Data Summer Conf 2018, “Building unified Batch and Stream processing pipeline with Apache Beam (RUS)” — Oleksandr Saienko, Tech Leader/ Senior Software Engineer at SoftServe
3 likes624 views

The document discusses building a unified batch and stream processing pipeline using Apache Beam, highlighting the concept of unbounded data and its processing requirements. Apache Beam offers a unified programming model that supports both batch and streaming data use cases, allowing for portability and extensibility across various execution environments. It outlines essential components such as PCollections, transforms, windowing, and triggers, emphasizing the simplicity and maintainability of the programming model.


























![Beam Processing pipeline
[Output PCollection] = [Input PCollection].apply([Transform])
[Final Output PCollection] =
[Initial Input PCollection].apply([First Transform])
.apply([Second Transform])
.apply([Third Transform])
https://beam.apache.org/documentation/programming-guide/#applying-transforms](https://image.slidesharecdn.com/saienko-180801114919/85/Data-Summer-Conf-2018-Building-unified-Batch-and-Stream-processing-pipeline-with-Apache-Beam-RUS-Oleksandr-Saienko-Tech-Leader-Senior-Software-Engineer-at-SoftServe-27-320.jpg)

































Data Summer Conf 2018, “Building unified Batch and Stream processing pipeline with Apache Beam (RUS)” — Oleksandr Saienko, Tech Leader/ Senior Software Engineer at SoftServe
- 1. Building unified Batch and Stream processing pipeline with Apache Beam Senior Software Engineer, PhD Oleksandr Saienko
- 2. What is a Stream Data? Unbounded data: – Conceptually infinite, set of data items / events Unbounded data processing: – Practically continuous stream of data, which needs to be processed / analyzed Low-latency, approximate, and/or speculative results: - These types of results are most often associated with streaming engines https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101 Flickr Image: Binary Flow by Adrenalin
- 3. Streaming data sources • The internet of things (IoT) - Real Time Sensor data collection, analysis & alerts • Autonomous Driving – 1GB data per minute per car (all sensors) • Traffic Monitoring – High event rates: millions events / sec – High query rates: thousands queries / sec • Pre-processing of sensor data – CERN experiments generate ~1PB of measurements per second. – Unfeasible to store or process directly, fast preprocessing is a must. … https://www.cohere-technologies.com/technology/overview/
- 4. Big Data vs Fast Data vs Big Fast Data https://www.scads.de/images/Events/3rdSummerSchool/Talks/TRabl_StreamProcessing.pdf Image by: Peter Pietzuch Latency
- 5. 8 Requirements of Stream Processing • Keep the data moving • Declarative access • Handle imperfections • Predictable outcomes • Integrate stored and streaming data • Data safety and availability • Automatic partitioning and scaling • Instantaneous processing and response http://cs.brown.edu/~ugur/8rulesSigRec.pdf The 8 Requirements of Real-Time Stream Processing – Stonebraker et al. 2005
- 6. Big Data Landscape 2018 http://mattturck.com/wp-content/uploads/2018/07/Matt_Turck_FirstMark_Big_Data_Landscape_2018_Final.png
- 7. Big Data Landscape 2018 http://mattturck.com/wp-content/uploads/2018/07/Matt_Turck_FirstMark_Big_Data_Landscape_2018_Final.png
- 9. Customer requirements: • Unified solution that can be deployed on Cloud and on-premise (without major changes) • Cloud agnostic, can be run on GCP, AWS, Azure, etc… • Can work both batch and streaming mode • Easy to find developers • Easy maintainable
- 10. Typical solution: • Extremely painful to maintain two different stacks • Different programming models and languages • Multi implementation effort • Multi operational effort • … • Build two (or more) stacks – one for batch, one for streaming • Build two (or more) solutions – for cloud (using cloud managed services), one for on-premise
- 11. Distributed Streaming Processing APIs…
- 12. What is Apache Beam? Apache Beam is a unified programming model designed to provide efficient and portable data processing pipelines https://beam.apache.org/get-started/beam-overview/
- 13. What is Apache Beam? Apache Beam is a unified programming model designed to provide efficient and portable data processing pipelines https://beam.apache.org/get-started/beam-overview/
- 14. Why Apache Beam? Unified - One model handles batch and streaming use cases. Portable - Pipelines can be executed on multiple execution environments, avoiding lock-in. Extensible - Supports user and community driven SDKs, Runners, transformation libraries, and IO connectors. https://beam.apache.org/get-started/beam-overview/
- 15. What is Apache Beam? https://beam.apache.org/get-started/beam-overview/
- 16. The Apache Beam Vision The Beam abstraction Model: ● Choice of SDK: Users write their pipelines in a language that’s familiar and integrated with their other tooling ● Choice of Runners: Users choose the right runtime for their current needs -- on-prem / cloud, open source / not, fully managed ● Scalability for Developers: Clean APIs allow developers to contribute modules independently https://beam.apache.org/get-started/beam-overview/
- 17. The Apache Beam Vision ● Multiple runners: ○ Apache Apex ○ Apache Flink ○ Apache Spark ○ Google Dataflow ○ Apache Samza ○ Apache Gearpump ● Programming lang: ○ Java ○ Python ○ Go ○ Scala* (Scio) https://beam.apache.org/get-started/beam-overview/
- 18. Beam currently supports the following language-specific SDKs: Java Go Python A Scala interface is also available as Scio The Apache Beam Vision https://beam.apache.org/get-started/beam-overview/ *Beam SQL
- 19. A Scala API for Apache Beam and Google Cloud Dataflow l Scio is a Scala API for Apache Beam and Google Cloud Dataflow inspired by Apache Spark and Scalding. Features: Scala API close to that of Spark and Scalding core APIs Unified batch and streaming programming model Integration with Algebird and Breeze https://github.com/spotify/scio
- 20. The Cloud Dataflow Service A great place for executing Beam pipelines which provides: ● Fully managed, no-ops execution environment ● Integration with Google Cloud Platform https://beam.apache.org/get-started/beam-overview/
- 21. In Beam, a big data processing pipeline is a DAG (directed, acyclic graph) of parallel operations called PTransforms processing data from PCollections Beam Processing pipeline https://beam.apache.org/get-started/beam-overview/
- 22. PipelineRunner PipelineRunner: specifies where and how the pipeline should execute. The Spark Runner executes Beam pipelines on top of Apache Spark, providing: •Batch and streaming (and combined) pipelines. •The same fault-tolerance guarantees as provided by RDDs and DStreams. •Native support for Beam side-inputs via spark’s Broadcast variables. $ java -Dexec.mainClass=com.examples.WordCount -Dexec.args=“ --runner=SparkRunner …. Options options = PipelineOptionsFactory.fromArgs(args)
- 23. PCollection • Parallel collection of timestamped elements • Could be bounded or unbounded. • Immutable. Once created, you cannot add, remove, or change individual elements. • Does not support random access to individual elements. • Belongs to the pipeline in which it is created. You cannot share a PCollection between Pipeline objects.
- 24. Built-in I/O Support Messaging Amazon Kinesis AMQP Apache Kafka Google Cloud PubSub JMS MQTT File-based Apache HDFS, Amazon S3, Google GCS, local filesystems. FileIO (general- purpose) AvroIO ParquetIO TextIO TFRecordIO XmlIO TikaIO Database Apache Cassandra Apache Hadoop InputFormat Apache HBase Apache Hive (HCatalog) Apache Solr Elasticsearch Google BigQuery Google Cloud Bigtable Google Cloud Datastore JDBC MongoDB Redis https://beam.apache.org/documentation/io/built-in/
- 25. In-Progress I/O ... https://beam.apache.org/documentation/io/built-in/
- 27. Beam Processing pipeline [Output PCollection] = [Input PCollection].apply([Transform]) [Final Output PCollection] = [Initial Input PCollection].apply([First Transform]) .apply([Second Transform]) .apply([Third Transform]) https://beam.apache.org/documentation/programming-guide/#applying-transforms
- 28. Performs a user-provided transformation on each element of a PCollection independently ParDo can output 1, 0 or many values for each input element ParDo can be used for many different operations... Element Wise Transforms: ParDo https://beam.apache.org/documentation/programming-guide/#applying-transforms
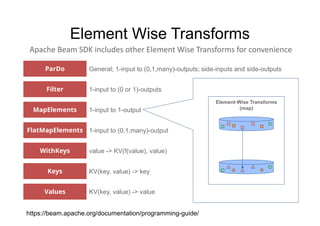
- 29. Apache Beam SDK includes other Element Wise Transforms for convenience FlatMapElements MapElements ParDo Filter Values Keys WithKeys General; 1-input to (0,1,many)-outputs; side-inputs and side-outputs 1-input to (0 or 1)-outputs 1-input to 1-output 1-input to (0,1,many)-output value -> KV(f(value), value) KV(key, value) -> key KV(key, value) -> value Element-Wise Transforms (map) Element Wise Transforms https://beam.apache.org/documentation/programming-guide/
- 30. Apache Beam SDK includes other Element Wise Transforms for convenience FlatMapElements MapElements ParDo Filter Values Keys WithKeys Element Wise Transforms You can use Java 8 lambda functions with several other Beam transforms, including Filter, FlatMapElements, and Partition https://beam.apache.org/documentation/programming-guide/
- 31. What your (Java) Code Looks Like Filter ToLowerCase Count WriteFile ReadFile ExtractWords File Predictions Pipeline p = Pipeline.create(new PipelineOptions()) p.run(); .apply("ExtractWords",FlatMapElements.into(TypeDescriptors.strings()) .via((String word) -> Arrays.<String>asList(word.split("... .apply("Filter",Filter.by((String word) -> word.length()>1)) .apply("ToLowerCase",MapElements.into(TypeDescriptors.strings()) .via((String word) -> word.toLowerCase())) .apply(TextIO.write().to("... .p.apply("ReadFile",TextIO.read().from("... .apply("CountWords", Count.perElement()) ... https://beam.apache.org/documentation/programming-guide/
- 32. Grouping Transforms: GroupByKey The input to GroupByKey is a collection of key/value pairs, you use GroupByKey to collect all of the values associated with each unique key. https://beam.apache.org/documentation/programming-guide/
- 33. Grouping Transforms: CoGroupByKey CoGroupByKey performs a relational join of two or more key/value PCollections that have the same key type: https://beam.apache.org/documentation/programming-guide/
- 35. Combine Combine is a Beam transform for combining collections of elements or values in your data. When you apply a Combine transform, you must provide the function that contains the logic for combining the elements or values. The combining function should be commutative and associative https://beam.apache.org/documentation/programming-guide/
- 36. Partition Partition is a Beam transform for PCollection objects that store the same data type. Partition splits a single PCollection into a fixed number of smaller collections. https://beam.apache.org/documentation/programming-guide/
- 39. Flatten Flatten and is a Beam transform for PCollection objects that store the same data type. Flatten merges multiple PCollection objects into a single logical PCollection.
- 41. Composite transforms Transforms can have a nested structure, where a complex transform performs multiple simpler transforms (such as more than one ParDo, Combine, GroupByKey, or even other composite transforms). Nesting multiple transforms inside a single composite transform can make your code more modular and easier to understand. Composite Transforms (reusable combinations) https://beam.apache.org/documentation/programming-guide/
- 43. Requirements for writing user code for Beam transforms In general, your user code must fulfill at least these requirements: • Your function object must be serializable. • Your function object must be thread-compatible, and be aware that the Beam SDKs are not thread-safe. https://beam.apache.org/documentation/programming-guide/
- 44. Immutability requirements • You should not in any way modify an element returned by ProcessContext.element() or ProcessContext.sideInput() (the incoming elements from the input collection). • Once you output a value using ProcessContext.output() or ProcessContext.sideOutput(), you should not modify that value in any way. https://beam.apache.org/documentation/programming-guide/
- 45. Side inputs Side inputs – global view of a PCollection used for broadcast / joins. ParDo can receive extra inputs “on the side” For example broadcast the count of elements to the processing of each element Side inputs are computed (and accessed) per-window https://beam.apache.org/documentation/programming-guide/
- 46. Side Outputs ParDo(SomeDoFn) input elements Main Output Bogus Inputs Write Out Continue Pipeline ParDos can produce multiple outputs For example: A main output containing all the successfully processed results A side output containing all the elements that failed to be processed https://beam.apache.org/documentation/programming-guide/
- 47. Beam SQL Beam SQL allows to query bounded and unbounded PCollections with SQL statements. Your SQL query is translated to a PTransform, an encapsulated segment of a Beam pipeline. https://beam.apache.org/documentation/dsls/sql/overview/ http://calcite.apache.org/ PCollection<Row> filteredNames = items.apply( BeamSql.query( "SELECT appId, description, rowtime FROM PCOLLECTION WHERE id=1"));
- 48. Windowing Key 2Key 1 Key 3 1 Fixed 2 3 4 Key 2Key 1 Key 3 Sliding 1 2 3 5 4 Key 2Key 1 Key 3 Sessions 2 4 3 1 Windowing - partitions data based on the timestamps associated with events https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
- 50. Windowing
- 51. Unbounded, out of order Streams 8:00 8:00 8:00 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
- 52. Processing Time vs Event Time ProcessingTime Realtime Event Time Delay
- 53. Triggers allow you to deal with late-arriving data or to provide early results Determines when to emit the results of aggregation as unbounded data arrives. Triggers When collecting and grouping data into windows, Beam uses triggers to determine when to emit the aggregated results of each window input .apply(Window.into(FixedWindows.of(...)) .triggering( AfterWatermark.pastEndOfWindow())) .apply(Sum.integersPerKey()) .apply(BigQueryIO.Write.to(...)) https://beam.apache.org/documentation/programming-guide/
- 55. Watermarks • The “event time”, determined by the timestamp on the data element itself • Watermark, which is the system’s notion of when all data in a certain window can be expected to have arrived in the pipeline. • Data that arrives with a timestamp after the watermark is considered late data. https://beam.apache.org/documentation/programming-guide/#watermarks-and-late-data Note: Managing late data is not supported in the Beam SDK for Python
- 59. Pros of Apache Beam • Abstraction over different execution backends and programming languages. • Clean and Simple programming model. (easy to understand, implement and maintain) • Same data pipeline for batch processing as well as for stream processing.
- 60. Apache Beam https://beam.apache.org The World Beyond Batch 101 & 102 https://www.oreilly.com/ideas/the-world-beyond-batch- streaming-101 https://www.oreilly.com/ideas/the-world-beyond-batch- streaming-102 Why Apache Beam? A Google Perspective http://goo.gl/eWTLH1
- 61. Thank you!