Distributed count(distinct) with hyper loglog on postgresql | PGConf EU 2017) | Burak Yucesoy
0 likes1,468 views

The document discusses distributed counting of distinct elements in PostgreSQL using HyperLogLog (HLL), an approximation algorithm that estimates the cardinality of data efficiently with low memory usage. It outlines the challenges of distributed counting, including data too large for a single machine's memory, and presents HLL as a scalable solution for approximating distinct counts with mathematically proven error bounds. The process involves hashing data, observing rare bit patterns, and taking stochastic averages to provide accurate estimations while minimizing memory footprint.
1 of 39
Downloaded 14 times






































Ad
Recommended
To find raise to five of any number
To find raise to five of any numberInternational Journal of Latest Research in Engineering and Technology This document presents a method for finding the fifth power (raise to five) of any number. It begins by reviewing how to find the cube of a number, then extends this method to finding higher powers. The key steps are to (1) raise the leftmost digit to the power, (2) write subsequent digits in a ratio-based pattern, (3) multiply certain digits and write the results under the original numbers, (4) add the rows together while carrying digits. An example of finding 12^5 is shown step-by-step. The method is then generalized to any numbers and higher powers.
Tutorial of topological data analysis part 3(Mapper algorithm)
Tutorial of topological data analysis part 3(Mapper algorithm)Ha Phuong The document provides an overview of the Mapper algorithm, a technique from topological data analysis. It begins by introducing basic concepts from topology like Reeb graphs and Morse theory. It then describes the key steps of the Mapper algorithm: (1) defining a filter function on the data, (2) clustering inverse images of the filter, and (3) connecting clusters to form a graph. The document discusses practical considerations like choosing filter functions and parameters. It also provides examples of applying Mapper for tasks like clustering, feature selection, and data exploration.
Lecture1a data types
Lecture1a data typesmbadhi barnabas The document discusses different data types including primitive data types like integer, real, boolean, and char, as well as complex data types like arrays, matrices, and records/structures. For each data type, it provides definitions, examples of values and operations, and in some cases pseudocode. It discusses integer and real numbers in depth, explaining how they are represented and operated on in computers. Boolean logic and truth tables are also covered. The last part provides exercises for readers to practice applying concepts from the document.
FPGA DESIGN FOR H.264/AVC ENCODER
FPGA DESIGN FOR H.264/AVC ENCODERIJCSEA Journal This document presents an FPGA architecture for a real-time H.264/AVC video encoder, achieving over 177 million pixels per second throughput at 130 MHz. The design utilizes parallel and pipelined architecture optimized for area cost and is described in VHDL, suitable for high-definition video applications. It discusses encoding techniques, such as intra and inter prediction, motion estimation, and integer transformations for enhanced compression performance.
Graph Matching
Graph Matchinggraphitech The document describes using the Kuhn-Munkres or "Hungarian" algorithm to solve the graph matching problem. It formulates graph matching as a minimum-cost bipartite matching problem that can be solved using the Hungarian algorithm. It then outlines the steps of the algorithm, which involves constructing adjacency matrices for the graphs, computing eigenvectors, obtaining a correlation matrix, converting it into a cost matrix, applying the Hungarian algorithm to find the matching, and outputting the results.
presentation
presentationjie ren This document presents a scheme for interactive communication between a base station and mobile stations to efficiently allocate resources. It models the problem and analyzes an approach where the base station broadcasts a threshold and mobile stations reply to indicate if their value is above or below it. Through multiple rounds of interaction, the base station can determine the mobile station with the maximum value with significantly less overhead than non-interactive schemes. Simulation results show the proposed approach of encoding the threshold or number of users at each round performs better than baselines. Extensions consider incorporating distortion and trading off communication costs versus time.
The DE-9IM Matrix in Details using ST_Relate: In Picture and SQL
The DE-9IM Matrix in Details using ST_Relate: In Picture and SQLtorp42 The document presents an in-depth exploration of the DE-9IM matrix and the ST_Relate function in spatial database contexts, particularly for 2D geometries. It outlines various geometrical relationships through examples involving polygons and linestrings, emphasizing the practical applications of ST_Relate in SQL queries. The content is structured to enhance understanding of geometry relationships and provides insights into the workings of spatial queries.
What is HyperLogLog and Why You Will Love It | PostgreSQL Conference Europe 2...
What is HyperLogLog and Why You Will Love It | PostgreSQL Conference Europe 2...Citus Data The document explains HyperLogLog (HLL), an efficient algorithm for approximating the count of distinct elements in large datasets, addressing limitations of traditional count(distinct) methods such as high resource consumption and slow performance. HLL provides a low memory footprint, can handle streaming data, and offers mathematically provable error rates, making it suitable for various applications, including PostgreSQL integrations. Additionally, it covers practical implementations, including rollup tables to optimize aggregation results over specified time intervals.
Kusto (Azure Data Explorer) Training for R&D - January 2019
Kusto (Azure Data Explorer) Training for R&D - January 2019 Tal Bar-Zvi This document summarizes a training presentation on Azure Data Explorer (Kusto). The presentation covered:
1. An introduction to Kusto as a new way to analyze big data and logs that is fast, easy to use, and helps understand services quickly.
2. Examples of different Kusto query types including counting, filtering, aggregating, rendering graphs, and combining queries.
3. How Kusto is used at Taboola to analyze HTTP logs from their CDN, including database sizes and architecture.
4. Additional features like dashboards, alerts, notebooks, and community resources for learning more.
5. A question and answer session addressing common questions about Kusto.
Welcome to International Journal of Engineering Research and Development (IJERD)
Welcome to International Journal of Engineering Research and Development (IJERD)IJERD Editor This document describes the VHDL implementation of an arithmetic logic unit (ALU) with built-in self-test (BIST) capability. It first provides background on BIST and its components like the test pattern generator, circuit under test, and response analyzer. It then discusses implementing an ALU with BIST using linear feedback shift registers as the test pattern generator. Simulation results show the ALU operating correctly in normal and BIST modes. The hardware resource utilization is reported, showing the ALU with BIST uses 55 slices, 43 flip-flops, and 102 look-up tables, representing a small area overhead.
Oblu Integration Guide
Oblu Integration Guideoblu.io The document is an integration guide for the oblu multi-IMU inertial navigation module, detailing its data processing flow and communication protocol. It outlines the capabilities of oblu for foot-mounted pedestrian applications, including wireless data transfer, simplified output data formats, and a variety of commands for interfacing with external application platforms. Key features include stepwise dead reckoning and transmitting inertial sensor data, along with examples of command structures and data packet formats.
1 out of 20 scenarios
1 out of 20 scenariosDario Buono The document discusses methods for temporal disaggregation of annual sector accounts data, particularly for small EU countries which report only partial quarterly data. It outlines various mathematical and regression-based methods, emphasizing that approaches like Chow-Lin offer statistical advantages for estimating missing quarterly series. The exercise demonstrates that with modern software such as JDemetra+, these disaggregation methods can be executed rapidly and are beneficial for data production.
Data Monitoring with whylogs
Data Monitoring with whylogsAlexey Grigorev Whylogs is an open source tool for data monitoring that automatically creates statistical summaries called profiles of datasets. It helps with data monitoring by generating these profiles which can be compared over time to detect changes visually or programmatically. This allows issues like schema changes or bugs in data pipelines to be identified. The profiles have properties like being descriptive, lightweight and mergeable, which enables monitoring across distributed systems by allowing profile data to be logically merged. Whylogs thus provides a step towards observability of data systems.
Proposal and Implementation of the Connected-Component Labeling of Binary Ima...
Proposal and Implementation of the Connected-Component Labeling of Binary Ima...CSCJournals The paper presents a proposal and implementation for an efficient connected-component labeling (CCL) technique for binary images, enhancing the conventional methods by introducing a pixel-by-pixel parallel algorithm and a hole filling process (HFP) that operates on both foreground and background simultaneously. The implementation on the Jetson TX2 demonstrated significant performance improvements, with rewriting label IDs being 3.7-13.8 times faster than traditional CPU methods, and the HFP method achieving 13-27% better performance than previous approaches. These advancements enable high-speed image processing applications, such as facial detection, on low-cost processors.
IRJET- Design of 16 Bit Low Power Vedic Architecture using CSA & UTS
IRJET- Design of 16 Bit Low Power Vedic Architecture using CSA & UTSIRJET Journal The document proposes a 16-bit low power Vedic architecture using the Urdhava Tiryakbhyam Sutra (UTS) method of Vedic mathematics and carry select adders. UTS allows for the parallel generation of partial products in multiplication, improving speed. The proposed design decomposes 16-bit numbers into pairs of 8-bit blocks, uses 8-bit UTS multipliers, and adds results with carry select adders. This structure is expected to reduce power consumption and delay compared to other multipliers.
Robert Haas Query Planning Gone Wrong Presentation @ Postgres Open
Robert Haas Query Planning Gone Wrong Presentation @ Postgres OpenPostgresOpen The document summarizes the results of analyzing hundreds of email threads about query performance problems in PostgreSQL over two years. It found that the most common issues were:
1) Planner errors in row count or cost estimation, particularly underestimating the selectivity of correlated filter conditions and incorrectly estimating the performance of index scans with ordering and limits.
2) Settings like cost constants, work_mem, and statistics targets that could be optimized.
3) Queries that are inherently slow due to processing large amounts of data or disk access versus memory.
4) Areas where the planner is limited like not generating certain plan types or parameterization.
DESIGN OF 8-BIT COMPARATORS
DESIGN OF 8-BIT COMPARATORSIRJET Journal This document summarizes the design of different types of 8-bit comparators. It discusses the design of a conventional bit-wise comparator, a borrow look-ahead comparator, and a mux-based comparator. The comparators were designed using Xilinx Vivado software. Simulation results show that the borrow look-ahead comparator has the lowest power consumption of 0.071W and fewest number of cells at 46, making it the most efficient design compared to the conventional and mux-based comparators. The document compares the performance of the different comparator designs in terms of power consumption and number of cells.
Implementation of an arithmetic logic using area efficient carry lookahead adder
Implementation of an arithmetic logic using area efficient carry lookahead adderVLSICS Design The document presents the design of an 8-bit Arithmetic Logic Unit (ALU) that supports various arithmetic operations, including 4-bit multiplication using Booth's algorithm, in order to optimize speed and reduce circuit area. The ALU utilizes a carry look-ahead adder to improve addition performance and integrates multiple logic functions like subtraction and bitwise operations. It emphasizes the efficiency of the design for use in VLSI systems, making it suitable for advanced digital circuits.
GRAPHICAL STRUCTURES in our lives
GRAPHICAL STRUCTURES in our livesxryuseix The document discusses the concept of graphs, defining their essential elements like nodes and edges, and how they can represent events in our lives. It also covers graph implementation techniques, particularly the use of adjacency lists, and explores the efficiency of operations through segment trees. The conclusion emphasizes that events can be represented as graphs, which are manageable by computers and allow for operational efficiencies.
Implementation of 32 Bit Binary Floating Point Adder Using IEEE 754 Single Pr...
Implementation of 32 Bit Binary Floating Point Adder Using IEEE 754 Single Pr...iosrjce El artículo propone la implementación de un sumador de punto flotante de 32 bits utilizando el formato de precisión simple IEEE 754, destacando su habilidad para realizar operaciones aritméticas precisas en FPGA. Se centra en la reducción de la latencia general y el consumo de energía, presentando un algoritmo que mejora el rendimiento de las unidades de punto flotante. La metodología incluye un diseño detallado de módulos de hardware necesarios para la suma y la normalización de resultados en aplicaciones científicas y de procesamiento de datos.
IRJET - Design and Implementation of FFT using Compressor with XOR Gate Topology
IRJET - Design and Implementation of FFT using Compressor with XOR Gate TopologyIRJET Journal This document describes a design for implementing a Fast Fourier Transform (FFT) using an adder compressor with a new XOR gate topology. The goals are to increase power efficiency, reduce logic utilization (LUTs), and decrease time complexity/delay compared to other FFT implementations. An adder compressor is proposed that uses XOR gates to compress 4 input bits into 2 output bits (sum and carry), allowing parallel addition without carry propagation. Simulation results on a Xilinx FPGA show the compressor-based FFT uses fewer LUTs, consumes less power, and has a shorter delay compared to an FFT using a Booth multiplier.
IRJET- To Design 16 bit Synchronous Microprocessor using VHDL on FPGA
IRJET- To Design 16 bit Synchronous Microprocessor using VHDL on FPGAIRJET Journal This document describes the design of a 16-bit synchronous microprocessor using VHDL and its implementation on an FPGA. It discusses the design of key components like the ALU, registers, control unit, memory etc. in VHDL. The individual components are simulated and tested separately before integrating them to build the full microprocessor design. Finally, the functionality of the integrated microprocessor design is validated through simulation using a VHDL simulator.
IRJET- VLSI Architecture for Reversible Radix-2 FFT Algorithm using Programma...
IRJET- VLSI Architecture for Reversible Radix-2 FFT Algorithm using Programma...IRJET Journal This document describes the design of a reversible radix-2 FFT algorithm using programmable reversible gates. It begins with background on the discrete Fourier transform and fast Fourier transform. It then discusses previous work using reversible Peres and TR gates. The main contribution is a proposed method for implementing the radix-2 FFT using a reversible DKG gate. Simulation results for 8-point, 16-point and 32-point FFTs are presented, showing the structure was implemented on a Xilinx FPGA. The reversible FFT design reduces power consumption compared to traditional irreversible implementations.
An efficient hardware logarithm generator with modified quasi-symmetrical app...
An efficient hardware logarithm generator with modified quasi-symmetrical app...IJECEIAES This document presents a low-error, low-area FPGA-based hardware logarithm generator that utilizes a modified quasi-symmetrical approach for efficient digital signal processing. The proposed method enhances approximation accuracy while minimizing hardware complexity compared to traditional logarithm generation methods. Results indicate a significant reduction in both approximation error and hardware area, making it suitable for real-time applications.
Optimizing Geospatial Operations with Server-side Programming in HBase and Ac...
Optimizing Geospatial Operations with Server-side Programming in HBase and Ac...DataWorks Summit The document outlines the optimization of geospatial operations using server-side programming in HBase and Accumulo, detailing the benefits of GeoMesa for managing and analyzing spatio-temporal data at scale. Key topics include indexing with space filling curves, filtering and aggregation techniques, and the implementation of server-side optimizations to enhance performance. It also covers practical applications, integration with frameworks like MapReduce and Spark, and the support for interactive data discovery using notebook servers.
IRJET- Implementation of Ternary ALU using Verilog
IRJET- Implementation of Ternary ALU using VerilogIRJET Journal This document describes the design and implementation of a Ternary Arithmetic Logic Unit (TALU) using Verilog. Ternary logic uses three voltage levels (0, 1, Z) instead of the two levels used in binary, providing benefits like reduced gate counts, memory requirements, and faster speeds. The authors constructed truth tables and implemented simplified logic expressions using ternary multiplexers to build combinational circuits like a full adder. Their TALU design achieved 0% utilization of LUTs and slices on the FPGA, with a delay of 6.125ns which is 84.3% of the maximum delay. The document concludes that ternary logic designs require less memory and power than equivalent binary
BlaBlaCar Elastic Search Feedback
BlaBlaCar Elastic Search Feedbacksinfomicien This document discusses BlaBlaCar's transition from a relational database to the search engine Elasticsearch. It describes how BlaBlaCar changed its data model and indexing approach to better suit Elasticsearch. Challenges included modifying mappings, handling grouping, and dealing with IO limits on their initial two node cluster. The document encourages following BlaBlaCar and applying for open jobs.
Paper id 37201520
Paper id 37201520IJRAT This document describes a novel design for a 32-bit unsigned multiplier using a modified carry select adder (MCSLA). It begins with background on adders and multipliers in VLSI design. It then describes the conventional carry select adder (CSLA) and proposes a modified CSLA (MCSLA) that uses common boolean logic to reduce area and power. The document presents the design and VHDL simulation results of a 32-bit unsigned multiplier using both CSLA and the proposed MCSLA. The results show the MCSLA based multiplier achieves a 45% reduction in power-area-delay product compared to the CSLA based multiplier.
Architecting peta-byte-scale analytics by scaling out Postgres on Azure with ...
Architecting peta-byte-scale analytics by scaling out Postgres on Azure with ...Citus Data The document discusses the hyperscale (Citus) extension for PostgreSQL, which allows for the scaling of distributed, sharded databases while maintaining the benefits of PostgreSQL. It highlights Microsoft's acquisition of Citus Data and the implementation of a robust analytics dashboard for Windows engineers, capable of processing vast amounts of data and supporting high query volumes. Additionally, it covers architectural features such as sharding, high availability, backup, and restore options essential for managing large-scale applications.
Data Modeling, Normalization, and De-Normalization | PostgresOpen 2019 | Dimi...
Data Modeling, Normalization, and De-Normalization | PostgresOpen 2019 | Dimi...Citus Data The document explores data modeling techniques, including normalization and denormalization, with a focus on PostgreSQL. It discusses various database constraints, the significance of primary and foreign keys, and the impact of data structures on algorithms. It also covers examples of denormalization, including the use of materialized views and caching for efficiency in data access.
More Related Content
Similar to Distributed count(distinct) with hyper loglog on postgresql | PGConf EU 2017) | Burak Yucesoy (20)
Kusto (Azure Data Explorer) Training for R&D - January 2019
Kusto (Azure Data Explorer) Training for R&D - January 2019 Tal Bar-Zvi This document summarizes a training presentation on Azure Data Explorer (Kusto). The presentation covered:
1. An introduction to Kusto as a new way to analyze big data and logs that is fast, easy to use, and helps understand services quickly.
2. Examples of different Kusto query types including counting, filtering, aggregating, rendering graphs, and combining queries.
3. How Kusto is used at Taboola to analyze HTTP logs from their CDN, including database sizes and architecture.
4. Additional features like dashboards, alerts, notebooks, and community resources for learning more.
5. A question and answer session addressing common questions about Kusto.
Welcome to International Journal of Engineering Research and Development (IJERD)
Welcome to International Journal of Engineering Research and Development (IJERD)IJERD Editor This document describes the VHDL implementation of an arithmetic logic unit (ALU) with built-in self-test (BIST) capability. It first provides background on BIST and its components like the test pattern generator, circuit under test, and response analyzer. It then discusses implementing an ALU with BIST using linear feedback shift registers as the test pattern generator. Simulation results show the ALU operating correctly in normal and BIST modes. The hardware resource utilization is reported, showing the ALU with BIST uses 55 slices, 43 flip-flops, and 102 look-up tables, representing a small area overhead.
Oblu Integration Guide
Oblu Integration Guideoblu.io The document is an integration guide for the oblu multi-IMU inertial navigation module, detailing its data processing flow and communication protocol. It outlines the capabilities of oblu for foot-mounted pedestrian applications, including wireless data transfer, simplified output data formats, and a variety of commands for interfacing with external application platforms. Key features include stepwise dead reckoning and transmitting inertial sensor data, along with examples of command structures and data packet formats.
1 out of 20 scenarios
1 out of 20 scenariosDario Buono The document discusses methods for temporal disaggregation of annual sector accounts data, particularly for small EU countries which report only partial quarterly data. It outlines various mathematical and regression-based methods, emphasizing that approaches like Chow-Lin offer statistical advantages for estimating missing quarterly series. The exercise demonstrates that with modern software such as JDemetra+, these disaggregation methods can be executed rapidly and are beneficial for data production.
Data Monitoring with whylogs
Data Monitoring with whylogsAlexey Grigorev Whylogs is an open source tool for data monitoring that automatically creates statistical summaries called profiles of datasets. It helps with data monitoring by generating these profiles which can be compared over time to detect changes visually or programmatically. This allows issues like schema changes or bugs in data pipelines to be identified. The profiles have properties like being descriptive, lightweight and mergeable, which enables monitoring across distributed systems by allowing profile data to be logically merged. Whylogs thus provides a step towards observability of data systems.
Proposal and Implementation of the Connected-Component Labeling of Binary Ima...
Proposal and Implementation of the Connected-Component Labeling of Binary Ima...CSCJournals The paper presents a proposal and implementation for an efficient connected-component labeling (CCL) technique for binary images, enhancing the conventional methods by introducing a pixel-by-pixel parallel algorithm and a hole filling process (HFP) that operates on both foreground and background simultaneously. The implementation on the Jetson TX2 demonstrated significant performance improvements, with rewriting label IDs being 3.7-13.8 times faster than traditional CPU methods, and the HFP method achieving 13-27% better performance than previous approaches. These advancements enable high-speed image processing applications, such as facial detection, on low-cost processors.
IRJET- Design of 16 Bit Low Power Vedic Architecture using CSA & UTS
IRJET- Design of 16 Bit Low Power Vedic Architecture using CSA & UTSIRJET Journal The document proposes a 16-bit low power Vedic architecture using the Urdhava Tiryakbhyam Sutra (UTS) method of Vedic mathematics and carry select adders. UTS allows for the parallel generation of partial products in multiplication, improving speed. The proposed design decomposes 16-bit numbers into pairs of 8-bit blocks, uses 8-bit UTS multipliers, and adds results with carry select adders. This structure is expected to reduce power consumption and delay compared to other multipliers.
Robert Haas Query Planning Gone Wrong Presentation @ Postgres Open
Robert Haas Query Planning Gone Wrong Presentation @ Postgres OpenPostgresOpen The document summarizes the results of analyzing hundreds of email threads about query performance problems in PostgreSQL over two years. It found that the most common issues were:
1) Planner errors in row count or cost estimation, particularly underestimating the selectivity of correlated filter conditions and incorrectly estimating the performance of index scans with ordering and limits.
2) Settings like cost constants, work_mem, and statistics targets that could be optimized.
3) Queries that are inherently slow due to processing large amounts of data or disk access versus memory.
4) Areas where the planner is limited like not generating certain plan types or parameterization.
DESIGN OF 8-BIT COMPARATORS
DESIGN OF 8-BIT COMPARATORSIRJET Journal This document summarizes the design of different types of 8-bit comparators. It discusses the design of a conventional bit-wise comparator, a borrow look-ahead comparator, and a mux-based comparator. The comparators were designed using Xilinx Vivado software. Simulation results show that the borrow look-ahead comparator has the lowest power consumption of 0.071W and fewest number of cells at 46, making it the most efficient design compared to the conventional and mux-based comparators. The document compares the performance of the different comparator designs in terms of power consumption and number of cells.
Implementation of an arithmetic logic using area efficient carry lookahead adder
Implementation of an arithmetic logic using area efficient carry lookahead adderVLSICS Design The document presents the design of an 8-bit Arithmetic Logic Unit (ALU) that supports various arithmetic operations, including 4-bit multiplication using Booth's algorithm, in order to optimize speed and reduce circuit area. The ALU utilizes a carry look-ahead adder to improve addition performance and integrates multiple logic functions like subtraction and bitwise operations. It emphasizes the efficiency of the design for use in VLSI systems, making it suitable for advanced digital circuits.
GRAPHICAL STRUCTURES in our lives
GRAPHICAL STRUCTURES in our livesxryuseix The document discusses the concept of graphs, defining their essential elements like nodes and edges, and how they can represent events in our lives. It also covers graph implementation techniques, particularly the use of adjacency lists, and explores the efficiency of operations through segment trees. The conclusion emphasizes that events can be represented as graphs, which are manageable by computers and allow for operational efficiencies.
Implementation of 32 Bit Binary Floating Point Adder Using IEEE 754 Single Pr...
Implementation of 32 Bit Binary Floating Point Adder Using IEEE 754 Single Pr...iosrjce El artículo propone la implementación de un sumador de punto flotante de 32 bits utilizando el formato de precisión simple IEEE 754, destacando su habilidad para realizar operaciones aritméticas precisas en FPGA. Se centra en la reducción de la latencia general y el consumo de energía, presentando un algoritmo que mejora el rendimiento de las unidades de punto flotante. La metodología incluye un diseño detallado de módulos de hardware necesarios para la suma y la normalización de resultados en aplicaciones científicas y de procesamiento de datos.
IRJET - Design and Implementation of FFT using Compressor with XOR Gate Topology
IRJET - Design and Implementation of FFT using Compressor with XOR Gate TopologyIRJET Journal This document describes a design for implementing a Fast Fourier Transform (FFT) using an adder compressor with a new XOR gate topology. The goals are to increase power efficiency, reduce logic utilization (LUTs), and decrease time complexity/delay compared to other FFT implementations. An adder compressor is proposed that uses XOR gates to compress 4 input bits into 2 output bits (sum and carry), allowing parallel addition without carry propagation. Simulation results on a Xilinx FPGA show the compressor-based FFT uses fewer LUTs, consumes less power, and has a shorter delay compared to an FFT using a Booth multiplier.
IRJET- To Design 16 bit Synchronous Microprocessor using VHDL on FPGA
IRJET- To Design 16 bit Synchronous Microprocessor using VHDL on FPGAIRJET Journal This document describes the design of a 16-bit synchronous microprocessor using VHDL and its implementation on an FPGA. It discusses the design of key components like the ALU, registers, control unit, memory etc. in VHDL. The individual components are simulated and tested separately before integrating them to build the full microprocessor design. Finally, the functionality of the integrated microprocessor design is validated through simulation using a VHDL simulator.
IRJET- VLSI Architecture for Reversible Radix-2 FFT Algorithm using Programma...
IRJET- VLSI Architecture for Reversible Radix-2 FFT Algorithm using Programma...IRJET Journal This document describes the design of a reversible radix-2 FFT algorithm using programmable reversible gates. It begins with background on the discrete Fourier transform and fast Fourier transform. It then discusses previous work using reversible Peres and TR gates. The main contribution is a proposed method for implementing the radix-2 FFT using a reversible DKG gate. Simulation results for 8-point, 16-point and 32-point FFTs are presented, showing the structure was implemented on a Xilinx FPGA. The reversible FFT design reduces power consumption compared to traditional irreversible implementations.
An efficient hardware logarithm generator with modified quasi-symmetrical app...
An efficient hardware logarithm generator with modified quasi-symmetrical app...IJECEIAES This document presents a low-error, low-area FPGA-based hardware logarithm generator that utilizes a modified quasi-symmetrical approach for efficient digital signal processing. The proposed method enhances approximation accuracy while minimizing hardware complexity compared to traditional logarithm generation methods. Results indicate a significant reduction in both approximation error and hardware area, making it suitable for real-time applications.
Optimizing Geospatial Operations with Server-side Programming in HBase and Ac...
Optimizing Geospatial Operations with Server-side Programming in HBase and Ac...DataWorks Summit The document outlines the optimization of geospatial operations using server-side programming in HBase and Accumulo, detailing the benefits of GeoMesa for managing and analyzing spatio-temporal data at scale. Key topics include indexing with space filling curves, filtering and aggregation techniques, and the implementation of server-side optimizations to enhance performance. It also covers practical applications, integration with frameworks like MapReduce and Spark, and the support for interactive data discovery using notebook servers.
IRJET- Implementation of Ternary ALU using Verilog
IRJET- Implementation of Ternary ALU using VerilogIRJET Journal This document describes the design and implementation of a Ternary Arithmetic Logic Unit (TALU) using Verilog. Ternary logic uses three voltage levels (0, 1, Z) instead of the two levels used in binary, providing benefits like reduced gate counts, memory requirements, and faster speeds. The authors constructed truth tables and implemented simplified logic expressions using ternary multiplexers to build combinational circuits like a full adder. Their TALU design achieved 0% utilization of LUTs and slices on the FPGA, with a delay of 6.125ns which is 84.3% of the maximum delay. The document concludes that ternary logic designs require less memory and power than equivalent binary
BlaBlaCar Elastic Search Feedback
BlaBlaCar Elastic Search Feedbacksinfomicien This document discusses BlaBlaCar's transition from a relational database to the search engine Elasticsearch. It describes how BlaBlaCar changed its data model and indexing approach to better suit Elasticsearch. Challenges included modifying mappings, handling grouping, and dealing with IO limits on their initial two node cluster. The document encourages following BlaBlaCar and applying for open jobs.
Paper id 37201520
Paper id 37201520IJRAT This document describes a novel design for a 32-bit unsigned multiplier using a modified carry select adder (MCSLA). It begins with background on adders and multipliers in VLSI design. It then describes the conventional carry select adder (CSLA) and proposes a modified CSLA (MCSLA) that uses common boolean logic to reduce area and power. The document presents the design and VHDL simulation results of a 32-bit unsigned multiplier using both CSLA and the proposed MCSLA. The results show the MCSLA based multiplier achieves a 45% reduction in power-area-delay product compared to the CSLA based multiplier.
More from Citus Data (20)
Architecting peta-byte-scale analytics by scaling out Postgres on Azure with ...
Architecting peta-byte-scale analytics by scaling out Postgres on Azure with ...Citus Data The document discusses the hyperscale (Citus) extension for PostgreSQL, which allows for the scaling of distributed, sharded databases while maintaining the benefits of PostgreSQL. It highlights Microsoft's acquisition of Citus Data and the implementation of a robust analytics dashboard for Windows engineers, capable of processing vast amounts of data and supporting high query volumes. Additionally, it covers architectural features such as sharding, high availability, backup, and restore options essential for managing large-scale applications.
Data Modeling, Normalization, and De-Normalization | PostgresOpen 2019 | Dimi...
Data Modeling, Normalization, and De-Normalization | PostgresOpen 2019 | Dimi...Citus Data The document explores data modeling techniques, including normalization and denormalization, with a focus on PostgreSQL. It discusses various database constraints, the significance of primary and foreign keys, and the impact of data structures on algorithms. It also covers examples of denormalization, including the use of materialized views and caching for efficiency in data access.
JSONB Tricks: Operators, Indexes, and When (Not) to Use It | PostgresOpen 201...
JSONB Tricks: Operators, Indexes, and When (Not) to Use It | PostgresOpen 201...Citus Data The document discusses the use of JSON and JSONB data types in PostgreSQL, highlighting their characteristics such as being human-readable and indexable. It describes various operators and functions introduced in PostgreSQL 12 for querying JSON data, including jsonb_path_query and operators like @ and #>. The document also includes links to customer stories and resources for further learning about the use of JSON in PostgreSQL.
Tutorial: Implementing your first Postgres extension | PGConf EU 2019 | Burak...
Tutorial: Implementing your first Postgres extension | PGConf EU 2019 | Burak...Citus Data The document provides a comprehensive guide on developing PostgreSQL extensions, outlining the life cycle from coding to distribution. It explains what PostgreSQL extensions are, their extendable components, and offers examples such as task scheduling with pg_cron. Additionally, it covers internal PostgreSQL concepts like datums, tuples, and memory contexts crucial for extension development.
Whats wrong with postgres | PGConf EU 2019 | Craig Kerstiens
Whats wrong with postgres | PGConf EU 2019 | Craig KerstiensCitus Data The document discusses various issues and misconceptions about PostgreSQL, highlighting both its strengths and areas for improvement. It addresses common user errors, installation challenges, operational concerns, and community expectations. Additionally, it proposes solutions for achieving better configuration, high availability, and documentation for new users.
When it all goes wrong | PGConf EU 2019 | Will Leinweber
When it all goes wrong | PGConf EU 2019 | Will LeinweberCitus Data This document summarizes a presentation about troubleshooting Postgres performance problems. It discusses how to determine if the issue is with the database, system resources, or the application. It provides examples of common problems like running out of CPU, memory, disk, or parallelism. It also recommends tools to diagnose issues like perf, gdb, iostat, iotop, htop, bwm-ng, and pg_stat_statements. Finally, it discusses setting boundaries around economics, workload, performance, and errors to avoid instability.
Amazing SQL your ORM can (or can't) do | PGConf EU 2019 | Louise Grandjonc
Amazing SQL your ORM can (or can't) do | PGConf EU 2019 | Louise GrandjoncCitus Data Louise Grandjonc's presentation at PGConf EU 2019 covers advanced SQL techniques and ORM capabilities using Python and Ruby frameworks like Django, SQLAlchemy, ActiveRecord, and Sequel. The talk includes various SQL concepts such as aggregate functions, subqueries, and joins, with practical examples related to a dataset of music artists and their albums. The aim is to help developers leverage the full potential of SQL and ORMs in their applications.
What Microsoft is doing with Postgres & the Citus Data acquisition | PGConf E...
What Microsoft is doing with Postgres & the Citus Data acquisition | PGConf E...Citus Data PostgreSQL's popularity has surged, supported by a strong community and 30 years of development, earning it the title of DBMS of the year for two consecutive years. Azure Database for PostgreSQL offers a fully-managed service with extensive support for extensions, security, scalability, and intelligent performance features. The latest advances include enhanced resource management, compliance certifications, and community-focused events to foster growth and collaboration.
Deep Postgres Extensions in Rust | PGCon 2019 | Jeff Davis
Deep Postgres Extensions in Rust | PGCon 2019 | Jeff DavisCitus Data The document discusses the development of a Rust-based extension framework for PostgreSQL, called postgres-extension.rs, which aims to enhance memory safety and modern programming capabilities compared to traditional C extensions. It integrates deeply with the PostgreSQL backend, allowing for direct manipulation of PostgreSQL structures and improved error handling between Rust and C. The author encourages exploring Rust for writing database extensions, highlighting its growing community and potential within the PostgreSQL ecosystem.
Why Postgres Why This Database Why Now | SF Bay Area Postgres Meetup | Claire...
Why Postgres Why This Database Why Now | SF Bay Area Postgres Meetup | Claire...Citus Data The SF Bay Area PostgreSQL Meetup held in July 2019 featured a presentation by Claire Giordano from Microsoft, discussing the advantages and growing popularity of PostgreSQL. Key topics included its open-source nature, strong community support, and extension capabilities that enhance its functionality. The meetup emphasized PostgreSQL's relevance in modern database management and its role in the tech ecosystem, especially after Citus Data's acquisition by Microsoft.
A story on Postgres index types | PostgresLondon 2019 | Louise Grandjonc
A story on Postgres index types | PostgresLondon 2019 | Louise GrandjoncCitus Data The document is an extensive guide on PostgreSQL indexes, focusing on their purpose, various types (like B-tree, GIN, and GiST), and the internal structure and functionality of each index type. It explains how indexes enhance query performance by allowing faster access to data and provides detailed insights into how they are implemented and managed in PostgreSQL. Through examples and illustrations, it covers not only the creation and searching of indexes but also the more complex aspects like handling concurrent inserts and page splits.
Why developers need marketing now more than ever | GlueCon 2019 | Claire Gior...
Why developers need marketing now more than ever | GlueCon 2019 | Claire Gior...Citus Data The document discusses the importance of marketing for developers, emphasizing that strong marketing is essential for the success of a product in a competitive landscape. It addresses biases against marketing within the developer community and highlights the collaborative nature required between developers and marketers for effective results. By drawing analogies from sailboat racing, it illustrates that every role, including marketing, is vital for achieving success and reaching users effectively.
The Art of PostgreSQL | PostgreSQL Ukraine | Dimitri Fontaine
The Art of PostgreSQL | PostgreSQL Ukraine | Dimitri FontaineCitus Data The document provides an overview of PostgreSQL for developers, detailing its features such as transactions, data types, and data modeling, while also highlighting its advantages over other database management systems. It includes practical examples, SQL commands, and Python scripts for handling data and generating reports, particularly focused on financial data from the NYSE. Additionally, it discusses migration processes and tools like pgloader to simplify transitions to PostgreSQL.
Optimizing your app by understanding your Postgres | RailsConf 2019 | Samay S...
Optimizing your app by understanding your Postgres | RailsConf 2019 | Samay S...Citus Data The presentation discusses optimizing applications by understanding PostgreSQL database performance issues, focusing on monitoring and utilizing database statistics. Key takeaways include the importance of cache hit ratios, the use of the 'pg_stat_statements' extension for identifying slow queries, and techniques for improving database performance through proper indexing and vacuuming. Practical examples and queries are provided to help attendees analyze and optimize specific database interactions.
When it all goes wrong (with Postgres) | RailsConf 2019 | Will Leinweber
When it all goes wrong (with Postgres) | RailsConf 2019 | Will LeinweberCitus Data The document discusses common issues and troubleshooting strategies related to PostgreSQL in application development, emphasizing the difficulty in diagnosing performance problems. It highlights resource exhaustion, application backlogs, and workload patterns as key factors affecting database performance. Tools and methods for diagnosing these issues, as well as potential configurations or code changes to improve system resilience, are also mentioned.
The Art of PostgreSQL | PostgreSQL Ukraine Meetup | Dimitri Fontaine
The Art of PostgreSQL | PostgreSQL Ukraine Meetup | Dimitri FontaineCitus Data The document discusses PostgreSQL from a developer's perspective, focusing on key features such as transactions, data modeling, and advanced indexing. It includes practical examples, such as migrating data with pgloader and querying stock exchange information. Additionally, it outlines the structure of SQL queries, data types, and performance analysis within PostgreSQL.
Using Postgres and Citus for Lightning Fast Analytics, also ft. Rollups | Liv...
Using Postgres and Citus for Lightning Fast Analytics, also ft. Rollups | Liv...Citus Data The document outlines a live demo presented by Sai Srirampur on using Postgres and Citus for fast analytics and rollups. It emphasizes the challenges of scaling databases and outlines the benefits of using Citus to distribute data and improve performance for analytics workloads. The presentation also covers concepts like rollups and estimation techniques like HLL for efficient data processing.
How to write SQL queries | pgDay Paris 2019 | Dimitri Fontaine
How to write SQL queries | pgDay Paris 2019 | Dimitri FontaineCitus Data The document provides detailed instructions on writing SQL queries, including generating monthly reports and analyzing datasets related to races and NBA games. It includes code snippets for creating queries to extract and compute various data points such as race results, driver statistics, and historical NBA game information. Additionally, it discusses PostgreSQL features like geolocation and histogram creation.
When it all Goes Wrong |Nordic PGDay 2019 | Will Leinweber
When it all Goes Wrong |Nordic PGDay 2019 | Will LeinweberCitus Data The document discusses common issues and troubleshooting strategies related to PostgreSQL databases, particularly from the perspective of application developers. It emphasizes understanding system resource allocation, workload management, and potential bottlenecks while offering tools for diagnosing problems. The talk also references resilience in complex systems and the importance of recognizing various sources of database performance issues.
Why PostgreSQL Why This Database Why Now | Nordic PGDay 2019 | Claire Giordano
Why PostgreSQL Why This Database Why Now | Nordic PGDay 2019 | Claire GiordanoCitus Data The presentation at Nordic PGDay 2019 in Copenhagen, led by Claire Giordano from Citus Data/Microsoft, discusses the appeal of PostgreSQL as a database choice. It highlights the community support, performance growth, and features such as JSONB and extensions that contribute to its increasing popularity. The session emphasizes PostgreSQL's ability to meet modern data requirements and its strong ecosystem.
Ad
Recently uploaded (20)
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...NTT DATA Technology & Innovation Can We Use Rust to Develop Extensions for PostgreSQL?
(POSETTE: An Event for Postgres 2025)
June 11, 2025
Shinya Kato
NTT DATA Japan Corporation
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdf
Tech-ASan: Two-stage check for Address Sanitizer - Yixuan Cao.pdfcaoyixuan2019 A presentation at Internetware 2025.
War_And_Cyber_3_Years_Of_Struggle_And_Lessons_For_Global_Security.pdf
War_And_Cyber_3_Years_Of_Struggle_And_Lessons_For_Global_Security.pdfbiswajitbanerjee38 Russia is one of the most aggressive nations when it comes to state coordinated cyberattacks — and Ukraine has been at the center of their crosshairs for 3 years. This report, provided the State Service of Special Communications and Information Protection of Ukraine contains an incredible amount of cybersecurity insights, showcasing the coordinated aggressive cyberwarfare campaigns of Russia against Ukraine.
It brings to the forefront that understanding your adversary, especially an aggressive nation state, is important for cyber defense. Knowing their motivations, capabilities, and tactics becomes an advantage when allocating resources for maximum impact.
Intelligence shows Russia is on a cyber rampage, leveraging FSB, SVR, and GRU resources to professionally target Ukraine’s critical infrastructures, military, and international diplomacy support efforts.
The number of total incidents against Ukraine, originating from Russia, has steadily increased from 1350 in 2021 to 4315 in 2024, but the number of actual critical incidents has been managed down from a high of 1048 in 2022 to a mere 59 in 2024 — showcasing how the rapid detection and response to cyberattacks has been impacted by Ukraine’s improved cyber resilience.
Even against a much larger adversary, Ukraine is showcasing outstanding cybersecurity, enabled by strong strategies and sound tactics. There are lessons to learn for any enterprise that could potentially be targeted by aggressive nation states.
Definitely worth the read!
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdf
ENERGY CONSUMPTION CALCULATION IN ENERGY-EFFICIENT AIR CONDITIONER.pdfMuhammad Rizwan Akram DC Inverter Air Conditioners are revolutionizing the cooling industry by delivering affordable,
energy-efficient, and environmentally sustainable climate control solutions. Unlike conventional
fixed-speed air conditioners, DC inverter systems operate with variable-speed compressors that
modulate cooling output based on demand, significantly reducing energy consumption and
extending the lifespan of the appliance.
These systems are critical in reducing electricity usage, lowering greenhouse gas emissions, and
promoting eco-friendly technologies in residential and commercial sectors. With advancements in
compressor control, refrigerant efficiency, and smart energy management, DC inverter air conditioners
have become a benchmark in sustainable climate control solutions
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptx
FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography.pptxFIDO Alliance FIDO Seminar: Evolving Landscape of Post-Quantum Cryptography
FIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptx
FIDO Seminar: Perspectives on Passkeys & Consumer Adoption.pptxFIDO Alliance FIDO Seminar: Perspectives on Passkeys & Consumer Adoption
Artificial Intelligence in the Nonprofit Boardroom.pdf
Artificial Intelligence in the Nonprofit Boardroom.pdfOnBoard OnBoard recently partnered with Microsoft Tech for Social Impact on the AI in the Nonprofit Boardroom Survey, an initiative designed to uncover the current and future role of artificial intelligence in nonprofit governance.
FIDO Seminar: Authentication for a Billion Consumers - Amazon.pptx
FIDO Seminar: Authentication for a Billion Consumers - Amazon.pptxFIDO Alliance FIDO Seminar: Authentication for a Billion Consumers - Amazon
AudGram Review: Build Visually Appealing, AI-Enhanced Audiograms to Engage Yo...
AudGram Review: Build Visually Appealing, AI-Enhanced Audiograms to Engage Yo...SOFTTECHHUB AudGram changes everything by bridging the gap between your audio content and the visual engagement your audience craves. This cloud-based platform transforms your existing audio into scroll-stopping visual content that performs across all social media platforms.
Supporting the NextGen 911 Digital Transformation with FME
Supporting the NextGen 911 Digital Transformation with FMESafe Software Next Generation 911 involves the transformation of our 911 system from an old analog one to the new digital internet based architecture. The evolution of NG911 opens up a host of new opportunities to improve the system. This includes everything from device based location, to real time text. This can improve location accuracy dramatically as well as provide live updates from the citizen in need along with real time sensor updates. There is also the opportunity to provide multi-media attachments and medical records if the end user approves. This digital transformation and enhancements all require the support of new NENA and CRTC standards, along with integration across a variety of data streams.
This presentation will focus on how FME has supported NG911 transformations to date, and how we are positioning FME to support the enhanced capabilities to come. This session will be of interest to emergency services, municipalities and anyone who may be interested to know more about how emergency services are being improved to provide more accurate, localized information in order to improve the speed and relevance of emergency response and ultimately save more lives and provide better outcomes for those in need.
AI VIDEO MAGAZINE - June 2025 - r/aivideo
AI VIDEO MAGAZINE - June 2025 - r/aivideo1pcity Studios, Inc AI VIDEO MAGAZINE - r/aivideo community newsletter – Exclusive Tutorials: How to make an AI VIDEO from scratch, PLUS: How to make AI MUSIC, Hottest ai videos of 2025, Exclusive Interviews, New Tools, Previews, and MORE - JUNE 2025 ISSUE -
Bridging the divide: A conversation on tariffs today in the book industry - T...
Bridging the divide: A conversation on tariffs today in the book industry - T...BookNet Canada A collaboration-focused conversation on the recently imposed US and Canadian tariffs where speakers shared insights into the current legislative landscape, ongoing advocacy efforts, and recommended next steps. This event was presented in partnership with the Book Industry Study Group.
Link to accompanying resource: https://bnctechforum.ca/sessions/bridging-the-divide-a-conversation-on-tariffs-today-in-the-book-industry/
Presented by BookNet Canada and the Book Industry Study Group on May 29, 2025 with support from the Department of Canadian Heritage.
Reducing Conflicts and Increasing Safety Along the Cycling Networks of East-F...
Reducing Conflicts and Increasing Safety Along the Cycling Networks of East-F...Safe Software In partnership with the Belgian Province of East-Flanders this project aimed to reduce conflicts and increase safety along a cycling route between the cities of Oudenaarde and Ghent. To achieve this goal, the current cycling network data needed some extra key information, including: Speed limits for segments, Access restrictions for different users (pedestrians, cyclists, motor vehicles, etc.), Priority rules at intersections. Using a 360° camera and GPS mounted on a measuring bicycle, we collected images of traffic signs and ground markings along the cycling lanes building up mobile mapping data. Image recognition technologies identified the road signs, creating a dataset with their locations and codes. The data processing entailed three FME workspaces. These included identifying valid intersections with other networks (e.g., roads, railways), creating a topological network between segments and intersections and linking road signs to segments and intersections based on proximity and orientation. Additional features, such as speed zones, inheritance of speed and access to neighbouring segments were also implemented to further enhance the data. The final results were visualized in ArcGIS, enabling analysis for the end users. The project provided them with key insights, including statistics on accessible road segments, speed limits, and intersection priorities. These will make the cycling paths more safe and uniform, by reducing conflicts between users.
Raman Bhaumik - Passionate Tech Enthusiast
Raman Bhaumik - Passionate Tech EnthusiastRaman Bhaumik A Junior Software Developer with a flair for innovation, Raman Bhaumik excels in delivering scalable web solutions. With three years of experience and a solid foundation in Java, Python, JavaScript, and SQL, she has streamlined task tracking by 20% and improved application stability.
Security Tips for Enterprise Azure Solutions
Security Tips for Enterprise Azure SolutionsMichele Leroux Bustamante Delivering solutions to Azure may involve a variety of architecture patterns involving your applications, APIs data and associated Azure resources that comprise the solution. This session will use reference architectures to illustrate the security considerations to protect your Azure resources and data, how to achieve Zero Trust, and why it matters. Topics covered will include specific security recommendations for types Azure resources and related network security practices. The goal is to give you a breadth of understanding as to typical security requirements to meet compliance and security controls in an enterprise solution.
Creating Inclusive Digital Learning with AI: A Smarter, Fairer Future
Creating Inclusive Digital Learning with AI: A Smarter, Fairer FutureImpelsys Inc. Have you ever struggled to read a tiny label on a medicine box or tried to navigate a confusing website? Now imagine if every learning experience felt that way—every single day.
For millions of people living with disabilities, poorly designed content isn’t just frustrating. It’s a barrier to growth. Inclusive learning is about fixing that. And today, AI is helping us build digital learning that’s smarter, kinder, and accessible to everyone.
Accessible learning increases engagement, retention, performance, and inclusivity for everyone. Inclusive design is simply better design.
Down the Rabbit Hole – Solving 5 Training Roadblocks
Down the Rabbit Hole – Solving 5 Training RoadblocksRustici Software Feeling stuck in the Matrix of your training technologies? You’re not alone. Managing your training catalog, wrangling LMSs and delivering content across different tools and audiences can feel like dodging digital bullets. At some point, you hit a fork in the road: Keep patching things up as issues pop up… or follow the rabbit hole to the root of the problems.
Good news, we’ve already been down that rabbit hole. Peter Overton and Cameron Gray of Rustici Software are here to share what we found. In this webinar, we’ll break down 5 training roadblocks in delivery and management and show you how they’re easier to fix than you might think.
Crypto Super 500 - 14th Report - June2025.pdf
Crypto Super 500 - 14th Report - June2025.pdfStephen Perrenod This OrionX's 14th semi-annual report on the state of the cryptocurrency mining market. The report focuses on Proof-of-Work cryptocurrencies since those use substantial supercomputer power to mint new coins and encode transactions on their blockchains. Only two make the cut this time, Bitcoin with $18 billion of annual economic value produced and Dogecoin with $1 billion. Bitcoin has now reached the Zettascale with typical hash rates of 0.9 Zettahashes per second. Bitcoin is powered by the world's largest decentralized supercomputer in a continuous winner take all lottery incentive network.
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...
Can We Use Rust to Develop Extensions for PostgreSQL? (POSETTE: An Event for ...NTT DATA Technology & Innovation
Ad
Distributed count(distinct) with hyper loglog on postgresql | PGConf EU 2017) | Burak Yucesoy
- 1. Burak Yucesoy | Citus Data | PGConf EU Distributed COUNT(DISTINCT) with HyperLogLog on PostgreSQL
- 2. Burak Yucesoy | Citus Data | PGConf EU What is COUNT(DISTINCT)? ● Number of unique elements (cardinality) in given data ● Useful to find things like… ○ Number of unique users visited your web page ○ Number of unique products in your inventory
- 3. Burak Yucesoy | Citus Data | PGConf EU What is distributed COUNT(DISTINCT)? Worker Node 1 logins_001 Coordinator Worker Node 2 logins_002 Worker Node 3 logins_003
- 4. Burak Yucesoy | Citus Data | PGConf EU Why do we need distributed COUNT(DISTINCT)? ● Your data is too big to fit in memory of single machine ● Naive approach for COUNT(DISTINCT) needs too much memory
- 5. Burak Yucesoy | Citus Data | PGConf EU Why does distributed COUNT(DISTINCT) is difficult? Worker Node 1 logins_001 CoordinatorSELECT COUNT(*) FROM logins; Worker Node 2 logins_002 Worker Node 3 logins_003 600 100 200 300SELECT COUNT(*) FROM ...;
- 6. Burak Yucesoy | Citus Data | PGConf EU Why does distributed COUNT(DISTINCT) is difficult? Worker Node 1 logins_001 CoordinatorSELECT COUNT(DISTINCT username) FROM logins; Worker Node 2 logins_002 Worker Node 3 logins_003 SELECT COUNT(DISTINCT user_id) FROM ...;
- 7. Burak Yucesoy | Citus Data | PGConf EU Why does distributed COUNT(DISTINCT) is difficult? Worker Node 1 logins_001 username | date ----------+----------- Alice | 2017-01-02 Bob | 2017-01-03 Charlie | 2017-01-05 Eve | 2017-01-07 Worker Node 3 logins_003 username | date ----------+----------- Frank | 2017-03-23 Eve | 2017-03-29 Charlie | 2017-03-02 Charlie | 2017-03-03 Worker Node 2 logins_002 username | date ----------+----------- Bob | 2017-02-11 Bob | 2017-02-13 Dave | 2017-02-17 Alice | 2017-02-19
- 8. Burak Yucesoy | Citus Data | PGConf EU Why does distributed COUNT(DISTINCT) is difficult? Worker Node 1 logins_001 username | date ----------+----------- Alice | 2017-01-02 Bob | 2017-01-03 Charlie | 2017-01-05 Eve | 2017-01-07 Worker Node 3 logins_003 username | date ----------+----------- Dave | 2017-03-23 Eve | 2017-03-29 Charlie | 2017-03-02 Charlie | 2017-03-03 Worker Node 2 logins_002 username | date ----------+----------- Bob | 2017-02-11 Bob | 2017-02-13 Dave | 2017-02-17 Alice | 2017-02-19
- 9. Burak Yucesoy | Citus Data | PGConf EU Some Possible Approaches ● Pull all distinct data to one node and count there. (Doesn’t scale) ● Repartition data on the fly. (Scales but it’s very slow) ● Use HyperLogLog. (Scales and fast)
- 10. Burak Yucesoy | Citus Data | PGConf EU HyperLogLog(HLL) HLL is; ● Approximation algorithm ● Estimates cardinality of given data ● Mathematically proven error bounds
- 11. Burak Yucesoy | Citus Data | PGConf EU Is it OK to approximate? It depends…
- 12. Burak Yucesoy | Citus Data | PGConf EU HLL ● Very fast ● Low memory footprint ● Can work with streaming data ● Can merge estimations of two separate datasets efficiently
- 13. Burak Yucesoy | Citus Data | PGConf EU How does HLL work? Steps; 1. Hash all elements a. Ensures uniform data distribution b. Can treat all data types same 2. Observing rare bit patterns 3. Stochastic averaging
- 14. Burak Yucesoy | Citus Data | PGConf EU How does HLL work? - Observing rare bit patterns hash Alice 645403841 binary 0010...001 Number of leading zeros: 2 Maximum number of leading zeros: 2
- 15. Burak Yucesoy | Citus Data | PGConf EU How does HLL work? - Observing rare bit patterns hash Bob 1492309842 binary 0101...010 Number of leading zeros: 1 Maximum number of leading zeros: 2
- 16. Burak Yucesoy | Citus Data | PGConf EU How does HLL work? - Observing rare bit patterns ... Maximum number of leading zeros: 7 Cardinality Estimation: 27
- 17. Burak Yucesoy | Citus Data | PGConf EU How does HLL work? Stochastic Averaging Measuring same thing repeatedly and taking average.
- 18. Burak Yucesoy | Citus Data | PGConf EU
- 19. Burak Yucesoy | Citus Data | PGConf EU
- 20. Burak Yucesoy | Citus Data | PGConf EU How does HLL work? Stochastic Averaging Data Partition 1 Partition 3 Partition 2 7 5 12 228.968... Estimation 27 25 212
- 21. Burak Yucesoy | Citus Data | PGConf EU How does HLL work? Stochastic Averaging 01000101...010 First m bits to decide partition number Remaining bits to count leading zeros
- 22. Burak Yucesoy | Citus Data | PGConf EU Error rate of HLL is damn good ● Typical Error Rate: 1.04 / sqrt(number of partitions) ● Memory need is number of partitions * log(log(max. value in hash space)) bit ● Can estimate cardinalities well beyond 109 with 1% error rate while using a memory of only 6 kilobytes ● Memory vs accuracy tradeoff
- 23. Burak Yucesoy | Citus Data | PGConf EU Why does HLL work? It turns out, combination of lots of bad estimation is a good estimation
- 24. Burak Yucesoy | Citus Data | PGConf EU Some interesting examples Alice Alice Alice … … … Alice Partition 1 Partition 3 Partition 2 0 2 0 1.103... Harmonic Mean 20 22 20 hash Alice 645403841 binary 00100110...001 ... ... ...
- 25. Burak Yucesoy | Citus Data | PGConf EU Some interesting examples Charlie Partition 1 Partition 8 Partition 2 29 0 0 1.142... Harmonic Mean 229 20 20 hash Charlie 0 binary 00000000...000 ... ... ...
- 26. Burak Yucesoy | Citus Data | PGConf EU postgresql-hll ● https://github.com/aggregateknowledge/postgresql-hll ● https://github.com/citusdata/postgresql-hll ● Companies using postgresql-hll for their dashboard ● Neustar ● Cloudflare
- 27. Burak Yucesoy | Citus Data | PGConf EU postgresql-hll uses a data structure, also called hll to keep maximum number of leading zeros of each partition. ● Use hll_hash_bigint to hash elements. ○ There are some other functions for other common data types. ● Use hll_add_agg to aggregate hashed elements into hll data structure. ● Use hll_cardinality to materialize hll data structure to actual distinct count. postgresql-hll in single node
- 28. Burak Yucesoy | Citus Data | PGConf EU What Happens in Distributed Scenario?
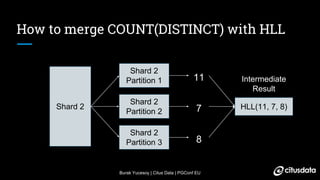
- 29. Burak Yucesoy | Citus Data | PGConf EU How to merge COUNT(DISTINCT) with HLL Shard 1 Shard 1 Partition 1 Shard 1 Partition 3 Shard 1 Partition 2 7 5 12 HLL(7, 5, 12) Intermediate Result
- 30. Burak Yucesoy | Citus Data | PGConf EU How to merge COUNT(DISTINCT) with HLL Shard 2 Shard 2 Partition 1 Shard 2 Partition 3 Shard 2 Partition 2 11 7 8 HLL(11, 7, 8) Intermediate Result
- 31. Burak Yucesoy | Citus Data | PGConf EU How to merge COUNT(DISTINCT) with HLL 11 7 12 1053.255 211 27 212 HLL(11, 7, 8) HLL(7, 5, 12) HLL(11, 7, 12) hll_union_agg
- 32. Burak Yucesoy | Citus Data | PGConf EU How to merge COUNT(DISTINCT) with HLL Shard 1 + Shard 2 Shard 1 Partition 1(7) + Shard 2 Partition 1(11) 11 7 12 1053.255 Estimation Shard 1 Partition 2(5) + Shard 2 Partition 2(7) Shard 1 Partition 3(12) + Shard 2 Partition 4(8)
- 33. Burak Yucesoy | Citus Data | PGConf EU 1. Separate data into shards. postgresql-hll in distributed environment logins_001 logins_002 logins_003
- 34. Burak Yucesoy | Citus Data | PGConf EU 2. Put shards into separate nodes. postgresql-hll in distributed environment Worker Node 1 Coordinator Worker Node 2 Worker Node 3 logins_001 logins_002 logins_003
- 35. Burak Yucesoy | Citus Data | PGConf EU 3. For each shard, calculate hll (but do not materialize). postgresql-hll in distributed environment Shard 1 Shard 1 Partition 1 Shard 1 Partition 3 Shard 1 Partition 2 7 5 12 HLL(7, 5, 12) Intermediate Result
- 36. Burak Yucesoy | Citus Data | PGConf EU 4. Pull intermediate results to a single node. postgresql-hll in distributed environment Worker Node 1 logins_001 Coordinator Worker Node 2 logins_002 Worker Node 3 logins_003 HLL(6, 4, 11) HLL(10, 6, 7) HLL(7, 12, 5)
- 37. Burak Yucesoy | Citus Data | PGConf EU 5. Merge separate hll data structures and materialize them postgresql-hll in distributed environment 11 13 12 10532.571... 211 213 212 HLL(11, 7, 8) HLL(7, 5, 12) HLL(11, 13, 12) HLL(8, 13, 6)
- 38. Burak Yucesoy | Citus Data | PGConf EU Or use Citus :) postgresql-hll in distributed environment
- 39. Burak Yucesoy | Citus Data | PGConf EU Burak Yucesoy [email protected] @byucesoy Thank You citusdata.com | @citusdata