Integrating Apache NiFi and Apache Flink
Download as PPTX, PDF7 likes1,451 views

Hortonworks DataFlow delivers data to streaming analytics platforms, inclusive of Storm, Spark and Flink These are slides from an Apache Flink Meetup: Integration of Apache Flink and Apache Nifi, Feb 4 2016.




![Page5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Apache NiFi
• Powerful and reliable system to process and
distribute data
• Directed graphs of data routing and transformation
• Web-based User Interface for creating, monitoring,
& controlling data flows
• Highly configurable - modify data flow at runtime,
dynamically prioritize data
• Data Provenance tracks data through entire
system
• Easily extensible through development of custom
components
[1] https://nifi.apache.org/](https://image.slidesharecdn.com/integratingnifiandflink-160205173646/85/Integrating-Apache-NiFi-and-Apache-Flink-5-320.jpg)











![Page18 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Flink + NiFi Integration
• Use Site-To-Site Client in Flink Streaming
• NiFiSource to pull data from NiFi Output Port
• NiFiSink to push data to NiFi Input Port
• NiFiDataPacket to represent data to/from NiFi (think FlowFile)
public interface NiFiDataPacket {
byte[] getContent();
Map<String, String> getAttributes();
}](https://image.slidesharecdn.com/integratingnifiandflink-160205173646/85/Integrating-Apache-NiFi-and-Apache-Flink-18-320.jpg)










![Page29 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Summary
• Use NiFi to drive data from sources to Flink
• Leverage Flink results to adjust your dataflows
Sources
• [1] https://nifi.apache.org/
Resources
• https://github.com/bbende/nifi-streaming-examples
• https://github.com/apache/flink/tree/master/flink-examples/flink-examples-streaming
• https://flink.apache.org/news/2015/02/09/streaming-example.html
Contact Info:
• Email: bbende@hortonworks.com
• Twitter: @bbende](https://image.slidesharecdn.com/integratingnifiandflink-160205173646/85/Integrating-Apache-NiFi-and-Apache-Flink-29-320.jpg)































Ad
More Related Content
What's hot (17)
Similar to Integrating Apache NiFi and Apache Flink (20)















Ad
Recently uploaded (20)




















Ad
Integrating Apache NiFi and Apache Flink
- 1. Page1 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Integrating Apache NiFi and Apache Flink Feb 4th 2016 Bryan Bende – Member of Technical Staff
- 2. Page2 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Outline • Introduction to NiFi • NiFi Site-To-Site • Flink + NiFi Integration • Use Case Discussion
- 3. Page3 © Hortonworks Inc. 2011 – 2015. All Rights Reserved About Me • Member of Technical Staff at Hortonworks • Apache NiFi Committer & PMC Member since June 2015 • Contributed NiFi + Flink Streaming Integration • Twitter: @bbende / Blog: bryanbende.com
- 4. Page4 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Introduction to Apache NiFi
- 5. Page5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Apache NiFi • Powerful and reliable system to process and distribute data • Directed graphs of data routing and transformation • Web-based User Interface for creating, monitoring, & controlling data flows • Highly configurable - modify data flow at runtime, dynamically prioritize data • Data Provenance tracks data through entire system • Easily extensible through development of custom components [1] https://nifi.apache.org/
- 6. Page6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi - Terminology FlowFile • Unit of data moving through the system • Content + Attributes (key/value pairs) Processor • Performs the work, can access FlowFiles Connection • Links between processors • Queues that can be dynamically prioritized Process Group • Set of processors and their connections • Receive data via input ports, send data via output ports
- 7. Page7 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi - User Interface • Drag and drop processors to build a flow • Start, stop, and configure components in real time • View errors and corresponding error messages • View statistics and health of data flow • Create templates of common processor & connections
- 8. Page8 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi - Provenance • Tracks data at each point as it flows through the system • Records, indexes, and makes events available for display • Handles fan-in/fan-out, i.e. merging and splitting data • View attributes and content at given points in time
- 9. Page9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi - Queue Prioritization • Configure a prioritizer per connection • Determine what is important for your data – time based, arrival order, importance of a data set • Funnel many connections down to a single connection to prioritize across data sets • Develop your own prioritizer if needed
- 10. Page10 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi - Extensibility Built from the ground up with extensions in mind Service-loader pattern for… • Processors • Controller Services • Reporting Tasks • Prioritizers Extensions packaged as NiFi Archives (NARs) • Deploy NiFi lib directory and restart • Provides ClassLoader isolation • Same model as standard components
- 11. Page11 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi - Architecture OS/Host JVM Flow Controller Web Server Processor 1 Extension N FlowFile Repository Content Repository Provenance Repository Local Storage OS/Host JVM Flow Controller Web Server Processor 1 Extension N FlowFile Repository Content Repository Provenance Repository Local Storage OS/Host JVM NiFi Cluster Manager – Request Replicator Web Server Master NiFi Cluster Manager (NCM) OS/Host JVM Flow Controller Web Server Processor 1 Extension N FlowFile Repository Content Repository Provenance Repository Local Storage Slaves NiFi Nodes
- 12. Page12 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi Site-To-Site
- 13. Page13 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi Site-To-Site • Direct communication between two NiFi instances • Push to Input Port on receiver, or Pull from Output Port on source • Communicate between clusters, standalone instances, or both • Handles load balancing and reliable delivery • Secure connections using certificates (optional)
- 14. Page14 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Site-To-Site Push • Source connects Remote Process Group to Input Port on destination • Site-To-Site takes care of load balancing across the nodes in the cluster NCM Node 1 Input Port Node 2 Input Port Standalone NiFi RPG
- 15. Page15 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Site-To-Site Pull • Destination connects Remote Process Group to Output Port on the source • If source was a cluster, each node would pull from each node in cluster NCM Node 1 RPG Node 2 RPG Standalone NiFi Output Port
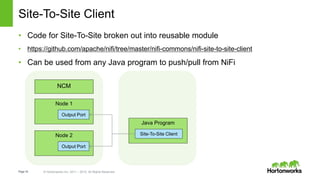
- 16. Page16 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Site-To-Site Client • Code for Site-To-Site broken out into reusable module • https://github.com/apache/nifi/tree/master/nifi-commons/nifi-site-to-site-client • Can be used from any Java program to push/pull from NiFi Java Program Site-To-Site Client Node 1 Output Port NCM Node 2 Output Port
- 17. Page17 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Flink + NiFi Integration
- 18. Page18 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Flink + NiFi Integration • Use Site-To-Site Client in Flink Streaming • NiFiSource to pull data from NiFi Output Port • NiFiSink to push data to NiFi Input Port • NiFiDataPacket to represent data to/from NiFi (think FlowFile) public interface NiFiDataPacket { byte[] getContent(); Map<String, String> getAttributes(); }
- 19. Page19 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi Source Example StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); SiteToSiteClientConfig clientConfig = new SiteToSiteClient.Builder() .url("http://localhost:8080/nifi") .portName("Data for Flink") .requestBatchCount(…) .buildConfig(); SourceFunction<NiFiDataPacket> nifiSource = new NiFiSource(clientConfig); DataStream<NiFiDataPacket> streamSource = env.addSource(nifiSource);
- 20. Page20 © Hortonworks Inc. 2011 – 2015. All Rights Reserved NiFi Sink Example StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); SiteToSiteClientConfig clientConfig = new SiteToSiteClient.Builder() .url("http://localhost:8080/nifi") .portName("Data from Flink") .buildConfig(); // Creates a NiFiDataPacket from incoming data of a given type // Here we are creating NiFiDataPackets for each String NiFiDataPacketBuilder<String> dpb = ... DataStreamSink<String> dataStream = ... .addSink(new NiFiSink<>(clientConfig, dpb));
- 21. Page21 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Use Case Discussion
- 22. Page22 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Drive Data to Flink for Analysis NiFi Flink NiFi NiFi • Drive data from sources to central data center for analysis • Tiered collection approach at various locations, think regional data centers Edge Edge Core
- 23. Page23 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Dynamically Adjusting Data Flow • Push analytic results from Flink back to NiFi • Push results back to edge locations/devices to change behavior NiFi Flink NiFi NiFi Edge Edge Core
- 24. Page24 © Hortonworks Inc. 2011 – 2015. All Rights Reserved 1. Logs filtered by level and sent from Edge -> Core 2. Flink produces new filter levels based on rate & sends back to core 3. Edge polls core for new filter levels & updates filtering Example: Dynamic Log Collection Core NiFi Flink Edge NiFi Logs Logs New Filters Logs Output Log Input Log Output Result Input Store Result Service Fetch ResultPoll Service Filter New Filters New Filters Poll Analytic
- 25. Page25 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Dynamic Log Collection – Edge NiFi
- 26. Page26 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Dynamic Log Collection – Core NiFi
- 27. Page27 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Dynamic Log Collection – Flink Streaming StreamExecutionEnvironment env = ... SiteToSiteClientConfig clientConfig = getSourceConfig(props); DataStream<NiFiDataPacket> streamSource = env.addSource(new NiFiSource(clientConfig)); int windowMs = ... LogLevelFlatMap logLevelFlatMap = new LogLevelFlatMap(...); DataStream<LogLevels> counts = streamSource.flatMap(logLevelFlatMap) .timeWindowAll(Time.of(windowSize, TimeUnit.MILLISECONDS)) .apply(new LogLevelWindowCounter()); double rate = ... SiteToSiteClientConfig sinkConfig = getSinkConfig(props); NiFiDataPacketBuilder<LogLevels> builder = new DictionaryBuilder(window, rate); counts.addSink(new NiFiSink<>(sinkConfig, builder));
- 28. Page28 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Dynamic Log Collection – Full Flow NiFi Flink NiFi NiFi Edge Edge Core Logs Logs Logs New Filters New Filters New Filters
- 29. Page29 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Summary • Use NiFi to drive data from sources to Flink • Leverage Flink results to adjust your dataflows Sources • [1] https://nifi.apache.org/ Resources • https://github.com/bbende/nifi-streaming-examples • https://github.com/apache/flink/tree/master/flink-examples/flink-examples-streaming • https://flink.apache.org/news/2015/02/09/streaming-example.html Contact Info: • Email: [email protected] • Twitter: @bbende
- 30. Page30 © Hortonworks Inc. 2011 – 2015. All Rights Reserved Thank you