Sneaky computation
Download as ODP, PDF0 likes221 views

Talk on sneaky computation to be given at Reykjavik University. Sneaky computation is the using spare CPU cycles with little or no intervention from the user.



![Let's listen to the sagas The sheepherder of Thorkel TrefI will from Svignaskarð went out that morning to his flock and he saw them going along, driving all sorts of livestock. He mentioned this to Thorkel. I know what is happening, said Thorkel. These are men from Thverárhlið [Cross-river Slope] and friends of mine. They were hard-hit by the winter and will be driving their animals here. They are welcome. I have enough hay , and there is enough pasture for grazing. Hænsa-Thori's Saga, http://lugl.info/fu](https://image.slidesharecdn.com/sneaky-computation-reykjavik-100811030534-phpapp01/85/Sneaky-computation-4-320.jpg)








































![That's not the whole story: meet BOINC Used by projects worldwide [email_address] , Xgrid, XtremeWeb... Encouraged as a competitive tool Teams](https://image.slidesharecdn.com/sneaky-computation-reykjavik-100811030534-phpapp01/85/Sneaky-computation-46-320.jpg)


































More Related Content
Similar to Sneaky computation (20)
More from Juan J. Merelo (20)


















Recently uploaded (20)




















Sneaky computation
- 2. What is your computer doing now? Nada
- 3. All these cycles are lost in time... … like tears in the rain
- 4. Let's listen to the sagas The sheepherder of Thorkel TrefI will from Svignaskarð went out that morning to his flock and he saw them going along, driving all sorts of livestock. He mentioned this to Thorkel. I know what is happening, said Thorkel. These are men from Thverárhlið [Cross-river Slope] and friends of mine. They were hard-hit by the winter and will be driving their animals here. They are welcome. I have enough hay , and there is enough pasture for grazing. Hænsa-Thori's Saga, http://lugl.info/fu
- 5. So, what's sneaky computation Use of spare xPU cycles x=C,G,N...
- 6. If possible, with the owner being none the wiser Parasitic, volunteer, community grid...
- 7. Sneaky computation was born in sin Actually, the most typical example of sneaky computation.
- 8. A worm/virus steals CPU and disk space And mindshare to boot First viri were actually worms .
- 9. El jinete de la onda de shock Los gusanos existieron primero en la ficción que en la realidad.
- 10. El primer gusano salvaje fue el gusano de Arpanet. Robert Morris, 1988 O el Creeper/Reaper Años 70, creador desconocido.
- 11. Gusanos y polillas Los gusanos, en realidad, se aprovechan de los errores.
- 12. Y en general, el único recurso que usan es la conectividad.
- 13. Sin embargo, los gusanos ya no son lo que eran.
- 14. ¿Cómo funcionan los gusanos? Los gusanos se aprovechan de debilidades en los programas a los que llegan Programas de email, servidores web, sistemas operativos. También de las debilidades de las personas.
- 15. Looking for their better half Botnets are sets of computers infected with a particular worm.
- 16. Computers are called zombies or drones .
- 17. They can include up to several million computers
- 18. Botnets for fun and profit Blackmail
- 19. Individual data collection (keyloggers, sniffers).
- 20. Distributed Denial of Service on tap.
- 21. Software installation under request (adware)
- 22. Spam-relaying
- 23. Anatomy of a botnet
- 24. Fases de un ataque Primero se ataca un URL.
- 25. Luego el ISP
- 26. Luego el proveedor de DNS
- 27. Se va yendo hacia arriba en la cadena de proveedores.
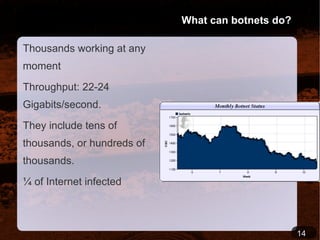
- 29. What can botnets do? Thousands working at any moment
- 31. They include tens of thousands, or hundreds of thousands.
- 32. ¼ of Internet infected
- 33. Vale, tengo miedo. ¿Qué hago ahora? La mayoría de las soluciones son legales, no técnicas.
- 34. Atacar el centro de control. O tomar control del mismo. Atacar el DNS .
- 35. Dejar que se casquen entre ellos.
- 36. From the Eastern maffia R&D Department Use of P2P technology: The Sinit worms uses a decentralized system to send commands. Use of Ipv6
- 39. Pero todavía nos queda una solución Pasarnos todos a Linux (o Mac)
- 40. All is not evil in the world Volunteer computing lends cycles to chosen experiments.
- 41. 1996: GIMPS Mersenne primes 1997: Distributed.net
- 42. 1998: Bayanihan and other Java-based systems.
- 43. How do I become a volunteer? Downloading a client program Initially working as screensaver
- 44. Currently when there's other activity Also a daemon , or a cron job .
- 45. Most OS-independent systems written in Java.
- 46. That's not the whole story: meet BOINC Used by projects worldwide [email_address] , Xgrid, XtremeWeb... Encouraged as a competitive tool Teams
- 48. Security issues All results are validated before assigning credit
- 50. Spot-checking Credibility-based fault tolerance. Luis F. G. Sarmenta. "Sabotage-Tolerance Mechanisms for Volunteer Computing Systems." Future Generation Computer Systems: Special Issue on Cluster Computing and the Grid , Vol. 18, Issue 4, March 2002: http://lugl.info/a3
- 51. Money for nothing, that's the way you do it Since choice is made by the user, volunteer computing democratizes research.
- 52. Mutual trust volunteer-project Volunteer is always right. Boosts popular interest in science.
- 53. See BOINC wiki: http://lugl.info/Bl
- 54. Bueno, sí lo es En la época dorada de las puntocom, surgieron varias empresas que vendían capacidad de cómputo distribuido Popular Power, United Devices, Entropia.net... Y pagaban a los usuarios.
- 55. Ninguna pasó de 2002.
- 56. Community matters And this is just an example of how social issues affect performance.
- 57. You can't buy love Biggest superomputer (september 2006): [email_address]
- 58. 535169 Gigaflops 331000 computers x 1.6 Gflops/computer.
- 59. Biggest user in Iceland: 3 Gflops
- 61. Credit assignment is essential for performance -> the social factor is part of the computer
- 62. Wait, there's more [email_address] , went over the Petaflop
- 63. Thanks, in part, to tens of thousands of volunteers using PS3
- 64. The start of parasitic computing Barabási's experiment: use NIC to compute boolean satisfiability problems: 2-SAT, 3-SAT
- 65. Design packet so that checksum is solution to the problem.
- 66. Proof of concept, 2001
- 68. Life as a bug Game of life simulated using ICMP over a network of 10⁵ computers.
- 69. Implicit Simulations using Messaging Protocols, G.A. Kohring, http://arxiv.org/abs/cs/0208021
- 70. Proof of concept stage
- 71. Parasitic storage Using packets sent through the network to permanently store information.
- 72. Characteristics analysis of parasitic storage,Jincai CHEN, Jiang ZHOU, Gongye ZHOU, DOI 10.1007/s12200-010-0010-3
- 73. Juggling bytes Establishing a mechanism that keeps data packets on the network by repeated sending.
- 74. Ping (ICMP) used for sending packets.
- 75. 4 Gigabytes capacity for 70000 parasitifiers
- 76. But it can be easier And stealthier
- 77. Ajax to the rescue Javascript by itself can't be used as a distributed computing vehicle.
- 78. An asynchronous communication protocol is needed
- 79. Ajax=Asynchronous Javascript & XML initially
- 80. Other languages can be used for transport.
- 81. Ajax for everybody Most, if not all, browsers include Javascript ECMA standard Object model is also compatible. W3C standard Constraint: XMLHttpRequest in the browser.
- 82. How does Ajax work?
- 83. Parasitic Javascript JavaScript is used all the time in web applications.
- 84. Running time restrictions for scripts.
- 85. Ajax requests only to originating domain Unless in Chrome environment. Nick Jenkin: Parasitic Javascript http://lugl.info/3C
- 86. Implementation of a distributed computing system in Ruby on Rails Ruby on Rails is a framework based on MVC paradigm.
- 87. Uses Ruby, AJAX and a DBMS such as MySQL.
- 88. What is DCoR? A distributed computation system via Ajax built on RoR used mainly for evolutionary computation.
- 89. Topology is client-server, but server-server is also possible.
- 90. Tests as a proof of concept, most favorable environment, and a performance baseline.
- 91. Merelo et al. Browser-based distributed evolutionary computation: performance and scaling behavior, http://lugl.info/Ll Looking for a cool logo. Suggestions welcome
- 92. Initial experiments Royal Road problem Maximize number of ones in groups
- 93. Toy problem for baseline measures. =3 1 1 1 =0 1 0 1
- 94. Experimental setup Client/serrver on the same or different computers.
- 95. Evolutionary operators applied on server; clients performing fitness evaluations only.
- 96. Using Royal Road problem.
- 98. Browser wars
- 99. Let's go backpacking Binary bin-packing problem Maximize the weight of the content of a container respecting restrictions. Same setup used for experiments. Who needs a cluster?
- 102. Scaling
- 103. Introducing AGAJAJ Merelo et al., Asynchronous Genetic Algorithm with JavaScript and JSON: http://lugl.info/1o
- 104. Framework changed to CGIs in Perl
- 105. All the evolutionary algorithms is performed on the client Server used for interchange of individuals.
- 106. Back to the Royal Road
- 107. Slashdot effect
- 108. Where do we go from here? Sneaky computation is possible. And good! Social factors are essential.
- 109. Programming is not trivial.
- 110. Server must be carefully designed.
- 112. We're done Thank you very much!
Editor's Notes
- #2: Thanks to Tomas Runarsson, who invited me and funded my stay here
- #3: La mayor parte de los ordenadores están siempre enchufados, y no aprovechan más que un porcentaje muy bajo de su capacidad. De hecho, el aumento en capacidad de los ordenadores sólo está siendo útil para juegos que desperdician cada vez más ciclos de CPU y procesadores que gastan cada vez más electricidad. Es como lo que decía Chandler (el de friends) cuando se compró el ordenador nuevo... para juegos y eso
- #4: Picture CC (like all the others in this presentation) taken from http://www.flickr.com/photos/pefectfutures/3313316367/in/photostream/
- #5: Usually when you go to other pastures to take advantage of their CPU it's not because it's winter and you have none, but the issue holds anyways. Besides, the grass is greener always at the other side of the fence.
- #6: A finales de los 90 hubo hasta media docena de empresas que vendían ciclos de CPU “sobrantes”: Popular Power, por ejemplo. Otros intentos son no comerciales: [email_address] , por ejemplo. Barabási fue quien introdujo el concepto de computación sigilosa: usando la comprobación de CRC de routers y tarjetas de red
- #8: Los gusanos lo que tratan es de aprovecharse de la red para propagarse. Son programas que se reproducen y aprovechan la conexión de red para mandarse a sí mismos a otro ordenador. Si no los paras, claro, la puedes liar. De hecho, el gusano de Morris se replicó más de la cuenta por un error y tiró la Internet de aquella época. Creeper virus was detected on ARPANET infecting the Tenex operating system. Creeper gained access independently through a modem and copied itself to the remote system where the message, 'I'M THE CREEPER : CATCH ME IF YOU CAN.' was displayed. The Reaper program, itself a virus, was created to delete Creeper, the creators of both programs are unknown.
- #9: Los gusanos ya no son simplemente formas de explorar la red hechas por un búlgaro en su sótano, sino verdaderas empresas criminales.
- #10: El virus I Love You (VBS/Loveletter) era una obra de arte de la ingeniería social: a base de un tema llamativo, lograba que la gente ejecutara el programa. Blaster fue posiblemente uno de los primeros virus, junto con Ramen (para RedHat) que no necesitaba intervención humana para propagarse: simplemente, un ordenador encendido. Santy fue uno de los primeros que se propagaba solito, usando Google y todo para buscar nuevos objetivos. Se acabó su propagación cuando Google filtró la búsqueda. Pero no siempre vamos a tener esa suerte.
- #11: Ya el blaster estaba programado para atacar windowsupdate.com en una fecha determinada. Lo que ocurre con las botnets es que son flexibles, y tienen objetivos que pueden variar. No hay nada más sigiloso que estos zombies; de hecho, se les llama zombies porque son inconscientes de lo que llevan. Estos ordenadores zombies son simplemente ordenadores infectados por un virus que lleva asociado un troyano. Ese troyano abre una puerta trasera, que permite controlarlo desde fuera.
- #12: Muchas botnets se usan para enviar spam. Hoy en día, la mayoría del spam (entre el 50 y el 80%) procede de ordenadores zombies atrapados en botnets, de hecho. Algunas también instalan adware o spyware de algún fabricante que lo solicita. Por ejemplo, el ataque del gusano Mocbot en septiembre, instalaba un programa de DollarRevenue que le reportó en 24 horas 400 y pico dólares (entre un céntimo y unos 20 por instalación) En 2004, una serie de botnets atacaron sitios de apuestas online; se pedía entre 10 y 50000 dólares para evitar el ataque.
- #13: La creación de botnets es una verdadera empresa. Son programas con sus ciclos de desarrollo, prueba, mejora, creación de diferentes versiones... Pero lo importante es que su uso se ha convertido en una empresa criminal. Los botnet herders , o pastores de la grey de bots, venden sus servicios a spammers y demás gente de mal vivir por un precio. O los más amigos de trabajar por su cuenta directamente extorsionan a empresarios amenazándoles con un ataque de denegación de servicio.
- #14: Uno de los ataques
- #17: Check password-protected
- #19: No es computación tan sigilosa; de hecho, tiene unos colores que no son exactamente de camuflaje. Pero sólo usa capacidad sobrante. ¿Qué pasó en el año 96-98 para que empezaran a surgir este tipo de proyectos? Claramente, existía ese excedente de recursos. Y ya llevaba 4-5 años la web funcionando, y la gente empezaba a tener en casa ordenadores conectados de forma permanente. Curiosamente, el Napster surgió un año después, en 1999. La primera mensajería instantánea, ICQ, surge también en 1996. Una mensajería instantánea necesita conexión permanente, porque usa su propio protocolo de direccionamiento.
- #20: El proyecto más célebre es el [email_address] que aparece en la ilustración. Pero hay muchos proyectos similares. [email_address] Busca signos de inteligencia extraterrestre analizando señales de radiotelescopios en busca de patrones regulares. No hace falta decir que no ha encontrado nada nunca, pero si le sirvió a alguien para encontrar el portátil de su esposa, que se lo habían guindado. Como en los registros de SETI aparecen las Ips a las que está conectada un nombre de usuario determinado, descubrieron que el chorizo se había conectado desde una IP determinada, lo rastrearon... La esposa declaró “Sabía que casarme con un informático serviría de algo”
- #21: Hoy en día, cualquiera se puede montar un proyecto similar usando BOINC, un sistema con origen en [email_address] y basado en un servidor con MySQL y PHP.
- #22: Esto introduce un factor social en este tipo de arquitecturas. Dar ciclos está bien, pero tiene que haber algún tipo de incentivo: pantallazos chulos, tu nombre en una lista de equipos ganadores, los ordenadores de tu empresa los más potentes y los que van mejor. El sistema de créditos sirve para eso. Por supuesto, si se trata de encontrar algo, el que lo encuentre querrá que se sepa.
- #25: All kind of social issues have to be taken into account, and that's a constant in volunteer/sneaky computing.
- #26: Now they are using GPUs, PS3 and all kind of new devices. Data from boinc.berkeley.edu/boinc_papers/internet/paper.pdfboinc.berkeley.edu/boinc_papers/internet/paper.pdf (latest paper published on the subject, 2006) If the social plart was not considered, overall performance would decrease and/or be less predictable.
- #27: Foto de: http://www.flickr.com/photos/williamhook/1983337986/ http://folding.stanford.edu/English/FAQ-Petaflop Data for Folding@home
- #28: http://www.flickr.com/photos/isaacg/3502262604/in/photostream/
- #29: http://www.flickr.com/photos/netkismet/3232590025/in/photostream/ Actually, it's 4000 times slower than doing it on a sigle computer; a computer is needed per cell.
- #30: http://www.flickr.com/photos/zooboing/4702020006/in/photostream/ It's indeed similar to mercury tube memories, which were originaly used int the 40s to keep radar signals
- #31: Picture adapted from here http://www.flickr.com/photos/helico/404640681/
- #32: This is a set of most browsers available.
- #34: JavaScript está construido alrededor de una serie de estándares ECMA. http://en.wikipedia.org/wiki/Ajax_(programming ) En realidad, hay otras formas de interaccionar de forma asíncrona entre el navegador y el servidor; ahora mismo, ésta es la más popular. Besides, there are new facilities in HTML5 which will make stuff even easier. XMLHttpRequesst is on its way to become a standard, being in the stage of the last working draft http://en.wikipedia.org/wiki/XMLHttpRequest
- #35: Image taken from http://www.adaptivepath.com/ideas/essays/archives/000385.php
- #36: Insect hideout http://www.flickr.com/photos/magtravels/217465263/in/photostream/
- #37: Se podría haber usado un entorno diferente. En realidad, tampoco se usa excesivamente RoR y puede ser incluso una rémora a la hora de conseguir altas prestaciones. La gran ventaja que tiene es la integración con ajax. Es muy fácil hacer llamadas AJAX. Pero quizás hoy lo haría en otro lenguaje: Perl o usando el Google Web Toolkit. También se podría usar un entorno totalmente diferente: Microsoft .Net, por ejemplo, o Ruby. Pero no sería tan ubicuo.
- #38: En principio, se podría usar otro cualquiera. De hecho, es posible que lo cambiemos, según el “peso” de la aplicación vaya del servidor al cliente. Pero el desarrollo en RoR es rápido, y tiene una comunidad activa
- #43: En mi casa, con mi ordenador de sobremesa, y dos portátiles, el mío y el que le compramos a Lourdes, dos VAIO.
- #45: El Opera parte la pana, y en un experimento masivo, puede conseguir muchas mejores prestaciones. Lo que ocurre es que no siempre se puede elegir.
- #46: No es como para tirar cohetes, pero algo se consigue. El problema es que RoR (mongrel) tiene una sola hebra de salida, y en estas condiciones se producen bloqueos para servir al cliente los resultados. Tampoco está optimizado en este sentido. Está en modo debug y no producción (aunque esto afectaría sobre todo a las prestaciones por nodo, no al escalado). En pruebas hechas con clusters de nodos se han conseguido mejores resultados, pero la aplicación no está hecha para trabajar con muchos nodos clientes. Así que hay que plantearse un cambio en el servidor, o en la distribución cliente-servidor
- #49: Microsiervos lo publicó aquí: http://www.microsiervos.com/archivo/ordenadores/experimento-computacion-distribuida.html There are power laws all over the place, which can be correlated with the incoming links and popularity of the site it's announced in. Once again, there are social factors which influence performance.