Scaling web applications with cassandra presentation
Download as PPT, PDF3 likes1,622 views

This document provides an introduction and overview of Cassandra, including: - Cassandra is a distributed database modeled after Amazon Dynamo and Google Bigtable that is highly scalable and fault tolerant. - It is used by many large companies for applications that require fast writes, high availability, and elastic scalability. - Cassandra's data model uses a column-oriented design organized into keyspaces, column families, rows, and columns. It also supports super columns. - The document discusses Cassandra's features like tunable consistency levels, replication, and its data distribution using consistent hashing. - An overview of Cassandra's Thrift API and basic operations like get, batch mutate, and























![0.6 example
$cassandra –f
$bin/cassandra-cli
cassandra> connect localhost/9160
cassandra> set Keyspace1.Standard1[‘eben’]
[‘age’]=‘29’
cassandra> set Keyspace1.Standard1[‘eben’]
[‘email’]=‘e@e.com’
cassandra> get Keyspace1.Standard1[‘eben'][‘age']
=> (column=6e616d65, value=39,
timestamp=1282170655390000)](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-121230161326-phpapp01/85/Scaling-web-applications-with-cassandra-presentation-24-320.jpg)
![a column has 3 parts
1. name
– byte[]
– determines sort order
– used in queries
– indexed
1. value
– byte[]
– you don’t query on column values
1. timestamp
– long (clock)
– last write wins conflict resolution](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-121230161326-phpapp01/85/Scaling-web-applications-with-cassandra-presentation-25-320.jpg)







![• get() : Column
– get the Col or SC at given ColPath
read api
COSC cosc = client.get(key, path, CL);
• get_slice() : List<ColumnOrSuperColumn>
– get Cols in one row, specified by SlicePredicate:
List<ColumnOrSuperColumn> results =
client.get_slice(key, parent, predicate, CL);
• multiget_slice() : Map<key, List<CoSC>>
– get slices for list of keys, based on SlicePredicate
Map<byte[],List<ColumnOrSuperColumn>> results =
client.multiget_slice(rowKeys, parent, predicate, CL);
• get_range_slices() : List<KeySlice>
– returns multiple Cols according to a range
– range is startkey, endkey, starttoken, endtoken:
List<KeySlice> slices = client.get_range_slices(
parent, predicate, keyRange, CL);](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-121230161326-phpapp01/85/Scaling-web-applications-with-cassandra-presentation-33-320.jpg)
![client.insert(userKeyBytes, parent, write api
new Column(“band".getBytes(UTF8),
“Funkadelic".getBytes(), clock), CL);
batch_mutate
– void batch_mutate(
map<byte[], map<String, List<Mutation>>> , CL)
remove
– void remove(byte[],
ColumnPath column_path, Clock, CL)](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-121230161326-phpapp01/85/Scaling-web-applications-with-cassandra-presentation-34-320.jpg)
![//create param
batch_mutate
Map<byte[], Map<String, List<Mutation>>> mutationMap =
new HashMap<byte[], Map<String, List<Mutation>>>();
//create Cols for Muts
Column nameCol = new Column("name".getBytes(UTF8),
“Funkadelic”.getBytes("UTF-8"), new Clock(System.nanoTime()););
Mutation nameMut = new Mutation();
nameMut.column_or_supercolumn = nameCosc; //also phone, etc
Map<String, List<Mutation>> muts = new HashMap<String, List<Mutation>>();
List<Mutation> cols = new ArrayList<Mutation>();
cols.add(nameMut);
cols.add(phoneMut);
muts.put(CF, cols);
//outer map key is a row key; inner map key is the CF name
mutationMap.put(rowKey.getBytes(), muts);
//send to server
client.batch_mutate(mutationMap, CL);](https://image.slidesharecdn.com/scalingwebapplicationswithcassandrapresentation-121230161326-phpapp01/85/Scaling-web-applications-with-cassandra-presentation-35-320.jpg)







































Ad
More Related Content
What's hot (20)
Viewers also liked (6)




Ad
Similar to Scaling web applications with cassandra presentation (20)




















Ad
More from Murat Çakal (8)








Recently uploaded (20)




















Scaling web applications with cassandra presentation
- 1. introduction to cassandra eben hewitt september 29. 2010 web 2.0 expo new york city
- 2. @ebenhewitt • director, application architecture at a global corp • focus on SOA, SaaS, Events • i wrote this
- 3. agenda • context • features • data model • api
- 4. “nosql” “big data” • mongodb • couchdb • tokyo cabinet • redis • riak • what about? – Poet, Lotus, Xindice – they’ve been around forever… – rdbms was once the new kid…
- 5. innovation at scale • google bigtable (2006) – consistency model: strong – data model: sparse map – clones: hbase, hypertable • amazon dynamo (2007) – O(1) dht – consistency model: client tune-able – clones: riak, voldemort cassandra ~= bigtable + dynamo
- 6. proven • The Facebook stores 150TB of data on 150 nodes web 2.0 • used at Twitter, Rackspace, Mahalo, Reddit, Cloudkick, Cisco, Digg, SimpleGeo, Ooyala, OpenX, others
- 7. cap theorem • consistency – all clients have same view of data • availability – writeable in the face of node failure • partition tolerance – processing can continue in the face of network failure (crashed router, broken network)
- 9. write consistency Level Description ZERO Good luck with that ANY 1 replica (hints count) ONE 1 replica. read repair in bkgnd QUORUM (DCQ for RackAware) (N /2) + 1 ALL N = replication factor read consistency Level Description ZERO Ummm… ANY Try ONE instead ONE 1 replica QUORUM (DCQ for RackAware) Return most recent TS after (N /2) + 1 report ALL N = replication factor
- 10. agenda • context • features • data model • api
- 11. cassandra properties • tuneably consistent • very fast writes • highly available • fault tolerant • linear, elastic scalability • decentralized/symmetric • ~12 client languages – Thrift RPC API • ~automatic provisioning of new nodes • 0(1) dht • big data
- 12. write op
- 13. Staged Event-Driven Architecture • A general-purpose framework for high concurrency & load conditioning • Decomposes applications into stages separated by queues • Adopt a structured approach to event-driven concurrency
- 14. instrumentation
- 15. data replication
- 16. partitioner smack-down Random Preserving Order Preserving • system will use MD5(key) to • key distribution determined distribute data across nodes by token • even distribution of keys • lexicographical ordering from one CF across • required for range queries ranges/nodes – scan over rows like cursor in index • can specify the token for this node to use • ‘scrabble’ distribution
- 17. agenda • context • features • data model • api
- 18. structure
- 19. keyspace • ~= database • typically one per application • some settings are configurable only per keyspace
- 20. column family • group records of similar kind • not same kind, because CFs are sparse tables • ex: – User – Address – Tweet – PointOfInterest – HotelRoom
- 21. think of cassandra as row-oriented • each row is uniquely identifiable by key • rows group columns and super columns
- 22. column family key nickname= user=eben The 123 Situation key icon= n= user=alison 456 42
- 23. json-like notation User { 123 : { email: [email protected], icon: }, 456 : { email: [email protected], location: The Danger Zone} }
- 24. 0.6 example $cassandra –f $bin/cassandra-cli cassandra> connect localhost/9160 cassandra> set Keyspace1.Standard1[‘eben’] [‘age’]=‘29’ cassandra> set Keyspace1.Standard1[‘eben’] [‘email’]=‘[email protected]’ cassandra> get Keyspace1.Standard1[‘eben'][‘age'] => (column=6e616d65, value=39, timestamp=1282170655390000)
- 25. a column has 3 parts 1. name – byte[] – determines sort order – used in queries – indexed 1. value – byte[] – you don’t query on column values 1. timestamp – long (clock) – last write wins conflict resolution
- 26. column comparators • byte • utf8 • long • timeuuid • lexicaluuid • <pluggable> – ex: lat/long
- 27. super column super columns group columns under a common name
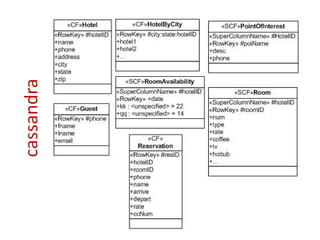
- 28. super column family <<SCF>>PointOfInterest <<SC>>Central <<SC>> Park Empire State Bldg 10017 desc=Fun to desc=Great phone=212. walk in. view from 555.11212 102nd floor! <<SC>> 85255 Phoenix Zoo
- 29. super column family super column family PointOfInterest { key: 85255 { column Phoenix Zoo { phone: 480-555-5555, desc: They have animals here. }, Spring Training { phone: 623-333-3333, desc: Fun for baseball fans. }, }, //end phx key super column key: 10019 { flexible schema Central Park { desc: Walk around. It's pretty.} , s Empire State Building { phone: 212-777-7777, desc: Great view from 102nd floor. } } //end nyc }
- 30. about super column families • sub-column names in a SCF are not indexed – top level columns (SCF Name) are always indexed • often used for denormalizing data from standard CFs
- 31. agenda • context • features • data model • api
- 32. slice predicate • data structure describing columns to return – SliceRange • start column name • finish column name (can be empty to stop on count) • reverse • count (like LIMIT)
- 33. • get() : Column – get the Col or SC at given ColPath read api COSC cosc = client.get(key, path, CL); • get_slice() : List<ColumnOrSuperColumn> – get Cols in one row, specified by SlicePredicate: List<ColumnOrSuperColumn> results = client.get_slice(key, parent, predicate, CL); • multiget_slice() : Map<key, List<CoSC>> – get slices for list of keys, based on SlicePredicate Map<byte[],List<ColumnOrSuperColumn>> results = client.multiget_slice(rowKeys, parent, predicate, CL); • get_range_slices() : List<KeySlice> – returns multiple Cols according to a range – range is startkey, endkey, starttoken, endtoken: List<KeySlice> slices = client.get_range_slices( parent, predicate, keyRange, CL);
- 34. client.insert(userKeyBytes, parent, write api new Column(“band".getBytes(UTF8), “Funkadelic".getBytes(), clock), CL); batch_mutate – void batch_mutate( map<byte[], map<String, List<Mutation>>> , CL) remove – void remove(byte[], ColumnPath column_path, Clock, CL)
- 35. //create param batch_mutate Map<byte[], Map<String, List<Mutation>>> mutationMap = new HashMap<byte[], Map<String, List<Mutation>>>(); //create Cols for Muts Column nameCol = new Column("name".getBytes(UTF8), “Funkadelic”.getBytes("UTF-8"), new Clock(System.nanoTime());); Mutation nameMut = new Mutation(); nameMut.column_or_supercolumn = nameCosc; //also phone, etc Map<String, List<Mutation>> muts = new HashMap<String, List<Mutation>>(); List<Mutation> cols = new ArrayList<Mutation>(); cols.add(nameMut); cols.add(phoneMut); muts.put(CF, cols); //outer map key is a row key; inner map key is the CF name mutationMap.put(rowKey.getBytes(), muts); //send to server client.batch_mutate(mutationMap, CL);
- 36. raw thrift: for masochists only • pycassa (python) • fauna (ruby) • hector (java) • pelops (java) • kundera (JPA) • hectorSharp (C#)
- 37. ? what about… SELECT WHERE ORDER BY JOIN ON GROUP
- 38. rdbms: domain-based model what answers do I have? cassandra: query-based model what questions do I have?
- 39. SELECT WHERE cassandra is an index factory <<cf>>USER Key: UserID Cols: username, email, birth date, city, state How to support this query? SELECT * FROM User WHERE city = ‘Scottsdale’ Create a new CF called UserCity: <<cf>>USERCITY Key: city Cols: IDs of the users in that city. Also uses the Valueless Column pattern
- 40. SELECT WHERE pt 2 • Use an aggregate key state:city: { user1, user2} • Get rows between AZ: & AZ; for all Arizona users • Get rows between AZ:Scottsdale & AZ:Scottsdale1 for all Scottsdale users
- 41. ORDER BY Columns Rows are sorted according to are placed according to their Partitioner: CompareWith or CompareSubcolumnsWith •Random: MD5 of key •Order-Preserving: actual key are sorted by key, regardless of partitioner
- 44. is cassandra a good fit? • you need really fast writes • your programmers can deal • you need durability – documentation • you have lots of data – complexity – consistency model > GBs – change >= three servers – visibility tools • your app is evolving • your operations can deal – startup mode, fluid data – hardware considerations structure – can move data • loose domain data – JMX monitoring – “points of interest”