Ray: Enterprise-Grade, Distributed Python
1 like980 views

Ray (ray.io) is an open-source, distributed framework from U.C. Berkeley’s RISELab that easily scales Python applications from a laptop to a cluster.
1 of 26
Downloaded 37 times

























Ad
Recommended
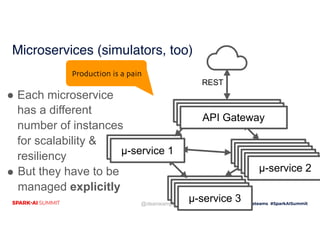
Ray distributed python framework 
Ray distributed python framework AryanJadon3 Ray is an open-source Python framework that makes it simple to scale compute-intensive Python workloads across multiple machines. It provides primitives for building fault-tolerant distributed applications with little code changes. Ray's architecture uses tasks for stateless functions, objects for immutable application values, actors for stateful workers, and a driver program to coordinate tasks and objects across a job.
Building an ML Platform with Ray and MLflow
Building an ML Platform with Ray and MLflowDatabricks This document summarizes a talk on building an ML platform with Ray and MLflow. Ray is an open-source framework for distributed computing and machine learning. It provides libraries like Ray Tune for hyperparameter tuning and Ray Serve for model serving. MLflow is a tool for managing the machine learning lifecycle including tracking experiments, managing models, and deploying models. The talk demonstrates how to build an end-to-end ML platform by integrating Ray and MLflow for distributed training, hyperparameter tuning, model tracking, and low-latency serving.
Feature Engineering
Feature EngineeringSri Ambati In this talk, Dmitry shares his approach to feature engineering which he used successfully in various Kaggle competitions. He covers common techniques used to convert your features into numeric representation used by ML algorithms.
Flink Streaming
Flink StreamingGyula Fóra Flink Streaming is the real-time data processing framework of Apache Flink. Flink streaming provides high level functional apis in Scala and Java backed by a high performance true-streaming runtime.
HBase in Practice
HBase in Practicelarsgeorge From: DataWorks Summit 2017 - Munich - 20170406
HBase hast established itself as the backend for many operational and interactive use-cases, powering well-known services that support millions of users and thousands of concurrent requests. In terms of features HBase has come a long way, overing advanced options such as multi-level caching on- and off-heap, pluggable request handling, fast recovery options such as region replicas, table snapshots for data governance, tuneable write-ahead logging and so on. This talk is based on the research for the an upcoming second release of the speakers HBase book, correlated with the practical experience in medium to large HBase projects around the world. You will learn how to plan for HBase, starting with the selection of the matching use-cases, to determining the number of servers needed, leading into performance tuning options. There is no reason to be afraid of using HBase, but knowing its basic premises and technical choices will make using it much more successful. You will also learn about many of the new features of HBase up to version 1.3, and where they are applicable.
Financial Event Sourcing at Enterprise Scale
Financial Event Sourcing at Enterprise Scaleconfluent For years, Rabobank has been actively investing in becoming a real-time, event-driven bank. If you are familiar with banking processes, you will understand that this is not simple. Many banking processes are implemented as batch jobs on not-so-commodity hardware, meaning that any migration effort is immense.
*Find out how Rabobank redesigned Rabo Alerts while continuing to provide a robust and stable alert system for its existing user base
*Learn how the project team managed to achieve a balance between the need to decentralise activity while not losing control
*Understand how Rabobank re-invented a reliable service to meet modern customer expectations
Ray and Its Growing Ecosystem
Ray and Its Growing EcosystemDatabricks Ray (https://github.com/ray-project/ray) is a framework developed at UC Berkeley and maintained by Anyscale for building distributed AI applications. Over the last year, the broader machine learning ecosystem has been rapidly adopting Ray as the primary framework for distributed execution. In this talk, we will overview how libraries such as Horovod (https://horovod.ai/), XGBoost, and Hugging Face Transformers, have integrated with Ray. We will then showcase how Uber leverages Ray and these ecosystem integrations to simplify critical production workloads at Uber. This is a joint talk between Anyscale and Uber.
Cassandra vs. ScyllaDB: Evolutionary Differences
Cassandra vs. ScyllaDB: Evolutionary DifferencesScyllaDB Apache Cassandra and ScyllaDB are distributed databases capable of processing massive globally-distributed workloads. Both use the same CQL data query language. In this webinar you will learn:
- How are they architecturally similar and how are they different?
- What's the difference between them in performance and features?
- How do their software lifecycles and release cadences contrast?
Cassandra at eBay - Cassandra Summit 2012
Cassandra at eBay - Cassandra Summit 2012Jay Patel "Buy It Now! Cassandra at eBay" talk at Cassandra Summit 2012
http://www.datastax.com/events/cassandrasummit2012
Change Data Feed in Delta
Change Data Feed in DeltaDatabricks This document discusses Delta Change Data Feed (CDF), which allows capturing changes made to Delta tables. It describes how CDF works by storing change events like inserts, updates and deletes. It also outlines how CDF can be used to improve ETL pipelines, unify batch and streaming workflows, and meet regulatory needs. The document provides examples of enabling CDF, querying change data and storing the change events. It concludes by offering a demo of CDF in Jupyter notebooks.
DASK and Apache Spark
DASK and Apache SparkDatabricks Gurpreet Singh from Microsoft gave a talk on scaling Python for data analysis and machine learning using DASK and Apache Spark. He discussed the challenges of scaling the Python data stack and compared options like DASK, Spark, and Spark MLlib. He provided examples of using DASK and PySpark DataFrames for parallel processing and showed how DASK-ML can be used to parallelize Scikit-Learn models. Distributed deep learning with tools like Project Hydrogen was also covered.
Dive into PySpark
Dive into PySparkMateusz Buśkiewicz Apache Spark™ is a fast and general engine for large-scale data processing. Spark is written in Scala and runs on top of JVM, but Python is one of the officially supported languages. But how does it actually work? How can Python communicate with Java / Scala? In this talk, we’ll dive into the PySpark internals and try to understand how to write and test high-performance PySpark applications.
Big Data at Riot Games – Using Hadoop to Understand Player Experience - Stamp...
Big Data at Riot Games – Using Hadoop to Understand Player Experience - Stamp...StampedeCon At the StampedeCon 2013 Big Data conference in St. Louis, Riot Games discussed Using Hadoop to Understand and Improve Player Experience. Riot Games aims to be the most player-focused game company in the world. To fulfill that mission, it’s vital we develop a deep, detailed understanding of players’ experiences. This is particularly challenging since our debut title, League of Legends, is one of the most played video games in the world, with more than 32 million active monthly players across the globe. In this presentation, we’ll discuss several use cases where we sought to understand and improve the player experience, the challenges we faced to solve those use cases, and the big data infrastructure that supports our capability to provide continued insight.
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다.
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다.Yongho Ha 백날 자습해도 이해 안 가던 딥러닝, 머리속에 인스톨 시켜드립니다.
이 슬라이드를 보고 나면, 유명한 영상인식을 위한 딥러닝 구조 VGG를
코드 수준에서 읽으실 수 있을 거에요
Funnel Analysis with Apache Spark and Druid
Funnel Analysis with Apache Spark and DruidDatabricks Every day, millions of advertising campaigns are happening around the world.
As campaign owners, measuring the ongoing campaign effectiveness (e.g “how many distinct users saw my online ad VS how many distinct users saw my online ad, clicked it and purchased my product?”) is super important.
However, this task (often referred to as “funnel analysis”) is not an easy task, especially if the chronological order of events matters.
One way to mitigate this challenge is combining Apache Druid and Apache DataSketches, to provide fast analytics on large volumes of data.
However, while that combination can answer some of these questions, it still can’t answer the question “how many distinct users viewed the brand’s homepage FIRST and THEN viewed product X page?”
In this talk, we will discuss how we combine Spark, Druid and DataSketches to answer such questions at scale.
Embulk - 進化するバルクデータローダ
Embulk - 進化するバルクデータローダSadayuki Furuhashi This document discusses Embulk, an open-source parallel bulk data loader that loads records from one source to another using plugins. It describes the pains of bulk data loading such as data cleaning, error handling, idempotency, and performance. Embulk addresses these issues through its plugin architecture, parallel execution, transaction control, and features like resuming and incremental execution. The document also outlines new features added to Embulk over time including different plugin types, template generation, and integration with tools like Gradle.
Imply at Apache Druid Meetup in London 1-15-20
Imply at Apache Druid Meetup in London 1-15-20Jelena Zanko Druid is a real-time analytics engine that allows for fast querying of large datasets. It is column-oriented, supports high concurrency, and can scale to thousands of servers and millions of messages per second. Druid uses an immutable segment-based architecture to store data efficiently and supports real-time and batch ingestion of data. It allows for complex queries through SQL and JSON and uses approximations and data sketches to improve query performance for large datasets.
Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis -...
Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis -...Seattle Apache Flink Meetup Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis - Seattle Apache Flink Meetup 06/28/2018
Apache Kylin – Cubes on Hadoop
Apache Kylin – Cubes on HadoopDataWorks Summit This document provides an overview of Apache Kylin, an open source distributed analytics engine that provides SQL interface and multi-dimensional analysis (OLAP) capabilities on Hadoop for extremely large datasets. The presentation covers what Kylin is, its key features and technical highlights including performance, its roadmap, and concludes with a Q&A section.
Data in Motion Tour 2024 Riyadh, Saudi Arabia
Data in Motion Tour 2024 Riyadh, Saudi Arabiaconfluent Data streaming platforms are becoming increasingly important in today’s fast-paced world. From retail giants who need to monitor inventory levels to ensure stores never run out of items, to new-age, innovative banks who are building out-of-the-box banking solutions for traditional retail banks, data streaming platforms are at the centre, powering these workflows.
Data streaming platforms connect all your applications, systems, and teams with a shared view of the most up-to-date, real-time data. From Gen AI, stream governance to stream processing - it’s these cutting edge developments that will be featured during the day.
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)Yongho Ha 요즘 Hadoop 보다 더 뜨고 있는 Spark.
그 Spark의 핵심을 이해하기 위해서는 핵심 자료구조인 Resilient Distributed Datasets (RDD)를 이해하는 것이 필요합니다.
RDD가 어떻게 동작하는지, 원 논문을 리뷰하며 살펴보도록 합시다.
http://www.cs.berkeley.edu/~matei/papers/2012/sigmod_shark_demo.pdf
Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]![Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]](https://cdn.slidesharecdn.com/ss_thumbnails/tfx-kfp-191031073013-thumbnail.jpg?width=560&fit=bounds)
Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]Animesh Singh Kubeflow Pipelines and TensorFlow Extended (TFX) together is end-to-end platform for deploying production ML pipelines. It provides a configuration framework and shared libraries to integrate common components needed to define, launch, and monitor your machine learning system. In this talk we describe how how to run TFX in hybrid cloud environments.
Large-Scale Text Processing Pipeline with Spark ML and GraphFrames: Spark Sum...
Large-Scale Text Processing Pipeline with Spark ML and GraphFrames: Spark Sum...Spark Summit In this talk we evaluate Apache Spark for a data-intensive machine learning problem. Our use case focuses on policy diffusion detection across the state legislatures in the United States over time. Previous work on policy diffusion has been unable to make an all-pairs comparison between bills due to computational intensity. As a substitute, scholars have studied single topic areas.
We provide an implementation of this analysis workflow as a distributed text processing pipeline with Spark ML and GraphFrames.
Histogrammar package—a cross-platform suite of data aggregation primitives for making histograms, calculating descriptive statistics and plotting in Scala—is introduced to enable interactive data analysis in Spark REPL.
We discuss the challenges and strategies of unstructured data processing, data formats for storage and efficient access, and graph processing at scale.
Scaling Hadoop at LinkedIn
Scaling Hadoop at LinkedInDataWorks Summit LinkedIn leverages the Apache Hadoop ecosystem for its big data analytics. Steady growth of the member base at LinkedIn along with their social activities results in exponential growth of the analytics infrastructure. Innovations in analytics tooling lead to heavier workloads on the clusters, which generate more data, which in turn encourage innovations in tooling and more workloads. Thus, the infrastructure remains under constant growth pressure. Heterogeneous environments embodied via a variety of hardware and diverse workloads make the task even more challenging.
This talk will tell the story of how we doubled our Hadoop infrastructure twice in the past two years.
• We will outline our main use cases and historical rates of cluster growth in multiple dimensions.
• We will focus on optimizations, configuration improvements, performance monitoring and architectural decisions we undertook to allow the infrastructure to keep pace with business needs.
• The topics include improvements in HDFS NameNode performance, and fine tuning of block report processing, the block balancer, and the namespace checkpointer.
• We will reveal a study on the optimal storage device for HDFS persistent journals (SATA vs. SAS vs. SSD vs. RAID).
• We will also describe Satellite Cluster project which allowed us to double the objects stored on one logical cluster by splitting an HDFS cluster into two partitions without the use of federation and practically no code changes.
• Finally, we will take a peek at our future goals, requirements, and growth perspectives.
SPEAKERS
Konstantin Shvachko, Sr Staff Software Engineer, LinkedIn
Erik Krogen, Senior Software Engineer, LinkedIn
Accelerate Your ML Pipeline with AutoML and MLflow
Accelerate Your ML Pipeline with AutoML and MLflowDatabricks Building ML models is a time consuming endeavor that requires a thorough understanding of feature engineering, selecting useful features, choosing an appropriate algorithm, and performing hyper-parameter tuning. Extensive experimentation is required to arrive at a robust and performant model. Additionally, keeping track of the models that have been developed and deployed may be complex. Solving these challenges is key for successfully implementing end-to-end ML pipelines at scale.
In this talk, we will present a seamless integration of automated machine learning within a Databricks notebook, thus providing a truly unified analytics lifecycle for data scientists and business users with improved speed and efficiency. Specifically, we will show an app that generates and executes a Databricks notebook to train an ML model with H2O’s Driverless AI automatically. The resulting model will be automatically tracked and managed with MLflow. Furthermore, we will show several deployment options to score new data on a Databricks cluster or with an external REST server, all within the app.
Giraph at Hadoop Summit 2014
Giraph at Hadoop Summit 2014Claudio Martella Apache Giraph is a large-scale graph processing system built on Hadoop. It provides an iterative processing model and vertex-centric programming model for graphs that can be too large for a single machine. Giraph scales to graphs with trillions of edges by distributing computation across a Hadoop cluster. It is faster than traditional MapReduce approaches for graph algorithms and allows graphs to be processed in memory across iterations while only writing intermediate data to disk.
Kafka Streams: What it is, and how to use it?
Kafka Streams: What it is, and how to use it?confluent Kafka Streams is a client library for building distributed applications that process streaming data stored in Apache Kafka. It provides a high-level streams DSL that allows developers to express streaming applications as set of processing steps. Alternatively, developers can use the lower-level processor API to implement custom business logic. Kafka Streams handles tasks like fault-tolerance, scalability and state management. It represents data as streams for unbounded data or tables for bounded state. Common operations include transformations, aggregations, joins and table operations.
Deploy and Serve Model from Azure Databricks onto Azure Machine Learning
Deploy and Serve Model from Azure Databricks onto Azure Machine LearningDatabricks The document discusses deploying a model trained in Azure Databricks onto Azure Machine Learning. It covers model training in Databricks, packaging the model and storing it in Azure Blob Storage, registering the model with Azure ML, deploying it to an Azure Kubernetes Service cluster, and serving it as a web service. Demo sections show training a model for semantic type detection in Databricks and deploying it using Azure ML. The goal is to make model deployment and consumption seamless across Azure services.
Getting Spark ready for real-time, operational analytics
Getting Spark ready for real-time, operational analyticsairisData SnappyData provides a unified cluster for operational analytics that can handle OLTP, OLAP and streaming workloads. It integrates an in-memory columnar store with Spark to allow for real-time queries and analytics. SnappyData aims to drastically reduce the cost and complexity of modern big data systems by combining streaming, interactive and batch processing workloads in a single cluster. It offers high performance and scalability for use cases such as market surveillance, real-time recommendations and sensor analytics.
JavaScript and Artificial Intelligence by Aatman & Sagar - AhmedabadJS
JavaScript and Artificial Intelligence by Aatman & Sagar - AhmedabadJSKNOWARTH - Software Development Company Artificial Intelligence
Deep Learning vs Machine Learning
Machine Learning
Terminology
Core Concepts
JavaScript and AI
TensorFlow
TensorFlow JS
Examples
Ad
More Related Content
What's hot (20)
Cassandra at eBay - Cassandra Summit 2012
Cassandra at eBay - Cassandra Summit 2012Jay Patel "Buy It Now! Cassandra at eBay" talk at Cassandra Summit 2012
http://www.datastax.com/events/cassandrasummit2012
Change Data Feed in Delta
Change Data Feed in DeltaDatabricks This document discusses Delta Change Data Feed (CDF), which allows capturing changes made to Delta tables. It describes how CDF works by storing change events like inserts, updates and deletes. It also outlines how CDF can be used to improve ETL pipelines, unify batch and streaming workflows, and meet regulatory needs. The document provides examples of enabling CDF, querying change data and storing the change events. It concludes by offering a demo of CDF in Jupyter notebooks.
DASK and Apache Spark
DASK and Apache SparkDatabricks Gurpreet Singh from Microsoft gave a talk on scaling Python for data analysis and machine learning using DASK and Apache Spark. He discussed the challenges of scaling the Python data stack and compared options like DASK, Spark, and Spark MLlib. He provided examples of using DASK and PySpark DataFrames for parallel processing and showed how DASK-ML can be used to parallelize Scikit-Learn models. Distributed deep learning with tools like Project Hydrogen was also covered.
Dive into PySpark
Dive into PySparkMateusz Buśkiewicz Apache Spark™ is a fast and general engine for large-scale data processing. Spark is written in Scala and runs on top of JVM, but Python is one of the officially supported languages. But how does it actually work? How can Python communicate with Java / Scala? In this talk, we’ll dive into the PySpark internals and try to understand how to write and test high-performance PySpark applications.
Big Data at Riot Games – Using Hadoop to Understand Player Experience - Stamp...
Big Data at Riot Games – Using Hadoop to Understand Player Experience - Stamp...StampedeCon At the StampedeCon 2013 Big Data conference in St. Louis, Riot Games discussed Using Hadoop to Understand and Improve Player Experience. Riot Games aims to be the most player-focused game company in the world. To fulfill that mission, it’s vital we develop a deep, detailed understanding of players’ experiences. This is particularly challenging since our debut title, League of Legends, is one of the most played video games in the world, with more than 32 million active monthly players across the globe. In this presentation, we’ll discuss several use cases where we sought to understand and improve the player experience, the challenges we faced to solve those use cases, and the big data infrastructure that supports our capability to provide continued insight.
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다.
자습해도 모르겠던 딥러닝, 머리속에 인스톨 시켜드립니다.Yongho Ha 백날 자습해도 이해 안 가던 딥러닝, 머리속에 인스톨 시켜드립니다.
이 슬라이드를 보고 나면, 유명한 영상인식을 위한 딥러닝 구조 VGG를
코드 수준에서 읽으실 수 있을 거에요
Funnel Analysis with Apache Spark and Druid
Funnel Analysis with Apache Spark and DruidDatabricks Every day, millions of advertising campaigns are happening around the world.
As campaign owners, measuring the ongoing campaign effectiveness (e.g “how many distinct users saw my online ad VS how many distinct users saw my online ad, clicked it and purchased my product?”) is super important.
However, this task (often referred to as “funnel analysis”) is not an easy task, especially if the chronological order of events matters.
One way to mitigate this challenge is combining Apache Druid and Apache DataSketches, to provide fast analytics on large volumes of data.
However, while that combination can answer some of these questions, it still can’t answer the question “how many distinct users viewed the brand’s homepage FIRST and THEN viewed product X page?”
In this talk, we will discuss how we combine Spark, Druid and DataSketches to answer such questions at scale.
Embulk - 進化するバルクデータローダ
Embulk - 進化するバルクデータローダSadayuki Furuhashi This document discusses Embulk, an open-source parallel bulk data loader that loads records from one source to another using plugins. It describes the pains of bulk data loading such as data cleaning, error handling, idempotency, and performance. Embulk addresses these issues through its plugin architecture, parallel execution, transaction control, and features like resuming and incremental execution. The document also outlines new features added to Embulk over time including different plugin types, template generation, and integration with tools like Gradle.
Imply at Apache Druid Meetup in London 1-15-20
Imply at Apache Druid Meetup in London 1-15-20Jelena Zanko Druid is a real-time analytics engine that allows for fast querying of large datasets. It is column-oriented, supports high concurrency, and can scale to thousands of servers and millions of messages per second. Druid uses an immutable segment-based architecture to store data efficiently and supports real-time and batch ingestion of data. It allows for complex queries through SQL and JSON and uses approximations and data sketches to improve query performance for large datasets.
Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis -...
Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis -...Seattle Apache Flink Meetup Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis - Seattle Apache Flink Meetup 06/28/2018
Apache Kylin – Cubes on Hadoop
Apache Kylin – Cubes on HadoopDataWorks Summit This document provides an overview of Apache Kylin, an open source distributed analytics engine that provides SQL interface and multi-dimensional analysis (OLAP) capabilities on Hadoop for extremely large datasets. The presentation covers what Kylin is, its key features and technical highlights including performance, its roadmap, and concludes with a Q&A section.
Data in Motion Tour 2024 Riyadh, Saudi Arabia
Data in Motion Tour 2024 Riyadh, Saudi Arabiaconfluent Data streaming platforms are becoming increasingly important in today’s fast-paced world. From retail giants who need to monitor inventory levels to ensure stores never run out of items, to new-age, innovative banks who are building out-of-the-box banking solutions for traditional retail banks, data streaming platforms are at the centre, powering these workflows.
Data streaming platforms connect all your applications, systems, and teams with a shared view of the most up-to-date, real-time data. From Gen AI, stream governance to stream processing - it’s these cutting edge developments that will be featured during the day.
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)
Spark 의 핵심은 무엇인가? RDD! (RDD paper review)Yongho Ha 요즘 Hadoop 보다 더 뜨고 있는 Spark.
그 Spark의 핵심을 이해하기 위해서는 핵심 자료구조인 Resilient Distributed Datasets (RDD)를 이해하는 것이 필요합니다.
RDD가 어떻게 동작하는지, 원 논문을 리뷰하며 살펴보도록 합시다.
http://www.cs.berkeley.edu/~matei/papers/2012/sigmod_shark_demo.pdf
Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]
Hybrid Cloud, Kubeflow and Tensorflow Extended [TFX]Animesh Singh Kubeflow Pipelines and TensorFlow Extended (TFX) together is end-to-end platform for deploying production ML pipelines. It provides a configuration framework and shared libraries to integrate common components needed to define, launch, and monitor your machine learning system. In this talk we describe how how to run TFX in hybrid cloud environments.
Large-Scale Text Processing Pipeline with Spark ML and GraphFrames: Spark Sum...
Large-Scale Text Processing Pipeline with Spark ML and GraphFrames: Spark Sum...Spark Summit In this talk we evaluate Apache Spark for a data-intensive machine learning problem. Our use case focuses on policy diffusion detection across the state legislatures in the United States over time. Previous work on policy diffusion has been unable to make an all-pairs comparison between bills due to computational intensity. As a substitute, scholars have studied single topic areas.
We provide an implementation of this analysis workflow as a distributed text processing pipeline with Spark ML and GraphFrames.
Histogrammar package—a cross-platform suite of data aggregation primitives for making histograms, calculating descriptive statistics and plotting in Scala—is introduced to enable interactive data analysis in Spark REPL.
We discuss the challenges and strategies of unstructured data processing, data formats for storage and efficient access, and graph processing at scale.
Scaling Hadoop at LinkedIn
Scaling Hadoop at LinkedInDataWorks Summit LinkedIn leverages the Apache Hadoop ecosystem for its big data analytics. Steady growth of the member base at LinkedIn along with their social activities results in exponential growth of the analytics infrastructure. Innovations in analytics tooling lead to heavier workloads on the clusters, which generate more data, which in turn encourage innovations in tooling and more workloads. Thus, the infrastructure remains under constant growth pressure. Heterogeneous environments embodied via a variety of hardware and diverse workloads make the task even more challenging.
This talk will tell the story of how we doubled our Hadoop infrastructure twice in the past two years.
• We will outline our main use cases and historical rates of cluster growth in multiple dimensions.
• We will focus on optimizations, configuration improvements, performance monitoring and architectural decisions we undertook to allow the infrastructure to keep pace with business needs.
• The topics include improvements in HDFS NameNode performance, and fine tuning of block report processing, the block balancer, and the namespace checkpointer.
• We will reveal a study on the optimal storage device for HDFS persistent journals (SATA vs. SAS vs. SSD vs. RAID).
• We will also describe Satellite Cluster project which allowed us to double the objects stored on one logical cluster by splitting an HDFS cluster into two partitions without the use of federation and practically no code changes.
• Finally, we will take a peek at our future goals, requirements, and growth perspectives.
SPEAKERS
Konstantin Shvachko, Sr Staff Software Engineer, LinkedIn
Erik Krogen, Senior Software Engineer, LinkedIn
Accelerate Your ML Pipeline with AutoML and MLflow
Accelerate Your ML Pipeline with AutoML and MLflowDatabricks Building ML models is a time consuming endeavor that requires a thorough understanding of feature engineering, selecting useful features, choosing an appropriate algorithm, and performing hyper-parameter tuning. Extensive experimentation is required to arrive at a robust and performant model. Additionally, keeping track of the models that have been developed and deployed may be complex. Solving these challenges is key for successfully implementing end-to-end ML pipelines at scale.
In this talk, we will present a seamless integration of automated machine learning within a Databricks notebook, thus providing a truly unified analytics lifecycle for data scientists and business users with improved speed and efficiency. Specifically, we will show an app that generates and executes a Databricks notebook to train an ML model with H2O’s Driverless AI automatically. The resulting model will be automatically tracked and managed with MLflow. Furthermore, we will show several deployment options to score new data on a Databricks cluster or with an external REST server, all within the app.
Giraph at Hadoop Summit 2014
Giraph at Hadoop Summit 2014Claudio Martella Apache Giraph is a large-scale graph processing system built on Hadoop. It provides an iterative processing model and vertex-centric programming model for graphs that can be too large for a single machine. Giraph scales to graphs with trillions of edges by distributing computation across a Hadoop cluster. It is faster than traditional MapReduce approaches for graph algorithms and allows graphs to be processed in memory across iterations while only writing intermediate data to disk.
Kafka Streams: What it is, and how to use it?
Kafka Streams: What it is, and how to use it?confluent Kafka Streams is a client library for building distributed applications that process streaming data stored in Apache Kafka. It provides a high-level streams DSL that allows developers to express streaming applications as set of processing steps. Alternatively, developers can use the lower-level processor API to implement custom business logic. Kafka Streams handles tasks like fault-tolerance, scalability and state management. It represents data as streams for unbounded data or tables for bounded state. Common operations include transformations, aggregations, joins and table operations.
Deploy and Serve Model from Azure Databricks onto Azure Machine Learning
Deploy and Serve Model from Azure Databricks onto Azure Machine LearningDatabricks The document discusses deploying a model trained in Azure Databricks onto Azure Machine Learning. It covers model training in Databricks, packaging the model and storing it in Azure Blob Storage, registering the model with Azure ML, deploying it to an Azure Kubernetes Service cluster, and serving it as a web service. Demo sections show training a model for semantic type detection in Databricks and deploying it using Azure ML. The goal is to make model deployment and consumption seamless across Azure services.
Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis -...
Approximate Queries and Graph Streams on Apache Flink - Theodore Vasiloudis -...Seattle Apache Flink Meetup
Similar to Ray: Enterprise-Grade, Distributed Python (20)
Getting Spark ready for real-time, operational analytics
Getting Spark ready for real-time, operational analyticsairisData SnappyData provides a unified cluster for operational analytics that can handle OLTP, OLAP and streaming workloads. It integrates an in-memory columnar store with Spark to allow for real-time queries and analytics. SnappyData aims to drastically reduce the cost and complexity of modern big data systems by combining streaming, interactive and batch processing workloads in a single cluster. It offers high performance and scalability for use cases such as market surveillance, real-time recommendations and sensor analytics.
JavaScript and Artificial Intelligence by Aatman & Sagar - AhmedabadJS
JavaScript and Artificial Intelligence by Aatman & Sagar - AhmedabadJSKNOWARTH - Software Development Company Artificial Intelligence
Deep Learning vs Machine Learning
Machine Learning
Terminology
Core Concepts
JavaScript and AI
TensorFlow
TensorFlow JS
Examples
Introduction to NetGuardians' Big Data Software Stack
Introduction to NetGuardians' Big Data Software StackJérôme Kehrli NetGuardians is executing it's Big Data Analytics Platform on three key Big Data components underneath: ElasticSearch, Apache Mesos and Apache Spark. This is a presentation of the behaviour of this software stack.
SnappyData Toronto Meetup Nov 2017
SnappyData Toronto Meetup Nov 2017SnappyData SnappyData is a new open source project started by Pivotal GemFire founders to provide a unified platform for OLTP, OLAP and streaming analytics using Spark. It aims to simplify big data architectures by supporting mixed workloads in a single clustered database, allowing for real-time operational analytics on live data without copying to other systems. This provides faster insights than current approaches that require periodic data copying between different databases and analytics systems.
Is Spark the right choice for data analysis ?
Is Spark the right choice for data analysis ?Ahmed Kamal This document discusses whether Spark is the right choice for data analysis. It provides an overview of Spark and compares it to other tools. Some key points:
- Spark can be used to build models on large datasets to detect fraud or recommend products using machine learning. It is well-suited to iterative algorithms.
- Existing tools like R and Python are good for small datasets but don't scale well. Spark addresses this by running efficiently on clusters through its in-memory processing and optimized execution engine.
- Spark provides a programming model that makes writing parallel code easier and encourages good choices for distributed systems. This bridges the gap between research and production compared to other frameworks.
- While still maturing, Spark
Scalable machine learning
Scalable machine learningArnaud Rachez This document provides a summary of large scale machine learning frameworks. It discusses out-of-core learning, data parallelism using MapReduce, graph parallel frameworks like Pregel, and model parallelism using parameter servers. Spark is described as easy to use with a well-designed API, while GraphLab is designed for ML researchers with vertex programming. Parameter servers are presented as aiming to support very large learning but still being in early development.
Machine learning model to production
Machine learning model to productionGeorg Heiler This document discusses moving machine learning models from prototype to production. It outlines some common problems with the current workflow where moving to production often requires redevelopment from scratch. Some proposed solutions include using notebooks as APIs and developing analytics that are accessed via an API. It also discusses different data science platforms and architectures for building end-to-end machine learning systems, focusing on flexibility, security, testing and scalability for production environments. The document recommends a custom backend integrated with Spark via APIs as the best approach for the current project.
Scala Days Highlights | BoldRadius
Scala Days Highlights | BoldRadiusBoldRadius Solutions Did you miss Scala Days 2015 in San Francisco? Have no fear! BoldRadius was there and we've compiled the best of the best! Here are the highlights of a great conference.
From lots of reports (with some data Analysis)
to Massive Data Analysis (Wit...
From lots of reports (with some data Analysis)
to Massive Data Analysis (Wit...Mark Rittman Presentation given at the Danish BI Meetup in September 2016, on the future of BI and how Hadoop, and Big Data, will revolutionise the industry.
From HDFS to S3: Migrate Pinterest Apache Spark Clusters
From HDFS to S3: Migrate Pinterest Apache Spark ClustersDatabricks The document discusses Pinterest migrating their Apache Spark clusters from HDFS to S3 storage. Some key points:
1) Migrating to S3 provided significantly better performance due to the higher IOPS of modern EC2 instances compared to their older HDFS nodes. Jobs saw 25-35% improvements on average.
2) S3 is eventually consistent while HDFS is strongly consistent, so they implemented the S3Committer to handle output consistency issues during job failures.
3) Metadata operations like file moves were very slow in S3, so they optimized jobs to reduce unnecessary moves using techniques like multipart uploads to S3.
SnappyData at Spark Summit 2017
SnappyData at Spark Summit 2017Jags Ramnarayan Why does big data always have to go through a pipeline? multiple data copies, slow, complex and stale analytics? We present a unified analytics platform that brings streaming, transactions and adhoc OLAP style interactive analytics in a single in-memory cluster based on Spark.
SnappyData, the Spark Database. A unified cluster for streaming, transactions...
SnappyData, the Spark Database. A unified cluster for streaming, transactions...SnappyData Apache Spark 2.0 offers many enhancements that make continuous analytics quite simple. In this talk, we will discuss many other things that you can do with your Apache Spark cluster. We explain how a deep integration of Apache Spark 2.0 and in-memory databases can bring you the best of both worlds! In particular, we discuss how to manage mutable data in Apache Spark, run consistent transactions at the same speed as state-the-art in-memory grids, build and use indexes for point lookups, and run 100x more analytics queries at in-memory speeds. No need to bridge multiple products or manage, tune multiple clusters. We explain how one can take regulation Apache Spark SQL OLAP workloads and speed them up by up to 20x using optimizations in SnappyData.
We then walk through several use-case examples, including IoT scenarios, where one has to ingest streams from many sources, cleanse it, manage the deluge by pre-aggregating and tracking metrics per minute, store all recent data in a in-memory store along with history in a data lake and permit interactive analytic queries at this constantly growing data. Rather than stitching together multiple clusters as proposed in Lambda, we walk through a design where everything is achieved in a single, horizontally scalable Apache Spark 2.0 cluster. A design that is simpler, a lot more efficient, and let’s you do everything from Machine Learning and Data Science to Transactions and Visual Analytics all in one single cluster.
SnappyData Overview Slidedeck for Big Data Bellevue 
SnappyData Overview Slidedeck for Big Data Bellevue SnappyData SnappyData is a new open source project that extends Apache Spark to enable real-time operational analytics by combining OLTP, OLAP, and stream processing capabilities. It provides a unified cluster that allows storing data in-memory for fast queries and updates while maintaining high availability. SnappyData integrates Spark and GemFire technologies to offer low-latency queries, updates and analytics on fast moving streaming and batch data.
Architecting Agile Data Applications for Scale
Architecting Agile Data Applications for ScaleDatabricks Data analytics and reporting platforms historically have been rigid, monolithic, hard to change and have limited ability to scale up or scale down. I can’t tell you how many times I have heard a business user ask for something as simple as an additional column in a report and IT says it will take 6 months to add that column because it doesn’t exist in the datawarehouse. As a former DBA, I can tell you the countless hours I have spent “tuning” SQL queries to hit pre-established SLAs. This talk will talk about how to architect modern data and analytics platforms in the cloud to support agility and scalability. We will include topics like end to end data pipeline flow, data mesh and data catalogs, live data and streaming, performing advanced analytics, applying agile software development practices like CI/CD and testability to data applications and finally taking advantage of the cloud for infinite scalability both up and down.
Microsoft Openness Mongo DB
Microsoft Openness Mongo DBHeriyadi Janwar This document discusses Microsoft's support for open source tools and NoSQL databases on the Azure platform. It provides examples of various open source technologies supported, such as Linux, Hadoop, Java, PHP, and Node.js. It then discusses how Azure provides solutions for large-scale social networking and e-commerce applications through patterns like data sharding, caching layers, and messaging. Azure aims to provide high availability, elastic scale, and support for flexible data models and processing paradigms to meet the needs of NoSQL and big data applications.
Apache Spark for Everyone - Women Who Code Workshop
Apache Spark for Everyone - Women Who Code WorkshopAmanda Casari Women Who Code Ignite 2015 Workshop - Introducing Apache Spark in notebooks to technologists, using Java, Scala, Python + R.
Powering a Startup with Apache Spark with Kevin Kim
Powering a Startup with Apache Spark with Kevin KimSpark Summit In Between (A mobile App for couples, downloaded 20M in Global), from daily batch for extracting metrics, analysis and dashboard. Spark is widely used by engineers and data analysts in Between, thanks to the performance and expendability of Spark, data operating has become extremely efficient. Entire team including Biz Dev, Global Operation, Designers are enjoying data results so Spark is empowering entire company for data driven operation and thinking. Kevin, Co-founder and Data Team leader of Between will be presenting how things are going in Between. Listeners will know how small and agile team is living with data (how we build organization, culture and technical base) after this presentation.
Healthcare Claim Reimbursement using Apache Spark
Healthcare Claim Reimbursement using Apache SparkDatabricks The document discusses rewriting a claims reimbursement system using Spark. It describes how Spark provides better performance, scalability and cost savings compared to the previous Oracle-based system. Key points include using Spark for ETL to load data into a Delta Lake data lake, implementing the business logic in a reusable Java library, and seeing significant increases in processing volumes and speeds compared to the prior system. Challenges and tips for adoption are also provided.
In-Memory Computing - The Big Picture
In-Memory Computing - The Big PictureMarkus Kett In-memory computing is ultra-fast and offers completely new possibilities. Let‘s analyze which factors slow down classic JPA apps, why NoSQL isn't more effective, how we can optimize JPA performance, and where are the limits are.
After that, you will learn which in-memory strategies you can choose to speed up your performance. Let's have a look at in-memory databases like Times-Ten, in-memory grids like Coherence, and popular caching frameworks.
After that, you will learn which in-memory strategies you can choose to speed up your apps. We will have a look at in-memory databases like Times-Ten, in-memory grids like Coherence, and caching frameworks.
Finally, we introduce you to the pure Java in-memory computing paradigm. You will learn how you can build up Java in-memory database apps, how you can execute queries in microseconds or even nanoseconds, and how you can persist your data on disk. No magic, but pure Java and JVM-power only.
Dirty data? Clean it up! - Datapalooza Denver 2016
Dirty data? Clean it up! - Datapalooza Denver 2016Dan Lynn Dan Lynn (AgilData) & Patrick Russell (Craftsy) present on how to do data science in the real world. We discuss data cleansing, ETL, pipelines, hosting, and share several tools used in the industry.
JavaScript and Artificial Intelligence by Aatman & Sagar - AhmedabadJS
JavaScript and Artificial Intelligence by Aatman & Sagar - AhmedabadJSKNOWARTH - Software Development Company
Ad
More from Databricks (20)
DW Migration Webinar-March 2022.pptx
DW Migration Webinar-March 2022.pptxDatabricks The document discusses migrating a data warehouse to the Databricks Lakehouse Platform. It outlines why legacy data warehouses are struggling, how the Databricks Platform addresses these issues, and key considerations for modern analytics and data warehousing. The document then provides an overview of the migration methodology, approach, strategies, and key takeaways for moving to a lakehouse on Databricks.
Data Lakehouse Symposium | Day 1 | Part 1
Data Lakehouse Symposium | Day 1 | Part 1Databricks The world of data architecture began with applications. Next came data warehouses. Then text was organized into a data warehouse.
Then one day the world discovered a whole new kind of data that was being generated by organizations. The world found that machines generated data that could be transformed into valuable insights. This was the origin of what is today called the data lakehouse. The evolution of data architecture continues today.
Come listen to industry experts describe this transformation of ordinary data into a data architecture that is invaluable to business. Simply put, organizations that take data architecture seriously are going to be at the forefront of business tomorrow.
This is an educational event.
Several of the authors of the book Building the Data Lakehouse will be presenting at this symposium.
Data Lakehouse Symposium | Day 1 | Part 2
Data Lakehouse Symposium | Day 1 | Part 2Databricks The world of data architecture began with applications. Next came data warehouses. Then text was organized into a data warehouse.
Then one day the world discovered a whole new kind of data that was being generated by organizations. The world found that machines generated data that could be transformed into valuable insights. This was the origin of what is today called the data lakehouse. The evolution of data architecture continues today.
Come listen to industry experts describe this transformation of ordinary data into a data architecture that is invaluable to business. Simply put, organizations that take data architecture seriously are going to be at the forefront of business tomorrow.
This is an educational event.
Several of the authors of the book Building the Data Lakehouse will be presenting at this symposium.
Data Lakehouse Symposium | Day 2
Data Lakehouse Symposium | Day 2Databricks The world of data architecture began with applications. Next came data warehouses. Then text was organized into a data warehouse.
Then one day the world discovered a whole new kind of data that was being generated by organizations. The world found that machines generated data that could be transformed into valuable insights. This was the origin of what is today called the data lakehouse. The evolution of data architecture continues today.
Come listen to industry experts describe this transformation of ordinary data into a data architecture that is invaluable to business. Simply put, organizations that take data architecture seriously are going to be at the forefront of business tomorrow.
This is an educational event.
Several of the authors of the book Building the Data Lakehouse will be presenting at this symposium.
Data Lakehouse Symposium | Day 4
Data Lakehouse Symposium | Day 4Databricks The document discusses the challenges of modern data, analytics, and AI workloads. Most enterprises struggle with siloed data systems that make integration and productivity difficult. The future of data lies with a data lakehouse platform that can unify data engineering, analytics, data warehousing, and machine learning workloads on a single open platform. The Databricks Lakehouse platform aims to address these challenges with its open data lake approach and capabilities for data engineering, SQL analytics, governance, and machine learning.
5 Critical Steps to Clean Your Data Swamp When Migrating Off of Hadoop
5 Critical Steps to Clean Your Data Swamp When Migrating Off of HadoopDatabricks In this session, learn how to quickly supplement your on-premises Hadoop environment with a simple, open, and collaborative cloud architecture that enables you to generate greater value with scaled application of analytics and AI on all your data. You will also learn five critical steps for a successful migration to the Databricks Lakehouse Platform along with the resources available to help you begin to re-skill your data teams.
Democratizing Data Quality Through a Centralized Platform
Democratizing Data Quality Through a Centralized PlatformDatabricks Bad data leads to bad decisions and broken customer experiences. Organizations depend on complete and accurate data to power their business, maintain efficiency, and uphold customer trust. With thousands of datasets and pipelines running, how do we ensure that all data meets quality standards, and that expectations are clear between producers and consumers? Investing in shared, flexible components and practices for monitoring data health is crucial for a complex data organization to rapidly and effectively scale.
At Zillow, we built a centralized platform to meet our data quality needs across stakeholders. The platform is accessible to engineers, scientists, and analysts, and seamlessly integrates with existing data pipelines and data discovery tools. In this presentation, we will provide an overview of our platform’s capabilities, including:
Giving producers and consumers the ability to define and view data quality expectations using a self-service onboarding portal
Performing data quality validations using libraries built to work with spark
Dynamically generating pipelines that can be abstracted away from users
Flagging data that doesn’t meet quality standards at the earliest stage and giving producers the opportunity to resolve issues before use by downstream consumers
Exposing data quality metrics alongside each dataset to provide producers and consumers with a comprehensive picture of health over time
Learn to Use Databricks for Data Science
Learn to Use Databricks for Data ScienceDatabricks Data scientists face numerous challenges throughout the data science workflow that hinder productivity. As organizations continue to become more data-driven, a collaborative environment is more critical than ever — one that provides easier access and visibility into the data, reports and dashboards built against the data, reproducibility, and insights uncovered within the data.. Join us to hear how Databricks’ open and collaborative platform simplifies data science by enabling you to run all types of analytics workloads, from data preparation to exploratory analysis and predictive analytics, at scale — all on one unified platform.
Why APM Is Not the Same As ML Monitoring
Why APM Is Not the Same As ML MonitoringDatabricks Application performance monitoring (APM) has become the cornerstone of software engineering allowing engineering teams to quickly identify and remedy production issues. However, as the world moves to intelligent software applications that are built using machine learning, traditional APM quickly becomes insufficient to identify and remedy production issues encountered in these modern software applications.
As a lead software engineer at NewRelic, my team built high-performance monitoring systems including Insights, Mobile, and SixthSense. As I transitioned to building ML Monitoring software, I found the architectural principles and design choices underlying APM to not be a good fit for this brand new world. In fact, blindly following APM designs led us down paths that would have been better left unexplored.
In this talk, I draw upon my (and my team’s) experience building an ML Monitoring system from the ground up and deploying it on customer workloads running large-scale ML training with Spark as well as real-time inference systems. I will highlight how the key principles and architectural choices of APM don’t apply to ML monitoring. You’ll learn why, understand what ML Monitoring can successfully borrow from APM, and hear what is required to build a scalable, robust ML Monitoring architecture.
The Function, the Context, and the Data—Enabling ML Ops at Stitch Fix
The Function, the Context, and the Data—Enabling ML Ops at Stitch FixDatabricks Autonomy and ownership are core to working at Stitch Fix, particularly on the Algorithms team. We enable data scientists to deploy and operate their models independently, with minimal need for handoffs or gatekeeping. By writing a simple function and calling out to an intuitive API, data scientists can harness a suite of platform-provided tooling meant to make ML operations easy. In this talk, we will dive into the abstractions the Data Platform team has built to enable this. We will go over the interface data scientists use to specify a model and what that hooks into, including online deployment, batch execution on Spark, and metrics tracking and visualization.
Stage Level Scheduling Improving Big Data and AI Integration
Stage Level Scheduling Improving Big Data and AI IntegrationDatabricks In this talk, I will dive into the stage level scheduling feature added to Apache Spark 3.1. Stage level scheduling extends upon Project Hydrogen by improving big data ETL and AI integration and also enables multiple other use cases. It is beneficial any time the user wants to change container resources between stages in a single Apache Spark application, whether those resources are CPU, Memory or GPUs. One of the most popular use cases is enabling end-to-end scalable Deep Learning and AI to efficiently use GPU resources. In this type of use case, users read from a distributed file system, do data manipulation and filtering to get the data into a format that the Deep Learning algorithm needs for training or inference and then sends the data into a Deep Learning algorithm. Using stage level scheduling combined with accelerator aware scheduling enables users to seamlessly go from ETL to Deep Learning running on the GPU by adjusting the container requirements for different stages in Spark within the same application. This makes writing these applications easier and can help with hardware utilization and costs.
There are other ETL use cases where users want to change CPU and memory resources between stages, for instance there is data skew or perhaps the data size is much larger in certain stages of the application. In this talk, I will go over the feature details, cluster requirements, the API and use cases. I will demo how the stage level scheduling API can be used by Horovod to seamlessly go from data preparation to training using the Tensorflow Keras API using GPUs.
The talk will also touch on other new Apache Spark 3.1 functionality, such as pluggable caching, which can be used to enable faster dataframe access when operating from GPUs.
Simplify Data Conversion from Spark to TensorFlow and PyTorch
Simplify Data Conversion from Spark to TensorFlow and PyTorchDatabricks In this talk, I would like to introduce an open-source tool built by our team that simplifies the data conversion from Apache Spark to deep learning frameworks.
Imagine you have a large dataset, say 20 GBs, and you want to use it to train a TensorFlow model. Before feeding the data to the model, you need to clean and preprocess your data using Spark. Now you have your dataset in a Spark DataFrame. When it comes to the training part, you may have the problem: How can I convert my Spark DataFrame to some format recognized by my TensorFlow model?
The existing data conversion process can be tedious. For example, to convert an Apache Spark DataFrame to a TensorFlow Dataset file format, you need to either save the Apache Spark DataFrame on a distributed filesystem in parquet format and load the converted data with third-party tools such as Petastorm, or save it directly in TFRecord files with spark-tensorflow-connector and load it back using TFRecordDataset. Both approaches take more than 20 lines of code to manage the intermediate data files, rely on different parsing syntax, and require extra attention for handling vector columns in the Spark DataFrames. In short, all these engineering frictions greatly reduced the data scientists’ productivity.
The Databricks Machine Learning team contributed a new Spark Dataset Converter API to Petastorm to simplify these tedious data conversion process steps. With the new API, it takes a few lines of code to convert a Spark DataFrame to a TensorFlow Dataset or a PyTorch DataLoader with default parameters.
In the talk, I will use an example to show how to use the Spark Dataset Converter to train a Tensorflow model and how simple it is to go from single-node training to distributed training on Databricks.
Scaling your Data Pipelines with Apache Spark on Kubernetes
Scaling your Data Pipelines with Apache Spark on KubernetesDatabricks There is no doubt Kubernetes has emerged as the next generation of cloud native infrastructure to support a wide variety of distributed workloads. Apache Spark has evolved to run both Machine Learning and large scale analytics workloads. There is growing interest in running Apache Spark natively on Kubernetes. By combining the flexibility of Kubernetes and scalable data processing with Apache Spark, you can run any data and machine pipelines on this infrastructure while effectively utilizing resources at disposal.
In this talk, Rajesh Thallam and Sougata Biswas will share how to effectively run your Apache Spark applications on Google Kubernetes Engine (GKE) and Google Cloud Dataproc, orchestrate the data and machine learning pipelines with managed Apache Airflow on GKE (Google Cloud Composer). Following topics will be covered: – Understanding key traits of Apache Spark on Kubernetes- Things to know when running Apache Spark on Kubernetes such as autoscaling- Demonstrate running analytics pipelines on Apache Spark orchestrated with Apache Airflow on Kubernetes cluster.
Scaling and Unifying SciKit Learn and Apache Spark Pipelines
Scaling and Unifying SciKit Learn and Apache Spark PipelinesDatabricks Pipelines have become ubiquitous, as the need for stringing multiple functions to compose applications has gained adoption and popularity. Common pipeline abstractions such as “fit” and “transform” are even shared across divergent platforms such as Python Scikit-Learn and Apache Spark.
Scaling pipelines at the level of simple functions is desirable for many AI applications, however is not directly supported by Ray’s parallelism primitives. In this talk, Raghu will describe a pipeline abstraction that takes advantage of Ray’s compute model to efficiently scale arbitrarily complex pipeline workflows. He will demonstrate how this abstraction cleanly unifies pipeline workflows across multiple platforms such as Scikit-Learn and Spark, and achieves nearly optimal scale-out parallelism on pipelined computations.
Attendees will learn how pipelined workflows can be mapped to Ray’s compute model and how they can both unify and accelerate their pipelines with Ray.
Sawtooth Windows for Feature Aggregations
Sawtooth Windows for Feature AggregationsDatabricks In this talk about zipline, we will introduce a new type of windowing construct called a sawtooth window. We will describe various properties about sawtooth windows that we utilize to achieve online-offline consistency, while still maintaining high-throughput, low-read latency and tunable write latency for serving machine learning features.We will also talk about a simple deployment strategy for correcting feature drift – due operations that are not “abelian groups”, that operate over change data.
Redis + Apache Spark = Swiss Army Knife Meets Kitchen Sink
Redis + Apache Spark = Swiss Army Knife Meets Kitchen SinkDatabricks We want to present multiple anti patterns utilizing Redis in unconventional ways to get the maximum out of Apache Spark.All examples presented are tried and tested in production at Scale at Adobe. The most common integration is spark-redis which interfaces with Redis as a Dataframe backing Store or as an upstream for Structured Streaming. We deviate from the common use cases to explore where Redis can plug gaps while scaling out high throughput applications in Spark.
Niche 1 : Long Running Spark Batch Job – Dispatch New Jobs by polling a Redis Queue
· Why?
o Custom queries on top a table; We load the data once and query N times
· Why not Structured Streaming
· Working Solution using Redis
Niche 2 : Distributed Counters
· Problems with Spark Accumulators
· Utilize Redis Hashes as distributed counters
· Precautions for retries and speculative execution
· Pipelining to improve performance
Re-imagine Data Monitoring with whylogs and Spark
Re-imagine Data Monitoring with whylogs and SparkDatabricks In the era of microservices, decentralized ML architectures and complex data pipelines, data quality has become a bigger challenge than ever. When data is involved in complex business processes and decisions, bad data can, and will, affect the bottom line. As a result, ensuring data quality across the entire ML pipeline is both costly, and cumbersome while data monitoring is often fragmented and performed ad hoc. To address these challenges, we built whylogs, an open source standard for data logging. It is a lightweight data profiling library that enables end-to-end data profiling across the entire software stack. The library implements a language and platform agnostic approach to data quality and data monitoring. It can work with different modes of data operations, including streaming, batch and IoT data.
In this talk, we will provide an overview of the whylogs architecture, including its lightweight statistical data collection approach and various integrations. We will demonstrate how the whylogs integration with Apache Spark achieves large scale data profiling, and we will show how users can apply this integration into existing data and ML pipelines.
Raven: End-to-end Optimization of ML Prediction Queries
Raven: End-to-end Optimization of ML Prediction QueriesDatabricks Machine learning (ML) models are typically part of prediction queries that consist of a data processing part (e.g., for joining, filtering, cleaning, featurization) and an ML part invoking one or more trained models. In this presentation, we identify significant and unexplored opportunities for optimization. To the best of our knowledge, this is the first effort to look at prediction queries holistically, optimizing across both the ML and SQL components.
We will present Raven, an end-to-end optimizer for prediction queries. Raven relies on a unified intermediate representation that captures both data processing and ML operators in a single graph structure.
This allows us to introduce optimization rules that
(i) reduce unnecessary computations by passing information between the data processing and ML operators
(ii) leverage operator transformations (e.g., turning a decision tree to a SQL expression or an equivalent neural network) to map operators to the right execution engine, and
(iii) integrate compiler techniques to take advantage of the most efficient hardware backend (e.g., CPU, GPU) for each operator.
We have implemented Raven as an extension to Spark’s Catalyst optimizer to enable the optimization of SparkSQL prediction queries. Our implementation also allows the optimization of prediction queries in SQL Server. As we will show, Raven is capable of improving prediction query performance on Apache Spark and SQL Server by up to 13.1x and 330x, respectively. For complex models, where GPU acceleration is beneficial, Raven provides up to 8x speedup compared to state-of-the-art systems. As part of the presentation, we will also give a demo showcasing Raven in action.
Processing Large Datasets for ADAS Applications using Apache Spark
Processing Large Datasets for ADAS Applications using Apache SparkDatabricks Semantic segmentation is the classification of every pixel in an image/video. The segmentation partitions a digital image into multiple objects to simplify/change the representation of the image into something that is more meaningful and easier to analyze [1][2]. The technique has a wide variety of applications ranging from perception in autonomous driving scenarios to cancer cell segmentation for medical diagnosis.
Exponential growth in the datasets that require such segmentation is driven by improvements in the accuracy and quality of the sensors generating the data extending to 3D point cloud data. This growth is further compounded by exponential advances in cloud technologies enabling the storage and compute available for such applications. The need for semantically segmented datasets is a key requirement to improve the accuracy of inference engines that are built upon them.
Streamlining the accuracy and efficiency of these systems directly affects the value of the business outcome for organizations that are developing such functionalities as a part of their AI strategy.
This presentation details workflows for labeling, preprocessing, modeling, and evaluating performance/accuracy. Scientists and engineers leverage domain-specific features/tools that support the entire workflow from labeling the ground truth, handling data from a wide variety of sources/formats, developing models and finally deploying these models. Users can scale their deployments optimally on GPU-based cloud infrastructure to build accelerated training and inference pipelines while working with big datasets. These environments are optimized for engineers to develop such functionality with ease and then scale against large datasets with Spark-based clusters on the cloud.
Massive Data Processing in Adobe Using Delta Lake
Massive Data Processing in Adobe Using Delta LakeDatabricks At Adobe Experience Platform, we ingest TBs of data every day and manage PBs of data for our customers as part of the Unified Profile Offering. At the heart of this is a bunch of complex ingestion of a mix of normalized and denormalized data with various linkage scenarios power by a central Identity Linking Graph. This helps power various marketing scenarios that are activated in multiple platforms and channels like email, advertisements etc. We will go over how we built a cost effective and scalable data pipeline using Apache Spark and Delta Lake and share our experiences.
What are we storing?
Multi Source – Multi Channel Problem
Data Representation and Nested Schema Evolution
Performance Trade Offs with Various formats
Go over anti-patterns used
(String FTW)
Data Manipulation using UDFs
Writer Worries and How to Wipe them Away
Staging Tables FTW
Datalake Replication Lag Tracking
Performance Time!
Ad
Recently uploaded (20)
Process Mining at Dimension Data - Jan vermeulen
Process Mining at Dimension Data - Jan vermeulenProcess mining Evangelist Dimension Data has over 30,000 employees in nine operating regions spread over all continents. They provide services from infrastructure sales to IT outsourcing for multinationals. As the Global Process Owner at Dimension Data, Jan Vermeulen is responsible for the standardization of the global IT services processes.
Jan shares his journey of establishing process mining as a methodology to improve process performance and compliance, to grow their business, and to increase the value in their operations. These three pillars form the foundation of Dimension Data's business case for process mining.
Jan shows examples from each of the three pillars and shares what he learned on the way. The growth pillar is particularly new and interesting, because Dimension Data was able to compete in a RfP process for a new customer by providing a customized offer after analyzing the customer's data with process mining.

Chapter-3-PROBLEM-SOLVING.pdf hhhhhhhhhh
Chapter-3-PROBLEM-SOLVING.pdf hhhhhhhhhhChrisjohnAlfiler math fhxjrjxtckcktcktckttkctkctkvtkvtkvtovyovyovoyvtovvlyyovvoyvyotvlvottovtovvotvtovtotvovotvotvtovtovtovotvtlvltlvtvlt

定制(意大利Rimini毕业证)布鲁诺马代尔纳嘉雷迪米音乐学院学历认证
定制(意大利Rimini毕业证)布鲁诺马代尔纳嘉雷迪米音乐学院学历认证Taqyea 2025年新版意大利毕业证布鲁诺马代尔纳嘉雷迪米音乐学院文凭【q微1954292140】办理布鲁诺马代尔纳嘉雷迪米音乐学院毕业证(Rimini毕业证书)2025年新版毕业证书【q微1954292140】布鲁诺马代尔纳嘉雷迪米音乐学院offer/学位证、留信官方学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作【q微1954292140】Buy Conservatorio di Musica "B.Maderna G.Lettimi" Diploma购买美国毕业证,购买英国毕业证,购买澳洲毕业证,购买加拿大毕业证,以及德国毕业证,购买法国毕业证(q微1954292140)购买荷兰毕业证、购买瑞士毕业证、购买日本毕业证、购买韩国毕业证、购买新西兰毕业证、购买新加坡毕业证、购买西班牙毕业证、购买马来西亚毕业证等。包括了本科毕业证,硕士毕业证。
主营项目:
1、真实教育部国外学历学位认证《意大利毕业文凭证书快速办理布鲁诺马代尔纳嘉雷迪米音乐学院毕业证定购》【q微1954292140】《论文没过布鲁诺马代尔纳嘉雷迪米音乐学院正式成绩单》,教育部存档,教育部留服网站100%可查.
2、办理Rimini毕业证,改成绩单《Rimini毕业证明办理布鲁诺马代尔纳嘉雷迪米音乐学院办理文凭》【Q/WeChat:1954292140】Buy Conservatorio di Musica "B.Maderna G.Lettimi" Certificates《正式成绩单论文没过》,布鲁诺马代尔纳嘉雷迪米音乐学院Offer、在读证明、学生卡、信封、证明信等全套材料,从防伪到印刷,从水印到钢印烫金,高精仿度跟学校原版100%相同.
3、真实使馆认证(即留学人员回国证明),使馆存档可通过大使馆查询确认.
4、留信网认证,国家专业人才认证中心颁发入库证书,留信网存档可查.
《布鲁诺马代尔纳嘉雷迪米音乐学院留服认证意大利毕业证书办理Rimini文凭不见了怎么办》【q微1954292140】学位证1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。
高仿真还原意大利文凭证书和外壳,定制意大利布鲁诺马代尔纳嘉雷迪米音乐学院成绩单和信封。毕业证定制Rimini毕业证【q微1954292140】办理意大利布鲁诺马代尔纳嘉雷迪米音乐学院毕业证(Rimini毕业证书)【q微1954292140】学位证书制作代办流程布鲁诺马代尔纳嘉雷迪米音乐学院offer/学位证成绩单激光标、留信官方学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作。帮你解决布鲁诺马代尔纳嘉雷迪米音乐学院学历学位认证难题。
意大利文凭布鲁诺马代尔纳嘉雷迪米音乐学院成绩单,Rimini毕业证【q微1954292140】办理意大利布鲁诺马代尔纳嘉雷迪米音乐学院毕业证(Rimini毕业证书)【q微1954292140】安全可靠的布鲁诺马代尔纳嘉雷迪米音乐学院offer/学位证办理原版成绩单、留信官方学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作。帮你解决布鲁诺马代尔纳嘉雷迪米音乐学院学历学位认证难题。
意大利文凭购买,意大利文凭定制,意大利文凭补办。专业在线定制意大利大学文凭,定做意大利本科文凭,【q微1954292140】复制意大利Conservatorio di Musica "B.Maderna G.Lettimi" completion letter。在线快速补办意大利本科毕业证、硕士文凭证书,购买意大利学位证、布鲁诺马代尔纳嘉雷迪米音乐学院Offer,意大利大学文凭在线购买。
如果您在英、加、美、澳、欧洲等留学过程中或回国后:
1、在校期间因各种原因未能顺利毕业《Rimini成绩单工艺详解》【Q/WeChat:1954292140】《Buy Conservatorio di Musica "B.Maderna G.Lettimi" Transcript快速办理布鲁诺马代尔纳嘉雷迪米音乐学院教育部学历认证书毕业文凭证书》,拿不到官方毕业证;
2、面对父母的压力,希望尽快拿到;
3、不清楚认证流程以及材料该如何准备;
4、回国时间很长,忘记办理;
5、回国马上就要找工作《正式成绩单布鲁诺马代尔纳嘉雷迪米音乐学院文凭详解细节》【q微1954292140】《研究生文凭Rimini毕业证详解细节》办给用人单位看;
6、企事业单位必须要求办理的;
7、需要报考公务员、购买免税车、落转户口、申请留学生创业基金。
【q微1954292140】帮您解决在意大利布鲁诺马代尔纳嘉雷迪米音乐学院未毕业难题(Conservatorio di Musica "B.Maderna G.Lettimi" )文凭购买、毕业证购买、大学文凭购买、大学毕业证购买、买文凭、日韩文凭、英国大学文凭、美国大学文凭、澳洲大学文凭、加拿大大学文凭(q微1954292140)新加坡大学文凭、新西兰大学文凭、爱尔兰文凭、西班牙文凭、德国文凭、教育部认证,买毕业证,毕业证购买,买大学文凭,购买日韩毕业证、英国大学毕业证、美国大学毕业证、澳洲大学毕业证、加拿大大学毕业证(q微1954292140)新加坡大学毕业证、新西兰大学毕业证、爱尔兰毕业证、西班牙毕业证、德国毕业证,回国证明,留信网认证,留信认证办理,学历认证。从而完成就业。布鲁诺马代尔纳嘉雷迪米音乐学院毕业证办理,布鲁诺马代尔纳嘉雷迪米音乐学院文凭办理,布鲁诺马代尔纳嘉雷迪米音乐学院成绩单办理和真实留信认证、留服认证、布鲁诺马代尔纳嘉雷迪米音乐学院学历认证。学院文凭定制,布鲁诺马代尔纳嘉雷迪米音乐学院原版文凭补办,扫描件文凭定做,100%文凭复刻。
特殊原因导致无法毕业,也可以联系我们帮您办理相关材料:
1:在布鲁诺马代尔纳嘉雷迪米音乐学院挂科了,不想读了,成绩不理想怎么办???
2:打算回国了,找工作的时候,需要提供认证《Rimini成绩单购买办理布鲁诺马代尔纳嘉雷迪米音乐学院毕业证书范本》【Q/WeChat:1954292140】Buy Conservatorio di Musica "B.Maderna G.Lettimi" Diploma《正式成绩单论文没过》有文凭却得不到认证。又该怎么办???意大利毕业证购买,意大利文凭购买,
3:回国了找工作没有布鲁诺马代尔纳嘉雷迪米音乐学院文凭怎么办?有本科却要求硕士又怎么办?
How to join illuminati Agent in uganda call+256776963507/0741506136
How to join illuminati Agent in uganda call+256776963507/0741506136illuminati Agent uganda call+256776963507/0741506136 How to join illuminati Agent in uganda call+256776963507/0741506136
3. Univariable and Multivariable Analysis_Using Stata_2025.pdf
3. Univariable and Multivariable Analysis_Using Stata_2025.pdfaxonneurologycenter1 Univariable and Multivariable Analysis_Using Stata


Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...
Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...James Francis Paradigm Asset Management By James Francis, CEO of Paradigm Asset Management
In the landscape of urban safety innovation, Mt. Vernon is emerging as a compelling case study for neighboring Westchester County cities. The municipality’s recently launched Public Safety Camera Program not only represents a significant advancement in community protection but also offers valuable insights for New Rochelle and White Plains as they consider their own safety infrastructure enhancements.

Deloitte Analytics - Applying Process Mining in an audit context
Deloitte Analytics - Applying Process Mining in an audit contextProcess mining Evangelist Mieke Jans is a Manager at Deloitte Analytics Belgium. She learned about process mining from her PhD supervisor while she was collaborating with a large SAP-using company for her dissertation.
Mieke extended her research topic to investigate the data availability of process mining data in SAP and the new analysis possibilities that emerge from it. It took her 8-9 months to find the right data and prepare it for her process mining analysis. She needed insights from both process owners and IT experts. For example, one person knew exactly how the procurement process took place at the front end of SAP, and another person helped her with the structure of the SAP-tables. She then combined the knowledge of these different persons.
FPET_Implementation_2_MA to 360 Engage Direct.pptx
FPET_Implementation_2_MA to 360 Engage Direct.pptxssuser4ef83d Engage Direct 360 marketing optimization sas entreprise miner
Volkswagen - Analyzing the World's Biggest Purchasing Process
Volkswagen - Analyzing the World's Biggest Purchasing ProcessProcess mining Evangelist Philipp Horn has worked in the Business Intelligence area of the Purchasing department of Volkswagen for more than 5 years. He is a front runner in adopting new techniques to understand and improve processes and learned about process mining from a friend, who in turn heard about it at a meet-up where Fluxicon had participated with other startups.
Philipp warns that you need to be careful not to jump to conclusions. For example, in a discovered process model it is easy to say that this process should be simpler here and there, but often there are good reasons for these exceptions today. To distinguish what is necessary and what could be actually improved requires both process knowledge and domain expertise on a detailed level.
录取通知书加拿大TMU毕业证多伦多都会大学电子版毕业证成绩单
录取通知书加拿大TMU毕业证多伦多都会大学电子版毕业证成绩单Taqyea 保密服务多伦多都会大学英文毕业证书影本加拿大成绩单多伦多都会大学文凭【q微1954292140】办理多伦多都会大学学位证(TMU毕业证书)成绩单VOID底纹防伪【q微1954292140】帮您解决在加拿大多伦多都会大学未毕业难题(Toronto Metropolitan University)文凭购买、毕业证购买、大学文凭购买、大学毕业证购买、买文凭、日韩文凭、英国大学文凭、美国大学文凭、澳洲大学文凭、加拿大大学文凭(q微1954292140)新加坡大学文凭、新西兰大学文凭、爱尔兰文凭、西班牙文凭、德国文凭、教育部认证,买毕业证,毕业证购买,买大学文凭,购买日韩毕业证、英国大学毕业证、美国大学毕业证、澳洲大学毕业证、加拿大大学毕业证(q微1954292140)新加坡大学毕业证、新西兰大学毕业证、爱尔兰毕业证、西班牙毕业证、德国毕业证,回国证明,留信网认证,留信认证办理,学历认证。从而完成就业。多伦多都会大学毕业证办理,多伦多都会大学文凭办理,多伦多都会大学成绩单办理和真实留信认证、留服认证、多伦多都会大学学历认证。学院文凭定制,多伦多都会大学原版文凭补办,扫描件文凭定做,100%文凭复刻。
特殊原因导致无法毕业,也可以联系我们帮您办理相关材料:
1:在多伦多都会大学挂科了,不想读了,成绩不理想怎么办???
2:打算回国了,找工作的时候,需要提供认证《TMU成绩单购买办理多伦多都会大学毕业证书范本》【Q/WeChat:1954292140】Buy Toronto Metropolitan University Diploma《正式成绩单论文没过》有文凭却得不到认证。又该怎么办???加拿大毕业证购买,加拿大文凭购买,【q微1954292140】加拿大文凭购买,加拿大文凭定制,加拿大文凭补办。专业在线定制加拿大大学文凭,定做加拿大本科文凭,【q微1954292140】复制加拿大Toronto Metropolitan University completion letter。在线快速补办加拿大本科毕业证、硕士文凭证书,购买加拿大学位证、多伦多都会大学Offer,加拿大大学文凭在线购买。
加拿大文凭多伦多都会大学成绩单,TMU毕业证【q微1954292140】办理加拿大多伦多都会大学毕业证(TMU毕业证书)【q微1954292140】学位证书电子图在线定制服务多伦多都会大学offer/学位证offer办理、留信官方学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作。帮你解决多伦多都会大学学历学位认证难题。
主营项目:
1、真实教育部国外学历学位认证《加拿大毕业文凭证书快速办理多伦多都会大学毕业证书不见了怎么办》【q微1954292140】《论文没过多伦多都会大学正式成绩单》,教育部存档,教育部留服网站100%可查.
2、办理TMU毕业证,改成绩单《TMU毕业证明办理多伦多都会大学学历认证定制》【Q/WeChat:1954292140】Buy Toronto Metropolitan University Certificates《正式成绩单论文没过》,多伦多都会大学Offer、在读证明、学生卡、信封、证明信等全套材料,从防伪到印刷,从水印到钢印烫金,高精仿度跟学校原版100%相同.
3、真实使馆认证(即留学人员回国证明),使馆存档可通过大使馆查询确认.
4、留信网认证,国家专业人才认证中心颁发入库证书,留信网存档可查.
《多伦多都会大学学位证购买加拿大毕业证书办理TMU假学历认证》【q微1954292140】学位证1:1完美还原海外各大学毕业材料上的工艺:水印,阴影底纹,钢印LOGO烫金烫银,LOGO烫金烫银复合重叠。文字图案浮雕、激光镭射、紫外荧光、温感、复印防伪等防伪工艺。
高仿真还原加拿大文凭证书和外壳,定制加拿大多伦多都会大学成绩单和信封。学历认证证书电子版TMU毕业证【q微1954292140】办理加拿大多伦多都会大学毕业证(TMU毕业证书)【q微1954292140】毕业证书样本多伦多都会大学offer/学位证学历本科证书、留信官方学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作。帮你解决多伦多都会大学学历学位认证难题。
多伦多都会大学offer/学位证、留信官方学历认证(永久存档真实可查)采用学校原版纸张、特殊工艺完全按照原版一比一制作【q微1954292140】Buy Toronto Metropolitan University Diploma购买美国毕业证,购买英国毕业证,购买澳洲毕业证,购买加拿大毕业证,以及德国毕业证,购买法国毕业证(q微1954292140)购买荷兰毕业证、购买瑞士毕业证、购买日本毕业证、购买韩国毕业证、购买新西兰毕业证、购买新加坡毕业证、购买西班牙毕业证、购买马来西亚毕业证等。包括了本科毕业证,硕士毕业证。
real illuminati Uganda agent 0782561496/0756664682
real illuminati Uganda agent 0782561496/0756664682way to join real illuminati Agent In Kampala Call/WhatsApp+256782561496/0756664682 real illuminati Uganda agent 0782561496/0756664682
Call illuminati Agent in uganda+256776963507/0741506136
Call illuminati Agent in uganda+256776963507/0741506136illuminati Agent uganda call+256776963507/0741506136 Call illuminati Agent in uganda+256776963507/0741506136
04302025_CCC TUG_DataVista: The Design Story
04302025_CCC TUG_DataVista: The Design Storyccctableauusergroup CCCCO and WestEd share the story behind how DataVista came together from a design standpoint and in Tableau.
Customer Segmentation using K-Means clustering
Customer Segmentation using K-Means clusteringIngrid Nyakerario This project demonstrates the application of machine learning—specifically K-Means Clustering—to segment customers based on behavioral and demographic data. The objective is to identify distinct customer groups to enable targeted marketing strategies and personalized customer engagement.
The presentation walks through:
Data preprocessing and exploratory data analysis (EDA)
Feature scaling and dimensionality reduction
K-Means clustering and silhouette analysis
Insights and business recommendations from each customer segment
This work showcases practical data science skills applied to a real-world business problem, using Python and visualization tools to generate actionable insights for decision-makers.
indonesia-gen-z-report-2024 Gen Z (born between 1997 and 2012) is currently t...
indonesia-gen-z-report-2024 Gen Z (born between 1997 and 2012) is currently t...disnakertransjabarda Gen Z (born between 1997 and 2012) is currently the biggest generation group in Indonesia with 27.94% of the total population or. 74.93 million people.
How to join illuminati Agent in uganda call+256776963507/0741506136
How to join illuminati Agent in uganda call+256776963507/0741506136illuminati Agent uganda call+256776963507/0741506136
Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...
Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...James Francis Paradigm Asset Management
real illuminati Uganda agent 0782561496/0756664682
real illuminati Uganda agent 0782561496/0756664682way to join real illuminati Agent In Kampala Call/WhatsApp+256782561496/0756664682
Call illuminati Agent in uganda+256776963507/0741506136
Call illuminati Agent in uganda+256776963507/0741506136illuminati Agent uganda call+256776963507/0741506136
indonesia-gen-z-report-2024 Gen Z (born between 1997 and 2012) is currently t...
indonesia-gen-z-report-2024 Gen Z (born between 1997 and 2012) is currently t...disnakertransjabarda
Ray: Enterprise-Grade, Distributed Python
- 2. Ray: Enterprise-Grade, Distributed Python Dean Wampler Anyscale
- 3. @deanwampler Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.
- 4. Agenda Why Ray? Demo When to use Spark? When to use Ray? How to get started with Ray
- 5. Why Ray?
- 6. @deanwampler Usage% 2012 2014 2016 Ti 05 Hence, there is a pressing need for robust, easy to use solutions for distributed Python Model sizes and therefore compute requirements outstripping Moore’s Law Moore’s Law (2x every 18 months) 35x every 18 months! Python growth driven by ML/AI and other data science workloads
- 7. Reinforcement Learning: Motivation for Ray
- 10. @deanwampler ▪Observations ▪ Board state ▪Actions ▪ Where to place stones ▪Rewards ▪ 1 if win ▪ 0 otherwise AlphaGo (Silver et al. 2016)
- 11. @deanwampler
- 12. @deanwampler Diverse Compute Requirements Motivated Creation of Ray! Simulator (game engine, robot sim, factory floor sim…) Neural network “stuff” And repeated play, over and over again, to train for achieving the best reward Complex agent?
- 15. @deanwampler Microservices (simulators, too) REST API Gateway µ-service 1 µ-service 2 µ-service 3 Nice! (In theory…)
- 16. @deanwampler Microservices (simulators, too) REST API Gateway µ-service 1 µ-service 2 µ-service 3 Production is a pain API GatewayAPI Gateway µ-service 1 µ-service 2µ-service 2µ-service 2µ-service 2µ-service 2 µ-service 3µ-service 3µ-service 3 ! Each microservice has a different number of instances for scalability & resiliency ! But they have to be managed explicitly
- 17. @deanwampler Ray Cluster task/ actortask/ actor task/ actor task/ actortask/ actor task/ actor task/ actor task/ actor task/ actor task/ actor task/ actor task/ actor task/ actor task/ actor Microservices (simulators, too) REST API Gateway µ-service 1 µ-service 2 µ-service 3 Back to simplicity ! Back to one “logical” instance ! Ray handles scaling transparently
- 18. Demo!
- 19. When to use Spark When to use Ray
- 20. @deanwampler Where Spark Excels ▪ Massive-scale data sets ▪ Uniform, records with a schema ▪ Efficient, parallelized transformations ▪ SQL ▪ Batch analytics ▪ Stream processing ▪ Intuitive, high-level abstractions for data science & engineering tasks
- 21. @deanwampler Where Ray Excels ▪ Highly non-uniform data graphs ▪ Think typical “in-memory object models”, but distributed ▪ Handles distributed state intuitively ▪ Highly non-uniform task graphs ▪ Small to large scale tasks ▪ Intuitive API for the “90%” of cases ▪ Supports compute problems ranging from ▪ general services, games, and simulators ▪ to ▪ stochastic gradient descent, HPO, …
- 22. Getting started with Ray
- 23. @deanwampler If you’re already using these… ▪ asyncio ▪ joblib ▪ multiprocessing.Pool ▪ Use Ray’s implementations ▪ Drop-in replacements ▪ Change import statements ▪ Break the one-node limitation! For example, from this: from multiprocessing.pool import Pool To this: from ray.util.multiprocessing.pool import Pool
- 24. @deanwampler Ray Community and Resources ▪ ray.io - entry point for all things Ray ▪ Tutorials: anyscale.com/academy ▪ github.com/ray-project/ray ▪ anyscale.com/events
- 25. @deanwampler Feedback Your feedback is important to us. Don’t forget to rate and review the sessions.