Network Programming: Data Plane Development Kit (DPDK)
8 likes2,808 views

The document outlines the architecture and implementation of high-performance networking using Data Plane Development Kit (DPDK), emphasizing efficient packet processing and management. It discusses networking protocols, memory management, and the benefits of user space libraries for reducing latency in packet handling. Additionally, it explains the operational mechanics of data planes, including mechanisms for packet reception and transmission in a multi-core environment.
















![Fitting Into 249 Cycles: Bursts
Process few packets at a time (a burst), not one-by-one:
1. Amortize slow memory reads per burst
2. Increase cache hit ratio: do the same for few packets at once
void lcore_loop()
{
struct rte_mbuf *burst[32];
while (1) {
nb_rx = rte_eth_rx_burst(0, 0, burst, 32);
...
rte_eth_tx_burst(1, 0, burst, nb_rx);
}
}
17
Pros/cons?](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/85/Network-Programming-Data-Plane-Development-Kit-DPDK-17-320.jpg)










![DPDK
Kernel
So, Let’s Make a Simple Hub!
28
void lcore_loop()
{
struct rte_mbuf *burst[32];
uint16_t id = rte_lcore_id();
while (1) {
nb_rx = rte_eth_rx_burst(0, id, burst, 32);
rte_eth_tx_burst(1, id, burst, nb_rx);
nb_rx = rte_eth_rx_burst(1, id, burst, 32);
rte_eth_tx_burst(0, id, burst, nb_rx);
}
}
PMD
App
PMD
while (1) {
rx(...); tx(...);
}
mmap()](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/85/Network-Programming-Data-Plane-Development-Kit-DPDK-28-320.jpg)


![DPDK Command Line Arguments
31
1. Number of workers:
-c COREMASK, i.e. -c 0xf
better: -l CORELIST, i.e. -l 0-3
best: --lcores COREMAP, i.e. --lcores 0-3@0
2. Number of memory channels (optional):
-n NUM, i.e. -n 4
3. Allocate memory using hugepages (optional):
-m MB, i.e. -m 512
--socket-mem SOCKET_MB,SOCKET_MB,..., i.e. --socket-mem 384,128
4. Add virtual devices (optional):
--vdev <driver><id>[,key=val, ...], i.e. --vdev net_pcap0,iface=eth0
More command-line options: http://dpdk.org/doc/guides/testpmd_app_ug/run_app.html](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/85/Network-Programming-Data-Plane-Development-Kit-DPDK-31-320.jpg)
![DPDK Main Loop
1. Receive burst of packets:
nb_rx = rte_eth_rx_burst(port_id, queue_id, burst, BURST_SZ);
2. Process packets (app logic)
3. Send burst of packets:
nb_tx = rte_eth_tx_burst(port_id, queue_id, burst, nb_rx);
4. Free unsent buffers:
for (; nb_tx < nb_rx; nb_tx++)
rte_pktmbuf_free(burst[nb_tx]);
32](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/85/Network-Programming-Data-Plane-Development-Kit-DPDK-32-320.jpg)

















![Cuckoo Hash Structures
50
B
Bucket
Numberofbuckets
Bucket entries
S
Ki
A
Key signatures []
Entry
K
Key indexes []
Alt. signatures []
Numberofslots
D
KeyData
Ring of free
slots](https://image.slidesharecdn.com/networkprogrammingdpdk-180621090830/85/Network-Programming-Data-Plane-Development-Kit-DPDK-50-320.jpg)














Network Programming: Data Plane Development Kit (DPDK)
- 1. Andriy Berestovskyy 2014 ( ц ) А н д р і й Б е р е с т о в с ь к и й networking hourTCP UDP NAT IPsec IPv4 IPv6 internet protocolsAH ESP authentication authorization accounting encapsulation security BGP OSPF ICMP ACLSNAT tunnelPPPoE GRE ARP discovery NDP OSI broadcast multicast IGMP PIM MAC DHCP DNS fragmentation semihalf berestovskyy Network Programming Data Plane Development Kit
- 2. Network Programming Series ● Berkeley Sockets ● > Data Plane Development Kit (DPDK) ● Open Data Plane (ODP) 2
- 3. Let’s Make a 10Gbit/s Switch! 3 1. Receive frame, check Ethernet FCS 2. Add/update source MAC in MAC table 3. If multicast bit is set: a. forward all ports, but the source 4. If destination is in MAC table: a. forward to the specific port 5. Else, forward to all ports
- 4. Let’s Make a Switch Simple Hub! 4 1. Receive frame, check Ethernet FCS 2. Add/update source MAC in MAC table 3. If multicast bit is set: a. forward all ports, but the source 4. If destination is in MAC table: a. forward to the specific port 5. Else, forward to another port But still, 10 Gbit/s!
- 5. Recap: Ethernet Frame Format 5Source: https://en.wikipedia.org/wiki/Ethernet_frame Ethernet Frame Bits 2 1 7 Preamble, 7 octets Start of Frame, 1 octet 6 Destination MAC, 6 octets 6 Source MAC, 6 octets 4 Optional 802.1q (VLAN) Tag, 4 octets Ethertype, 2 octets 46-1500 4 Frame Check Sequence, 4 octets 12 Interframe gap, 12 octetsPayload, 46-1500 octets 72 — 1530 octets 64 — 1522 octets TrailerHeader
- 6. Performance Challenges Minimum Ethernet Frame Size: min frame size = preamble + start + min frame + interframe gap min frame size = 7 + 1 + 64 + 12 = 84 octets (84 * 8 = 672 bits) Maximum number of frames on 1 Gbps link: packets per second = 1 Gbps / 672 bits = 1 488 095 pps Maximum number of frames on 10 Gbps link: packets per second = 10 Gbps / 672 bits =14,88 Mpps 6
- 7. Ethernet vs CPU 7 Skylake Intel® Xeon® Processor E3-1280 v5 — 3,7 GHz CPU budget per packet = CPU Freq / Packet Per Second CPU budget per packet = 3,7 GHz / 14,88 Mpps = 249 cycles 249 CPU cycles per packet Is it a lot?
- 8. Recap: Xeon Memory Hierarchy 8 Xeon Package Core Core Registers 32 KB L1 / ~4 cycles 256 KB L2 / ~10 cycles 36 MB LLC / ~30 cycles 32 KB L1 / ~4 cycles 256 KB L2 / ~10 cycles Registers Up to 1.5 TB DDR4 / ~200 cycles / 60 GB/s Source: http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-optimization-manual.pdf
- 9. Ethernet vs Memory 9 249 cycles per packet is: 249 cycles / 4 cycles = 62 L1 cache reads 249 cycles / 10 cycles = 24 L2 cache reads 249 cycles / 30 cycles = 8 L3 cache reads 249 cycles / 200 cycles = 1 DDR4 read :(
- 10. What is Wrong With Kernel? 1. Interrupts 2. Context switches 3. User-kernel space data copying 4. Kernel development is not easy 10
- 11. Solution? 11
- 12. Data Plane Development Kit — set of user space dataplane libraries and NIC drivers for fast packet processing — Wikipedia 12 Dataplane?
- 13. Dataplane — part of architecture that decides what to do with packets arriving on an inbound interface — Wikipedia 13
- 14. What is DPDK 1. Set of user space libraries 2. Set of user space drivers with direct NIC access 3. Support for Network Functions Virtualization 4. Open source, BSD Licensed 14 How?
- 15. What DPDK is Not 1. Not a TCP/IP stack 2. Not a Berkeley socket API 3. Not a ready to use solution, i.e. neither a router nor a switch 15
- 16. Fitting Into 249 Cycles: Polling Poll for new packets, do not wait for an interrupt: 1. Interrupts are out of the budget 2. Avoid context switches void lcore_loop() { while (1) { ... } } 16 Pros/cons?
- 17. Fitting Into 249 Cycles: Bursts Process few packets at a time (a burst), not one-by-one: 1. Amortize slow memory reads per burst 2. Increase cache hit ratio: do the same for few packets at once void lcore_loop() { struct rte_mbuf *burst[32]; while (1) { nb_rx = rte_eth_rx_burst(0, 0, burst, 32); ... rte_eth_tx_burst(1, 0, burst, nb_rx); } } 17 Pros/cons?
- 18. Fitting Into 249 Cycles: Hugepages Virtual-Physical address translation — Translation Lookaside Buffer: 1. Haswell First Level DTLB Cache for 4K pages: 64 entries x 4 (~4 cycles) 2. Haswell Second Level DTLB Cache: 1024 entries x 8 (~10 cycles) Use 2MB or 1GB hugepages to reduce TLB cache misses: GRUB_CMDLINE_LINUX_DEFAULT=”... default_hugepagesz=1G hugepagesz=1G hugepages=4” # mount -t hugetlbfs nodev /mnt/huge 18More on system requirements: http://dpdk.org/doc/guides/linux_gsg/sys_reqs.html
- 19. Fitting Into 249 Cycles: Multicore Use few CPU cores to process packets: 1. Use Receive Side Scaling 2. Use Flow affinity void main() { ... rte_eal_mp_remote_launch(lcore_loop, ...); ... } 19 Pros/cons? CPU 1: lcore_loop() CPU 2: lcore_loop() CPU 3: lcore_loop() port port
- 20. Why DPDK? 1. High performance ○ efficient memory-management (zero-copy, hugepages, user space) ○ efficient packet handling (DIR-24-8 implementation, cuckoo hash) ○ efficient CPU management (lockless poll-mode drivers, run-to-completion, NUMA awarness) 2. Simple ○ user space application ○ many examples 3. De-facto standard for dataplanes in Linux 20
- 21. Pipeline Model lcore 3: TX lcore 2: process Run-to-Completion Model lcore 1: RX, process, TX lcore 2: RX, process, TX lcore 3: RX, process, TX Dataplane Application Models 21 port port lcore 1: RX port port Cons/pros? lcore?
- 22. Lcore — logical execution unit of the processor, sometimes called a hardware thread (usually, pthread bound to a CPU core) — Wikipedia 22
- 23. Pipeline Model lcore 3: TX lcore 2: process Run-to-Completion Model lcore 1: RX, process, TX lcore 2: RX, process, TX lcore 3: RX, process, TX Synchronization Issues 23 port port lcore 1: RX port port How? How?
- 24. Run-to-Completion Model port q2 lcore 1: RX, process, TX lcore 2: RX, process, TX lcore 3: RX, process, TX Run-to-Completion Synchronization 24 port q1 q3 q2 q1 q3 Hardware queue Cons/pros?
- 25. RSS* and Flow Affinity 25 q2 lcore 1: RX, process, TX lcore 2: RX, process, TX lcore 3: RX, process, TX q1 q3 q2 q1 q3 Why? port port * Receive Side Scaling
- 26. Pipeline Model Synchronization 26 Pipeline Model lcore 3: TX lcore 2: process lcore 1: RX port q1 portq1 Software queue Cons/pros?
- 27. DPDK Overview 27 User space Kernel Hardware NICNIC NIC igb_uio (~700 lines) or vfio-pci or uio_pci_generic DPDK lcore 3 Classification and Scheduling Linux/FreeBSD App App Poll Mode Drivers Hashing and Forwarding CPU and Memory Management NIC QEMU (VM) eth0 ixgbe lcore 2 lcore 1 tap0 log vEth0KNI Driver PCAP Driver rte_kni Virtio Virtio Shared Memory TUN/TAP
- 28. DPDK Kernel So, Let’s Make a Simple Hub! 28 void lcore_loop() { struct rte_mbuf *burst[32]; uint16_t id = rte_lcore_id(); while (1) { nb_rx = rte_eth_rx_burst(0, id, burst, 32); rte_eth_tx_burst(1, id, burst, nb_rx); nb_rx = rte_eth_rx_burst(1, id, burst, 32); rte_eth_tx_burst(0, id, burst, nb_rx); } } PMD App PMD while (1) { rx(...); tx(...); } mmap()
- 29. DPDK Libraries Overview 29 rte_malloc Hugepage-based heap rte_eal Environment Abstraction Layer: hugepages, CPU, PCI, logs, debugs ... rte_ring Lockless queue Multi/single consumer/producer rte_mempool Fixed-sized objects Uses rings to keep free objects rte_mbuf Memory buffer Uses mempools as a storage rte_cmdline Command line interface rte_ether Generic PMD API rte_hash Hash library rte_kni Kernel NIC interface rte_meter + rte_sched QoS classifier and scheduler rte_pmd_* Poll Mode Drivers rte_timer Timers management Why? rte_lpm Longest prefix match (DIR-24-8) rte_net IP-related (ARP, IP, TCP, UDP...)
- 30. DPDK Application Initialization 1. Init Environment Abstraction Layer (EAL): rte_eal_init(argc, argv); 2. Allocate mempools: rte_pktmbuf_pool_create(name, n, cache_sz, …); 3. Configure ports: rte_eth_dev_configure(port_id, nb_rx_q, nb_tx_q, …); 4. Configure queues: rte_eth_*_queue_setup(port_id, queue_id, nb_desc, …); 5. Launch workers (lcores): rte_eal_mp_remote_launch(lcore_loop, …); 30 Arguments?
- 31. DPDK Command Line Arguments 31 1. Number of workers: -c COREMASK, i.e. -c 0xf better: -l CORELIST, i.e. -l 0-3 best: --lcores COREMAP, i.e. --lcores 0-3@0 2. Number of memory channels (optional): -n NUM, i.e. -n 4 3. Allocate memory using hugepages (optional): -m MB, i.e. -m 512 --socket-mem SOCKET_MB,SOCKET_MB,..., i.e. --socket-mem 384,128 4. Add virtual devices (optional): --vdev <driver><id>[,key=val, ...], i.e. --vdev net_pcap0,iface=eth0 More command-line options: http://dpdk.org/doc/guides/testpmd_app_ug/run_app.html
- 32. DPDK Main Loop 1. Receive burst of packets: nb_rx = rte_eth_rx_burst(port_id, queue_id, burst, BURST_SZ); 2. Process packets (app logic) 3. Send burst of packets: nb_tx = rte_eth_tx_burst(port_id, queue_id, burst, nb_rx); 4. Free unsent buffers: for (; nb_tx < nb_rx; nb_tx++) rte_pktmbuf_free(burst[nb_tx]); 32
- 33. DPDK CPU Management 33 Master lcore int main() { rte_eal_mp_remote_launch(m_loop, ...); lcore 1 void m_loop() { while (!stop) { rx_burst(); ... tx_burst(); } } lcore 2 void m_loop() { while (!stop) { rx_burst(); ... tx_burst(); } } void signal_handler(int signum) { if (SIGINT == signum) stop = 1; } rte_eal_init(argc, argv); wait wait rte_eal_mp_wait_lcore() wait wait Allocate mempools, configure ports...
- 34. rte_memzone_reserve(name, len, socket, size) rte_mempool_create(name, n, elt_size, ...) DPDK Memory Management 34 phys. memory: hugepages memory zones: mempool zonering zone heap zonefree rte_pktmbuf: rte_mempool: free◌ free mbufs mbufmbuf free mbuf mbuf mbuf privatefree headroom tailroomdata next rte_pktmbuf_alloc(mempool) priv free
- 35. Memory Management Libraries 35 rte_eal Hugepages management rte_memzone_reserve(name, len, socket) rte_malloc Hugepage-based heap rte_malloc(type, size, align) rte_free(ptr) rte_ring Lockless queue rte_ring_create(name,count,socket,flags) rte_ring_dequeue_bulk(r, table,n) rte_mempool Fixed-sized objects rte_mempool_create(name, n, elt_size, ...) rte_mempool_get_bulk(pool, table, n) rte_mbuf Memory buffers rte_pktmbuf_alloc(mempool) *_bulk(N): N objects or nothing *_burst(N): 0-N objects
- 36. 1. Lockless 2. Fixed size queue of pointers 3. Bulk/burst enqueue/dequeue operations DPDK Lockless Queue 36 Lockless? consumer Why head/tail? producer cons.head cons.tail rte_ring: ptr1 ptr2 ptr3free free free prod.head prod.tail ptr2 ptr1 ptr3
- 37. Non-blocking Algorithms Blocking — sequential access, other threads are blocked: mutex, semaphore Non-blocking — sequential access, other threads busy wait: spinlocks Lock-free — concurrent access, unpredictable number of retries: consistency markers Wait-free — concurrent access, predictable number of steps 37 Markers?
- 38. cons.head cons.tail lcore 2 lcore 1 Enqueue Lock-Free Algorithm 38 rte_ring: ptr1 ptr2 free free free free next Step 1 1. head = prod.head 2. next = head + N head nexthead prod.head prod.tail cons.head cons.tail lcore 2 lcore 1 rte_ring: ptr1 ptr2 free free free free next Step 2 1. CAS(prod.head, head, next) 2. if (failed) goto Step 1 head nexthead prod.tail prod.head Predictable?
- 39. 1. Uses memory zones to store pointers 2. rte_ring_dequeue_* to consume pointers 3. rte_ring_enqueue_* to produce pointers DPDK rte_ring Library 39 rte_eal Hugepages management rte_memzone_reserve(name, len, socket) rte_ring Lockless queue rte_ring_create(name,count,socket,flags) rte_ring_dequeue_bulk(r, table,n) *_bulk(N): N objects or nothing *_burst(N): 0-N objects
- 40. lcore 1 rte_mempool_create(name, n, elt_size, ...) memory zones: mempool zonering zone heap zonefree rte_mempool: free◌ free mbufs mbufmbuf free mbuf mbuf mbuf privatefree DPDK Memory Pools 40 1. Allocator of fixed-sized objects 2. Uses ring to store free objects 3. High-performance RX ringTX ring
- 41. DPDK rte_mempool Library 41 rte_eal Hugepages management rte_memzone_reserve(name, len, socket) rte_ring Lockless queue rte_ring_create(name,count,socket,flags) rte_ring_dequeue_bulk(r, table,n) rte_mempool Fixed-sized objects rte_mempool_create(name, n, elt_size, ...) rte_mempool_get_bulk(pool, table, n) 1. Uses ring as a queue of free objects 2. rte_mempool_get_* to allocate objects 3. rte_mempool_put_* to free objects 4. Optional per-lcore cache *_bulk(N): N objects or nothing *_burst(N): 0-N objects Why?
- 42. DPDK Memory Buffer 42 rte_pktmbuf: rte_mempool: free◌ free mbufs mbufmbuf free mbuf mbuf mbuf privatefree headroom tailroomdata next or NULL next rte_pktmbuf_alloc(mempool) priv 1. Fixed-size buffers 2. Chained buffers support 3. Indirect buffers support Why?Why?
- 43. Chained Memory Buffers 43 mbuf mbuf mbuf mbuf next next next NULL 1. For jumbo frames 2. To append/prepend more than head/tailroom
- 44. Indirect Memory Buffers 44 1. For fast packet “cloning” 2. For broadcasts/multicasts rte_pktmbuf: headroom tailroomdatapriv rte_pktmbuf: buf_addr refcnt 2 buf_addr flags |= ATTACHED
- 45. DPDK rte_hash Library 45 1. Array of buckets 2. Fixed number of entries per bucket 3. No data, key management only 4. 4-byte key signatures Why? Why? keyskeysrte_hash free sigfree free sig sig sig free sigsigfree int. key array free keyfree free key key key free keykeyfree index data Data?
- 47. 47 Cuckoo hashing — scheme for resolving hash collisions with worst-case constant lookup time — Wikipedia Collision?
- 48. Cuckoo Hashing Algorithm 48 AA A B B 1 2 3a A B A C 3b C B A C no collision primary hash collision - use alt. location both hashes collision - push hash to alt. location add hash to a vacant space Double addressing Cuckoo
- 49. Why Cuckoo Hashing? 49 ● Fast ● Constant lookup time ● High load factor (~90%)
- 50. Cuckoo Hash Structures 50 B Bucket Numberofbuckets Bucket entries S Ki A Key signatures [] Entry K Key indexes [] Alt. signatures [] Numberofslots D KeyData Ring of free slots
- 51. 51 DPDK Longest Prefix Match: Why?
- 52. Recap: IP Routing 52 WAN LAN2LAN1 IP: 2.2.2.2 IP: 1.1.1.1 R1 R2 1 By default, send to R1 All 1.*.*.*, send to R2 3 All 1.*.*.*, send locally 2
- 53. Recap: IP Flexible Subnetting 53 3.2.5100. Subnet Host Service Provider (AS100) Subnet 100.0.0.0 Company 3 Subnet 100.3.0.0 Office 100.3.1.0 Lab 100.3.2.0 2.5100.3. 5100.3.2. 100.3.2.5 How? Route to: AS100 Route to: AS100, Company 3 Route to: AS100, Company 3, Lab Deliver to: AS100, Company 3, Lab, Host 5 AS200
- 54. Recap: Router Logic 54 Service Provider Subnet 100.0.0.0 Company 3 Subnet 100.3.0.0 Lab 100.3.2.0 1. Receive IP packet: ○ Check Ethernet FCS ○ Remove Ethernet header 2. Decrease TTL 3. Find the best route in routing table: ○ Most specific route is the best 4. If found, send to next-hop router: ○ Destination MAC = next-hop gateway IP 5. Else, drop the packet Lab Router Routing Table: 100.3.2.* —> dev eth1 (Lab), directly *.*.*.* —> dev eth0 (Company 3), via 100.3.0.1 (Company 3 Router)
- 55. Recap: IPv4 Subnet Mask 55 32-bit Number 0110 0100 0000 0011 0000 0010 0000 0101 100. 3. 2. 5 IPv4 Address IPv4 Address in Dotted Decimal Notation 1111 1111 1111 1111 1111 1111 0000 0000 255. 255. 255. 0 IPv4 Subnet Mask Subnet Mask in Dotted Decimal Notation & 0110 0100 0000 0011 0000 0010 0000 0000 100. 3. 2. 0 IPv4 Subnet Subnet in Dotted Decimal Notation
- 56. Recap: IPv4 Subnet Mask Length 56 Subnet Mask Length = 24 1111 1111 1111 1111 1111 1111 0000 0000 255. 255. 255. 0 IPv4 Subnet Mask Subnet Mask in Dotted Decimal Notation Dotted Decimal Notation: IPv4 Address: 100.3.2.5 Subnet Mask: 255.255.255.0 CIDR* Notation: IPv4 Prefix: 100.3.2.5/24 == * Classless Inter-Domain Routing
- 57. Longest Prefix Match (LPM) Example routing table: 0.0.0.0/0 -> R1 10.0.0.0/8 -> R2 10.10.0.0/16 -> R3 Destination address 10.10.0.1 matches all three routes. Which route to use? 57
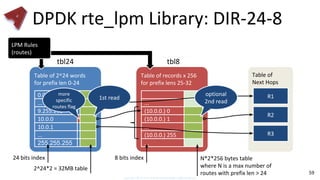
- 58. DPDK rte_lpm Library IPv4: 1. 32-bit keys 2. Fixed maximum number of rules 3. LPM rule: 32-bit key + prefix len + user data (next hop) 4. DIR-24-8 algorithm (1-2 memory reads per match) IPv6: 1. 128-bit keys 2. Similar algorithm: 24 bit + 13 x 8 bit tables = 1-14 memory reads (typically 5) 58 How?
- 59. DPDK rte_lpm Library: DIR-24-8 59 Table of Next Hops R1 Table of 2^24 words for prefix len 0-24 0.0.0 Table of records x 256 for prefix lens 25-32 ... R2 9.255.255 10.0.0 10.0.1 ... 255.255.255 R3 ... (10.0.0.) 0 (10.0.0.) 1 ... (10.0.0.) 255 ... 2^24*2 = 32MB table N*2*256 bytes table where N is a max number of routes with prefix len > 24 tbl24 tbl8 24 bits index 8 bits index more specific routes flag LPM Rules (routes) 1st read optional 2nd read
- 60. DPDK Poll Mode Drivers 1. Lock-free —> thread unsafe 2. Based on user space IO (uio) 3. Limited number of NICs 4. Any interface via PCAP (slow) 60
- 61. DPDK Kernel NIC Interface 61 User space Kernel Hardware NIC igb_uio DPDK lcore 2 Linux/FreeBSD ping Poll Mode Drivers lcore 1 vEth0KNI Driver rte_kni 1. Allows user space applications to access Linux control plane 2. Allows management of DPDK ports using Linux tools 3. Interface with the kernel network stack
- 62. DPDK Thread Safety 1. Thread unsafe: all performance sensitive functions hash, LPM, PMD... 2. Multi-threaded: performance insensitive malloc, memzone... 3. Fast and thread safe: rings (lockless queues) and mempools 62
- 63. DPDK Performance Tips 1. Never use libc nor Linux API malloc -> rte_malloc printf -> RTE_LOG 2. Avoid cache misses / false sharing by using per lcore variables Example: port statistics 3. Use NUMA sockets to allocate local memory 4. Use rings to inter-core communication 5. Use burst mode in PMDs 6. Help branch predictor: use likely()/unlikely() 7. Prefetch data into cache with rte_prefetchX() 63 Why? False sharing?
- 64. DPDK Checklist 1. What is DPDK? 2. Performance challenges? 3. DPDK application command line options? 4. Application models? 5. Flow affinity? 6. Lockless queue? 7. Indirect buffers? 8. Cuckoo hash? 9. Longest Prefix match? 10. KNI? 11. Performance tips? 64
- 65. References 1. DPDK Programmer’s Guide: http://dpdk.org/doc/guides/prog_guide/ 2. Alex Kogan, Erez Petrank. Wait-Free Queues With Multiple Enqueuers and Dequeuers, 2011 3. Michael, Scott. Simple, fast and practical non-blocking and blocking concurrent queue algorithms, 1996. 65