Navigating the World of User Data Management and Data Discovery
Download as PPTX, PDF2 likes1,469 views

This document discusses navigating user data management and data discovery. It provides an overview of evaluating and selecting data management tools for a Hadoop data lake. Key criteria for evaluation include metadata curation, lineage and versioning, integration capabilities, and performance. Several vendors were evaluated, with Global ID, Attivio, and Waterline Data scoring highest based on the criteria. The presentation emphasizes selecting a limited number of tools based on business and user requirements.





































Navigating the World of User Data Management and Data Discovery
- 1. NAVIGATING THE WORLD OF USER DATA MANAGEMENT AND DATA DISCOVERY SMITI SHARMA, VIRTUSTREAM - EMC
- 2. About Me 2 Principal Engineer & Lead, Big Data Cloud, Virtustream Oracle – Principal Engineer & PM team EMC – Big Data Lead Pivotal – Global CTO Virtustream EMC Areas of expertise Architecting, developing and managing Mission Critical Transactional and Analytics Platforms RDBMS & NoSQL – Hadoop Platforms Product Management and Development ODPi RT member Sessions at Hadoop Summit 2016 Wed: 11:30am Room 211: User Data Management in HD Wed: 4:10pm Room 212: Building PAAS for Smart cities [email protected] @smiti_sharma
- 3. About Virtustream Enterprise-Class Cloud Solutions − Cloud IAAS, PAAS − Cloud Software Solutions − Cloud Managed Services − Cloud Professional Services Developer of xStream Cloud Management Platform SW Inventor of the µVMTM (MicroVM) Cloud Technology Industry leading Cloud offers in areas of − SAP Landscape, HANA − Storage − Big Data Close partnerships with SAP, EMC, VMWare Service Provider to 2,000 Global Workloads Global Footprint
- 4. Data Management Overview Project Background & Context High level Architecture and data flow Solution criteria Evaluation criteria of Data Management Tools Differentiation factors Proposed Solution Conclusions Agenda 4
- 5. 5 5
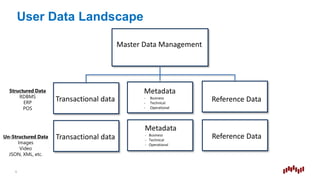
- 6. User Data Landscape Master Data Management Metadata - Business - Technical - Operational Reference DataTransactional data 6 Reference DataTransactional data Metadata - Business - Technical - Operational
- 7. Driving Factors for Data Management • IT custodian of business data • Data Characteristics – Business Value • Analytical vs. transactional systems – Volume and Volatility – Complexity of Data type and formats – Adaptive feedback from IT to Business – Reusability factor – across different teams – De-duplication factor 7
- 8. MDM is an organizational approach to managing data as a corporate asset 8 What is Master Data Management Application framework and collection of tools implemented with the business goal of providing, managing & using data intelligently and productively
- 9. Multi-Domain & Organizational MDM Metadata Data Reference Data Transactional Data 9 Domain 1: Product Master Data Metadata Data Reference Data Transactional Data Domain 3: Logistics Master Data Metadata Data Reference Data Transactional Data Domain 2: Supply Chain Master Data
- 11. 11 Data Management for Hadoop: Why, At what stage 7% 4% 9% Today In three years Growth Indicator Fig 2: Source TDWI Fig 1: Source TDWI Primary Strategy to improve Quality of Data managed in Hadoop
- 12. • Uni-directional movement of data • Static and limited identification patterns • Focused mainly on Transactional systems – data type/Hadoop OSS integration limited • Non-adaptive solutions to rapidly changing “schema” • Limiting performance 12 Traditional MDM Challenges
- 13. Building “Data Management Layer” for Hadoop Data Lake 13
- 14. Project(s) and Context • Project initiated at two Large Retailers • Goal to extend the analytical Data Lake – As of Late 2015 Data Lake built only for Analytics – Pulls data from Transactional, ERP, POS systems – Implemented using ODPi (Pivotal/Hortonworks) Distribution and Greenplum for MPPDB • Next Generation Data Lake – Current ETL system reaching performance and scale limits Move ETL in Hadoop – Move BIDW and Transactional reporting to Hadoop – Increase users on this system – Security and Quality constraints – In-store SKU count ~ 500 Million ; Online SKU count ~ 5 Million • Complex Master Data Management around existing systems – For Hadoop – the EIM integration didn’t exist and/or processes were not in place – Little to no interest from EIM data integration team 14
- 15. Key Problem Statement (at least 1 of them!) Evaluate and Prototype the Data Management Strategy and Product(s) to enhance and enrich the “Next Generation Data Lake” 15
- 16. High Level Logical Data Architecture Metadata repository, Policy management and Business Rules Engine Enterprise Security Framework (AD/LDAP) Query/Accessand VisualizationLayer • API to access data sources • Interfaces with Metadata Repository to define data query path • Potentially Custom Portals for User queries as well as standard tools Access DataSources I n g e s t Data Sources (Raw)/Aggregated* Inventory data Logistics Product/ Vendor Data Data Fabric/“Landing Zone” Processing Framework In- Memory Process- ing Object store HDFS MPP DB RDBMS NoSQL/ NewSQL Data Ingest to Persistence or memory layer Federated query Ingest to Metadata management Layer Cross reference for Rules, policies and Metadata LEGEND 16 Metadata Management Ingestion and Indexing Data Management
- 17. Solution Requirements • Inherent Data processing requirements • Incoming data from sources e.g. Kafka, Storm, Sqoop, Spark • Be able to manage complex data types e.g. Video files from POS • Data placement based on priority and sensitivity – memory or disk • Handling both Synchronous and Async (In-band and out-of-band) • Integration with existing EIM tools • Performance requirements • Increasing ingest volume of data and expanding sources • Varied Data Type support and considerations 17
- 18. File format type Embedded Metadata Compression& Splitable HQL/SQL interface viability Popularity in current and new landscape Support for Schema evolution 18 CSV/Text No No^ Hive/Hawq Most common Limited Avro Yes Yes Hive Increasing footprint Yes JSON Yes No^ Hive/ MongoDB Increasing footprint Yes RC Files Limited Not as well Hive (RW) Yes No ORC Files No Yes Hive (RW) Impala ( R) Yes No Sequence Files (binary format) No Yes Hive (RW) Impala ( R) None today Limited Parquet Yes Yes Yes – Hive and impala Increasing footprint Limited • Read/Write performance • Source, Application and development effort and support • Hierarchical model File Format Considerations
- 19. File format type Embedded Metadata Compression& Splitable HQL/SQL interface viability Popularity in current and new landscape Support for Schema evolution 19 CSV/Text No No^ Hive/Hawq Most common Limited Avro Yes Yes Hive Increasing footprint Yes JSON Yes No^ Hive/ MongoDB Increasing footprint Yes RC Files Limited Not as well Hive (RW) Yes No ORC Files No Yes Hive (RW) Impala ( R) Yes No Sequence Files (binary format) No Yes Hive (RW) Impala ( R) None today Limited Parquet Yes Yes Yes – Hive and impala Increasing footprint Limited • Read/Write performance • Source, Application and development effort and support • Hierarchical model File Format Considerations
- 20. Key Evaluation and Selection Criteria 20
- 21. Initial Challenge • Too many tools to choose from • Each claimed to be Metadata management tool • Each claimed security and integration features • Resistance from the EIM team when initially involved • Translating Data Management Ideology to tasks of evaluation 21
- 22. Project Approach • Build a list of KPI to evaluate tools • Working with EIM team (best practices advise & SME engagement), business and IT team support Data lake project • Vendor Identification – List of 5 • Implementation • Minimized scope of project • Decided to tackle integration with legacy EIM at a later date • After Evaluation, focused on implementing no-more than 2 Data management tools for Next-Gen Data Fabric Platform 22
- 23. • Define Business Metadata (Is reference data available within tool or outside) • Automation and flexibility in crawling the HDFS and understand the various format – Range of File formats supported – Reading each file to extract metadata – Both for data persisted already and incoming new files in real-time – Cross reference with lookup or repository for pre-existing classes and profiles – Maturity of attaching context or facet to the atomic data – Ability to retrieve descriptive and Structural Metadata even with no Metadata within the content • Storing the profiled data – actual data and metadata in a repository • Custom Tagging as well as recognizing Metadata information • Translation and integration with industry certification and models 23 Metadata Curation and Management (1/2) Data Profiling
- 24. • Ability to classify data – based on user defined categories – Search/Crawl and identification "Facet Finder” and efficiency of internal repository – Presence of Data Models if any – Features around custom Metadata and Tagging • Once classified - ability for Metadata information to be indexed, and searchable thru API or Web Interfaces – Efficiency of Search and indexing – Richness of Integration with NLPTK • Data Re-mediation • Data Archiving and policy implementation • Notification: Configurable triggers – based on user-defined criteria 24 Metadata Curation and Management (2/2) Data Classification
- 25. Lineage and Versioning • Be able to identify the origin of data – i.e. from – Transactional systems, Dump files, Another HDFS file, Repository etc. – Level of depth of data origination and lineage • Ability of the solution to sense and preserve Metadata Versions around a given entity during Capture process and post • Ability to support Deduplication with the Entity’s metadata – On the fly without impacting the performance 25
- 26. Integration • Ability to integrate its meta store with enterprise MDM /EIM systems – Maturity of Metadata Entity Readers (Input/Output) Artifacts from Metastore – Bi-directional API for other tool integration to identify lineage – Bi-directional API for other tool integration for SIEM threat assessment and detection – While maintaining user and security context • Integration with the various tools of Ingestion, Transformation & Consumption – Spark, Storm, Kafka, Informatica, Data Stage etc. • Integration with security tools – LDAP, ACLs, encryption • Rules and Policy engine 26
- 27. Performance, Accuracy and Ease of Use • Sample visualization of Metadata with Native Reporting tools & others • Ability to process compressed and encrypted files • Level of Error and exception handling built in during all processes • Impact on performance from – Crawling, scanning and profiling – Classification & transformation • Enable notifications of data availability - how customizable are they? • Self-service discovery portal leveraging curated artifacts 27
- 28. Some of the notable Vendors evaluated • Attivio • Global ID • Waterline Data • Zaloni • Adaptive Inc. 28 At the time of this study, Falcon and Ranger were new. Little analysis on these products was done
- 29. Vendor Evaluation Scoreboard (Template) 29
- 30. Vendor Evaluation Summary Results
- 31. 31 Metadata curation and management Lineage and versioning Integration Performance, Accuracy and Ease of use Attivio Global ID Waterline Data Zaloni Global ID Attivio Waterline Data Zaloni Zaloni Attivio Global ID Waterline Data Attivio Zaloni Waterline Data Global ID • All tools had satisfactory features overall with emphasis in 1 or 2 areas. • Your choice of tools needs to align with Business and User Requirements • Waterline: Automated data discovery, self- service • Attivio: Data Curation – Discovery, Search, flexibility of tagging, performant and scalable • Global ID: Efficient in Mapping logical models, overlapping data identification and pattern matching • Zaloni: Had notable interface for Data mapping and flow, integration with external tools Evaluation Summary CAVEAT: Based on criterion driven by customer needs. You eval and updates from vendor will affect results
- 32. High Level Logical Data Architecture Metadata repository, Policy management and Business Rules Engine Enterprise Security Framework (AD/LDAP) Query/Accessand VisualizationLayer • API to access data sources • Interfaces with Metadata Repository to define data query path • Potentially Custom Portals for User queries as well as standard tools Access DataSources I n g e s t Data Sources (Raw)/Aggregated* Inventory data Logistics Product/ Vendor Data Data Fabric/“Landing Zone” Processing Framework In- Memory Process- ing Object store HDFS MPP DB RDBMS NoSQL/ NewSQL 32 Metadata Management Ingestion and Indexing Data Management Data Ingest to Persistence or memory layer Federated query Ingest to Metadata management Layer Cross reference for Rules, policies and Metadata LEGEND
- 33. High Level Logical Data Architecture Metadata repository, Policy management and Business Rules Engine Enterprise Security Framework (AD/LDAP) CustomPortal/other evaluations(TBD) • API to access data sources • Interfaces with Metadata Repository to define data query path • Potentially Custom Portals for User queries as well as standard tools Access DataSources Flume/Kafka/SpringXD Data Sources (Raw)/Aggregated* Inventory data Logistics Product/ Vendor Data Data Fabric/“Landing Zone” Processing Framework Apache Spark/ GemFir e Object store HDFS MPP DB RDBMS NoSQL/ NewSQL 33 Metadata Management Attivio Global ID Data Ingest to Persistence or memory layer Federated query Ingest to Metadata management Layer Cross reference for Rules, policies and Metadata LEGEND
- 34. Key Takeaways 34
- 35. Market − Metadata Mgmt tools in market are still evolving for Data Lake architectures − Ever growing and Rich Partner ecosystem − Hadoop does not offer a sufficient policy engine or action framework Customer − Choice of tool is IT and business driven. Sponsorship important ! − To drive adoption – ease of use and intuitive product a must − Balancing Multi-vendor and functionality: Limit number of tools to 3 − Recommendation to use Information management Professional Services with selected tool (s) Key Takeaways
- 36. PROCESS Evaluation of the tools − Reviews and demo of the tools versus a full-fledged POC − Build an adaptive matrix of KPI measurements, customized to your organization - Unless quantified evaluation would be very subjective Beware of the Trap- Analysis - Paralysis − Multiple business units drive this decision − Functionality scope - workflows, ETL processes and integration or pure-play data management − Integration with existing EIM tools was delayed as a priority: Huge part of the success Investment/Cost: Existing tools, Level of Effort and implementation Key Takeaways
- 37. References • References to the following documents were made – TDWI- Hadoop for enterprise – MDM institute • Acknowledgements from the following authors and additional work – EMC IT Team – Customer’s IT team for Prototyping along with EMC Field resources 37