

































































Ad
More Related Content
What's hot (20)
Viewers also liked (10)








Ad
Similar to Expand a Data warehouse with Hadoop and Big Data (20)




















Ad
Recently uploaded (20)




















Expand a Data warehouse with Hadoop and Big Data
- 1. 1 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 2. Expand your Data Warehouse with new Data Streams Jean-Pierre Dijcks Team Lead – Big Data Product Management
- 3. Agenda Big Data Technologies Big Data Trends and Patterns Next Generation Data Infrastructure Big Data Appliance Summary 3 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 4. New as well as Proven Technologies The Hadoop Family The NoSQL Family Event Processing Technologies Oracle Database / Oracle Exadata And more… 4 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 5. Hadoop Framework for distributed processing Large Data Sets Clusters of Computers Simple Computing Models Highly Available Service 5 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 6. Cross-Platform Strengths Extreme Performance Highly Secure Analytic SQL Rich Tool Set Vast Expertise Low-cost Scalability Flexible Schema on Read Abstract Storage Model Open Rapid Evolution Exadata 6 Big Data Appliance + Oracle Database + Hadoop Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 7. New as well as Proven Technologies A simple segmentation of usage Recommendations NoSQL DB Profiles Correlation Usage Logs Aggregation Transactions Counters Hadoop 7 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. RDBMS
- 8. New as well as Proven Technologies A simple segmentation of usage Recommendations NoSQL DB Profiles Interaction Correlation Usage Logs Aggregation Transactions Counters Hadoop 8 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. RDBMS
- 9. Fact: Data Expansion AUTOMOTIVE Auto sensors reporting location, proble ms COMMUNICATIONS Location-based advertising HIGH TECHNOLOGY / INDUSTRIAL MFG. Mfg quality Warranty analysis TRAVEL & TRANSPORTATION Sensor analysis for optimal traffic flows Customer sentiment MEDIA/ ENTERTAINMENT Viewers / advertising effectiveness Cross Sell FINANCIAL SERVICES Risk & portfolio analysis New products 9 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Retail / CPG Sentiment analysis Hot products Optimized Marketing OIL & GAS Drilling exploration sensor analysis LIFE SCIENCES Clinical trials Genomics Games Adjust to player behavior In-Game Ads ON-LINE SERVICES / SOCIAL MEDIA People & career matching Web-site optimization UTILITIES Smart Meter analysis for network capacity, EDUCATION & RESEARCH Experiment sensor analysis HEALTH CARE Patient sensors, monitoring , EHRs Quality of care LAW ENFORCEMENT & DEFENSE Threat analysis social media monitoring, photo analysis
- 10. Fact: Data Expansion AUTOMOTIVE Auto sensors reporting location, problems COMMUNICATIONS Location-based advertising HIGH TECHNOLOGY / INDUSTRIAL MFG. Mfg quality Warranty analysis TRAVEL & TRANSPORTATION Sensor analysis for optimal traffic flows Customer sentiment MEDIA/ ENTERTAINMENT Viewers / advertising effectiveness Cross Sell FINANCIAL SERVICES Risk & portfolio analysis New products 10 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Retail / CPG Sentiment analysis Hot products Optimized Marketing Games Adjust to player behavior In-Game Ads Analyze Bigger, More Diverse Data Sets OIL & GAS Drilling exploration sensor analysis ON-LINE SERVICES / SOCIAL MEDIA People & career matching Web-site optimization Finding and Monetizing Unknown Relationships LIFE SCIENCES Clinical trials Genomics UTILITIES Smart Meter analysis for network capacity, Data Driven Business Decisions EDUCATION & RESEARCH Experiment sensor analysis HEALTH CARE Patient sensors, monitoring , EHRs Quality of care LAW ENFORCEMENT & DEFENSE Threat analysis social media monitoring, photo analysis
- 11. Capturing Data Expansion Expand Data Warehouse with Data Reservoir • • Online Scalable Hadoop • Flexible • Cost Effective 11 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Σ Business Intelligence Σ Data Warehouse Marts
- 12. Capturing Data Expansion Instant Responses to Streaming Data Event Decisions NoSQL Hadoop • • • • 12 Online Scalable Flexible Cost Effective Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Data Warehouse Business Intelligence
- 13. Oracle Big Data Solution Business Analytics Oracle Real-Time Decisions Endeca Information Discovery Oracle Event Processing Cloudera Hadoop Apache Flume Oracle NoSQL Database Oracle GoldenGate Fast Data 13 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Oracle R Distribution Oracle BI Foundation Suite Oracle Big Data Connectors Oracle Database Oracle Advanced Analytics Oracle Data Integrator Big Data Platform Oracle Spatial & Graph
- 14. Expanding the DW Architecture Big Store Data Warehouse Data Hadoop 14 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. RDBMS
- 15. Expanding the DW Architecture Batch processing of data moves to Hadoop and enables more cycles for analytics in the DW 1 Data 2 Other diverse streams of data enter the Hadoop reservoir for processing and correlation or exploration 15 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 16. Expanding the DW Architecture 1 Data 16 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. New data sets are continuously generated and moved for both mass-comsumption and further analysis in the DW
- 17. Expanding the DW for Streaming Data Logical Architecture Cache Data Data Warehouse Event Processor Big Store 17 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
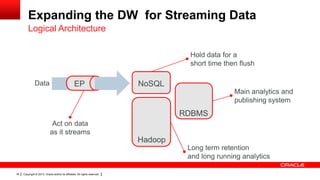
- 18. Expanding the DW for Streaming Data Logical Architecture Hold data for a short time then flush Data EP NoSQL Main analytics and publishing system RDBMS Act on data as it streams Hadoop Long term retention and long running analytics 18 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 19. Expanding the DW for Streaming Data Logical Architecture Data is received and kept for a “short duration” to enable real-time monitoring and views 2 Data 1 Data is transported and acted upon while streaming using event processing logic Without moving it, data is 3 exposed (sometimes aggregated) to the real-time DW 4 Without moving it, data is exposed to Hadoop processing enabling an up-to-date view 19 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 20. Expanding the DW for Streaming Data Logical Architecture Data As data is flushed, aggregates 1 are materialized in the DW to avoid double work Raw data is flushed into the 1 Hadoop store for long term storage and analytics on raw data (plus aggregation) 20 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 2 New data sets (aggregations and more) are continuously created in the DW for mass-consumption and consolidated analysis
- 21. Expanding the DW for Streaming Data Logical Architecture Event Processing reads relevant data with low latency from cache Business logic (scores, profiles) are moved into the cache for fast look-up by the Event Processors 2 Data 3 Decisions and results are stored with context in Big Store 21 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. 1 1 4 Results are continuously evaluated and scores etc are re-calculated
- 22. Oracle Big Data Solution Business Analytics Oracle Real-Time Decisions Endeca Information Discovery Oracle Event Processing Cloudera Hadoop Apache Flume Oracle NoSQL Database Oracle GoldenGate Fast Data 22 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Oracle R Distribution Oracle BI Foundation Suite Oracle Big Data Connectors Oracle Database Oracle Advanced Analytics Oracle Data Integrator Big Data Platform Oracle Spatial & Graph
- 23. Big Data Connectors and Data Integrator 15TB / hour 10x Faster Big Data Appliance + Hadoop 23 Exadata + Oracle Database Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 24. Analyze All Your Data In-Place Advanced Analytics Big Data Appliance + Hadoop 24 Exadata + Oracle Database Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 25. Expose All Data to End Users OBI EE Endeca Big Data Appliance + Hadoop 25 Exadata + Oracle Database Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 26. Oracle Big Data Solution Business Analytics Oracle Real-Time Decisions Oracle Event Processing Endeca Information Discovery Cloudera Hadoop Oracle BI Foundation Suite Scalable, low-cost data storage Oracle Oracle Big Data and processing Database engine Connectors Apache Flume Oracle GoldenGate Fast Data 26 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Oracle NoSQL Database Oracle R Distribution Oracle Advanced Analytics Scalable key-value store Oracle Data Integrator Oracle Spatial & Graph Statistical analysis framework Big Data Platform
- 27. Big Data Appliance for Hadoop and NoSQL Multi-Purpose Big Data Platform Lower TCO than DIY Hadoop 27 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Simplified Operations Comprehensive Security
- 28. Big Data Appliance Multi-Purpose Big Data Platform Includes all components of Cloudera Enterprise and Add-ons – Cloudera CDH – Cloudera Impala – Cloudera HBase (with Apache Accumulo) – Cloudera Search – Cloudera Manager (incl. BDR and Navigator) Oracle NoSQL Database Oracle R Distribution 28 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 29. Big Data Appliance Lower TCO than DIY Hadoop $700k % 40 Beats a DIY Cluster on: Initial Cost Time to Value Operations Performance Cost Savings % 33 Faster Time to Value $0k DIY 29 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. BDA
- 30. Big Data Appliance Simplified Operations Out-of-the-Box Performance One-command: – Installation – Patching – Updating – Expansion Enterprise Manager Plug-in for Big Data Appliance Single Contact for all Support 30 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 31. Big Data Appliance Comprehensive Security Authenticate Authorize Audit Hadoop Non-Relational Data Audit Vault Databases Relational Data 31 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Operating Systems
- 32. Western European Media Company Creating a linked customer analytics system Objectives Benefits Maximizing customer value Phase 1: Improved Data Quality Single View of all Customers improves - Toyota Global Vision customer management Optimizing campaign cost through Automation and Targeting Solution Business Objects Mobile Single, rich customer repository based on Big Data Appliance and NG Data® Lily® Analytics drive: subscriber management (up-sell/cross-sell, churn, conservation) editorial use (article engagement, adapt content over time) 32 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. Subscribers Web Social Digital, RDBMS, External BDA NG Data Lily Customer Analytics Customer Data Store Oracle Data Warehouse Customer Analytics & Aggregated data
- 33. US-based Bank Lowering Costs by Simplifying IT Infrastructure Objectives Benefits Comply with regulations requiring more Fast access to 85% more data data to support stress testing Reduce IT costs & streamline processing by eliminating duplicate data stores Lower costs, simplified architecture and fast time to value - Toyota Global Vision Solution Oracle Enterprise Manager S1 Master Single, reliable BDA/Exadata-based ODS supporting all downstream systems Landing zone & archival repository for both structured & unstructured data Use Exadata as “19th” BDA node 33 Copyright © 2013, Oracle and/or its affiliates. All rights reserved. • Agile business model • All data • De-normalized & Partialnormalized S2 Master • Normalized • Aggregate data • EDW Sn Master BDA Exadata Oracle Data Integrator Mainframe, RD BMS, more Operational Data Store SOA/API CRMS Other Data Delivery
- 34. Thomson Reuters Identifying Cross Sell and Upsell Opportunities Objectives Maximize cross-sell opportunities Lower cost and complexity Solution “Oracle's engineered systems… are geared toward high performance big data delivery - and that is exactly the type of work we do” Rick King Chief Operating Officer for Technology Thomson Reuters Economically capture all customer activity Upsell/Cross Sell Testing 50M events/sec ingest rates into BDA and Oracle NoSQL DB Feeds Exadata EDW for customer profitability & segmentation analysis Research Applications Copyright © 2013, Oracle and/or its affiliates. All rights reserved. EDW Sandbox & DR BDA 34 Event Capture & Store Exadata Interactive Analytics Exalytics
- 35. Summary The Future is Now! Business requirements are here now – Your end users want more analytics and more data Technology is available – Hadoop, NoSQL, Event Processing are commercially available Technology is increasingly easy to consume – Oracle Big Data Appliance, Oracle Exadata make deployment much simpler compared to DIY systems Your competitors are doing this today – so should you! 35 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 36. 36 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
- 37. 37 Copyright © 2013, Oracle and/or its affiliates. All rights reserved.
Editor's Notes
- #24: THEME: Integrating with Existing EnterpriseBut, Big data is not an island. Oracle customers have a lot invested in their Oracle ecosystems. Their Oracle data warehouses contain valuable data that drive their analyses and insights. Oracle databases are also at the core of transaction systems and enterprise applications. Oracle BI is used to visualize this critical information - using dashboards, answers and mobile - and use these insights to make better decisions.We want to extend these applications to be able to leverage big data. In order to accomplish this, we need blazingly fast connections and simple access to data in Hadoop. Describe Big Data Connectors - 12TB/hour - automatic access to data in Hive. Off-line. On-line. Create queries that combine data in DB w/data in Hadoop.Entire stack is “big data enabled”. Exalytics - access data in Hive. Endeca - information discovery over data in Hadoop.
- #25: THEME: Integrating with Existing EnterpriseAnalyze all data in-placeAnalytics is critical - it’s oftentimes the reason you implement big data. And, with the big data platform - you are not limited to analyzing data samples - you can analyze all your data. Simpler algorithms on all your data have been proven to be easier to implement and frankly more effective than more complex algorithms over samples.Rich analytics in both Hadoop and the Oracle database. Explain…We now have ascaleable analytic platform:Database: Oracle Advanced Analytics: SQL & RHadoop: ORCH +
- #26: THEME: Integrating with Existing EnterpriseAnalyze all data in-placeAnalytics is critical - it’s oftentimes the reason you implement big data. And, with the big data platform - you are not limited to analyzing data samples - you can analyze all your data. Simpler algorithms on all your data have been proven to be easier to implement and frankly more effective than more complex algorithms over samples.Rich analytics in both Hadoop and the Oracle database. Explain…We now have ascaleable analytic platform:Database: Oracle Advanced Analytics: SQL & RHadoop: ORCH +
- #35: Company/BackgroundLeading source of intelligent information for the world’s businesses and professionalsWestlaw & Westlaw Next legal research used by more than 80% of Fortune 500 companies with revenues > $3BUsed by legal professionals to find and share specific points of law and search for topically-related commentaryChallenges/OpportunitiesNeeded better understanding of customer behavior in order to identify cross sell and upsell opportunitiesUnable to justify cost of collecting “low value” data into standard database platformSolutionBDA and NoSQL are being tested to support ingesting up to 50M events/sec to be processed and fed into Exadata EDW. Customer segmentation models drive recommendations. Return legal search results beyond customers’ current subscription. Automatic upsell additional subscriptions.Key ProductsOracle Big Data Appliance, Oracle Exadata, Oracle ExalyticsOracle Big Data Connectors, Oracle Advanced Analytics, Oracle Spatial & Graph, Oracle OLAPWhy OracleBDA price extremely competitive with DIYBDA/Exadata integration and performanceFuture PlansCentralized BDA IaaS for Thomson Reuters divisionsUnderstand/optimize web site usageUnderstand and visualize strength of connections between entities using network graphs