Why we love ArangoDB. The hunt for the right NosQL Database
5 likes6,381 views

ArangoDB is a modern multi-model NoSQL database. The slides explains how we found and why we love ArangoDB. The talk was given at PyMunich 2016.































































Ad
More Related Content
What's hot (20)
Similar to Why we love ArangoDB. The hunt for the right NosQL Database (20)

![NoSQL for great good [hanoi.rb talk]](https://cdn.slidesharecdn.com/ss_thumbnails/kvs-hanoirb-150728163935-lva1-app6891-thumbnail.jpg?width=560&fit=bounds)
















Ad
More from Andreas Jung (20)




















Ad
Recently uploaded (20)




















Why we love ArangoDB. The hunt for the right NosQL Database
- 1. The hunt for the right NoSQL database Andreas Jung @MacYET [email protected] • www.zopyx.de Why we ♥
- 2. Why we ♥ /about • Python developer since 1993 • Freelancer since 2004 • Python, Zope, Plone … • individual software development • Electronic Publishing (Publishing workflows DOCX→XML→PDF | EPUB | HTML, XML consulting) • Founded publishing projects • XML-Director • Produce & Publish
- 3. Why we ♥ Disclaimer • This talk is completely • biased • opinionated • unscientific • not affiliated with ArangoDB GmbH
- 4. Why we ♥ Relational databases • well understood • common data model • long history: • System R (1974) • Oracle (1979) • Structured Query Language (Standards: ISO/IEC 9075 + 13249) • theoratically interoperable if you stick to the SQL standard
- 5. Why we ♥ NoSQL = not SQL
- 6. Why we ♥ NoSQL = non-relational
- 7. Why we ♥ “NoSQL is not about performance, scaling, dropping ACID or hating SQL — it is about choice. As NoSQL databases are somewhat different it does not help very much to compare the databases by their throughput and chose the one which is faster. Instead—the user should carefully think about his overall requirements and weight the different aspects. Massively scalable key/value stores or memory-only systems can archive much higher benchmarks. But your aim is to provide a much more convenient system for a broader range of use-cases— which is fast enough for almost all cases.” Jan Lenhardt (CouchDB)
- 8. Why we ♥ Categories of NoSQL databases • Key-Value • Memcached, Redis, Riak, … • Column-oriented • Cassandra, … • Document (JSON) • MongoDB, CouchDB, … • Tabular • Big Table, Hase, … • Graph • Neo4J, … • XML, Object… • eXist, BaseX, Marclogic, ZODB, … http://martinfowler.com/articles/nosqlKeyPoints.html https://www.youtube.com/watch?v=qI_g07C_Q5I
- 9. Why we ♥ New challenges • Cloud • Replication • massive data explosion: „Big Data“ • Globally distributed systems • Specialized requirements ➡ more specialized databases ➡ Relational databases are no longer the only option
- 10. Why we ♥ CAP Theorem It is impossible for a distributed computer system to simultaneously provide all three of the following guarantees: • Consistency (every read receives the most recent write or an error) • Availability (every request receives a response, without guarantee that it contains the most recent version of the information) • Partition tolerance (the system continues to operate despite arbitrary partitioning due to network failures) (Eric Brewer) PICK TWO
- 11. Why we ♥ My personal hunt for a multi-purpose NoSQL database … • Should fit most mid-size projects • Document store (+ graphs) • Arbitary query options • Cross-table/collection relationships • (optional) transactional integrity (ACID) across multiple documents and operations • replication/clustering
- 12. Why we ♥ My personal hunt… …and various others
- 13. Why we ♥ My personal hunt… …and various others
- 14. Why we ♥ bought in 2015 by
- 15. Why we ♥ The high-end $$$$ solution • the most professional, feature-complete, feature-rich NoSQL database ever • document (XML/JSON) store and graph database • focus on data integration and data consolidation • expensive but worth the money if you need the features • widely used in enterprises (saved „Obama-Care“ project)
- 16. Why we ♥ A native multi-model database • Document store (JSON) • JOINs, secondary indexes, ACID transactions • Key-value store • Graph database • integrates with document store • rich graph query operations • nodes and edges can contain complex data ➡ all models can be combined
- 17. Why we ♥ Foxx framework • implement your own REST micro-services directly with Javascript running inside ArangoDB • unified data storage logic (decouples API from external services) • reduced network overhead (no network latencies) • you can use the full JS Stack • batteries included • build-in job queue
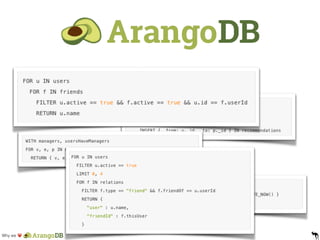
- 18. Why we ♥ AQL - One Query Language to rule them all • AQL = Arango Query Language • declarative, human-readable DSL (I hate JSON queries) • document queries, graph queries, joins, all combined in one statement • ACID support with multi-collection transactions • easy to understand with some SQL background
- 19. Why we ♥
- 20. Why we ♥
- 21. Why we ♥
- 22. Why we ♥
- 23. Why we ♥
- 24. Why we ♥
- 25. Why we ♥ • Agency (high-avail resilient key/value store, Raft Consensus Protocol) • Coordinators • Primary DB servers • Secondaries • Asynchronous/ synchronous replication with automatic fail-over Custering, replication, sharding
- 26. Why we ♥ Benchmark (against ArangoDB V 2) https://www.arangodb.com/2015/10/benchmark-postgresql-mongodb-arangodb/
- 27. Why we ♥ Benchmark (against ArangoDB V 2) https://www.arangodb.com/2015/10/benchmark-postgresql-mongodb-arangodb/ Neighbour search Shortest path
- 28. Why we ♥ Python bindings (PyArango)
- 29. Why we ♥ Python bindings (PyArango) Query (AQL) Query (by example)
- 30. Why we ♥ Graphs
- 31. Why we ♥ Deployment & operations
- 32. Why we ♥ Misc • current version 3.0, (3.1 RC3) • good documentation • regular updates and fixes • nicely supported • supported by ArangoDB GmbH in Cologne
- 33. Why we ♥ • Community Edition (Apache License 2.0) • Enterprise Edition (SLA, support options, smart graphs, auditing, better security control) https://www.arangodb.com/why-arangodb/references/https://www.arangodb.com/arangodb-drivers/