Boosting big data with apache spark
Download as PPTX, PDF1 like841 views

This document provides an overview of Apache Spark presented by Mathias Lavaert of InfoFarm. The presentation introduces Spark as a fast and general engine for big data processing, and covers Spark's core concepts including RDDs, transformations and actions. It also discusses Spark SQL, MLLib for machine learning, and Spark Streaming. The presentation demonstrates Spark's capabilities and notes how Spark can easily run on Amazon EC2. It promotes Spark as a modern full-stack framework suitable for both batch and real-time big data applications.







































![Veldkant 33A, Kontich ● info@infofarm.be ● www.infofarm.be
Getting started with Spark SQL
● Create an instance of SQLContext or HiveContext
○ Entry point for all SQL functionality
○ Wraps/extends existing Spark Context (Decorator Pattern)
● If you’re using the shell a SQLContext has been created for you
val sparkContext = new SparkContext("local[4]", "SQL")
val sqlContext = new SQLContext(sparkContext)](https://image.slidesharecdn.com/boostingbigdatawithapachespark-150430020854-conversion-gate02/85/Boosting-big-data-with-apache-spark-41-320.jpg)

















































Ad
More Related Content
What's hot (20)
Viewers also liked (8)






Ad
Similar to Boosting big data with apache spark (20)




















Ad
Recently uploaded (20)



















![Download Wondershare Filmora Crack [2025] With Latest](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-howkgsareshapingthefutureofgenerativeaiatawssummitlondonapril2024-240426125209-2d9db05d-250419-250428115407-a04afffa-thumbnail.jpg?width=560&fit=bounds)
Boosting big data with apache spark
- 1. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Data Science Company Boosting Big Data with Apache Spark Mathias Lavaert April 2015
- 2. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company About Infofarm
- 3. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Data Science Big Data Identifying, extracting and using data of all types and origins; exploring, correlating and using it in new and innovative ways in order to extract meaning and business value from it.
- 4. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be
- 5. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Java PHP E-Commerce Mobile Web Development
- 6. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be
- 7. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be About me Mathias Lavaert Big Data Developer at InfoFarm since May, 2014 Proud citizen of West-Flanders Outdoor enthusiast
- 8. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Agenda • What is Apache Spark? • An in-depth overview – Spark Core and Resilient Distributed Data – Unified access to structured data with Spark SQL – Machine Learning with Spark MLLib – Scalable streaming applications Spark Streaming • Q&A • Wrap-up & lunch
- 9. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company What is Apache Spark?
- 10. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be “Apache Spark is a fast and general engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing”
- 11. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be History • Created by Matei Zaharia at UC Berkeley in 2009 • Based on 2007 Microsoft Dryad paper • Donated in 2013 to Apache Software Foundation • 465 contributors in 2014 making it the most active Apache Project • Currently supported by Databricks, a company founded by the creators of Apache Spark
- 12. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Target users ● Data Scientists ○ Data exploration and data modelling using interactive shells ○ Machine Learning ○ Ad Hoc analysis to answer business questions or discovering new insights ● Engineers ○ Fault-tolerant production data applications ○ ‘Productizing’ the work of the data scientist ○ Integration with business application
- 13. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Where to situate Apache Spark?
- 14. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Differences with MapReduce • Faster by minimizing IO and trying to use the memory as much as possible • Unified libraries • Huge community effort, very fast development pace. • Ships with higher level tools included
- 15. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Daytona GraySort Contest
- 16. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Differences with Hive, Pig, others... • One integrated framework that suits a wide range of problems • No need for a workflow application like Oozie • Only 1 language/framework to learn
- 17. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Explosion of Specialized Systems
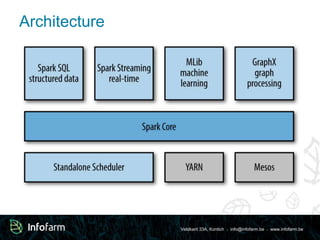
- 18. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Architecture
- 19. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Advantages of unified libraries Advancements in higher-level libraries are pushed down into core and vice-versa ● Spark Core ○ Highly-optimized, low overhead, network-saturating shuffle ● Spark Streaming ○ Garbage collection, memory management, cleanup improvements ● Spark GraphX ○ IndexedRDD for random access within a partition vs scanning entire partition ● Spark MLLib ○ Statistics (Correlations, sampling, heuristics)
- 20. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Supported languages
- 21. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Difference between Java and Scala
- 22. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Cluster Resource Managers ● Spark Standalone ○ Suitable for a lot of production workloads ○ Only suitable for Spark workloads ● YARN ○ Allows hierarchies of resources ○ Kerberos integration ○ Multiple workloads from different execution frameworks ■ Hive, Pig, Spark, MapReduce, Cascading, etc… ● Mesos ○ Similar to YARN, but allows elastic allocation ○ Coarse-grained ■ Single, long-running Mesos tasks runs Spark mini tasks ○ Fine-grained ■ New Mesos task for each Spark task ■ Higher overhead, not good for long-running Spark jobs (Streaming)
- 23. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Storage Layers for Spark Spark can create distributed datasets from: ● Any file stored in the Hadoop distributed filesystem (HDFS) ● Any storage system supported by the Hadoop APIs ○ Local filesystem ○ S3 ○ Cassandra ○ Hive ○ HBase Note that Apache Spark doesn’t require Hadoop, but it has support for storage systems implementing the Hadoop APIs.
- 24. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Short introduction to functional programming
- 25. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be What is functional programming? A programming paradigm where the basic unit of abstraction is the function
- 26. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Basic concepts ● Higher-order functions ○ Are functions that can either take other functions as arguments ○ or return functions as a result of a function ● Pure functions ○ Purely functional expressions have no side effects ● Recursion ○ Iteration in functional languages is usually accomplished via recursion. ● Immutable data structures
- 27. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Small example with a functional language: Scala
- 28. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Introduction to Spark concepts
- 29. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Resilient Distributed Datasets (RDDs) ● Core Spark abstraction ● Immutable distributed collection of objects ● Split into multiple partitions ● May be computed on different nodes of the cluster ● Can contain any type of Scala, Java or Python object including user-defined classes “Distributed Scala collections”
- 30. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Driver and context ● Driver ○ Shell ○ Standalone program ● Spark Context represents a connection to a computing cluster
- 31. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be RDD Operations ● Transformations ○ map ○ filter ○ flatMap ○ sample ○ groupByKey ○ reduceByKey ○ union ○ join ○ sort ● Actions ○ count ○ collect ○ reduce ○ lookup ○ save ● Transformations are lazy ● Actions force the computation of transformations
- 32. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Narrow vs wide dependencies
- 33. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Demo using only core operations
- 34. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Specialized operations for specific types of RDDs
- 35. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Specialized operations for Key/Value pairs ● reduceByKey ● groupByKey ● combineByKey ● mapValues ● flatMapValues ● keys ● sortByKey ● subtractByKey ● join ● rightOuterJoin ● leftOuterJoin ● cogroup
- 36. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Specialized operations for numeric RDDs ● count ● mean ● sum ● max ● min ● variance ● sampleVariance ● stdev ● sampleStDev
- 37. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be And many more... ● HadoopRDD ● FilteredRDD ● MappedRDD ● PairRDD ● ShuffledRDD ● UnionRDD ● DoubleRDD ● JdbcRDD ● JsonRDD ● SchemaRDD ● VertexRDD ● EdgeRDD ● CassandraRDD ● GeoRDD ● EsSpark (Elastic Search
- 38. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Spark SQL
- 39. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Spark SQL Overview ● Newest component of Spark ● Tightly integrated to work with structured data ○ Tables with rows and columns ● Transform RDDs using SQL ● Data source integration: Hive, Parquet, JSON and more… ● Optimizes execution plan
- 40. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Differences with Spark Core ● Spark + RDDs ○ Functional transformations on collections of objects ● SQL + SchemaRDDs ○ Declarative transformations on collections of tuples
- 41. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Getting started with Spark SQL ● Create an instance of SQLContext or HiveContext ○ Entry point for all SQL functionality ○ Wraps/extends existing Spark Context (Decorator Pattern) ● If you’re using the shell a SQLContext has been created for you val sparkContext = new SparkContext("local[4]", "SQL") val sqlContext = new SQLContext(sparkContext)
- 42. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Language Integrated UDFs ● Ability to write custom SQL-functions in one of the languages that is supported by Spark ● Another example on how Spark simplifies the big data stack
- 43. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Parquet compatibility Native support for reading data stored in Parquet: ● Columnar storage avoids reading unneeded data ● SchemaRDDs can be written to Parquet while preserving the schema ● Convert other slower formats like JSON to Parquet for repeated querying.
- 44. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Demo: Spark SQL
- 45. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Spark MLLib
- 46. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Machine Learning Algorithms ● Supervised ○ Prediction: Train a model with existing data + label, predict label for new data ■ Classification (categorical) ■ Regression (continuous numeric) ○ Recommendation: recommend to similar users ■ User -> user, item -> item, user -> item similarity ● Unsupervised ○ Clustering: Find natural clusters in data based on similarities
- 47. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Algorithms provided by Spark ● Classification and regression ○ Linear models (SVMs, logistic regression, linear regression) ○ Naive Bayes ○ Decision trees ○ Ensembles of trees (Random Forests and Gradient-Boosted trees) ○ Isotonic regression ● Recommendations ○ Alternating Least Squares (ALS) ○ FP-growth ● Clustering ○ K-Means ○ Gaussian mixture ○ Power Iteration clustering ○ Latent Dirichlet allocation ○ Streaming k-means ● Dimensionality reduction ○ Singular value decomposition (SVD) ○ Principal component analysis (PCA)
- 48. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Tools provided by Spark ● Tools for basic statistics including ○ Summary statistics ○ Correlations ○ Sampling ○ Hypothesis testing ○ Random data generation ● Tools for feature extraction and transformation ○ Extracting features out of text ○ Uniform Vector format to store features ● Tools to build Machine Learning Pipelines using Spark SQL
- 49. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Why choose for MLLib? ● One of the best documented machine learning libraries available for the JVM ● Simple API, constructs are the same for different algorithms ● Well integrated with other Spark-components
- 50. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Demo: Spark MLLib
- 51. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Spark Streaming
- 52. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Spark Streaming Overview ● Build around the concept of DStreams or discretized streams ● Long-running Spark application ● Micro-batch architecture ● Supports Flume, Kafka, Twitter, Amazon Kinesis, Socket, File…
- 53. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be DStreams ● A sequence of RDDs ● Stateless transformations ● Stateful transformations ● Checkpointing
- 54. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Spark Streaming Use Cases ● ETL and enrichment of streaming data on ingestion ● Lambda Architecture ● Operational dashboards
- 55. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Demo: Spark Streaming
- 56. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Spark on Amazon EC2
- 57. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Apache Spark runs easily on Amazon EC2 Apache Spark comes with a script to launch Spark clusters on Amazon EC2. So there is no need to invest in a cluster of servers... Furthermore it has support for multiple Amazon components. ● Spark can read files from Amazon S3 ● Spark Streaming can easily be integrated with Amazon Kinesis
- 58. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Conclusion
- 59. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.be Why choose for Apache Spark? ● Modern integrated full-stack Big Data framework ● Suitable for both batch and (near) real time applications ● Well supported by a very large community ● The Big Data landscape seems to shift to Apache Spark
- 60. Veldkant 33A, Kontich ● [email protected] ● www.infofarm.beData Science Company Questions?