Optimize your Machine Learning workloads (April 2019)
Download as PPTX, PDF0 likes272 views

The document discusses Amazon's machine learning services including Amazon SageMaker for building, training, and deploying machine learning models at scale. It highlights features such as one-click deployment and training, hyperparameter optimization, and model compilation to run models on different devices and frameworks. It also covers Amazon EC2 instance types optimized for machine learning workloads and Amazon Elastic Inference for accelerating inference.

















![Compiling ResNet-50 for the Raspberry Pi
Configure the compilation job
{
"RoleArn":$ROLE_ARN,
"InputConfig": {
"S3Uri":"s3://jsimon-neo/model.tar.gz",
"DataInputConfig": "{"data": [1, 3, 224, 224]}",
"Framework": "MXNET"
},
"OutputConfig": {
"S3OutputLocation": "s3://jsimon-neo/",
"TargetDevice": "rasp3b"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 300
}
}
Compile the model
$ aws sagemaker create-compilation-job
--cli-input-json file://config.json
--compilation-job-name resnet50-mxnet-pi
$ aws s3 cp s3://jsimon-neo/model-
rasp3b.tar.gz .
$ gtar tfz model-rasp3b.tar.gz
compiled.params
compiled_model.json
compiled.so
Predict with the compiled model
from dlr import DLRModel
model = DLRModel('resnet50', input_shape,
output_shape, device)
out = model.run(input_data)](https://image.slidesharecdn.com/aml4-optimizeyourmlworkloads-190405121946/85/Optimize-your-Machine-Learning-workloads-April-2019-18-320.jpg)





Optimize your Machine Learning workloads (April 2019)
- 1. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Optimizeyour MachineLearning workloads Julien Simon Global Evangelist,AI & Machine Learning @julsimon
- 2. Amazon SageMaker Fully managed hosting with auto- scaling One-click deployment Deploy Model compilation Elastic inference Inference pipelines Pre-built notebooks for common problems Built-in, high- performance algorithms Build One-click training Hyperparameter optimization Train P3DN, C5N TensorFlow on 256 GPUs DynamicTraining on MXNet Automatic ModelTuning
- 3. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
- 4. Amazon EC2 P3dn https://aws.amazon.com/blogs/aws/new-ec2-p3dn-gpu-instances-with-100-gbps-networking-local-nvme-storage-for-faster-machine-learning-p3- price-reduction/ Reduce machine learning training time Better GPU utilization Support larger, more complex models K E Y F E A T U R E S 100Gbps of networking bandwidth 8 NVIDIATesla V100 GPUs 32GB of memory per GPU (2x more P3) 96 Intel Skylake vCPUs (50% more than P3) with AVX-512
- 5. Amazon EC2 C5n https://aws.amazon.com/blogs/aws/new-c5n-instances-with-100-gbps-networking/ Intel Xeon Platinum 8000 Up to 3.5GHz single core speed Up to 100Gbit networking Based on Nitro hypervisor for bare metal-like performance
- 6. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
- 7. MakingTensorFlow faster https://aws.amazon.com/blogs/machine-learning/faster-training-with- optimized-tensorflow-1-6-on-amazon-ec2-c5-and-p3-instances/ (March 2018) Training a ResNet-50 benchmark with the synthetic ImageNet dataset using our optimized build ofTensorFlow 1.11 on a c5.18xlarge instance type is 11x faster than training on the stock binaries. https://aws.amazon.com/about-aws/whats- new/2018/10/chainer4-4_theano_1-0- 2_launch_deep_learning_ami/ (October 2018)
- 8. ScalingTensorFlow near-linearly to 256 GPUs https://aws.amazon.com/about-aws/whats-new/2018/11/tensorflow-scalability-to-256-gpus/ Stock TensorFlow AWS-Optimized TensorFlow 65% 90% scaling efficiency with 256 GPUs scaling efficiency with 256 GPUs 30m 14m training time training time Available with Amazon SageMaker and the AWS Deep Learning AMIs
- 9. Dynamic training with Apache MXNet and RIs https://aws.amazon.com/blogs/machine-learning/introducing-dynamic-training-for-deep-learning-with-amazon-ec2/ Use a variable number of instances for distributed training No loss of accuracy Coming soon spot instances, additional frameworks
- 10. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
- 11. Examples of hyperparameters Neural Networks Number of layers Hidden layer width Learning rate Embedding dimensions Dropout … XGBoost Tree depth Max leaf nodes Gamma Eta Lambda Alpha …
- 12. Automatic Model Tuning Finding the optimal set of hyper parameters 1. Manual Search (”I know what I’m doing”) 2. Grid Search (“X marks the spot”) • Typically training hundreds of models • Slow and expensive 3. Random Search (“Spray and pray”) • Works better and faster than Grid Search • But… but… but… it’s random! 4. HPO: use Machine Learning • Training fewer models • Gaussian Process Regression and Bayesian Optimization • You can now resume from a previous tuning job
- 13. Demo: HPO with Apache MXNet https://github.com/awslabs/amazon-sagemaker- examples/tree/master/hyperparameter_tuning/hpo_mxnet_mnist.ipynb
- 14. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved.
- 15. © 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Inference 90% Training 10% Predictionsdrive complexityand costinproduction
- 16. Model optimization is extremely complex
- 17. Amazon Neo: compiling models https://aws.amazon.com/blogs/aws/amazon-sagemaker-neo-train-your-machine-learning-models-once-run-them-anywhere/ • Train once, run anywhere • Frameworks and algorithms • TensorFlow, Apache MXNet, PyTorch, ONNX, and XGBoost • Hardware architectures • ARM, Intel, and NVIDIA starting today • Cadence, Qualcomm, and Xilinx hardware coming soon • Amazon SageMaker Neo is open source, enabling hardware vendors to customize it for their processors and devices: https://github.com/neo-ai/
- 18. Compiling ResNet-50 for the Raspberry Pi Configure the compilation job { "RoleArn":$ROLE_ARN, "InputConfig": { "S3Uri":"s3://jsimon-neo/model.tar.gz", "DataInputConfig": "{"data": [1, 3, 224, 224]}", "Framework": "MXNET" }, "OutputConfig": { "S3OutputLocation": "s3://jsimon-neo/", "TargetDevice": "rasp3b" }, "StoppingCondition": { "MaxRuntimeInSeconds": 300 } } Compile the model $ aws sagemaker create-compilation-job --cli-input-json file://config.json --compilation-job-name resnet50-mxnet-pi $ aws s3 cp s3://jsimon-neo/model- rasp3b.tar.gz . $ gtar tfz model-rasp3b.tar.gz compiled.params compiled_model.json compiled.so Predict with the compiled model from dlr import DLRModel model = DLRModel('resnet50', input_shape, output_shape, device) out = model.run(input_data)
- 19. Demo: compiling a pre-trained PyTorch model with Neo https://github.com/awslabs/amazon-sagemaker- examples/blob/master/advanced_functionality/pytorch_torchvision_neo/pytorch_torchvision_neo.ipynb
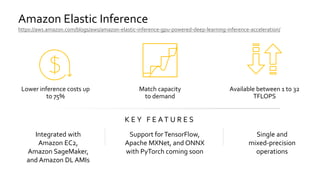
- 20. Amazon Elastic Inference https://aws.amazon.com/blogs/aws/amazon-elastic-inference-gpu-powered-deep-learning-inference-acceleration/ Match capacity to demand Available between 1 to 32 TFLOPS K E Y F E A T U R E S Integrated with Amazon EC2, Amazon SageMaker, and Amazon DL AMIs Support forTensorFlow, Apache MXNet, and ONNX with PyTorch coming soon Single and mixed-precision operations Lower inference costs up to 75%
- 22. Train & predict faster Save time Save money Save your sanity (no plumbing!)
- 23. © 2018, Amazon Web Services, Inc. or Its Affiliates. All rights reserved. Getting started https://ml.aws https://aws.amazon.com/sagemaker https://github.com/awslabs/amazon-sagemaker-examples
- 24. Thank you! © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Julien Simon Global Evangelist,AI & Machine Learning @julsimon https://medium.com/@julsimon
Editor's Notes
- #2: This talk is for builders I want to build a new app or website and I want it to work on every platform I want easily leverage AWS from my existing web or mobile apps and I don’t want to rewrite everything I want to learn about cool new development tools like React, GraphQL, CLIs, and serverless technologies I want to focus less on ops and configuration and more on my product If you recognize yourself in one of the previous sentences, you’re in the right room. TODO for the presenter : adjust the banner to the conference you will speak to.
- #3: Once your model is trained and tuned, SageMaker makes it easy to deploy in production so you can start generating predictions on new data (a process called inference). Amazon SageMaker deploys your model on an auto-scaling cluster of Amazon EC2 instances that are spread across multiple availability zones to deliver both high performance and high availability. It also includes built-in A/B testing capabilities to help you test your model and experiment with different versions to achieve the best results. For maximum versatility, we designed Amazon SageMaker in three modules – Build, Train, and Deploy – that can be used together or independently as part of any existing ML workflow you might already have in place.
- #5: 1/ The new Amazon EC2 P3dn instance 2/ With four-times the networking bandwidth and twice the GPU memory of the largest P3 instance, P3dn is ideal for large scale distributed training. No one else has anything close. 3/ P3dn.24xlarge instances offer 96vCPUs of Intel Skylake processors to reduce preprocessing time of data required for machine learning training. 3/ The enhanced networking of the P3n instance allows GPUs to be used more efficiently in multi-node configurations so training jobs complete faster. 4/ Finally, the extra GPU memory allows developers to easily handle more advanced machine learning models such as holding and processing multiple batches of 4k images for image classification and object detection systems
- #9: 1/ Let’s take a look at a common computer vision model for image classification, a deep neural network called ResNet-50 <rez net fifty>, trained on hundreds of thousands of images. 2/ The fastest time to train this model, by a team in Mountain View, was 30 minutes, using a specially built training algorithm which was optimized just for this single neural network, and for specialized hardware which is only available in beta (and not available to most developers). These improvements are locked away from most models, and out of reach of the vast majority of developers. 4/ With the improvements we made in TF, we reduced training time by over 50% to just 14 minutes. This is the fastest time for training ResNet using TensorFlow, anywhere. 5/ But even more importantly, our optimizations can be applied to multiple different models - including convolutional neural networks (images), and recurrent neural networks (language, recommendation). 6/ It also runs on P3 instances, which are globally available to all developers in 14 regions. 7/ Available in SageMaker and the Deep Learning AMI
- #17: These performance and accuracy trade offs are felt most acutely at the edge. 1/ IoT applications are usually running on devices, out there in the real world. This means that the accuracy of models can be felt quickly, and immediately. Consumer IoT applications have a high expectation of accuracy - such as Alexa detecting the wake word reliably - the accuracy of that model really matters to the overall experience. In industrial IoT, devices are often responsible for monitoring and maintaining and core manufacturing processes, or safety. The accuracy of a model here is critical. 2/ Applications running on IoT devices at the edge are commonly very sensitive to latency; it’s part of the reason why customers are running the workload there in the first place, because they can’t afford the round trip to the cloud and back. So any increase in that latency can have a meaningful impact on the success of the device itself. 3/ IoT applications are often incredibly resource constrained, in a way which is much more acute than in the cloud. The devices are smaller, and have less memory and processing power, which is a real problem for machine learning models. 4/ In many cases, IoT applications need to run on very diverse hardware platforms, with a dizzying myriad of processor architectures. To get any sort of performance, developers have to optimize 5/ Finally, one of the key benefits of machine learning can get lost; the ability to continually improve the model. IoT applications are great data generators, and once that data is “ground-truthed”, it can be used to build more sophisticated models. However, if the effort to optimize those improved models for the constraints and diverse hardware at the edge is high, then it’s less likely to happen, and developers are leaving money on the table. A real missed opportunity. 6/ We don’t think that customers should have to choose between accuracy and performance. It’s a false choice, with a high cost. So I’m excited to announce a new feature of SageMaker…
- #25: TODO for the presenter : adjust the banner to the conference you will speak to.