Training Slides: 153 - Working with the CLI
0 likes77 views

Watch this 55min training session to learn about the main command line tools you’ll be using when working with Tungsten Replicator. TOPICS COVERED - Re-cap the previous Installation - Explore the main Command Line Tools - tpm - trepctl - thl




![tpm
• Tungsten Package Manager
• As well as using tpm for installs and updates, it can also be used for a number of other actions. You
can issue tpm help for a list of possible options.
• Most common options:
• tools/tpm validate[-update]
• [tools/]tpm update [--replace-release]
• tools/tpm install
• tpm diag – Gathers package of stats for support!
• tpm mysql – Launches the MySQL command-line client and connects to the MySQL server
process running on the local host](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-6-320.jpg)

![trepctl
• trepctl services
• Short list output of all services running on the host
• Shows basic information
• trepctl [-service SERVICENAME] status [-r N]
• Shows the full status of the replicator
• Specify –service if multiple services available
• Specify –r N to refresh every N seconds or until CTRL+C
• trepctl [-service SERVICENAME] status -name stages
• A more complete status view showing detailed output of each replicator stage](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-8-320.jpg)
![trepctl
• trepctl [-service SERVICENAME] qs [-r N]
• Shows a quick summary of the replicator progress
• Specify –service if multiple services available
• Specify –r N to refresh every N seconds or until CTRL+C
• trepctl [-service SERVICENAME] perf [-r N]
• Shows the status of each stage of the replication pipeline
• Output differs between Primary and Replicas
• Specify –service if there are multiple services available
• Specify –r N to refresh every N seconds or until CTRL+C](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-9-320.jpg)
![trepctl
• trepctl [-service SERVICENAME] reset {OPTIONS}
• Performs a FULL reset of the replicator
• VERY destructive if used incorrectly
• Resets SEQNO to 0
• trepctl [-service SERVICENAME] offline|online {OPTIONS}
• Bring a service online or offline
• Can be used with various options to control how/when
• Used with –skip-seqno to skip errors](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-10-320.jpg)












![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-24-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
Global Sequence number for the event](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-25-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
Associated THL File on Disk](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-26-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
Commit time to Binary Logs](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-27-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
Associated Binary Log File and Position](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-28-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
Source of transaction (Should be a Primary!)](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-29-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
Metadata](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-30-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
The database schema that the
following SQL is being applied to](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-31-320.jpg)
![thl
SEQ# = 2 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:50:52.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000000939;12297
- SOURCEID = db1
- METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true;
- service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1,
unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1,
sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,
ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33,
collation_connection = 33, collation_server = 8]
- SCHEMA = hr
- SQL(0) = CREATE TABLE regions
( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY
, region_name VARCHAR(25)
)
DDL Statement](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-32-320.jpg)
![thl
SEQ# = 5 / FRAG# = 0 (last frag)
- FILE = thl.data.0000000001
- TIME = 2020-01-08 13:51:38.0
- EPOCH# = 0
- EVENTID = mysql-bin.000005:0000000000001746;-1
- SOURCEID = db1
- METADATA = [mysql_server_id=101;dbms_type=mysql;tz_aware=true;service=training1;shard=hr]
- TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent
- OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8]
- SQL(0) =
- ACTION = INSERT
- SCHEMA = hr
- TABLE = regions
- ROW# = 0
- COL(1: ) = 1
- COL(2: ) = europe
Row Change Data](https://image.slidesharecdn.com/153-working-with-the-cli-200817150000/85/Training-Slides-153-Working-with-the-CLI-33-320.jpg)


































More Related Content
What's hot (20)
Similar to Training Slides: 153 - Working with the CLI (20)

![[Altibase] 12 replication part5 (optimization and monitoring)](https://cdn.slidesharecdn.com/ss_thumbnails/altibase12replicationpart5optimizationandmonitoring-160126072237-thumbnail.jpg?width=560&fit=bounds)
















More from Continuent (20)




















Recently uploaded (19)



















Training Slides: 153 - Working with the CLI
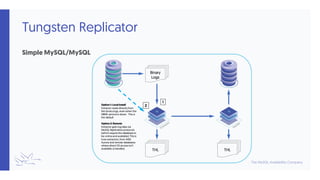
- 1. The MySQL Availability Company Tungsten Replicator Master Class Basics: Working with Command Line Tools Chris Parker, Customer Success Director, EMEA & APAC
- 2. Topics In this short course, we will • Re-cap the previous Installation • Explore the main Command Line Tools • tpm • trepctl • thl
- 6. tpm • Tungsten Package Manager • As well as using tpm for installs and updates, it can also be used for a number of other actions. You can issue tpm help for a list of possible options. • Most common options: • tools/tpm validate[-update] • [tools/]tpm update [--replace-release] • tools/tpm install • tpm diag – Gathers package of stats for support! • tpm mysql – Launches the MySQL command-line client and connects to the MySQL server process running on the local host
- 7. trepctl • Used to control and manage the replicator Java process • Most common uses are • View replicator status • Stop/Start replication • Skip “safe” errors • trepctl help to see all options
- 8. trepctl • trepctl services • Short list output of all services running on the host • Shows basic information • trepctl [-service SERVICENAME] status [-r N] • Shows the full status of the replicator • Specify –service if multiple services available • Specify –r N to refresh every N seconds or until CTRL+C • trepctl [-service SERVICENAME] status -name stages • A more complete status view showing detailed output of each replicator stage
- 9. trepctl • trepctl [-service SERVICENAME] qs [-r N] • Shows a quick summary of the replicator progress • Specify –service if multiple services available • Specify –r N to refresh every N seconds or until CTRL+C • trepctl [-service SERVICENAME] perf [-r N] • Shows the status of each stage of the replication pipeline • Output differs between Primary and Replicas • Specify –service if there are multiple services available • Specify –r N to refresh every N seconds or until CTRL+C
- 10. trepctl • trepctl [-service SERVICENAME] reset {OPTIONS} • Performs a FULL reset of the replicator • VERY destructive if used incorrectly • Resets SEQNO to 0 • trepctl [-service SERVICENAME] offline|online {OPTIONS} • Bring a service online or offline • Can be used with various options to control how/when • Used with –skip-seqno to skip errors
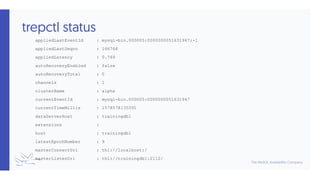
- 11. trepctl status appliedLastEventId : mysql-bin.000005:0000000051631947;-1 appliedLastSeqno : 166764 appliedLatency : 0.769 autoRecoveryEnabled : false autoRecoveryTotal : 0 channels : 1 clusterName : alpha currentEventId : mysql-bin.000005:0000000051631947 currentTimeMillis : 1578578135591 dataServerHost : trainingdb1 extensions : host : trainingdb1 latestEpochNumber : 9 masterConnectUri : thl://localhost:/ masterListenUri : thl://trainingdb1:2112/
- 12. trepctl status appliedLastEventId : mysql-bin.000005:0000000051631947;-1 appliedLastSeqno : 166764 appliedLatency : 0.769 autoRecoveryEnabled : false autoRecoveryTotal : 0 channels : 1 clusterName : alpha currentEventId : mysql-bin.000005:0000000051631947 currentTimeMillis : 1578578135591 dataServerHost : trainingdb1 extensions : host : trainingdb1 latestEpochNumber : 9 masterConnectUri : thl://localhost:/ masterListenUri : thl:// trainingdb1 :2112/ On a Primary, the last ending binary log position written to the THL along with the Seqno for that event, and the latency between the database commit to the binlog and the THL write completion. On a replica, displays the last event written to the target database with the corresponding Seqno, and the latency between the source database commit and the completed apply of that event to the target database.
- 13. trepctl status appliedLastEventId : mysql-bin.000005:0000000051631947;-1 appliedLastSeqno : 166764 appliedLatency : 0.769 autoRecoveryEnabled : false autoRecoveryTotal : 0 channels : 1 clusterName : alpha currentEventId : mysql-bin.000005:0000000051631947 currentTimeMillis : 1578578135591 dataServerHost : trainingdb1 extensions : host : trainingdb1 latestEpochNumber : 9 masterConnectUri : thl://localhost:/ masterListenUri : thl:// trainingdb1 :2112/ Auto-Recovery properties
- 14. trepctl status appliedLastEventId : mysql-bin.000005:0000000051631947;-1 appliedLastSeqno : 166764 appliedLatency : 0.769 autoRecoveryEnabled : false autoRecoveryTotal : 0 channels : 1 clusterName : alpha currentEventId : mysql-bin.000005:0000000051631947 currentTimeMillis : 1578578135591 dataServerHost : trainingdb1 extensions : host : trainingdb1 latestEpochNumber : 9 masterConnectUri : thl://localhost:/ masterListenUri : thl://trainingdb1:2112/ Current Binlog position of the database (NONE on Replicas)
- 15. trepctl status appliedLastEventId : mysql-bin.000005:0000000051631947;-1 appliedLastSeqno : 166764 appliedLatency : 0.769 autoRecoveryEnabled : false autoRecoveryTotal : 0 channels : 1 clusterName : alpha currentEventId : mysql-bin.000005:0000000051631947 currentTimeMillis : 1578578135591 dataServerHost : trainingdb1 extensions : host : trainingdb1 latestEpochNumber : 9 masterConnectUri : thl://localhost:/ masterListenUri : thl://trainingdb1:2112/ masterConnectUri shows the source THL server we are connected to masterListenUri shows the THL server listener protocol, host and port information for replicas to connect with
- 16. trepctl status maximumStoredSeqNo : 166764 minimumStoredSeqNo : 0 offlineRequests : NONE pendingError : NONE pendingErrorCode : NONE pendingErrorEventId : NONE pendingErrorSeqno : -1 pendingExceptionMessage: NONE pipelineSource : /var/lib/mysql relativeLatency : 580.591 resourceJdbcDriver : org.drizzle.jdbc.DrizzleDriver resourceJdbcUrl : jdbc:mysql:thin://trainingdb1:13306/${DBNAME}. . . resourcePrecedence : 99 resourceVendor : mysql rmiPort : 10000
- 17. trepctl status maximumStoredSeqNo : 166764 minimumStoredSeqNo : 0 offlineRequests : NONE pendingError : NONE pendingErrorCode : NONE pendingErrorEventId : NONE pendingErrorSeqno : -1 pendingExceptionMessage: NONE pipelineSource : /var/lib/mysql relativeLatency : 580.591 resourceJdbcDriver : org.drizzle.jdbc.DrizzleDriver resourceJdbcUrl : jdbc:mysql:thin:// trainingdb1:13306 /${DBNAME}. . . resourcePrecedence : 99 resourceVendor : mysql rmiPort : 10000 When the Replicator goes into an OFFLINE:ERROR state, these fields will show all the associated information. Always check the trepsvc.log file for more detail as needed.
- 18. trepctl status maximumStoredSeqNo : 166764 minimumStoredSeqNo : 0 offlineRequests : NONE pendingError : NONE pendingErrorCode : NONE pendingErrorEventId : NONE pendingErrorSeqno : -1 pendingExceptionMessage: NONE pipelineSource : /var/lib/mysql relativeLatency : 580.591 resourceJdbcDriver : org.drizzle.jdbc.DrizzleDriver resourceJdbcUrl : jdbc:mysql:thin://trainingdb1:13306/${DBNAME}. . . resourcePrecedence : 99 resourceVendor : mysql rmiPort : 10000 The current source of THL. A Primary will show the binary log directory, a Replica will match the masterListenURI from the extractor.
- 19. trepctl status maximumStoredSeqNo : 166764 minimumStoredSeqNo : 0 offlineRequests : NONE pendingError : NONE pendingErrorCode : NONE pendingErrorEventId : NONE pendingErrorSeqno : -1 pendingExceptionMessage: NONE pipelineSource : /var/lib/mysql relativeLatency : 580.591 resourceJdbcDriver : org.drizzle.jdbc.DrizzleDriver resourceJdbcUrl : jdbc:mysql:thin://trainingdb1:13306/${DBNAME}. . . resourcePrecedence : 99 resourceVendor : mysql rmiPort : 10000 Latency between NOW and the timestamp of the last event in the local THL.
- 20. trepctl status role : master seqnoType : java.lang.Long serviceName : alpha serviceType : local simpleServiceName : alpha siteName : default sourceId : trainingdb1 state : ONLINE timeInStateSeconds : 85641.738 timezone : GMT transitioningTo : uptimeSeconds : 85673.511 useSSLConnection : false version : Tungsten Clustering 6.1.4 build 44
- 21. trepctl status role : master seqnoType : java.lang.Long serviceName : training1 serviceType : local simpleServiceName : training1 siteName : default sourceId : trainingdb1 state : ONLINE timeInStateSeconds : 85641.738 timezone : GMT transitioningTo : uptimeSeconds : 85673.511 useSSLConnection : false version : Tungsten Clustering 6.1.4 build 44 Current role : master, slave Current State, can be : • ONLINE • ONLINE:DEGRADED • ONLINE:DEGRADED-BINLOG-FULLY-READ • OFFLINE:NORMAL • SUSPECT • OFFLINE:ERROR • GOING-ONLINE:SYNCHRONISING • GOING-ONLINE:RESTORING • GOING-ONLINE:PROVISIONING
- 22. Applied Latency vs Relative Latency The appliedLatency is the latency between the commit time of the source event and the time the last committed transaction reached the end of the corresponding pipeline within the replicator. Within a primary, this indicates the latency between the transaction commit time and when it was written to the THL. In a replica, it indicates the latency between the commit time on the primary database and when the transaction has been committed to the destination database. Clocks must be synchronized across hosts for this information to be accurate. The latency is measured in seconds. Increasing latency may indicate that the destination database is unable to keep up with the transactions from the primary. In replicators that are operating with parallel apply, appliedLatency indicates the latency of the trailing channel. Because the parallel apply mechanism does not update all channels simultaneously, the figure shown may trail significantly from the actual latency. The relativeLatency is the latency between now and timestamp of the last event written into the local THL. This information gives an indication of how fresh the incoming THL information is. On a primary, it indicates whether the primary is keeping up with transactions generated on the primary database. On a replica, it indicates how up to date the THL read from the extractor is. A large value can either indicate that the database is not busy, that a large transaction is currently being read from the source database or from the primary replicator, or that the replicator has stalled for some reason. An increasing relativeLatency on the replica may indicate that the replicator may have stalled and stopped applying changes to the database.
- 23. thl • Interface for viewing the contents of the THL • thl help to view all command options • thl info – Show a summary of the THL available on disk • thl list will product a lot of output, always use with options to filter the result set • -low|from SEQ – Start from supplied seqno • -high|to SEQ – Stop at supplied seqno • -first – Show first seqno available • -first N – Show first N entries • -last – Show last seqno available • -last N – Show last N entries • thl index – re-index THL – can help to speed up replicator restarts • thl purge – Use with CARE since this command will REMOVE ALL THL on disk for that service
- 24. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) )
- 25. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) Global Sequence number for the event
- 26. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) Associated THL File on Disk
- 27. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) Commit time to Binary Logs
- 28. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) Associated Binary Log File and Position
- 29. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) Source of transaction (Should be a Primary!)
- 30. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) Metadata
- 31. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) The database schema that the following SQL is being applied to
- 32. thl SEQ# = 2 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:50:52.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000000939;12297 - SOURCEID = db1 - METADATA = [mysql_server_id=101;unsafe_for_block_commit;dbms_type=mysql;tz_aware=true; - service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [##charset = UTF-8, autocommit = 1, sql_auto_is_null = 0, foreign_key_checks = 1, unique_checks = 1, auto_increment_increment = 2, auto_increment_offset = 1, sql_mode = 'NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES, ERROR_FOR_DIVISION_BY_ZERO,NO_ZERO_DATE,NO_ZERO_IN_DATE', character_set_client = 33, collation_connection = 33, collation_server = 8] - SCHEMA = hr - SQL(0) = CREATE TABLE regions ( region_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY , region_name VARCHAR(25) ) DDL Statement
- 33. thl SEQ# = 5 / FRAG# = 0 (last frag) - FILE = thl.data.0000000001 - TIME = 2020-01-08 13:51:38.0 - EPOCH# = 0 - EVENTID = mysql-bin.000005:0000000000001746;-1 - SOURCEID = db1 - METADATA = [mysql_server_id=101;dbms_type=mysql;tz_aware=true;service=training1;shard=hr] - TYPE = com.continuent.tungsten.replicator.event.ReplDBMSEvent - OPTIONS = [foreign_key_checks = 1, unique_checks = 1, time_zone = '+00:00', ##charset = UTF-8] - SQL(0) = - ACTION = INSERT - SCHEMA = hr - TABLE = regions - ROW# = 0 - COL(1: ) = 1 - COL(2: ) = europe Row Change Data
- 34. When the PrimaryKey (pkey) filter is enabled, the key information is optimized to only contain the actual primary keys for the row-based THL record. - SQL(0) = - ACTION = UPDATE - SCHEMA = hr - TABLE = regions - ROW# = 0 - COL(1: ) = 1 - COL(2: ) = Europe - KEY(1: ) = 1 - KEY(2: ) = europe - SQL(0) = - ACTION = UPDATE - SCHEMA = hr - TABLE = regions - ROW# = 0 - COL(1: ) = 1 - COL(2: ) = Europe - KEY(1: ) = 1 - SQL(0) = - ACTION = DELETE - SCHEMA = hr - TABLE = regions - ROW# = 0 - KEY(1: ) = 1 - KEY(2: ) = Europe - SQL(0) = - ACTION = DELETE - SCHEMA = hr - TABLE = regions - ROW# = 0 - KEY(1: ) = 1 UPDATE DELETE Without pkey filter With pkey filter
- 35. Summary What we have learnt today • How to use the command line tools • tpm • trepctl • thl • How to interpret status output
- 36. Next Steps In the next session we will • Discuss Maintenance Operations • Updating paramaters • auto-recovery • thl • Upgrades
- 37. THANK YOU FOR LISTENING continuent.com The MySQL Availability Company Chris Parker, Customer Success Director, EMEA & APAC