Python 3 + apache hadoop
0 gostou394 visualizações

Este documento discute problemas de processamento de grandes volumes de dados em meteorologia e linguística de corpus e propõe soluções usando Apache Hadoop. Ele descreve desafios com bases de dados meteorológicas atualizadas frequentemente e operações comuns em linguística de corpus. Também analisa porque soluções anteriores como Celery + NFS e Python + Mongo não funcionaram bem e propõe que o Apache Hadoop é uma boa alternativa por causa de sua tolerância a falhas, interface amigável e boa documentação.





![Linguística de Corpus [0]
Linguística de corpus ocupa-se ela da coleta e da exploração de corpora, ou
conjutos de dados linguísticos textuais coletados criteriosamente, com o
propósito de servirem para a pesquisa de uma língua ou variedade linguística.
Como tal, dedica-se à exploração da linguagem por meio de evidências
empíricas, extraídas de computadores
(Sardinha, 2014)](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-6-320.jpg)
![Linguística de Corpus [1]
● O que esperar?
○ Não é PLN
○ Não é mineração de dados
○ Não é aprendizado de máquina](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-7-320.jpg)
![Linguística de Corpus [2]
Operações básicas esperadas LC (Mike Scott):
● Contagem de palavras (WordList)
● Concordância (Concord)
● Comparação (KeyWords)
● Etiquetagem (Tagging)](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-8-320.jpg)







![Apache Hadoop [0]
● Framework livre
● Escrito em Java
● Adaptação do Google File System (GFS)
● Adaptação do algorítimo de MapReduce
● “Pode ser programado em qualquer
linguagem” - Streaming](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-17-320.jpg)
![Apache Hadoop [1]
● Tolerância a falhas
● Interface amigável
● Boa documentação
● YARN](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-18-320.jpg)
![Apache Hadoop [2]](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-19-320.jpg)
![MapReduceLib [1]](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-20-320.jpg)
![Hadoop Streaming [0]
● Boa interface para se trabalhar com
qualquer linguagem quando usamos shell
script
● Código ‘simples’](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-21-320.jpg)


![Python + Hadoop [0]
● Pydoop (CRS4)
● Hadoopy
● MrJob (Yelp)
● Dumbo (LastFm)
Nenhuma funciona com Python 3+](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-24-320.jpg)
![Python + Hadoop [1]](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-25-320.jpg)
![MapReduceLib [0]
● Uma maneira de não mexer mais com Shell e
Java
● Uma abstração simples com um único import
● Funcionar bem com o modo interativo
● Acessar o sistema de arquivos distribuído
● Executar funções administrativas
● Fosse compatível com Spark](https://image.slidesharecdn.com/python3apachehadoop-151218022912/85/Python-3-apache-hadoop-26-320.jpg)

































Anúncio
Mais conteúdo relacionado
Destaque (14)
Semelhante a Python 3 + apache hadoop (20)












Anúncio
Python 3 + apache hadoop
- 1. Python 3 + Apache Hadoop Eduardo Mendes (z4r4tu5tr4)
- 2. z4r4tu5tr4@Babbage: whoami ● Eduardo Mendes ● Fatec Americana ● github.com/z4r4tu5tr4 ● [email protected]
- 3. Estrutura ● Problemas ○ Metereologia ○ Linguística de Corpus ● Soluções ○ Celery + NFS ○ Python + Mongo ○ Disco ○ Hadoop
- 4. Problemas Metereologia e Linguística de Corpus
- 5. Metereologia ● Cruzamento de duas bases de dados ● Atualizadas de 15 em 15 minutos ● Durante 100 anos ● Tabelas xls ● Mudança de padrão com o passar dos anos
- 6. Linguística de Corpus [0] Linguística de corpus ocupa-se ela da coleta e da exploração de corpora, ou conjutos de dados linguísticos textuais coletados criteriosamente, com o propósito de servirem para a pesquisa de uma língua ou variedade linguística. Como tal, dedica-se à exploração da linguagem por meio de evidências empíricas, extraídas de computadores (Sardinha, 2014)
- 7. Linguística de Corpus [1] ● O que esperar? ○ Não é PLN ○ Não é mineração de dados ○ Não é aprendizado de máquina
- 8. Linguística de Corpus [2] Operações básicas esperadas LC (Mike Scott): ● Contagem de palavras (WordList) ● Concordância (Concord) ● Comparação (KeyWords) ● Etiquetagem (Tagging)
- 10. Celery + NFS ● Complexibilidade de código ● Problemas com logs ● NFS não particiona arquivos ○ Problemas de leitura e armazenamento
- 11. Python + Mongo ● Uma solução excelente com metereologia e péssima com Linguística.
- 12. Soluções O que deu certo
- 13. Sistema de arquivos distribuído ● Google File System ○ Particiona arquivos em partes de 64mb ○ Três cópias de cada replicação ○ Arquitetura ‘Master - slave’
- 14. Sistema de arquivos distribuído
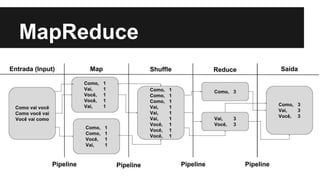
- 15. MapReduce
- 16. Disco ● Framework para processamento distribuído ● Feito em Python ● Projeto ‘Jovem’ ● “Não tem a melhor documentação do mundo”
- 17. Apache Hadoop [0] ● Framework livre ● Escrito em Java ● Adaptação do Google File System (GFS) ● Adaptação do algorítimo de MapReduce ● “Pode ser programado em qualquer linguagem” - Streaming
- 18. Apache Hadoop [1] ● Tolerância a falhas ● Interface amigável ● Boa documentação ● YARN
- 20. MapReduceLib [1]
- 21. Hadoop Streaming [0] ● Boa interface para se trabalhar com qualquer linguagem quando usamos shell script ● Código ‘simples’
- 24. Python + Hadoop [0] ● Pydoop (CRS4) ● Hadoopy ● MrJob (Yelp) ● Dumbo (LastFm) Nenhuma funciona com Python 3+
- 25. Python + Hadoop [1]
- 26. MapReduceLib [0] ● Uma maneira de não mexer mais com Shell e Java ● Uma abstração simples com um único import ● Funcionar bem com o modo interativo ● Acessar o sistema de arquivos distribuído ● Executar funções administrativas ● Fosse compatível com Spark