Visualizations using Visualbox
1 like1,161 views

In this talk I will show Visualbox, a "visualization server" based on LODSPeaKr that can make easy for non javascript experts to create simple but meaningful visualizations.
























































More Related Content
Viewers also liked (8)
Similar to Visualizations using Visualbox (20)






More from Alvaro Graves (11)











Recently uploaded (20)




















Visualizations using Visualbox
- 1. VISUALIZATIONS WITH SPARQL AND VISUALBOX Alvaro Graves @alvarograves [email protected]
- 2. MOTIVATION Linked Data brings tons of multidimensional data that is easy(*) to query However, having to make use of all that data we still need to being able to process it (as humans) One good way to make sense of this data is by using visualizations (*) Once you learn SPARQL
- 3. EXAMPLE versus Images: Few, Stephen (2010): Data Visualization for Human Perception. In: Soegaard, Mads and Dam, Rikke Friis (eds.). "Encyclopedia of Human-Computer Interaction". Aarhus, Denmark: The Interaction Design Foundation. Available online at http://www.interaction-design.org/encyclopedia/data_visualization_for_human_perception.html
- 4. VISUALBOX Based on LODSPeaKr Make use of new and already existing visualization filters Creating of visualization via new GUI Principle: Good data representation leads to good/easy data manipulation Corolary: Effort should be focused on obtaining the right data
- 5. VISUALBOX
- 6. MODELS (SPARQL QUERY) Using the SELECT query form will return a table, similar to SQL. main.query PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?person1 ?person2 WHERE{ ?person1 foaf:knows ?person2 . } person1 person2 http://example.org/john http://example.org/paul http://example.org/john http://example.org/ringo http://example.org/george http://example.org/paul
- 7. VIEWS (TEMPLATES) We can decide how to operate with the data. html.template <ul> {{for row in models.main}} <li>{{row.person1.value}} knows {{row.person2.value}}</li> {{endfor}} </ul> output http://example.org/john knows http://example.org/paul http://example.org/john knows http://example.org/ringo http://example.org/george knows http://example.org/paul
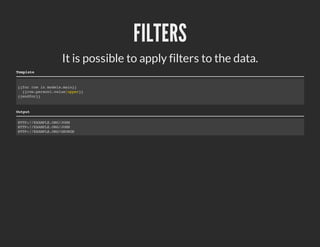
- 8. FILTERS It is possible to apply filters to the data. Template {{for row in models.main}} {{row.person1.value|upper}} {{endfor}} Output HTTP://EXAMPLE.ORG/JOHN HTTP://EXAMPLE.ORG/JOHN HTTP://EXAMPLE.ORG/GEORGE
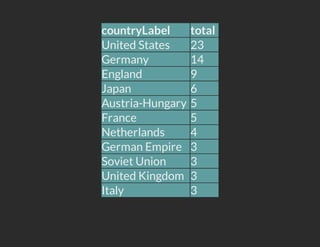
- 9. VISUALIZATION FILTERS It is possible to apply visualization filters directly to all the results. These filters will generate the necessary code to create a visualization Model (main.query) PREFIX cat: <http://dbpedia.org/resource/Category:> SELECT ?countryLabel (COUNT(?nobel) as ?total) WHERE { ?nobel dcterms:subject cat:Nobel_laureates_in_Physics; a foaf:Person; dbp:placeOfBirth ?country . ?country a schema:Country ; rdfs:label ?countryLabel FILTER(LANG(?countryLabel) = "en") }GROUP BY ?country ?countryLabel ORDER BY DESC(?total) LIMIT 100
- 10. countryLabel total United States 23 Germany 14 England 9 Japan 6 Austria-Hungary 5 France 5 Netherlands 4 German Empire 3 Soviet Union 3 United Kingdom 3 Italy 3
- 11. View (html.template) <body> <h2>Total of Nobel laureates in Physics by country</h2> {{models.main|GoogleVizPieChart:"countryLabel,total"}} </body>
- 12. TABULAR DATA Easiest case: consider table-based visualizations. View (html.template) {{models.main|GoogleVizColumnChart:"countryLabel,total"}}
- 15. MAPS Represent data as latitude, longitude and label SELECT DISTINCT ?city SAMPLE(?lat) AS ?latitude SAMPLE(?long) AS ?longitude ?area WHERE{ ?city a sch:City ; <http://dbpedia.org/ontology/country> <http://dbpedia.org/resource/United_States> ; geo:lat ?lat ; geo:long ?long; dbp:areaTotalKm ?area . }GROUP BY ?city ?area ORDER BY DESC(?area) LIMIT 10
- 16. latitude longitude area 45.4983 -91.7389 25.0 30.3167 -81.6667 2292 45.9989 -112.53 1868
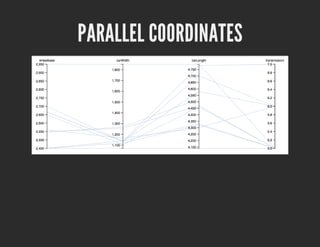
- 18. PARALLEL COORDINATES Query SELECT ?carLabel ?wheelbase ?carWidth ?carLength ?transmission WHERE { ?car dcterms:subject <http://dbpedia.org/resource/Category:Lamborghini_vehicles>; <http://dbpedia.org/ontology/Automobile/wheelbase> ?wheelbase; <http://dbpedia.org/ontology/MeanOfTransportation/height> ?carWidth; <http://dbpedia.org/ontology/MeanOfTransportation/length> ?carLength; <http://dbpedia.org/property/transmission> ?transmission; rdfs:label ?carLabel. FILTER(LANG(?carLabel) = "en") }
- 19. PARALLEL COORDINATES carLabel wheelbase carWidth carLength transmission Lamborghini Aventador 2700.0 1136.0 4780.0 7 Lamborghini Reventón 2665.0 1135.0 4700.0 6 Lamborghini 400GT 2550.0 1257.0 4470.0 5 Template {{models.main|D3ParallelCoordinates:"carLabel,wheelbase,carWidth,carLength,transmission"}}
- 21. GRAPHS Question: How to express a graph in a table? Answer: Table child → parent Model (main.query) SELECT ?person1 ?person2 WHERE{ ?person1 foaf:knows ?person2 . } person1 person2 Elizabeth Engstrom Ray Bradbury Neil Gaiman Robert A. Heinlein Neil Gaiman Ray Bradbury
- 22. View (html.template) {{models.main|D3ForceGraph:"person1,person2"}}
- 23. TREE STRUCTURES Problem: How do we retrieve a tree as a table? Solution (so far): Table child,parent with one row with no parent (root) child parent area Averill Park, New York Rensselaer County, New York 8.02896e+06 Sand Lake, New York Rensselaer County, New York 9.36e+07 Schaghticoke (town), New York Rensselaer County, New York 1.3442e+08 Poestenkill (town), New York Rensselaer County, New York 8.44336e+07 Schaghticoke (village), New York Rensselaer County, New York 2.33099e+06 Rensselaer County, New York
- 24. TREE STRUCTURES Query PREFIX d: <http://dbpedia.org/ontology/> SELECT max(?regionLabel) as ?child max(?superregionLabel) as ?parent (max(?totalArea) as ?area) WHERE{ { ?region d:isPartOf <http://dbpedia.org/resource/Rensselaer_County,_New_York>; d:areaTotal ?totalArea ; rdfs:label ?regionLabel; d:isPartOf ?superregion . ?superregion rdfs:label ?superregionLabel. FILTER(?superregion = <http://dbpedia.org/resource/Rensselaer_County,_New_York>) FILTER(lang(?superregionLabel) = "en") }UNION{ ?region rdfs:label ?regionLabel . FILTER(?region = <http://dbpedia.org/resource/Rensselaer_County,_New_York>) } FILTER(lang(?regionLabel) = "en") }GROUP BY ?regionLabel ?superregionLabel Template {{models.main|D3CirclePacking:"child,parent,area"}}
- 26. TREE STRUCTURES (2) Query (neruda.query) PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX dbp: <http://dbpedia.org/ontology/> PREFIX d: <http://dbpedia.org/resource/> SELECT DISTINCT ?child ?parent WHERE{ { ?childNode dbp:influencedBy ?mid ; rdfs:label ?child . ?mid dbp:influencedBy ?parentNode; rdfs:label ?parent . FILTER(LANG(?parent) = "en" && ?parentNode = d:Pablo_Neruda) }UNION{ ?childNode dbp:influencedBy d:Pablo_Neruda; dbp:influencedBy ?parentNode; rdfs:label ?child . ?parentNode rdfs:label ?parent . FILTER(LANG(?parent) = "en" && ?parentNode = d:Pablo_Neruda) }UNION{ d:Pablo_Neruda rdfs:label ?child } FILTER(LANG(?child) = "en") }
- 27. child parent Pablo Neruda Dane Zajc Pablo Neruda Gary Soto Pablo Neruda James Tate (writer) Pablo Neruda Richard Aitson Pablo Neruda Erin Siegal Pablo Neruda Jože Snoj Dane Zajc Rudi Šeligo Dane Zajc Veno Taufer Dane Zajc Rigoberto González Gary Soto Thomas Lux James Tate (writer) html.template {{models.main|D3Dendrogram:"child,parent"}}
- 29. NOW YOU CREATE YOUR OWN VISUALIZATION Use data that is of interest for you Describe to tell a story or support a statement Give me feedback on how does visualbox works for you