
























































































Ad
More Related Content
What's hot (20)
Recently uploaded (20)











![PRE-NATAL GRnnnmnnnnmmOWTH seminar[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pre-natalgrowthseminar1-250427093235-de04befc-thumbnail.jpg?width=560&fit=bounds)






Ad
Big Data Architecture and Design Patterns
- 1. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. John Yeung, AWS Solutions Architect 31 October 2017 Big Data Architecture & Design Patterns AWS Big Data and Machine Learning Day | Hong Kong
- 2. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. What to expect from the session Big Data Challenges Architectural Principles Design Patterns Demo (around 15 mins)
- 3. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Ever-Increasing Big Data Volume Velocity Variety
- 4. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Big Data Evolution Batch Processing Stream Processing Machine Learning
- 5. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Plenty of Tools Amazon Glacier S3 DynamoDB RDS EMR Amazon Redshift Data Pipeline Amazon Kinesis Amazon Kinesis Streams app Lambda Amazon ML SQS ElastiCache DynamoDB Streams Amazon Elasticsearch Service Amazon Kinesis Analytics
- 6. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Big Data Challenges Why? How? What tools should I use? Is there a reference architecture?
- 7. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Architectural Principles
- 8. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Architecture Principles #1: Build Decoupled Systems • Data → Store → Process → Store → Analyze → Answers #2: Use Right Tool for the Job • Data structure, latency, throughput, access patterns #3: Leverage AWS Managed Services • Scalable/elastic, available, reliable, secure, no/low admin #4: Use Lambda Architecture Ideas • Immutable (append-only) log, batch/speed/serving layer #5: Be Cost-conscious • Big data ≠ big cost
- 9. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Simplify Big Data Processing COLLECT STORE PROCESS/ ANALYZE CONSUME 1. Time to answer (Latency) 2. Throughput 3. Cost
- 10. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. COLLECT
- 11. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Types of DataCOLLECT Mobile apps Web apps Data centers AWS Direct Connect RECORDS Applications In-memory data Database records AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail DOCUMENTS FILES LoggingTransport Search documents Log files Messaging Message MESSAGES Messaging Messages Devices Sensors & IoT platforms AWS IoT STREAMS IoT Data streams Transaction-based File-based Event-based
- 12. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Store
- 13. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. STORE Devices Sensors & IoT platforms AWS IoT STREAMS IoT COLLECT AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail DOCUMENTS FILES LoggingTransport Messaging Message MESSAGES MessagingApplications Mobile apps Web apps Data centers AWS Direct Connect RECORDS Types of Data Stores Database SQL & NoSQL databases Search Search engines File store File systems Queue Message queues Stream storage Pub/sub message queues In-memory Caches
- 14. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. In-memory COLLECT STORE Mobile apps Web apps Data centers AWS Direct Connect RECORDS Database AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail DOCUMENTS FILES Search Messaging Message MESSAGES Devices Sensors & IoT platforms AWS IoT STREAMS Apache Kafka Amazon Kinesis Streams Amazon Kinesis Firehose Amazon DynamoDB Streams Hot Stream Amazon SQS Message Amazon S3 File LoggingIoTApplicationsTransportMessaging In-memory, Database, Search
- 15. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. COLLECT STORE Mobile apps Web apps Data centers AWS Direct Connect RECORDS AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail DOCUMENTS FILES Messaging Message MESSAGES Devices Sensors & IoT platforms AWS IoT STREAMS Apache Kafka Amazon Kinesis Streams Amazon Kinesis Firehose Amazon DynamoDB Streams Hot Stream Amazon SQS Message Amazon Elasticsearch Service Amazon DynamoDB Amazon S3 Amazon ElastiCache Amazon RDS SearchSQLNoSQLCacheFile LoggingIoTApplicationsTransportMessaging Amazon ElastiCache • Managed Memcached or Redis service Amazon DynamoDB • Managed NoSQL database service Amazon RDS • Managed relational database service Amazon Elasticsearch Service • Managed Elasticsearch service
- 16. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Use the Right Tool for the Job Data Tier Search Amazon Elasticsearch Service In-memory Amazon ElastiCache Redis Memcached SQL Amazon Aurora Amazon RDS MySQL PostgreSQL Oracle SQL Server NoSQL Amazon DynamoDB Cassandra HBase MongoDB
- 17. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. In-memory COLLECT STORE Mobile apps Web apps Data centers AWS Direct Connect RECORDS Database AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail DOCUMENTS FILES Search Messaging Message MESSAGES Devices Sensors & IoT platforms AWS IoT STREAMS Apache Kafka Amazon Kinesis Streams Amazon Kinesis Firehose Amazon DynamoDB Streams Hot Stream Amazon S3 Amazon SQS Message Amazon S3 File LoggingIoTApplicationsTransportMessaging File Storage
- 18. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Why Is Amazon S3 Good for Big Data Natively supported by big data frameworks (Spark, Hive, Presto, etc.) Multiple & heterogeneous analysis clusters can use the same data Unlimited number of objects and volume of data Very high bandwidth – no aggregate throughput limit Designed for 99.99% availability – can tolerate zone failure Designed for 99.999999999% durability No need to pay for data replication Native support for versioning Tiered-storage (Standard, IA, Amazon Glacier) via life-cycle policies Secure – SSL, client/server-side encryption at rest Low cost
- 19. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. In-memory Amazon Kinesis Firehose Amazon Kinesis Streams Apache Kafka Amazon DynamoDB Streams Amazon SQS Amazon SQS • Managed message queue service Apache Kafka • High throughput distributed streaming platform Amazon Kinesis Streams • Managed stream storage + processing Amazon Kinesis Firehose • Managed data delivery Amazon DynamoDB • Managed NoSQL database • Tables can be stream-enabled Message & Stream Storage Devices Sensors & IoT platforms AWS IoT STREAMS IoT COLLECT STORE Mobile apps Web apps Data centers AWS Direct Connect RECORDS Database Applications AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail DOCUMENTS FILES Search File store LoggingTransport Messaging Message MESSAGES Messaging Message Stream
- 20. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Why Stream Storage Decouple producers & consumers Persistent buffer Collect multiple streams Preserve client ordering Parallel consumption 4 4 3 3 2 2 1 1 4 3 2 1 4 3 2 1 4 3 2 1 4 3 2 1 4 4 3 3 2 2 1 1 shard 1 / partition 1 shard 2 / partition 2 Consumer 1 Count of red = 4 Count of violet = 4 Consumer 2 Count of blue = 4 Count of green = 4 DynamoDB stream Amazon Kinesis stream Kafka topic
- 21. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. What Stream Storage should I use? Amazon DynamoDB Streams Amazon Kinesis Streams Amazon Kinesis Firehose Apache Kafka Amazon SQS AWS managed service Yes Yes Yes No Yes Guaranteed ordering Yes Yes Yes Yes No Delivery exactly-once at-least-once exactly-once at-least-once at-least-once Data retention period 24 hours 7 days N/A Configurable 14 days Availability 3 AZ 3 AZ 3 AZ Configurable 3 AZ Scale / throughput No limit / ~ table IOPS No limit / ~ shards No limit / automatic No limit / ~ nodes No limits / automatic Parallel clients Yes Yes No Yes No Stream MapReduce Yes Yes N/A Yes N/A Record/object size 400 KB 1 MB Redshift row size Configurable 256 KB Cost Higher (table cost) Low Low Low (+admin) Low-medium Hot Warm
- 22. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Which Data Store Should I Use Data Structure → Fixed schema, JSON, key-value Access Patterns → Store data in the format you will access it Data Characteristics → Hot, Warm, Cold Cost → Right cost
- 23. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Data Structure and Access Patterns Access Patterns What to use? Put/Get (key, value) In-memory, NoSQL Simple relationships → 1:N, M:N NoSQL Multi-table joins, transaction, SQL SQL Faceting, search Search Data Structure What to use? Fixed schema SQL, NoSQL Schema-free (JSON) NoSQL, Search (Key, value) In-memory, NoSQL
- 24. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. What is the temperature of your data
- 25. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Data characteristics: Hot, Warm or Cold Hot Warm Cold Volume MB–GB GB–TB PB–EB Item size B–KB KB–MB KB–TB Latency ms ms, sec min, hrs Durability Low–high High Very high Request rate Very high High Low Cost/GB $$-$ $-¢¢ ¢ Hot data Warm data Cold data
- 26. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. In-memory SQL Request rate High Low Cost/GB High Low Latency Low High Data volume Low High Amazon Glacier Structure NoSQL Hot data Warm data Cold data Low High
- 27. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Which Data Store Should I Use Amazon ElastiCache Amazon DynamoDB Amazon RDS/Aurora Amazon ES Amazon S3 Amazon Glacier Average latency ms ms ms, sec ms,sec ms,sec,min (~ size) hrs Typical data stored GB GB–TBs (no limit) GB–TB (64 TB max) GB–TB MB–PB (no limit) GB–PB (no limit) Typical item size B-KB KB (400 KB max) KB (64 KB max) B-KB (2 GB max) KB-TB (5 TB max) GB (40 TB max) Request Rate High – very high Very high (no limit) High High Low – high (no limit) Very low Storage cost GB/month $$ ¢¢ ¢¢ ¢¢ ¢ ¢4/10 Durability Low - moderate Very high Very high High Very high Very high Availability High 2 AZ Very high 3 AZ Very high 3 AZ High 2 AZ Very high 3 AZ Very high 3 AZ Hot data Warm data Cold data
- 28. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. PROCESS / ANALYZE
- 29. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Analytics & Frameworks Interactive Takes seconds Example: Self-service dashboards Amazon Redshift, Amazon Athena, Amazon EMR (Presto, Spark) Batch Takes minutes to hours Example: Daily/weekly/monthly reports Amazon EMR (MapReduce, Hive, Pig, Spark) Message Takes milliseconds to seconds Example: Message processing Amazon SQS applications on Amazon EC2 Stream Takes milliseconds to seconds Example: Fraud alerts, 1 minute metrics Amazon EMR (Spark Streaming), Amazon Kinesis Analytics, KCL, Storm, AWS Lambda PROCESS / ANALYZE Amazon Machine Learning MLMessage Amazon SQS apps Amazon EC2 Streaming Amazon Kinesis Analytics KCL apps AWS Lambda Stream Amazon EC2 Amazon EMR Fast Amazon Redshift Presto Amazon EMR FastSlow Amazon Athena BatchInteractive
- 30. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. What about ETL https://aws.amazon.com/big-data/partner-solutions/ ETLSTORE PROCESS / ANALYZE Data Integration Partners Reduce the effort to move, cleanse, synchronize, manage, and automatize data related processes. AWS Glue AWS Glue is a fully managed ETL service that makes it easy to understand your data sources, prepare the data, and move it reliably between data stores New
- 31. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. CONSUME
- 32. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. COLLECT STORE CONSUMEPROCESS / ANALYZE Amazon Elasticsearch Service Apache Kafka Amazon SQS Amazon Kinesis Streams Amazon Kinesis Firehose Amazon DynamoDB Amazon S3 Amazon ElastiCache Amazon RDS Amazon DynamoDB Streams HotHotWarm FileMessage Stream Mobile apps Web apps Devices Messaging Message Sensors & IoT platforms AWS IoT Data centers AWS Direct Connect AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail RECORDS DOCUMENTS FILES MESSAGES STREAMS LoggingIoTApplicationsTransportMessaging ETL SearchSQLNoSQLCache Streaming Amazon Kinesis Analytics KCL apps AWS Lambda Fast Stream Amazon EC2 Amazon EMR Amazon SQS apps Amazon Redshift Amazon Machine Learning Presto Amazon EMR FastSlow Amazon EC2 Amazon Athena BatchMessageInteractiveML
- 33. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. STORE CONSUMEPROCESS / ANALYZE Amazon QuickSight Apps & Services Analysis&visualizationNotebook s IDEAPI Applications & API Analysis and visualization Notebooks IDE Business users Data scientist, developers COLLECT ETL
- 34. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Put them together
- 35. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Streaming Amazon Kinesis Analytics KCL apps AWS Lambda COLLECT STORE CONSUME PROCESS / ANALYZE Amazon Elasticsearch Service Apache Kafka Amazon SQS Amazon Kinesis Streams Amazon Kinesis Firehose Amazon DynamoDB Amazon S3 Amazon ElastiCache Amazon RDS Amazon DynamoDB Streams HotHotWarm Fast Stream SearchSQLNoSQLCacheFileMessageStream Amazon EC2 Mobile apps Web apps Devices Messaging Message Sensors & IoT platforms AWS IoT Data centers AWS Direct Connect AWS Import/Export Snowball Logging Amazon CloudWatch AWS CloudTrail RECORDS DOCUMENTS FILES MESSAGES STREAMS Amazon QuickSight Apps & Services Analysis&visualizationNotebooksIDEAPI LoggingIoTApplicationsTransportMessaging ETL Amazon EMR Amazon SQS apps Amazon Redshift Amazon Machine Learning Presto Amazon EMR FastSlow Amazon EC2 Amazon Athena BatchMessageInteractiveML
- 36. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Design Patterns
- 37. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Concept #1: Decoupled Data Bus • Storage decoupled from processing • Multiple stages Store Process Store Process Process Store
- 38. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Concept #2: Multiple Stream Processing Process Store Amazon Kinesis Amazon DynamoDB Amazon S3 AWS Lambda Amazon Kinesis Connector Library KCL • Parallel processing
- 39. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Concept #3: Multiple Data Stores Amazon EMR Amazon Kinesis AWS Lambda Amazon S3 Amazon DynamoDB Spark Streaming Amazon Kinesis Connector Library KCL Spark SQL • Analysis framework reads from or writes to multiple data stores Process Store
- 40. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon EMR Apache Kafka KCL AWS Lambda Spark Streaming Apache Storm Amazon SNS Amazon ML Notifications Amazon ElastiCache (Redis) Amazon DynamoDB Amazon RDS Amazon ES Alert App state Real-time prediction KPI DynamoDB Streams Amazon Kinesis Process Store Real-time Analytics Design Pattern
- 41. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon SQS Amazon SQS App Amazon SQS App Amazon SNS Subscribers Amazon ElastiCache (Redis) Amazon DynamoDB Amazon RDS Amazon ES Publish App state KPI Amazon SQS App Amazon SQS App Auto Scaling group Amazon SQSPriority queue Messages / events Process Store Message / Event Processing Design Pattern
- 42. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon S3 Amazon EMR Hive Pig Spark Amazon Machine Learning Consume Amazon Redshift Amazon EMR Presto Spark Batch Mode Interactive Mode Batch prediction Real-time prediction Amazon Kinesis Firehose Amazon Athena Amazon Kinesis Analytics Files Process Store Interactive & Batch Analytics Design Pattern
- 43. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Demonstration Apply what we’ve just learnt
- 44. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Real-time Analytics Design Pattern Apache Web Server Amazon Kinesis Firehose Amazon Kinesis Firehose Amazon Kinesis Analytics Amazon S3 bucket Availability Zone #1 KibanaAmazon ElasticSearch
- 45. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon Elastic Cloud Computing EC2 Amazon EC2 provides the Virtual Machines VMs, known as instances, to run your web application on the platform you choose. It allows you to configure and scale your compute capacity easily to meet changing requirements and demand. In this demo, this instance is installed with Apache Web Server which continuously generates web access log records and Amazon Kinesis Agent which streams these records to Amazon Kinesis Firehose. Apache Web Server + Amazon Kinesis Agent
- 46. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon Kinesis Firehose Amazon Kinesis Firehose is a fully managed service for delivering real-time streaming data to destinations such as Amazon Simple Storage Service (AmazonS3), Amazon Redshift, or Amazon Elasticsearch Service (Amazon ES). In this step, we will create an Amazon Kinesis Firehose delivery stream to save each log entry in Amazon S3 and to provide the log data to the Amazon Kinesis Analytics application. Amazon Kinesis Firehose
- 47. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Example: Real-time Analytics (1) Apache Web Server Amazon Kinesis Firehose Availability Zone #1 1. A Linux Instance is installed with Amazon Kinesis Agent which sends log records to Amazon Kinesis Firehose continuously. Streaming data COLLECT
- 48. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon Simple Storage Service S3 Amazon S3 has a simple web services interface that you can use to store and retrieve any amount of data, at any time, from anywhere on the web. It gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure. Examples: Web Access Log, Static Web Site and Data Lake etc. Amazon S3
- 49. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon Kinesis Analytics Amazon Kinesis Analytics enables you to query streaming data or build entire streaming applications using SQL, so that you can gain actionable insights promptly. It takes care of everything required to run your queries continuously and scales automatically to match the volume and throughput rate of your incoming data. Amazon Kinesis Analytics
- 50. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Example: Real-time Analytics (2) Apache Web Server Amazon Kinesis Firehose Amazon S3 bucket Availability Zone #1 2a. Amazon Kinesis Firehose will write each log record to Amazon Simple Storage Service S3 for durable storage. COLLECT STORE
- 51. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Example: Real-time Analytics (2) Apache Web Server Amazon Kinesis Firehose Amazon Kinesis Analytics Amazon S3 bucket Availability Zone #1 2b. Amazon Kinesis Analytics run a SQL statement against the streaming input data. COLLECT STORE PROCESS / ANALYZE
- 52. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. SQL Operations Inside Kinesis Analytics Source Stream Insert & Select (Pump) Destination Stream Amazon Kinesis Analytics CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( datetime VARCHAR(30), status INTEGER, statusCount INTEGER); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TIMESTAMP_TO_CHAR('yyyy-MM- dd''T''HH:mm:ss.SSS', LOCALTIMESTAMP) as datetime, "response" as status, COUNT(*) AS statusCount FROM "SOURCE_SQL_STREAM_001" GROUP BY "response", FLOOR(("SOURCE_SQL_STREAM_001".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') minute / 1 TO MINUTE); Amazon Kinesis Firehose
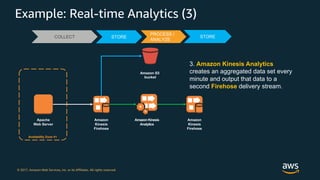
- 53. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Example: Real-time Analytics (3) Apache Web Server Amazon Kinesis Firehose Amazon Kinesis Firehose Amazon Kinesis Analytics Amazon S3 bucket Availability Zone #1 COLLECT STORE PROCESS / ANALYZE 3. Amazon Kinesis Analytics creates an aggregated data set every minute and output that data to a second Firehose delivery stream. STORE
- 54. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Amazon Elasticsearch Service ES Amazon Elasticsearch Service makes it easy to deploy, secure, operate, and scale Elasticsearch for log analytics, full text search, application monitoring, and more. Amazon Elasticsearch Service is a fully managed service that delivers real-time analytics capabilities alongside the availability, scalability, and security that production workloads require. The service offers built-in integrations with Kibana, Logstash and other AWS services. It enables you to go from raw data to actionable insights quickly and securely. Amazon Elasticsearch
- 55. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Example: Real-time Analytics (4) Apache Web Server Amazon Kinesis Firehose Amazon Kinesis Firehose Amazon Kinesis Analytics Amazon S3 bucket Availability Zone #1 Amazon ElasticSearch COLLECT STORE PROCESS / ANALYZE STORE 4. This Firehose delivery stream will write the aggregated data to an Amazon ES domain.
- 56. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Kibana Kibana lets you visualize your Elasticsearch data. It provides you interactive visualizations with various types including histograms, line graphs, pie charts, and more. It leverages the full aggregation capabilities of Elasticsearch. Kibana
- 57. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Example: Real-time Analytics (5) Apache Web Server Amazon Kinesis Firehose Amazon Kinesis Firehose Amazon Kinesis Analytics Amazon S3 bucket Availability Zone #1 KibanaAmazon ElasticSearch COLLECT STORE PROCESS / ANALYZE STORE CONSUME 5. Finally, use Kibana to visualize the result of your system.
- 58. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Implementation Steps Apache Web Server Amazon Kinesis Firehose Amazon Kinesis Firehose Amazon Kinesis Analytics Amazon S3 bucket Availability Zone #1 KibanaAmazon ElasticSearch COLLECT STORE PROCESS / ANALYZE STORE CONSUME 1 2a 2b 345 6
- 59. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Let’s build your own one in 60 mins! https://aws.amazon.com/getting-started/projects/build-log-analytics-solution/
- 60. © 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Thank you! John Yeung | [email protected]