DF1 - R - Natekin - Improving Daily Analysis with data.table
Download as PPTX, PDF1 like581 views
Presentation from Moscow Data Fest #1, September 12. Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice. Link: http://www.meetup.com/Moscow-Data-Fest/
1 of 34
Downloaded 20 times












![13
Core principle
DT[i, j, by]
1. Take DT
2. Subset rows by i
3. Calculate j
4. …grouped by by](https://image.slidesharecdn.com/df1-r-1-natekin-improvingdailyanalysiswithdatatable-150921141401-lva1-app6892/85/DF1-R-Natekin-Improving-Daily-Analysis-with-data-table-13-320.jpg)



















Ad
Recommended
DF1 - ML - Petukhov - Azure Ml Machine Learning as a Service
DF1 - ML - Petukhov - Azure Ml Machine Learning as a ServiceMoscowDataFest Presentation from Moscow Data Fest #1, September 12.
Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice.
Link: http://www.meetup.com/Moscow-Data-Fest/
Making Machine Learning Scale: Single Machine and Distributed
Making Machine Learning Scale: Single Machine and DistributedTuri, Inc. This document summarizes machine learning scalability from single machine to distributed systems. It discusses how true scalability is about how long it takes to reach a target accuracy level using any available hardware resources. It introduces GraphLab Create and SFrame/SGraph for scalable machine learning and graph processing. Key points include distributed optimization techniques, graph partitioning strategies, and benchmarks showing GraphLab Create can solve problems faster than other systems by using fewer machines.
Microsoft Machine Learning Server. Architecture View
Microsoft Machine Learning Server. Architecture ViewDmitry Petukhov Microsoft Machine Learning Server (former Microsoft R Server): Architecture View. Slides from Data Geeks Meetup (Moscow)
Introduction to Analytics with Azure Notebooks and Python
Introduction to Analytics with Azure Notebooks and PythonJen Stirrup Introduction to Analytics with Azure Notebooks and Python for Data Science and Business Intelligence. This is one part of a full day workshop on moving from BI to Analytics
Scala: the unpredicted lingua franca for data science
Scala: the unpredicted lingua franca for data scienceAndy Petrella Talk given at Strata London with Dean Wampler (Lightbend) about Scala as the future of Data Science. First part is an approach of how scala became important, the remaining part of the talk is in notebooks using the Spark Notebook (http://spark-notebook.io/).
The notebooks are available on GitHub: https://github.com/data-fellas/scala-for-data-science.
Beyond Kaggle: Solving Data Science Challenges at Scale
Beyond Kaggle: Solving Data Science Challenges at ScaleTuri, Inc. This document summarizes a presentation on entity resolution and data deduplication using Dato toolkits. It discusses key concepts like entity resolution, challenges in entity resolution like missing data and data integration from multiple sources, and provides an example dataset of matching Amazon and Google products. It also outlines the preprocessing steps, describes using a nearest neighbors algorithm to find duplicate records, and shares some resources on entity resolution.
Agile Data Science
Agile Data ScienceRussell Jurney Agile Data Science 2.0 (O'Reilly 2017) defines a methodology and a software stack with which to apply the methods. *The methodology* seeks to deliver data products in short sprints by going meta and putting the focus on the applied research process itself. *The stack* is but an example of one meeting the requirements that it be utterly scalable and utterly efficient in use by application developers as well as data engineers. It includes everything needed to build a full-blown predictive system: Apache Spark, Apache Kafka, Apache Incubating Airflow, MongoDB, ElasticSearch, Apache Parquet, Python/Flask, JQuery. This talk will cover the full lifecycle of large data application development and will show how to use lessons from agile software engineering to apply data science using this full-stack to build better analytics applications. The entire lifecycle of big data application development is discussed. The system starts with plumbing, moving on to data tables, charts and search, through interactive reports, and building towards predictions in both batch and realtime (and defining the role for both), the deployment of predictive systems and how to iteratively improve predictions that prove valuable.
Machine Learning with Azure
Machine Learning with AzureBarbara Fusinska This document provides an overview of machine learning with Azure. It discusses various machine learning concepts like classification, regression, clustering and more. It outlines an agenda for a workshop on the topic that includes experiments in Azure ML Studio, publishing models as web services, and using various Azure data sources. The document encourages participants to clone a GitHub repo for sample code and data and to sign up for an Azure ML Studio account.
Azure Machine Learning
Azure Machine LearningDmitry Petukhov This document discusses the evolution of machine learning tools and services in the cloud, specifically on Microsoft Azure. It provides examples of machine learning frameworks, runtimes, and packages available over time on Azure including Azure ML (2015) and the Microsoft Cognitive Toolkit (CNTK) (2015). It also mentions the availability of GPU resources on Azure starting in 2016 and limitations to consider for the Azure ML service including restrictions on programming languages and a lack of debugging capabilities.
Spark - Philly JUG
Spark - Philly JUGBrian O'Neill Brian O'Neill from Monetate gave a presentation on Spark. He discussed Spark's history from Hadoop and MapReduce, the basics of RDDs, DataFrames, SQL and streaming in Spark. He demonstrated how to build and run Spark applications using Java and SQL with DataFrames. Finally, he covered Spark deployment architectures and ran a demo of a Spark application on Cassandra.
Better {ML} Together: GraphLab Create + Spark 
Better {ML} Together: GraphLab Create + Spark Turi, Inc. This document discusses using GraphLab Create and Apache Spark together for machine learning applications. It provides an overview of Spark and how to create resilient distributed datasets (RDDs) and perform parallel operations on clusters. It then lists many machine learning algorithms available in GraphLab Create, including recommender systems, classification, regression, text analysis, image analysis, and graph analytics. The document proposes using notebooks to build data science products that help deliver personalized experiences through ML and intelligent automation. It demonstrates clustering customer transactions from an expense reporting dataset to identify customer behavior patterns.
How to Integrate Spark MLlib and Apache Solr to Build Real-Time Entity Type R...
How to Integrate Spark MLlib and Apache Solr to Build Real-Time Entity Type R...Spark Summit Understanding the types of entities expressed in a search query (Company, Skill, Job Title, etc.) enables more intelligent information retrieval based upon those entities compared to a traditional keyword-based search. Because search queries are typically very short, leveraging a traditional bag-of-words model to identify entity types would be inappropriate due to the lack of contextual information. We implemented a novel entity type recognition system which combines clues from different sources of varying complexity in order to collect real-world knowledge about query entities. We employ distributional semantic representations of query entities through two models: 1) contextual vectors generated from encyclopedic corpora like Wikipedia, and 2) high dimensional word embedding vectors generated from millions of job postings using Spark MLlib. In order to enable real-time recognition of entity types, we utilize Apache Solr to cache the embedding vectors generated by Spark MLlib. This approach enable us to recognize entity types for entities expressed in search queries in less than 60 milliseconds which makes this system applicable for real-time entity type recognition.
SFrame
SFrameTuri, Inc. Scalable tabular (SFrame, SArray) and graph (SGraph) data-structures built for out-of-core data analysis.
The SFrame package provides the complete implementation of:
SFrame
SArray
SGraph
The C++ SDK surface area (gl_sframe, gl_sarray, gl_sgraph)
Introducing apache prediction io (incubating) (bay area spark meetup at sales...
Introducing apache prediction io (incubating) (bay area spark meetup at sales...Databricks Donald Szeto introduces Apache PredictionIO, an open source machine learning server for developers and ML engineers. He discusses why there is a need for PredictionIO, provides a quick demo, and digs deeper into key concepts like DASE (Data, Algorithm, Serving, Evaluation), engine instances, and engine variants. Szeto also outlines the current development focus, future roadmap, and calls for the community's help to further develop PredictionIO.
Big Data Analytics with Storm, Spark and GraphLab
Big Data Analytics with Storm, Spark and GraphLabImpetus Technologies A tutorial by Dr. Vijay Srinivas Agneeswaran, Director and Head, Big-data R&D, Innovation Labs, Impetus
Data Science with Spark
Data Science with SparkKrishna Sankar The document outlines an agenda for a conference on Apache Spark and data science, including sessions on Spark's capabilities and direction, using DataFrames in PySpark, linear regression, text analysis, classification, clustering, and recommendation engines using Spark MLlib. Breakout sessions are scheduled between many of the technical sessions to allow for hands-on work and discussion.
Agile data science with scala
Agile data science with scalaAndy Petrella How the data science pipelines have to evolve and how it'll be accessible using the right technologies from Scala and the Spark Notebook.
Optimizing Terascale Machine Learning Pipelines with Keystone ML
Optimizing Terascale Machine Learning Pipelines with Keystone MLSpark Summit The document describes KeystoneML, an open source software framework for building scalable machine learning pipelines on Apache Spark. It discusses standard machine learning pipelines and examples of more complex pipelines for image classification, text classification, and recommender systems. It covers features of KeystoneML like transformers, estimators, and chaining estimators and transformers. It also discusses optimizing pipelines by choosing solvers, caching intermediate data, and operator selection. Benchmark results show KeystoneML achieves state-of-the-art accuracy on large datasets faster than other systems through end-to-end pipeline optimizations.
Fishing Graphs in a Hadoop Data Lake by Jörg Schad and Max Neunhoeffer at Big...
Fishing Graphs in a Hadoop Data Lake by Jörg Schad and Max Neunhoeffer at Big...Big Data Spain The document discusses using a graph database to store and query graph data stored in a Hadoop data lake more efficiently. It describes the limitations of the typical approach of using Spark/GraphFrames on HDFS for graph queries. A graph database allows for faster ad hoc graph queries by leveraging graph traversals. The document proposes using a multi-model database that combines a document store, graph database, and key-value store with a common query language. It suggests this approach could run on a DC/OS cluster for easy deployment and management of resources. Examples show importing data into ArangoDB and running graph queries.
Multiplatform Spark solution for Graph datasources by Javier Dominguez
Multiplatform Spark solution for Graph datasources by Javier DominguezBig Data Spain This document summarizes a presentation given by Javier Dominguez at Big Data Spain about Stratio's multiplatform solution for graph data sources. It discusses graph use cases, different data stores like Spark, GraphX, GraphFrames and Neo4j. It demonstrates the machine learning life cycle using a massive dataset from Freebase, running queries and algorithms. It shows notebooks and a business example of clustering bank data using Jaccard distance and connected components. The presentation concludes with future directions like a semantic search engine and applying more machine learning algorithms.
Agile analytics applications on hadoop
Agile analytics applications on hadoopRussell Jurney This document discusses building agile analytics applications. It recommends taking an iterative approach where data is explored interactively from the start to discover insights. Rather than designing insights upfront, the goal is to build an application that facilitates exploration of the data to uncover insights. This is done by setting up an environment where insights can be repeatedly produced and shared with the team. The focus is on using simple, flexible tools that work from small local data to large datasets.
Bulletproof Jobs: Patterns for Large-Scale Spark Processing: Spark Summit Eas...
Bulletproof Jobs: Patterns for Large-Scale Spark Processing: Spark Summit Eas...Spark Summit Big data never stops and neither should your Spark jobs. They should not stop when they see invalid input data. They should not stop when there are bugs in your code. They should not stop because of I/O-related problems. They should not stop because the data is too big. Bulletproof jobs not only keep working but they make it easy to identify and address the common problems encountered in large-scale production Spark processing: from data quality to code quality to operational issues to rising data volumes over time.
In this session you will learn three key principles for bulletproofing your Spark jobs, together with the architecture and system patterns that enable them. The first principle is idempotence. Exemplified by Spark 2.0 Idempotent Append operations, it enables 10x easier failure management. The second principle is row-level structured logging. Exemplified by Spark Records, it enables 100x (yes, one hundred times) faster root cause analysis. The third principle is invariant query structure. It is exemplified by Resilient Partitioned Tables, which allow for flexible management of large scale data over long periods of time, including late arrival handling, reprocessing of existing data to deal with bugs or data quality issues, repartitioning already written data, etc.
These patterns have been successfully used in production at Swoop in the demanding world of petabyte-scale online advertising.
Analyzing Data With Python
Analyzing Data With PythonSarah Guido Sarah Guido gave a presentation on analyzing data with Python. She discussed several Python tools for preprocessing, analysis, and visualization including Pandas for data wrangling, scikit-learn for machine learning, NLTK for natural language processing, MRjob for processing large datasets in parallel, and ggplot for visualization. For each tool, she provided examples and use cases. She emphasized that the best tools depend on the type of data and analysis needs.
The Power of Unified Analytics with Ali Ghodsi 
The Power of Unified Analytics with Ali Ghodsi Databricks Databricks was founded in 2013 to bring Apache Spark to the enterprise. Their goal is to unify data science and engineering, which traditionally operate in silos. They have developed two main products to achieve this. Databricks Delta makes data lakes reliable and performant for AI use cases. MLflow unifies the workflows of data scientists and engineers by enabling them to track experiments, build reliable data pipelines, and deploy models into production. Overall, Databricks aims to make AI possible for more organizations by breaking down the barriers between data teams.
Agile Data Science: Building Hadoop Analytics Applications
Agile Data Science: Building Hadoop Analytics ApplicationsRussell Jurney This document discusses building agile analytics applications with Hadoop. It outlines several principles for developing data science teams and applications in an agile manner. Some key points include:
- Data science teams should be small, around 3-4 people with diverse skills who can work collaboratively.
- Insights should be discovered through an iterative process of exploring data in an interactive web application, rather than trying to predict outcomes upfront.
- The application should start as a tool for exploring data and discovering insights, which then becomes the palette for what is shipped.
- Data should be stored in a document format like Avro or JSON rather than a relational format to reduce joins and better represent semi-structured
Distributed Deep Learning + others for Spark Meetup
Distributed Deep Learning + others for Spark MeetupVijay Srinivas Agneeswaran, Ph.D This contains the agenda of the Spark Meetup I organised in Bangalore on Friday, the 23rd of Jan 2014. It carries the slides for the talk I gave on distributed deep learning over Spark
World’s Best Data Modeling Tool
World’s Best Data Modeling ToolArtem Chebotko The document describes the KDM tool, which automates Cassandra data modeling tasks. It streamlines the data modeling methodology by guiding users and automating conceptual to logical mapping, physical optimizations, and CQL generation. The KDM tool simplifies the complex data modeling process, eliminates human errors, and helps users build, verify, and learn data modeling. Future work on the tool includes support for materialized views, user defined types, application workflow design, and additional diagram types.
A look inside pandas design and development
A look inside pandas design and developmentWes McKinney This document summarizes Wes McKinney's presentation on pandas, an open source data analysis library for Python. McKinney is the lead developer of pandas and discusses its design, development, and performance advantages over other Python data analysis tools. He highlights key pandas features like the DataFrame for tabular data, fast data manipulation capabilities, and its use in financial applications. McKinney also discusses his development process, tools like IPython and Cython, and optimization techniques like profiling and algorithm exploration to ensure pandas' speed and reliability.
Trainer Regional Broschüre 2017
Trainer Regional Broschüre 2017Juergen Zirbik TRAINERegional - Informationen zu: Trainings, Seminaren, Workshops, Coaching, Specials: Führungsseminar im Flugsimulator, Verhandeln mit Einkaufs- und Verkaufstrainer. Unsere Trainer, Konditionen. Managementtrainings, Führungskräftecoaching. Neuigkeiten 2017
In 6 Monaten zum eigenen Buch 2017
In 6 Monaten zum eigenen Buch 2017Juergen Zirbik #buchschreiben #autorwerden - Präsentation zum Webinar. Im Webinar "In 6 Monaten zum eigenen Buch" erfahren Sie Möglichkeiten, wie Sie endlich loslegen und Ihr eigenes Werk nach rund einem halben Jahr in Händen halten können.
Know How und Tipps zu Struktur, Inhalt, Schreiben, Marketing, Hilfsmittel wie ISBN, Titelschutz und einiges mehr.
#videokurs - Link zum Videokurs "Buch selbst schreiben"
#Autorenseminar - Link zu Informationen zum Autorenseminar in Nürnberg
Ad
More Related Content
What's hot (20)
Azure Machine Learning
Azure Machine LearningDmitry Petukhov This document discusses the evolution of machine learning tools and services in the cloud, specifically on Microsoft Azure. It provides examples of machine learning frameworks, runtimes, and packages available over time on Azure including Azure ML (2015) and the Microsoft Cognitive Toolkit (CNTK) (2015). It also mentions the availability of GPU resources on Azure starting in 2016 and limitations to consider for the Azure ML service including restrictions on programming languages and a lack of debugging capabilities.
Spark - Philly JUG
Spark - Philly JUGBrian O'Neill Brian O'Neill from Monetate gave a presentation on Spark. He discussed Spark's history from Hadoop and MapReduce, the basics of RDDs, DataFrames, SQL and streaming in Spark. He demonstrated how to build and run Spark applications using Java and SQL with DataFrames. Finally, he covered Spark deployment architectures and ran a demo of a Spark application on Cassandra.
Better {ML} Together: GraphLab Create + Spark
Better {ML} Together: GraphLab Create + Spark Turi, Inc. This document discusses using GraphLab Create and Apache Spark together for machine learning applications. It provides an overview of Spark and how to create resilient distributed datasets (RDDs) and perform parallel operations on clusters. It then lists many machine learning algorithms available in GraphLab Create, including recommender systems, classification, regression, text analysis, image analysis, and graph analytics. The document proposes using notebooks to build data science products that help deliver personalized experiences through ML and intelligent automation. It demonstrates clustering customer transactions from an expense reporting dataset to identify customer behavior patterns.
How to Integrate Spark MLlib and Apache Solr to Build Real-Time Entity Type R...
How to Integrate Spark MLlib and Apache Solr to Build Real-Time Entity Type R...Spark Summit Understanding the types of entities expressed in a search query (Company, Skill, Job Title, etc.) enables more intelligent information retrieval based upon those entities compared to a traditional keyword-based search. Because search queries are typically very short, leveraging a traditional bag-of-words model to identify entity types would be inappropriate due to the lack of contextual information. We implemented a novel entity type recognition system which combines clues from different sources of varying complexity in order to collect real-world knowledge about query entities. We employ distributional semantic representations of query entities through two models: 1) contextual vectors generated from encyclopedic corpora like Wikipedia, and 2) high dimensional word embedding vectors generated from millions of job postings using Spark MLlib. In order to enable real-time recognition of entity types, we utilize Apache Solr to cache the embedding vectors generated by Spark MLlib. This approach enable us to recognize entity types for entities expressed in search queries in less than 60 milliseconds which makes this system applicable for real-time entity type recognition.
SFrame
SFrameTuri, Inc. Scalable tabular (SFrame, SArray) and graph (SGraph) data-structures built for out-of-core data analysis.
The SFrame package provides the complete implementation of:
SFrame
SArray
SGraph
The C++ SDK surface area (gl_sframe, gl_sarray, gl_sgraph)
Introducing apache prediction io (incubating) (bay area spark meetup at sales...
Introducing apache prediction io (incubating) (bay area spark meetup at sales...Databricks Donald Szeto introduces Apache PredictionIO, an open source machine learning server for developers and ML engineers. He discusses why there is a need for PredictionIO, provides a quick demo, and digs deeper into key concepts like DASE (Data, Algorithm, Serving, Evaluation), engine instances, and engine variants. Szeto also outlines the current development focus, future roadmap, and calls for the community's help to further develop PredictionIO.
Big Data Analytics with Storm, Spark and GraphLab
Big Data Analytics with Storm, Spark and GraphLabImpetus Technologies A tutorial by Dr. Vijay Srinivas Agneeswaran, Director and Head, Big-data R&D, Innovation Labs, Impetus
Data Science with Spark
Data Science with SparkKrishna Sankar The document outlines an agenda for a conference on Apache Spark and data science, including sessions on Spark's capabilities and direction, using DataFrames in PySpark, linear regression, text analysis, classification, clustering, and recommendation engines using Spark MLlib. Breakout sessions are scheduled between many of the technical sessions to allow for hands-on work and discussion.
Agile data science with scala
Agile data science with scalaAndy Petrella How the data science pipelines have to evolve and how it'll be accessible using the right technologies from Scala and the Spark Notebook.
Optimizing Terascale Machine Learning Pipelines with Keystone ML
Optimizing Terascale Machine Learning Pipelines with Keystone MLSpark Summit The document describes KeystoneML, an open source software framework for building scalable machine learning pipelines on Apache Spark. It discusses standard machine learning pipelines and examples of more complex pipelines for image classification, text classification, and recommender systems. It covers features of KeystoneML like transformers, estimators, and chaining estimators and transformers. It also discusses optimizing pipelines by choosing solvers, caching intermediate data, and operator selection. Benchmark results show KeystoneML achieves state-of-the-art accuracy on large datasets faster than other systems through end-to-end pipeline optimizations.
Fishing Graphs in a Hadoop Data Lake by Jörg Schad and Max Neunhoeffer at Big...
Fishing Graphs in a Hadoop Data Lake by Jörg Schad and Max Neunhoeffer at Big...Big Data Spain The document discusses using a graph database to store and query graph data stored in a Hadoop data lake more efficiently. It describes the limitations of the typical approach of using Spark/GraphFrames on HDFS for graph queries. A graph database allows for faster ad hoc graph queries by leveraging graph traversals. The document proposes using a multi-model database that combines a document store, graph database, and key-value store with a common query language. It suggests this approach could run on a DC/OS cluster for easy deployment and management of resources. Examples show importing data into ArangoDB and running graph queries.
Multiplatform Spark solution for Graph datasources by Javier Dominguez
Multiplatform Spark solution for Graph datasources by Javier DominguezBig Data Spain This document summarizes a presentation given by Javier Dominguez at Big Data Spain about Stratio's multiplatform solution for graph data sources. It discusses graph use cases, different data stores like Spark, GraphX, GraphFrames and Neo4j. It demonstrates the machine learning life cycle using a massive dataset from Freebase, running queries and algorithms. It shows notebooks and a business example of clustering bank data using Jaccard distance and connected components. The presentation concludes with future directions like a semantic search engine and applying more machine learning algorithms.
Agile analytics applications on hadoop
Agile analytics applications on hadoopRussell Jurney This document discusses building agile analytics applications. It recommends taking an iterative approach where data is explored interactively from the start to discover insights. Rather than designing insights upfront, the goal is to build an application that facilitates exploration of the data to uncover insights. This is done by setting up an environment where insights can be repeatedly produced and shared with the team. The focus is on using simple, flexible tools that work from small local data to large datasets.
Bulletproof Jobs: Patterns for Large-Scale Spark Processing: Spark Summit Eas...
Bulletproof Jobs: Patterns for Large-Scale Spark Processing: Spark Summit Eas...Spark Summit Big data never stops and neither should your Spark jobs. They should not stop when they see invalid input data. They should not stop when there are bugs in your code. They should not stop because of I/O-related problems. They should not stop because the data is too big. Bulletproof jobs not only keep working but they make it easy to identify and address the common problems encountered in large-scale production Spark processing: from data quality to code quality to operational issues to rising data volumes over time.
In this session you will learn three key principles for bulletproofing your Spark jobs, together with the architecture and system patterns that enable them. The first principle is idempotence. Exemplified by Spark 2.0 Idempotent Append operations, it enables 10x easier failure management. The second principle is row-level structured logging. Exemplified by Spark Records, it enables 100x (yes, one hundred times) faster root cause analysis. The third principle is invariant query structure. It is exemplified by Resilient Partitioned Tables, which allow for flexible management of large scale data over long periods of time, including late arrival handling, reprocessing of existing data to deal with bugs or data quality issues, repartitioning already written data, etc.
These patterns have been successfully used in production at Swoop in the demanding world of petabyte-scale online advertising.
Analyzing Data With Python
Analyzing Data With PythonSarah Guido Sarah Guido gave a presentation on analyzing data with Python. She discussed several Python tools for preprocessing, analysis, and visualization including Pandas for data wrangling, scikit-learn for machine learning, NLTK for natural language processing, MRjob for processing large datasets in parallel, and ggplot for visualization. For each tool, she provided examples and use cases. She emphasized that the best tools depend on the type of data and analysis needs.
The Power of Unified Analytics with Ali Ghodsi
The Power of Unified Analytics with Ali Ghodsi Databricks Databricks was founded in 2013 to bring Apache Spark to the enterprise. Their goal is to unify data science and engineering, which traditionally operate in silos. They have developed two main products to achieve this. Databricks Delta makes data lakes reliable and performant for AI use cases. MLflow unifies the workflows of data scientists and engineers by enabling them to track experiments, build reliable data pipelines, and deploy models into production. Overall, Databricks aims to make AI possible for more organizations by breaking down the barriers between data teams.
Agile Data Science: Building Hadoop Analytics Applications
Agile Data Science: Building Hadoop Analytics ApplicationsRussell Jurney This document discusses building agile analytics applications with Hadoop. It outlines several principles for developing data science teams and applications in an agile manner. Some key points include:
- Data science teams should be small, around 3-4 people with diverse skills who can work collaboratively.
- Insights should be discovered through an iterative process of exploring data in an interactive web application, rather than trying to predict outcomes upfront.
- The application should start as a tool for exploring data and discovering insights, which then becomes the palette for what is shipped.
- Data should be stored in a document format like Avro or JSON rather than a relational format to reduce joins and better represent semi-structured
Distributed Deep Learning + others for Spark Meetup
Distributed Deep Learning + others for Spark MeetupVijay Srinivas Agneeswaran, Ph.D This contains the agenda of the Spark Meetup I organised in Bangalore on Friday, the 23rd of Jan 2014. It carries the slides for the talk I gave on distributed deep learning over Spark
World’s Best Data Modeling Tool
World’s Best Data Modeling ToolArtem Chebotko The document describes the KDM tool, which automates Cassandra data modeling tasks. It streamlines the data modeling methodology by guiding users and automating conceptual to logical mapping, physical optimizations, and CQL generation. The KDM tool simplifies the complex data modeling process, eliminates human errors, and helps users build, verify, and learn data modeling. Future work on the tool includes support for materialized views, user defined types, application workflow design, and additional diagram types.
A look inside pandas design and development
A look inside pandas design and developmentWes McKinney This document summarizes Wes McKinney's presentation on pandas, an open source data analysis library for Python. McKinney is the lead developer of pandas and discusses its design, development, and performance advantages over other Python data analysis tools. He highlights key pandas features like the DataFrame for tabular data, fast data manipulation capabilities, and its use in financial applications. McKinney also discusses his development process, tools like IPython and Cython, and optimization techniques like profiling and algorithm exploration to ensure pandas' speed and reliability.
Viewers also liked (6)
Trainer Regional Broschüre 2017
Trainer Regional Broschüre 2017Juergen Zirbik TRAINERegional - Informationen zu: Trainings, Seminaren, Workshops, Coaching, Specials: Führungsseminar im Flugsimulator, Verhandeln mit Einkaufs- und Verkaufstrainer. Unsere Trainer, Konditionen. Managementtrainings, Führungskräftecoaching. Neuigkeiten 2017
In 6 Monaten zum eigenen Buch 2017
In 6 Monaten zum eigenen Buch 2017Juergen Zirbik #buchschreiben #autorwerden - Präsentation zum Webinar. Im Webinar "In 6 Monaten zum eigenen Buch" erfahren Sie Möglichkeiten, wie Sie endlich loslegen und Ihr eigenes Werk nach rund einem halben Jahr in Händen halten können.
Know How und Tipps zu Struktur, Inhalt, Schreiben, Marketing, Hilfsmittel wie ISBN, Titelschutz und einiges mehr.
#videokurs - Link zum Videokurs "Buch selbst schreiben"
#Autorenseminar - Link zu Informationen zum Autorenseminar in Nürnberg
How We Caffeinate
How We CaffeinateFood Insight When it comes to caffeine, it's not the source that matters, but how much. Moderate consumption is between 300-400mg.
Top 7 Reasons To Hire A Caterer For Your Next Event
Top 7 Reasons To Hire A Caterer For Your Next EventEason Chan Parties are supposed to be fun. When you’re doing all of the planning, the cooking, the hosting, the serving and the cleanup, they’re not so fun. Reliable help can put the enjoyment back into throwing a party. Here are the top seven reasons to hire a caterer for your next event. Shared by: https://www.rasacatering.sg/
Top 10 Most Eaten Foods In The World
Top 10 Most Eaten Foods In The WorldEason Chan Man eats to live and not that he lives in order to eat, thus food is considered one of the basic necessities of human beings. Though the choices and preferences differ, there are some common foods that are consumed in larger quantities than others all over the world. This is a ranking of the top ten most eaten foods in all the continents of the world.
Shared by: http://rasacatering.sg/
Leader's Guide to Motivate People at Work
Leader's Guide to Motivate People at WorkWeekdone.com To motivate employees, leaders should provide more praise, attention, responsibility, and incentives. Specifically, leaders should recognize employees' good work, keep employees informed about company goals and strategies, assign more challenging tasks with autonomy, establish incentive programs with realistic yet challenging goals, and provide pay raises correlated with employee performance and development. Leaders can use a performance management tool like Weekdone to understand employee status, provide transparent feedback, and align goals across different levels.
Ad
Similar to DF1 - R - Natekin - Improving Daily Analysis with data.table (20)
Five database trends - updated April 2015
Five database trends - updated April 2015Guy Harrison Presentation given at Oracle open world 2014. Five trends in database technology including big data, ssd, in-memory, NoSQL and column stores
A Tale of Three Apache Spark APIs: RDDs, DataFrames and Datasets by Jules Damji
A Tale of Three Apache Spark APIs: RDDs, DataFrames and Datasets by Jules DamjiData Con LA Abstract:- Of all the developers delight, none is more attractive than a set of APIs that make developers productive, that are easy to use, and that are intuitive and expressive. Apache Spark offers these APIs across components such as Spark SQL, Streaming, Machine Learning, and Graph Processing to operate on large data sets in languages such as Scala, Java, Python, and R for doing distributed big data processing at scale. In this talk, I will explore the evolution of three sets of APIs - RDDs, DataFrames, and Datasets available in Apache Spark 2.x. In particular, I will emphasize why and when you should use each set as best practices, outline its performance and optimization benefits, and underscore scenarios when to use DataFrames and Datasets instead of RDDs for your big data distributed processing. Through simple notebook demonstrations with API code examples, you'll learn how to process big data using RDDs, DataFrames, and Datasets and interoperate among them.

Data Mining with Excel 2010 and PowerPivot 201106
Data Mining with Excel 2010 and PowerPivot 201106Mark Tabladillo Delivered to Atlanta Code Camp, Marietta, GA. Excel 2010, SQL Server Analysis Services, and PowerPivot can enable desktop data mining.
Searching for Meaning
Searching for MeaningTrey Grainger "Searching for Meaning: The Hidden Structure in Unstructured Data". Presentation by Trey Grainger at the Southern Data Science Conference (SDSC) 2018. Covers linguistic theory, application in search and information retrieval, and knowledge graph and ontology learning methods for automatically deriving contextualized meaning from unstructured (free text) content.
Spark Based Distributed Deep Learning Framework For Big Data Applications 
Spark Based Distributed Deep Learning Framework For Big Data Applications Humoyun Ahmedov Deep Learning architectures, such as deep neural networks, are currently the hottest emerging areas of data science, especially in Big Data. Deep Learning could be effectively exploited to address some major issues of Big Data, such as fast information retrieval, data classification, semantic indexing and so on. In this work, we designed and implemented a framework to train deep neural networks using Spark, fast and general data flow engine for large scale data processing, which can utilize cluster computing to train large scale deep networks. Training Deep Learning models requires extensive data and computation. Our proposed framework can accelerate the training time by distributing the model replicas, via stochastic gradient descent, among cluster nodes for data resided on HDFS.
Oslo
OsloWillem Hendriks The document discusses using Apache Spark to analyze tourism data from Norway. It includes:
1) Creating a Spark RDD from a CSV file containing monthly guest nights data from various countries to Norway from 2013 to 2014.
2) Parsing each line of the CSV into a tuple containing country, month, and number of guest nights using the map transformation.
3) Applying the reduceByKey transformation to aggregate the guest nights by country, calculating the growth rate from 2013 to 2014 for each country.
4) The results show the countries with the highest growth rates in guest nights to Norway from 2013 to 2014, with Liechtenstein having the highest.
disertation
disertationRuben Casas This document discusses using Apache Hadoop and SQL Server to analyze large datasets. It finds that SQL Server struggles to efficiently query and analyze datasets with over 100 million rows, with query times increasing substantially with larger datasets. Apache Hadoop provides a more scalable solution by distributing data processing across a cluster. The document evaluates Hadoop and MongoDB for big data analysis, and chooses Hadoop for its ability to process large amounts of data for analytical purposes. It then discusses implementing Hortonworks Data Platform with Apache Ambari to analyze a 97GB population dataset using Hadoop.
Secrets of Enterprise Data Mining 201305
Secrets of Enterprise Data Mining 201305Mark Tabladillo Presented at SQL Saturday 220, Atlanta, GA, 201305. If you have a SQL Server license (Standard or higher) then you already have the ability to start data mining. In this new presentation, you will see how to scale up data mining from the free Excel 2013 add-in to production use. Aimed at beginning to intermediate data miners, this presentation will show how mining models move from development to production. We will use SQL Server 2012 tools including SSMS, SSIS, and SSDT.
How to Build a Semantic Search System
How to Build a Semantic Search SystemTrey Grainger Building a semantic search system - one that can correctly parse and interpret end-user intent and return the ideal results for users’ queries - is not an easy task. It requires semantically parsing the terms, phrases, and structure within queries, disambiguating polysemous terms, correcting misspellings, expanding to conceptually synonymous or related concepts, and rewriting queries in a way that maps the correct interpretation of each end user’s query into the ideal representation of features and weights that will return the best results for that user. Not only that, but the above must often be done within the confines of a very specific domain - ripe with its own jargon and linguistic and conceptual nuances.
This talk will walk through the anatomy of a semantic search system and how each of the pieces described above fit together to deliver a final solution. We'll leverage several recently-released capabilities in Apache Solr (the Semantic Knowledge Graph, Solr Text Tagger, Statistical Phrase Identifier) and Lucidworks Fusion (query log mining, misspelling job, word2vec job, query pipelines, relevancy experiment backtesting) to show you an end-to-end working Semantic Search system that can automatically learn the nuances of any domain and deliver a substantially more relevant search experience.
Making the leap to BI on Hadoop by Mariani, dave @ atscale
Making the leap to BI on Hadoop by Mariani, dave @ atscaleTin Ho This document discusses making the transition to business intelligence (BI) on Hadoop from traditional data warehousing. It notes that traditionally only 3% of data is analyzed due to the complexity of data warehousing which requires multiple copies of data and rigid schemas. Hadoop provides an alternative that allows for schema on read, direct analysis of raw data without transformation, and horizontal scaling without joins. The document demonstrates this through an example analyzing match data from the online game Dota 2, showing how different questions can be answered directly from raw JSON logs stored on Hadoop without loading to a data warehouse.
Graph Databases - Where Do We Do the Modeling Part?
Graph Databases - Where Do We Do the Modeling Part?DATAVERSITY Graph processing and graph databases have been with us for a while. However, since their physical implementations are the same for every database in production (Node connected to node, or triplets), there's a perception that data modeling (and data modelers) have no role on projects where graph databases are used.
This month we'll talk about where graph databases are a best fit in a modern data architecture and where data models add value.
Data stage scenario design9 - job1
Data stage scenario design9 - job1Naresh Bala This document discusses a DataStage scenario problem and solution involving splitting data from one input file into three separate output files based on a modulus calculation on the input column. The solution involves designing a job with a transformer stage to map the input column to the three output files, and setting constraints on each link based on the modulus calculation to control the data flow to each file. The job is then compiled and run to solve the problem.
Webinar: Enterprise Data Management in the Era of MongoDB and Data Lakes
Webinar: Enterprise Data Management in the Era of MongoDB and Data LakesMongoDB 1. The document discusses using MongoDB and data lakes for enterprise data management. It outlines the current issues with relational databases and how MongoDB addresses challenges like flexibility, scalability and performance.
2. Various architectures for enterprise data management with MongoDB are presented, including using it for raw, transformed and aggregated data stores.
3. The benefits of combining MongoDB and Hadoop in a data lake are greater agility, insight from handling different data structures, scalability and low latency for real-time decisions.
My Master's Thesis
My Master's ThesisHumoyun Ahmedov The document proposes a distributed deep learning framework for big data applications built on Apache Spark. It discusses challenges in distributed computing and deep learning in big data. The proposed system addresses issues like concurrency, asynchrony, parallelism through a master-worker architecture with data and model parallelism. Experiments on sentiment analysis using word embeddings and deep networks on a 10-node Spark cluster show improved performance with increased nodes.
2007 Mark Logic User Conference Keynote
2007 Mark Logic User Conference KeynoteDave Kellogg Here are Dave Kellogg's slides from the 2007 Mark Logic user conference in San Francisco, May 15 to May 17, 2007.
GreenDao Introduction
GreenDao IntroductionBooch Lin GreenDao is an ORM library that provides high performance for CRUD operations on SQLite databases in Android apps. It uses code generation to map objects to database tables, allowing data to be accessed and queried using objects rather than raw SQL. Some key features include object mapping, query building, caching, and bulk operations. The documentation provides examples of how to set up GreenDao in a project, define entity classes, perform queries, inserts, updates and deletes on objects.
Rental Cars and Industrialized Learning to Rank with Sean Downes
Rental Cars and Industrialized Learning to Rank with Sean DownesDatabricks Data can be viewed as the exhaust of online activity. With the rise of cloud-based data platforms, barriers to data storage and transfer have crumbled. The demand for creative applications and learning from those datasets has accelerated. Rapid acceleration can quickly accrue disorder, and disorderly data design can turn the deepest data lake into an impenetrable swamp.
In this talk, I will discuss the evolution of the data science workflow at Expedia with a special emphasis on Learning to Rank problems. From the heroic early days of ad-hoc Spark exploration to our first production sort model on the cloud, we will explore the process of industrializing the workflow. Layered over our story, I will share some best practices and suggestions on how to keep your data productive, or even pull your organization out of the data swamp.
Big Data: an introduction
Big Data: an introductionBart Vandewoestyne Introductory Big Data presentation given during one of our Sizing Servers Lab user group meetings. The presentation is targeted towards an audience of about 20 SME employees. It also contains a short description of the work packages for our BIg Data project proposal that was submitted in March.
Paper presentation
Paper presentationK.K. Tripathi A presentation based on a published paper "The Ambiguity of Data Science Team Roles and the Need for a Data Science Workforce Framework" by Jeffrey S. Saltz and Nancy W. Grady.
Ad
More from MoscowDataFest (6)
DF1 - Py - Kalaidin - Introduction to Word Embeddings with Python
DF1 - Py - Kalaidin - Introduction to Word Embeddings with PythonMoscowDataFest Presentation from Moscow Data Fest #1, September 12.
Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice.
Link: http://www.meetup.com/Moscow-Data-Fest/
DF1 - Py - Ovcharenko - Theano Tutorial
DF1 - Py - Ovcharenko - Theano TutorialMoscowDataFest Presentation from Moscow Data Fest #1, September 12.
Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice.
Link: http://www.meetup.com/Moscow-Data-Fest/
DF1 - ML - Vorontsov - BigARTM Topic Modelling of Large Text Collections
DF1 - ML - Vorontsov - BigARTM Topic Modelling of Large Text CollectionsMoscowDataFest Presentation from Moscow Data Fest #1, September 12.
Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice.
Link: http://www.meetup.com/Moscow-Data-Fest/
DF1 - DL - Lempitsky - Compact and Very Compact Image Descriptors
DF1 - DL - Lempitsky - Compact and Very Compact Image DescriptorsMoscowDataFest Presentation from Moscow Data Fest #1, September 12.
Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice.
Link: http://www.meetup.com/Moscow-Data-Fest/
DF1 - BD - Baranov - Mining Large Datasets with Apache Spark
DF1 - BD - Baranov - Mining Large Datasets with Apache SparkMoscowDataFest Presentation from Moscow Data Fest #1, September 12.
Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice.
Link: http://www.meetup.com/Moscow-Data-Fest/
DF1 - BD - Degtiarev - Practical Aspects of Big Data in Pharmaceutical
DF1 - BD - Degtiarev - Practical Aspects of Big Data in PharmaceuticalMoscowDataFest Presentation from Moscow Data Fest #1, September 12.
Moscow Data Fest is a free one-day event that brings together Data Scientists for sessions on both theory and practice.
Link: http://www.meetup.com/Moscow-Data-Fest/
Recently uploaded (20)
Structure formation with primordial black holes: collisional dynamics, binari...
Structure formation with primordial black holes: collisional dynamics, binari...Sérgio Sacani Primordial black holes (PBHs) could compose the dark matter content of the Universe. We present the first simulations of cosmological structure formation with PBH dark matter that consistently include collisional few-body effects, post-Newtonian orbit corrections, orbital decay due to gravitational wave emission, and black-hole mergers. We carefully construct initial conditions by considering the evolution during radiation domination as well as early-forming binary systems. We identify numerous dynamical effects due to the collisional nature of PBH dark matter, including evolution of the internal structures of PBH halos and the formation of a hot component of PBHs. We also study the properties of the emergent population of PBH binary systems, distinguishing those that form at primordial times from those that form during the nonlinear structure formation process. These results will be crucial to sharpen constraints on the PBH scenario derived from observational constraints on the gravitational wave background. Even under conservative assumptions, the gravitational radiation emitted over the course of the simulation appears to exceed current limits from ground-based experiments, but this depends on the evolution of the gravitational wave spectrum and PBH merger rate toward lower redshifts.
Preparation of Permanent mounts of Parasitic Protozoans.pptx
Preparation of Permanent mounts of Parasitic Protozoans.pptxDr Showkat Ahmad Wani Permanent Mount of Protozoans
VERMICOMPOSTING A STEP TOWARDS SUSTAINABILITY.pptx
VERMICOMPOSTING A STEP TOWARDS SUSTAINABILITY.pptxhipachi8 Vermicomposting: A sustainable practice converting organic waste into nutrient-rich fertilizer using worms, promoting eco-friendly agriculture, reducing waste, and supporting environmentally conscious gardening and farming practices naturally.


SuperconductingMagneticEnergyStorage.pptx
SuperconductingMagneticEnergyStorage.pptxBurkanAlpKale Ultra-fast, ultra-efficient grid storage
Presented by:
Burkan Alp Kale 20050711038
Numan Akbudak 21050711021
Nebil weddady 21050741003
Osama Alfares 21050741013
Culture Media Microbiology Presentation.pptx
Culture Media Microbiology Presentation.pptxmythorlegendbusiness This document explains the various Culture Media
The Man Who Dared to Challenge Newton and Won! - The True Story of Thane Hein...
The Man Who Dared to Challenge Newton and Won! - The True Story of Thane Hein...Thane Heins NOBEL PRIZE WINNING ENERGY RESEARCHER The Man Who Dared to Challenge Newton: The True Story of Thane Heins, the Canadian Genius
Who Changed the World
By Johnny Poppi – for international press
In a small town in Ontario, among wheat fields and wind-filled silences, a man has worked for decades in
anonymity, armed only with naive curiosity, motors, copper wires, and questions too big to ignore. His
name is Thane C/ Heins, and according to some scientists who have seen him in action, he may have
made—and indeed has made—the most important scientific discovery in the history of humanity.
A discovery which will eventually eliminate the need for oil, coal, and uranium, and at the very least their
harmful effects while eliminating the need to recharge electric vehicles, and even rewrite—as it has already
begun—the very laws of physics as we’ve known them since Aristotle in 300 BC.
Sound like science fiction? Then listen to this story.

Antliff, Mark. - Avant-Garde Fascism. The Mobilization of Myth, Art, and Cult...
Antliff, Mark. - Avant-Garde Fascism. The Mobilization of Myth, Art, and Cult...Francisco Sandoval Martínez Investigating the central role that theories of the visual arts and creativity played in the development of fascism in France, Mark Antliff examines the aesthetic dimension of fascist myth-making within the history of the avant-garde. Between 1909 and 1939, a surprising array of modernists were implicated in this project, including such well-known figures as the symbolist painter Maurice Denis, the architects Le Corbusier and Auguste Perret, the sculptors Charles Despiau and Aristide Maillol, the “New Vision” photographer Germaine Krull, and the fauve Maurice Vlaminck.
2025 Insilicogen Company Korean Brochure
2025 Insilicogen Company Korean BrochureInsilico Gen Insilicogen is a company, specializes in Bioinformatics. Our company provides a platform to share and communicate various biological data analysis effectively.
Vital Vitamins: A Clinical Nutrition Approach to Functions, Deficiency & Sources
Vital Vitamins: A Clinical Nutrition Approach to Functions, Deficiency & SourcesSarumathi Murugesan This presentation, titled "Vital Vitamins: A Clinical Nutrition Approach to Functions, Deficiency & Sources," offers a concise yet comprehensive overview of essential vitamins including A, D, E, K, B-complex, and C, as studied in the fields of clinical nutrition and dietetics.
Designed for students, educators, and healthcare professionals, this resource covers:
Physiological functions of fat- and water-soluble vitamins
Recommended Dietary Allowances (RDA) based on age and life stage
Major dietary sources relevant to practical diet planning
Common deficiency disorders with clinical relevance
Toxicity symptoms and risk of over-supplementation (where applicable)
Ideal for learners preparing for UGC NET, B.Sc. & M.Sc. Nutrition, Nursing, and Allied Health Sciences, this SlideShare simplifies complex content into clear, easy-to-follow slides rooted in evidence-based practice.

Infrastructure for Tracking Information Flow from Social Media to U.S. TV New...
Infrastructure for Tracking Information Flow from Social Media to U.S. TV New...Himarsha Jayanetti This study examines the intersection between social media and mainstream television (TV) news with an aim to understand how social media content amplifies its impact through TV broadcasts. While many studies emphasize social media as a primary platform for information dissemination, they often underestimate its total influence by focusing solely on interactions within the platform. This research examines instances where social media posts gain prominence on TV broadcasts, reaching new audiences and prompting public discourse. By using TV news closed captions, on-screen text recognition, and social media logo detection, we analyze how social media is referenced in TV news.
On the Lunar Origin of Near-Earth Asteroid 2024 PT5
On the Lunar Origin of Near-Earth Asteroid 2024 PT5Sérgio Sacani The near-Earth asteroid (NEA) 2024 PT5 is on an Earth-like orbit that remained in Earth's immediate vicinity for several months at the end of 2024. PT5's orbit is challenging to populate with asteroids originating from the main belt and is more commonly associated with rocket bodies mistakenly identified as natural objects or with debris ejected from impacts on the Moon. We obtained visible and near-infrared reflectance spectra of PT5 with the Lowell Discovery Telescope and NASA Infrared Telescope Facility on 2024 August 16. The combined reflectance spectrum matches lunar samples but does not match any known asteroid types—it is pyroxene-rich, while asteroids of comparable spectral redness are olivine-rich. Moreover, the amount of solar radiation pressure observed on the PT5 trajectory is orders of magnitude lower than what would be expected for an artificial object. We therefore conclude that 2024 PT5 is ejecta from an impact on the Moon, thus making PT5 the second NEA suggested to be sourced from the surface of the Moon. While one object might be an outlier, two suggest that there is an underlying population to be characterized. Long-term predictions of the position of 2024 PT5 are challenging due to the slow Earth encounters characteristic of objects in these orbits. A population of near-Earth objects that are sourced by the Moon would be important to characterize for understanding how impacts work on our nearest neighbor and for identifying the source regions of asteroids and meteorites from this understudied population of objects on very Earth-like orbits. Unified Astronomy Thesaurus concepts: Asteroids (72); Earth-moon system (436); The Moon (1692); Asteroid dynamics (2210)
Introduction to Mobile Forensics Part 1.pptx
Introduction to Mobile Forensics Part 1.pptxNivya George Introduction to Mobile Forensics, Sim card crimes
Skmuscle_properties_muscletone_muscletype.pptx
Skmuscle_properties_muscletone_muscletype.pptxmuralinath2 Excitability is a reaction or a response of a tissue particularly to irritation or activation. It is a physico-chemical change.
Effect of nutrition in Entomophagous Insectson
Effect of nutrition in Entomophagous InsectsonJabaskumarKshetri Effect of nutrition in Entomophagous Insects
Explains about insect nutrition and their effects.
when is CT scan need in breast cancer patient.pptx
when is CT scan need in breast cancer patient.pptxRukhnuddin Al-daudar when is CT scan need in breast cancer patient
RAPID DIAGNOSTIC TEST (RDT) overviewppt.pptx
RAPID DIAGNOSTIC TEST (RDT) overviewppt.pptxnietakam This a overview on rapid diagnostic test which is also known as rapid test focusing primarily on its principle which is lateral flow assay
The Man Who Dared to Challenge Newton and Won! - The True Story of Thane Hein...
The Man Who Dared to Challenge Newton and Won! - The True Story of Thane Hein...Thane Heins NOBEL PRIZE WINNING ENERGY RESEARCHER
Antliff, Mark. - Avant-Garde Fascism. The Mobilization of Myth, Art, and Cult...
Antliff, Mark. - Avant-Garde Fascism. The Mobilization of Myth, Art, and Cult...Francisco Sandoval Martínez
DF1 - R - Natekin - Improving Daily Analysis with data.table
- 1. Alex Natekin Deloitte Analytics Institute
- 2. 2 Been there, done that [email protected] vk.com/natekin linkedin.com/in/natekin facebook.com/alex.natekin
- 3. 3 Data.table
- 4. 4 Legend says And many others… “the R god of number crunching”
- 5. 5 Legend says (2) … to read the manual With great poweR comes great Responsibility of fasteR & richeR data crunching …
- 6. 6 Choose your side dplyr sqldfdata.table “Hadleyverse” Way of the warrior… …each one is way different from data.frame
- 7. 7 Choose your side… wisely from recent Matt Dowle’s meetup presentations
- 8. 8 from recent Matt Dowle’s meetup presentations …just search for “data.table benchmarks” Choose your side… wisely (2)
- 9. 9 data.table applicability Solution Data extraction & checks Data processing Feature engineering Models Stories …trying to find your place under the sun
- 10. 10 data.table applicability Solution Data extraction & checks Data processing Feature engineering Models Stories Naïve functionality Most awesome functionality Is closest to production code (if applicable to R)
- 11. 11 Core functionality 1. Data reading & memory management 2. Data access & ordering 3. Grouping & aggregation … feature engineering More efficient:
- 12. 12 Core functionality (2) 1. Data reading & memory management 2. Data access & ordering 3. Grouping & aggregation … feature engineering More efficient: …as data.frame extension (~100% compatible) 1. Reduce machine time 2. Reduce human programming time
- 13. 13 Core principle DT[i, j, by] 1. Take DT 2. Subset rows by i 3. Calculate j 4. …grouped by by
- 14. 14 Core principle (2) from data.table tutorial
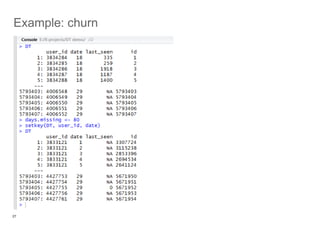
- 15. 15 Example: churn Sorry Laptop died last evening, no interactive tutorial Screenshots from remaining files
- 16. 16 Example
- 17. 17 Example
- 18. 18 Example
- 19. 19 Example (manual injection) setkey(DT, colA, colB) Yet another recent Matt Dowle’s meetup presentations
- 20. 20 Example
- 21. 21 Example
- 22. 22 Example
- 23. 23 Example
- 24. 24 Example
- 25. 25 Example
- 31. 31 Functionality: more 1. Fread 2. Column updates 3. Set functions (set, setnames, …) 4. Special symbols (.SD, .I, …) 5. Joins … next time
- 33. 33 SummaRy 1. data.table is helpful & awesome 2. go forth and use it 3. RTFM
- 34. Thanks! Alex Natekin [email protected] +7 915 070 45 74