Self-attention is a technique used in NLP that helps models to understand relationships between words or entities in a sentence, no matter where they appear. It is a important part of transformers model which is used in tasks like translation and text generation.
Understanding Attention in NLP
The goal of self attention mechanism is to improve performance of traditional models such as encoder-decoder models used in RNNs (Recurrent Neural Networks). In traditional encoder-decoder models input sequence is compressed into a single fixed-length vector which is then used to generate the output. This works well for short sequences but struggles with long ones because important information can be lost when compressed into a single vector. To overcome this problem self attention mechanism was introduced.
Encoder-Decoder Model
An encoder-decoder model is used in machine learning tasks that involve sequences like translating sentences, generating text or creating captions for images. Here's how it works:
- Encoder: It takes the input sequence like sentences and processes them. It converts input into a fixed-size summary called a latent vector or context vector. This vector holds all the important information from the input sequence.
- Decoder: It then uses this summary to generate an output sequence such as a translated sentence. It tries to reconstruct the desired output based on the encoded information.
 Encoder-Decoder Model
Encoder-Decoder ModelIt includes:
 Transformer
Transformer1. Input Embedding: Input text like a sentences are first converted into embeddings. These are vector representations of words in a continuous space.
2. Positional Encoding: Since Transformer doesn’t process words in a sequence like RNNs positional encodings are added to the input embeddings and these encode the position of each word in the sentence.
3. Multi-Head Attention:
- In this multiple attention heads are applied in parallel to process different part of sequences simultaneously.
- Each head finds the attention scores based on queries (Q), keys (K) and values (V) and adds information from different parts of input.
- Output of all attention heads is combined and passed through further processing.
4. Add and Norm: This layer helps in residual connections and layer normalization. This helps to avoid vanishing gradient problems and ensures stable training.
5. Feed Forward: After attention output is passed through a feed-forward neural network for further transformation.
6. Masked Multi-Head Attention for the Decoder: This is used in the decoder and ensures that each word can only attend to previous words in the sequence not future ones.
7. Output Embedding: Finally transformed output is mapped to a final output space and processed by softmax function to generate output probabilities.
Self-Attention Mechanism
This mechanism captures long-range dependencies by calculating attention between all words in the sequence and helping the model to look at the entire sequence at once. Unlike traditional models that process words one by one it helps the model to find which words are most relevant to each other helpful for tasks like translation or text generation. Here’s how the self-attention mechanism works:
- Input Vectors and Weight Matrices: Each encoder input vector is multiplied by three trained weight matrices (W(Q), W(K), W(V)) to generate the key, query and value vectors.
- Query-Key Interaction: Multiply the query vector of the current input by the key vectors from all other inputs to calculate the attention scores.
- Scaling Scores: Attention scores are divided by the square root of the key vector's dimension (dk) usually 64 to prevent the values from becoming too large and making calculations unstable.
- Softmax Function: Apply the softmax function to the calculated attention scores to normalize them into probabilities.
- Weighted Value Vectors: Multiply the softmax scores by the corresponding value vectors.
- Summing Weighted Vectors: Sum the weighted value vectors to produce the self-attention output for the input.
Above procedure is applied to all the input sequences. Mathematically self-attention matrix for input matrices (Q, K, V) is calculated as:
Attention\left ( Q, K, V \right ) = softmax\left ( \frac{QK^{T}}{\sqrt{d_{k}}} \right )V
where Q, K, V are the concatenation of query, key and value vectors where,
head_{i} = Attention \left ( QW_{i}^{Q},KW_{i}^{K}, VW_{i}^{V} \right )
Multi-headed-attention
In multi-headed attention mechanism, multiple attention heads are used in parallel which allows the model to focus on different parts of the input sequence simultaneously. This approach increases model's ability to capture various relationships between words in the sequence. Here’s a step-by-step breakdown of how multi-headed attention works:
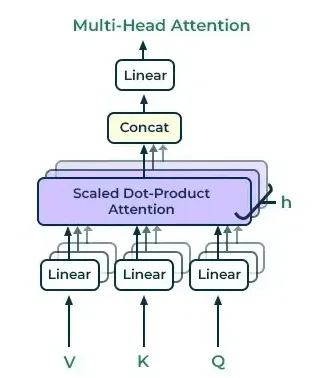 Multi-headed-attention
Multi-headed-attention- Generate Embeddings: For each word in the input sentence it generate its embedding representation.
- Create Multiple Attention Heads: Create h
(e.g h=8) attention heads and each with its own weight matrices W(Q),W(K),W(V).
- Matrix Multiplication: Multiply the input matrix by each of the weight matrices W(Q),W(K),W(V) for each attention head to produce key, query and value matrices.
- Apply Attention: Apply attention mechanism to the key, query and value matrices for each attention head which helps in generating an output matrix from each head.
- Concatenate and Transform: Concatenate the output matrices from all attention heads and apply a dot product with weight W_{O} to generate the final output of the multi-headed attention layer.
Mathematically multi-head attention can be represented by:
MultiHead\left ( Q, K, V \right ) = concat\left ( head_{1} head_{2} ... head_{n} \right )W_{O}
Why Multi-Headed Attention?
- Captures Different Aspects: Each attention head focuses on a different part of the sequence which allows the model to capture a variety of relationships between words.
- Parallel Processing: It helps in parallel computation of attention for different heads which speeds up the training process.
- Improved Performance: By combining the results from multiple heads the model becomes more efficient and flexible in understanding complex relationships within the input data.
- Encoder-Decoder Attention: In this layer, queries come from the previous decoder layer while the keys and values come from the encoder’s output. This allows each position in the decoder to focus on all positions in the input sequence.
- Encoder Self-Attention: This layer receives queries, keys and values from the output of the previous encoder layer. Each position in the encoder looks at all positions from the previous layer to calculate attention scores.

- Decoder Self-Attention: Similar to the encoder's self-attention but here the queries, keys and values come from the previous decoder layer. Each position can attend to the current and previous positions but future positions are masked (with (-Inf)) to prevent the model from looking ahead when generating the output and this is called masked self-attention.

Advantages of Self-Attention
- Parallelization: Unlike sequential models it allows for full parallel processing which speeds up training.
- Long-Range Dependencies: It provides direct access to distant elements making it easier to model complex structures and relationships across long sequences.
- Contextual Understanding: Each token’s representation is influenced by the entire sequence which integrates global context and improves accuracy.
- Interpretable Weights: Attention maps can show which parts of the input were most influential in making decisions.
Key challenges of Self-attention
Despite having many advantages, it also lacks in few way which are as follows:
- Computational Cost: Self-attention requires computing pairwise interactions between all input tokens which causes a time and memory complexity of O(n^2), where n is the sequence length. This becomes inefficient for long sequences.
- Memory Usage: Large number of pairwise calculations in self-attention uses high memory while working with very long sequences or large batch sizes.
- Lack of Local Context: It focuses on global dependencies across all tokens but it may not effectively capture local patterns. This can cause inefficiencies when local context is more important than global context.
- Overfitting: Due to its ability to model complex relationships it can overfit when it is trained on small datasets.
As machine learning continues to grow the exploration of attention mechanisms is opening up new opportunities and changing the way models understand and process complex data.
Similar Reads
Self - attention in NLP Self-attention is a technique used in NLP that helps models to understand relationships between words or entities in a sentence, no matter where they appear. It is a important part of transformers model which is used in tasks like translation and text generation.Understanding Attention in NLPThe goa
7 min read
Self -attention in NLP Self-attention was proposed by researchers at Google Research and Google Brain. It was proposed due to challenges faced by encoder-decoder in dealing with long sequences. The authors also provide two variants of attention and transformer architecture. This transformer architecture generates the stat
5 min read
Attention Layers in TensorFlow Attention Mechanism allows models to focus on specific parts of input data, enabling more effective processing and prediction. In this article, we'll explore what attention layers are, and how to implement them in TensorFlow.What is Attention in Deep Learning?Attention mechanisms in neural networks
3 min read
Transformer Attention Mechanism in NLP Transformer model is a type of neural network architecture designed to handle sequential data primarily for tasks such as language translation, text generation and many more. Unlike traditional recurrent neural networks (RNNs) or convolutional neural networks (CNNs), Transformers uses attention mech
7 min read
Bidirectional RNNs in NLP The state of a recurrent network at a given time unit only knows about the inputs that have passed before it up to that point in the sentence; it is unaware of the states that will come after that. With knowledge of both past and future situations, the outcomes are significantly enhanced in some app
10 min read
How Do Self-attention Masks Work? Self-attention mechanism enables each word or token in a sequence to focus on other relevant words or tokens within the same sequence, allowing for relationships between elements to be dynamic and context-dependent.For example, in the sentence "The cat sat on the mat", the word "sat" has to notice "
6 min read