou processus fait
accès à une adresse de mémoire, aucun autre ne
peut faire accès à la même adresse en même
temps
Extension: instructions machine exécutant
plusieurs actions (ex: lecture et écriture) sur la
même case de mémoire de manière atomique
(indivisible)
Une instruction atomique ne peut être exécutée
que par un thread à la fois (même en présence de
plusieurs processeurs)
296.
L’instruction test-and-
set
Une versionC de
test- and-set:
Un algorithme utilisant
testset pour Exclusion
Mutuelle:
Variable partagée b est
initialisée à 0
Le 1er Pi qui met b à 1
entre dans SC
bool testset(int& i)
{
if (i==0) {
i=1;
return
true;
} else
{ return
false;
}
}
Tâche Pi:
while testset(b)==false ;
SC //entre quand vrai
b=0;
SR
Instruction atomique!
Chap. 7 37
297.
L’instruction test-and-set (cont.)
Chap.7 38
Exclusion mutuelle est assurée: si Ti entre
dans SC, l’autre Tj est occupé à attendre
Problème: utilise encore occupé à
attendre
Peut procurer facilement l’exclusion mutuelle
mais nécessite algorithmes plus complexes
pour satisfaire les autres exigences du
problème de la section critique
Lorsque Ti sort de SC, la sélection du Tj qui
entrera dans SC est arbitraire: pas de limite
sur l’attente: possibilité de famine
298.
Instruction ‘Échange’
Chap. 739
Certains UCTs (ex: Pentium) offrent une
instruction xchg(a,b) qui interchange le
contenue de a et b de manière atomique.
Mais xchg(a,b) souffre des même lacunes que
test-and-set
299.
Utilisation de xchgpour exclusion
mutuelle
Chap. 7 40
(Stallings
)
Variable partagée b est
initialisée à 0
Chaque Ti possède une
variable locale k
Le Ti pouvant entrer dans
SC est celui qui trouve
b=0
Ce Ti exclue tous les
autres en assignant b à 1
Quand SC est occupée, k
et b seront 1 pour un
autre thread qui cherche
à entrer
Mais k est 0 pour le
thread qui est dans la SC
usage:
Thread Ti:
repeat
k = 1
while k!=0 xchg(k,b);
SC
xchg(k,b);
SR
forever
300.
Solutions basées surdes instructions
fournies par le SE (appels du système)
Chap. 7 41
Les solutions vues jusqu’à présent sont
difficiles à programmer et conduisent à du
mauvais code.
On voudrait aussi qu`il soit plus facile
d’éviter des erreurs communes, comme
interblocages, famine, etc.
Besoin d’instruction à plus haut niveau
Les méthodes que nous verrons
dorénavant utilisent des instructions
puissantes, qui sont implantées par des
appels au SE (system calls)
301.
Sémaphores
Chap. 7 42
Unsémaphore S est un entier qui, sauf pour l'Initialisation,
est accessible seulement par ces 2 opérations atomiques et
mutuellement exclusives:
wait(S) (appelé P dans le livre)
signal(S) (appelé V dans le livre)
Il est partagé entre tous les procs qui s`intéressent à la
même section critique
Les sémaphores seront présentés en deux étapes:
sémaphores qui sont occupés à attendre (busy waiting)
sémaphores qui utilisent des files d ’attente
On fait distinction aussi entre sémaphores compteurs et
sémaphores binaires, mais ce derniers sont moins
puissants (v. livre).
302.
Spinlocks d’Unix: Sémaphoresoccupés à attendre
(busy waiting)
Chap. 7 43
La façon la plus simple
d’implanter les sémaphores.
Utiles pour des situations où
l’attente est brève, ou il y a
beaucoup d’UCTs
S est un entier initialisé à une
valeur positive, de façon que un
premier thread puisse entrer
dans la SC
Quand S>0, jusqu’à n threads
peuvent entrer
S ne peut pas être négatif
wait(S):
while S=0 ;
S--;
signal(S):
S++;
Attend si no. de threads qui
peuvent entrer = 0
Augmente de 1 le no des threads qui
peuvent entrer
303.
Atomicité
Wait: La séquence
test-décrément est
atomique, mais pas la
boucle!
Signal est
atomique.
Rappel: les sections atomiques
ne peuvent pas être exécutées
simultanément par différent
threads
(ceci peut être obtenu un utilisant
un des mécanismes précédents)
S = 0
atomique S - -
F
V
S
C
Chap. 7 44
304.
Atomicité et
interruptibilité
atomique S- -
F
V
S = 0
S++
interruptible
SC
La boucle n’est pas atomique pour permettre à un
autre thread d’interrompre l’attente sortant de la SC
Chap. 7 45
autre thr.
S
C
(Autre
thread)
Utilisation des sémaphorespour sections
critiques
Chap. 7 47
Pour n threads
Initialiser S à 1
Alors 1 seul thread peut
être dans sa SC
Pour permettre à k
threads d’exécuter SC,
initialiser S à k
Thread Ti:
repeat
wait(S);
SC
signal(S);
SR
forever
307.
Utilisation des sémaphorespour
synchronisation de threads
Chap. 7 48
On a 2 threads: T1 et
T2
Énoncé S1 dans T1
doit être exécuté avant
énoncé S2 dans T2
Définissons un
sémaphore S
Initialiser S à 0
Synchronisation
correcte lorsque T1
contient:
S1;
signal(S);
et que T2 contient:
wait(S);
S2;
308.
Interblocage et famineavec les
sémaphores
Famine: un thread peut n’arriver jamais à
exécuter car il ne teste jamais le
sémaphore au bon moment
Interblocage: Supposons S et Q initialisés
à 1
T0 T1
wait(S)
wait(Q)
wait(Q
)
wait(S)
Chap. 7 49
309.
Sémaphores:
observations
Chap. 7 50
QuandS >= 0:
Le nombre de threads qui peuvent
exécuter wait(S) sans devenir bloqués = S
S threads peuvent entrer dans la SC
noter puissance par rapport à mécanismes déjà vus
dans les solutions où S peut être >1 il faudra avoir un
2ème sém. pour les faire entrer un à la fois (excl.
mutuelle)
Quand S devient > 1, le thread qui entre le
premier dans la SC est le premier à tester S
(choix aléatoire)
ceci ne sera plus vrai dans la solution
suivante
wait(S):
while S=0 ;
S--;
310.
Comment éviter l’attenteoccupée et le choix
aléatoire dans les sémaphores
Chap. 7 51
Quand un thread doit attendre qu’un sémaphore
devienne plus grand que 0, il est mis dans une file
d’attente de threads qui attendent sur le même
sémaphore.
Les files peuvent être PAPS (FIFO), avec priorités,
etc. Le SE contrôle l`ordre dans lequel les threads
entrent dans leur SC.
wait et signal sont des appels au système comme
les appels à des opérations d’E/S.
Il y a une file d ’attente pour chaque sémaphore
comme il y a une file d’attente pour chaque
unité d’E/S.
311.
Sémaphores sans attenteoccupée
Un sémaphore S devient une structure de données:
Une valeur
Une liste d’attente L
Un thread devant attendre un sémaphore S, est bloqué et ajouté la
file d’attente S.L du sémaphore (v. état bloqué = attente chap 4).
signal(S) enlève (selon une politique juste, ex: PAPS/FIFO) un thread
de S.L et le place sur la liste des threads prêts/ready.
Chap. 7 52
312.
Implementation
(les boîtes réprésententdes séquences non-
interruptibles)
wait(S): S.value --;
if S.value < 0
{
// SC occupée
add this thread to S.L;
block // thread mis en état attente
(wait)
}
signal(S): S.value ++;
if S.value 0 { // des threads attendent
remove a process P from S.L;
wakeup(P) // thread choisi
devient prêt
}
S.value doit être initialisé à une valeur non-négative (dépendant de
l’application, v. exemples)
Chap. 7 53
313.
5
Figure montrant la
relationentre le
contenu de la file et la
valeur de S
Chap. 7
(Stallings
)
Quand S < 0: le nombre
de threads qui attendent
sur S est = |S|
314.
Wait et signalcontiennent elles mêmes des SC!
Chap. 7 55
Les opérations wait et signal doivent être
exécutées atomiquement (un seul thr. à la fois)
Dans un système avec 1 seule UCT, ceci peut être
obtenu en inhibant les interruptions quand un
thread exécute ces opérations
Normalement, nous devons utiliser un des
mécanismes vus avant (instructions spéciales,
algorithme de Peterson, etc.)
L’attente occupée dans ce cas ne sera pas trop
onéreuse car wait et signal sont brefs
Le pb duproducteur - consommateur
Chap. 7 57
Un problème classique dans l ’étude des
threads communicants
un thread producteur produit des données
(p.ex.des enregistrements d ’un fichier)
pour un thread consommateur
317.
Chap. 7 58
Tamponsde communication
Prod
1 donn
Cons
Prod
Cons
1 donn 1 donn 1 donn
Si le tampon est de longueur 1, le producteur et consommateur
doivent forcement aller à la même vitesse
Des tampons de longueur plus grandes permettent une
certaine indépendance. P.ex. à droite le consommateur a
318.
Le tampon borné(bounded
buffer)
une structure de données fondamentale dans les
SE
b[0] b[1]
b[7] b[2]
b[6] b[3]
b[5] b[4]
ou
out: 1ère
pos. pleine
in: 1ère
pos. libre b[0] b[1] b[2] b[3] b[4] b[5] b[6] b[7]
in: 1ère
pos. libre
bleu: plein, blanc: libre
out: 1ère
pos.
pleine
Le tampon borné se trouve dans la mémoire partagée
entre consommateur et usager
Chap. 7 59
319.
Pb de syncentre threads pour le tampon
borné
Chap. 7 60
Étant donné que le prod et le
consommateur sont des threads
indépendants, des problèmes pourraient
se produire en permettant accès
simultané au tampon
Les sémaphores peuvent résoudre ce
problème
320.
Sémaphores: rappel.
Chap. 761
Soit S un sémaphore sur une SC
il est associé à une file d ’attente
S positif: S threads peuvent entrer dans SC
S zéro: aucun thread ne peut entrer, aucun thread en
attente
S négatif: |S| thread dans file d ’attente
Wait(S): S - -
si après S >= 0, thread peut entrer dans SC
si S < 0, thread est mis dans file d ’attente
Signal(S): S++
si après S<= 0, il y avait des threads en attente, et un
thread est réveillé
Indivisibilité = atomicité de ces ops
321.
Solution avec sémaphores
Chap.7 62
Un sémaphore S pour exclusion mutuelle
sur l’accès au tampon
Les sémaphores suivants ne font pas l’EM
Un sémaphore N pour synchroniser
producteur et consommateur sur le
nombre d’éléments consommables dans le
tampon
Un sémaphore E pour synchroniser
producteur et consommateur sur le
nombre d’espaces libres
322.
Chap. 7 63
Solutionde P/C: tampon circulaire fini de dimension k
Producer:
repeat
produce v;
wait(E);
wait(S);
append(v);
signal(S);
signal(N);
forever
Consumer:
repeat
wait(N)
;
wait(S)
;
w=take(
);
signal(S);
signal(E);
consume(w);
forever
Initialization: S.count=1; //excl. mut.
N.count=0; //esp. pleins
E.count=k; //esp. vides
a
p
p
e
n
d
(
v
)
:
b
[
i
n
]
Sections critiques
In ++ mod k;
take():
w=b[out];
Out ++ mod k;
return w;
323.
Points importants àétudier
Chap. 7 64
dégâts possibles en inter changeant les
instructions sur les sémaphores
ou en changeant leur initialisation
Généralisation au cas de plus. prods et
cons
324.
Concepts importants decette partie du Chap
7
Chap. 7 65
Le problème de la section critique
L’entrelacement et l’atomicité
Problèmes de famine et interblocage
Solutions logiciel
Instructions matériel
Sémaphores occupés ou avec files
Fonctionnement des différentes solutions
L’exemple du tampon borné
Par rapport au manuel: ce que nous n’avons pas
vu en classe vous le verrez au lab
325.
Glossaire
Chap. 7 66
Atomicité,non-interruptibilité:
La définition précise d’atomicité, non-déterminisme
etc. est un peu compliquée, et il y en a aussi des
différentes… (les curieux pourraient faire une
recherche Web sur ces mot clé)
Ce que nous discutons dans ce cours est une 1ère
approximation: une séquence d’ops est atomique si
elle est exécutée toujours sans être interrompue par
aucune autre séquence sur les mêmes données
Ou son résultat ne dépend jamais de l’existence
d’autres séquences en parallèle…
326.
Non-déterminisme et conditionsde course
Chap. 7 67
Non-déterminisme: une situation dans laquelle il y
a plusieurs séquences d’opérations possibles à
un certain moment, même avec les mêmes
données. Ces différentes séquences peuvent
conduire à des résultats différents
Conditions de course: Les situations dans
lesquelles des activités exécutées en parallèle
sont ‘en course’ les unes contre les autres pour
l`accès à des ressources (variables partagées,
etc.), sont appelées ‘conditions de course ’.
327.
Chapitre 7 continuation
Problèmesclassiques de synchronisation
Lecteurs - Rédacteurs
Les philosophes mangeant
Moniteurs
Threads en Java
http://w3.uqo.ca/lui
gi/
Chap. 7 1
328.
Sémaphores:
rappel
(les boîtes représententdes séquences
indivisibles)
wait(S): S.value --;
if S.value < 0
{
// SC occupée
ajouter ce thread à S.L;
block // thread mis en état attente
(wait)
}
signal(S): S.value ++;
if S.value 0 { // des threads attendent
enlever un thread P de S.L;
wakeup(P)
// thread choisi devient prêt
}
S.value doit être initialisé à une valeur non-
Chap. 7 2
329.
Sémaphores: rappel.
Chap. 73
Soit S un sémaphore sur une SC
il est associé à une file d ’attente
S positif: S thread peuvent entrer dans SC
S zéro: aucun thread ne peut entrer, aucun thread
en attente
S négatif: |S| thread dans file d ’attente
Wait(S): S - -
si après S >= 0, thread peut entrer dans SC
si S < 0, thread est mis dans file d ’attente
Signal(S): S++
si après S<= 0, il y avait des threads en attente, et
un thread est transféré à la file prêt
Indivisibilité = atomicité de wait et signal
330.
Problème des lecteurs- rédacteurs
Chap. 7 4
Plusieurs threads peuvent accéder à une
base de données
Pour y lire ou pour y écrire
Les rédacteurs doivent être synchronisés
entre eux et par rapport aux lecteurs
il faut empêcher à un thread de lire
pendant l’écriture
il faut empêcher à deux rédacteurs d
’écrire simultanément
Les lecteurs peuvent y accéder
simultanément
331.
Une solution (n’exclutpas la famine)
Chap. 7 5
Variable readcount: nombre de threads lisant la base de
données
Sémaphore mutex: protège la SC où readcount est mis à
jour
Sémaphore wrt: exclusion mutuelle entre rédacteurs et
lecteurs
Les rédacteurs doivent attendre sur wrt
les uns pour les autres
et aussi la fin de toutes les lectures
Les lecteurs doivent
attendre sur wrt quand il y a des rédacteurs qui
écrivent
bloquer les rédacteurs sur wrt quand il y a des lecteurs
qui lisent
redémarrer les rédacteurs quand personne ne lit
332.
Les données etles rédacteurs
Chap. 7 6
Données: deux sémaphores et une variable
mutex, wrt: semaphore (init. 1);
readcount : integer (init. 0);
Rédacteur
wait(wrt);
. . .
// écriture
. . .
signal(wrt);
333.
Les lecteurs
wait(mutex);
readcount ++;
if readcount == 1 then wait(wrt);
signal(mutex);
//SC: lecture
wait(mutex);
readcount -- ;
if readcount == 0 then signal(wrt);
signal(mutex):
Le dernier lecteur sortant
doit permettre l`accès aux
rédacteurs
Le premier lecteur d ’un groupe
pourrait devoir attendre sur wrt, il
doit aussi bloquer les rédacteurs.
Quand il sera entré, les suivants
pourront entrer librement
Chap. 7 7
334.
Observations
Chap. 7 8
Le1er lecteur qui entre dans la SC bloque
les rédacteurs
wait (wrt)
le dernier les remet en marche
signal (wrt)
Si 1 rédacteur est dans la SC, 1 lecteur
attend sur wrt, les autres sur mutex
un signal(wrt) peut faire exécuter un
lecteur ou un rédacteur
335.
Le problème desphilosophes mangeant
5 philosophes qui
mangent et pensent
Pour manger il faut 2
fourchettes, droite et
gauche
On en a seulement
5!
Un problème classique
de synchronisation
Illustre la difficulté
d’allouer ressources aux
threads tout en évitant
interblocage et famine
Chap. 7 9
336.
Le problème desphilosophes
mangean
t
Un thread par
philosophe
Un sémaphore par
fourchette:
fork: array[0..4]
of semaphores
Initialisation: fork[i]
=1 for i:=0..4
Première tentative:
interblocage si
chacun débute en
prenant sa
fourchette gauche!
wait(fork[i])
Thread Pi:
repeat
think;
wait(fork[i]);
wait(fork[i+1 mod 5]);
eat;
signal(fork[i+1 mod 5]);
signal(fork[i]);
forever
Chap. 7 10
337.
Le problème desphilosophes
mangean
t
Une solution: admettre
seulement 4 philosophes
à la fois qui peuvent
tenter de manger
Il y aura touj. au moins
1 philosophe qui
pourra manger
même si tous
prennent 1
fourchette
Ajout d’un sémaphore T
qui limite à 4 le nombre
de philosophes “assis à
la table”
initial. de T à 4
N’empêche pas famine!
Thread Pi:
repeat
think;
wait(T);
wait(fork[i]);
wait(fork[i+1 mod 5]);
eat;
signal(fork[i+1 mod
5]);
signal(fork[i]);
signal(T);
forever
Chap. 7 11
338.
Avantage des
sémaphores
Chap. 712
(par rapport aux solutions précédentes)
Une seule variable partagée par section
critique
deux seules opérations: wait, signal
contrôle plus localisé (que avec les
précéds)
extension facile au cas de plus. threads
possibilité de faire entrer plus. threads à la
fois dans une section critique
gestion de files d`attente par le SE: famine
évitée si le SE est équitable (p.ex. files
FIFO)
339.
Problème avec sémaphores:difficulté de
programmation
Chap. 7 13
wait et signal sont dispersés
parmi plusieurs threads, mais ils
doivent se correspondre
Utilisation doit être correcte dans tous
les threads
Un seul “mauvais” thread peut faire
échouer toute une collection de threads
(p.ex. oublie de faire signal)
Considérez le cas d`un thread qui a des
waits et signals dans des boucles et des
tests...
340.
Moniteurs: une autresolution
Constructions (en
langage de haut-niveau)
qui procurent une
fonctionnalité
équivalente aux
sémaphores mais plus
facile à contrôler
Disponibles en:
Concurrent
Pascal, Modula-
3...
• synchronized method
en Java (moniteurs
simplifiés)
Chap. 7 14
341.
Moniteur
Est un modulecontenant:
une ou plusieurs procédures
une séquence d’initialisation
variables locales
Caractéristiques:
variables locales accessibles seulement
à l’aide d’une procédure du moniteur
un thread entre dans le moniteur en
invoquant une de ses procédures
un seul thread peut exécuter dans le moniteur
à tout instant (mais plus. threads peuvent être en attente
dans le monit.)
Chap. 7 15
342.
Moniteu
r
Il assure àlui seul l’exclusion mutuelle: pas
besoins de le programmer explicitement
On assure la protection des données partagées
en les plaçant dans le moniteur
Le moniteur verrouille les données
partagées lorsqu’un thread y entre
Synchronisation de threads est effectuée en
utilisant des variables conditionnelles qui
représentent des conditions après lesquelles un
thread pourrait attendre avant d’exécuter dans le
moniteur
Chap. 7 16
343.
Structure générale dumoniteur (style
Java)
monitor nom-de-moniteur
{ // déclarations de vars
public entry p1(. . .) {code de méthode
p1} public entry p2(. . .) {code de
méthode p2}
. . .
}
La seule façon de manipuler les vars internes au
moniteur est d’appeler une des méthodes d’entrée
Chap. 7 17
Variables conditionnelles (n’existentpas en
Java)
Chap. 7 19
sont accessibles seulement dans le moniteur
accessibles et modifiables seulement à l’aide de 2
fonctions:
x: wait bloque l’exécution du thread exécutant
sur la condition x
le thread pourra reprendre l’exécution seulement
si un autre thread exécute x: signal)
x: signal reprend l’exécution d’un thread bloqué
sur la condition x
S’il en existe plusieurs: en choisir un (file?)
S’il n’en existe pas: ne rien faire
346.
Moniteur avec variablesconditionnelles
Chap. 7 20
Dans une banque, il y a
une file principale, mais
une fois entré on pourrait
vous faire attendre dans
un fauteuil jusqu’à ce que
le préposé soit disponible
347.
Un concept plusgénéral: Variables condition
Chap. 7 21
On appelle variable condition une var qui
peut être testée et
endorme le thread qui la teste si la
condition est fausse
le réveille quand la condition devient
vraie
Sont employées dans les moniteurs, mais
peuvent aussi être utilisées
indépendamment
348.
Blocage dans lesmoniteurs
threads attendent dans la file d’entrée ou dans
une file de condition (ils n ’exécutent pas)
sur x.wait: le thread est placé dans la file de
la condition (il n ’exécute pas)
x.signal amène dans le moniteur 1 thread de la
file x (si x vide, aucun effet)
Chap. 7 22
349.
Un pb concernantle
signal
Chap. 7 23
Quand un thread P exécute x.signal et
libère un thr. Q, il pourrait y avoir 2 thr. qui
peuvent exécuter, P et Q, ce qui est
défendu. Deux solutions possibles:
P pourrait attendre jusqu` à ce que Q sorte
du moniteur, p.ex. dans une file spéciale
(dite urgente) (v. Stallings)
Q pourrait attendre jusqu’à ce que P sorte
du moniteur
350.
Terminologie Java (davantageau
lab)
Chap. 7 24
Les méthodes synchronisées de Java sont essentiellement
des moniteurs
Un seul thread à la fois peut les exécuter
Il y a 2 files pour un objet:
File d’entrée
File d’attente (méthode wait)
Un thread ne peut avoir que 1 file wait
Limitation importante qui complique les choses en
Java…
Wait existe en Java + ou – comme décrit pour les
moniteurs
Signal s’appelle notify
Notify() libère 1 seul thread
NotifyAll les libères tous
Mais ils n’exécutent pas: ils sont mis dans la file d’entrée
351.
Java: diagramme simplifiéde transition d’état
threads
(sur la base de la fig. 5.10 du manuel)
nouvea
u
star
t
Sleep
Wait
I/O
join
susp
end
notify
Fin
E/S
resum
e
nouvea
u
exécutable
= runnable
mor
t
b loqué =
not
runnable
bloqué sur une file associée à
un événement
prêt ou en exécution
stop ou
term. de
run
Chap. 7 25
352.
Un diagramme plus
complet
NEW
READY
RUNNING
DEAD
NOT
RUNNABLE
new
start
complèterun
method ou
exception
pas traitée
Ordonnanceur
choisit fil
yield ou
terminaison
tranche ou
préemption
Notify, E/S
terminée, resume,
interrupted
Sleep,
wait, I/O,
join,
suspend
RUNNABLE =
READY ou
RUNNING
Chap. 7 26
Les méthodes suspend, resume, stop ne sont
pas recommandées aujourd’hui (deprecated).
Malheureusement le manuel s’en sert…
353.
Retour au problèmedes philosophes mangeant
5 philosophes qui
mangent et pensent
Pour manger il faut 2
baguettes, droite et
gauche
On en a seulement
5!
Un problème classique
de synchronisation
Illustre la difficulté
d’allouer ressources aux
threads tout en évitant
interblocage et famine
Chap. 7 27
354.
Philosophes mangeant structuresde
données
Chaque philos. a son propre state qui peut être
(thinking, hungry, eating)
philosophe i peut faire state[i] = eating ssi les voisins
ne mangent pas
Chaque condition a sa propre condition self
le philosophe i peut attendre sur self [ i ] si veut
manger, mais ne peut pas obtenir les 2 baguettes
Chap. 7 28
Chap. 7 30
privatetest(int i) {
if ( (state[(i + 4) % 5] != EATING) &&
(state[i] == HUNGRY) &&
(state[(i + 1) % 5] != EATING) ) {
state[i] = EATING;
self[i].signal;
}
}
Un philosophe mange
Un philosophe mange si ses voisins ne mangent pas et
s’il a faim.
Une fois mangé, il signale de façon qu’un autre
pickup soit possible, si pickup s’était arrêté sur wait
Il peut aussi sortir sans avoir mangé si le test est faux
357.
Chercher de prendreles baguettes
public entry pickUp(int i) {
state[i] =
HUNGRY; test(i);
if (state[i] !=
EATING)
self[i].wait;
}
Phil. cherche à manger en testant, s’il sort de test qu’il
n’est pas mangeant il attend – un
Chap. 7 31
358.
Déposer les baguettes
publicentry putDown(int i) {
state[i] = THINKING;
// tester les deux
voisins
test((i + 4) % 5);
test((i + 1) % 5);
} Une fois fini de manger, un philosophe se
préoccupe de faire manger ses voisins en les
testant
Chap. 7 32
P/C: tampon circulairede dimension k
Peut consommer seulement si le nombre N d’éléments
consommables est au moins 1 (N = in-out)
Peut produire seulement si le nombre E d’espaces libres est
au moins 1 (E = out-in)
Chap. 7 34
361.
Variables conditionnelles utilisées
Chap.7 35
Si le tampon est plein, le producteur doit
attendre qu’il devienne non-plein
Var conditionnelle notfull
Si le tampon est vide, le consommateur
doit attendre qu’il devienne non-vide
Var conditionnelle notempty
362.
Moniteur pour P/Cavec tampon
fini
Chap. 7 36
(syntaxe un peu différente, pas orienté objet)
Monitor boundedbuffer:
buffer: vecteur[0..k-1] de items;
nextin = 0, nextout = 0, count = 0 ;
notfull, notempty: condition;
Produce(v):
if (count==k) notfull.wait;
buffer[nextin] = v;
nextin = (nextin+1 mod k);
count ++;
notempty.signal;
Consume(v):
v = buffer[nextout];
nextout = (nextout+1 mod k);
count --;
notfull.signal;
Variable conditionnelle sur
laquellele producteur attend
s’il n’y a pas d’espaces libres
Variable conditionnelle sur
laquelle
if (count==0) notempty.wait; le consommateur attend s’il n’y a pas
d’espaces
occupés
363.
La solution Javaest plus compliquée
surtout à cause du fait que Java n’a
pas de variables conditionnelles
nommées
Chap. 7 37
V.
manuel
364.
Relation entre moniteurset autre
mécanismes
Chap. 7 38
Les moniteurs sont implantés utilisant les
sémaphores ou les autres mécanismes
déjà vus
Il est aussi possible d`implanter les
sémaphores en utilisant les moniteurs!
les laboratoires vont discuter ça
365.
Le problème dela SC en pratique...
Chap. 7 39
Les systèmes réels rendent disponibles
plusieurs mécanismes qui peuvent être
utilisés pour obtenir la solution la plus
efficace dans différentes situations
366.
Synchronisation en Solaris2 (avec UCT
multiples)
Plusieurs mécanismes utilisés:
adaptive mutex protège l ’accès aux
données partagées pour des SC courtes
sémaphores et condition variables
protègent des SC plus importantes
serrures lecteurs-rédacteurs (reader-writers
locks) protègent des données qui
normalement ne sont que lues
les mêmes mécanismes sont disponibles
aux usagers et dans le noyau
Chap. 7 40
367.
Adaptive mutex enSolaris 2
Utilisés pour des SC courtes: quand un
thread veut accéder à des données
partagées:
Si les données sont couramm. utilisées par
un thread exécutant sur un autre UCT, l
’autre thread fait une attente occupée
Sinon, le thread est mis dans une file d
’attente et sera réveillé quand les données
deviennent disponibles
Chap. 7 41
368.
Windows NT
: aussiplus. mécanismes
exclusion mutuelle sur données partagées:
un fil doit demander accès et puis libérer
section critiques: semblables mais pour
synchroniser entre fils de threads
différents
sémaphores
event objects: semblables à condition
variables
Chap. 7 42
369.
Concepts importants duChapitre 7
Chap. 7 43
Sections critiques: pourquoi
Difficulté du problème de la synch sur SC
Bonnes et mauvaises solutions
Accès atomique à la mémoire
Solutions logiciel `pures`
Solution matériel: test-and-set
Solutions par appels du système:
Sémaphores, moniteurs, fonctionnement
Problèmes typiques: tampon borné,
lecteurs-écrivains, philosophes
370.
Par rapport aumanuel
Chap. 7 44
Le manuel couvre + ou – la même matière,
mais en utilisant une approche Java
Pour le test et examen, suivre ma
présentation
Pour les travaux de programmation, utiliser
les exemples du manuel
371.
Chap 8 1
Interblocage= impasse
(Deadlock)
Chapitre 8
http://w3.uqo.ca/lui
gi/
372.
Interblocages: concepts importants
Chap8 2
Caractérisation: les 4 conditions
Graphes allocation ressources
Séquences de terminaison
États sûrs et no-sûrs
Prévenir les interblocages
Éviter les interblocages
Détecter les interblocages
Récuperer d’un interblocage
373.
Exemple 1
Chap 83
Deux processus coexistent dans un système, qui a 2 lignes
téleph. seulement
Le proc 1 a besoin de
une ligne téléphonique pour démarrer
la ligne précédente, et une additionnelle, pour terminer
Le proc 2 est pareil
Scénario d ’interblocage:
proc 1 demande 1 ligne
proc 2 demande 1 ligne: les deux lignes sont engagées
interblocage! aucun proc ne peut compléter
à moins qu ’un des proc ne puisse être suspendu
ou puisse retourner en arrière
Observez que l ’interblocage n ’est pas inévitable, p.ex. si
1 complète avant le début de 2
Éviter / détecter le risque d’interblocage
Éviter / détecter qu’un interblocage se vérifie
374.
Exemple 2
Sémaphores
P0
wait (A);
wait(B);
P1
wait(B)
wait(A)
Scénario d’interblocage:
initialisation de A et B à 1
P0 exécute wait(A), A=0
P1 exécute wait(B), B=0
P0 et P1 ne peuvent pas aller plus loin
Qu’arrive au lieu si P0 exécute entièrement avant
P1?
Chap 8 4
375.
Définition (Tanenbaum)
Un ensemblede processus est en interblocage si
chaque processus attend un événement que seul
un autre processus de l’ensemble peut provoquer
L’événement est une libération de ressource
Prenant ce mot dans le sens le plus vaste:
ressource peut être un signal, un message,un
sémaphore, etc.
Exemple intéressant: interblocage entre lecteurs
ou écrivains sur une base de données???
Un processus en interblocage est en état
attente
Chap 8 5
376.
Caractérisation
d’interblocage
L’interblocage demande laprésence simultanée de 4 conditions
(conditions nécessaires et suffisantes)
Exclusion mutuelle: le système a des ressources non
partageables (1 seul proc à la fois peut s’en servir)
Ex.: un UCT, une zone de mémoire, une périphérique, mais
aussi sémaphores, moniteurs, sections critiques
Saisie et attente (hold and wait): un processus a saisi une
ressource non partageable et en attend des autres pour
compléter sa tâche
Pas de préemption: un processus qui a saisi une ressource
non partageable la garde jusqu’à ce qu’il aura complété sa
tâche
Attente circulaire: il y a un cycle de processus tel que chaque
processus pour compléter doit utiliser une ressource non
partageable qui est utilisée par le suivant, et que le suivant
gardera jusqu`à sa terminaison
En présence des 3 premières conditions, une attente circulaire est
un interblocage
Les 3 premières conditions n’impliquent pas nécessairement
interblocage, car l’attente circulaire pourrait ne pas se vérifier
important
Chap 8 6
377.
Chap 8 7
Attentecirculaire - aucun ne lâche - aucun
processus ne peut terminer donc
interblocage
P0
P3
P4
P2 P1
Pour terminer
, chaque processus doit saisir une ressource
que le prochain ne lâchera pas interblocage
378.
Exercice
Réfléchissez à cetexemple dans lequel des voitures
sont dans une situation d’interblocage sur un pont
et voir comment les différentes conditions sont
satisfaites.
V. aussi l’exemple à la page 1.
Chap 8 8
379.
Exercice
Chap 8 9
Considérezun système dans lequel
chaque processus n’a besoin que d’une
seule ressource pendant toute son
existence
L’interblocage, est-il possible?
380.
Exercice
Chap 8 10
Vérifierque si dans un système il y a
toujours suffisamment de ressources pour
tous, il n’y aura jamais d’interblocages
Cependant ceci est souvent impossible, surtout
dans le cas de sections critiques, car les données
partagées existent normalement dans un seul
exemplaire
381.
En principe, unproblème difficile
Chap 8 11
Le problème de déterminer s’il y a
d’interblocage dans un système est connu
comme problème insoluble en principe par
ordinateur (résultat théorique)
On ne pourrait pas écrire un programme S
qui, étant donnée un autre programme X en
entrée, pourrait déterminer à coup sûr si X
contient la possibilité d’interblocage
Cependant, nous pouvons développer des
critères pour trouver des réponses
plausibles dans des cas particuliers
382.
Graphes d’allocation ressources
Chap8 12
Un ensemble de sommets V et d’arêtes E
V est partitionné dans:
P = {P1, P2, …, Pn}, l’ensemble qui consiste
de tous les procs dans le système
R = {R1, R2, …, Rm}, l’ensemble qui consiste
de tous les types de ressources dans le
système
arête requête – arête dirigée Pi Rk
arête affectation – arête dirigée Ri Pk
383.
Graphe d’allocation ressources
Pja saisi (et utilise) un exemplaire de Rj
Pi
Pj
Processus
Ressource dont il y a 4 exemplaires (instances)
R
Pi a (ou aura) besoin pour terminer d’un
exemplaire de Ri, dont il y en a 4
Chap 8 13
Ri
Rj
384.
Exemple de grapheallocation ressources
P1 en attente
Chap 8 14
P2 en attente
P3 pas en attente
Y-a-t-il interblocage?
385.
Utilisation de cesgraphes
Chap 8 15
Nous supposons l’existence des 3 premières
conditions
Excl. Mutuelle, saisie et attente, pas de
préemption
Pour montrer qu’il n’y a pas d’interblocage, nous
devons montrer qu’il n’y a pas de cycle, car il y a
un processus qui peut terminer sans attendre
aucun autre, et puis les autres de suite
<P3, P2, P1> est un ordre de terminaison de
processus: tous peuvent terminer dans cet ordre
386.
Graphe allocation ressourcesavec
interblocage Nous avons deux cycles:
P1 R1 P2 R3 P3
R2 P1
P2 R3 P3 R2 P2
aucun proc ne peut
terminer aucune
possibilité d’en sortir
Chap 8 16
387.
Graphe allocation ressourcesavec cycle,
mais pas d’ interblocage (pourquoi?)
Attente circulaire, mais les ressources peuvent devenir
disponibles
Chap 8 17
388.
Constatations
Chap 8 18
Lescycles dans le graphe alloc ressources ne
signalent pas nécessairement une attente
circulaire
S ’il n`y a pas de cycles dans le graphe, aucun
interblocage
S ’il y a de cycles:
Si seulement une ressource par type,
interblocage
(pourquoi?!)
Si plusieurs ressources par type,
possibilité d’interblocage
Il faut se poser la question: y-a-t-il un processus qui
peut terminer et si oui, quels autres processus
peuvent terminer en conséquence?
389.
Hypothèse de terminaison
Chap8 19
Un proc qui a toutes les ressources dont il
a besoin, il s’en sert pour un temps fini,
puis il les libère
Nous disons que le processus termine,
mais il pourrait aussi continuer, n’importe,
l’important est qu’il laisse la ressource
390.
Méthodes pour traitementinterblocage
Chap 8 20
Concevoir le système de façon qu`un interblocage
soit impossible
difficile, très contraignant
approprié dans le cas de systèmes critiques
Les interblocages sont possibles, mais sont évités
(avoidance)
Permettre les interblocages, en récupérer
Ignorer le problème, qui donc doit être résolu par
le gérant ou l ’usager
malheureusement, méthode d ’utilisation générale!
391.
Prévention d’interblocage: prévenirau moins une des 4
conditions nécessaires
Chap 8 21
Exclusion mutuelle: réduire le plus possible l ’utilisation
des ressources partagées et Sections Critiques
Possible seulement dans le cas de procs
totalement indépendants
Saisie et attente (hold and wait): un processus qui
demande des nouvelles ressources ne devrait pas en
retenir des autres (les demander toutes ensemble)
Comment savoir?
Préemption: si un processus qui demande d’autres
ressources ne peut pas les avoir, il doit être suspendu, ses
ressources doivent êtres rendues disponibles
OK, demande intervention du SE
Attente circulaire: imposer un ordre partiel sur les
ressources, un processus doit demander les ressources
dans cet ordre (p.ex. tout processus doit toujours demander
une imprimante avant de demander une unité ruban)
Difficile
392.
Éviter les interblocages(deadlock avoidance)
Chap 8 22
Chaque processus doit déclarer le nombre
max. de ressources dont il prévoit avoir
besoin
L’algorithme examine toutes les
séquences d ’exécution possibles pour
voir si une attente circulaire est possible
393.
État sûr (safestate)
Un état est sûr si le système peut en sortir sans
interblocages
Ne pas allouer une ressource à un processus si
l’état qui en résulte n’est pas sûr
États sûrs
É. non-sûrs
Chap 8 23
Impasse
394.
État sûr
Chap 824
Une séquence de proc <P1, P2, …, Pn> est
sûre si pour chaque Pi, les ressources que
Pi peut encore demander peuvent être
satisfaites par les ressources couramment
disponibles + ressources utilisées par
les Pj qui les précèdent.
Quand Pi aboutit, Pi+1 peut obtenir les
ressources dont il a besoin, terminer,
donc
<P1, P2, …, Pn> est un ordre de terminaison
de processus: tous peuvent se terminer
dans cet ordre
395.
Algorithme d’allocation deressources
Chap 8 25
Il faut maintenant prendre en
considération:
les requêtes possibles dans le futur
(chaque processus doit déclarer ça)
Arête demande Pi - - > Rj indique que
le processus Pi peut demander la
ressource Rj (ligne à tirets)
396.
Chap 8 26
Graphed`allocation ressources
Ligne continue: requête
courante; tirets: requête
397.
Un état passûr
Si P2 demande R2, ce dernier ne peut pas lui être donné, car ceci peut causer
un cycle dans le graphe si P1 req R2. Mieux vaut attendre la fin de P1, puis
faire finir P2
Chap 8 27
398.
Détection d ’interblocage
Chap8 28
On permet au système d’entrer dans un
état d’interblocage
L’interblocage est détecté
On récupère de l’interblocage
399.
Différence entre attenteet interblocage
Chap 8 29
Il est difficile de détecter s ’il y a effectivement une
interblocage dans le système
Nous pourrions voir qu’un certain nombre
de processus est en attente de ressources
ceci est normal!
Pour savoir qu’il y a interblocage, il faut
savoir qu’aucun processus dans un groupe
n’a de chance de recevoir la ressource
car il y a attente circulaire!
Ceci implique une analyse additionnelle, que
peu de SE se prennent la peine de faire...
400.
Méthode de détectiond’interblocage dans le
cas d’une ressource par type
Chap 8 30
Essentiellement, la méthode déjà décrite
Construire un graphe d’allocation
ressources et voir s’il y a une manière dont
tous les proc peuvent terminer
Dans le cas d’une ressource par type,
l`algorithme cherche des cycles dans le
graphe (algorithme d’ordre n2, si n=nombre
de sommets)
Plus difficile dans le cas de
plus. ressources par type
Pas discuté
Récupérer d’interblocages
Chap 832
Terminer tous les processus dans
l’interblocage
Terminer un processus à la fois, espérant
d’éliminer le cycle d ’interblocages
Dans quel ordre: différents critères:
priorité
besoin de ressources: passé, futur
combien de temps il a exécuté, de combien
de temps il a encore besoin
etc.
403.
Récupération: préemption deressources
Chap 8 33
Minimiser le coût de sélectionner la victime
Rollback: retourner à un état sûr
besoin d`établir régulièrement et garder
des ‘points de reprise’, sortes de photos
de l ’état courant du processus
p.ex. Word établit des points de reprise
qu’il vous propose après un ‘accident’
Famine possible si le même processus est
toujours sélectionné
404.
Combinaison d’approches
Chap 834
Combiner les différentes approches, si
possible, en considération des contraintes
pratiques
prévenir
éviter
détecter
utiliser les techniques les plus appropriées
pour chaque classe de ressource
405.
Importance du pbde l’interblocage
Chap 8 35
L’interblocage est quasiment ignoré dans
la conception des systèmes d’aujourd’hui
Avec l’exception des systèmes critiques
S’il se vérifie, l’usager verra une panne de
système ou l’échec d’un processus
Dans les systèmes à haut parallélisme du
futur, il deviendra de plus en plus
important de le prévenir et éviter
406.
Par rapport aumanuel
Chap 8 36
Tout le chapitre, mais le code Java n’est
pas important pour l’examen
407.
Interblocages: concepts importants
Chap8 37
Caractérisation: les 4 conditions
Graphes allocation ressources
Séquences de terminaison
États sûrs et non-sûrs
Prévenir les interblocages
Éviter les interblocages
Détecter les interblocages
Récuperer d’un interblocage
Dans ce chapitrenous
verrons que, pour optimiser
l’utilisation dela mémoire, les
programmes sont éparpillés
en mémoire selon des
méthodes différentes:
Pagination, segmentation
Chap. 9 2
410.
Gestion de mémoire:objectifs
Chap. 9 3
Optimisation de l ’utilisation de la
mémoire principale = RAM
Les plus grand nombre possible de
processus actifs doit y être gardé, de
façon à optimiser le fonctionnement du
système en multiprogrammation
garder le système le plus occupé
possible, surtout l’UCT
s’adapter aux besoins de mémoire de l
’usager
allocation dynamique au besoin
411.
Gestion de lamémoire: concepts dans ce
chapitre
Chap. 9 4
Adresse physique et adresse logique
mémoire physique et mémoire logique
Remplacement
Allocation contiguë
partitions fixes
variables
Pagination
Segmentation
Segmentation et pagination combinées
Groupes de paires (buddy systems)
412.
Application de cesconcepts
Chap. 9 5
Pas tous les concepts de ce chapitre sont
effectivement utilisés tels quels
aujourd’hui dans la gestion de mémoire
centrale
Cependant plusieurs se retrouvent dans le
domaine de la gestion de mémoires
auxiliaires, surtout disques
413.
Mémoire/Adresses physiques etlogiques
Chap. 9 6
Mémoire physique:
la mémoire principale RAM de la machine
Adresses physiques: les adresses de cette
mémoire
Mémoire logique: l’espace d`adressage d’un
programme
Adresses logiques: les adresses dans cet
espace
Il faut séparer ces concepts car normalement, les
programmes sont chargés de fois en fois dans
positions différentes de mémoire
Donc adresse physique ≠ adresse logique
414.
Traduction adresses logiquesadr.
physiques
MMU: unité de gestion de mémoire
unité de traduction adresses
(memory management unit)
Chap. 9 7
415.
Définition des adresseslogiques
Chap. 9 8
Le manuel définit les adresses logiques
comme étant les adresses générées par
l’UCT
Mais parfois l’MMU est partie de l ’UCT!
Je préfère la déf suivante:
une adresse logique est une adresse à
une location de programme
par rapport au programme lui-même
seulement
indépendante de la position du
programme en mémoire physique
416.
Vue de l’usager
Chap.9 9
Normalement, nous avons plusieurs
types d’adressages p.ex.
les adresses du programmeur (noms symboliques)
sont traduites au moment de la compilation dans
des
adresses logiques
ces adresses sont traduites en adresses physiques
par l’unité de traduction adresses (MMU)
Étant donné la grande variété de matériel et logiciel, il
est impossible de donner des défs. plus précises.
417.
Liaison (Binding) d’adresseslogiques
et physiques (instructions et données)
Chap. 9 10
La liaison des adresses logiques aux adresses
physiques peut être effectuée en moments
différents:
Compilation: quand l’adresse physique est connue
au moment de la compilation (rare)
p.ex. parties du SE
Chargement: quand l’adresse physique où le progr
est chargé est connue, les adresses logiques
peuvent être traduites (rare aujourd’hui)
Exécution: normalement, les adresses physiques
ne sont connues qu’au moment de l ’exécution
p.ex. allocation dynamique
418.
Deux concepts de
base
Chap.9 11
Chargement = Loading. Le programme, ou une de
ses parties, est chargé en mémoire physique, prêt
à exécuter.
Statique (avant l’exécution)
Dynamique (pendant l’exécution)
Édition de liens = Liaison (enchaînement) des
différentes parties d’un programme pour en faire
une entité exécutable.
les références entre modules différents doivent
être traduites
statique (avant l`exécution)
dynamique (sur demande pendant exécution)
• N.B. parties du programme = modules =
segments = sousprogrammes = objets, etc.
419.
Chap. 9 12
Éditionde liens: adressage entre modules
B
Données
D
Sous-
progr.
A
Progr.
Princ.
C
Données
JUMP(D, 100)
LOAD(C,250)
LOAD(B,50)
Les adresses sont en deux parties :
(No de module, Décalage dans le
module)
doivent être traduites pour permettre
Espace
d’adressage
logique
420.
Édition de liens:
uneméthode possible qui supporte la liaison
dynamique
Tableau Définitions de
A Noms internes de
A
Nom Adresse
Tableau Usage de
A Noms Externes
de A
Nom x
Défini dans Module B
Module A corps
Réf à x dans B
Chaque module contient
deux tableaux
Tableau Définitions de
B Noms internes de
B
Nom x Adresse
Tableau Usage de
B Noms Externes
de B
Nom Défini dans Module
Module B corps
x dans B
Chap. 9 13
421.
Adressage
indirecte
peut être utilisédans cette
méthode
(v. aussi chaînes d’adresses en C ou C++)
code op adresse
instruction
Chap. 9 14
1
1
1
1: adresse indirecte: le mot contient
une adresse
0: ce mot est le mot qui contient la
donnée visée
mot adressé
0
422.
Cette méthode supportel’allocation
dynamique
Si le module B n’a pas encore
été chargé, la référence à B
dans le tableau des noms
externes de A contiendra
l ’information nécessaire
pour
trouver et charger B.
Après avoir fait ça, cette
référence sera traduite dans
une adresse de mémoire
physique.
Si B reste toujours au même
endroit, nous pouvons mettre
dans A directement l’adresse
finale (flèche pointillée), sinon
nous pouvons continuer de
rejoindre B par adressage
indirecte
Tableau Définitions de
A Noms internes de
A
Nom
Adresse Tableau
Usage de A Noms
Externes de A
Tableau Définitions de
B Noms internes de
B
Nom x
Adresse
Tableau Usage de B
Noms Externes de
B
Nom
Défini dans Module
Module B corps
Nom x Défini dans
Module B
Module A corps
Réf à x dans B x dans
B
Chap. 9 15
423.
Aspects du chargement
Chap.9 16
Trouver de la mémoire libre pour un
module de chargement: contiguë ou non
Traduire les adresses du programme et
effectuer les liaisons par rapport aux
adresses où le module est chargé
424.
Chargement (pas contiguici) et traduction d’adresses
Mémoire logique
Alloc. de mém.
JUMP 328
Mém. physique
Chap. 9 17
JUMP 10328
Autres
programmes
0
500K
425.
Liaison et
chargement
v. fig.plus complète dans
livre
Progr.
exécutable
Compilateur Modules
Objet
Éditeur
de liens
Modules
Liés
Chargeur
Autres
Mods
(librairie)
NB: on fait l`hypothèse que tous les modules soient connus au
début Souvent, ce n’est pas le cas chargement
dynamique
Chap. 9 18
Progr.
Source
426.
Chargement et liaisondynamique
Chap. 9 19
Un processus exécutant peut avoir besoin de différents
modules du programme en différents moments
Le chargement statique peut donc être inefficace
Il est mieux de charger les modules sur demande =
dynamique
dll, dynamically linked libraries
Dans un programme qui peut avoir besoin de charger des
modules dynamiquement, au début ces derniers sont
représentés par des stubs qui indiquent comment arriver au
modules (p.ex. où il se trouve: disque, www, autre...)
À sa 1ère exéc. le stub cause le chargement du module en
mémoire et sa liaison avec le reste du programme
liaison dynamique
Les invocations successives du module ne doivent pas
passer à travers ça, on saura l’adresse en mémoire
427.
Traduction d’adresses logique physique
Chap. 9 20
Dans les premiers systèmes, un programme était toujours
chargé dans la même zone de mémoire
La multiprogrammation et l’allocation dynamique ont
engendré le besoin de charger un programme dans
positions différentes
Au début, ceci était fait par le chargeur (loader) qui
changeait les adresses avant de lancer l ’exécution
Aujourd’hui, ceci est fait par le MMU au fur et à mesure que
le progr. est exécuté
Ceci ne cause pas d’hausse de temps d ’exécution, car le
MMU agit en parallèle avec autres fonctions d ’UCT
P.ex. l ’MMU peut préparer l ’adresse d ’une instruction
en même temps que l ’UCT exécute l ’instruction
précédente
428.
Recouvrement ou overlay
Dansquelques systèmes surtout dans le passé), la permutation
de modules (swapping) d’un même programme pouvait être
gérée par l ’usager
Deux parties d’un programme qui utilisent la même zone de
mémoire
Chap. 9 21
429.
Permutation de programmes(swapping)
Un programme, ou une partie de
programme, peut être temporairement
enlevé de mémoire pour permettre
l’exécution d’autres programmes (chap. 4)
il est mis dans mémoire secondaire,
normal. disque
Chap. 9 22
Affectation contiguë demémoire
Chap. 9 24
Nous avons plusieurs programmes à exécuter
Nous pouvons les charger en mémoire les uns
après les autres
le lieu où un programme est lu n’est connu
qu’au moment du chargement
Besoins de matériel: registres translation et
registres bornes
L’allocation contiguë n’est plus utilisée aujourd’hui pour la mémoire
centrale, mais les concepts que nous verrons sont encore utilisés pour
l’allocation de fichiers sur disques
432.
Affectation contiguë de
mémoire
SE
progr.1
progr. 2
disponible
progr. 3
Nous avons ici 4 partitions pour des
programmes - chacun est chargé dans une
seule zone de mémoire
Chap. 9 25
433.
Registres bornes (oulimites) et translation dans
MMU
adresse de base
de la partition où
le progr
. en éxec.
se trouve
adresse limite de
la partition o
ù le
progr
. en éxec. se
trouve
Chap. 9 26
434.
Fragmentation: mémoire nonutilisée
Chap. 9 27
Un problème majeur dans l`affectation
contiguë:
Il y a assez d ’espace pour exécuter un
programme, mais il est fragmenté de façon
non contiguë
externe: l`espace inutilisé est entre partitions
interne: l ’espace inutilisé est dans les
partitions
435.
Chap. 9 8
2
Partitionsfixes
Mémoire principale
subdivisée en régions
distinctes: partitions
Les partitions sont soit
de même taille ou de
tailles inégales
N’importe quel progr.
peut être affecté à une
partition qui soit
suffisamment grande
(Stallings)
436.
Chap. 9 9
2
Algorithmede placement
pour partitions fixes
Partitions de tailles
inégales: utilisation de
plusieurs files
assigner chaque
processus à la
partition de la plus
petite taille pouvant
le contenir
1 file par taille
de partition
tente de minimiser
la fragmentation
interne
Problème: certaines
files seront vides s’il
(Stallings)
437.
Chap. 9 0
3
Algorithmede placement
pour partitions fixes
Partitions de tailles
inégales: utilisation
d’une seule file
On choisit la plus
petite partition libre
pouvant contenir le
prochain processus
le niveau de
multiprogrammation
augmente au profit de
la fragmentation
interne
(Stallings)
438.
Partitions
fixes
Chap. 9 31
Simple,mais...
Inefficacité de l’utilisation de la mémoire:
tout programme, si petit soit-il, doit
occuper une partition entière. Il y a
fragmentation interne.
Les partitions à tailles inégales atténue ces
problèmes mais ils y demeurent...
439.
Partitions dynamiques
Chap. 932
Partitions en nombre et tailles variables
Chaque processus est alloué exactement la
taille de mémoire requise
Probablement des trous inutilisables se
formeront dans la mémoire: c’est la
fragmentation externe
440.
Partitions dynamiques:
exemple
(Stallings
)
(d) Ily a un trou de 64K après avoir chargé 3 processus: pas
assez d’espace pour autre processus
Si tous les proc se bloquent (p.ex. attente d’un événement), P2
peut être permuté et P4=128K peut être chargé.
Swapped out
Chap. 9 33
441.
34
(e-f) Progr. 2est suspendu, Progr. 4 est chargé. Un trou de 224-128=96K est créé
(fragmentation externe)
(g-h) P1 se termine ou il est suspendu, P2 est repris à sa place: produisant un autre
trou de 320-224=96K...
Nous avons 3 trous petits et probabl. inutiles. 96+96+64=256K de fragmentation
externe
Chap. 9COMPRESSION pour en faire un seul trou de 256K
Partitions dynamiques: exemple (Stallings)
442.
Algorithmes
de Placement
pour déciderde
l’emplacement du prochain
processus
But: réduire l’utilisation de la
compression (prend du
temps...)
Choix possibles:
Best fit: choisir le plus
petit trou (meilleur accès)
Worst fit: le plus grand
(pire accès)
First-fit: choisir 1er trou à
partir du début (premier
accès)
Next-fit: choisir 1er trou
à partir du dernier
placement (prochain accès) (Stallings)
Chap. 9 35
443.
Algorithmes de placement:commentaires
Chap. 9 36
Quel est le meilleur?
critère principal: diminuer la probabilité de situations
où un processus ne peut pas être servi, même s ’il y a
assez de mémoire...
Best-fit: cherche le plus petit bloc possible: le trou créé
est le plus petit possible
la mémoire se remplit de trous trop petits pour
contenir un programme
Worst-fit: le trous crées seront les plus grands
possibles
Next-fit: les allocations se feront souvent à la
fin de la
mémoire
La simulation montre qu` il ne vaut pas la peine d ’utiliser
les algo les plus complexes... donc first fit
444.
Suspension (v. chap4)
Lorsque tous les programmes en mémoire
sont bloqués, le SE peut en suspendre un
(swap/suspend)
On transfère au disque un des processus
bloqués (en le mettant ainsi en état
suspended) et le remplacer par un
processus prêt à être exécuté
ce dernier processus exécute une
transition d’état Nouveau ou Suspendu à
état Ready
Chap. 9 37
445.
Compression (compaction)
Chap. 938
Une solution pour la fragmentation externe
Les programmes sont déplacés en mémoire de
façon à réduire à 1 seul grand trou plusieurs
petits trous disponibles
Effectuée quand un programme qui demande
d’être exécuté ne trouve pas une partition assez
grande, mais sa taille est plus petite que la
fragmentation externe existante
Désavantages:
temps de transfert programmes
besoin de rétablir tous les liens entre adresses
de différents programmes
446.
Système de «groupede paires » (buddy
systems):
Chap. 9 39
une approche complètement différente (Unix, Linux, sect.
21.6.1)
Débutons avec un seul gros block de taille 2U
Sur une requête pour un block de taille S:
Si 2U-1 < S <= 2U alors allouer le block entier de taille 2U
Sinon, partager ce block en deux compagnons
(buddies), chacun de taille 2U-1
Si 2U-2 < S <= 2U-1 alors allouer un des deux
compagnons
Sinon diviser un de ces 2 compagnons
Le processus est répété jusqu’à ce que le plus petit block
pouvant contenir S soit généré
Deux compagnons sont fusionnés lorsqu’ils deviennent
tous deux non alloués
Système de groupesde paires (Buddy system)
Chap. 9 41
Le SE maintient plusieurs listes de trous
la i-liste est la liste des trous de taille 2i
lorsqu’une paire de compagnons se
trouvent dans une i-liste, ils sont enlevés
de cette liste et deviennent un seul trou de
la (i+1)-liste
Sur une requête pour une allocation d’un
block de taille k tel que 2i-1 < k <= 2i:
on examine d’abord la i-liste
si elle est vide, on tente de trouver un trou
dans la (i+1)-liste, si trouvé, il sera divisé en
2
449.
Comment trouver lecompagnon
Chap. 9 42
Étant donné
L’adresse binaire d’un bloc
La longueur du bloc
Comment trouver son compagnon
Si la longueur du bloc est 2n
Si le bit n de l’adresse est 0, changer à 1
(compagnon est à droite)
Si le bit n de l’adresse est 1, changer à 0
(compagnon est à gauche)
Exemples:
011011110000 longueur 100: 011011110100
011011110000 longueur 10000: 011011100000
(Compter les bits à partir de la droite et de 0)
450.
Groupes de paires:remarques
Chap. 9 43
En moyenne, la fragmentation interne est de 25%
par processus
en moyenne pour chaque proc nous aurons
une partition pleine de la grandeur d`une
puissance de deux, plus une utilisée à moitié
+ il pourra y avoir aussi des blocs non utilisés
s’il n’y a pas de programmes en attente
pouvant les utiliser.
Pas besoin de compression
simplifie la gestion de la mémoire
451.
Allocation non contiguë
Chap.9 44
A fin de réduire la fragmentation, tous les ordis
d’aujourd’hui utilisent l’allocation non contiguë
diviser un programme en morceaux et permettre
l`allocation séparée de chaque morceau
les morceaux sont beaucoup plus petits que le
programme entier et donc permettent une utilisation
plus efficace de la mémoire
les petits trous peuvent être utilisés plus facilement
Il y a deux techniques de base pour faire ceci: la pagination
et la segmentation
la segmentation utilise des parties de programme qui ont
une valeur logique (des modules)
la pagination utilise des parties de programme
arbitraires (morcellement du programmes en pages de
longueur fixe).
elles peuvent être combinées
Je trouve que la segmentation est plus naturelle, donc
je commence par celle-ci
452.
Chap. 9 45
Lessegments sont des parties logiques du progr.
A
Progr.
Princ.
B
Données
D
Sous-
progr.
C
Données
JUMP(D, 100)
LOAD(C,250)
LOAD(B,50)
4 segments: A, B, C,
453.
Les segments commeunités d’alloc
mémoire
0
2
1
3
0
3
1
2
espace usager mémoire physique
Étant donné que les segments sont plus petits que les programmes
entiers, cette technique implique moins de fragmentation (qui est
externe dans ce cas)
Chap. 9 46
454.
Mécanisme pour la
segmentation
Untableau contient l’adresse de début de tous les segments dans un
processus
Chaque adresse dans un segment est ajoutée à l ’adresse de début du
segment par la MMU
0
3
1
2
Adr de 3
Adr de 2
Adr de 1
Adr de 0
segment courant
Tableau de
descripteurs de
segments
m
Chap. 9 47
455.
Détail
s
Chap. 9 48
L’adresselogique consiste d ’une paire:
<No de segm, décalage>
où décalage est l ’adresse dans le segment
Le tableau des segments contient: descripteurs de
segments
adresse de base
longueur du segment
Infos de protection, on verra…
Dans le PCB du processus il y aura un pointeur à
l ’adresse en mémoire du tableau des segments
Il y aura aussi là dedans le nombre de segments
dans le processus
Au moment de la commutation de contexte, ces
infos seront chargées dans les registres
appropriés d’UCT
Traduction d`adresses dansla
segmentation
(figure de Stallings: légère diff. par rapport à la terminologie de
Silberschatz)
Aussi, si d > longueur:
Chap. 9 50
458.
Le mécanisme endétail (implanté dans le
matériel)
Stallings Adresse
Chap. 9 51
Dans le
programme
459.
Chap. 9 52
Partagede segments: le segment 0 est
partagé
P
.ex: Programme Word utilisé pour éditer
différents
documents
DLL utilisé par plus
460.
Mécanisme pour 2processus qui exécutent un seul
programme sur données différentes
La même instruction, si elle est exécutée
par le proc 1, son adresse est modifiée par le contenu du
registre 1
par le proc 2, son adresse est modif par le contenu du
registre 2 Ceci fonctionne même si l’instruction est exécutée par
plus. UCT au même instant, si les registres se trouvent dans des
Programme
Données
proc 1
Données
proc 2
Instruction
R1
Chap. 9 53
R2
+
+
461.
Segmentation et protection
Chap.9 54
Chaque descripteur de segment peut
contenir des infos de protection:
longueur du segment
privilèges de l`usager sur le segment:
lecture, écriture, exécution
Si au moment du calcul de l’adresse on
trouve que l’usager n’a pas droit
d’accèsinterruption
ces infos peuvent donc varier d
’usager à usager, par rapport au même
segment!
limite base read, write,
execute?
462.
Évaluation de lasegmentation simple
Chap. 9 55
Avantages: l’unité d’allocation de mémoire est
plus petite que le programme entier
une entité logique connue par le programmeur
les segments peuvent changer de place en mémoire
la protection et le partage de segments sont aisés
(en principe)
Désavantage: le problème des partitions
dynamiques:
La fragmentation externe n’est pas éliminée:
trous en mémoire, compression?
Une autre solution est d`essayer à simplifier le mécanisme
en utilisant unités d`allocation mémoire de tailles égales
PAGINATION
463.
Segmentation contre pagination
Chap.9 56
Le pb avec la segmentation est que l’unité
d’allocation de mémoire (le segment) est
de longueur variable
La pagination utilise des unités
d’allocation de mémoire fixe, éliminant
donc ce pb
464.
Pagination simple
Chap. 957
La mémoire est partitionnée en petits morceaux de
même taille: les pages physiques ou ‘cadres’ ou
‘frames’
Chaque processus est aussi partitionné en petits
morceaux de même taille appelés pages (logiques)
Les pages logiques d’un processus peuvent donc être
assignés aux cadres disponibles n’importe où en
mémoire principale
Conséquences:
un processus peut être éparpillé n’importe où
dans la mémoire physique.
la fragmentation externe est éliminée
465.
Exemple de chargementde processus
Chap. 9 58
Supposons que le processus B se termine ou
est suspendu Stallings
466.
Exemple de chargementde processus
(Stallings)
Nous pouvons maintenant
transférer en mémoire un
progr. D, qui demande 5
cadres
bien qu`il n’y ait pas
5 cadres
contigus disponibles
La fragmentation externe
est limitée au cas que le
nombre de pages
disponibles n’est pas
suffisant pour exécuter un
programme en attente
Seule la dernière page d’un
progr peut souffrir de
fragmentation interne
(moy. 1/2 cadre par proc)
Chap. 9 59
467.
Tableaux de pages
Lesentrées dans le tableau
de pages sont aussi
appelées descripteurs de
pages
Chap. 9 60
468.
Tableaux de
pages
Le SEdoit maintenir une table de pages pour chaque
processus
Chaque descripteur de pages contient le numéro de cadre
où la page correspondante est physiquement localisée
Une table de pages est indexée par le numéro de la page
afin d’obtenir le numéro du cadre
Une liste de cadres disponibles est également
maintenue
(free frame list)
Stallings
Chap. 9 61
469.
Traduction
d’adresses
L’adresse logique estfacilement traduite
en adresse physique
car la taille des pages est une
puissance de 2
les pages débutent toujours à des
adresses qui sont puissances de 2
qui ont autant de 0s à droite que la
longueur de l’offset
donc ces 0s sont remplacés par
l’offset
Ex: si 16 bits sont utilisés pour les
adresses et que la taille d’une page = 1K:
on a besoins de 10 bits pour le décalage,
laissant ainsi 6 bits pour le numéro de
page
L’adresse logique (n,m) est traduite à
l ’adresse physique (k,m) en utilisant n
comme index sur la table des pages et
en le remplaçant par l ’adresse k trouvée
m ne change pas
Stalling6
Chap. 9
Trad. d’adresses: segmentationet pagination
Chap. 9 65
Tant dans le cas de la segmentation, que dans le
cas de la pagination, nous ajoutons le décalage à
l’adresse du segment ou page.
Cependant, dans la pagination, l’addition peut être
faite par simple concaténation:
11010000+1010
=
1101 1010
473.
Deux petits problèmes
Chap.9 66
A) Considérez un système de 4 cadres ou pages physiques, chacune de 4
octets. Les adresses sont de 4 bits, deux pour le numéro de page, et 2 pour
le décalage. Le tableau de pages du processus couramment en exécution
est:
Numéro
de page
Numéro
de cadre
00 11
01 10
10 01
11 00
.
Considérez l'adresse logique 1010. Quelle sera l'adresse
physique correspondante?
B) Considérez maintenant un système de segmentation, pas de
pagination. Le tableau des segments du processus en exécution est
comme suit:
Segmen
t
number
Base
00 110
01 100
10 000
Considérez l'adresse logique (no de seg, décalage)= (01, 01) , quelle
est l'adresse physique?
474.
Adresse logique (pagination)
Chap.9 67
Les pages sont invisibles au programmeur,
compilateur ou assembleur (seule les adresses
relatives sont employées)
Un programme peut être exécuté sur
différents matériels employant dimensions de
pages différentes
Ce qui change est la manière dont l’adresse est
découpée
475.
Problèmes d’efficacité
Chap. 968
La traduction d`adresses, y compris la recherche
des adresses des pages et de segments, est
exécutée par des mécanismes de matériel
Cependant, si la table des pages est en mémoire
principale, chaque adresse logique occasionne au
moins 2 références à la mémoire
Une pour lire l’entrée de la table de pages
L’autre pour lire le mot référencé
Le temps d`accès mémoire est doublé...
476.
Pour améliorer l`efficacité
Chap.9 69
Où mettre les tables des pages (les mêmes idées
s ’appliquent aussi aux tabl. de segm)
Solution 1: dans des registres de UCT.
avantage: vitesse
désavantage: nombre limité de pages par proc., la
taille de la mém. logique est limitée
Solution 2: en mémoire principale
avantage: taille de la mém. logique illimitée
désavantage: mentionné
Solution 3 (mixte): les tableaux de pages sont en
mémoire principale, mais les adresses les plus
utilisées sont aussi dans des registres d`UCT.
477.
Chap. 9 v.Content-addressable memory dans Wikipedia
Régistres associatifs
TLB
TLB: Translation Lookaside Buffers, ou caches d’adressage
Recherche parallèle d ’une adresse:
l ’adresse recherchée est cherchée dans la
partie gauche de la table en parallèle (matériel
spécial)
Traduction page cadre
Si la page recherchée a été utilisée récemment elle
se trouvera dans les registres associatifs
recherche rapide
3 15
7 19
0 17
2 23
No Page No
Cadre
478.
Recherche associative dansTLB
Chap. 9 71
Le TLB est un petit tableau de registres de
matériel où chaque ligne contient une paire:
Numéro de page logique, Numéro de cadre
Le TLB utilise du matériel de mémoire
associative: interrogation simultanée de tous les
numéros logiques pour trouver le numéro
physique recherché
Chaque paire dans le TLB est fournie d ’un
indice de référence pour savoir si cette paire a
été utilisée récemment. Sinon, elle est
remplacée par la dernière paire dont on a besoin
479.
Translation Lookaside Buffer(TLB)
Chap. 9 72
Sur réception d’une adresse logique, le processeur
examine le cache TLB
Si cette entrée de page y est , le numéro de cadre
en est extrait
Sinon, le numéro de page indexe la table de page
du processus (en mémoire)
Cette nouvelle entrée de page est mise dans le TLB
Elle remplace une autre pas récemment utilisée
Le TLB est vidé quand l’UCT change de proc
Les premières trois opérations sont faites par matériel
7
Temps d’accès réelavec TLB
Recherche dans TLB = unités de temps (normalement petit)
Supposons que le cycle de mémoire soit 1 microseconde
= probabilité de touches (hit ratio) = probabilité qu’un numéro
de page soit trouvé dans les registres associatifs (quantité entre 0 et 1)
ceci est en relation avec le nombre de registres associatifs disponibles
Temps effectif d’accès tea:
tea = (1 + ) + (2 + )(1 – )
= 2 + –
si est près de 1 et est petit, ce temps sera près de 1.
Dans plusieurs ordinateurs, il y a simultanéité entre ces opérations
et d’autres opérations de l’UCT donc le temps d’accès réel est plus
favorable
Généralisation de la formule prenant m comme temps d’accès à la mémoire
centrale: tea = (m+ ) + (2m+ )(1- ) = m + + 2m - 2m + -
=
= 2m + -m
Cette formule peut être utilisée de différentes manières,
p.ex. étant connu un tea désiré, déterminer nécessaire
Chap. 9
482.
Tableaux de pagesà deux niveaux
(quand les tableaux de pages sont très grands, ils peuvent être eux mêmes
paginés)
tableau de pages du
tableau de pages
Chap. 9 75
483.
Tableaux de pagesà deux niveaux
La partie de l ’adresse qui appartient au numéro
de page est elle-même divisée en 2
Chap. 9 76
484.
Partage de pages:
3proc. partageant un éditeur, sur des données privées à chaque
proc
1 seule copie de
l’éditeur en mémoire
au lieu de 3
Chap. 9 77
485.
Segmentation simple vsPagination
simple
Chap. 9 78
La pagination se préoccupe seulement du problème du chargement,
tandis que
La segmentation vise aussi le problème de la liaison
La segmentation est visible au programmeur mais la pagination ne
l’est pas
Le segment est une unité logique de protection et partage, tandis
que la page ne l’est pas
Donc la protection et le partage sont plus aisés dans la
segmentation
La segmentation requiert un matériel plus complexe pour la
traduction d’adresses (addition au lieu d`enchaînement)
La segmentation souffre de fragmentation externe (partitions
dynamiques)
La pagination produit de fragmentation interne, mais pas beaucoup
(1/2 cadre par programme)
Heureusement, la segmentation et la pagination peuvent être
combinées
486.
Pagination et segmentationcombinées
Chap. 9 79
Les programmes sont divisés en segments
et les segments sont paginés
Donc chaque adresse de segment n`est
pas une adresse de mémoire, mais une
adresse au tableau de pages du segment
Les tableaux de segments et de pages
peuvent être eux-mêmes paginés
Méthode inventée pour le système Multics
de l’MIT, approx. 1965.
487.
Adressage (sans considérerla pagination des tableaux
de pages et de segments)
segment table base
register: un registre de
l`UCT
s p d’
d
Chap. 9 80
Utilisation de TranslationLookaside Buffer
Chap. 9 82
Dans le cas de systèmes de pagination à
plusieurs niveaux, l’utilisation de TLB
devient encore plus importante pour éviter
multiples accès en mémoire pour calculer
une adresse physique
Les adresses les plus récemment
utilisées sont trouvées directement dans la
TLB.
490.
Conclusions sur GestionMémoire
Chap. 9 83
Problèmes de:
fragmentation (interne et externe)
complexité et efficacité des algorithmes
Méthodes
Allocation contiguë
Partitions fixes
Partitions variables
Groupes de paires
Pagination
Segmentation
Problèmes en pagination et segmentation:
taille des tableaux de segments et pages
pagination de ces tableaux
efficacité fournie par Translation Lookaside Buffer
Les différentes méthodes décrites dans ce chapitre, et dans le
chapitre suivant, sont souvent utilisées conjointement, donnant
lieu a des systèmes complexes
491.
Recapitulation sur lafragmentation
Chap. 9 84
Partition fixes: fragmentation interne car les partitions ne
peuvent pas être complèt. utilisées + fragm. externe s`il y
a des partitions non utilisées
Partitions dynamiques: fragmentation externe qui conduit
au besoin de compression.
Paires: fragmentation interne de 25% pour chaque
processus + fragm. externe s ’il y a des partit. non utilisées
Segmentation sans pagination: pas de fragmentation
interne, mais fragmentation externe à cause de segments
de longueur différentes, stockés de façon contiguë (comme
dans les partitions dynamiques)
Pagination:
en moyenne, 1/2 cadre de fragm. interne par processus
dans le cas de mémoire virtuelle, aucune
fragmentation externe (v. chap suivant)
Donc la pagination avec mémoire virtuelle offre la meilleure
solution au pb de la fragmentation
492.
Par rapport aulivre
Chap. 9 85
Tout à l’exception de la section 9.4.4
(tables de pages inversées)
493.
DLL http://www.webopedia.com/TERM/D/DLL.html
Chap. 986
Short for Dynamic Link Library, a library of executable functions or data
that can be used by a Windows application. Typically, a DLL provides one
or more particular functions and a program accesses the functions by
creating either a static or dynamic link to the DLL. A static link remains
constant during program execution while a dynamic link is created by the
program as needed. DLLs can also contain just data. DLL files usually end
with the extension .dll,.exe., drv, or .fon.
A DLL can be used by several applications at the same time. Some DLLs
are provided with the Windows operating system and available for any
Windows application. Other DLLs are written for a particular application
and are loaded with the application. Short for Dynamic Link Library, a
library of executable functions or data that can be used by a Windows
application. Typically, a DLL provides one or more particular functions and
a program accesses the functions by creating either a static or dynamic link
to the DLL. A static link remains constant during program execution while a
dynamic link is created by the program as needed. DLLs can also contain
just data. DLL files usually end with the extension .dll,.exe., drv, or .fon.
A DLL can be used by several applications at the same time. Some DLLs
are provided with the Windows operating system and available for any
Windows application. Other DLLs are written for a particular application
and are loaded with the application.
Mémoire Virtuelle
Chap 102
Pagination sur demande
Problèmes de performance
Remplacement de pages: algorithmes
Allocation de cadres de mémoire
Emballement
Ensemble de travail
496.
Concepts importants duChap. 10
Chap 10 3
Localité des références
Mémoire virtuelle implémentée par va-et-vient des pages,
mécanismes, défauts de pages
Adresses physiques et adresses logiques
Temps moyen d’accès à la mémoire
Récriture ou non de pages sur mém secondaire
Algorithmes de remplacement pages:
OPT, LRU, FIFO, Horloge
Fonctionnement, comparaison
Écroulement, causes
Ensemble de travail (working set)
Relation entre la mémoire allouée à un proc et le nombre
d’interruptions
Relation entre la dimension de pages et le nombre
d’interruptions
Prépagination, post-nettoyage
Effets de l’organisation d’un programme sur l’efficacité de la
pagination
497.
Chap 10 4
Lamémoire virtuelle est une application du
concept de hiérarchie de mémoire
C’est intéressant de savoir que des
concepts très semblables s’appliquent
aux mécanismes de la mémoire cache
Cependant dans ce cas les mécanismes
sont surtout de matériel
magnetic
tapes
optical disk
magnetic disk
electronic disk
cache
main m e m o ry
registers
Mécanismes cache
Méc. mém. virtuelle
RAM
(flash)
498.
La mémoire virtuelle
Chap10 5
À fin qu’un programme soit exécuté, il ne doit pas
nécessairement être tout en mémoire centrale!
Seulement les parties qui sont en exécution ont
besoin d’être en mémoire centrale
Les autres parties peuvent être sur mém
secondaire (p.ex. disque), prêtes à être amenées
en mémoire centrale sur demande
Mécanisme de va-et-vient ou swapping
Ceci rend possible l’exécution de programmes
beaucoup plus grands que la mémoire physique
Réalisant une mémoire virtuelle qui est plus grande
que la mémoire physique
499.
De la paginationet segmentation à la mémoire
virtuelle
Mécanisme de va-et-vien ou
Chap 10 6
Un processus est constitué de morceaux (pages ou segments) ne
nécessitant pas d’occuper une région contiguë de la mémoire
principale
Références à la mémoire sont traduites en adresses physiques au
moment d’exécution
Un processus peut être déplacé à différentes régions de la
mémoire, aussi mémoire secondaire!
Donc: tous les morceaux d’un processus ne nécessitent pas d’être
en mémoire principale durant l’exécution
L’exécution peut continuer à condition que la prochaine
instruction (ou donnée) est dans un morceau se trouvant en
mémoire principale
La somme des mémoires logiques des procs en exécution
peut donc excéder la mémoire physique disponible
Le concept de base de la mémoire virtuelle
Une image de tout l’espace d’adressage du processus est gardée en
mémoire secondaire (normal. disque) d’où les pages manquantes
pourront être prises au besoin
Localité et mémoire
virtuelle
Chap10 8
Principe de localité des références: les
références à la mémoire dans un processus
tendent à se regrouper
Donc: seule quelques pièces d’un processus
seront utilisées durant une petite période de
temps (pièces: pages ou segments)
Il y a une bonne chance de “deviner” quelles
seront les pièces demandées dans un avenir
rapproché
Pages en RAMou sur disque
Page A en RAM et
sur disque
Chap 10 10
Page E seulement
sur disque
504.
Nouveau format dutableau des pages (la même idée peut
être appliquée aux tableaux de segments)
Adresse de
la page
Bit
présen
t
bit présent
1 si en mém.
princ., 0 si en
mém second.
Si la page est en mém.
princ., ceci est une adr. de
mém. Principale
sinon elle est une adresse
de mémoire secondaire
Au début, bit présent = 0 pour toutes les
pages
Chap 10 11
505.
Avantages du chargement
partiel
Chap10 12
Plus de processus peuvent être maintenus en exécution en
mémoire
Car seules quelques pièces sont chargées pour chaque
processus
L’usager est content, car il peut exécuter plusieurs
processus et faire référence à des gros données sans avoir
peur de remplir la mémoire centrale
Avec plus de processus en mémoire principale, il est plus
probable d’avoir un processus dans l’état prêt, meilleure
utilisation d’UCT
Plusieurs pages ou segments rarement utilisés n’auront peut être
pas besoin d`être chargés du tout
Il est maintenant possible d’exécuter un ensemble de processus
lorsque leur taille excède celle de la mémoire principale
Il est possible d’utiliser plus de bits pour l’adresse logique
que le nombre de bits requis pour adresser la mémoire
principale
Espace d ’adressage logique >> esp. d ’adressage physique
506.
Mémoire Virtuelle: PourraitÊtre Énorme!
Chap 10 13
Ex: 16 bits sont nécessaires pour adresser une mémoire
physique de 64KB
En utilisant des pages de 1KB, 10 bits sont requis pour le
décalage
Pour le numéro de page de l’adresse logique nous pouvons
utiliser un nombre de bits qui excède 6, car toutes les pages ne
doivent pas être en mémoire simultanément
Donc la limite de la mémoire virtuelle est le nombre de bits qui
peuvent être réservés pour l ’adresse
Dans quelques architectures, ces bits peuvent être inclus dans
des registres
La mémoire logique est donc appelée mémoire virtuelle
Est maintenue en mémoire secondaire
Les pièces sont amenées en mémoire principale seulement
quand nécessaire, sur demande
507.
Mémoire Virtuelle
Chap 1014
Pour une meilleure performance, la mémoire
virtuelle se trouve souvent dans une région du
disque qui est n’est pas gérée par le système
de fichiers
Mémoire va-et-vient, swap memory
La mémoire physique est celle qui est référencée
par une adresse physique
Se trouve dans le RAM et cache
La traduction de l’adresse logique en adresse
physique est effectuée en utilisant les
mécanismes étudiés dans le chapitre précédent.
Exécution d’un Processus
Chap10 16
Le SE charge la mémoire principale de quelques
pièces (seulement) du programme (incluant le point
de départ)
Chaque entrée de la table de pages (ou segments)
possède un bit présent qui indique si la page ou
segment se trouve en mémoire principale
L’ensemble résident (résident set) est la portion du
processus se trouvant en mémoire principale
Une interruption est générée lorsque
l’adresse logique réfère à une pièce qui n’est
pas dans l’ensemble résident
défaut de pagination, page fault
510.
Exécution d’une défautde page: va-et-vient plus en
détail
Mémoir
e
virtuell
e
Chap 10 17
511.
Séquence d’événements pourdéfaut de page
Chap 10 18
Trappe au SE: page demandée pas en RAM
Sauvegarder registres et état du proc dans PCB
Un autre proc peut maintenant gagner l ’UCT
SE détermine si la page demandée est légale
sinon: terminaison du processus
et trouve la position de la page sur disque
dans le descripteur de la page
lire la page de disque dans un cadre de mémoire
libre (supposons qu`il y en a!)
exécuter les ops disque nécessaires pour lire la
page
512.
Séquence d’événements pourdéfaut de page
(ctn.)
Chap 10 19
L ’unité disque a complété le transfert et
interrompt l’UCT
sauvegarder les registres etc. du proc
exécutant
SE met à jour le contenu du tableau des pages du
proc. qui a causé le défaut de page
Ce processus devient prêt=ready
À un certain point, il retournera à exécuter
la page désirée étant en mémoire, il pourra
maintenant continuer
513.
Chap 10 20
Tempsmoyen d’accès à la
mémoire
Supposons que:
• accès en mémoire: 100 nanosecs
•temps de traitement de défaut de page: 25 millisecs =
25,000,000 nanosecs (inclut le temps de lecture-écriture disque)
• p: probabilité de trouver une page en mémoire (défaut)
(quantité entre 0 et 1)
Temps moyen d’accès mémoire:
p x 100 + (1-p) x 25,000,000 (pas de défaut +
défaut)
En utilisant la même formule, nous pouvons déterminer quel
est le nombre de défauts que nous pouvons tolérer
, si un
certain niveau deperformance est désiré (v. manuel).
P
.ex. avec ces params, si le ralentissement à cause de
pagination nepeut pas excéder 10%, 1 seul défaut de
pagination peut être toléré pour chaque 2,500,000 accès de
aujourd’hui= autour de
10ms)
514.
Quand la RAMest pleine mais nous avons
besoin d`une page pas en RAM
Chap 10 21
Remplacement de pages
Chap10 23
Quoi faire si un processus demande une nouvelle
page et il n’y a pas de cadres libres en RAM?
Il faudra choisir une page déjà en mémoire
principale, appartenant au même ou à un autre
processus, qu’il est possible d ’enlever de la
mémoire principale
la victime!
Un cadre de mémoire sera donc rendu
disponible
Évidemment, plusieurs cadres de mémoire ne
peuvent pas être `victimisés`:
p.ex. cadres contenant le noyau du SE,
tampons d ’E/S...
517.
Bit de modification, dirty
bit
Chap 10 24
La ‘victime’ doit-elle être récrite en
mémoire secondaire?
Seulement si elle a été changée depuis
qu`elle a été amenée en mémoire principale
sinon, sa copie sur disque est encore fidèle
Bit de modif sur chaque descripteur
de page indique si la page a été
changée
Donc pour calculer le coût en temps d’une
référence à la mémoire il faut aussi
considérer la probabilité qu’une page soit
‘sale’ et le temps de récriture dans ce cas
518.
Algorithmes de remplacementpages
Chap 10 25
Choisir la victime de façon à minimiser le
taux de défaut de pages
pas évident!!!
Page dont nous n`aurons pas besoin dans
le futur? impossible à savoir!
Page pas souvent utilisée?
Page qui a été déjà longtemps en
mémoire??
etc. nous verrons...
519.
Critères d’évaluation desalgorithmes
Chap 10 26
Les algorithmes de choix de pages à
remplacer doivent être conçus de façon à
minimiser le taux de défaut de pages à
long terme
Mais ils ne peuvent pas impliquer des
inefficacités
Ni l’utilisation de matériel
dispendieux
520.
Critères d’efficacité
Chap 1027
Il est intolérable d’exécuter un algorithme
complexe chaque fois qu’une opération de
mémoire est exécutée
Ceci impliquerait des accès additionnels
de mémoire
Cependant ceci peut se faire chaque fois
qu’il y a une faute de pagination
Les opérations qui doivent être faites à
chaque accès de mémoire doivent être
câblées dans le matériel
521.
Explication et évaluationdes algorithmes
Chap 10 28
Nous allons expliquer et évaluer les algorithmes
en utilisant la chaîne de référence pages suivante
(prise du livre de Stallings):
2, 3, 2, 1, 5, 2, 4, 5, 3, 2, 5, 2
Attention: les séquences d’utilisation pages ne
sont pas aléatoires...
Localité de référence
Ces références proviendront de plusieurs
processus
L’évaluation sera faite sur la base de cet exemple,
évidemment pas suffisant pour en tirer des
conclusions générales
522.
Algorithmes pour lapolitique de
remplacement
Chap 10 29
L’algorithme optimal (OPT) choisit pour
page à remplacer celle qui sera référencée
le plus tardivement
produit le + petit nombre de défauts de
page
impossible à réaliser (car il faut connaître le
futur) mais sert de norme de comparaison
pour les autres algorithmes:
Ordre chronologique d’utilisation (LRU)
Ordre chronologique de chargement (FIFO)
Deuxième chance ou Horloge (Clock)
523.
Ordre chronologique d’utilisation(LRU)
Remplace la page dont la dernière
référence remonte au temps le plus lointain
(le passé utilisé pour prédire le futur)
En raison de la localité des références, il
s’agit de la page qui a le moins de
chanStcalleings d’être référencée
performance presque aussi bonne
que l’algo. OPT
Chap 10 30
Algorithmes pour la politique de
remplacement
524.
Comparaison OPT-LRU
hap
C Stalling31
Exemple: Un processus de 5 pages s’ìl n`y
a que 3 pages physiques disponibles.
Dans cet exemple, OPT occasionne 3+3
défauts, LRU 3+4.
525.
Note sur lecomptage des défauts de page
Chap 10 32
Lorsque la mémoire principale est vide,
chaque nouvelle page que nous ajoutons
est le résultat d’un défaut de page
Mais pour mieux comparer les algorithmes,
il est utile de garder séparés ces défauts
initiaux
car leur nombre est le même pour tous
les algorithmes
526.
Implémentation problématique deLRU
Chap 10 33
Chaque page peut être marquée (dans le
descripteur dans la table de pages) du temps de la
dernière référence:
besoin de matériel supplémentaire.
La page LRU est celle avec la + petite valeur de
temps (nécessité d’une recherche à chaque défaut
de page)
On pourrait penser à utiliser une liste de pages
dans l’ordre d ’utilisation: perte de temps à
maintenir et consulter cette liste (elle change à
chaque référence de mémoire!)
D’autres algorithmes sont utilisés:
LRU approximations
527.
Premier arrivé, premiersorti (FIFO)
Chap 10 34
Logique: une page qui a été longtemps en
mémoire a eu sa chance d ’exécuter
Lorsque la mémoire est pleine, la plus
vieille page est remplacée. Donc: “first-in,
first-out”
Simple à mettre en application
Mais: Une page fréquemment utilisée est
souvent la plus vielle, elle sera remplacée
par FIFO!
528.
Comparaison de FIFOavec LRU (Stallings)
Contrairement à FIFO, LRU reconnaît que les
pages 2 and 5 sont utilisées fréquemment
Dans ce cas, la performance de FIFO est moins
bonne:
LRU = 3+4, FIFO = 3+6
Chap 10 35
529.
Implantation de FIFO
Chap10 36
Facilement implantable en utilisant un
tampon circulaire de cadres de mémoire
Qui ne doit être mis à jour que à chaque
défaut de page
Exercice: concevoir l’implantation de
ce tampon (v. exemple précédent)
530.
Problème conceptuel avecFIFO
Chap 10 37
Les premières pages amenées en mémoire
sont souvent utiles pendant toute
l’exécution d’un processus!
variables globales, programme principal,
etc.
Ce qui montre un problème avec notre
façon de comparer les méthodes sur la
base d ’une séquence aléatoire:
les références aux pages dans un
programme réel ne seront pas vraiment
aléatoires
531.
L’algorithme de l’horloge(deuxième
chance)
Chap 10 38
Semblable à FIFO, mais il tient compte de l’utilisation
récente de pages
La structure à liste circulaire est celle de FIFO
Mais les cadres qui viennent d’être utilisés (bit=1) ne sont
pas remplacées (deuxième chance)
Les cadres forment conceptuellement un tampon circulaire
Lorsqu’une page est chargée dans un cadre, un pointeur
pointe sur le prochain cadre du tampon
Pour chaque cadre du tampon, un bit “utilisé” est mis à 1 (par
le matériel) lorsque:
une page y est nouvellement chargée
sa page est utilisée
Le prochain cadre du tampon à être remplacé sera le
premier rencontré qui aura son bit “utilisé” = 0.
Durant cette recherche, tout bit “utilisé” = 1 rencontré sera
mis à 0
532.
39
La page 727est chargée dans le cadre 4.
La proch. victime est 5, puis 8.
Chap 10
Algorithme de l’horloge: un exemple (Stallings).
533.
Chap 10 40
Comparaison:Horloge, FIFO et LRU (Stallings)
Astérisque indique que le bit utilisé est 1
L’horloge protège du remplacement les pages
fréquemment utilisées en mettant à 1 le bit “utilisé” à
chaque référence
LRU = 3+4, FIFO = 3+6, Horloge =
534.
Détail sur lefonctionnement de l’horloge
Tous les bits étaient à 1. Nous avons
fait tout le tour et donc nous avons
changé le bit de toutes les pages à 0.
Donc la 1ère page est réutilisée
Chap 10 41
535.
Matériel additionnel pourl’algo CLOCK
Chap 10 42
Chaque bloc de mémoire a
un bit ‘touché’ (use)
Quand le contenu du bloc
est utilisé, le bit est mis à 1
par le matériel
Le SE regarde le bit
S’il est 0, la page peut
être remplacée
S’il est 1, il le met à 0
1
0
0
0
1
Mémoir
e
536.
Résumé des algorithmesle plus importants
Chap 10 43
OPTIMAL Le meilleur en principe mais pas
implantable, utilisé comme référence
LRU Excellent en principe, mais demande du
matériel dispendieux
FIFO Facile à implanter, mais peut écarter
des pages très utilisées
Horloge Modification de FIFO vers LRU:
évite d’écarter des pages récemment
utilisées
Les algorithmes utilisés en pratique sont des
variations et combinaisons de ces concepts
537.
Algorithmes compteurs
Chap 1044
Garder un compteur pour les références à chaque
page
LFU: Least Frequently Used: remplacer la pages
avec le plus petit compteur
MFU: Most Frequently Used: remplacer les pages
bien usées pour donner une chance aux nouvelles
Ces algorithmes sont d’implantation dispendieuse
et ne sont pas beaucoup utilisés
Mise à jour de compteurs à chaque opération
de mémoire!
538.
Utilisation d’une pile(stack)
Chap 10 45
Quand une page est utilisée, est mise au
sommet de la pile.
donc la page la plus récemment utilisée
est toujours au sommet,
la moins récemment utilisée est toujours
au fond
Bonne implémentation du principe de
localité, cependant…
La pile doit être mise à jour chaque fois
qu’une page est utilisée
Inefficace, pas pratique
539.
Anomalie de Belady
Chap10 46
Pour quelques algorithmes, dans quelques
cas il pourrait avoir plus de défauts avec
plus de mémoire!
p. ex. FIFO, mais pas LRU, OPT, CLOCK
Chap 10-2 2
Allocationde cadres RAM
Pour exécuter, un processus a besoin d’un nombre minimal
de cadres de mémoire RAM
par exemple, quelques instructions pourraient avoir
besoin de plusieurs pages simultanément pour exécuter!
Il est aussi facile de voir que un proc qui reçoit très peu
de mémoire subira un nombre excessif de défauts de
pagination, donc il sera excessivement ralenti
Comment s`assurer qu’un proc soit alloué son minimum
allocation égale: chaque processus a droit a une
portion égale de la mémoire physique
allocation proportionnelle: chaque processus a droit à
une portion proportionnelle à sa taille
le critère devrait plutôt être le besoin de pages: v.
working set
http://w3.uqo.ca/lui
545.
Allocation globale oulocale
Chap 10-2 3
globale: la `victime`est prise de n`importe
quel processus
locale: la `victime`est prise du processus
qui a besoin de la page
546.
Écroulement ou thrashing(liter.: défaite)
S ’il n`y a pas assez de mémoire pour
exécuter un proc sans trop de défauts de
pagination, le proc finira pour passer trop
de temps dans les files d`attente
Si cette situation se généralise à plusieurs
procs, l ’UCT se trouvera à être sous-
utilisée
Le SE pourra chercher de remédier à cette
situation en augmentant le niveau de
multiprogrammation
plus de procs en mémoire!
moins de mém par proc!
plus de défauts de pagination!
Désastre: écroulement
le système devient entièrement
occupé à faire des E/S de pages, il
ne réussit plus à faire de travail
utile
Chap 10-2 4
547.
La raison del`écroulement
Chaque processus a
besoin d ’un certain
nombre de pages pour
exécuter efficacement
Le nombre de pages
dont l’ensemble de
processus a besoin à
l’instant excède le
nombre de cadres de
mémoire RAM
disponible
défaite du concept
de mémoire
virtuelle
Chap 10-2 5
548.
Ensemble de travail(working set)
Chap 10-2 6
L’ensemble de travail d’un proc donné à un
moment d’exécution donné est l’ensemble
des pages dont le proc a besoin pour
exécuter sans trop de défauts de
pagination
Malheureusement, un concept flou
549.
Chercher à prévoirles demandes de pages
sur la base des demandes passées
t1
WS(t1) = {1, 2, 5, 6, 7}
WS(t2) = {3, 4}
t2
… 2 6 1 5 7 7 7 7 5 1 6 2 3 4 1 2 3 4 4 4 3 4 3 4 4 4 1 3 2 3 4 4 4 3 4 4 4
…
Fixer un intervalle
Les pages intéressées par les dernières
operations de mémoire sont dans
l ’ensemble de travail déterminé par
Comment choisir un approprié?
Chaîne
Figure 10.16
Chap 10-2 7
Working-set model.
=10
opér
de réf.
= 4 donnerait le même résultat pour
t2!
550.
Modèle de l’ensemblede
travail
Chap 10-2 8
une fenêtre d’ensemble de travail
= un nombre fixe de réf. de pages
p.ex. 10.000 opérations de mémoire
SI trop petit, il contiendra pas tout l ’ensemble de pages
couramment utilisé par un proc
Si trop grand, il contiendra plusieurs ensembles de
pages
WSSi (ensemble de travail du proc. i)
D = ∑ WSSi nombre total de cadres demandés par tous les
procs en exéc
Si D > mémoire Risque d’écroulement
S’assurer que ceci ne se vérifie pas
si nécessaire, suspendre un des processus
Problème: choisir un bon
peut être fait par le gérant du système
551.
Implémentation du conceptde WS: difficile!
Chap 10-2 9
Minuterie et bits référence
Bit de référence qui est mis à 1 chaque fois
que une page est utilisée
Minuterie qui interrompt régulièrement
pour voir les pages qui ont été utilisées
dans un intervalle de temps
552.
Le concept deWS en pratique
Chap 10-2 10
Deux types de difficultés:
fixer le de façon différente pour chaque
processus, pour représenter ses besoins
Du matériel spécial est nécessaire pour suivre le
WS d ’un proc à un moment donné
553.
Pour chaque processus,il existe une
dimension de mémoire acceptable
Chap 10-2 11
ceci suggère une approche plus
pratique
554.
Une méthode plusfacile à implanter que WS
Chap 10-2 12
Le gérant du système détermine quelles sont les
nombres de défauts de pagination maximales et
minimales tolérables dans le système, et pour
chaque travail, selon ses caractéristiques
Si un travail en produit plus que sa juste
partie, lui donner plus de mémoire
Si un travail en produit moins, lui donner moins
de mémoire
Suspendre si possible des travaux qu`on ne peut
pas satisfaire
Ou amorcer d’autres travaux si les ressources
sont disponibles
555.
Optimisations
Chap 10-2 13
Ungrand nombre de techniques
d’optimisation ont été proposées et
implantées
Le manuel en discute plusieurs:
Prépagination, post-nettoyage
Stockage efficace
Taille optimale des pages
556.
Prépagination, post-nettoyage
Chap 10-214
Prépagination
noter quelles pages paraissent être reliées les unes
aux autres
quand une de ces pages est amenée en mémoire
RAM, y amener les autres en même temps
ne pas amener une seule page, s’il n`y a pas assez d
’espace pour les autres
éventuellement, stocker toutes ces pages dans des
secteurs contigus de disque, de façon qu ’elles puissent
être lues rapidement en séquence
Post-nettoyage (post-purging)
enlever ensemble tout un groupe de pages reliées
(même localité)
Tailles de pages(un pb de conception matériel)
Chap 10-2 16
Grande variété de tailles de pages aujourd’hui
en pratique: de 512B à 16MB
Avantages des petites pages:
moins de fragmentation interne
moins d’information inutile en mémoire
Avantages des grandes pages:
tableaux de pages plus petits
le temps de disque le plus important est le temps de
positionnement
une fois le disque positionné, il vaut la peine de lire une grande
page
Tendance aujourd’hui vers grandes pages car nous avons des
grands RAMs
4-8KB
559.
Pages grandes ou
petites
Avecune petite taille
grand nombre de pages en
mém. centrale
chaque page contient
uniquement du code utilisé
peu de défauts de page une
fois que toutes les pages
utiles sont chargées
En augmentant la taille
moins de pages peuvent
être gardées dans RAM
chaque page contient plus de
code qui n’est pas utilisé
plus de défauts de page
Mais ils diminuent lorsque nous
approchons le point P où la taille
d’une page est celle d’un programme
entier
Stallings
Chap 10-2 17
560.
Différentes tailles de
pages
Chap10-2 18
Certains processeurs supportent plusieurs tailles.
Ex:
Pentium supporte 2 tailles: 4KB ou 4MB
R4000 supporte 7 tailles: 4KB à 16MB
dimensions différentes peuvent être en
utilisation par des travaux différents, selon
leur caractéristiques de localité
Travaux qui utilisent des grosses boucles et
grosses structures de données pourront utiliser
bien les grosses pages
Des gros travaux qui ‘sautent’ un peu partout
sont dans la situation contraire
L’UCT (ou MMU) contient un registre qui dit la
taille de page couramment utilisée
561.
Effets de l’organisationdu programme sur
l’efficacité de la pagination
Chap 10-2 19
En principe, la pagination est censée être invisible
au programmeur
Mais le programmeur peut en voir les
conséquences en termes de dégradation de
performance
p.ex. quand il change d ’un contexte à l’autre
Le programmeur peut chercher à éviter la
dégradation en cherchant d ’augmenter la localité
des références dans son programme
En réalité, ce travail est fait normalement par le
compilateur
562.
Effets de l’organisationdu programme sur
l’efficacité de la pagination
Chap 10-2 20
Structure de programme
Array A[1024, 1024]
chaque ligne est stockée dans une page
différente,
un cadre différent
Programme 1: balayage par
colonnes: for j = 1 to 1024 do
for i = 1 to 1024 do
A[i,j] = 0;
1024 x 1024 défauts de pagination
Programme 2: balayage par
lignes: for i = 1 to 1024 do
for j = 1 to 1024 do
A[i,j] = 0;
1024 défauts de pagination
563.
Taille de pageset localité processus
Chap 10-2 21
Dans le cas de programmes qui exécutent
du code qui ’saute’ beaucoup, les petites
pages sont préférables (code OO est dans
cette catégorie)
564.
Verrouillage de pagesen mémoire
Chap 10-2 22
Certaines pages doivent être verrouillées
en mémoire, p.ex. celles qui contiennent le
noyau du SE
Il est aussi essentiel de verrouiller en
mémoire des pages sur lesquelles il y a
exécution d ’E/S
Ceci peut être obtenu avec un bit `verrou`
sur le cadre de mémoire
ce bit veut dire que ce cadre ne peut pas
être sélectionné comme `victime`
565.
Systèmes en tempsréel
Chap 10-2 23
Avec la mémoire virtuelle, les temps
d’exécution d’un processus deviennent
moins prévisibles
retards inattendus à cause de la
pagination
Donc les systèmes en temps réel
`durs` utilisent rarement la mémoire
virtuelle
566.
Combinaison de techniques
Chap10-2 24
Les SE réels utilisent les techniques que nous avons
étudiées en combinaison, e.g.
Linux utilise le buddy system en combinaison avec la
pagination (la plus petite portion de mémoire
allouable est une page)
d`autres systèmes utilisent les partitions fixes
avec la pagination, ce qui peut être fait de
plusieurs façons:
diviser la mémoire réelle en partitions fixes, assigner chaque
partition à un ou plusieurs processus, puis paginer un
processus dans la partitions qui lui a été assignée
diviser la mémoire virtuelle en partitions, assigner
chaque partition à un ou plus. processus, puis utiliser
la technique appropriée pour chaque processus dans
sa partition
Les SE réels sont complexes et variés, mais les principes
étudiés dans ce cours en constituent la base.
567.
Conclusions 1
Chap 10-225
Il est fortement désirable que l`espace
d ’adressage de l ’usager puisse être beaucoup
plus grand que l ’espace d ’adressage de la
mémoire RAM
Le programmeur sera donc libéré de la
préoccupation de gérer son occupation de
mémoire
cependant, il devra chercher à maximiser la localité
de son processus
La mémoire virtuelle aussi permet à plus de
processus d ’être en exécution
UCT, E/S plus occupées
568.
Conclusions 2
Chap 10-226
Le problème de décider la page victime
n’est pas facile.
Les meilleurs algorithmes sont impossibles
ou difficiles à implanter
Cependant en pratique l ’algorithme FIFO
est acceptable
569.
Conclusions 3
Chap 10-227
Il faut s’assurer que chaque processus ait assez
de pages en mémoire physique pour exécuter
efficacement
risque d ’écroulement
Le modèle de l’ensemble de travail exprime bien
les exigences, cependant il est difficile à implanter
Solution plus pragmatique, où on décide de
donner + ou - de mémoire aux processus selon
leur débit de défauts de pagination
À fin que ces mécanismes de gestion mémoire
soient efficaces, plusieurs types de mécanismes
sont désirables dans le matériel
570.
Dans un systèmeréel
Chap 10-2 28
Une lecture disque sur un PC prend approx
10ms
Donc la limite est autour de 100 fautes
de pagination par seconde
Dans un serveur avec mémoire secondaire
éléctronique (p.ex. flash memory)
le taux de pagination peut arriver à
milliers de pages par seconde
http://bsd7.starkhome.cs.sunysb.edu/~samson
571.
Concepts importants duChap. 10
Chap 10-2 29
Localité des références
Mémoire virtuelle implémentée par va-et-vient des pages,
mécanismes, défauts de pages
Adresses physiques et adresses logiques
Temps moyen d’accès à la mémoire
Récriture ou non de pages sur mém secondaire
Algorithmes de remplacement pages:
OPT, LRU, FIFO, Horloge
Fonctionnement, comparaison
Écroulement, causes
Ensemble de travail (working set)
Relation entre la mémoire allouée à un proc et le nombre
d’interruptions
Relation entre la dimension de pages et le nombre
d’interruptions
Prépagination, post-nettoyage
Effets de l’organisation d’un programme sur l’efficacité de la
pagination
572.
Par rapport aumanuel…
Chap 10-2 30
Section 10.6: intéressante, mais pas sujet
d’examen
Concepts importants duchapitre
Chap 11 2
Systèmes fichiers
Méthodes d’accès
Structures Répertoires
Protection
Structures de systèmes fichiers
Méthodes d’allocation
Gestion de l’espace libre
Implémentation de répertoires
Questions d’efficacité
575.
Que c’est qu’unfichier
Chap 11 3
Collection nommée d’informations
apparentées, enregistrée sur un stockage
secondaire
Nature permanente
Les données qui se trouvent sur un
stockage secondaires doivent être dans un
fichier
Différents types:
Données (binaire, numérique, caractères….)
Programmes
Chap 11 5
Attributsd’un
fichier
Constituent les propriétés du fichiers et sont stockés dans
un fichier spécial appelé répertoire (directory). Exemples
d’attributs:
Nom:
pour permet aux personnes d’accéder au fichier
Identificateur:
Un nombre permettant au SE d’identifier le fichier
Type:
Ex: binaire, ou texte; lorsque le SE supporte cela
Position:
Indique le disque et l’adresse du fichier sur disque
Taille:
En bytes ou en blocs
Protection:
Détermine qui peut écrire, lire, exécuter…
Date:
pour la dernière modification, ou dernière utilisation
Autres…
578.
Opérations sur lesfichiers: de base
Chap 11 6
Création
Écriture
Pointeur d’écriture qui donne la position
d’écriture
Lecture
Pointeur de lecture
Positionnement dans un fichier (temps de
recherche)
Suppression d’un fichier
Libération d’espace
Troncature: remise de la taille à zéro tout en
conservant les attributs
579.
Autres opérations
Chap 117
Ajout d’infos (p.ex. concaténation)
Rénommage
Copie
peut être faite par rénommage: deux noms pour un
seul fichier
Ouverture d’un fichier: le fichier devient associé à
un processus qui en garde les attributs, position,
etc.
Fermeture
Ouverture et fermeture peuvent être explicites
(ops open, close)
ou implicites
580.
Informations reliées àun fichier ouvert
Chap 11 8
Pointeurs de fichier
Pour accès séquentiel
P.ex. pour read, write
Compteur d’ouvertures
Emplacement
581.
Types de fichiers
Chap11 9
Certains SE utilisent l’extension du nom du fichier
pour identifier le type.
Microsoft: Un fichier exécutable doit avoir
l’extension
.EXE, .COM, ou .BAT (sinon, le SE
refusera de l’exécuter)
Le type n’est pas défini pour certains SE
Unix: l’extension est utilisée (et reconnue)
seulement par les applications
Pour certains SE le type est un attribut
MAC-OS: le fichier a un attribut qui contient le nom
du programme qui l’a généré (ex: document Word
Perfect)
Chap 11 11
Structurelogique des
fichiers
Le type d’un fichier spécifie sa structure
Le SE peut alors supporter les différentes
structures correspondant aux types de fichiers
Cela complexifie le SE mais simplifie les
applications
Généralement, un fichier est un ensemble
d’enregistrements (records)
Chaque enregistrement est constitué d’un ensemble
de champs (fields)
Un champ peut être numérique ou chaîne de chars.
Les enregistrements sont de longueur fixe ou
variable (tout dépendant du type du fichier)
Mais pour Unix, MS-DOS et autres, un fichier est
simplement une suite d’octets « byte stream »
Donc ici, 1 enregistrement = 1 octet
C’est l’application qui interprète le contenu et
spécifie une structure
Méthodes d’accès: 4de base
Chap 11 13
Séquentiel (rubans ou disques): lecture ou
écriture des enregistrements dans un ordre fixe
Indexé séquentiel (disques): accès séquentiel ou
accès direct (aléatoire) par l’utilisation d’index
Indexée: multiplicité d’index selon les besoins,
accès direct par l’index
Direct ou hachée: accès direct à travers tableau
d’hachage
Pas tous les SE supportent les méthodes
d’accès
Quand le SE ne les supporte pas, c’est aux
librairies d’usager de les supporter
586.
Méthodes d’accès auxfichiers
Chap 11 14
La structure logique d’un fichier détermine sa méthode
d’accès
Les SE sur les « mainframe » fournissent généralement
plusieurs méthodes d’accès
Car ils supportent plusieurs types de fichiers
Plusieurs SE modernes (Unix, Linux, MS-DOS…) fournissent
une seule méthode d’accès (séquentielle) car les fichiers
sont tous du même type (ex: séquence d’octets)
Mais leur méthode d’allocation de fichiers (voir + loin)
permet habituellement aux applications d’accéder aux
fichiers de différentes manières
Ex: les systèmes de gestions de bases de données
(DBMS) requièrent des méthodes d’accès plus efficaces
que juste séquentielle
Un DBMS sur un « mainframe » peut utiliser une
structure fournie par le SE pour accès efficace aux
enregistrements.
Un DBMS sur un SE qui ne fournit qu’un accès séquentiel
doit donc « ajouter » une structure aux fichiers de bases
de données pour accès directs plus rapides.
587.
Chap 11 15
Fichiersà accès séquentiel (archétype: rubans)
bloc bloc
. . . . . .
La seule façon de retourner en
arrière est de retourner au début
(rébobiner, rewind)
En avant seulement, 1 seul enreg.
à la fois
. . .
enregistrements
588.
Lecture physique etlecture logique dans un
fichier séquentiel
Chap 11 16
Un fichier séquentiel consiste en blocs d’octets enregistrés sur un
support tel que ruban, disque…
La dimension de ces blocs est dictée par les caractéristiques du
support
Ces blocs sont lus (lecture physique) dans un tampon en
mémoire
Un bloc contient un certain nombre d’enregistrements (records) qui
sont des unités d’information logiques pour l’application (un
étudiant, un client, un produit…)
Souvent de longueur et contenu uniformes
Triés par une clé, normalement un code (code d’étudiant,
numéro produit…)
Une lecture dans un programme lit le prochain enregistrement
Cette lecture peut être réalisée par
La simple mise à jour d’un pointeur si la lecture logique
précédente ne s’était pas rendue à la fin du tampon
la lecture du proch. bloc (dans un tampon d’E/S en
mémoire) si la lecture logique précédente s’était rendue à la
fin du tampon
Dans ce cas le pointeur est remis à 0
589.
Autres propriétés desfichiers séquentiels
Chap 11 17
Pour l’écriture, la même idée: une instruction
d’écriture dans un programme cause l’ajout d’un
enregistrement à un tampon, quand le tampon est
plein il y a une écriture de bloc
Un fichier séquentiel qui a été ouvert en lecture ne
peut pas être écrit et vice-versa (impossible de
mélanger lectures et écritures)
Les fichiers séquentiels ne peuvent être lus ou
écrits qu’un enregistrement à la fois et seulement
dans la direction ‘en avant’
590.
Mise à jourde fichiers séquentiels
Vieux
maître
Fichie
r mise
à
jour
Nouvea
u
maître
Programme de
mise à
jour
Tous les
fichiers sont
triés par la
même clé
Chap 11 18
591.
Mise à jourde fichiers séquentiels
triés:
exempl
e
02
05
12
17
21
26
02
12
17
20
21
26
27
Retirer 5
Modif 12
Ajout 20
Ajout 27
Vieux maître Mises à jour Nouveau maître
+ =
(12 a été modifié)
L’algorithme fonctionne lisant un enregistrement à la fois, en séquence, du vieux
maître et du fichier des mises à jour
À un moment donné il n’y a que trois enregistrements en mémoire, un par
fichier
Programme de
mise à
jour
Vieux
maître
Fichier
mise
à
jour
Nouvea
u
maître
Programme de mise
à jour
Chap 11 19
592.
Accès direct ouhaché ou
aléatoire:
Chap 11 20
accès direct à travers tableau
d’hachage
Une fonction d’hachage est une fonction qui
traduit une clé dans adresse,
P.ex. Matricule étudiant adresse disque
Rapide mais:
Si les adresses générées sont trop
éparpillées, gaspillage d’espace
Si les adresses ne sont pas assez éparpillées,
risque que deux clés soient renvoyées à la même
adresse
Dans ce cas, il faut de quelques façon renvoyer une
des clés à une autre adresse
593.
Problème avec lesfonctions
d’hachage
Fonction d’hachage
dispersée qui n’utilise pas
bien l’espace disponible
Chap 11 21
Fonction d’hachage concentrée qui
utilise mieux l’espace mais introduit
des doubles affectations
clés
adr. disque
clés
adr. disque
594.
Hachage:Traitement des doublesaffectations
On doit détecter les doubles affectations,
et s’il y en a, un des deux enregistrements
doit être mis ailleurs
ce qui complique l’algorithme
adr. disque
clés
adr. alternative disque
Chap 11 22
595.
Adressage Indexé séquentiel(index sequential)
Chap 11 23
Un index permet d’arriver directement à
l’enregistrement désiré, ou en sa proximité
Chaque enregistrement contient un champ
clé
Un fichier index contient des repères (pointeurs) à
certain points importants dans le fichier principal
(p.ex. début de la lettre S, début des Lalande, début des
matricules qui commencent par 8)
Le fichier index pourra être organisé en niveaux
(p.ex. dans l’index de S on trouve l’index de tous
ceux qui commencent par S)
Le fichier index permet d’arriver au point de repère
dans le fichier principal, puis la recherche est
séquentielle
596.
Exemples d’index etfichiers relatifs
Pointe au début des Smiths (il y en aura plusieurs)
Le fichier index est à accès direct, le fichier relatif est à accès
séquentiel
Accès direct: voir ci-
Chap 11 24
597.
Index et fichierprincipal (Stallings)
(Relative file)
Chap 11 25
Dans cette figure, l’index est
étendu à plusieurs niveaux,
donc il y a un fichier index qui
renvoie à un autre fichier
index, n niveaux
598.
Pourquoi plusieurs niveauxd’index
Chap 11 26
Un premier niveau d’index pourrait
conduire au début de la lettre S
Un deuxième niveau au début des Smith,
etc.
Donc dans le cas de fichiers volumineux
plusieurs niveaux pourraient être justifiés.
599.
Séquentiel et indexséquentiel: comparaison
Chap 11 27
P.ex. Un fichier contient 1 million
d’enregistrements
En moyenne, 500.000 accès sont nécessaires pour
trouver un enregistrement si l’accès est
séquentiel!
Mais dans un séquentiel indexé, s’il y a un seul
niveau d’indices avec 1000 entrées (et chaque entrée
pointe donc à 1000 autres),
En moyenne, ça prend 1 accès pour trouver le
repère approprié dans le fichier index
Puis 500 accès pour trouver séquentiellement le
bon enregistrement dans le fichier relatif
600.
Mais… besoin defichier débordement
Chap 11 28
Les nouveaux enregistrements
seront ajoutés à un fichier
débordement
Les enregistrements du fichier
principal qui le précèdent dans
l’ordre de tri seront mis à jour
pour contenir un pointeur au
nouveau enregistrement
Donc accès additionnels au fichiers
débordement
Périodiquement, le fichier
principal sera fusionné avec le
fichier débordement
Fichier indexé
Chap 1130
Utilise des index multiples pour différentes
clés, selon les différents besoins de
consultation
Quelques uns pourraient être exhaustifs,
quelques uns partiels, et organisés de
façons différentes
Utilisation des 4
méthodes
Chap11 32
Séquentiel (rubans ou disques): applications périodiques qui
demandent la lecture ou écriture des enregistrements dans un
ordre fixe, ces applications sont appelées ‘batch’=‘par lots’
Salaires, comptabilité périodique, sauvegarde périodique
(backups)
Indexé séquentiel (disques): accès séquentiel ou accès direct par
l’utilisation d’index
Pour fichiers qui doivent être consultés parfois de façon séquentielle,
parfois de façon directe (p.ex. par nom d’étudiant)
Indexée: multiplicité d’index selon les besoins, accès direct par
l’index
Pour fichiers qui doivent être consultés de façon directe selon des
critères différents (p.ex. pouvoir accéder aux infos concernant les
étudiants par la côte du cours auquel ils sont inscrits)
Direct ou hachée: accès direct à travers tableau d’hachage
Pour fichiers qui doivent être consultés de façon directe par une clé
uniforme (p.ex. accès aux information des étudiants par matricule)
importa
nt
Structures de répertoires(directories)
F 1
Chap 11 34
F 2
F 3
F 4
Une collection de structures de données contenant
infos sur les fichiers.
Répertoires
F n
Tant les répertoires, que les fichiers, sont sur
disques
À l’exception d’un rép. racine en mém.
centrale
Fichiers
607.
Organisation typique desystème de fichiers
Deux répertoires dans un seul disque
Un répertoire dans deux
disques
Chap 11 35
608.
Information dans unrépertoire
Chap 11 36
Nom du fichier
Type
Adresse sur disque, sur ruban...
Longueur courante
Longueur maximale
Date de dernier accès
Date de dernière mise à jour
Propriétaire
Protection
etc
609.
Opérations sur répertoires
Chap11 37
Recherche de fichier
Création de fichier
Suppression de fichier
Lister un répertoire
Renommer un fichier
Traverser un système de fichier
610.
Organisation de répertoires
Chap11 38
Efficacité: arriver rapidement à un
enregistrement
Structure de noms: convenable pour
usager
deux usagers peuvent avoir le même
noms pour fichiers différents
Le même fichier peut avoir différents
noms
Groupement de fichiers par type:
tous les programmes Java
tous les programmes objet
611.
Structure à unniveau
Un seul rép. pour tous les usagers
Ambiguïté de noms
Pas de groupement
Primitif, pas pratique
Chap 11 39
612.
Répertoires à deuxniveaux
Rép. séparé pour chaque usager
`path name`, nom de chemin
même nom de fichier pour usagers différents est
permis
recherche efficace
Pas de groupements
Chap 11 40
Caractéristiques des répertoiresà arbres
Chap 11 42
Recherche efficace
Possibilité de grouper
Repertoire courant (working directory)
cd /spell/mail/prog
615.
Graphes sans cycles:permettent de partager
fichiers
Unix: un symbolic link donne un chemin à un fichier
ou sous- répertoire
Chap 11 43
616.
Références multiples dansgraphes
acycliques
Un nœud peut avoir deux noms
différents
Si dict supprime list donc
pointeur vers fichier inexistant
(dangling pointer). Solutions:
Pointeurs en arrière,
effacent tous les pointeurs
Compteurs de références (s’il
y a encore des refs au fichier,
il ne sera pas effacé)
Ni Unix ni Microsoft
n’implémentent ces
politiques, donc messages
d’erreur
Solutions impossibles à
gérer dans un système
fortement reparti (ex: www)
Chap 11 44
617.
Graphes avec cycles(structure générale)
Chap 11 45
•Presque inévitables quand il est permis de pointer à un noeud
arbitraire de la structure
•Pourraient être détectés avec des contrôles appropriés au moment de
la création d ’un nouveau pointeur
•Contrôles qui ne sont pas faits dans les SE courants
618.
Considérations dans lecas de cycles
En traversant le graphe, il est nécessaire de savoir si on
retombe sur un noeud déjà visité
Un noeud peut avoir compteur de ref != 0 en se trouvant
dans une boucle de noeuds qui n ’est pas accessible!
Des algorithmes existent pour permettre de traiter ces cas,
cependant ils sont compliqués et ont des temps d ’exécution
non négligeables, ce qui fait qu’ ils ne sont pas toujours
employés
Ramasse-miettes = garbage collection
roo
t Un sous-arbre qui n’est pas
accessible à partir de la racine
mais il ne peut pas être effacé
en utilisant le critère ref=0 car il
fait ref à lui-meme!
Chap 11 46
Protection (détails dansun chap suivant)
Chap 11 48
Types d ’accès permis
lecture
écriture
exécution
append (annexation)
effacement
listage: lister les noms et les attributs d
’un fichier
Par qui
621.
Listes et groupesd’accès - UNIX
Chap 11 49
Modes d ’accès: R W E
Trois classes d ’usager:
propriétaire
groupe
public
demander à l ’administrateur de créer un
nouveau groupe avec un certain usager et
un certain propriétaire
droit du propriétaire de régler les droits
d ’accès et d ’ajouter des nouveaux
usagers
622.
Listes et groupes
d’accès
Mode d’accès: read, write, execute
Trois catégories d’usagers:
RWX
a) owner access 7 1 1 1
b) group access 6
RWX
1 1 0
c) others access 1
RWX
0 0 1
Demander au gestionnaire de créer un groupe, disons G, et
ajouter des usagers au groupe
Pour un fichier particulier, disons jeux, définir un accès
approprié
owner group
public
chmod 761
jeux
Changer le groupe d’un fichier
chgrp
G
Chap 11 50
jeux
Structures de systèmesde fichiers
Chap 11 52
Structure de fichiers: deux façons de voir un fichier:
unité d’allocation espace
collection d ’informations reliées
Le système de fichiers réside dans la
mémoire secondaire: disques, rubans...
File control block: structure de données
contenant de l ’info sur un fichier
Structure physique desfichiers
Chap 11 54
La mémoire secondaire est subdivisée en blocs et chaque
opération d’E /S s’effectue en unités de blocs
Les blocs ruban sont de longueur variable, mais les
blocs disque sont de longueur fixe
Sur disque, un bloc est constitué d’un multiple de
secteurs contigus (ex: 1, 2, ou 4)
la taille d’un secteur est habituellement 512 bytes
Il faut donc insérer les enregistrements dans les blocs et
les extraire par la suite
Simple lorsque chaque octet est un enregistrement
par lui- même
Plus complexe lorsque les enregistrements possèdent
une structure (ex: « main-frame IBM » )
Les fichiers sont alloués en unité de blocs. Le dernier bloc
est donc rarement rempli de données
Fragmentation interne
627.
Trois méthodes d’allocationde fichiers
Chap 11 55
Allocation contiguë
Allocation
enchaînée
Allocation indexée
Allocation contiguë
Chaque fichieroccupe
un ensemble de blocs
contigu sur disque
Simple: nous n’avons
besoin que d’adresses
de début et longueur
Supporte tant l’accès
séquentiel, que l’accès
direct
Moins pratique pour
les autres méthodes
Chap 11 57
630.
Allocation contiguë
Application des
problèmeset
méthodes vus dans le
chapitre de l’alloc de
mémoire contiguë
Les fichiers ne
peuvent pas grandir
Impossible d’ajouter
au milieu
Exécution périodique
d’une compression
(compaction) pour
récupérer l’espace
libre
Chap 11 58
631.
Allocation enchaînée
Le répertoirecontient
l ’adresse du premier
et dernier bloc,
possibl. le nombre de
blocs
Chaque bloc contient
un pointeur à l’adresse
du prochain bloc:
pointeur
bloc =
Chap 11 59
Avantages - désavantages
Chap11 62
Pas de fragmentation externe - allocation
de mémoire simple, pas besoin de
compression
L’accès à l ’intérieur d ’un fichier ne peut
être que séquentiel
Pas façon de trouver directement le
4ème enregistrement...
N’utilise pas la localité car les
enregistrements seront éparpillés
L’intégrité des pointeurs est essentielle
Les pointeurs gaspillent un peu d ’espace
635.
Allocation indexée: semblableà la pagination
Tous les pointeurs sont regroupés dans un
tableau (index block)
index
table
Chap 11 63
Allocation indexée
Chap 1165
À la création d ’un fichier, tous les
pointeurs dans le tableau sont nil (-1)
Chaque fois qu’un nouveau bloc doit
être alloué, on trouve de l ’espace
disponible et on ajoute un pointeur avec
son adresse
638.
Allocation indexée
Chap 1166
Pas de fragmentation externe, mais les
index prennent de l’espace
Permet accès direct (aléatoire)
Taille de fichiers limitée par la taille de
l’index block
Mais nous pouvons avoir plusieurs
niveaux d’index: Unix
Index block peut utiliser beaucoup de
mémoire
639.
Chap 11
1024
x
1024
bloc
s de
UNIXBSD: indexé à niveaux (config. possible)
12 blocs disque de 4K
chaque
1024 blocs de
4K chaque
Bloc de 4K contient 1024
Ce répertoire est en mémoire,
tous les autres sont sur disque
640.
UNIX BSD (v.manuel Section 20.7)
Les premiers blocs d’un fichier sont accessibles directement
Si le fichier contient des blocs additionnels, les premiers sont
accessibles à travers un niveau d’indices
Les suivants sont accessibles à travers 2 niveaux d’indices,
etc.
Donc le plus loin du début un enregistrement se trouve, le plus
indirect est son accès
Permet accès rapide à petits fichiers, et au début de tous les
fich.
Permet l’accès à des grands fichier avec un petit répertoire en
mémoire
Chap 11 68
Gestion d’espace
libre
Solution 1:vecteur de bits (solution
Macintosh, Windows 2000)
Vecteur de bits (n blocs)
0 1 2
n-1
…
bit[i]
=
Chap 11 70
1 block[i] libre
2 block[i]
occupé
Exemple d’un vecteur de bits où les blocs 3,
4, 5, 9, 10, 15, 16 sont occupés:
00011100011000011…
L’adresse du premier bloc libre peut être
trouvée par un simple calcul
643.
Gestion d’espace
libre
Solution 2:Liste liée de mémoire libre (MS-DOS, Windows
9x) Tous les blocs de mémoire libre sont
liés ensemble par des pointeurs
Chap 11 71
644.
Comparaison
Chap 11 72
Bitmap:
si la bitmap de toute la mémoire secondaire est
gardée en mémoire principale, la méthode est
rapide mais demande de l’espace de mémoire
principale
si les bitmaps sont gardées en mémoire
secondaire, temps de lecture de mémoire
secondaire...
Elles pourraient être paginées, p.ex.
Liste liée
Pour trouver plusieurs blocs de mémoire libre,
plus. accès de disque pourraient être demandés
Pour augmenter l’efficacité, nous pouvons garder
en mémoire centrale l ’adresse du 1er bloc libre
Implantation de répertoires(directories)
Chap 11 74
Liste linéaire de noms de fichiers avec
pointeurs aux blocs de données
accès séquentiel
simple à programmer
temps nécessaire pour parcourir la
liste
Tableaux de hachage: tableaux
calculés
temps de recherche rapide
mais problèmes de collisions
647.
Efficacité et performance
Chap11 75
L ’efficacité dépend de:
méthode d’allocation et
d’organisation répertoires
Pour augmenter la performance:
Rendre efficace l’accès aux blocs
souvent visités
Dédier des tampons de mémoire qui
contiennent l’image des infos plus
souvent utilisées
Optimiser l’accès séquentiel s’il est
souvent utilisé: free behind and read
ahead
648.
Disque RAM
fonctionne commemémoire cache pour
le disque
Image (partielle?) du contenu du disque en mémoire
RAM
Le pilote de disque RAM accepte toutes les ops qui sont
acceptées par le disque
Chap 11 76
649.
Le problème dela récupération, ou
cohérence
Chap 11 77
Parties des fichiers et des répertoires se
trouvent tant en mémoire principale, que
sur disque
Il faut donc des mécanisme qui assurent
leur cohérence, surtout après pannes dans
le système
650.
Récupération: différentes méthodes
Chap11 78
Contrôles de cohérence entre la structure
de répertoires en mémoire centrale et le
contenu des disques
Essaye de réparer les incohérences
Sauvegarder les données sur disque dans
autres supports auxiliaires (backups) (p.ex.
autres disques, rubans)
Restaurer les disques à partir de
ces supports quand nécessaire
651.
Concepts importants duChapitre 11
Chap 11 79
Fichiers: structures, attributs, opérations
Méthodes d’accès: séquentiel, séquentiel indexée,
indexée, direct ou hachée
Répertoires et leur structures: repertoires
arborescents, sans ou avec cycles
Partage de fichiers, protection, liste
d’accès
Allocation d’espace: contiguë,
enchaînée, indexée
Application en UNIX
Gestion d’espace libre: bitmap, liste liée
652.
Par rapport aumanuel…
Chap 11 80
Nous n’avons pas discuté:
Section 11.1.6
Section 11.5.2
Section 11.6.4
653.
Chapitre 12
Chap 121
Systèmes
d’entrée/sortie
http://w3.uqo.ca/lui
gi/
654.
Concepts importants duchapitre
Chap 12 2
• Matériel E/S
• Communication entre UCT et contrôleurs
périphériques
• Interruptions et scrutation
• DMA
• Pilotes et contrôleurs de périphs
• E/S bloquantes ou non, synchrones ou asynch
• Sous-système du noyau pour E/S
– Tamponnage, cache, spoule
Communication entre UCTet
contrôleurs périphériques
• Différentes techniques:
– UCT et contrôleurs communiquent directement par des registres
– UCT et contrôleurs communiquent par des petites zones de mémoire
centrale d’adresse fixe pour chaque contrôleur (ports)
– Aussi, le SE utilise le RAM pour des tampons pour les données d’E/S
– Et combinaisons de ces techniques
RA
M
UCT
Contr.
Péripher.
tampon
Chap 12 4
Quand communiquer entre
programmeet périphérique?
Chap 12 6
• Deux méthodes principales:
– Scrutation (polling): l’initiative est au
programme
– Interruption: l’initiative est à la
périphérique
• Grande variété d’implémentations
659.
Scrutation (polling)
Chap 127
• Bit dans le contrôleur E/S:
– 0 si si occupé à travailler
– 1 si libre - prêt à accepter commande
• Bit dans l’UCT: commande prête (command ready)
– 1 s’il y a une commande prête à exécuter par le contrôleur
• L’UCT continue de regarder le bit occupé du contrôleur
jusqu’à ce qu’il soit libre (c’est la scrutation)
• Elle positionne alors le bit commande prête
• Le contrôleur voit ceci et devient occupé
• Inefficacité de cette méthode si (comme normal) l’UCT se
trouve très souvent dans une boucle de scrutation
– Attente occupée
660.
Interruption
• L’UCT faitson travail, jusqu’à ce qu’elle reçoit un
signal sur la ligne de requête d’interruption
(interrupt request line)
– Cette ligne est interrogée après l’exécution de
chaque instruction
• À moins que l’interruption ne soit masquée
• Souvent deux lignes d’interruptions: masquable, non
masquable
– Transfert à une adresse de mémoire où il y a
renvoi à la routine de traitement (dans le vecteur
d’interruption)
– Les interruptions ont différentes priorités
• Si une interruption d’haute priorité se présente lors que le
système est en train de traiter une int. de prio. faible, la
première est traitée avant
Chap 12 8
Table des vecteursd’interruptions
Intel Pentium (partie non-masquable jusqu’à 31)
Chap 12 10
663.
Appels système
• Quandun usager demande un service du
noyau, le SE exécute une instruction qui
cause une interruption logicielle ou
déroutement (trap)
• Le système passe en mode
superviseur et trouve dans
l’instruction les paramètres qui
déterminent quoi faire
• Plus basse priorité que p.ex. E/S
Chap 12 11
664.
Accès direct enmémoire (DMA)
• Dans les systèmes sans DMA, l’UCT est
impliquée dans le transfert de chaque
octet
• DMA est utile pour exclure l’implication de
l’UCT surtout pour des E/S volumineuses
• Demande un contrôleur spécial
• Ce contrôleur a accès direct à la
mémoire centrale
Chap 12 12
Vol de cycles
•Le D
M
A ralentit encore le traitement d’UCT car
quand le D
M
A utilise le bus mémoire,
l’UCT ne peut pas s’en servir
• Mais beaucoup moins que sans DMA, quand
l’UCT doit s’occuper de gérer le transfert
Mémoire <-> Périphérique
Mém
UCT
DM
A
c
Contr.
Contr UCT Mém
Chap 12 14
667.
Interface E/S d’application
Chap12 15
• Le système d’E/S encapsule le comportement
despériphériques dans classes génériques
• La couche pilote de périfs masque les
différences existantes entre périphs
spécifiques
• Ceci simplifie l’inter changement de
différentes périphériques
• Mais le constructeur d’une périph doit créer
autant depilotes qu’il y a de SE qui peuvent
utiliser la périph
Périphériques par blocsou
caractères
Chap 12 18
• Périphériques par blocs: disques, rubans…
– Commandes: read, write, seek
– Accès brut (raw) ou à travers système fichiers
– Accès représenté en mémoire (memory-mapped)
• Semblable au concept de mémoire virtuelle ou cache:
– une certaine partie du contenu de la
périphérique est stocké en mémoire principale, donc
quand un programme fait une lecture de disque, ceci
pourrait être une lecture de mémoire principale
• Périphériques par caractère (clavier
, écran)
– Get, put traitent des caractères
– Librairies au dessus peuvent permettre édition de
lignes, etc.
671.
Périphériques réseau
Chap 1219
• Unix et Windows utilisent le concept de
socket
– Permet à l’application de faire
abstraction du protocole
– Fonctionnalité select: appel à select indique
en retour quelles sont les sockets prêts à
recevoir un paquet ou quelles peuvent
accepter un paquet à transmettre
• Grand nombre de solutions différentes:
pipes, FIFOs, streams, queues, mailboxes
672.
Horloge et minuterie
Chap12 20
• Fournit le temps courant, le temps
écoulé, déclenche des minuteries
• Peuvent être utilisées pour
interruptions périodiques, interruptions
après des périodes données
– Grand nombre d’applications
673.
E/S bloquantes,synchrones et
non-bloquantes
Chap12 21
• Bloquante: le processus qui demande une E/S est
suspendu jusqu’à la fin de l’E/S
– Facile à comprendre
– Mais le proc pourrait vouloir continuer pour faire d’autres
choses urgentes
• Asynchrone: l’E/S est demandée, et le processus
continue son exécution, il sera plus tard averti de la
terminaison
– Utilisée dans le passé, peu utilisée à présent car le temps de
terminaison est imprévisible
– Programmation difficile: quoi faire en attente de l’interruption?
• Non-bloquante: dans ce cas, le proc peut créer des
différentes tâches qui lui permettent de continuer avec
autres activités
674.
Chap 12 22
E/Ssynchrones, asynch et
non-bloquantes
Synchrone:proc
suspendu pendant
E/S
Asynch:proc continue,
sera interrompu quand
E/S complétée
Non-bloquante:proc A crée proc B
pour faire une E/S synchrone,
continue pour
faire autre chose puis les
deux se
réunisse
A
B
Interr.
join
675.
Sous-système E/S dunoyau
Chap 12 23
• Fonctionnalités:
– Ordonnancement E/S
– Mise en tampon
– Mise en cache
– Mise en attente et réservation de
périphérique
– Gestion des erreurs
676.
Sous-système E/S dunoyau
Ordonnancement E/S
Chap 12 24
• Optimiser l’ordre dans lequel les E/S
sont exécutées
– Chapitre sur ordonnancement disque
677.
Sous-système E/S dunoyau
Chap 12 25
Mise en tampon
• Double tamponnage:
– P
.ex. en sortie: un processus écrit le prochain
enregistrement sur un tampon en
mémoire tant que l’enregistrement précédent
est en train d’être écrit
– Permet superposition traitement/E/S
678.
Sous-système E/S dunoyau
Mise en cache
Chap 12 26
• Quelques éléments couramment utilisés
d’une mémoire secondaire sont gardés
en mémoire centrale
• Donc quand un processus exécute une
E/S, celle-ci pourrait ne pas être une
E/S réelle: – Elle pourrait être un transfert
en mémoire, une
simple mise à jour d’un pointeur
, etc.
• V.disque RAM Chap. 11
679.
Sous-système E/S dunoyau
Chap 12 27
Mise en attente et réservation de
périphérique: spoule
• Spoule ou Spooling est un mécanisme par lequel des
travaux àfaire sont stockés dans un fichier
, pour être
ordonnancés plus tard
• Pour optimiser l’utilisation des périphériques lentes, le SE
pourrait diriger à un stockage temporaire les données
destinés àla périphérique (ou provenant d’elle)
– P
.ex. chaque fois qu’un programmeur fait une impression, les
données pourraient au lieu être envoyées à un disque,
pour être imprimées dans leur ordre de priorité
– Aussi les données en provenance d’un lecteur optique
pourraient être stockées pour traitement plus tard
680.
Sous-système E/S dunoyau
Gestion des erreurs
Chap 12 28
• Exemples d’erreurs à être traités par le
SE:
– Erreurs de lecture/écriture, protection,
périph non- disponible
• Les erreurs retournent un code ‘raison’
• Traitement différent dans les différents
cas…
681.
Structures de donnéesdu noyau
• Le noyau garde toutes les informations
concernant les fichiers ouverts,
composants E/S, connections
• U
n grand nombre de structures de
données complexes pour garder
l’information sur les tampons,
l’allocation de mémoire, etc.
Chap 12 29
682.
Gestion de requêtesE/S
Chap 12 30
• P
. ex. lecture d’un fichier de disque
– Déterminer où se trouve le fichier
– Traduire le nom du fichier en nom de
périphérique et location dans périphérique
– Lire physiquement le fichier dans le tampon
– Rendre les données disponibles au processus
– Retourner au processus
683.
Cycle de vied’une requête E/S
Si données
déjà en RAM
(cache)
Chap 12 31
Concepts importants duchapitre
Chap 12 33
• Matériel E/S
• Communication entre UCT et contrôleurs
périfériques
• Interruptions et scrutation
• DMA
• Pilotes et contrôleurs de périfs
• E/S bloquantes ou non, asynchrones
• Sous-système du noyau pour E/S
– Tamponnage, cache, spoule
686.
Concept de Cache
Chap12 34
• Le mot cache est utilisé souvent dans situations
apparemmentdifférentes, p.ex:
– Entre l’UCT et la mémoire RAM nous pouvons avoir une
mémoire cache
– Le Translation Lookaside Buffer (TLB) utilisé pour contenir les
adresses de mémoire virtuelle les plus récemment utilisés est
souvent appelé cache
– La technique de charger en RAM certains données disque
qui sont beaucoup utilisées est aussi appelée ‘caching’
• En général, caching veut dire transférer dans une
mémoire plus rapide des informations normalement
contenues dans unemémoire plus lente, quand le SE croit
qu’elles seront demandéesbientôt
687.
Chap. 13 1
Chapitre13 (Seul. 13.1, 13.2,
13.4)
Structure de mémoire de masse (disques)
http://w3.uqo.ca/lui
gi/
688.
Concepts importants duchapitre 13
Chap. 13 2
Fonctionnement et structure des unités
disque
Calcul du temps d’exécution d’une
séquence d’opérations
Différents algorithmes
d’ordonnancement
Fonctionnement, rendement
Gestion de l’espace de
permutation
Unix
689.
Disques magnétiques
Chap. 133
Plats rigides couverts de matériaux
d ’enregistrement magnétique
surface du disque divisée en pistes (tracks)
qui sont divisées en secteurs
le contrôleur disque détermine
l`interaction logique entre l ’unité et l
’ordinateur
Beaucoup d’infos utiles dans:
http://www.storagereview.com/guide2000/ref/
hdd
/index.html
Un disque àplusieurs surfaces
Chap. 13 5
http://computer.howstuffworks.com
692.
Disques éléctroniques
Chap. 136
Aujourd’hui nous trouvons de plus en plus
des types de mémoires qui sont adressées
comme si elle étaient des disques, mais
sont complètement électroniques
P. ex. flash memory
Il n’y aura pas les temps de
positionnement, latence, etc. discutés
plus tard
693.
Ordonnancement disques
Chap. 137
Problème: utilisation optimale du matériel
Réduction du temps total de lecture disque
étant donné une file de requêtes de
lecture disque, dans quel ordre les
exécuter?
694.
Paramètres à prendreen considération
Temps de positionnement (seek
time):
le temps pris par l`unité disque
pour se positionner sur le
cylindre désiré
Temps de latence de rotation
le temps pris par l ’unité de
disque qui est sur le bon cylindre
pour se positionner sur le
secteur désirée
Temps de lecture
temps nécessaire pour lire la
piste
Le temps de positionnement est
normalement le plus important, donc
il est celui que nous chercherons à
minimiser
Chap. 13 8
695.
File d’attente disque
Chap.13 9
Dans un système multiprogrammé avec mémoire virtuelle,
il y aura normalement une file d’attente pour l ’unité disque
Dans quel ordre choisir les requêtes d ’opérations disques
de façon à minimiser les temps de recherche totaux
Nous étudierons différents méthodes par rapport à une
file d ’attente arbitraire:
98, 183, 37, 122, 14, 124, 65, 67
Chaque chiffre est un numéro séquentiel de cylindre
Il faut aussi prendre en considération le cylindre de départ:
53
Dans quel ordre exécuter les requêtes de lecture de façon
à minimiser les temps totaux de positionnement cylindre
Hypothèse simpliste: un déplacement d`1 cylindre coûte 1
unité de temps
696.
Chap. 13 10
Premierentré, premier sorti:
FIFO
axe de
rotation
45
85
146
85
108
110
59
2
Mouvement total: 640 cylindres = (98-53) + (183-98)+...
En moyenne: 640/8 = 80
697.
SSTF: Shortest SeekTime
First
Chap. 13 11
Plus court d’abord
À chaque moment, choisir la requête avec
le temps de recherche le plus court à partir
du cylindre courant
Clairement meilleur que le précédent
Mais pas nécessairement optimal! (v.
manuel)
Peut causer famine
698.
SSTF: Plus courtservi
Mouvement total: 236 cylindres (680 pour le précédent)
En moyenne: 236/8 = 29.5 (80 pour le précédent)
Chap. 13 12
699.
Problèmes commun àtous les algorithmes
qui sélectionnent toujours le plus voisin:
Chap. 13 13
Balaient efficacement un voisinage, puis
quand ils ont fini là dedans doivent faire
des déplacement plus importants pour
traiter ce qui reste
Famine pour les autres s’il y a apport
continu d’éléments dans le voisinage
700.
SCAN: l’algorithme del’ascenseur
Chap. 13 14
La tête balaye le disque dans une
direction, puis dans la direction opposée,
etc., en desservant les requêtes quand il
passe sur le cylindre désiré
Pas de famine
Problèmes du SCAN
Chap.13 16
Peu de travail à faire après le renversement
de direction
Les requêtes seront plus denses à l’autre
extrémité
Arrive inutilement jusqu’à 0
703.
C-SCAN
Chap. 13 17
Retourrapide au début (cylindre 0) du disque au
lieu de renverser la direction
Hypothèse: le mécanisme de retour est beaucoup
plus rapide que le temps de visiter les cylindres
Comme si les disques étaient en forme de beignes!
C-LOOK
La même idée, mais au lieu de retourner au
cylindre 0, retourner au premier cylindre qui a une
requête
704.
153 sans considérerle retour (19.1 en moyenne) (26 pour SCAN)
MAIS 322 avec retour (40.25 en moyenne)
Chap. 1N3 ormalement le retour sera rapide donc le coût réel sera entre 18
C-
LOOK
retour: 169 (??)
direction
705.
C-LOOK avec directioninitiale opposée
directio
n
Résultats très semblables:
157 sans considérer le retour
, 326 avec le
retour
Chap. 13 19
Retour
169
706.
Exemple pratique…
Chap. 1320
Si on doit ramasser des gens de Gatineau
Est à Aylmer, il pourrait être plus rapide de
faire le tour à Gatineau, puis prendre
l’autoroute jusqu’à Aylmer et ramasser le
reste, au lieu d’arriver à Aylmer par rues
régulières tout en ramassant des gens…
707.
Comparaison
Chap. 13 21
Sila file souvent ne contient que très peu
d’éléments, l’algorithme du ‘premier servi ’ devrait
être préféré (simplicité)
Sinon, SSTF ou SCAN ou C-SCAN?
En pratique, il faut prendre en considération:
Les temps réels de déplacement et retour au début
L`organisation des fichiers et des répertoires
Les répertoires sont sur disque aussi…
La longueur moyenne de la file
Le débit d ’arrivée des requêtes
708.
Gestion de l’espacede permutation en
mémoire virtuelle (swap space) (13.4)
Chap. 13 22
Nous avons vu comment les systèmes de
mém virtuelle utilisent la mém secondaire
Grande variété d’implémentations de
systèmes d’espace de permutation dans
différents SE
L’esp permutation (swap)
peut être des fichiers normaux dans
l’espace disque utilisé par les autres
fichiers,
ou peut avoir sa propre partition disque
Peut être mis dans des disques plus
efficaces
709.
Gestion d’espace depermutation (disque) en
Unix 4.3BSD
Chap. 13 23
Pour chaque processus, il y a
Un segment texte = le programme
Ne change pas pendant exécution
Et il y a aussi un segment
données
Sa taille peut changer pendant
exéc
710.
Unix 4.3BSD: Tableaud’allocation du
segment de texte=programme
L’espace disque est alloué en morceaux
fixes de 512K
Dernier morceau
de programme
plus court
Chap. 13 24
711.
Unix 4.3BSD: Tableaud’allocation du
segment données sur disque
Les données changent de taille plus
souvent que le programme
Chaque fois qu’un proc demande plus de
mémoire, on lui donne le double
Chap. 13 25
712.
Autres mécanismes enUnix
Chap. 13 26
Les mécanismes sont différents dans
différentes versions de Unix
Les différentes versions fonctionnent avec
autres mécanismes, comme pagination,
systèmes compagnons (buddy) etc.
713.
RAID: Redundant Arrayof Independent Disks
Stallings
En distribuant les données sur différents disques, il est probable
qu’une grosse lecture puisse être faite en parallèle (au lieu de
lire strip0 et strip1 en séquence, cette organisation permet de les
lire en même temps)
Chap. 13 27
714.
Redondance dans RAID
Chap.13 28
Stallings
Dupliquer les données pour incrémenter le parallélisme
et remédier aux pertes de données (coûteux mais
utilisé en pratique)
715.
RAID: Correction d’erreurspar codes de
correction
Chap. 13 29
Stallings
Les codes de correction d’erreur pour des données
enregistrées sur un disque sont sauvegardés sur un autre
disque (plus de résistance aux erreurs)
716.
Concepts importants duchapitre 13
Chap. 13 30
Fonctionnement et structure des unités
disque
Calcul du temps d’exécution d’une
séquence d’opérations
Différents algorithmes
d’ordonnancement
Fonctionnement, rendement
Gestion de l’espace de
permutation
Unix
RAID: réorganisation des fichiers pour
performance et résistance aux erreurs
717.
Par rapport aulivre
Chap. 13 31
Seulement 13.1, 13.2, 13.4


























![Phase 2.5: Traitement par lots
multiprogrammé
[Stallings]
Ch. 1 20
Les opérations E/S sont extrêmement lentes
(comparé aux autres instructions)
P. ex. une boucle de programme pourrait durer 10
microsecondes, une opération disque 10
millisecondes
C’est la différence entre 1 heure et un mois et demi!
Même avec peu d’E/S, un programme passe la
majorité de son temps à attendre
Donc: pauvre utilisation de l’UCT lorsqu’un seul
pgm usager se trouve en mémoire](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-27-320.jpg)
![Traitement par lots multiprogrammé
Si la mémoire peut contenir +sieurs pgms,
l’UCT peut exécuter un autre pgm
lorsqu’un pgm attend après E/S
C’est la multiprogrammation
[Stallings]
Ch. 1 21](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-28-320.jpg)




























![50
Programmes Hello World d’aujourd’hui
class HelloWorld {
public static void printHello( ) {
System.out.println("Hello,
World");
}
}
class UseHello {
public static void main(String[ ] args)
{ HelloWorld myHello = new
HelloWorld( ); myHello.printHello( );
}
}
Dans l’article:
C. Hu. Dataless objects considered harmful.
Comm. ACM 48 (2), 99-101
http://portal.acm.org/citation.cfm?id=1042091.1042126#
l’auteur présente deux versions orientées objet de
programmes ‘Hello World’. Il critique la version ci-
dessous disant qu’elle n’est pas vraiment orientée
objet
et qu’il faudrait vraiment utiliser la version à droite.
Quelle est la mémoire demandée par ces
class Message {
String messageBody;
public void setMessage(String
newBody) { messageBody =
newBody;
}
public String getMessage(
) { return messageBody;
}
public void printMessage( )
{ System.out.println(messageBo
dy);
}
}
public class MyFirstProgram {
public static void main(String[ ]
args) { Message mine = new
Message ( );
mine.setMessage("Hello, World");
Message yours = new Message
( );
yours.setMessage("This is my first
program!"); mine.printMessage( );
System.out.println(yours.getMessage( ) +
"—" +
mine.getMessage( ) );](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-57-320.jpg)









![Le cycle d’instruction de base
[Stallings]
Ch.2 10
• L’UCT extrait l’instruction de la mémoire.
• Ensuite l’UCT exécute cette instruction
•Le compteur d’instruction (PC) contient l’adresse de la
prochaine instruction à extraire
• Le PC est incrémenté automatiquement après chaque extraction](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-67-320.jpg)
![Le cycle d’instruction avec interruptions
[Stallings]
Après chaque instruction, si les interruptions sont habilitées, l’UCT
examine s’il y a eu une interruption
S’il n’y en a pas, il extrait la prochaine instruction du programme
S’il y en a, il suspend le pgm en cours et branche l’exécution à une
position fixe de mémoire (déterminée par le type d ’interruption)
une partie de la mémoire et réservée pour ça
Ch.2 11](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-68-320.jpg)






![Ordre séquentiel des interruptions [Stallings]
Interruption désactivée durant l’exécution d’un IH
Les interruptions sont en attente jusqu’à ce que l’UCT active les
interruptions (file d’attente en matériel).
L’UCT examine s’il y a des interruptions en attente après avoir
terminé d’exécuter l’IH
Ch.2 18](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-75-320.jpg)







































































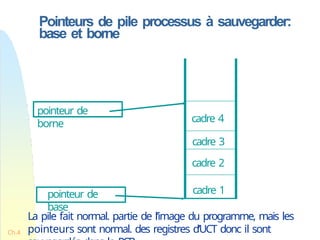












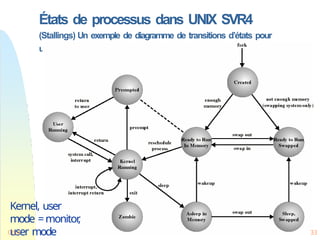



![Le tampon borné (bounded
buffer)
une structure de données fondamentale dans les
SE
b[0] b[1]
b[7] b[2]
b[6] b[3]
b[5] b[4]
ou
in: 1ère
pos. libre
out: 1ère
pos. pleine
Le tampon borné se trouve dans la mémoire partagée
entre consommateur et usager
b[0] b[1] b[2] b[3] b[4] b[5] b[6] b[7]
in: 1ère
pos. libre
Ch.4 37
out: 1ère
pos.
pleine
bleu: plein, blanc:
libre
À l’écriture d’une nouvelle info dans le tampon, le producteur
met à jour le pointeur in
Si le tampon est plein, le prod devra s’endormir, il sera plus
tard réveillé par le consommateur
Le rôle du consommateur est symétrique (v. Chap. 7)](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-164-320.jpg)








![Threads et processus [Stallings]
Ch.5 6](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-173-320.jpg)
















































![Importance de différents valeurs de coefficients
[Stallings]
Peu d’import. aux cycles
récents
Beaucoup d’import aux cycles
récs
Ch. 6 26
Stallings](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-222-320.jpg)
![Importance de différents valeurs de coefficients
[Stallings]
S1 = 0 (priorité aux nouveaux processus)
Un coefficient plus élevé réagit plus rapidement aux
changements de comportement
Ch. 6 27
Stallings](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-223-320.jpg)
![Un deuxième exemple [Stallings]
Stallings
Ch. 6 28](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-224-320.jpg)



![Tourniquet = Round-Robin
(RR)
P[0] P[1]
P[7] P[2]
P[6] P[3]
P[5] P[4]
Le plus utilisé en pratique
Chaque processus est alloué une tranche de
temps (p.ex. 10-100 millisecs.) pour exécuter
Tranche aussi appelée quantum
S’il exécute pour tranche entière sans autres
interruptions, il est interrompu par la minuterie
et l ’UCT est donnée à un autre processus
Le processus interrompu redevient prêt (à la fin de
la file)
Méthode préemptive
La file prêt est un
cercle (dont RR)
Ch. 6 32](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-228-320.jpg)





![Ch. 6 38
Choix de la tranche pour le tourniquet
[Stallings]
doit être beaucoup plus grande que le temps requis pour
exécuter le changement de contexte
doit être un peu plus grand que le cycle typique (pour donner
le temps à la plupart des proc de terminer leur cycle, mais pas trop pour éviter
de pénaliser les processus courts)
Stallings
v. ex. prec. où les point optimaux sont 6 et 7, et il y a deux cycles](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-234-320.jpg)



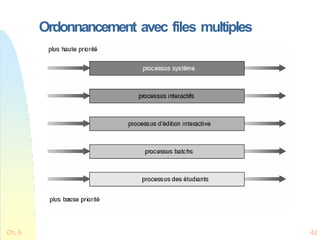



















![62
Critère
sélection
Préempt Motivation Temps de
rotat. et att.
Temps de
système
Effect sur
processus
Famine
FCFS Max [w] non Simplicité Variable Minim. Favor. proc.
trib. UCT
Non
Tourniq. Tour fixe oui
Equité
Variable selon
tranche,
Normalement
élevé
Élevé
pour
tranche
courte
Équitable Non
SJF Min[s] non
Optimisatio
n des
temps
Optimal, mais
souffre si des
procs longs
arrivent au début
Peut être
élevé (pour
estimer les
longs. des
trames)
Bon pour
proc.
courts,
pénalise
proc. longs
Possible
SJF
préemp.
Min[s-e] oui
Évite le problème
de procs longs au
début
Meilleur, même si
des procs longs
arrivent au début
Peut être
élevé
Pénalise
plus encore
proc. longs
Possible
Files
multiniv.
v. détails oui
Varie la longueur
des tranches en
fonction des
besoins
Variable
Peut être
élévé
Variable
Possible
w: temps total dans système jusqu’à
présent;
Chs. :6temps
e: temps en exec jusqu’à
présent
Famine est ‘renvoi](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-258-320.jpg)




















![Algorithme 2 ou l’excès de
courtoisie...
Une variable Booléenne par
Thread: flag[0] et flag[1]
Ti signale qu’il désire exécuter
sa SC par: flag[i] =vrai
Mais il n’entre pas si l’autre
est aussi intéressé!
Exclusion mutuelle ok
Progrès pas satisfait:
Considérez la séquence:
T0: flag[0] = vrai
T1: flag[1] = vrai
Chaque thread attendra
indéfiniment pour
exécuter sa SC: on a un
interblocage
Thread Ti:
repeat
flag[i] = vrai;
while(flag[j]);
SC
flag[i] = faux;
SR
forever rien
faire
Chap. 7 20](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-279-320.jpg)
![Thread T0:
repeat
flag[0] = vrai;
while(flag[1]);
SC
flag[0] = faux;
SR
forever
Thread T1:
repeat
flag[1] = vrai;
while(flag[0]);
SC
flag[1] = faux;
SR
forever
Algorithme 2 vue globale
T0: flag[0] =
vrai T1: flag[1]
= vrai
interblocage!
Après vous,
monsieur
Après vous,
monsieur
Chap. 7 21](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-280-320.jpg)
![Algorithme 3 (dit de Peterson):
bon!
Chap. 7 22
combine les deux idées: flag[i]=intention d’entrer; turn=à qui le
tour
Initialisation:
flag[0] = flag[1] =
faux
turn = i ou j
Désire d’exécuter SC est
indiqué par flag[i] = vrai
flag[i] = faux à la section de
sortie
Thread Ti:
repeat
flag[i] = vrai;
// je veux entrer
turn = j;
// je donne une chance à l’autre
do while
(flag[j] && turn==j);
SC
flag[i] = faux;
SR
forever](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-281-320.jpg)
![Entrer ou attendre?
Chap. 7 23
Thread Ti attend si:
Tj veut entrer est c’est la chance à Tj
flag[j]==vrai et turn==j
Un thread Ti entre si:
Tj ne veut pas entrer ou c’est la chance à Ti
flag[j]==faux ou turn==i
Pour entrer, un thread dépend de l’autre qu’il lui
donne la chance!](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-282-320.jpg)
![Thread T0:
repeat
flag[0] = vrai;
// T0 veut entrer
turn = 1;
// T0 donne une chance à T1
while
(flag[1]&&turn=1);
SC
flag[0] = faux;
// T0 ne veut plus
entrer
SR
forever
Thread T1:
repeat
flag[1] = vrai;
// T1 veut entrer
turn = 0;
// T1 donne une chance à 0
while
(flag[0]&&turn=0);
SC
flag[1] = faux;
// T1 ne veut plus
entrer
SR
forever
Algorithme de Peterson vue
globale
Chap. 7 24](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-283-320.jpg)
![Scénario pour le changement de contrôle
Thread T0:
…
SC
flag[0] = faux;
// T0 ne veut plus entrer
SR
…
Thread T1:
…
flag[1]
= vrai;
// T1
veut
entrer
turn =
0;
// T1
donne
une
chance à
T0
while
(flag[0]&&turn=0) ;
//test faux, entre
(F&&V)
T1 prend la relève, donne une chance à T0 mais
T0 a dit qu’il ne veut pas entrer.
T1 entre donc dans la SC
Chap. 7 25](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-284-320.jpg)
![Autre scénario de changem. de
contrôle
Thread T0:
SC
flag[0] = faux;
// T0 ne veut plus entrer
SR
flag[0] = vrai;
// T0 veut entrer
turn = 1;
// T0 donne une chance à T1
while
(flag[1]==vrai&&turn=1) ;
// test vrai, n’entre pas
(V&&V)
Thread T1:
flag[1] = vrai;
// T1 veut entrer
turn = 0;
// T1 donne une chance à T0
// mais T0 annule cette action
while
(flag[0]&&turn=0) ;
//test faux, entre
(V&&F)
T0 veut rentrer mais est obligé de donner une chance à T1,
qui entre
Chap. 7 26](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-285-320.jpg)
![Chap. 7 27
Mais avec un petit décalage, c’est encore
T0!
Thread T0:
SC
flag[0] = faux;
// 0 ne veut plus entrer
RS
flag[0] = vrai;
// 0 veut entrer
turn = 1;
// 0 donne une chance à 1
// mais T1 annule cette action
while
(flag[1] && turn=1) ;
// test faux, entre (V&&F)
Thread T1:
flag[1] = vrai;
// 1 veut entrer
turn = 0;
// 1 donne une chance à 0
while
(flag[0]&&turn=0);
// test vrai,
n’entre pas
Si T0 et T1 tentent simultanément d’entrer dans SC, seule une valeur pour
turn survivra:
non-déterminisme (on ne sait pas qui gagnera), mais l’exclusion](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-286-320.jpg)
![Donc cet algo. n’oblige pas une tâche
d’attendre
pour d’autres qui pourraient ne pas avoir besoin de la SC
Supposons que T0 soit le seul à avoir besoin de la SC, ou que
T1 soit
lent à agir: T0 peut rentrer de suite
(flag[1]==faux
est sorti)
la dernière fois que
T1
flag[0] = vrai // prend l’initiative
turn = 1 // donne une chance à
l’autre while flag[1] && turn=1 //test faux, entre
SC
flag[0] = faux // donne une chance à
l’autre
Cette propriété est désirable, mais peut causer famine pour
Chap. 7 28](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-287-320.jpg)
![Algorithme 3: preuve de
validité
Chap. 7 29
(pas matière d’examen, seulement pour les
intéressés…)
Exclusion mutuelle est assurée car:
T0 et T1 sont tous deux dans SC seulement si
turn est simultanément égal à 0 et 1
(impossible)
Démontrons que progrès et attente limitée
sont satisfaits:
Ti ne peut pas entrer dans SC seulement si
en attente dans la boucle while() avec
condition: flag[ j] == vrai and turn = j.
Si Tj ne veut pas entrer dans SC alors flag[ j]
= faux et Ti peut alors entrer dans SC](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-288-320.jpg)
![Algorithme 3: preuve de validité (cont.)
Chap. 7 30
Si Tj a effectué flag[ j]=vrai et se trouve dans
le while(), alors turn==i ou turn==j
Si
turn==i, alors Ti entre dans SC.
turn==j alors Tj entre dans SC mais il
fera
flag[ j] =false à la sortie: permettant à Ti
d’entrer CS
mais si Tj a le temps de faire
flag[ j]=true, il devra aussi faire turn=i
Puisque Ti ne peut modifier turn lorsque
dans le while(), Ti entrera SC après au plus
une entrée dans SC par Tj (attente limitée)](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-289-320.jpg)




























![Le tampon borné (bounded
buffer)
une structure de données fondamentale dans les
SE
b[0] b[1]
b[7] b[2]
b[6] b[3]
b[5] b[4]
ou
out: 1ère
pos. pleine
in: 1ère
pos. libre b[0] b[1] b[2] b[3] b[4] b[5] b[6] b[7]
in: 1ère
pos. libre
bleu: plein, blanc: libre
out: 1ère
pos.
pleine
Le tampon borné se trouve dans la mémoire partagée
entre consommateur et usager
Chap. 7 59](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-318-320.jpg)



![Chap. 7 63
Solution de P/C: tampon circulaire fini de dimension k
Producer:
repeat
produce v;
wait(E);
wait(S);
append(v);
signal(S);
signal(N);
forever
Consumer:
repeat
wait(N)
;
wait(S)
;
w=take(
);
signal(S);
signal(E);
consume(w);
forever
Initialization: S.count=1; //excl. mut.
N.count=0; //esp. pleins
E.count=k; //esp. vides
a
p
p
e
n
d
(
v
)
:
b
[
i
n
]
Sections critiques
In ++ mod k;
take():
w=b[out];
Out ++ mod k;
return w;](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-322-320.jpg)













![Le problème des philosophes
mangean
t
Un thread par
philosophe
Un sémaphore par
fourchette:
fork: array[0..4]
of semaphores
Initialisation: fork[i]
=1 for i:=0..4
Première tentative:
interblocage si
chacun débute en
prenant sa
fourchette gauche!
wait(fork[i])
Thread Pi:
repeat
think;
wait(fork[i]);
wait(fork[i+1 mod 5]);
eat;
signal(fork[i+1 mod 5]);
signal(fork[i]);
forever
Chap. 7 10](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-336-320.jpg)
![Le problème des philosophes
mangean
t
Une solution: admettre
seulement 4 philosophes
à la fois qui peuvent
tenter de manger
Il y aura touj. au moins
1 philosophe qui
pourra manger
même si tous
prennent 1
fourchette
Ajout d’un sémaphore T
qui limite à 4 le nombre
de philosophes “assis à
la table”
initial. de T à 4
N’empêche pas famine!
Thread Pi:
repeat
think;
wait(T);
wait(fork[i]);
wait(fork[i+1 mod 5]);
eat;
signal(fork[i+1 mod
5]);
signal(fork[i]);
signal(T);
forever
Chap. 7 11](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-337-320.jpg)
















![Philosophes mangeant structures de
données
Chaque philos. a son propre state qui peut être
(thinking, hungry, eating)
philosophe i peut faire state[i] = eating ssi les voisins
ne mangent pas
Chaque condition a sa propre condition self
le philosophe i peut attendre sur self [ i ] si veut
manger, mais ne peut pas obtenir les 2 baguettes
Chap. 7 28](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-354-320.jpg)

![Chap. 7 30
private test(int i) {
if ( (state[(i + 4) % 5] != EATING) &&
(state[i] == HUNGRY) &&
(state[(i + 1) % 5] != EATING) ) {
state[i] = EATING;
self[i].signal;
}
}
Un philosophe mange
Un philosophe mange si ses voisins ne mangent pas et
s’il a faim.
Une fois mangé, il signale de façon qu’un autre
pickup soit possible, si pickup s’était arrêté sur wait
Il peut aussi sortir sans avoir mangé si le test est faux](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-356-320.jpg)
![Chercher de prendre les baguettes
public entry pickUp(int i) {
state[i] =
HUNGRY; test(i);
if (state[i] !=
EATING)
self[i].wait;
}
Phil. cherche à manger en testant, s’il sort de test qu’il
n’est pas mangeant il attend – un
Chap. 7 31](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-357-320.jpg)
![Déposer les baguettes
public entry putDown(int i) {
state[i] = THINKING;
// tester les deux
voisins
test((i + 4) % 5);
test((i + 1) % 5);
} Une fois fini de manger, un philosophe se
préoccupe de faire manger ses voisins en les
testant
Chap. 7 32](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-358-320.jpg)



![Moniteur pour P/C avec tampon
fini
Chap. 7 36
(syntaxe un peu différente, pas orienté objet)
Monitor boundedbuffer:
buffer: vecteur[0..k-1] de items;
nextin = 0, nextout = 0, count = 0 ;
notfull, notempty: condition;
Produce(v):
if (count==k) notfull.wait;
buffer[nextin] = v;
nextin = (nextin+1 mod k);
count ++;
notempty.signal;
Consume(v):
v = buffer[nextout];
nextout = (nextout+1 mod k);
count --;
notfull.signal;
Variable conditionnelle sur
laquellele producteur attend
s’il n’y a pas d’espaces libres
Variable conditionnelle sur
laquelle
if (count==0) notempty.wait; le consommateur attend s’il n’y a pas
d’espaces
occupés](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-362-320.jpg)





















































































































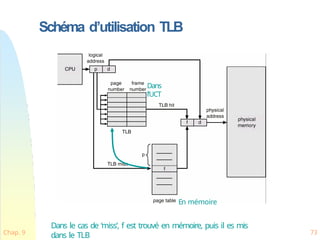

















































































![Effets de l’organisation du programme sur
l’efficacité de la pagination
Chap 10-2 20
Structure de programme
Array A[1024, 1024]
chaque ligne est stockée dans une page
différente,
un cadre différent
Programme 1: balayage par
colonnes: for j = 1 to 1024 do
for i = 1 to 1024 do
A[i,j] = 0;
1024 x 1024 défauts de pagination
Programme 2: balayage par
lignes: for i = 1 to 1024 do
for j = 1 to 1024 do
A[i,j] = 0;
1024 défauts de pagination](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-562-320.jpg)














































































![Gestion d’espace
libre
Solution 1: vecteur de bits (solution
Macintosh, Windows 2000)
Vecteur de bits (n blocs)
0 1 2
n-1
…
bit[i]
=
Chap 11 70
1 block[i] libre
2 block[i]
occupé
Exemple d’un vecteur de bits où les blocs 3,
4, 5, 9, 10, 15, 16 sont occupés:
00011100011000011…
L’adresse du premier bloc libre peut être
trouvée par un simple calcul](https://image.slidesharecdn.com/cours-complet-systemes-dexploitation-250630084056-5dede61b/85/cours-complet-systemes-adexploitation-pptx-642-320.jpg)


























































































































