Semantics2018 Zhang,Petrak,Maynard: Adapted TextRank for Term Extraction: A Generic Method of Improving Automatic Term Extraction Algorithms
0 likes94 views

Slides for the talk about the paper: Ziqi Zhang, Johann Petrak and Diana Maynard, 2018: Adapted TextRank for Term Extraction: A Generic Method of Improving Automatic Term Extraction Algorithms. Semantics-2018, Vienna, Austria

![The Task of ATE
● Input: a (reasonably large) domain specific corpus
● Output: a list of candidate terms from the corpus,
representing the domain
● Approach
■ Candidate extraction: domain-dependent, usually noun
phrases, n-grams, or sequence matched by PoS patterns
■ Candidate ranking & selection: scoring candidates
based on corpus statistics, selection by threshold, or
machine learning
Domain specific
corpus
ATE
Terms for the
corpusCandidate
Extraction
Candidate
Ranking,
Selection
[ semantic, 0.67,
ontology, 0.34,
nlp, 0.33
text mining, 0.12
…
web page, 0.012 ]](https://image.slidesharecdn.com/semantics2018zhangpetrakmaynardslides-180911143154/85/Semantics2018-Zhang-Petrak-Maynard-Adapted-TextRank-for-Term-Extraction-A-Generic-Method-of-Improving-Automatic-Term-Extraction-Algorithms-2-320.jpg)




![AdaText - Overview
Adapted TextRank for Automatic Term Extraction
Domain specific
corpus
Domain
specific
seed
words/
phrases
Extract words
Semantic
relatedness
Filter by
threshold
[ w1
=0.67,
w2
=0.34,
w3
=0.22,
… ]
TextRank
ATE (any
algorithm)
[ t1
=1.99,
t2
=1.21,
t3
=1.10,
… ] +Re-rank
[ t1
=2.19,
t3
=1.41,
t2
=1.29,
… ]](https://image.slidesharecdn.com/semantics2018zhangpetrakmaynardslides-180911143154/85/Semantics2018-Zhang-Petrak-Maynard-Adapted-TextRank-for-Term-Extraction-A-Generic-Method-of-Improving-Automatic-Term-Extraction-Algorithms-7-320.jpg)
![AdaText - Overview
Adapted TextRank for Automatic Term Extraction
Domain specific
corpus
Domain
specific
seed words/
phrases
Extract words
Semantic
relatedness
Filter by
threshold
[ w1
=0.67,
w2
=0.34,
w3
=0.22,
… ]
TextRank
ATE (any
algorithm)
[ t1
=1.99,
t2
=1.21,
t3
=1.10,
… ] +Re-rank
[ t1
=2.19,
t3
=1.41,
t2
=1.29,
… ]
SEEDING CORPUS LEVEL
TEXTRANK
COMBINING
WITH ATE](https://image.slidesharecdn.com/semantics2018zhangpetrakmaynardslides-180911143154/85/Semantics2018-Zhang-Petrak-Maynard-Adapted-TextRank-for-Term-Extraction-A-Generic-Method-of-Improving-Automatic-Term-Extraction-Algorithms-8-320.jpg)









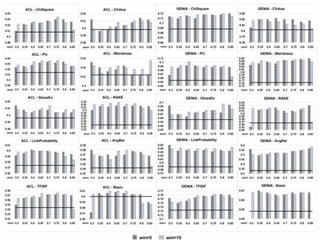
![- The min threshold: too low (creating lots of isolated graphs) or too
high (including too many weakly related words) can harm
performance
- The win threshold: no strong pattern as to which (5 or 10) is better
- Within min=[0.6, 0.75], AvgP@K improvement by 1 ~ 25
percentage points depending on the base ATE, and dataset](https://image.slidesharecdn.com/semantics2018zhangpetrakmaynardslides-180911143154/85/Semantics2018-Zhang-Petrak-Maynard-Adapted-TextRank-for-Term-Extraction-A-Generic-Method-of-Improving-Automatic-Term-Extraction-Algorithms-19-320.jpg)



































Ad
More Related Content
What's hot (20)
Similar to Semantics2018 Zhang,Petrak,Maynard: Adapted TextRank for Term Extraction: A Generic Method of Improving Automatic Term Extraction Algorithms (20)


















Ad
Recently uploaded (20)




















Ad
Semantics2018 Zhang,Petrak,Maynard: Adapted TextRank for Term Extraction: A Generic Method of Improving Automatic Term Extraction Algorithms
- 1. Adapted TextRank for Term Extraction: A Generic Method of Improving Automatic Term Extraction Algorithms Semantics 2018 - 12 September 2018 Ziqi Zhang1 , Johann Petrak2 , Diana Maynard2 [email protected], [email protected], [email protected] 1. Information School, The University of Sheffield, UK 2. Department of Computer Science, The University of Sheffield, UK
- 2. The Task of ATE ● Input: a (reasonably large) domain specific corpus ● Output: a list of candidate terms from the corpus, representing the domain ● Approach ■ Candidate extraction: domain-dependent, usually noun phrases, n-grams, or sequence matched by PoS patterns ■ Candidate ranking & selection: scoring candidates based on corpus statistics, selection by threshold, or machine learning Domain specific corpus ATE Terms for the corpusCandidate Extraction Candidate Ranking, Selection [ semantic, 0.67, ontology, 0.34, nlp, 0.33 text mining, 0.12 … web page, 0.012 ]
- 3. The Task of ATE ● A classic text mining problem ■ Dating back to 1990s (Bourigault 1992) ■ To date still an active area of research ● A fundamental step to many complex tasks ■ Ontology engineering ■ Dictionary construction ■ Information Retrieval ■ Translation ■ … ● Context of this work: KNOWMAK (https://www.knowmak.eu/)
- 4. The Task of ATE Differentiation from related tasks ATE Keyword Extraction - document specific - only a handful - mainly for indexing - domain specific - # depends on corpus - mainly knowledge acquisition NER - usually real world named entities - sentence context is more important - semantic typing - domain specific terms - corpus level statistics are more important - no typing Source: https://imanage.com/blog/named-entity-recognitio n-ravn-part-1/
- 5. Motivation and Contribution ● ATE still an unsolved problem ■ No ‘all-rounder’ method ■ Performance always depends on data and domain ■ ‘one-size-fits-all’ solution feasible? ● ATE methods are predominantly unsupervised ■ For many domains there are already domain specific resources potentially useful, e.g., unlabelled corpus, pre-compiled named entity lists, partial ontologies, etc ■ Can we benefit from those?
- 6. Motivation and Contribution A generic method that employs semantic relatedness to a set of domain specific seed words to potentially improve any ATE algorithms (by up to 25 percentage points in average precision in experiments). ● ATE still an unsolved problem ■ No ‘all-rounder’ method ■ Performance always depends on data and domain ■ ‘one-size-fits-all’ solution feasible? ● ATE methods are predominantly unsupervised ■ For many domains there are already domain specific resources potentially useful, e.g., unlabelled corpus, pre-compiled named entity lists, partial ontologies, etc ■ Can we benefit from those?
- 7. AdaText - Overview Adapted TextRank for Automatic Term Extraction Domain specific corpus Domain specific seed words/ phrases Extract words Semantic relatedness Filter by threshold [ w1 =0.67, w2 =0.34, w3 =0.22, … ] TextRank ATE (any algorithm) [ t1 =1.99, t2 =1.21, t3 =1.10, … ] +Re-rank [ t1 =2.19, t3 =1.41, t2 =1.29, … ]
- 8. AdaText - Overview Adapted TextRank for Automatic Term Extraction Domain specific corpus Domain specific seed words/ phrases Extract words Semantic relatedness Filter by threshold [ w1 =0.67, w2 =0.34, w3 =0.22, … ] TextRank ATE (any algorithm) [ t1 =1.99, t2 =1.21, t3 =1.10, … ] +Re-rank [ t1 =2.19, t3 =1.41, t2 =1.29, … ] SEEDING CORPUS LEVEL TEXTRANK COMBINING WITH ATE
- 9. AdaText - Seeding ● Input ■ C - the target corpus from which terms are extracted ■ S - a set of ‘seed’ word/phrases representing the domain ● taken from existing domain lexicons, or generated in an unsupervised way from available corpora ● May not contain real terms from C ● Process ■ Extract words from C, as W ■ Compute pairwise semantic relatedness for S x W ● Cosine similarity using GloVe embedding vectors ● OOV ignored, phrase based on compositional averaging (Iyyer et al. 2015) ● Output ■ Wsub a subset of W, satisfying relatedness > min Intuitively, they are more ‘relevant’ to the domain
- 10. AdaText - Corpus Level TextRank ● Input ■ C - the target corpus from which terms are extracted ■ Wsub - the subset of words selected before ● Process ■ Apply TextRank to the graph created for Wsub to compute a TextRank (tr) score of every word w in Wsub ■ Traditional TextRank (Mihalcea et al., 2004) is a PageRank process to a graph of words from each document, where an edge is created if words co-occur in a context window of win Compatibility of systems of linear constraints over the set of natural numbers. Criteria of compatibility of a system of linear Diophantine equations, strict inequations, and nonstrict inequations are considered. Upper bounds for components of a minimal set of solutions and algorithms of construction of minimal generating sets of solutions for all types of systems are given. These criteria and the corresponding algorithms for constructing a minimal supporting set of solutions can be used in solving all the considered types systems and systems of mixed types
- 11. AdaText - Corpus Level TextRank ● Input ■ C - the target corpus from which terms are extracted ■ Wsub - the subset of words selected before ● Process ■ Apply TextRank to the graph created for Wsub to compute a TextRank (tr) score of every word w in Wsub ■ Here it is adapted in two ways ● A graph of words from the entire corpus ● An edge is created if two words appear within win anywhere in the corpus (in any document) ● Output ■ tr scores for every word w in Wsub
- 12. AdaText - Combining with ATE ● Input ■ C - the target corpus from which terms are extracted ■ ATE - some ATE algorithm ■ tr scores for every word w in Wsub ● Process ■ Apply ATE to C to extract and score candidate terms ■ Revise each candidate term’s score using tr scores for its composing words ■ Then re-rank candidate terms by the new score ● Output ■ Re-ranked list of candidate terms
- 13. Experiment and Findings ● Base ATE methods (as AdaText needs ATE scores of candidate terms) ■ Modified TFIDF (Zhang et al., 2016) ■ CValue (Ananiadou 1994) ■ Basic (Bordea et al., 2013) ■ RAKE (Rose et al., 2010) ■ Weirdness (Ahmad et al., 1999) ■ LinkProbability (LP, Astrakhantsev, 2016) ■ X2 (Matsuo et al., 2003) ■ GlossEx (Park et al., 2002) ■ Positive Unlabelled (PU) learning (Astrakhantsev, 2016) ■ AvgRel - average relatedness score with seeds ● Use implementations: ■ JATE (https://github.com/ziqizhang/jate) ■ ATR4S (https://github.com/ispras/atr4s)
- 14. Experiment and Findings Evaluation measures ■ Precision for top K ranked candidate terms ■ K = {50, 100, 500, 1000, 2000} ■ Average P@K for all five K’s
- 15. Experiment and Findings Datasets ● GENIA ■ 2,000 semantically annotated Medline abstracts ■ 434k words ■ 33k target terms ● ACLv2 ■ 300 ACL paper abstracts ■ 32k words ■ 3k target terms
- 16. Experiment and Findings Seeds and parameters ● For GENIA: 5,502 named entities from the BioNLP Shared Task 2011, only 25 match candidate terms ● For ACLv2: 1,301 noun phrases from the titles of ACL, NAACL, and EACL papers (since 2000), none matches candidate terms ● Semantic relatedness threshold min=0.5 to 0.85 with 0.05 increment ● TextRank context window win=5, 10
- 17. Result - Base ATE - Base ATE performance varies significantly depending on datasets. - No single, consistently winning method on all five K’s. - E.g., PU is the best performing in AvgP@K on the ACL corpus, but the fourth worst performing on the GENIA corpus.
- 19. - The min threshold: too low (creating lots of isolated graphs) or too high (including too many weakly related words) can harm performance - The win threshold: no strong pattern as to which (5 or 10) is better - Within min=[0.6, 0.75], AvgP@K improvement by 1 ~ 25 percentage points depending on the base ATE, and dataset
- 20. Conclusion ● The takeaway message ■ There is probably never a ‘one-size-fit-all’ ATE method, instead, think about improving existing ones ■ AdaText makes use of existing domain resources and builds on the TextRank algorithm ■ Generic method able to improve, potentially, any ATE method ● Future work ■ Whether and how the size and source of the seed lexicon affects performance ■ Adapt TextRank to a graph of both words and phrases, and see how this affects results
- 21. Resources and Software ● Data ■ Genia corpus, ACL corpus available ■ Glove embeddings available ● Software ■ JATE (https://github.com/ziqizhang/jate) ■ ATR4S (https://github.com/ispras/atr4s) ■ Code for this work: https://github.com/ziqizhang/texpr
- 22. References 1. Bourigault, D. 1992. Surface grammatical analysis for the extraction of terminological noun phrases. In 14th International Conference on Computational Linguistics - COLING 92, 977–98 2. Iyyer, M., Manjunatha, V., Boyd-Graber, J., Daume, H., 2015. Deep unordered composition rivals syntactic methods for text classification, in: Association for Computational Linguistics. URL: docs/2015_acl_dan.pdf. 3. Mihalcea, R., Tarau, P., 2004. TextRank: Bringing order into texts, in: Proc. of EMNLP’04. 4. Zhang, Z., Gao, J., Ciravegna, F., 2016. Jate 2.0: Java automatic term extraction with apache solr, in: Proc. of LREC’16 5. Ananiadou, S., 1994. A methodology for automatic term recognition, in: Proc. of COLING1994, ACL, Stroudsburg, PA, USA. pp. 1034–1038. 6. Bordea, G., Buitelaar, P., Polajnar, T., 2013. Domain-independent term extraction through domain modelling, in: Proc. of the Conference on Terminology and Artificial Intelligence. 7. Astrakhantsev, N., 2015. Methods and software for terminology extraction from domainspecific text collection, in: Ph.D. thesis. Institute for System Programming of Russian Academy of Sciences. 8. Rose, S., Engel, D., Cramer, N., Cowley, W., 2010. Automatic keyword extraction from individual documents. John Wiley and Sons. 9. Ahmad, K., Gillam, L., Tostevin, L., 1999. University of surrey participation in trec 8: Weirdness indexing for logical document extrapolation and retrieval (wilder), in: Proc. of TREC1999. 10. Astrakhantsev, N., 2016. Atr4s: Toolkit with state-of-the-art automatic terms recognition methods in scala. arXiv preprint arXiv:1611.07804. 11. Matsuo, Y., Ishizuka, M., 2003. Keyword extraction from a single document using word co-occurrence statistical information. International Journal on Artificial Intelligence Tools 13, 157–169. 12. Park, Y., Byrd, R., Boguraev, B., 2002. Automatic glossary extraction: Beyond terminology identification, in: Proc. of COLING’02, Association for Computational Linguistics. pp. 1–7.
- 23. Acknowledgements This work is supported by the European Union's Horizon 2020 research and innovation programme under grant agreement No. 726992 (KNOWMAK project) https://www.knowmak.eu/
- 24. Thank you