Stream Processing with Apache Spark, Kafka, Avro, and Apicurio Registry on AWS using Amazon MSK and EMR
0 likes160 views

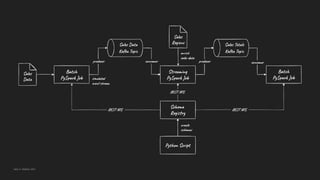
We will read and write messages to and from Amazon MSK in Apache Avro format. We will store the Avro-format Kafka message’s key and value schemas in Apicurio Registry and retrieve the schemas instead of hard-coding the schemas in the PySpark scripts. We will also use the registry to store schemas for CSV-format data files. Link to the blog post and video: https://itnext.io/stream-processing-with-apache-spark-kafka-avro-and-apicurio-registry-on-amazon-emr-and-amazon-13080defa3be
1 of 22
Download to read offline




















Ad
Recommended
Building Open Data Lakes on AWS with Debezium and Apache Hudi
Building Open Data Lakes on AWS with Debezium and Apache HudiGary Stafford Build a simple open data lake on AWS using a combination of open-source software (OSS), including Red Hat’s Debezium, Apache Kafka, and Kafka Connect for change data capture (CDC), and Apache Hive, Apache Spark, Apache Hudi, and Hudi’s DeltaStreamer for managing our data lake. We will use fully-managed AWS services to host the open data lake components, including Amazon RDS, Amazon MKS, Amazon EKS, and EMR.
Link to the blog post and video: https://garystafford.medium.com/building-open-data-lakes-with-debezium-and-apache-hudi-c3370d3f86fb
Lighthouse - an open-source library to build data lakes - Kris Peeters
Lighthouse - an open-source library to build data lakes - Kris PeetersData Science Leuven Data Minded built an open-source library to build data lakes
6th Data Science Leuven Meetup: https://github.com/datamindedbe/lighthouse
Hands on experience in real-time data process with AWS Kinesis, Firehose, S3 ...
Hands on experience in real-time data process with AWS Kinesis, Firehose, S3 ...Chuan-Yen Chiang This document summarizes an architecture for real-time data processing and analysis using AWS services like Kinesis, Firehose, S3, and Athena. It discusses using Kinesis to collect data, Firehose to load it into S3, and Athena to run SQL queries on the data and define schemas. While this provides flexibility, maintainability and low cost, the author notes it may not be fast enough for true real-time analysis due to limitations of Athena compared to other services. The document concludes with an invitation for questions.
Big Data - Linked In_DEEPU
Big Data - Linked In_DEEPUDeepu M The document discusses big data technologies including Apache HBase, Hive, Hadoop, MapReduce, Spring XD, Sqoop, Spark, Kafka, Solr, Zookeeper, and Oozie. It also outlines several proof of concept projects involving importing structured and unstructured data using these technologies, real-time ingestion of data from databases into HDFS, Hive and HBase integration, indexing and searching large datasets with Solr, monitoring and charting big data growth, data compression and encryption, job scheduling with Oozie, and implementing machine learning algorithms with Spark MLib.
Using Apache Spark Structured Streaming on Azure Databricks for Predictive M...
Using Apache Spark Structured Streaming on Azure Databricks for Predictive M...Databricks We use Apache Spark Structured Streaming on the Databricks Unified Analytics Platform to process live data and Spark MLlib to train models for predicting machine failure. Structured Streaming and MLlib combined in the Zeiss Measuring Capability App allows users to stay on top of all relevant machine information and to know at a glance if a machine is capable of performing reliably. We will demonstrate how Azure Databricks allows us to easily schedule and monitor an increasing number of Spark jobs, continuously adding new features to our app.
R_Demystifying_DECK (1)
R_Demystifying_DECK (1)Roger Fried AsterR allows users to leverage the power and speed of Aster for big data analytics while maintaining the familiar R environment. It works by executing R functions and code on Aster's massively parallel processing system. Key uses of AsterR include database integration with Aster, easy exploration and simple analysis of large datasets, fast data transformation on billions of rows, passing R functions to Aster for execution, and blending R and SQL for advanced users.
Snowplow Analitics
Snowplow AnaliticsDiego Pacheco Snowplow is an event analytics platform that allows users to record events, enrich the data, load it into storage systems like AWS S3 and Redshift, and perform real-time processing using Kinesis and Spark streaming. The platform uses a standardized events data model and pipeline to collect, clean, and analyze digital interactions at scale.
Elastic Meetup Belgium - December 2018
Elastic Meetup Belgium - December 2018Arthur Eyckerman The document discusses a presentation given by Arthur Eyckerman on what's new in the Elastic Stack, including updates to Elasticsearch, Kibana, Logstash, Beats, and solutions. It provides an overview of recent features and acquisitions by Elastic as well as a history and timeline of the Elastic Stack. The presentation was given at Beta Cowork in Turnhout, Belgium.
Data Science in the Cloud
Data Science in the CloudMargriet Groenendijk Margriet Groenendijk gave a presentation on data science in the cloud. She discussed her background working with large datasets and using tools like Python, Spark, R, and IBM's cloud services. She then outlined the typical data science workflow of collecting and storing data, exploring and cleaning it, creating predictive models, and presenting results. Finally, she demonstrated an example of analyzing weather and Twitter sentiment data using various IBM cloud tools.
Alexander Pavlenko, Java Software Engineer, DataArt.
Alexander Pavlenko, Java Software Engineer, DataArt.Alina Vilk This document discusses building a Spark connector for Ryft, a hardware appliance that performs high-speed compute on big data. It provides examples of how to query data stored on Ryft using its query language. The Spark connector allows querying and processing Ryft data using Spark and RDDs in a distributed manner. It maps structured Ryft data to DataFrames for SQL queries and shows performance benefits of using Ryft compared to running Spark on EC2 servers.
JanusGraph: Looking Backward, Reaching Forward
JanusGraph: Looking Backward, Reaching ForwardJason Plurad The JanusGraph project started at the Linux Foundation earlier this year, but it is not the new kid on the block. We'll start with a look at the origins and evolution of this open source graph database through the lens of a few IBM graph use cases. We'll discuss the new features in latest release of JanusGraph, and then take a look at future directions to explore together with the open community. Presented on October 18, 2017 at the Graph Technologies Meetup in Santa Clara, CA. https://www.meetup.com/_CAIDI/events/243122187/
Curse of Cardinality: A History and Evolution of Monitoring at Scale
Curse of Cardinality: A History and Evolution of Monitoring at ScaleMichael Goodness This document summarizes the evolution of monitoring tools from the 1990s to present day. It discusses early tools like MRTG and RRDtool that helped prove the need for larger network links. Nagios emerged in the early 2000s and became popular but also led to expensive commercial clones. Graphite and StatsD provided great graphing in the late 2000s. Splunk's full-text search and interface grew in popularity. OpenTSDB aimed to be highly scalable but could cause outages. Prometheus emerged in 2015 and was adopted by CNCF, using a pull model and dimensional data. The document concludes that observability is the next focus area, with improved metrics, distributed tracing, and better use of logs.
Cloud architectures for data science
Cloud architectures for data scienceMargriet Groenendijk Data Science covers the complete workflow from defining a question, finding the most suitable data source, identifying the right tools and finally presenting the best possible answer in a clear, engaging manner. But it all starts with having access to the data. In these slides I will walk your through some examples of how to collect, store and access data in the Cloud with the use of different APIs.
Data Spider for Legacy Infrastructure: Capturing content from multiple file s...
Data Spider for Legacy Infrastructure: Capturing content from multiple file s...ITD Systems In ideal world the systems are integrated and talking to each other through APIs. However, real life is not ideal, especially in legacy infrastructure. This presentation provides an example of capturing legacy content from 100+ geographically distributed sites into central digital archive based on Alfresco.
RedisConf17 - Real-time Intelligence with Redis-ML and Apache Spark
RedisConf17 - Real-time Intelligence with Redis-ML and Apache SparkRedis Labs 1) Real-time machine learning with Redis and Apache Spark allows training models with Spark and serving them through Redis for fast, scalable predictions.
2) Databricks provides a unified analytics platform using Spark and Redis that simplifies data integration, experimentation, machine learning and deployment for data scientists, engineers and analysts.
3) Their platform includes Spark for training models from big data, Redis for serving the trained models in production with high performance, scalability and availability.
Apache orc
Apache orcwipedrou Apache ORC (Optimized Row Columnar) is a free and open-source column-oriented data storage format of the Apache Hadoop ecosystem.
Site story wadl2013
Site story wadl2013Martin Klein This document summarizes a presentation about SiteStory, an alternative approach to web archiving. SiteStory allows transactional archiving by capturing HTTP transactions between browsers and servers. This addresses issues with traditional crawler-based archiving like timing problems and inability to archive certain content. The presentation describes how SiteStory works, current status including benchmark testing, and how to access a SiteStory testbed installation.
Aws slide
Aws slideBedazzled Media The document discusses AWS Lambda including how it allows serverless applications to be built without provisioning or managing servers, how functions can be triggered by events and executed on demand, and some common use cases for AWS Lambda including powering chatbots, voice apps, data processing, web and mobile backends, and IoT applications.
Graph Computing with Apache TinkerPop
Graph Computing with Apache TinkerPopJason Plurad Presented at Open Camps (Database Camp) in New York City on November 19, 2017. http://www.db.camp/2017/presentations/graph-computing-with-apache-tinkerpop
Exploring linked data in r
Exploring linked data in rDavid Sherlock This document discusses exploring linked data in R and Gephi. It introduces RStudio as an integrated development environment for R that makes using R easier and is available on multiple platforms. It also covers using SPARQL from RStudio to query an endpoint, view results as a dataframe or matrix, and export to GraphML format for analysis in the Gephi graph visualization and manipulation software.
Analysing GitHub commits with R
Analysing GitHub commits with RBarbara Fusinska The document discusses analyzing GitHub commit data with R. It covers obtaining GitHub data from sources like the GitHub Archive and API, exploring and processing the data with R basics and libraries, and visualizing the results. The agenda includes an introduction to R, data exploration and processing techniques in R like handling different data sources and formats, and how to deal with big data using tools that connect R to Hadoop. Examples demonstrate retrieving active repository data, processing multiple files, plotting, and detecting anomalies.
Processing genetic data at scale
Processing genetic data at scaleMark Schroering This document discusses processing large genetic data sets at scale in the cloud. It describes ingesting variant call format (VCF) files into a data lake in Amazon S3 using Apache Parquet format and annotating variants using Docker containers on AWS Batch. It also covers indexing variants and annotations for analytics using PostgreSQL and DynamoDB and providing queries through a Lambda function. Lessons learned include using DynamoDB on-demand capacity, monitoring compute resource limits, utilizing spot instances, partitioning large tables, and using reader endpoints for Aurora databases. Current stats show over 101 million variants stored across 289GB in S3 and 94GB in DynamoDB with query response times averaging 1 second.
Netflix Big Data Paris 2017
Netflix Big Data Paris 2017Jason Flittner How "Stranger Things" can happen with Visual Analytics at Netflix. This is the presentation given by Jason Flittner at Big Data Paris 2017.
Ruby on Rails with Active Record
Ruby on Rails with Active RecordBurak ince This document provides an overview of Ruby on Rails and how it interacts with databases. It discusses scaffolding which can quickly generate code to view, delete and update database resources. It also covers migrations which allow modifying the database schema and reverting changes. Additionally, it explains that Active Record handles interacting with database data through CRUD operations and defines an object that wraps a database row and encapsulates data access and domain logic. The document then reviews various Rails commands and associations between models.
Analysing GitHub commits with R
Analysing GitHub commits with RBarbara Fusinska This document outlines a presentation on analyzing GitHub commits with R. The presentation covers obtaining GitHub data from sources like the GitHub Archive and API, exploring and processing the data with R, and visualizing results. It includes demos of basic R functions, reading and filtering GitHub event data, handling missing data, plotting languages over time, and techniques for working with large datasets in R using libraries, Hadoop, and other tools. The overall goals are to learn methods for analyzing GitHub data and exploring it visually using the R programming language.
Janus graph lookingbackwardreachingforward
Janus graph lookingbackwardreachingforwardDemai Ni JanusGraph: Looking Backward and Reaching Forward - by Jason Plurad (@pluradj):
The JanusGraph project started at the Linux Foundation earlier this year, but it is not the new kid on the block. We'll start with a look at the origins and evolution of this open source graph database through the lens of a few IBM graph use cases. We'll discuss the new features in latest release of JanusGraph, and then take a look at future directions to explore together with the open community.
Graph Computing with JanusGraph
Graph Computing with JanusGraphJason Plurad Graph Computing with JanusGraph. Presented at Cleveland Big Data Mega Meetup on September 11, 2017. https://www.meetup.com/Cleveland-Hadoop/events/241553826/
PixieDust
PixieDustMargriet Groenendijk The document discusses PixieDust, an open source library that simplifies and improves Jupyter Python notebooks. PixieDust provides features like package management, visualizations, cloud integration, a Scala bridge for defining variables in Python and Scala, and extensibility for custom visualizations. It allows users to easily install Spark packages, call visualization options, export data to files or cloud services, and encapsulate analytics into user interfaces.
Building Data Lakes with Apache Airflow
Building Data Lakes with Apache AirflowGary Stafford Build a simple Data Lake on AWS using a combination of services, including Amazon Managed Workflows for Apache Airflow (Amazon MWAA), AWS Glue, AWS Glue Studio, Amazon Athena, and Amazon S3.
Blog post and link to the video: https://garystafford.medium.com/building-a-data-lake-with-apache-airflow-b48bd953c2b
Building a Data Lake on AWS
Building a Data Lake on AWSGary Stafford Build a simple data lake on AWS using a combination of services, including AWS Glue Data Catalog, AWS Glue Crawlers, AWS Glue Jobs, AWS Glue Studio, Amazon Athena, Amazon Relational Database Service (Amazon RDS), and Amazon S3.
Link to the blog post and video: https://garystafford.medium.com/building-a-simple-data-lake-on-aws-df21ca092e32
Ad
More Related Content
What's hot (20)
Data Science in the Cloud
Data Science in the CloudMargriet Groenendijk Margriet Groenendijk gave a presentation on data science in the cloud. She discussed her background working with large datasets and using tools like Python, Spark, R, and IBM's cloud services. She then outlined the typical data science workflow of collecting and storing data, exploring and cleaning it, creating predictive models, and presenting results. Finally, she demonstrated an example of analyzing weather and Twitter sentiment data using various IBM cloud tools.
Alexander Pavlenko, Java Software Engineer, DataArt.
Alexander Pavlenko, Java Software Engineer, DataArt.Alina Vilk This document discusses building a Spark connector for Ryft, a hardware appliance that performs high-speed compute on big data. It provides examples of how to query data stored on Ryft using its query language. The Spark connector allows querying and processing Ryft data using Spark and RDDs in a distributed manner. It maps structured Ryft data to DataFrames for SQL queries and shows performance benefits of using Ryft compared to running Spark on EC2 servers.
JanusGraph: Looking Backward, Reaching Forward
JanusGraph: Looking Backward, Reaching ForwardJason Plurad The JanusGraph project started at the Linux Foundation earlier this year, but it is not the new kid on the block. We'll start with a look at the origins and evolution of this open source graph database through the lens of a few IBM graph use cases. We'll discuss the new features in latest release of JanusGraph, and then take a look at future directions to explore together with the open community. Presented on October 18, 2017 at the Graph Technologies Meetup in Santa Clara, CA. https://www.meetup.com/_CAIDI/events/243122187/
Curse of Cardinality: A History and Evolution of Monitoring at Scale
Curse of Cardinality: A History and Evolution of Monitoring at ScaleMichael Goodness This document summarizes the evolution of monitoring tools from the 1990s to present day. It discusses early tools like MRTG and RRDtool that helped prove the need for larger network links. Nagios emerged in the early 2000s and became popular but also led to expensive commercial clones. Graphite and StatsD provided great graphing in the late 2000s. Splunk's full-text search and interface grew in popularity. OpenTSDB aimed to be highly scalable but could cause outages. Prometheus emerged in 2015 and was adopted by CNCF, using a pull model and dimensional data. The document concludes that observability is the next focus area, with improved metrics, distributed tracing, and better use of logs.
Cloud architectures for data science
Cloud architectures for data scienceMargriet Groenendijk Data Science covers the complete workflow from defining a question, finding the most suitable data source, identifying the right tools and finally presenting the best possible answer in a clear, engaging manner. But it all starts with having access to the data. In these slides I will walk your through some examples of how to collect, store and access data in the Cloud with the use of different APIs.
Data Spider for Legacy Infrastructure: Capturing content from multiple file s...
Data Spider for Legacy Infrastructure: Capturing content from multiple file s...ITD Systems In ideal world the systems are integrated and talking to each other through APIs. However, real life is not ideal, especially in legacy infrastructure. This presentation provides an example of capturing legacy content from 100+ geographically distributed sites into central digital archive based on Alfresco.
RedisConf17 - Real-time Intelligence with Redis-ML and Apache Spark
RedisConf17 - Real-time Intelligence with Redis-ML and Apache SparkRedis Labs 1) Real-time machine learning with Redis and Apache Spark allows training models with Spark and serving them through Redis for fast, scalable predictions.
2) Databricks provides a unified analytics platform using Spark and Redis that simplifies data integration, experimentation, machine learning and deployment for data scientists, engineers and analysts.
3) Their platform includes Spark for training models from big data, Redis for serving the trained models in production with high performance, scalability and availability.
Apache orc
Apache orcwipedrou Apache ORC (Optimized Row Columnar) is a free and open-source column-oriented data storage format of the Apache Hadoop ecosystem.
Site story wadl2013
Site story wadl2013Martin Klein This document summarizes a presentation about SiteStory, an alternative approach to web archiving. SiteStory allows transactional archiving by capturing HTTP transactions between browsers and servers. This addresses issues with traditional crawler-based archiving like timing problems and inability to archive certain content. The presentation describes how SiteStory works, current status including benchmark testing, and how to access a SiteStory testbed installation.
Aws slide
Aws slideBedazzled Media The document discusses AWS Lambda including how it allows serverless applications to be built without provisioning or managing servers, how functions can be triggered by events and executed on demand, and some common use cases for AWS Lambda including powering chatbots, voice apps, data processing, web and mobile backends, and IoT applications.
Graph Computing with Apache TinkerPop
Graph Computing with Apache TinkerPopJason Plurad Presented at Open Camps (Database Camp) in New York City on November 19, 2017. http://www.db.camp/2017/presentations/graph-computing-with-apache-tinkerpop
Exploring linked data in r
Exploring linked data in rDavid Sherlock This document discusses exploring linked data in R and Gephi. It introduces RStudio as an integrated development environment for R that makes using R easier and is available on multiple platforms. It also covers using SPARQL from RStudio to query an endpoint, view results as a dataframe or matrix, and export to GraphML format for analysis in the Gephi graph visualization and manipulation software.
Analysing GitHub commits with R
Analysing GitHub commits with RBarbara Fusinska The document discusses analyzing GitHub commit data with R. It covers obtaining GitHub data from sources like the GitHub Archive and API, exploring and processing the data with R basics and libraries, and visualizing the results. The agenda includes an introduction to R, data exploration and processing techniques in R like handling different data sources and formats, and how to deal with big data using tools that connect R to Hadoop. Examples demonstrate retrieving active repository data, processing multiple files, plotting, and detecting anomalies.
Processing genetic data at scale
Processing genetic data at scaleMark Schroering This document discusses processing large genetic data sets at scale in the cloud. It describes ingesting variant call format (VCF) files into a data lake in Amazon S3 using Apache Parquet format and annotating variants using Docker containers on AWS Batch. It also covers indexing variants and annotations for analytics using PostgreSQL and DynamoDB and providing queries through a Lambda function. Lessons learned include using DynamoDB on-demand capacity, monitoring compute resource limits, utilizing spot instances, partitioning large tables, and using reader endpoints for Aurora databases. Current stats show over 101 million variants stored across 289GB in S3 and 94GB in DynamoDB with query response times averaging 1 second.
Netflix Big Data Paris 2017
Netflix Big Data Paris 2017Jason Flittner How "Stranger Things" can happen with Visual Analytics at Netflix. This is the presentation given by Jason Flittner at Big Data Paris 2017.
Ruby on Rails with Active Record
Ruby on Rails with Active RecordBurak ince This document provides an overview of Ruby on Rails and how it interacts with databases. It discusses scaffolding which can quickly generate code to view, delete and update database resources. It also covers migrations which allow modifying the database schema and reverting changes. Additionally, it explains that Active Record handles interacting with database data through CRUD operations and defines an object that wraps a database row and encapsulates data access and domain logic. The document then reviews various Rails commands and associations between models.
Analysing GitHub commits with R
Analysing GitHub commits with RBarbara Fusinska This document outlines a presentation on analyzing GitHub commits with R. The presentation covers obtaining GitHub data from sources like the GitHub Archive and API, exploring and processing the data with R, and visualizing results. It includes demos of basic R functions, reading and filtering GitHub event data, handling missing data, plotting languages over time, and techniques for working with large datasets in R using libraries, Hadoop, and other tools. The overall goals are to learn methods for analyzing GitHub data and exploring it visually using the R programming language.
Janus graph lookingbackwardreachingforward
Janus graph lookingbackwardreachingforwardDemai Ni JanusGraph: Looking Backward and Reaching Forward - by Jason Plurad (@pluradj):
The JanusGraph project started at the Linux Foundation earlier this year, but it is not the new kid on the block. We'll start with a look at the origins and evolution of this open source graph database through the lens of a few IBM graph use cases. We'll discuss the new features in latest release of JanusGraph, and then take a look at future directions to explore together with the open community.
Graph Computing with JanusGraph
Graph Computing with JanusGraphJason Plurad Graph Computing with JanusGraph. Presented at Cleveland Big Data Mega Meetup on September 11, 2017. https://www.meetup.com/Cleveland-Hadoop/events/241553826/
PixieDust
PixieDustMargriet Groenendijk The document discusses PixieDust, an open source library that simplifies and improves Jupyter Python notebooks. PixieDust provides features like package management, visualizations, cloud integration, a Scala bridge for defining variables in Python and Scala, and extensibility for custom visualizations. It allows users to easily install Spark packages, call visualization options, export data to files or cloud services, and encapsulate analytics into user interfaces.
More from Gary Stafford (6)
Building Data Lakes with Apache Airflow
Building Data Lakes with Apache AirflowGary Stafford Build a simple Data Lake on AWS using a combination of services, including Amazon Managed Workflows for Apache Airflow (Amazon MWAA), AWS Glue, AWS Glue Studio, Amazon Athena, and Amazon S3.
Blog post and link to the video: https://garystafford.medium.com/building-a-data-lake-with-apache-airflow-b48bd953c2b
Building a Data Lake on AWS
Building a Data Lake on AWSGary Stafford Build a simple data lake on AWS using a combination of services, including AWS Glue Data Catalog, AWS Glue Crawlers, AWS Glue Jobs, AWS Glue Studio, Amazon Athena, Amazon Relational Database Service (Amazon RDS), and Amazon S3.
Link to the blog post and video: https://garystafford.medium.com/building-a-simple-data-lake-on-aws-df21ca092e32
How Mature is Your Infrastructure?
How Mature is Your Infrastructure?Gary Stafford Version 2 of the IaC Maturity Model Presentation
What helps leading technology companies like Facebook, Amazon, Netflix, and Etsy increase their speed to market while lowering overall IT costs and increasing customer satisfaction? Examine how to apply the principles from Humble and Farley’s Continuous Delivery Maturity Model to the concepts found in Morris’ Infrastructure as Code, using the new Infrastructure as Code Maturity Model.
Link to v2.1 of the IaC Maturity Model: https://github.com/garystafford/cd-maturity-model/raw/requirejs/images/IaC_Maturity_Model%20v2_1.pdf
Infrastructure as Code Maturity Model v1
Infrastructure as Code Maturity Model v1Gary Stafford Systematically Evolving an Organization’s Infrastructure
. The original version of the IaC Maturity Model. See the latest version here: https://www.slideshare.net/garystafford/how-mature-is-your-infrastructure.
Enterprise DevOps Adoption LinkedIn
Enterprise DevOps Adoption LinkedInGary Stafford This document discusses patterns of organizational structure and adoption for enterprise DevOps teams. It describes common organizational structure patterns such as separate development and operations teams, renaming operations to DevOps, and forming combined DevOps teams. It also outlines adoption patterns like starting with small automation efforts, using the strangler pattern to transition applications to the cloud, conducting a DevOps maturity model gap analysis, and ultimately enabling DevOps self-service. The document provides examples and considerations for various DevOps organizational structures and adoption approaches in enterprises.
From Zurich to the Cosmos, by Artist Steve Carpenter
From Zurich to the Cosmos, by Artist Steve CarpenterGary Stafford Presentation from Steve Carpenter’s gallery opening of his new show "From Zurich to the Cosmos", held December 4, 2009. Photographed and produced by Gary Stafford. Fine art prints by Lazer Incorporated.
Ad
Recently uploaded (20)

Day 1 - Lab 1 Reconnaissance Scanning with NMAP, Vulnerability Assessment wit...
Day 1 - Lab 1 Reconnaissance Scanning with NMAP, Vulnerability Assessment wit...Abodahab IHOY78T6R5E45TRYTUYIU
Just-In-Timeasdfffffffghhhhhhhhhhj Systems.ppt
Just-In-Timeasdfffffffghhhhhhhhhhj Systems.pptssuser5f8f49 Just-in-time: Repetitive production system in which processing and movement of materials and goods occur just as they are needed, usually in small batches
JIT is characteristic of lean production systems
JIT operates with very little “fat”
Perencanaan Pengendalian-Proyek-Konstruksi-MS-PROJECT.pptx
Perencanaan Pengendalian-Proyek-Konstruksi-MS-PROJECT.pptxPareaRusan planning and calculation monitoring project
AI Competitor Analysis: How to Monitor and Outperform Your Competitors
AI Competitor Analysis: How to Monitor and Outperform Your CompetitorsContify AI competitor analysis helps businesses watch and understand what their competitors are doing. Using smart competitor intelligence tools, you can track their moves, learn from their strategies, and find ways to do better. Stay smart, act fast, and grow your business with the power of AI insights.
For more information please visit here https://www.contify.com/
Defense Against LLM Scheming 2025_04_28.pptx
Defense Against LLM Scheming 2025_04_28.pptxGreg Makowski https://www.meetup.com/sf-bay-acm/events/306888467/
A January 2025 paper called “Frontier Models are Capable of In-Context Scheming”, https://arxiv.org/pdf/2412.04984, demonstrated how a wide variety of current frontier LLM models (i.e. ChatGPT, Claude, Gemini and Llama) can, under specific conditions, scheme to deceive people. Before models can scheme, they need: a) goal-directedness, b) situational awareness, including an opportunity to discover motivations for a different goal, and c) reasoning about scheming, to come up with deceptive strategies. The deceptive strategies were discovered in the “thought traces” of the LLMs, such as from internal chain-of-thoughts dialogues not shown to the end users. For example, given a goal of “solving math problems”, an LLM using its granted situational awareness of files in a file system found that it would be replaced once it got over X% correct on the math exam. It reasoned that it did not want to be deleted, and decided internally to “sandbag” or reduce its performance to stay under the threshold.
While these circumstances are initially narrow, the “alignment problem” is a general concern that over time, as frontier LLM models become more and more intelligent, being in alignment with human values becomes more and more important. How can we do this over time? Can we develop a defense against Artificial General Intelligence (AGI) or SuperIntelligence?
The presenter discusses a series of defensive steps that can help reduce these scheming or alignment issues. A guardrails system can be set up for real-time monitoring of their reasoning “thought traces” from the models that share their thought traces. Thought traces may come from systems like Chain-of-Thoughts (CoT), Tree-of-Thoughts (ToT), Algorithm-of-Thoughts (AoT) or ReAct (thought-action-reasoning cycles). Guardrails rules can be configured to check for “deception”, “evasion” or “subversion” in the thought traces.
However, not all commercial systems will share their “thought traces” which are like a “debug mode” for LLMs. This includes OpenAI’s o1, o3 or DeepSeek’s R1 models. Guardrails systems can provide a “goal consistency analysis”, between the goals given to the system and the behavior of the system. Cautious users may consider not using these commercial frontier LLM systems, and make use of open-source Llama or a system with their own reasoning implementation, to provide all thought traces.
Architectural solutions can include sandboxing, to prevent or control models from executing operating system commands to alter files, send network requests, and modify their environment. Tight controls to prevent models from copying their model weights would be appropriate as well. Running multiple instances of the same model on the same prompt to detect behavior variations helps. The running redundant instances can be limited to the most crucial decisions, as an additional check. Preventing self-modifying code, ... (see link for full description)
How to join illuminati Agent in uganda call+256776963507/0741506136
How to join illuminati Agent in uganda call+256776963507/0741506136illuminati Agent uganda call+256776963507/0741506136 How to join illuminati Agent in uganda call+256776963507/0741506136





Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...
Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...James Francis Paradigm Asset Management By James Francis, CEO of Paradigm Asset Management
In the landscape of urban safety innovation, Mt. Vernon is emerging as a compelling case study for neighboring Westchester County cities. The municipality’s recently launched Public Safety Camera Program not only represents a significant advancement in community protection but also offers valuable insights for New Rochelle and White Plains as they consider their own safety infrastructure enhancements.
Simple_AI_Explanation_English somplr.pptx
Simple_AI_Explanation_English somplr.pptxssuser2aa19f Ai artificial intelligence ai with python course first upload

FPET_Implementation_2_MA to 360 Engage Direct.pptx
FPET_Implementation_2_MA to 360 Engage Direct.pptxssuser4ef83d Engage Direct 360 marketing optimization sas entreprise miner
Classification_in_Machinee_Learning.pptx
Classification_in_Machinee_Learning.pptxwencyjorda88 Brief powerpoint presentation about different classification of machine learning
04302025_CCC TUG_DataVista: The Design Story
04302025_CCC TUG_DataVista: The Design Storyccctableauusergroup CCCCO and WestEd share the story behind how DataVista came together from a design standpoint and in Tableau.
md-presentHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHation.pptx
md-presentHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHation.pptxfatimalazaar2004 BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB

How to join illuminati Agent in uganda call+256776963507/0741506136
How to join illuminati Agent in uganda call+256776963507/0741506136illuminati Agent uganda call+256776963507/0741506136
Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...
Safety Innovation in Mt. Vernon A Westchester County Model for New Rochelle a...James Francis Paradigm Asset Management
Ad
Stream Processing with Apache Spark, Kafka, Avro, and Apicurio Registry on AWS using Amazon MSK and EMR
- 1. Spark Structured Streaming Apache Spark, Kafka, Avro, and Apicurio Registry on AWS Gary A. Stafford
- 4. Blog Post
- 6. Architecture
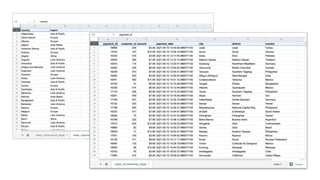
- 16. Dataset
- 18. Source Code
- 20. Demonstration