








































































































































![sort ( 10K * [ hotness, rowptr ] )](https://image.slidesharecdn.com/why02-091012025326-phpapp02/85/Why02-139-320.jpg)












![5 00,000 записей 56 MB данных (.ibd файл) 32 MB innodb_buffer_pool age \in [ 18 .. 8 0 ] hotness \in [-5.. 5 ]](https://image.slidesharecdn.com/why02-091012025326-phpapp02/85/Why02-152-320.jpg)



















































































































Ad
More Related Content
Viewers also liked (8)
More from HighLoad2009 (18)




Ad
Why02
- 1. Зачем знать алгоритмы Андрей Аксенов Sphinx Technologies Inc. Highload++2009
- 2. Who is Mr. Aksenov?
- 4. честно листал все !
- 5. не прочитал ни одной :(
- 7. делал веб-сайты и веб-движок
- 9. делал игры и 3D движок
- 11. <
- 13. free open source search
- 14. << free :(
- 17. как устроены всякие движки
- 19. на пальцах, не по книжке! (см. “ не читатель ” )
- 20. про движок СУБД ( любой )
- 21. С истема У правления Б азой Д анных
- 22. данные – это таблицы . из строк
- 24. строки – нужно где-то хранить
- 27. это, кстати, данные – без индексов
- 28. добавляем PK, и брюки превращаются…
- 31. почему так? разные стратегии хранения строк
- 32. MyISAM – в порядке поступления (в конец файла)
- 33. InnoDB – хранит постранично, внутри странички – в порядке PK
- 34. (InnoDB, после добавления PK)
- 35. MyISAM – “ обычное ” хранение InnoDB – т.н. “ кластерное ”
- 36. умеем хранить – теперь нужно быстро искать!
- 37. SELECT * FROM users WHERE id=123
- 38. SELECT * FROM users WHERE lastname=‘Pupkin’
- 39. SELECT * FROM users WHERE lastname LIKE ‘Pu%’
- 40. SELECT * FROM goods WHERE MATCH(‘ipod’) ORDER BY price ASC
- 41. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age<=25
- 44. полный перебор ? мееедленно
- 45. нас спасут…
- 47. индексы! алгоритмы уже спешат на помощь!
- 48. смысл любого вида индекса ?
- 49. быстрый поиск по ключу(-ам)
- 55. видов индексов – тоже много
- 56. hash index
- 57. R-tree index
- 58. full-text index
- 59. индекс общего назначения – типично B-tree
- 60. поиск – по равенству , диапазону ( чисел, строк, и т.п.)
- 61. дискует – страничками (хорошо!)
- 67. используется несмотря ни на что!!!
- 68. как устроено?
- 69. ( B- дерево ; странички ; масштаб 1: 72) 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 70. два вида страничек
- 71. Промежуточные = ключи + указатели на другие странички { key1, ptr1, key2, ptr2, …, keyN } Аня Женя Маша
- 72. Листовые = ключи + соотв-е им данные ( eg. row_offset) { key1, data1, key2, data2, … } Ваня 3 Аня 141 Боря 592 3 Аня 141 Боря 592 Ваня id key
- 73. Промежуточные Листовые 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 74. почему все используют этот ужас?!
- 75. во-1х – легко искать по ключу
- 76. пример – ищем Зину
- 77. 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 78. 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 79. 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 80. 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 81. 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 82. 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 83. ура – Зина нашлась!!!
- 84. хорошо – поиск работает…
- 85. … но он чё, всегда такой резкий ?
- 87. – В жизни – под 1000 (а не 3) записей на страничку – Два уровня страничек – 1000*1000 – миллион – Три уровня – миллиард … – Итого 2-3 странички max – практически всегда 3 Аня 141 Боря 592 Ваня id key 653 Гоша 589 Дима 793 Ева id key 238 Женя 462 Зина 643 Ира id key 383 Коля 279 Лена 502 Маша id key Аня Гоша Ева Женя Коля Маша Аня Женя Маша
- 88. почему все используют этот ужас?!
- 89. во- 2 х – легко обновлять
- 90. странички обычно НЕ полны ? ? 3 Аня ? ? id key
- 91. вставляем… ? ? 3 Аня 141 Боря id key
- 92. вставляем… 592 Ваня 3 Аня 141 Боря id key
- 93. вставляем… оп-па, некуда!! 592 Ваня 653 Гоша 3 Аня 141 Боря id key
- 94. создаем новую страничку 592 Ваня 653 Гоша 3 Аня 141 Боря id key ? ? ? ? ? ? ? ? id key
- 95. создаем новую страничку ? ? 141 Боря 3 Аня id key ? ? 592 Ваня 653 Гоша id key
- 96. … и суем “ ее ” в родителя 141 Боря ? ? 3 Аня id key ? ? 592 Ваня 653 Гоша id key
- 97. это все – тоже трогаем max 2-3 странички 141 Боря ? ? 3 Аня id key ? ? 592 Ваня 653 Гоша id key
- 100. вернемся к запросам?
- 101. SELECT * FROM users WHERE id=123 1 . “ Ищем Зину ” (rowoffset по id=123) 2. seek(rowoffset) в файле строк ( .MYD) 3. read(rowdata) из файла 4. и… все – результат готов
- 102. усложним – добавим условий
- 103. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age<=25
- 104. индекс “ в лоб ” по sex?
- 105. 12352 F 12351 F 12350 F 12349 F 12348 F 12347 F 12346 F 12345 F id key 12360 F 12359 F 12358 F 12357 F 12356 F 12355 F 12354 F 12353 F id key 12368 F 12367 F 12366 F 12365 F 12364 F 12363 F 12362 F 12361 F id key 12376 F 12375 F 12374 F 12373 F 12372 F 12371 F 12370 F 12369 F id key
- 106. 12352 F 12351 F 12350 F 12349 F 12348 F 12347 F 12346 F 12345 F id key 12360 F 12359 F 12358 F 12357 F 12356 F 12355 F 12354 F 12353 F id key 12368 F 12367 F 12366 F 12365 F 12364 F 12363 F 12362 F 12361 F id key 12376 F 12375 F 12374 F 12373 F 12372 F 12371 F 12370 F 12369 F id key
- 107. они ВСЕ подходят по условию ‘F’!
- 109. … и нам надо прочитать с диска (!) 5,000,000+ строк…
- 110. … и для каждой лично проверить паспорт и age>=18 and age<=25?!
- 111. 12352 F 12351 F 12350 F 12349 F 12348 F 12347 F 12346 F 12345 F id key 12360 F 12359 F 12358 F 12357 F 12356 F 12355 F 12354 F 12353 F id key 12368 F 12367 F 12366 F 12365 F 12364 F 12363 F 12362 F 12361 F id key 12376 F 12375 F 12374 F 12373 F 12372 F 12371 F 12370 F 12369 F id key
- 112. неселективный индекс – косяк и западло!
- 113. sex=‘F’ AND age>=18 AND age<=25 индекс “ по лбу ” по age?
- 114. но – вдруг это мужики?! 12352 16 12351 15 12350 14 12349 14 12348 14 12347 13 12346 13 12345 13 id key 12360 22 12359 21 12358 20 12357 19 12356 18 12355 18 12354 18 12353 17 id key 12368 64 12367 53 12366 42 12365 31 12364 29 12363 27 12362 25 12361 25 id key
- 115. мужики нам не нужны!!!
- 116. либо опять читать ненужные строки (мужиков) – либо…
- 117. покрывающий (covering) индекс по обоим полям
- 118. 12352 F, 23 12351 F, 23 12350 F, 22 12349 F, 21 12348 F, 21 12347 F, 19 12346 F, 17 12345 F, 13 id key 12360 M, 17 12359 M, 13 12358 M, 11 12357 F, 42 12356 F, 33 12355 F, 31 12354 F, 27 12353 F, 25 id key 12368 M, 47 12367 M, 43 12366 M, 41 12365 M, 37 12364 M, 31 12363 M, 29 12362 M, 23 12361 M, 19 id key
- 119. список нужных строк – ясен сразу
- 120. чтений с диска – минимум скорости – максимум
- 121. бонус – сортировка по age
- 122. кстати, про сортировку …
- 123. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age<=25 ORDER BY hotness DESC LIMIT 10
- 124. как выполнять ? есть варианты
- 126. налево – read_index(WHERE) + read_rows + sort_rows(ORDER)
- 127. индекс данные сортировка результат 12354 F, 27 12351 F, 23 12350 F, 22 12349 F, 21 12348 F, 21 12347 F, 19 12346 F, 17 12345 F, 13 id key Федор Штын Нина Сидорова Ли Си Цын Маша Петрова Мацал Кошек Шараф Худайбердыев Лена Иванова name Ru Ru Cn Ua Cz Uz Ru Country 12351 80356 … дырка еще на 2000 записей … … дырка на 1000 записей … 24624 12347 10756 24523 12350 id
- 128. read_index – мало и быстро
- 129. 10 K*( 1+4+8 bytes ) = 130 KB 5-10 ms/seek, 50+ MB/s read
- 130. read_ random _rows – медленно ! 10 K *5-10 ms/seek = 50-100 sec…
- 131. sort_rows – обычно быстро 10 K*0.1-1 KB/row = 1-10 MB (in RAM)
- 132. мораль – все зло от random rows!
- 133. (еще от sort_rows , если их много )
- 135. … sex=‘F’ AND age>=18 AND age<=25 ORDER BY hotness DESC LIMIT 10
- 136. направо – read_ fat _index(WHERE) + sort_index(ORDER) + LIMIT + read_ less _rows + sort_rows
- 137. нужен утолщенный INDEX ( sex, age, hotness )
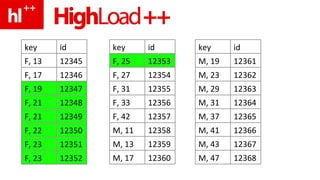
- 138. вместе с поиском по sex, age – сразу узнаем hotness (+40 KB)
- 139. sort ( 10K * [ hotness, rowptr ] )
- 140. read_rows – почти не нужен (10 строк результата…)
- 141. sort_rows – вообще не нужен
- 142. PROFIT?
- 143. не панацея – даже в теории
- 144. INDEX ( sex, age, hotness ) WHERE sex=‘F’ ORDER BY hotness LIMIT 10
- 145. в теории – обработать 50% индекса затем – прочитать 10 строк (пф!)
- 146. INDEX ( sex, age, hotness ) 1M rows, ~20 MB, 50% = ~10 MB
- 147. INDEX ( sex, age, hotness ) WHERE sex=‘F’ AND hotness>0 ORDER BY age LIMIT 10
- 148. в теории – читаем индекс линейно – пока не заполним limit
- 149. что на практике ?
- 150. welcome to real world
- 151. CREATE TABLE usertest ( id INTEGER PRIMARY KEY NOT NULL, sex ENUM ('m','f'), age INTEGER NOT NULL, hotness INTEGER NOT NULL, name VARCHAR(255) NOT NULL, INDEX (sex,age,hotness) )
- 152. 5 00,000 записей 56 MB данных (.ibd файл) 32 MB innodb_buffer_pool age \in [ 18 .. 8 0 ] hotness \in [-5.. 5 ]
- 153. mysql> explain select * from usertest where sex='f' and age>=18 and age<=25 order by hotness desc limit 10 \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: usertest type: ref possible_keys: sex key: sex key_len: 2 ref: const rows: 25119 Extra: Using where; Using filesort 1 row in set (0.00 sec)
- 154. filesort – НЕ про временный файл filesort – про “ сортировку строк ”
- 155. Using where – проверка условия НЕ по индексу – ?!!
- 156. запрос проще , точно по индексу ?
- 157. mysql> explain select * from usertest where sex='f' and age=18 order by hotness desc limit 10 \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: usertest type: ref possible_keys: sex key: sex key_len: 6 ref: const,const rows: 10386 Extra: Using where (bug #30733, 30 aug 2007?) 1 row in set (0.00 sec)
- 159. mysql> select * from usertest where sex= ' f ' and age>=18 and age<=25 order by hotness desc limit 10; ... 10 rows in set ( 23 .05 sec) mysql> select * from usertest where sex='f' and age=18 order by hotness desc limit 10; ... 10 rows in set (0.05 sec)
- 160. причина ?
- 161. mysql> explain select * from usertest where sex='f' and age>=18 and age<=25 order by hotness desc limit 10 \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: usertest type: ref possible_keys: sex key: sex key_len: 2 используется только начало, поле “sex”!!! ref: const rows: 25119 Extra: Using where; Using filesort так и есть :( 1 row in set (0.00 sec)
- 162. MySQL не умеет сортировать элементы индекса :(
- 163. сортировка “ по индексу ” – только если индекс гарантирует порядок
- 164. 1) в куске индекса sex=F, 18<=age<=25 порядок hotness desc НЕ гарантирован
- 165. 2) optimizer лажанул, 18<=age<=25 считается НЕ по индексу (а могло бы)
- 166. (теория говорит – можно лучше!)
- 167. проверяем дальше !
- 168. mysql> explain select * from usertest where sex='f' order by hotness desc limit 10 \G ... key: sex key_len: 2 ref: const rows: 226072 Extra: Using where; Using filesort mysql> explain select * from usertest where sex='f' order by hotness desc limit 10 \G ... 10 rows in set ( 20 . 25 sec)
- 169. и последний запрос
- 170. mysql> explain select * from usertest where sex='f' and hotness>0 order by age asc limit 10 \G ... key: sex key_len: 2 ref: const rows: 226072 Extra: Using where; Using filesort mysql> select * from usertest where sex='f' and hotness>0 order by age asc limit 10; ... 10 rows in set ( 0 . 25 sec)
- 171. итого HELL NO 20 . 2 5 Order – Const=F 0. 2 5 0.0 5 23 .05 Time Order Const=18 Range=18..25 Age Cond>0 Order Order Hotness KINDA OK Const=F OK Const=F HELL NO Const=F Optimal Sex
- 172. теория была оптимистична…
- 173. … реальность внесла коррективы .
- 174. не учли детали реализации
- 175. 1. нету “ досортировки ” индекса (MySQL specific)
- 176. 2. limit обрабатывается … так себе (MySQL specific)
- 177. 3 . optimizer ошибается (везде и у всех)
- 178. про ошибки optimizer и спасительный full-scan
- 179. mysql> select * from usertest where sex='f' order by hotness desc limit 10; ... 10 rows in set (20.25 sec) mysql> select * from usertest ignore index(sex) where sex='f' order by hotness desc limit 10; ... 10 rows in set (0.55 sec)
- 180. 10,000 x 10 ms = 100 sec 100,000 x 1KB / 50 M/s = 2 sec
- 181. мораль : random IO очень плохо (водка яд водка яд водка яд)
- 182. про “ обработку ” limit
- 183. теория – приоритетная очередь
- 185. приоритетная !!
- 186. технически – heap
- 188. или просто double buffer
- 191. ключевое свойство – в памяти храним только top-N
- 192. LIMIT 10 – надо хранить 10 строк
- 193. LIMIT 1 3 0,10 – надо 1 4 0
- 194. практика – MySQL vs. LIMIT
- 195. выбрать и отсортировать ВСЕ (*) * – всегда, когда индекс не гарантирует точный порядок
- 196. выбрать OK – избежать нельзя
- 198. сортировать все плохо …
- 200. лишний удар по CPU/RAM/IO :(
- 201. как убирать mysql сортировку ?
- 202. строить более другие индексы
- 203. ставить более другой софт
- 204. умеет и “ обычный ” поиск !
- 205. трюки про WHERE вместо LIMIT ( я не пробовал, но говорят, возможно)
- 206. … именно в таком порядке.
- 207. более практический пример ?
- 208. импортируем дамп Wikipedia
- 209. XML дамп -> 2 толстые таблицы хочется – а) одну б) тонкую !
- 210. INSERT INTO my content SELECT t.old_id, p.page_id, UNIX_TIMESTAMP(p.page_touched), p.page_len, p.page_title, COMPRESS(t.old_text) FROM text t, page p WHERE t.old_id=p.page_latest AND page_namespace=0 AND page_is_redirect=0; 15 GB text, 0.5 GB page, ~4.5M rows tps=~200, bi/bo=~1 MB/sec ~200 MB .MYD in ~20 mins, ETA 10+ hrs
- 211. mysql> EXPLAIN SELECT t.old_id, ... \G ********************** 1. row ********************** table: p age type: ref key: name_title ref: const rows: 4435392 Extra: Using where ********************** 2. row ********************** table: t ext type: eq_ref key: PRIMARY ref: wiki.p.page_latest rows: 1
- 212. что хотим? scan 15 GB text, join 0.5 GB page
- 213. почему не выходит ? … FROM text t, page p WHERE t.old_id= p.page_latest
- 214. решение – index(page_latest)
- 215. еще пришлось STRAIGHT_JOIN (optimizer опять лажанул!)
- 216. результат – 40 минут , включая CREATE INDEX
- 218. так зачем же знать алгоритмы?
- 219. “ did we learn something today?”
- 221. как устроено B- дерево
- 222. как работает индекс
- 223. как работают выборки
- 224. зачем нужны full-scans
- 225. как работает сортировка с LIMIT
- 226. чего можно добиться в идеале – в теории
- 227. … и как оно, бывает, не работает – на практике !
- 228. а толку?!
- 229. чего ждать от БД
- 230. чего не ждать
- 231. как и что тестировать
- 232. как объяснять потом результаты
- 234. в итоге – как заставлять таки работать
- 236. … БЫСТРО работать.
- 237. “ это все ” (с) вопросы ?!
Editor's Notes
- #2: Объявляю в хате доклад. Меня зовут Андрей Аксенов, и в этом докладе я хочу поделиться своими философскими соображениями на неожиданную тему – зачем вообще разработчику знать алгоритмы.
- #3: Уверен, что немалой части зала крайне интересно – кто вообще этот человек с микрофоном, и зачем нам его занудная философия ? Вопрос актуальный, нужно пояснить.