An AI-Powered Chatbot to Simplify Apache Spark Performance Management
1 like1,132 views

The document discusses an AI-powered chatbot created by Unravel to help users optimize Spark performance. It describes how the chatbot uses machine learning models trained on historical monitoring and failure data to recommend Spark configuration tuning parameters and diagnose issues. The chatbot's backend uses a Gaussian process model and an expected improvement algorithm to iteratively select the best configuration settings based on previous results. It also uses natural language processing and predictive models to identify the root causes of job failures from application logs. The chatbot aims to simplify Spark management and make users more productive by acting as an AI-driven Spark expert.










































![Learning the predictive model
• Shallow Learning
– Logistic Regression
– Random forests
• Deep Learning
– Neural networks
44
• Training and testing with injected failures
• Test to train data set ratio 75% to 25%
• Models: logistic regression, random forests
80
85
90
95
100
TF-IDF Doc2Vec
AccuracyScore
[%]
Logistic Regression Random Forests
#UnifiedAnalytics #SparkAISummit](https://image.slidesharecdn.com/022002shivnathbabu-190510184829/85/An-AI-Powered-Chatbot-to-Simplify-Apache-Spark-Performance-Management-44-320.jpg)









![[Pgday.Seoul 2017] 3. PostgreSQL WAL Buffers, Clog Buffers Deep Dive - 이근오](https://cdn.slidesharecdn.com/ss_thumbnails/pgday171104-171106041604-thumbnail.jpg?width=560&fit=bounds)

























Ad
More Related Content
What's hot (20)
Similar to An AI-Powered Chatbot to Simplify Apache Spark Performance Management (20)


















Ad
More from Databricks (20)




















Ad
Recently uploaded (20)




















An AI-Powered Chatbot to Simplify Apache Spark Performance Management
- 1. WIFI SSID:SparkAISummit | Password: UnifiedAnalytics
- 2. Shivnath Babu Cofounder/CTO, Unravel Adjunct Professor, Duke University An AI-powered Chatbot to Simplify Spark Performance Management #UnifiedAnalytics #SparkAISummit
- 3. Meet the speaker • Cofounder/CTO at Unravel • Adjunct Professor of Computer Science at Duke University • Focusing on ease-of-use and manageability of data-intensive systems • Recipient of US National Science Foundation CAREER Award, three IBM Faculty Awards, HP Labs Innovation Research Award 3#UnifiedAnalytics #SparkAISummit
- 4. What is a Chatbot? 4#UnifiedAnalytics #SparkAISummit
- 5. A program which conducts a conversation via text or voice 5#UnifiedAnalytics #SparkAISummit
- 6. Chatbots are making a real difference 6#UnifiedAnalytics #SparkAISummit
- 8. 8#UnifiedAnalytics #SparkAISummit TOBi generates 2x more ecommerce conversions in ½ the time for Vodafone
- 9. 9#UnifiedAnalytics #SparkAISummit Zara provides fast services to 20% of Zurich Insurance customers
- 10. 10#UnifiedAnalytics #SparkAISummit Woebot, the therapist chatbot, talks to more people in a day than a human therapist does in a lifetime
- 11. Chatbots ó Spark Performance What is the connection? 11#UnifiedAnalytics #SparkAISummit
- 12. The happy Spark user 12#UnifiedAnalytics #SparkAISummit • Spark is fast • Spark has easy-to-use and comprehensive APIs • Wow, I can do SQL, Streaming, AI/ML, and Graphs in one system! • Spark has a rich ecosystem
- 13. 13#UnifiedAnalytics #SparkAISummit “I have no clue which cloud instance type to pick for my workload” “My cloud costs are getting out of control. Help!” “I have no idea why my app is slow” “My app failed and I don’t know why!” The frustrated Spark user
- 14. • Many levels of correlated stack traces • Identifying the root cause is hard and time consuming 14 Typical app failure in Spark #UnifiedAnalytics #SparkAISummit
- 15. 15#UnifiedAnalytics #SparkAISummit “My app failed and I don’t know why!” Spark User Spark Chatbot “I know that sucks! Let me take a look here …” “I see the problem. Executors are running out of memory” “Setting spark.executor.memory to 12g fixes the problem. I have verified it. See this run here” “Wow. Thanks. You are awesome!”
- 16. I will show you a Chatbot that • Makes you more productive • Saves you time and money • Becomes your AI-driven Spark Expert in a Bot! 16#UnifiedAnalytics #SparkAISummit
- 17. My app is too slow… 17 DATA ENGINEER #UnifiedAnalytics #SparkAISummit
- 18. I need to make it faster… 18 DATA ENGINEER #UnifiedAnalytics #SparkAISummit
- 19. Current approach 19 1. Review Spark/YARN UI to find the app 2. Review metrics in the UI 3. Review jobs and stages associated with the app 4. Identify all containers associated with the app 6. Identify “problematic” jobs, stages, or containers 7. Guess which parameters to tune for performance 5. Review and debug container logs 9. Rinse & repeat 8. Do trial-and-error by changing a parameter setting #UnifiedAnalytics #SparkAISummit
- 20. There has to be a better way 20#UnifiedAnalytics #SparkAISummit
- 21. What is going on here? 21#UnifiedAnalytics #SparkAISummit
- 22. 22#UnifiedAnalytics #SparkAISummit Messaging Platform Bot’s NLP Layer Bot’s Backend Layer Chatbot Architecture from 30000 ft
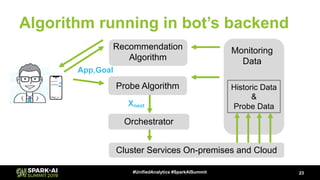
- 23. Monitoring Data Historic Data & Probe Data Recommendation Algorithm Cluster Services On-premises and Cloud App,Goal Orchestrator Algorithm running in bot’s backend Xnext Probe Algorithm 23#UnifiedAnalytics #SparkAISummit
- 24. spark.driver.cores 2 spark.executor.cores … 10 spark.sql.shuffle.partitions 300 spark.sql.autoBroadcastJoinThres hold 20MB … SKEW('orders', 'o_custId') true spark.catalog.cacheTable(“orders") true … We represent this setting as vector X X PERFORMANCE 24 Spark tuning parameters #UnifiedAnalytics #SparkAISummit
- 25. • Find the setting of X that best meets the goal • Challenge: Response surface y = ƒ(X) is unknown X PERFORMANCE Given: App + Goal 25#UnifiedAnalytics #SparkAISummit
- 26. Model the response surface as The Gaussian Process model captures the uncertainty in our current knowledge of the response surface )()()(ˆ XZXfXy t += b !! b !! )(Xf t )(XZ X PERFORMANCE Challenge: Response surface y = ƒ(X) is unknown Here: is a regression model is the residual captured as a Gaussian Process #AI7SAIS 26
- 27. ò = -¥= -= )( )(ˆ * * )())(()( Xyp p Xy dpppdfpXyXEIP We can now estimate the expected improvement EIP(X) from doing a probe at any setting X Gaussian Process model helps estimate EIP(X) Improvement at any setting X over the best performance seen so far Probability density function (uncertainty estimate) X Opportunity 27 PERFORMANCE #UnifiedAnalytics #SparkAISummit
- 28. Get initial set of monitoring data from history or via probes: <X1,y1>, <X2,y2>, …, <Xn,yn> 1 Select next probe Xnext based on all history and probe data available so far to calculate the setting with maximum expected improvement EIP(X) 2 Bootstrap Probe Algorithm Until the stopping condition is reached #AI7SAIS 28 PERFORMANCE X
- 29. 4 6 8 10 12 02468 x1 y 4 6 8 10 12 02468 x1 y 4 6 8 10 12 02468 x1 y 4 6 8 10 12 02468 x1 y X Performance U EIP(X) U Xnext: Do next probe here This approach balances Exploration Vs. Exploitation U Exploration U Exploitation 29#UnifiedAnalytics #SparkAISummit
- 30. Credit: https://discovery.rsm.nl/articles/detail/130-how-to-balance-exploration-and-exploitation-in-multinational-enterprises Data Starved & High Uncertainty Data Rich & Low Uncertainty 30 App,Goal Xnext Probe Algorithm #UnifiedAnalytics #SparkAISummit
- 31. 31#UnifiedAnalytics #SparkAISummit Messaging Platform Bot’s NLP Layer Bot’s Backend Layer Chatbot architecture
- 32. • Many levels of correlated stack traces • Identifying the root cause is hard and time consuming 32 Typical app failure in Spark #UnifiedAnalytics #SparkAISummit
- 33. Let us see a better way 33#UnifiedAnalytics #SparkAISummit
- 34. What is going on here? 34#UnifiedAnalytics #SparkAISummit
- 35. 35#UnifiedAnalytics #SparkAISummit Predictive Model Root cause of the failure App failure App’s Container Logs Error Template Extraction Feature vector
- 36. 36#UnifiedAnalytics #SparkAISummit Predictive Model Root cause of the failure App failure App’s Container Logs Error Template Extraction Error Template Extraction Feature vectors Model Learning Container Logs Root cause labels Logs from millions of app failures Label Generation Feature vector
- 37. Two ways to get root-cause labels • Manual diagnosis by a domain expert • Automatic injection of the root cause 37#UnifiedAnalytics #SparkAISummit
- 38. Unravel’s large-scale lab framework for automatic root cause analysis Spark and multi-tenant Workloads: - Variety of workloads: Batch, ML, SQL, Streaming, etc. Failures: - Large set of root causes learned from customers & partners. Constantly updated - Continuously inject these root causes to train & test models for root-cause prediction Environment: - Lab created on demand on cloud or on-premises - Workloads are run and failures are injected 38#UnifiedAnalytics #SparkAISummit
- 39. Injecting “labeled” failures Application Execution Application Monitor FAILED Injected Failure Label Labeled Failures • Invalid input • Invalid memory configuration • OOME: Java heap space • OOME: GC overhead limit • Container killed by YARN • Runtime incompatibility Injected failure examples: • No space left on device • Transformations inside other transformations • Runtime error • Arithmetic error • Invalid configuration settings Input Feature Extraction 39 Training data #UnifiedAnalytics #SparkAISummit
- 40. We created a Failure Taxonomy for Labels Configuration Errors Data Errors Resource Errors Deployment Errors Root Node Category of failure Input Path Not Available Number Format Exception SparkSQL JsonProcessing Exception … Root cause labels 40#UnifiedAnalytics #SparkAISummit
- 41. Extracting input features from logs java.lang.OutOfMemoryError: Java heap space at scala.reflect.ManifestFactory$$anon$9.newArray(Manifest.scala:114) at scala.reflect.ManifestFactory$$anon$9.newArray(Manifest.scala:112) at … • Extracting stack traces and error messages • Tokenize by class names and words Tokens example: java.lang.OutOfmemoryError Java heap space at scala.reflect.ManifestFactory$$anon$9.newArray(Manife st.scala:114) 41#UnifiedAnalytics #SparkAISummit
- 42. Input feature extraction • Bag of Words with TF-IDF – Computes a vocabulary of words – Uses TF-IDF to reflect importance of words in a document • Doc2Vec – Maps words, paragraphs, or documents to multi-dimensional vectors – Evaluates the placement of words wrt neighboring words – Uses a 3-layer neural network 42#Exp8SAIS
- 43. 43#UnifiedAnalytics #SparkAISummit Predictive Model Root cause of the failure App failure App’s Container Logs Error Template Extraction Error Template Extraction Feature vectors Model Learning Container Logs Root cause labels Logs from millions of app failures Label Generation Feature vector
- 44. Learning the predictive model • Shallow Learning – Logistic Regression – Random forests • Deep Learning – Neural networks 44 • Training and testing with injected failures • Test to train data set ratio 75% to 25% • Models: logistic regression, random forests 80 85 90 95 100 TF-IDF Doc2Vec AccuracyScore [%] Logistic Regression Random Forests #UnifiedAnalytics #SparkAISummit
- 45. 45#UnifiedAnalytics #SparkAISummit Messaging Platform Bot’s NLP Layer Bot’s Backend Layer The NLP element in the Chatbot Algorithm Compute Storage
- 46. 46#UnifiedAnalytics #SparkAISummit Extract the intent Intent = AppAutoTune Entities: { AppName = ‘CEO report’, TuningGoal = Speedup } Invoke app autotuning algorithm How can I make CEO report query faster Tune an app Fetch a metric Generate a report Set an alert Diagnose a failure … Extract entities for the intent Take action The NLP element in the Chatbot
- 47. Many use cases can be addressed • Who are the top resource-wasting users on the cluster? • Which app is causing contention on the cluster? • Why is my app stuck? • Alert me if my query fails • Which part of my query failed? • Kill the sales report BI app if it uses more than $25 • And many more … 47#UnifiedAnalytics #SparkAISummit
- 48. In summary • AI-driven Spark Expert in a Bot! – Makes you more productive – Saves you time and money 48#UnifiedAnalytics #SparkAISummit Sign up for a free trial, we value your feedback! http://unraveldata.com/free-trial And yes, we are hiring @ Unravel [email protected]
- 49. DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT