Twitter with hadoop for oow
Download as PPTX, PDF6 likes1,530 views

"Analyzing Twitter Data with Hadoop - Live Demo", presented at Oracle Open World 2014. The repository for the slides is in https://github.com/cloudera/cdh-twitter-example















![What is JSON?
{
"retweeted_status": {
"contributors": null,
"text": "#Crowdsourcing – drivers already generate traffic data for your smartphone to suggest
alternative routes when a road is clogged. #bigdata",
"retweeted": false,
"entities": {
"hashtags": [
{
"text": "Crowdsourcing",
"indices": [0, 14]
},
{
"text": "bigdata",
"indices": [129,137]
}
],
"user_mentions": []
}
}
}
16 ©2012 Cloudera, Inc.](https://image.slidesharecdn.com/twitterwithhadoopforoow-141005111104-conversion-gate01/85/Twitter-with-hadoop-for-oow-16-320.jpg)

























































Ad
More Related Content
What's hot (20)
Viewers also liked (11)









Ad
Similar to Twitter with hadoop for oow (20)




















Ad
More from Gwen (Chen) Shapira (18)


















Twitter with hadoop for oow
- 1. 1 Analyzing Twitter Data with Hadoop Gwen Shapira, Software Engineer @Gwenshap ©2012 Cloudera, Inc.
- 2. IOUG SIG Meetings at OpenWorld All meetings located in Moscone South - Room 208 Monday, September 29 Exadata SIG: 2:00 p.m. - 3:00 p.m. BIWA SIG: 5:00 p.m. – 6:00 p.m. Tuesday, September 30 Internet of Things SIG: 11:00 a.m. - 12:00 p.m. Storage SIG: 4:00 p.m. - 5:00 p.m. SPARC/Solaris SIG: 5:00 p.m. - 6:00 p.m. Wednesday, October 1 Oracle Enterprise Manager SIG: 8:00 a.m. - 9:00 a.m. Big Data SIG: 10:30 a.m. - 11:30 a.m. Oracle 12c SIG: 2:00 p.m. – 3:00 p.m. Oracle Spatial and Graph SIG: 4:00 p.m. (*OTN lounge)
- 3. • Save more than $1,000 on education offerings like pre-conference workshops • Access the brand-new, specialized IOUG Strategic Leadership Program • Priority access to the hands-on labs with Oracle ACE support • Advance access to supplemental session material and presentations • Special IOUG activities with no "ante in" needed - evening networking opportunities and more COLLABORATE 15 – IOUG Forum April 12-16, 2015 Mandalay Bay Resort and Casino Las Vegas, NV The IOUG Forum Advantage www.collaborate.ioug.org Follow us on Twitter at @IOUG or via the conference hashtag #C15LV!
- 4. I have 15 years of experience in moving data around ©2014 Cloudera, Inc. All rights reserved.
- 5. • Oracle ACE Director • Member of Oak Table • Blogger • Presenter – Hotsos, IOUG, OOW, OSCON • NoCOUG board • Contributor to Apache Oozie, Sqoop, Kafka • Author – Hadoop Application Architectures ©2014 Cloudera, Inc. All rights reserved. In my spare time…
- 6. Analyzing Twitter Data with Hadoop BUILDING AN HADOOP APPLICATION 6 ©2012 Cloudera, Inc.
- 7. 7
- 8. Hive Level Architecture Hive + Oozie Data Source Flume HDFS 8 ©2012 Cloudera, Inc. Impala / Oracle
- 9. Analyzing Twitter Data with Hadoop AN EXAMPLE USE CASE 9 ©2012 Cloudera, Inc.
- 10. Analyzing Twitter • Social media popular with marketing teams • Twitter is an effective tool for promotion • Which twitter user gets the most retweets? • Who is influential in our industry? • Which topics are trending? • “You mentioned Oracle, please take this survey” 10 ©2012 Cloudera, Inc.
- 11. Analyzing Twitter Data with Hadoop HOW DO WE ANSWER THESE QUESTIONS? 11 ©2012 Cloudera, Inc.
- 12. Techniques • Bring Data with Flume • Complex data • Deeply nested • Variable schema • Clean, Standardize, Partition, etc • SQL • Filtering • Aggregation • Sorting 12
- 13. Analyzing Twitter Data with Hadoop FLUME 13
- 14. Flume Agent design 14
- 15. In our case… • Twitter source • Pulls JSON format files from twitter • Memory Channel • HDFS Sink – directory per hour 15
- 16. What is JSON? { "retweeted_status": { "contributors": null, "text": "#Crowdsourcing – drivers already generate traffic data for your smartphone to suggest alternative routes when a road is clogged. #bigdata", "retweeted": false, "entities": { "hashtags": [ { "text": "Crowdsourcing", "indices": [0, 14] }, { "text": "bigdata", "indices": [129,137] } ], "user_mentions": [] } } } 16 ©2012 Cloudera, Inc.
- 17. But Wait! There’s More! • Many sources – directory, files, log4j, net, JMS • Interceptors – process data in flight • Selectors – choose which sink • Many channels – Memory, file • Many sinks – HDFS, Hbase, Solr 17
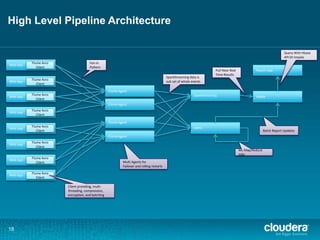
- 18. High Level Pipeline Architecture Web App 18 Flume Avro Client Web App Flume Avro Client Web App Flume Avro Client Web App Flume Avro Client Web App Flume Avro Client Web App Flume Avro Client Web App Flume Avro Client Web App Flume Avro Client Flume Agent Flume Agent Flume Agent Flume Agent SparkStreaming HBase HDFS Report App Fan-in Pattern Multi Agents for Failover and rolling restarts SparkStreaming data is sub set of whole events ML Map/Reduce Jobs Batch Report Updates Pull Near Real Time Results Query With Hbase API Or Impala Client providing, multi-threading, compression, encryption, and batching
- 19. TwitterAgent.sources = Twitter TwitterAgent.channels = MemChannel TwitterAgent.sinks = HDFS TwitterAgent.sources.Twitter.type = com.cloudera.flume.source.TwitterSource TwitterAgent.sources.Twitter.channels = MemChannel TwitterAgent.sources.Twitter.consumerKey = TwitterAgent.sources.Twitter.consumerSecret = TwitterAgent.sources.Twitter.accessToken = TwitterAgent.sources.Twitter.accessTokenSecret = TwitterAgent.sources.Twitter.keywords = hadoop, big data, flume, sqoop, oracle, oow TwitterAgent.sinks.HDFS.channel = MemChannel TwitterAgent.sinks.HDFS.type = hdfs TwitterAgent.sinks.HDFS.hdfs.path = hdfs://quickstart :8020/user/flume/tweets/%Y/%m/%d/%H/ TwitterAgent.sinks.HDFS.serializer = text TwitterAgent.channels.MemChannel.type = memory 19 Configuration
- 20. Analyzing Twitter Data with Hadoop FLUME DEMO 20 ©2012 Cloudera, Inc.
- 21. Analyzing Twitter Data with Hadoop HIVE 21 ©2012 Cloudera, Inc.
- 22. What is Hive? • Created at Facebook • HiveQL • SQL like interface • Hive interpreter converts HiveQL to MapReduce code • Returns results to the client 22 ©2012 Cloudera, Inc.
- 23. Hive Details • Metastore contains table definitions • Stored in a relational database • Basically a data dictionary • SerDes parse data • and converts to table/column structure • SerDe: • CSV, XML, JSON, Avro, Parquet, OCR files • Or write your own (We created one for CopyBook) 23
- 24. Complex Data SELECT t.retweet_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name AS retweet_screen_name, retweeted_status.text, max(retweeted_status.retweet_count) AS retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweet_screen_name ORDER BY total_retweets DESC LIMIT 10; 24 ©2012 Cloudera, Inc.
- 25. Analyzing Twitter Data with Hadoop HIVE DEMO 25 ©2012 Cloudera, Inc.
- 26. Analyzing Twitter Data with Hadoop IT’S A TRAP 26 ©2012 Cloudera, Inc.
- 27. Not a Database RDBMS Hive Impala Language Generally >= SQL-92 Subset of SQL-92 plus Hive specific extensions 27 ©2012 Cloudera, Inc. Subset of SQL- 92 Update Capabilities INSERT, UPDATE, DELETE Bulk INSERT, UPDATE, DELETE Insert, truncate Transactions Yes Yes No Latency Sub-second Minutes Sub-second Indexes Yes Yes No Data size Few Terabytes Petabytes Lots of Terabytes
- 28. Analyzing Twitter Data with Hadoop DATA FORMATS 28
- 29. I don’t like our data • Lots of small files • JSON – requires parsing • Can’t compress • Sensitive to changes 29
- 30. I’d rather use Avro • Few large files containing records • Schema in file • Schema evolution • Can compress • Well supported in Hadoop • Clients in other languages 30
- 31. Lets convert • Create table AVRO_TWEETS • Insert into Avro_tweets select …. From tweets 31
- 32. Analyzing Twitter Data with Hadoop IMPALA ASIDE 32 ©2012 Cloudera, Inc.
- 33. Cloudera Impala 33 Real-Time Query for Data Stored in Hadoop. Supports Hive SQL 4-30X faster than Hive over MapReduce Supports multiple storage engines & file formats Uses existing drivers, integrates with existing metastore, works with leading BI tools Flexible, cost-effective, no lock-in Deploy & operate with Cloudera Enterprise RTQ ©2012 Cloudera, Inc.
- 34. Benefits of Cloudera Impala 34 Real-Time Query for Data Stored in Hadoop • Real-time queries run directly on source data • No ETL delays • No jumping between data silos • No double storage with EDW/RDBMS • Unlock analysis on more data • No need to create and maintain complex ETL between systems • No need to preplan schemas • All data available for interactive queries • No loss of fidelity from fixed data schemas • Single metadata store from origination through analysis • No need to hunt through multiple data silos ©2012 Cloudera, Inc.
- 35. Cloudera Impala Details Query Planner Query Coordinator Query Exec Engine Query Planner Query Coordinator State Store HDFS NN HDFS DN HDFS DN HBase HBase SQL App ODBC 35 ©2012 Cloudera, Inc. Query Planner Query Coordinator Query Exec Engine HDFS DN Query Exec Engine HBase Fully MPP Distributed Local Direct Reads Hive Metastore YARN Common Hive SQL and interface Unified metadata and scheduler Low-latency scheduler and cache (low-impact failures)
- 36. LOAD DATA TO ORACLE
- 37. Oracle Connectors for Hadoop • Oracle Loader for Hadoop • Oracle SQL Connector for Hadoop • BigData SQL
- 38. Oracle Loader for Hadoop • Load data from Hadoop into Oracle • Map-Reduce job inside Hadoop • Converts data types, partitions and sorts • Direct path loads • Reduces CPU utilization on database • Supports Avro and compression
- 39. Oracle SQL Connector for Hadoop • Run a Java app • Creates an external table • Runs MapReduce when external table is queries • Can use Hive Metastore for schema • Optimized for parallel queries • Supports Avro and compression
- 40. Big Data SQL • Also external table • Can also use Hive metastore for schema • But …. NO MapReduce • Instead – an agent will do SMART SCANS • Bloom filters • Storage indexes • Filters • Supports any Hadoop data format 40
- 41. Analyzing Twitter Data with Hadoop PUTTING IT ALL TOGETHER 41 ©2012 Cloudera, Inc.
- 42. Hive Level Architecture Hive + Oozie Data Source Flume HDFS 42 ©2012 Cloudera, Inc. Impala / Oracle
- 43. What next? • Download Hadoop! • CDH available at www.cloudera.com • Cloudera provides pre-loaded VMs • https://ccp.cloudera.com/display/SUPPORT/Cloudera+Ma nager+Free+Edition+Demo+VM • Clone the source repo • https://github.com/cloudera/cdh-twitter-example
- 44. 44 ©2012 Cloudera, Inc.