Building data pipelines with kite
Download as PPTX, PDF16 likes5,671 views

Data ingest is a deceptively hard problem. In the world of big data processing, it becomes exponentially more difficult. It's not sufficient to simply land data on a system, that data must be ready for processing and analysis. The Kite SDK is a data API designed for solving the issues related to data infest and preparation. In this talk you'll see how Kite can be used for everything from simple tasks to production ready data pipelines in minutes.




















































































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Building data pipelines with kite (20)




















Ad
More from Joey Echeverria (12)












Recently uploaded (20)




















Building data pipelines with kite
- 1. Building Data Pipelines with the Kite SDK Joey Echeverria // Software Engineer
- 2. 2 Problem
- 4. 4 Hadoop ©2015 Cloudera, Inc. All rights reserved.
- 5. 5 Logs ©2015 Cloudera, Inc. All rights reserved. Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk syslog Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk Log Files Apache HTTPD Local Disk syslog Kafka Kafka Flume HDFS
- 6. 6 RDBMS ©2015 Cloudera, Inc. All rights reserved. Sqoop HDFS RDBMS
- 7. 7 Sea of text files ©2015 Cloudera, Inc. All rights reserved. CSV CSV CSV CSV CSV CSV CSV CSV CSV CSV
- 8. 8 A note on Hadoop
- 9. 9 Hadoop • Technically: – HDFS, YARN, MapReduce • Hadoop ecosystem: – Hadoop, HBase, Flume, Sqoop, Kafak, Oozie, Hive, Impala, Pig, Crunch, Spark, etc. – I’ll also call this just “Hadoop” ©2015 Cloudera, Inc. All rights reserved.
- 10. 10 Introduction to the Kite SDK ©2015 Cloudera, Inc. All rights reserved.
- 11. 11 • Hadoop is all about data • Bring all of your data to one platform • Access data using the best engine for your use case Data ©2015 Cloudera, Inc. All rights reserved.
- 12. 12 • Hadoop ecosystem built from open source components • Benefits: – Shared investments – No vendor lock-in – Fast evolution • Costs: – APIs tend to be low-level – Integration is ad-hoc Open source core ©2015 Cloudera, Inc. All rights reserved.
- 13. 13 • HDFS – Filesystem • HBase – Byte array keys -> byte array values Storage APIs ©2015 Cloudera, Inc. All rights reserved.
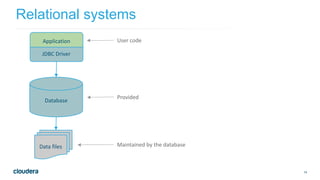
- 14. 14 Relational systems ©2015 Cloudera, Inc. All rights reserved. Database Data files User code Provided Maintained by the database Application JDBC Driver
- 15. 15 Hadoop without Kite ©2015 Cloudera, Inc. All rights reserved. Application Database Data files Data files HBase User code Application JDBC Driver
- 16. 16 Hadoop with Kite ©2015 Cloudera, Inc. All rights reserved. ApplicationApplication Database Data files Data files Kite HBase Data files HBase Maintained by the Kite Application JDBC Driver
- 17. 17 • Kite is the data API for the Hadoop ecosystem • Kite makes it easy to put your data into Hadoop and to use it once it’s there. Kite ©2015 Cloudera, Inc. All rights reserved.
- 18. 18 • Data is stored in datasets • Datasets are made up of entities • Related datasets are grouped into namespaces Abstractions ©2015 Cloudera, Inc. All rights reserved.
- 19. 19 • A collection of entities/records – Like a relational database table • Data types and field names defined by an Avro schema • Identified by URI – dataset:hdfs:/datasets/movie/ratings – dataset:hive:movie/ratings – dataset:hbase:zk1,zk2,zk3/ratings Datasets ©2015 Cloudera, Inc. All rights reserved.
- 20. 20 • A single record in a dataset – Think row in a relational database table • Entities can be complex and nested – Avro compiled objects – Avro generic objects – Plain old java objects (POJOs) Entities ©2015 Cloudera, Inc. All rights reserved.
- 21. 21 • Namespaces group related datasets – Think database or schema in a relational system • Dataset names are unique within the same namespace Namespaces ©2015 Cloudera, Inc. All rights reserved.
- 22. 22 Schem e Pattern Example Hive dataset:hive:<namespace>/<dataset- name> dataset:hive:movielens/movies HDFS dataset:hdfs:/<path>/<namespace>/<datas et-name> dataset:hdfs:/datasets/movielens/movies Local FS dataset:file:/<path>/<namespace>/<dataset -name> dataset:file:/tmp/data/movielens/movies HBase dataset:hbase:<zookeeper- hosts>/<dataset-name> dataset:hbase:zoo-1,zoo-2,zoo-3/movies Dataset URIs ©2015 Cloudera, Inc. All rights reserved. • Hive URIs accept an optional location parameter for external tables – dataset:hive:movielens/movies?location=/datasets/movielens/movies • HDFS URIs accept an optional nameservice and host – dataset:hdfs://namenode:8020/datasets/movielens/movies
- 23. 23 • Ingestion framework – Integrates with Sqoop, Flume, and Kafka; doesn’t replace them • ETL tool – Basic command-line tool – Complete ETL tools can build on Kite • Processing language – SQL, Crunch, MapReduce, Spark, Pig, etc. What Kite isn’t ©2015 Cloudera, Inc. All rights reserved.
- 24. 24 • Flume – Stream log events directly into Kite datasets • Sqoop – Ingest relational database tables into Kite datasets • Kafka – Integration is through Flafka (Flume/Kafka integration) Ingest integration ©2015 Cloudera, Inc. All rights reserved.
- 25. 25 • MapReduce – Input/OutputFormats • Crunch – Source and target • Spark – Use Input/OutputFormats to convert datasets to RDDs • Impala, Hive, Pig – Use underlying file format support Data processing integration ©2015 Cloudera, Inc. All rights reserved.
- 26. 26 • Codifies best practices • Interoperability • Shields you from Hadoop, Hive, etc. version changes • Get up and running faster What does Kite do for you? ©2015 Cloudera, Inc. All rights reserved.
- 27. 27 • Kite is Apache 2.0 licensed • Hosted on GitHub • Compatibility: – Test against upstream Apache Hadoop 1.0 and 2.3 as well as CDH4/5 • Contributors: – Cloudera, Cerner, Capital One, Intel, Pivotal • Distributions: – Cloudera, Hortonworks, Pivotal, MapR Open source ©2015 Cloudera, Inc. All rights reserved.
- 28. 28 • Site – http://kitesdk.org • Kite guide – http://tiny.cloudera.com/KiteGuide • Data module overview – http://tiny.cloudera.com/Datasets • Command-line interface tutorial – http://tiny.cloudera.com/KiteCLI • Kite examples – https://github.com/kite-sdk/kite-examples Resources ©2015 Cloudera, Inc. All rights reserved.
- 29. 29 Using Kite ©2015 Cloudera, Inc. All rights reserved.
- 30. 30 Architecture ©2015 Cloudera, Inc. All rights reserved. CSV Kite CLI Schema Kite CLI HDFS infer Avro schema create dataset Kite CLI load dataset Crunch HDFS ImpalaReport
- 31. 31 Dataset schemes • Pluggable dataset interface with multiple schemes • Schemes determine underlying storage mechanism and metadata provider • HDFS – Data stored in HDFS directories – Metadata stored in an Avro schema file and a Java properties file in the dataset directory • Hive – Data stored in HDFS directories – Metadata stored in Hive metastore • HBase – Data and metadata ©2015 Cloudera, Inc. All rights reserved.
- 32. 32 Which scheme? • HDFS – Best for raw data and intermediate data in an ETL pipeline – No SQL access • Hive – Best for data that is ready for query or SQL ETL – No performance difference between Hive and HDFS-backed datasets • HBase – Best for online serving applications – Provides sorted keys – Optimistic concurrency control ©2015 Cloudera, Inc. All rights reserved.
- 33. 33 Dataset formats • Physical serialization format • Avro – Row-based storage format with schemas and compression • Parquet – Column-based storage format optimized for query access • CSV – Read-only format – Used by ETL jobs to read raw data files ©2015 Cloudera, Inc. All rights reserved.
- 34. 34 Avro ©2015 Cloudera, Inc. All rights reserved. 1 2 3 4 5 6 7
- 35. 35 Parquet ©2015 Cloudera, Inc. All rights reserved. a b c d e f g h i j
- 36. 36 When to choose which format • Avro – Access all fields of a record at the same time – Intermediate/non-long-lived data • Parquet – Access subset of fields/columns at a time – SQL tables (Impala/Hive) ©2015 Cloudera, Inc. All rights reserved.
- 37. 37 Compression type • Uncompressed – Nope. Nope. Nope. Nope. • Snappy – Default – Balances performance and speed – Fastest for query • Deflate/gzip – Good for archived/infrequently accessed data – Slow writes, decent read performance ©2015 Cloudera, Inc. All rights reserved.
- 38. 38 • Schema – Record fields, like a table definition Configuration ©2015 Cloudera, Inc. All rights reserved.
- 39. 39 • Demo schema inference/generation Demo ©2015 Cloudera, Inc. All rights reserved.
- 40. 40 • Schema – Record fields, like a table definition • Partition strategy – Physical layout/storage key definition Configuration ©2015 Cloudera, Inc. All rights reserved.
- 41. 41 • Map entity fields to partitions • Unlike Hive, partitions are tied to per-entity data • Common partition types: values, hashes, timestamp parsing Partitioning ©2015 Cloudera, Inc. All rights reserved.
- 42. 42 • Demo partition definition Demo ©2015 Cloudera, Inc. All rights reserved.
- 43. 43 • Experiment before understanding • Creates configuration files • Handles dataset lifecycle – create, update, delete • Basic ETL tasks – copy datasets – transform individual records • Import CSV Command-line interface ©2015 Cloudera, Inc. All rights reserved.
- 44. 44 1. Describe your data kite-dataset obj-schema org.grouplens.Rating --jar group-lens-1.0.jar -o rating.avsc 2. Describe your layout kite-dataset partition-config ts:year ts:month ts:day --schema rating.avsc -o ymd.json 3. Create a dataset kite-dataset create ratings --schema rating.avsc --partition-by ymd.json Example ©2015 Cloudera, Inc. All rights reserved.
- 45. 45 • Two packages – Standalone for on-cluster use – Tarball with dependencies for remote access (CDH5-only) • Environment variables – HIVE_HOME, HIVE_CONF_DIR, HBASE_HOME, HADOOP_MAPRED_HOME, HADOOP_COMMON_HOME • Debug environment – debug=true ./kite-dataset <command> • Verbose output – ./kite-dataset -v <command> Command-line interface ©2015 Cloudera, Inc. All rights reserved.
- 46. 46 • Demo dataset creation with the CLI • Demo dataset loading with the CLI Demo ©2015 Cloudera, Inc. All rights reserved.
- 47. 47 Maven parent POM • Consolidated Kite and Hadoop dependencies • To use: – Set kite-app-parent-cdh4 or kite-app-parent-cdh5 as your project’s parent POM <parent> <group>org.kitesdk</group> <artifact>kite-app-parent-cdh5</artifact> <version>0.17.1</version> </parent> ©2015 Cloudera, Inc. All rights reserved.
- 48. 48 • Demo maven project using Kite parent pom Demo ©2015 Cloudera, Inc. All rights reserved.
- 49. 49 • Java dataflow API • Runs pipelines in memory, MapReduce, or Spark • Parallel collections Crunch ©2015 Cloudera, Inc. All rights reserved.
- 50. 50 Use Crunch with Kite • CrunchDatasets helper class – CrunchDatasets.asSource(View view) – CrunchDatasets.asTarget(View view) • Supports Crunch write modes: default, overwrite and append PCollection<Movie> movies = getPipeline().read( CrunchDatasets.asSource(“dataset:hive:movies”, Movie.class)); • Re-partition data before writing PCollection<Movie> partitionedMovies = CrunchDatasets. partition(movies, targetDataset); ©2015 Cloudera, Inc. All rights reserved.
- 51. 51 • Demo crunch processing on Kite Demo ©2015 Cloudera, Inc. All rights reserved.
- 52. 52 Impala • Massively parallel processing (MPP) database • SQL • Distributed • Fast ©2015 Cloudera, Inc. All rights reserved.
- 53. 53 • Demo querying a Kite dataset with Impala Demo ©2015 Cloudera, Inc. All rights reserved.
- 54. 54 Architecture ©2015 Cloudera, Inc. All rights reserved. CSV Kite CLI Schema Kite CLI HDFS infer Avro schema create dataset Kite CLI load dataset Crunch HDFS ImpalaReport
- 55. Thank you