mongodb tutorial
15 likes2,312 views

mongodb 소개 및 basic tutorial 자료입니다. - 데이터베이스의 진화 - nosql의 등장배경 및 역할 - mycq 개발 경험 - mongodb 기능 및 구조



































![실시간데이터스트림분석
window
queue1 as win1[size=5sec, slide=5sec]
select * from win1
where string like 'hello%' and (col2=1000 or col3=5000)
•MyCQ Server
•Esper
MyCQL
데이터분석](https://image.slidesharecdn.com/mongodb-141203013121-conversion-gate01/85/mongodb-tutorial-36-320.jpg)

















![JSON
•JSON(JavaScript Object Notation)
–Standard ECMA-262 3rd Edition -December 1999
object
{} {members}
members
pairpair,members
pair
string:value
array
[] [elements]
elements
valuevalue,elements
value
stringnumberobjectarray true,falsenull
Grammar
Example
Document](https://image.slidesharecdn.com/mongodb-141203013121-conversion-gate01/85/mongodb-tutorial-55-320.jpg)








![Index
•TTL Index
–날짜필드를가진문서에, 일정시간지나면데이터를삭제하도록인덱싱
•Geospatial Index
–2차원인덱싱
–{loc:[x,y]}
–db.places.ensureIndex( { loc: "2d" } )
–검색
•4각형: db.collection.find( { location: { $near: [100,100] } } );
•원형: db.collection.find( { location: { $within: { $center: [ center, radius } } } );
•다각형: db.collection.find( { location: { $within: { $box: [[100,120], [100,100], [120,100], [240,200]] } } } );](https://image.slidesharecdn.com/mongodb-141203013121-conversion-gate01/85/mongodb-tutorial-64-320.jpg)













































![[db tech showcase Tokyo 2017] C23: Lessons from SQLite4 by SQLite.org - Richa...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-sqlite4-20170906-170911071410-thumbnail.jpg?width=560&fit=bounds)





![[db tech showcase Tokyo 2017] A11: SQLite - The most used yet least appreciat...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-keynote-20170905-170911071000-thumbnail.jpg?width=560&fit=bounds)





















Ad
More Related Content
What's hot (20)
Similar to mongodb tutorial (20)


















Ad
More from Jaehong Park (10)










Ad
Recently uploaded (20)




















mongodb tutorial
- 2. Big Data 처리기술 NoSQL MongoDB
- 3. 사례시스템
- 4. 로그인프라
- 5. 3G망패킷분석
- 7. 항공기블랙박스
- 8. CCTV Person of Interest
- 9. 전파분석
- 10. Glory FS 관리도구
- 11. 오픈스택관리도구
- 13. 빅데이터처리기술개요
- 14. 데이터처리기술의진화 SQL에의존하지않는기술의발전및성공사례증가 빅서비스> 다양한데이터처리요구(데이터구조, 량, 속도)증가> 상용DB는고비용> 입맛에맞는기술이없음> 직접만들어사용
- 16. Scale Up vs. Scale Out 128cores(4core*32) 4 TB Memory 분산처리 20억원 1억원 vs. HP Superdome 2 (2010) (4core, 128G) * 32
- 17. NoSQL(No Join, No Transaction) 2PC? OK 네트워크로컴퓨터연결//복잡함 컴퓨터대수가많다보니, 고장확율높아짐. 이런상황에서TX보장및JOIN기능제공하면서성능내기쉽지않음. TRANSACTION (X) // Atomic Operation JOIN (X) // Embedded Document로해소 분산처리
- 18. NoSQL기술의시장은? 상용(오픈) RDBMS 상용(오픈) RDBMS NoSQL SQL (ex, Oracle): 현재가치가큰데이터 NoSQL: 미래가치가큰데이터 •대용량데이터처리비용감소 •전체데이터처리시장확대 RDBMS > NoSQL로전환 시장
- 19. 2014.2 2013
- 21. 빅데이터처리기술
- 22. 빅데이터처리플랫폼구조 빅데이터처리플랫폼 수집 플랫폼관리 분석서비스(GUI) 연동서비스(Open API) 저장 분석
- 23. 빅데이터처리플랫폼구조 데이터수집 •다양한데이터타입수집방법제공 •정형, 반정형, 비정형 •다양한데이터소스수집방법제공 •파일, DB, 스트림 데이터저장소 •대용량분산파일시스템 •HDFS, GloryFS, GridFS •대용량분산DB (NoSQL) •MongoDB 등 •대용량텍스트검색엔진 •Elastic Search 등 데이터분석프레임워크 •배치분석방법제공: 파일기반배치분석:HadoopM/R, DB 기반배치분석:MongoDB M/R •대화형분석방법제공: Hbase, Mongo 등 •머신러닝분석방법제공: Mahout등 •Complex Event Processing 분석방법제공: Esper, MyCQL등 플랫폼관리서비스 •클라우드가상머신기반자원할당 •인프라상태모니터링(노드, 프로세스, 로그등) •사용자인증및관리 •인프라설정관리 •빌링 분석서비스(GUI) •배치분석알고리즘관리및수행 •대화형분석방법제공 •워크플로우관리 •데이터업/다운로드방법제공 •분석결과시각화제공 연동서비스(Open API, 3rdParty 연동) •인증 •서비스검색 •서비스연동, 기능조회등 •데이터업/다운로드 •외부API 연동
- 24. 데이터소스 •파일 •(스트림)데이터 •DB •연동API •… 수집기 •데이터변환 •데이터변환규칙(XML, JSON, DB 등) •데이터필터링, Smoothing, Shedding, Sampling •데이터라우팅& 적재 •파일시스템또는데이터베이스에데이터적재 •데이터압축적재 •분산병렬적재기법 •적재신뢰성보장유무 •데이터보관주기 •용량기준데이터삭제후적재 •보관주기기준과거데이터삭제 •이벤트처리 •데이터적재전특정상황발생감지및전달 •방식: 에이젼트, API제공or 호출 •실행위치 •데이터가생산되는장비 •수집전용장비 저장소 데이터수집
- 25. •분산파일시스템 •분산DB(NoSQL) 시스템 •분산텍스트검색엔진시스템 •파티셔닝(샤딩) •복제 •로드밸런싱 •데이터마이그레이션 •유연성 •신뢰성 •가용성 •확장성 •안정성 •성능 •보안 저장기술 데이터저장
- 26. 분산파일시스템 ex) HadoopFS 메모리: 64M (2억5천개파일) Single Node 데이터저장
- 27. Key/Value DB Map Map.Put(key,value); Value = Map.Get(key); Key: User1 Value: Name1, Point1, X1 Key: User2 Value: Name2, Point2, X2 Key: X1 Value: **** Key: X2 Value: **** 데이터저장
- 28. GraphDB 데이터저장
- 29. MongoDB 데이터저장
- 30. 데이터저장
- 31. 데이터저장
- 33. MongoDB Map/Reduce // function finalize(key, value) -> final_value 데이터분석
- 35. Continuous Map/Reduce T(n) T(n-1) T(n-2) … … T(0) New Data Area 1 Area 2 데이터분석 Hot Cold
- 36. 실시간데이터스트림분석 window queue1 as win1[size=5sec, slide=5sec] select * from win1 where string like 'hello%' and (col2=1000 or col3=5000) •MyCQ Server •Esper MyCQL 데이터분석
- 37. 데이터분석
- 38. full text 검색 데이터분석
- 39. 서비스운영&품질관리 •운영 –관리 •처리용량설계&계획 •H/W(서버,네트워크장비) 설계및구축 •클러스터&노드추가,삭제,변경 •데이터삭제,백업,복구 •가상머신기반의클라우드환경에서관리 –모니터링 •GUI 제공(PC용, Mobile App, Web App(RIA 기반, W3C 표준준수) •H/W (CPU, Memory, Disk, Network 등) •데이터사이즈, 레코드수, OP(read,write,delete)성능등 •품질관리 –기능시험 •개발된수집,저장,분석기능에대한시험 –비기능시험 •성능, 안정성, 확장성등 –수집성능(처리량, 처리건수등), 분석성능(분석량, 건수등) –노드장애시안정성시험. –처리량에대한확장성시험등. 플랫폼관리
- 40. Data Source Real-Time Data Stream Processor Database Database Application Real-Time Application Batch Analysis pattern Event Archiving save events history data join events (tx) update rule Architecture
- 41. MONGO DB
- 42. MongoDB MongoDB (from "humongous") Scalable high-performance open source NoSQL database Written in C++ from 2007
- 43. User Application Client Library Apache, BSD, ... MongoDB Software License MongoDB GNU AGPL v3.0
- 45. MONGO DB Basic
- 46. www.mongodb.org
- 47. MongoDB 매뉴얼
- 49. MongoDB 다운로드
- 52. MongoDB MMS & Backup
- 53. MongoDB 특징 Document-Oriented Storage Full Index Support Replication & High Availability Auto-Sharding Querying Fast In-Place Updates Map/Reduce GridFS
- 54. MongoDB 저장구조(Logical) MongoDB Database Collection Document ... ... ...
- 55. JSON •JSON(JavaScript Object Notation) –Standard ECMA-262 3rd Edition -December 1999 object {} {members} members pairpair,members pair string:value array [] [elements] elements valuevalue,elements value stringnumberobjectarray true,falsenull Grammar Example Document
- 56. BSON http://bsonspec.org Grammar Example JSON에비해사이즈줄이고 컴퓨터가처리하기에성능이더좋음.
- 57. CRUD Demo •Shell •Java Application insert update find find remove find
- 59. SQL to MongoDB Mapping 실행파일
- 60. SQL to MongoDB Mapping
- 61. CREATE, ALTER, INDEX, DROP
- 62. INSERT, SELECT
- 63. Indexing indexing compound indexing People Collection Products Collection db.addresses.ensureIndex( { "user_id": 1 }, { unique: true } ) // 중복허용안함 db.accounts.ensureIndex( { username: 1 }, { unique: true, dropDups: true} ) db.people.ensureIndex( { zipcode: 1}, {background: true} ) //인덱싱하는동안에도CRUD 가능. db.addresses.ensureIndex( { "xmpp_id": 1 }, { sparse: true } ) //필드값존재하는문서의값만인덱싱
- 64. Index •TTL Index –날짜필드를가진문서에, 일정시간지나면데이터를삭제하도록인덱싱 •Geospatial Index –2차원인덱싱 –{loc:[x,y]} –db.places.ensureIndex( { loc: "2d" } ) –검색 •4각형: db.collection.find( { location: { $near: [100,100] } } ); •원형: db.collection.find( { location: { $within: { $center: [ center, radius } } } ); •다각형: db.collection.find( { location: { $within: { $box: [[100,120], [100,100], [120,100], [240,200]] } } } );
- 65. Update, Delete
- 67. MONGO DB DBA Level
- 68. REPLICATION •Replica set –A replica set consists of two or more nodes that are copies of each other. (i.e.: replicas) –The replica set automatically elects aprimary(master). No one member is intrinsically primary; that is, this is a share-nothing design. –Drivers (andmongos) can automatically detect when a replica set primary changes and will begin sending writes to the new primary. (The mongos shardingprocessdoes this too.) •Uses –Data Redundancy –Automated Failover / High Availability –Distributing read load –Simplify maintenance (compared to "normal" master-slave) –Disaster recovery eventual consistency or consistency
- 69. REPLICATION •Replica Set Member Type –Default –Secondary-Only: These members have data but cannot become primary under any circumstance. Hidden: These members are invisible to client applications. –Delayed: These members apply operations from the primary’soplogafter a specified delay. You can think of a delayed member as a form of “rolling backup.” –Arbiters: These members have no data and exist solely to participate inelections. –Non-Voting: These members do not vote in elections. Non-voting members are only used for larger sets with more than 12 members.
- 70. REPLICATION •OPLog –(operations log) is a specialcapped collection that keeps a rolling record of all operations that modify that data stored in your databases. •Rollbacks –MongoDB writes the rollback data to aBSONfile in the database’sdbpathdirectory oplog oplog oplog
- 71. Sharding •MongoDB의수평확장성은Auto-sharding(partitioning) 구조를기반으로함. –Automatic load balancing –Easy addition of new machines without down time –Scaling to one thousand nodes –No single points of failure –Automatic failover
- 72. Sharding
- 86. ShardingStatus
- 87. MAP/REDUCE // function finalize(key, value) -> final_value
- 88. MAP/REDUCE
- 89. Map Reduce Command 입력 출력 입력데이터검색(필터)
- 90. MongoDB’sMap/Reduce 분석프로그램 (분석알고리즘) MongoDShard MongoDShard MongoDShard MongoDShard 알고리즘 1-25 25-50 51-75 76-100 Result:X 알고리즘 알고리즘 알고리즘
- 91. GRID FS mongod mongod mongod File c1 c2 c3 split chunks File1 c1 File2 c2 File3 c3 File2 File2 c1 File2 c1 Grid FS 파일검색가능 파일정보에인덱싱가능 File에대한Meta정보추가/변경가능
- 92. Memory Map 커널에의해여유시간에RAM과DISK 의동기화가될때까지서로다른데이터를가질수있다. 개발자가직접커널에동기화를명령할수있다. fsync() Shred Memory-Map 메모리맵변경시원본파일과데이터가동기화가되는방식 Private Memory-Map 처음메모리맵에매핑될때파일의내용을읽어와서복사하고그이후동기화하지않는방식. MongoDB’sConsistency And Durability
- 93. MongoDB Journaling •Your disk has your data files and your journal files, which we’ll represent like this: MongoDB’sConsistency And Durability
- 94. MongoDB Journaling •When you start upmongod, it maps your data files to ashared view. Basically, the operating system says: “Okay, your data file is 2,000 bytes on disk. I’ll map that to memory address 1,000,000-1,002,000. So, if you read the memory at memory address 1,000,042, you’ll be getting the 42nd byte of the file.” (Also, the data won’t necessary be loaded until you actually access that memory.) MongoDB’sConsistency And Durability
- 95. MongoDB Journaling •This memory is still backed by the file: if you make changes in memory, the operating system will flush these changes to the underlying file. This is basically howmongodworks without journaling: it asks the operating system to flush in-memory changes every 60 seconds. •However, with journaling,mongodmakes a second mapping, this one to aprivate view. Incidentally, this is why enabling journallingdoubles the amount of virtual memorymongoduses. MongoDB’sConsistency And Durability
- 96. MongoDB Journaling •Note that the private view is not connected to the data file, so the operating system cannot flush any changes from the private view to disk. •Now, when you do a write,mongodwrites this to the private view. MongoDB’sConsistency And Durability
- 97. MongoDB Journaling •mongodwill then write this change to the journal file, creating a little description of which bytes in which file changed. MongoDB’sConsistency And Durability
- 98. MongoDB Journaling •The journal appends each change description it gets. MongoDB’sConsistency And Durability
- 99. MongoDB Journaling •At this point, the write is safe. Ifmongodcrashes, the journal can replay the change, even though it hasn’t made it to the data file yet. •The journal will then replay this change on the shared view. MongoDB’sConsistency And Durability
- 100. MongoDB Journaling •Finally, at a glacial speed compared to everything else, the shared view will be flushed to disk. By default, mongod requests that the OS do this every 60 seconds. MongoDB’sConsistency And Durability
- 101. MongoDB Journaling •The last step is thatmongodremaps the shared view to the private view. This prevents the private view from getting too “dirty” (having too many changes from the shared view it was mapped from). MongoDB’sConsistency And Durability
- 102. MongoDB’sWriteConcern Data File Memory Journal File Data File Memory Journal File Primary Secondary Replication 1.Write Request 2.To Memory 3.To Journal File (SAFE ) 4.To Data File (deprecated since v1.8) 5.To 2nd, 3rd… Nodes 6.To 2nd, 3rd… Nodes’ Journal File MongoDB’sConsistency And Durability
- 103. MongoDB’sWriteConcern FSYNC_SAFE Exceptions are raised for network issues, and server errors; the write operation waits for the server to flush the data to disk JOURNAL_SAFE Exceptions are raised for network issues, and server errors; the write operation waits for the server to group commit to the journal file on disk MAJORITY Exceptions are raised for network issues, and server errors; waits on a majority of servers for the write operation NONE No exceptions are raised, even for network issues NORMAL Exceptions are raised for network issues, but not server errors REPLICAS_SAFE Exceptions are raised for network issues, and server errors; waits for at least 2 servers for the write operation SAFE Exceptions are raised for network issues, and server errors; waits on a server for the write operation MongoDB’sConsistency And Durability
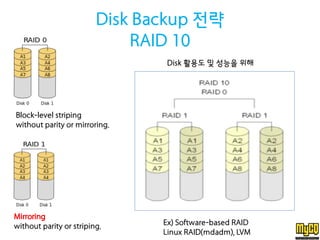
- 106. Disk Backup 전략RAID 10 Block-levelstriping withoutparityor mirroring. Mirroring without parity or striping. Ex) Software-based RAID Linux RAID(mdadm), LVM Disk 활용도및성능을위해
- 107. Client Libraries
- 108. MongoDB Developer & DBA •Mongo shell •Cluster Design –Operations –Replication –Sharding •Schema Design •Admin & Operation –Monitoring –Capability planning –Disaster Recovery –Backup –Hardware Selection •Performance Tuning •App Developer –애플리케이션개발: MongoDB Driver 기반의CRUD, M/R 개발 •DBA –설치와환경설정 –보안관리 –운영: 백업과복원, 사용자관리, 운영업무 –서비스레벨유지: 성능최적화및성능모니터링, 용량계획(Capacity Planning) –시스템가동시간관리: 시스템정지시간의계획과일정관리 –작업절차계획및규격화: 운영유지보수계획수립, 재난복구계획수립 –설계및개발지원: 데이터모델링, 데이터베이스설계 –긴급상황해결/장애복구 MongoDB를잘사용하기위해서는