Handling Data in Mega Scale Systems
Download as PPTX, PDF9 likes3,955 views

This document discusses strategies for handling large amounts of data in web applications. It begins by providing examples of how much data some large websites contain, ranging from terabytes to petabytes. It then covers various techniques for scaling data handling capabilities including vertical and horizontal scaling, replication, partitioning, consistency models, normalization, caching, and using different data engine types beyond relational databases. The key lessons are that data volumes continue growing rapidly, and a variety of techniques are needed to scale across servers, datacenters, and provide high performance and availability.








































































Handling Data in Mega Scale Systems
- 1. Intelligent People. Uncommon Ideas.Handling Data in Mega Scale Web Apps(lessons learnt @ Directi)Vineet Gupta | GM – Software Engineering | Directihttp://vineetgupta.spaces.live.comLicensed under Creative Commons Attribution Sharealike Noncommercial
- 2. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 3. Not CoveringOffline Processing (Batching / Queuing)Distributed Processing – Map ReduceNon-blocking IOFault Detection, Tolerance and Recovery
- 4. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 5. How Big Does it Get22M+ usersDozens of DB serversDozens of Web serversSix specialized graph database servers to run recommendations engineSource:http://highscalability.com/digg-architecture
- 6. How Big Does it Get1 TB / Day100 M blogs indexed / day10 B objects indexed / day0.5 B photos and videosData doubles in 6 monthsUsers double in 6 monthsSource:http://www.royans.net/arch/2007/10/25/scaling-technorati-100-million-blogs-indexed-everyday/
- 7. How Big Does it Get2 PB Raw Storage470 M photos, 4-5 sizes each400 k photos added / day35 M photos in Squid cache (total)2 M photos in Squid RAM38k reqs / sec to Memcached4 B queries / daySource:http://mysqldba.blogspot.com/2008/04/mysql-uc-2007-presentation-file.html
- 8. How Big Does it GetVirtualized database spans 600 production instances residing in 100+ server clusters distributed over 8 datacenters2 PB of data26 B SQL queries / day1 B page views / day3 B API calls / month15,000 App serversSource:http://highscalability.com/ebay-architecture/
- 9. How Big Does it Get450,000 low cost commodity servers in 2006Indexed 8 B web-pages in 2005200 GFS clusters (1 cluster = 1,000 – 5,000 machines)Read / write thruput = 40 GB / sec across a clusterMap-Reduce100k jobs / day20 PB of data processed / day10k MapReduce programsSource:http://highscalability.com/google-architecture/
- 10. Key TrendsData Size ~ PBData Growth ~ TB / dayNo of servers – 10s to 10,000No of datacenters – 1 to 10Queries – B+ / daySpecialized needs – more / other than RDBMS
- 11. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 12. HostRAMCPUCPURAMCPURAMApp ServerDB ServerVertical Scaling (Scaling Up)
- 13. Big IronsSunfire E20kPowerEdge SC143536x 1.8GHz processorsDualcore 1.8 GHz processor$450,000 - $2,500,000Around $1,500
- 14. Vertical Scaling (Scaling Up)Increasing the hardware resources on a hostProsSimple to implementFast turnaround timeConsFinite limitHardware does not scale linearly (diminishing returns for each incremental unit)Requires downtimeIncreases Downtime ImpactIncremental costs increase exponentially
- 15. HostHostApp ServerDB ServerVertical Partitioning of Services
- 16. Vertical Partitioning of ServicesSplit services on separate nodesEach node performs different tasksProsIncreases per application AvailabilityTask-based specialization, optimization and tuning possibleReduces context switchingSimple to implement for out of band processesNo changes to App requiredFlexibility increasesConsSub-optimal resource utilizationMay not increase overall availabilityFinite Scalability
- 17. Horizontal Scaling of App ServerWeb ServerLoad BalancerWeb ServerDB ServerWeb Server
- 18. Horizontal Scaling of App ServerAdd more nodes for the same serviceIdentical, doing the same taskLoad BalancingHardware balancers are fasterSoftware balancers are more customizable
- 19. The problem - StateWeb ServerUser 1Load BalancerWeb ServerDB ServerUser 2Web Server
- 20. Sticky SessionsWeb ServerUser 1Load BalancerWeb ServerDB ServerUser 2Web ServerAsymmetrical load distributionDowntime
- 21. Central Session StoreWeb ServerUser 1Load BalancerWeb ServerSession StoreUser 2Web ServerSPOFReads and Writes generate network + disk IO
- 22. Clustered SessionsWeb ServerUser 1Load BalancerWeb ServerUser 2Web Server
- 23. Clustered SessionsProsNo SPOFEasier to setupFast ReadsConsn x WritesIncrease in network IO with increase in nodesStale data (rare)
- 24. Sticky Sessions with Central StoreWeb ServerUser 1Load BalancerWeb ServerDB ServerUser 2Web Server
- 25. More Session ManagementNo SessionsStuff state in a cookie and sign it!Cookie is sent with every request / responseSuper Slim SessionsKeep small amount of frequently used data in cookiePull rest from DB (or central session store)
- 26. Sessions - RecommendationBadSticky sessionsGoodClustered sessions for small number of nodes and / or small write volumeCentral sessions for large number of nodes or large write volumeGreatNo Sessions!
- 27. App Tier Scaling - MoreHTTP Accelerators / Reverse ProxyStatic content caching, redirect to lighter HTTPAsync NIO on user-side, Keep-alive connection poolCDNGet closer to your userAkamai, LimelightIP AnycastingAsync NIO
- 28. Scaling a Web AppApp-LayerAdd more nodes and load balance!Avoid Sticky SessionsAvoid Sessions!!Data StoreTricky! Very Tricky!!!
- 29. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 30. Replication = Scaling by DuplicationApp LayerT1, T2, T3, T4
- 31. Replication = Scaling by DuplicationApp LayerT1, T2, T3, T4T1, T2, T3, T4T1, T2, T3, T4T1, T2, T3, T4T1, T2, T3, T4Each node has its own copy of dataShared Nothing Cluster
- 32. ReplicationRead : Write = 4:1Scale reads at cost of writes!Duplicate Data – each node has its own copyMaster SlaveWrites sent to one node, cascaded to othersMulti-MasterWrites can be sent to multiple nodesCan lead to deadlocksRequires conflict management
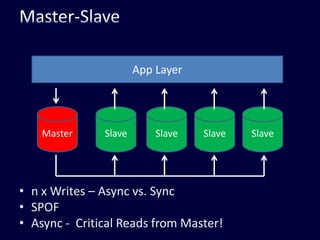
- 33. Master-SlaveApp LayerMasterSlaveSlaveSlaveSlaven x Writes – Async vs. SyncSPOFAsync - Critical Reads from Master!
- 34. Multi-MasterApp LayerMasterMasterSlaveSlaveSlaven x Writes – Async vs. SyncNo SPOFConflicts!
- 35. Replication ConsiderationsAsynchronousGuaranteed, but out-of-band replication from Master to SlaveMaster updates its own db and returns a response to clientReplication from Master to Slave takes place asynchronouslyFaster response to a client Slave data is marginally behind the MasterRequires modification to App to send critical reads and writes to master, and load balance all other readsSynchronousGuaranteed, in-band replication from Master to SlaveMaster updates its own db, and confirms all slaves have updated their db before returning a response to clientSlower response to a client Slaves have the same data as the Master at all timesRequires modification to App to send writes to master and load balance all reads
- 36. Replication ConsiderationsReplication at RDBMS levelSupport may exists in RDBMS or through 3rd party toolFaster and more reliableApp must send writes to Master, reads to any db and critical reads to MasterReplication at Driver / DAO levelDriver / DAO layer ensures writes are performed on all connected DBsReads are load balancedCritical reads are sent to a MasterIn most cases RDBMS agnosticSlower and in some cases less reliable
- 37. Diminishing ReturnsPer Server:4R, 1W2R, 1W1R, 1WReadReadReadWriteWriteWriteReadReadReadReadWriteWriteWriteWrite
- 38. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 39. Partitioning = Scaling by DivisionVertical PartitioningDivide data on tables / columnsScale to as many boxes as there are tables or columnsFiniteHorizontal PartitioningDivide data on rowsScale to as many boxes as there are rows!Limitless scaling
- 40. Vertical PartitioningApp LayerT1, T2, T3, T4, T5Note: A node here typically represents a shared nothing cluster
- 41. Vertical PartitioningApp LayerT3T4T5T2T1Facebook - User table, posts table can be on separate nodesJoins need to be done in code (Why have them?)
- 42. Horizontal PartitioningApp LayerT3T4T5T2T1First million rowsT3T4T5T2T1Second million rowsT3T4T5T2T1Third million rows
- 43. Horizontal Partitioning SchemesValue BasedSplit on timestamp of postsSplit on first alphabet of user nameHash BasedUse a hash function to determine clusterLookup MapFirst Come First ServeRound Robin
- 44. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 46. TransactionsTransactions make you feel aloneNo one else manipulates the data when you areTransactional serializabilityThe behavior is as if a serial order existsSource:http://blogs.msdn.com/pathelland/Slide 46
- 47. Life in the “Now”Transactions live in the “now” inside servicesTime marches forwardTransactions commit Advancing timeTransactions see the committed transactionsA service’s biz-logic lives in the “now”Source:http://blogs.msdn.com/pathelland/Slide 47
- 48. Sending Unlocked Data Isn’t “Now”Messages contain unlocked dataAssume no shared transactionsUnlocked data may changeUnlocking it allows changeMessages are not from the “now”They are from the pastThere is no simultaneity at a distance!Similar to speed of light
- 49. Knowledge travels at speed of light
- 50. By the time you see a distant object it may have changed!
- 51. By the time you see a message, the data may have changed!Services, transactions, and locks bound simultaneity! Inside a transaction, things appear simultaneous (to others)
- 52. Simultaneity only inside a transaction!
- 53. Simultaneity only inside a service!Source:http://blogs.msdn.com/pathelland/Slide 48
- 54. Outside Data: a Blast from the PastAll data from distant stars is from the past 10 light years away; 10 year old knowledge
- 55. The sun may have blown up 5 minutes ago
- 56. We won’t know for 3 minutes more…All data seen from a distant service is from the “past”By the time you see it, it has been unlocked and may changeEach service has its own perspectiveInside data is “now”; outside data is “past”My inside is not your inside; my outside is not your outsideThis is like going from Newtonian to Einstonian physics Newton’s time marched forward uniformly
- 58. Classic distributed computing: many systems look like one
- 59. RPC, 2-phase commit, remote method calls…
- 60. In Einstein’s world, everything is “relative” to one’s perspective
- 61. Today: No attempt to blur the boundarySource:http://blogs.msdn.com/pathelland/Slide 49
- 62. Versions and Distributed SystemsCan’t have “the same” dataat many locationsUnless it isa snapshotChanging distributed dataneeds versionsCreates asnapshot…Source:http://blogs.msdn.com/pathelland/
- 63. Subjective ConsistencyGiven what I know here and now, make a decisionRemember the versions of all the data used to make this decisionRecord the decision as being predicated on these versionsOther copies of the object may make divergent decisionsTry to sort out conflicts within the familyIf necessary, programmatically apologizeVery rarely, whine and fuss for human helpSubjective Consistency Given the information I have at hand, make a decision and act on it ! Remember the information at hand !Ambassadors Had AuthorityBack before radio, it could be months between communication with the king. Ambassadors would make treaties and much more... They had binding authority. The mess was sorted out later!Source:http://blogs.msdn.com/pathelland/
- 64. Eventual ConsistencyEventually, all the copies of the object share their changes“I’ll show you mine if you show me yours!”Now, apply subjective consistency:“Given the information I have at hand, make a decision and act on it!”Everyone has the same information, everyone comes to the same conclusion about the decisions to take…Eventual Consistency Given the same knowledge, produce the same result !
- 65. Everyone sharing their knowledge leads to the same result...This is NOT magic; it is a design requirement !Idempotence, commutativity, and associativity of the operations(decisions made) are all implied by this requirementSource:http://blogs.msdn.com/pathelland/
- 66. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 67. Why Normalize?Classic problemwith de-normalizationCan’t updateSam’s phone #since there aremany copiesEmp #Emp NameMgr #Mgr NameEmp Phone47Joe13Sam5-123418Sally38Harry3-312391Pete13Sam2-111266Mary02Betty5-7349Mgr Phone6-98765-67826-98764-0101Normalization’s Goal Is Eliminating Update AnomaliesCan Be Changed Without “Funny Behavior”Each Data Item Lives in One PlaceDe-normalization isOK if you aren’t going to update!Source:http://blogs.msdn.com/pathelland/
- 68. Eliminate Joins
- 69. Eliminate Joins6 joins for 1 query!Do you think FB would do this?And how would you do joins with partitioned data?De-normalization removes joinsBut increases data volumeBut disk is cheap and getting cheaperAnd can lead to inconsistent dataIf you are lazyHowever this is not really an issue
- 70. “Append-Only” DataMany Kinds of Computing are “Append-Only”Lots of observations are made about the worldDebits, credits, Purchase-Orders, Customer-Change-Requests, etcAs time moves on, more observations are addedYou can’t change the history but you can add new observationsDerived Results May Be CalculatedEstimate of the “current” inventoryFrequently inaccurateHistoric Rollups Are CalculatedMonthly bank statements
- 71. Databases and Transaction LogsTransaction Logs Are the TruthHigh-performance & write-onlyDescribe ALL the changes to the dataData-Base the Current OpinionDescribes the latest value of the data as perceived by the applicationLogDBThe Database Is a Caching of the Transaction Log !It is the subset of the latest committed values represented in the transaction log…Source:http://blogs.msdn.com/pathelland/
- 72. We Are Swimming in a Sea of Immutable Data Source:http://blogs.msdn.com/pathelland/
- 73. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 74. CachingMakes scaling easier (cheaper)Core IdeaRead data from persistent store into memoryStore in a hash-tableRead first from cache, if not, load from persistent store
- 75. Write thru CacheApp ServerCache
- 76. Write back CacheApp ServerCache
- 78. Memcached
- 79. How does it workIn-memory Distributed Hash TableMemcached instance manifests as a process (often on the same machine as web-server)Memcached Client maintains a hash tableWhich item is stored on which instanceMemcached Server maintains a hash tableWhich item is stored in which memory location
- 80. OutlineCharacteristicsApp Tier ScalingReplicationPartitioningConsistencyNormalizationCachingData Engine Types
- 81. It’s not all Relational!Amazon - S3, SimpleDb, DynamoGoogle - App Engine Datastore, BigTableMicrosoft – SQL Data Services, Azure StoragesFacebook – CassandraLinkedIn - Project VoldemortRingo, Scalaris, Kai, Dynomite, MemcacheDB, ThruDB, CouchDB, Hbase, Hypertable
- 82. TuplespacesBasic ConceptsNo tables - Containers-EntityNo schema - each tuple has its own set of propertiesAmazon SimpleDB – strings onlyMicrosoft Azure SQL Data ServicesStrings, blob, datetime, bool, int, double, etc.No x-container joins as of nowGoogle App Engine DatastoreStrings, blob, datetime, bool, int, double, etc.
- 83. Key-Value StoresGoogle BigTableSparse, Distributed, multi-dimensional sorted mapIndexed by row key, column key, timestampEach value is an un-interpreted array of bytesAmazon DynamoData partitioned and replicated using consistent hashingDecentralized replica sync protocolConsistency thru versioningFacebook CassandraUsed for Inbox searchOpen SourceScalarisKeys stored in lexicographical orderImproved Paxos to provide ACIDMemory resident, no persistence
- 84. In SummaryReal Life Scaling requires trade offsNo Silver BulletNeed to learn new thingsNeed to un-learnBalance!
- 85. QUESTIONS?
- 86. Intelligent People. Uncommon Ideas.Licensed under Creative Commons Attribution Sharealike Noncommercial