Kafka Summit NYC 2017 - Running Hundreds of Kafka Clusters with 5 People
1 like1,658 views

Tom Crayford discusses his experience running hundreds of Apache Kafka clusters on Heroku with a small team. Some key points discussed include: - Using automation to manage clusters and reduce manual work required - Common issues encountered like disk growth from log compaction bugs and addressing them by scanning clusters for anomalies - Kafka's built-in high availability and how it helped during an AWS EBS failure event - Novel failure cases encountered like a JVM memory leak from gzip usage and working to fix it - Importance of taking breaks and not wasting time when operating clusters at scale.









































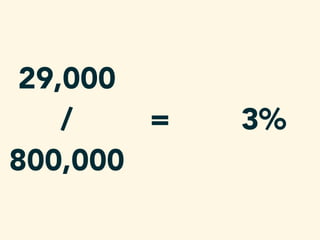


















































![at=LogCleaner [kafka-log-cleaner-thread-0], Error
due to java.lang.IllegalArgumentException:
requirement failed: 9750860 messages in segment
MY_FAVORITE_TOPIC-2/00000000000047580165.lo
g but offset map can fit only 5033164. You can
increase log.cleaner.dedupe.buffer.size or decrease
log.cleaner.threads](https://image.slidesharecdn.com/thomascrayfordherokukafka-summit-may-201711-170524205931/85/Kafka-Summit-NYC-2017-Running-Hundreds-of-Kafka-Clusters-with-5-People-93-320.jpg)








































































































































































































































Ad
More Related Content
What's hot (20)
Viewers also liked (11)









Ad
Similar to Kafka Summit NYC 2017 - Running Hundreds of Kafka Clusters with 5 People (20)


![[CCC-28c3] Post Memory Corruption Memory Analysis](https://cdn.slidesharecdn.com/ss_thumbnails/28c3-120107122834-phpapp02-thumbnail.jpg?width=560&fit=bounds)


![[HITB Malaysia 2011] Exploit Automation](https://cdn.slidesharecdn.com/ss_thumbnails/brossardhitb2011-111127232630-phpapp02-thumbnail.jpg?width=560&fit=bounds)





![[Kiwicon 2011] Post Memory Corruption Memory Analysis](https://cdn.slidesharecdn.com/ss_thumbnails/kiwiconbrossard-111127232850-phpapp01-thumbnail.jpg?width=560&fit=bounds)


![[Ruxcon 2011] Post Memory Corruption Memory Analysis](https://cdn.slidesharecdn.com/ss_thumbnails/ruxcon-111127233040-phpapp02-thumbnail.jpg?width=560&fit=bounds)





Ad
More from confluent (20)




















Recently uploaded (20)










![Pixologic ZBrush Crack Plus Activation Key [Latest 2025] New Version](https://cdn.slidesharecdn.com/ss_thumbnails/fashionevolution2-250322112409-f76abaa7-250428124909-b51264ff-250504160528-fc2bb1c5-thumbnail.jpg?width=560&fit=bounds)

![Download Wondershare Filmora Crack [2025] With Latest](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-howkgsareshapingthefutureofgenerativeaiatawssummitlondonapril2024-240426125209-2d9db05d-250419-250428115407-a04afffa-thumbnail.jpg?width=560&fit=bounds)







Kafka Summit NYC 2017 - Running Hundreds of Kafka Clusters with 5 People
- 2. apache kafka is great software
- 3. but it isn't perfect
- 5. hundreds of clusters with 5 people
- 6. Tom Crayford
- 11. Kafka as a Service
- 13. KAFKA_URL
- 15. provide and enforce best practices
- 16. RF >= 3
- 17. not safe in AWS without that!
- 19. automation
- 21. heroku kafka:upgrade --version 0.10.2.1
- 22. we take care of your cluster
- 24. use it how you like
- 25. we wear the pager
- 26. about us
- 27. heroku data
- 28. postgres
- 29. postgres redis
- 31. A U T O M A T I O N
- 35. 46 pages a day
- 36. pager storms
- 39. 29,000
- 40. 29,000 /
- 41. 29,000 / 800,000
- 43. 97%
- 45. 3%
- 46. 3%
- 47. 3%
- 48. 3%
- 49. A U T O M A T I O N
- 50. what you are going to learn
- 52. how to talk about 2 years of work?
- 53. how to talk about 10 years of work?
- 54. Incidents
- 58. Incident 1 lessons Incident 2 lessons Incident 3 lessons
- 59. why does this broker have 8TB of disk?
- 60. 🆒
- 61. context
- 64. you do what you want
- 67. disk growth
- 69. lvm array
- 70. why does this broker have 8TB of disk?
- 71. RULE 1
- 72. scan the fleet
- 73. YOU HAVE TO SCAN THE FLEET
- 74. "why do several of our clusters have very large on disk size?"
- 75. 🆒
- 76. pick a cluster
- 77. grab a shovel
- 78. nearly all the data in one topic
- 79. high volume?
- 80. not enough…
- 81. what else is different
- 82. compaction!
- 83. to the JIRA mine!
- 84. KAFKA-3587
- 87. welp
- 88. can't find anything in JIRA!
- 89. ok!
- 90. back to the shovel
- 91. time to look at logs
- 92. eventually
- 93. at=LogCleaner [kafka-log-cleaner-thread-0], Error due to java.lang.IllegalArgumentException: requirement failed: 9750860 messages in segment MY_FAVORITE_TOPIC-2/00000000000047580165.lo g but offset map can fit only 5033164. You can increase log.cleaner.dedupe.buffer.size or decrease log.cleaner.threads
- 94. some gold!
- 95. grep the code for the error
- 96. uhoh!
- 97. this exception…
- 98. this exception… kills the thread
- 99. this thread can die without any monitoring data
- 101. but compaction
- 102. "infinite disk, but"
- 103. scan the fleet
- 104. JMX thread dumps
- 105. dozens of brokers with log cleaner thread missing
- 106. 🆒
- 107. ok!
- 108. time to fix
- 109. first, the shovel
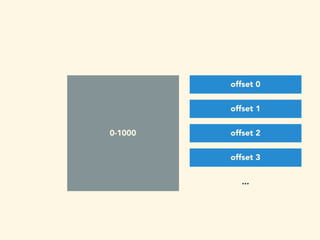
- 113. 0-1000 offset 0 offset 1 offset 2 offset 3 ...
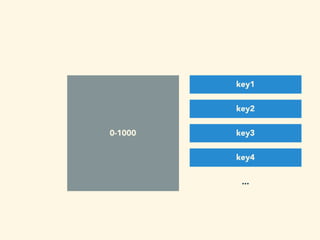
- 115. 0-1000 offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key4 ...
- 116. 0-1000 offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 ...
- 117. 0-1000 offset 1 key2 offset 2 key3 offset 3 key1 ...
- 120. offset map {}
- 121. {} offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1
- 122. {} offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1
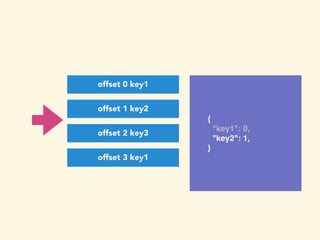
- 123. { "key1": 0, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1
- 124. { "key1": 0, "key2": 1, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1
- 125. { "key1": 0, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1
- 126. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1
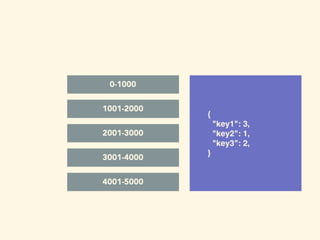
- 127. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 128. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 129. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 130. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 131. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 132. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 133. { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 134. latest offset: 3 { "key1": 3, "key2": 1, "key3": 2, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 0-1000 1001-2000 2001-3000 3001-4000 4001-5000
- 135. what was the bug?
- 136. assumption: "fit the whole segment in the map"
- 137. the fix
- 138. { "key1": 0, "key2": 1, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1
- 139. { "key1": 0, "key2": 1, } offset 0 key1 offset 1 key2 offset 2 key3 offset 3 key1 latest offset: 1
- 143. Lessons
- 144. scan the fleet
- 146. 1. Impact
- 148. 1. Impact 2. Mitigate 3. Fix
- 149. 1. Impact 2. Mitigate 3. Fix 4. Follow up
- 150. apache kafka is great software
- 151. but it isn't perfect
- 152. A U T O M A T I O N
- 153. you can fix things
- 154. (I don't know scala)
- 155. you can fix things
- 156. takeways scan the fleet 4 steps A U T O M A T I O N you can fix things
- 157. EBS
- 158. start getting paged by a bunch of postgres/redis failing health checks in a single AZ
- 159. hundreds of pages
- 160. grab a shovel
- 161. ok, EBS degradation
- 162. seen this in the past
- 164. but… why isn't kafka impacted?
- 166. false!
- 167. found several kafka nodes had been automatically replaced!
- 168. can you spell
- 169. A U T O M A T I O N
- 170. HANDLING FAILURE
- 171. health checks
- 172. kafka does much of the work
- 174. our job: make the cluster fully healthy again
- 175. two kinds of failures:
- 177. continues to fail
- 178. "hello, automation, have you tried turning it off and on again?"
- 179. that 3% number?
- 180. mostly turning shit off and back on again
- 181. replace the node
- 183. "hello, automation, have you tried turning it off and on again?"
- 184. automation saved us
- 185. wooo
- 186. LESSONS
- 187. everything worked?
- 188. kafka's HA
- 190. what can we do better?
- 199. one thing at a time
- 200. takeways kafka's HA A U T O M A T I O N safe automation
- 201. 3am
- 202. broker won't restart
- 203. at all
- 204. well, kafka is HA enough, and this cluster has 8 brokers
- 205. back to sleep!
- 206. next day:
- 207. not a 3am ops monkey
- 208. coffee breakfast
- 209. can't scan the fleet yet, don't know what we're looking for
- 210. grab a shovel
- 211. in kafka's logs:
- 213. happens within 20s of broker boot
- 214. syslog though…
- 215. There is insufficient memory for the Java Runtime Environment to continue.
- 216. 🆒
- 217. scan the fleet
- 218. only this cluster has seen this error
- 219. not about to restart other things!
- 221. but first, fix the cluster
- 222. happens to be an internal cluster
- 225. talk to internal team
- 226. replaced the node
- 227. time for that shovel
- 229. query memory using jmx in a tight loop during boot
- 230. ♥ JMX exposure starts *super* early
- 231. uhh, max of 63.2MB
- 233. on heap vs off heap
- 234. off heap :(
- 236. use sysdig to look at mmap calls
- 237. no notable patterns
- 238. time for a walk
- 239. periodic reminder: you are human
- 240. periodic reminder: you are human so is your team
- 241. help your brain out
- 242. hunch!
- 243. this cluster switched to gzip recently
- 244. gzip might allocate native memory…
- 245. let me google that for you
- 249. "This shows that 94% of the "live" blocks were allocated by Java_java_util_zip_Deflater_init and deflatInit2 (part of zlib)"
- 250. search jira: nothing
- 251. file KAFKA-3933
- 252. fix it!
- 253. time to look at the source
- 254. you can grep!
- 256. follow the chain to
- 258. how is this used during startup?
- 259. we have that log message from before…
- 261. ok, it comes from Log
- 262. LogSegment. recover
- 263. // we need to decompress the message, if required, to get the offset of the first uncompressed message val startOffset = entry.message.compressionCodec match { case NoCompressionCodec => entry.offset case _ => ByteBufferMessageSet.deepIterator(entry.message).next().offset }
- 264. // we need to decompress the message, if required, to get the offset of the first uncompressed message val startOffset = entry.message.compressionCodec match { case NoCompressionCodec => entry.offset case _ => ByteBufferMessageSet.deepIterator(entry.message).next().offset }
- 267. but jvm not under heap pressure!
- 268. finalizers
- 269. patch to call close
- 271. super ugly, big, introduced new abstractions
- 274. much nicer!
- 275. no real loss, if message format > 0 we already do this work
- 276. tested patched version in staging
- 277. Ship it!
- 279. heroku kafka:upgrade --version 0.10.2.0
- 280. Lessons
- 281. 29k?
- 282. that 3%?
- 283. novel failure
- 284. A U T O M A T I O N
- 285. the space to solve real problems
- 286. take a break
- 287. 1. Impact 2. Mitigate 3. Fix 4. Follow up
- 288. apache kafka is great software
- 289. but it isn't perfect
- 290. A U T O M A T I O N
- 291. takeways take a break kafka is not perfect A U T O M A T I O N
- 292. Conclusion
- 293. if you run kafka in production
- 294. happy to talk
- 295. you can't waste my time
- 296. apache kafka is great software
- 297. but it isn't perfect
- 298. A U T O M A T I O N
- 299. hundreds of clusters with 5 people