Non-Fluff Software Defined Networking, Network Function Virtualization and IoT
5 likes898 views

A good granular 'non'fluff' presentation on Software Defined Networking (SDN) and Network Function Virtualization (NFV)












































































































































![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=560&fit=bounds)












Ad
More Related Content
What's hot (20)
Similar to Non-Fluff Software Defined Networking, Network Function Virtualization and IoT (20)


















Ad
Recently uploaded (20)




















Ad
Non-Fluff Software Defined Networking, Network Function Virtualization and IoT
- 1. SDNFV Slide 1 SDN NFV and all that Presented by: Yaakov (J) Stein CTO
- 2. SDNFV Slide 2 Outline * Introduction * SDN * NFV * Hype and doubts * OpenFlow * Alternatives
- 3. SDNFV Slide 3 Introduction to NFV and SDN
- 4. SDNFV Slide 4 Today’s communications world Today’s infrastructures are composed of many different Network Elements (NEs) • sensors, smartphones, notebooks, laptops, desk computers, servers, • DSL modems, Fiber transceivers, • SONET/SDH ADMs, OTN switches, ROADMs, • Ethernet switches, IP routers, MPLS LSRs, BRAS, SGSN/GGSN, • NATs, Firewalls, IDS, CDN, WAN aceleration, DPI, • VoIP gateways, IP-PBXes, video streamers, • performance monitoring probes , performance enhancement middleboxes, • etc., etc., etc. New and ever more complex NEs are being invented all the time, and RAD and other equipment vendors like it that way while Service Providers find it hard to shelve and power them all ! In addition, while service innovation is accelerating the increasing sophistication of new services the requirement for backward compatibility and the increasing number of different SDOs, consortia, and industry groups which means that it has become very hard to experiment with new networking ideas NEs are taking longer to standardize, design, acquire, and learn how to operate NEs are becoming more complex and expensive to maintain
- 5. SDNFV Slide 5 Trends over time * time cost / revenue margin Service Provider bankruptcy point * thanks to Prodip Sen from Verizon for ideas behind this slide
- 6. SDNFV Slide 6 Two complementary solutions Network Functions Virtualization (NFV) This approach advocates replacing hardware NEs with software running on COTS computers that may be housed in POPs and/or datacenters Advantages: • COTS server price and availability scales well • functionality can be placed where-ever most effective or inexpensive • functionality may be speedily deployed, relocated, and upgraded Software Defined Networks (SDN) This approach advocates replacing standardized networking protocols with centralized software applications that may configure all the NEs in the network Advantages: • easy to experiment with new ideas • software development is usually much faster than protocol standardization • centralized control simplifies management of complex systems • functionality may be speedily deployed, relocated, and upgraded Note: Some people call NFV Service Provider SDN or Telco SDN ! Note: Some people call this SDN Software Driven Networking and call NFV Software Defined Networking !
- 7. SDNFV Slide 7 New service creation Conventional networks are slow at adding new services • new service instances typically take weeks to activate • new service types may take months to years New service types often require new equipment or upgrading of existing equipment New pure-software apps can be deployed much faster ! There is a fundamental disconnect between software and networking An important goal of SDN and NFV is to speed deployment of new services
- 8. SDNFV Slide 8 Function relocation NFV and SDN facilitate (but don’t require) relocation of functionalities to Points of Presence and Data Centers Many (mistakenly) believe that the main reason for NFV is to move networking functions to data centers where one can benefit from economies of scale And conversely, even nonvirtualized functions can be relocated Some telecomm functionalities need to reside at their conventional location • Loopback testing • E2E performance monitoring but many don’t • routing and path computation • billing/charging • traffic management • DoS attack blocking The idea of optimally placing virtualized network functions in the network is called Distributed-NFV Optimal location of a functionality needs to take into consideration: • economies of scale • real-estate availability and costs • energy and cooling • management and maintenance • security and privacy • regulatory issues
- 9. SDNFV Slide 9 Example of relocation with SDN/NFV How can SDN and NFV facilitate network function relocation ? In conventional IP networks routers perform 2 functions • forwarding – observing the packet header – consulting the Forwarding Information Base – forwarding the packet • routing – communicating with neighboring routers to discover topology (routing protocols) – runs routing algorithms (e.g., Dijkstra) – populating the FIB used in packet forwarding SDN enables moving the routing algorithms to a centralized location • replace the router with a simpler but configurable SDN switch • install a centralized SDN controller – runs the routing algorithms (internally – w/o on-the-wire protocols) – configures the SDN switches by populating the FIB Furthermore, as a next step we can replace standard routing algorithms with more sophisticated path optimization algorithms !
- 10. SDNFV Slide 10 Service (function) chaining Service (function) chaining is a new SDN application that has been receiving a lot of attention and a new Network Service Chaining WG has been formed in the IETF Main application is inside data centers, but also applications in mobile networks A packet may need to be steered through a sequence of services Examples of services (functions) : • firewall • DPI for analytics • lawful interception (CALEA) • NAT • CDN • charging function • load balancing The chaining can be performed by source routing, or policy in each station, but simpler to dictate by policy from central policy server
- 11. SDNFV Slide 11 Y(J)S taxonomy While we have been using 2 buzz-words SDN and NFV, there are actually 5 distinguishable trends : • Computications – blurring of division between communications and computation • Physics - Logic – spectrum of implementation options between HW and SW – virtualization • Philosophy – touchless, configurable, and fully programmable devices • Geography – location of functionality (locally or remotely) • Politics – distributed control planes vs. centralized management planes
- 12. SDNFV Slide 12 Computications Once there was no overlap between communications (telephone, radio, TV) and computation (computers) Actually communications devices always ran complex algorithms but these are hidden from the user This dichotomy has certainly blurred ! Most home computers are not used for computation at all rather for entertainment and communications (email, chat, VoIP) Cellular telephones have become computers The differentiation can still be seen in the terms algorithm and protocol Protocols are to communications as algorithms are to computation SDN claims that packet forwarding is a pure computation problem and protocols as we know them are not needed Scott Shenker’s talk entitled The future of networking and the past of protocols
- 13. SDNFV Slide 13 Physics-Logic and Virtualization PHYSICS LOGICdedicated hardware ASIC FPGA special purpose processors general purpose software firmware VIRTUALIZATION CONCRETIZATION Concretization means moving a task usually implemented closer to SW towards HW Justifications for concretization include : • cost savings for mass produced products • miniaturization/packaging constraints • need for high processing rates • energy savings / power limitation / heat dissipation Virtualization is the opposite (although frequently reserved for the extreme case of HW → SW) Justifications are initially harder to grasp: • lower development efforts and cost • flexibility and ability to upgrade functionality
- 14. SDNFV Slide 14 Software Defined Radio An extreme case of virtualization is Software Defined Radio Transmitters and receivers (once exclusively implemented by analog circuitry) can be replaced by DSP code enabling higher accuracy (lower noise) and more sophisticated processing For example, an AM envelope detector and FM ring demodulator can be replaced by Hilbert transform based calculations reducing noise and facilitating advanced features (e.g., tracking frequency drift, notching out interfering signals) SDR enables downloading of DSP code for the transmitter / receiver of interest thus a single platform could be an LF AM receiver, or an HF SSB receiver, or a VHF FM receiver depending on the downloaded executable software Cognitive radio is a follow-on development the SDR transceiver dynamically selects the best channel available based on regulatory constraints, spectrum allocation, noise present at particular frequencies, measured performance, etc.) and sets its transmission and reception parameters accordingly
- 15. SDNFV Slide 15 Philosophy Zero Touch Simplest devices have no configurable options and very sophisticated devices may autonomously learn everything needed Most communications devices need some configuration to perform a function More flexible devices may be configured to perform multiple functions we will see that OpenFlow is of this type More complex devices may be programmed to perform multiple functions from an intended ensemble Full Programmability Most flexible devices can be programmed to do anything ! ZERO TOUCH FULL PROGRAMMABILITY BASIC CONFIGURABILITY OpenFlow flexibility DPI
- 16. SDNFV Slide 16 Geography NFV and SDN facilitate (but don’t require) relocation of functionalities to Points of Presence and Data Centers Optimal location of a functionality needs to take into consideration: • economies of scale • real-estate availability and costs • energy and cooling • management and maintenance • security and privacy • regulatory issues Some telecomm functionalities need to reside at their conventional location • Loopback testing • E2E performance monitoring but many don’t • routing and path computation • billing/charging • traffic management • DoS attack blocking
- 17. SDNFV Slide 17 Relocation without SDN/NFV Just as virtualization in computation facilitated cloud computing SDN/NFV facilitates relocation of network functions However, there are relocation cases that do not depend on it Examples: • CPRI – relocation of eNodeB processing to PoP – leaves only mixer and A/D at antenna location • MOCA – relocation of WiFi Access Point to closet – leaves only amplifier at antenna position • IPS as a service (e.g., RADWARE’s DefenseFlow) – relocation of DefensePro functionality to data center – leaves only basic detection at router
- 18. SDNFV Slide 18 Relocation with SDN/NFV - RouteFlow How do SDN and NFV facilitate network function relocation ? In conventional IP networks routers perform 2 functions • forwarding – observing the packet header – consulting the Forwarding Information Base – forwarding the packet • routing – communicating with neighboring routers to discover topology (routing protocols) – runs routing algorithms (e.g., Dijkstra) – populating the FIB used in packet forwarding SDN enables moving the routing algorithms to a centralized location • replace the router with a simpler but configurable SDN switch • install a centralized SDN controller – runs the routing algorithms (internally – w/o on-the-wire protocols) – configures the SDN switches by populating the FIB Furthermore, as a next step we can replace standard routing algorithms with more sophisticated path optimization algorithms !
- 19. SDNFV Slide 19 Politics It has long been traditional to distinguish between : • forwarding • routing (i.e., learning how to forward) • administration (setting policy, service commissioning, monitoring, billing, …) This leads to defining three planes – data (or user), control, and management Traditionally the distinction between control and management was that : • management had a human in the loop • while the control plane was automatic With the introduction of more sophisticated software the human could often be removed from the loop The difference that remains is that • the management plane is slow and centralized • the control plane is fast and distributed data plane control plane management plane
- 20. SDNFV Slide 20 Data, control, and management planes As we specified, many SDN proponents claim that separation of the data and control planes is a defining attribute of SDN rather than a time-honored fundamental characteristic of networks This belief apparently arises from these proponents being familiar with the Linux router which does not clearly separate forwarding from routing However, the Linux router was written by programmers not by networking experts What SDN really does is to erase the difference between control and management planes Note: some SDN proponents are now proposing a 4-plane model with evolutionary introduction from top to bottom data plane control plane management plane data plane control plane management plane service plane
- 22. SDNFV Slide 22 Why SDN ? Abstractions SDN was triggered by the development of networking technologies not keeping up with the new user applications requiring networking Computer science theorists theorized that this derived from a lack of abstractions In CS an abstraction is a representation that reveals semantics needed at a given level while hiding implementation details thus allowing a programmer to focus on necessary concepts without getting bogged down in unnecessary details Much of the progress in CS resulted from finding new abstractions Example: Programming languages with higher and higher layers of abstraction have been developed It is very slow to code directly in assembly language (with 1 abstraction : mnemonics for opcodes) It is a bit faster to coding in a low-level language like C (additional abstractions : variables, structures) It is much faster coding in high-level imperative language like Python It is much faster yet coding in a declarative language (coding has been abstracted away) It is fastest coding in a domain-specific language (only contains the needed abstractions)
- 23. SDNFV Slide 23 Control plane abstractions The CS theorists came to the conclusion that 1 : • The data plane has a useful abstraction – layering • There is no unified control plane or useful abstractions instead each network application has its own tailored-made control plane with its own element discovery, state distribution, failure recovery, etc. Note the subtle change of terminology instead of calling switching, routing, load balancing, etc. network functions to the CS theorists they are network applications (like SW apps, they can be easily added) SDN principle 1 APIs instead of protocols Replace control plane protocols with well-defined APIs to network applications This would hide details of the network from the network application revealing high-level concepts such as requesting connectivity between A and B but hiding details unimportant to the application such as details of switches through which the path A → B passes 1 I personally believe that this insight is mostly misguided, but here I am reporting history
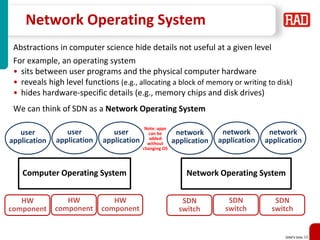
- 24. SDNFV Slide 24 Network Operating System Abstractions in computer science hide details not useful at a given level For example, an operating system • sits between user programs and the physical computer hardware • reveals high level functions (e.g., allocating a block of memory or writing to disk) • hides hardware-specific details (e.g., memory chips and disk drives) We can think of SDN as a Network Operating System user application Computer Operating System HW component user application user application HW component HW component network application Network Operating System SDN switch network application network application SDN switch SDN switch Note: apps can be added without changing OS
- 25. SDNFV Slide 25 Packet forwarding abstraction Continuing the CS-theorist’s argument another abstraction relates to how a network element forwards packets • A switch observes MAC addresses and VLAN tags and performs exact match • A router observes IP addresses and performs longest prefix match • A firewall observes multiple fields and performs regular expression match We can hide these details and state : SDN principle 2 Packet forwarding as a computational problem The function of any Network Element is to • receive a packet • observe packet fields • apply algorithm (classification, decision logic) • optionally edit packet • forward or discard packet
- 26. SDNFV Slide 26 Flows It would be too slow for a Network Element to query the central algorithm for every packet received So, it needs to store some network state In order to reduce the amount of state it needs to store we identify packets as belonging to flows SDN principle 3 Flows (as in OpenFlow) Packets are handled solely based on the flow to which they belong Flows are thus just like Forwarding Equivalence Classes Thus a flow may be determined by • an IP prefix in an IP network • A label in an MPLS network • VLANs in VLAN cross-connect networks The granularity of a flow depends on the application
- 27. SDNFV Slide 27 Network state and graph algorithms In order to perform the forwarding algorithm on a packet belonging to a flow NEs need to know something of the network state (this may be complete knowledge or very limited local knowledge) The best decisions can be made when there is full global knowledge but it would be expensive for every NE to acquire and store such state With full knowledge of topology and constraints the flow routing problem can be solved by a graph algorithm While it is possible to perform the decision algorithms in a distributed manner it makes more sense to perform them centrally The algorithm may be the same Dijkstra, but performed in a central location by an entity with full knowledge SDN principle 4 Eliminate distributed protocols Replace distributed routing protocols with graph algorithms performed at a central location However, if the algorithm is not performed at the NE, how does it know how to forward packets ?
- 28. SDNFV Slide 28 Configuration The optimal amount of network state to be stored at the individual NE is just a flow table describing how to forward a packet belonging to a flow (FIB) Conventional NEs have two parts: 1. smart but slow CPUs that create the FIB 2. fast but dumb switch fabrics that use the FIB Since the algorithms to build the FIB are performed elsewhere SDN brings the added bonus that we don’t need the CPU Such a simplified NE is called an SDN switch We populate the flow table by direct configuration The entity that communicates with the SDN switch to send configuration is called an SDN controller SDN principle 5 Configuration SDN switches are dumb and flows are configured by an SDN controller
- 29. SDNFV Slide 29 SDN as a compiler We have discussed the popular model of SDN as a Network Operating System An alternative abstraction (advocated by Contrail, recently acquired by Juniper) views SDN as a compiler The idea is that the network user describes its requirements/constraints in a high level declarative description The SDN compiler parses the requirements compiles them to low level instructions for a NE (which may be an SDN switch)
- 30. SDNFV Slide 30 Robustness SDN academicians complain about the brittleness / fragility of communications protocols As opposed to the robustness their approach can bring To investigate this claim, we need to understand what robustness means We say that a system is robust to X when it can continue functioning even when X happens For example, • A communications network is robust to failures if it continues functioning even when links or network elements fail • A communications network is robust to capacity increase if it continues functioning when the capacity it is required to handle increases Note that it is meaningless to say that a system is robust without saying to what !
- 31. SDNFV Slide 31 Robustness (cont.) Unfortunately, robustness to X may contradict robustness to Y For example, • In order to achieve robustness to failures the network is designed with redundancy (e.g., 1+1) • In order to achieve robustness to capacity increase the network is designed for efficiency, i.e., with no redundancy Thus networks can not be designed to be robust to everything Instead, networks are designed to profitably provide services The X that seems to be most on the minds of SDN proponents is creation of new types of services In the past, new service type creation was infrequent so networks were not required to be robust to it This is an area where SDN can make a big difference !
- 32. SDNFV Slide 32 OpenFlow SDN (pre)history 2005 ● 4D project Greenberg, Hjalmtysson, Maltz, Myers, Rexford, Xie, Yan, Zhan, Zhang 2005-2006 ● Stanford PhD student Martin Casado develops Ethane (with Michael Freedman, Nick McKeown, Scott Shenker, and others) 2008 ● OpenFlow: Enabling Innovation in Campus Networks paper Authors: Nick McKeown, Guru Parulkar (Stanford), Tom Anderson (U Washington), Hari Balakrishnan (MIT), Larry Peterson, Jennifer Rexford (Princeton), Scott Shenker (Berkeley), Jonathan Turner (Washington U St. Louis) • Stanford establishes OpenFlow Switching Consortium 2009 • reporter Kate Greene coins term SDN (after SDR) in interview with McKeown • Nicira raises $575k funding • OpenFlow 1.0 spec published by Standford 2010 • Big Switch raises $1.4M in seed funding 2011 • NEC, HP, and Marvell announce OpenFlow products • Cisco, Juniper and others start talking about SDN • first Open Networking Summit • ONF founded, OpenFlow 1.1 and 1.2 and OF-CONFIG 1.0 specs published 2012 ● OpenFlow 1.3 and OF-CONFIG 1.1 specs published
- 33. SDNFV Slide 33 Ethane – precursor to OpenFlow Ethane was an enterprise network architecture where connectivity is governed by high-level global fine-grained policy, e.g., • users can only communicate if allowed • traffic of untrusted users may be required to pass through an IDS • traffic or rogue hosts can be blocked upon entry • certain traffic types may be given preferential treatment Ethane had 2 components : 1. centralized omniscient controller that manages flows 2. simple (dumb) flow-based Ethane switches Ethane was built to be backwards-compatible with existing hosts and switches and thus enables hybrid topologies and migration The controller • knows the global network topology • explicitly grants access by enabling flows • performs route computation for permitted flows Ethane switches are simpler than Ethernet switches, consisting of • a flow table • a secure channel to the controller
- 34. SDNFV Slide 34 Ethane in action Bootstrapping • switches and controller form spanning tree with controller as root Registration • all users, hosts, and switches must be authenticated • users are mapped to hosts, hosts to switch+port (mobility is part of policy) Flow setup • A sends packet to B via switch • switch forwards packet to controller • controller consults policy and decides whether to allow /deny and path • controller adds flow entry to all switches along the path • controller sends packet back to switch • switch forwards packet Forwarding When a packet arrives to an Ethane switch • if in flow table, forwarded according to matching flow entry • if not in the flow table, it is sent to controller
- 35. SDNFV Slide 35 SDN interfaces Today, the most popular type of SDN : 1. utilizes flexibly programmable SDN switches 2. employs a centralized SDN controller SDN thus requires a (southbound) protocol to connect the SDN controller with SDN switches The most popular such protocol is OpenFlow others include ForCES, I2RS, netconf, BGP, … In the popular model the SDN controller itself is not intelligent intelligence sitting above it in the Network Operating System (NOS) and network applications (switching, routing, load balancing, security, etc.) There is thus the need for a (northbound) protocol to connect the SDN controller to the applications NB protocols have yet to be standardized
- 36. SDNFV Slide 36 SDN overall architecture Network SDN controller app app app app Network Operating System SDN switch SDN switch SDN switch SDN switch SDN switch SDN switch southbound interface (e.g., OpenFlow) northbound interface
- 37. SDNFV Slide 37 Is SDN better than routing ? OK, SDN switches may be cheaper – but is that the only advantage of SDN ? Distributed routing protocols are limited to • finding simple connectivity • minimizing number of hops but can not perform more sophisticated operations, such as • optimizing paths under constraints (e.g., security) • setting up non-overlapping backup paths • integrating networking functionalities (e.g., NAT, firewall) into paths This is why MPLS created the Path Computation Element architecture An SDN controller is omniscient (“God box”) • can perform arbitrary optimization calculations on the network graph • directly configures the forwarding actions of the SDN switches But this advantage comes at a price • the controller is a single point of failure • the architecture is limited to a single network • additional (overhead) bandwidth is required • additional set-up delay may be incurred
- 38. SDNFV Slide 38 RAD SDN RAD CTO Office has developed an OF to CLI converter for ETX2 and a graphic application above a standard OF controller The converter enables standard ETXs to be used in an SDN network The application enables setting up ETXs in a graphical manner WARNING– DEMOONLY
- 39. SDNFV Slide 39 SDN vs. conventional NMS So 1) is OF/SDN simply a new network management protocol ? and if so 2) is it better than existing NMS protocols ? 1) Since it is replaces both control and management planes it is much more dynamic than present management systems 2) Present systems all have drawbacks as compared to OF : SNMP (currently the most common mechanism for configuration and monitoring) is not sufficiently dynamic or fine-grained (has limited expressibility) not multivendor (commonly relies on vendor-specific MIBs) Netconf just configuration - no monitoring capabilities CLI scripting not multivendor (but I2RS is on its way) Syslog mining just monitoring - no configuration capabilities requires complex configuration and searching
- 40. SDNFV Slide 40 SDN case study - Google Google operates two backbones: I-scale Internet facing network that carries user traffic G-scale Internal network that carries traffic between datacenters (petabytes of web indexes, Gmail backups, different priorities) The two backbones have very different requirements and traffic characteristics I-scale has smooth diurnal pattern G-scale is bursty with wild demand swings , requires complex TE Since early 2012 G-scale is managed using OpenFlow Since no suitable OF device was available Google built its own switches from merchant silicon and open source stacks For fault tolerance and scalability • network has multiple controllers • each site has multiple switches
- 41. SDNFV Slide 41 SDN case study – Google (cont.) Why did Google re-engineer G-scale ? The new network has centralized traffic engineering that leads to network utilization is close to 95% ! This is done by continuously collecting real-time metrics • global topology data • bandwidth demand from applications/services • fiber utilization Path computation simplified due to global visibility and computation can be concentrated in latest generation of servers The system computes optimal path assignments for traffic flows and then programs the paths into the switches using OpenFlow. As demand changes or network failures occur the service re-computes path assignments and reprograms the switches Network can respond quickly and be hitlessly upgraded Effort started in 2010, basic SDN working in 2011, move to full TE took only 2 months
- 42. SDNFV Slide 42 Other SDN trials / deployments DT’s Croatian subsidiary Hrvatski Telekom is integrating Tail-F technology for service management in the new TeraStream all-IPv6 network Colt is in pilot stage for a new SDN-based datacenter architecture Telus and SFR are evaluating Nuage Networks datacenter solution Telstra and Ericsson are working on service chaining and optimizing the access network using SDN Portugal Telecom is collaborating with NEC on SDN in carrier datacenters Verizon is already using SDN to steer video traffic through in their network and is studying the advantages of SDN in cloud environments AT&T is offering SDN corporate VPN services for data and voice
- 43. SDNFV Slide 43 Ofelia OFELIA is an EU FP7 project Participants : EICT, DT, I Bristol, i2CAT, TU Berlin, NEC, iMinds, Leland Stanford U, ADVA, CNIT, CREATE-NET, CTTC, Lancaster U, ITAV, U Sao Paulo, UFU, The project set up a OF-controlled optical network that can be dynamically controlled and extended by researchers over the web The network • extends SDN into optical and wireless technologies • allows flexible control down to individual flows • is protocol agnostic and allows non-IP experiments such as content-based addressing • allows deployment and test of new controllers and apps • supports automatic creation of slices • enables multi-domain extensions of controllers (for federation of islands)
- 44. SDNFV Slide 44 Some more SDN projects Comprehensive • OpenDaylight SDN controllers: • NOX, POX (ICSI) • FloodLight (Big Switch) • Beacon (Stanford) • Trema (Open Source) NOS and routing • Maestro (Rice U) • RouteFlow (CpqD) Switches • Open vSwitch (Nicira/VMware) • Indigo (Big Switch) • Snabb (Open Source) • Pantou / OpenWRT (Standford) Testing • Mininet (Stanford) • Cbench (Stanford) • NICE (EPFL, Princeton) • OFTest (Big Switch) Extensions • Ofelia
- 46. SDNFV Slide 46 Virtualization of computation In the field of computation, there has been a major trend towards virtualization Virtualization here means the creation of a virtual machine (VM) that acts like an independent physical computer (or other hardware device) A VM is software that emulates hardware (e.g., an x86 CPU) over which one can run software as if it is running on a physical computer The VM runs on a host machine and creates a guest machine (e.g., an x86 environment) A single host computer may host many fully independent guest VMs and each VM may run different Operating Systems and/or applications For example • a datacenter may have many racks of server cards • each server card may have many (host) CPUs • each CPU may run many (guest) VMs A hypervisor is software that enables creation and monitoring of VMs
- 47. SDNFV Slide 47 Cloud computing Once computational and storage resources are virtualized they can be relocated to a Data Center as long as there is a network linking the place the user to the DC DCs are worthwhile because • user gets infrastructure (IaaS) or platform (PaaS) or software (SaaS) as a service and can focus on its core business instead of IT • user only pays for CPU cycles or storage GB actually used (smoothing peaks) • agility – user can quickly upscale or downscale resources • ubiquitousness – user can access service from anywhere • cloud provider enjoys economies of scale, centralized energy/cooling A standard cloud service consists of • Allocate, monitor, release compute resources (EC2, Nova) • Allocate and release storage resources (S3, Swift) • Load application to compute resource (Glance) • Dashboard to monitor performance and billing
- 48. SDNFV Slide 48 Network Functions Virtualization Computers are not the only hardware device that can be virtualized Many (but not all) NEs can be replaced by software running on a CPU or VM This would enable • using standard COTS hardware (e.g., high volume servers, storage) – reducing CAPEX and OPEX • fully implementing functionality in software – reducing development and deployment cycle times, opening up the R&D market • consolidating equipment types – reducing power consumption • optionally concentrating network functions in datacenters or POPs – obtaining further economies of scale. Enabling rapid scale-up and scale-down For example, switches, routers, NATs, firewalls, IDS, etc. are all good candidates for virtualization as long as the data rates are not too high Physical layer functions (e.g., Software Defined Radio) are not ideal candidates High data-rate (core) NEs will probably remain in dedicated hardware
- 49. SDNFV Slide 49 Distributed NFV The idea of optimally placing virtualized network functions in the network is called Distributed-NFVTM Optimal location of a functionality needs to take into consideration: • resource availability (computational power, storage, bandwidth) • real-estate availability and costs • energy and cooling • management and maintenance • other economies of scale • security and privacy • regulatory issues For example, consider moving a DPI engine from where it is needed this requires sending the packets to be inspected to a remote DPI engine If bandwidth is unavailable or expensive or excessive delay is added then DPI must not be relocated even if computational resources are less expensive elsewhere!
- 50. SDNFV Slide 50 D-NFV orchestration Data center orchestration systems decide where to place computational tasks based on constraints, costs, present CPU/memory loading, etc Similarly, with D-NFV we need to solve the VNF placement problem i.e., to compute the optimal location to insert a virtual function taking into account constraints, costs, CPU/memory load, … For function chaining (placement of multiple VNFs) there are frequently (partial) order rules as well It is suboptimal to perform path computation and D-NFV placement separately so we need to perform joint path computation and D-NFV placement This is a novel and challenging graph optimization problem !
- 51. SDNFV Slide 51 RAD D-NFV : ETX2 with VM RAD’s first step in D-NFV is an x86 module for the ETX2 • stand-alone device with standard computational (CPU) resources • x86 connected to switch ports, and can operate on packets at various stages • modular design – preparation for x86 server module module may be upgraded x86 module
- 52. SDNFV Slide 52 ETX2 with VM The ETX2 with module houses three virtual entities 1. standard ETX NTU (OAM, policing, shaping, etc.) 2. VM infrastructure (based on a KVM hypervisor) 3. VNFs that run on the VM infrastructure The VNF software may be managed by OpenStack Network ETX2 Customer Site Customer Network Data Center Hypervisor VNF VNF OpenStack Compute node OpenStack Controller
- 53. SDNFV Slide 53 Firewall with ETX/VM • 1 Gbps 3rd party firewall app • Data paths are directed to the VM per VLAN • Local filtering at customer firewall maximizes upstream BW Network Hypervisor Firewall VNF Customer Network Firewall VLANs Pass-through VLANs NNIUNI Firewall VLANs Firewall Management Open vSwitch OpenStack
- 54. SDNFV Slide 54 Packet collection with ETX/VM • Packet collector monitors traffic to analyze network behavior, performance and applications • Hardware forwarding with Flow Mirroring ensures VM does not introduce delay and is not a bottleneck Network Hypervisor TCPdump VNF Customer Network Monitored VLANs Pass-through VLANs NNIUNI Monitored VLANs TCPdump Management PC running PuTTY for activating TCPdump and retrieving the file SSH to activate/ deactivate TCPdump SFTP for file transfer Open vSwitch OpenStack
- 55. SDNFV Slide 55 Distributed Application Awareness with ETX/VM • AAw-NID – Ethernet/IP CLE sends new application samples to the DPI engine, and then handles traffic per application policy • DPI server – identifies the application based on sample traffic sent by the CPE • DB server – collects application-related information and statistics • Display application – generates graphs and reports based on collected application information • Policy server – distributes policies to the AAw-NIDs DPI Client/Server traffic DB presentation information Application Performance information Policy information Customer Premises IPFIX RADIUS Central Site(s) Policy ServerDB Server Display Application DPI Engine Network Customer Network SQL PM Engine AAW SFP AAw-NID
- 56. SDNFV Slide 57 RAD D-NFV : VNFs The next step will be in-house and partner development of VNFs RAD will create an ecosystem of software vendors writing for RAD VM devices Service Providers will also be able to write their own VNFs Virtual functions that are not network functions may also be hosted FM MEP Y.1731/802.1ag compliant “light” MEP for FM FM MIP Y.1731/802.1ag compliant MEP PM MEP full Y.1731 compliant MEP TWAMPGEN TWAMP generator TWAMPREF TWAMP reflector Visualizer Service/Application visibility AttackBlocker DoS attack blocker Quencher Rate limit specific application flows Replicator Replicate specific packets and send to specified server Packet editor Edit packets in flight TunnelMaker Encapsulate packets for tunneling through network NAT64 Gateway between IPv4 and IPv6 networks Booster TCP performance improvement Cryptorizer Encryption tool AAW Distributed Application Awareness ROUTIT router for flows WANACC WAN acceleration (deduplication, caching, compression) FIREWALL third party firewall IPPBX IP PBX ExampleVNFs
- 57. SDNFV Slide 59 Is NFV a new idea ? Virtualization has been used in networking before, for example • VLAN and VRF – virtualized L2/L3 infrastructure • Linux router – virtualized forwarding element on Linux platform But these are not NFV as presently envisioned Possibly the first real virtualized function is the Open Source network element : • Open vSwitch – Open Source (Apache 2.0 license) production quality virtual switch – extensively deployed in datacenters, cloud applications, … – switching can be performed in SW or HW – now part of Linux kernel (from version 3.3) – runs in many VMs – broad functionality (traffic queuing/shaping, VLAN isolation, filtering, …) – supports many standard protocols (STP, IP, GRE, NetFlow, LACP, 802.1ag) – now contains SDN extensions (OpenFlow)
- 58. SDNFV Slide 60 Potential VNFs OK, so we can virtualize a basic switch – what else may be useful ? Potential Virtualized Network Functions • switching elements: Ethernet switch, Broadband Network Gateway, CG-NAT, router • mobile network nodes: HLR/HSS, MME, SGSN, GGSN/PDN-GW, RNC, NodeB, eNodeB • residential nodes: home router and set-top box functions • gateways: IPSec/SSL VPN gateways, IPv4-IPv6 conversion, tunneling encapsulations • traffic analysis: DPI, QoE measurement • QoS: service assurance, SLA monitoring, test and diagnostics • NGN signalling: SBCs, IMS • converged and network-wide functions: AAA servers, policy control, charging platforms • application-level optimization: CDN, cache server, load balancer, application accelerator • security functions: firewall, virus scanner, IDS/IPS, spam protection
- 59. SDNFV Slide 61 NFV deployments and PoCs Open vSwitch widely deployed in DCs Colt has partnered with Juniper to deliver a virtual L3 CPE Telefonica is partnering with NEC in a migration scenario study to virtualize IP edge network elements BT 2012 BRAS and CDN PoC • COTS HP BladeSystem with 10GbE interfaces • WindRiver hypervisor, Linux , home-made BRAS, commercial CDN • Price/performance close to dedicated hardware BT/Intel 2013 H-QoS PoC • 2x Intel Xeon 8-core @2.7GHz, 20MB L3 cache, 32 GB DDR3 , X520-SR2 Dual Port 10GbE Controller • Fedora r6 , Intel DPDK 1.4 • Implemented a Hierarchical scheduler with: – 5 levels, 64K queues, traffic shaping, strict priority and weighted round robin • Performance per core close to 10 Gb line rate for 64B packets (13.3 Mpps)
- 60. SDNFV Slide 62 NFV ISG An Industry Specifications Group (ISG) has been formed under ETSI to study NFV ETSI is the European Telecommunications Standards Institute with >700 members Most of its work is performed in Technical Committees, but there are also ISGs • Open Radio equipment Interface (ORI) • Autonomic network engineering for the self-managing Future Internet (AFI) • Mobile Thin Client Computing (MTC) • Identity management for Network Services (INS) • Measurement Ontology for IP traffic (MOI) • Quantum Key Distribution (QKD) • Localisation Industry Standards (LIS) • Information Security Indicators (ISI) • Open Smart Grid (OSG) • Surface Mount Technique (SMT) • Low Throughput Networks (LTN) • Operational energy Efficiency for Users (OEU) • Network Functions Virtualisation (NFV) NFV now has 55 members (ETSI members) and 68 participants (non-ETSI members, including RAD)
- 61. SDNFV Slide 63 NFV ISG (cont.) Members Acme Packet, Allot, Amdocs, AT&T, ALU, Benu Networks, Broadcom, BT, Cablelabs, Ceragon, Cisco, Citrix, DT, DOCOMO, ETRI, FT, Fraunhofer FOKUS, Freescale, Fujitsu Labs, HP, Hitachi, Huawei, IBM, Intel, Iskratel, Italtel, JDSU, Juniper, KT, MetraTech, NEC, NSN, NTT, Oracle, PT, RadiSys, Samsung, Seven Principles, Spirent, Sprint, Swisscom, Tektronix, TI, Telefon Ericsson, Telefonica, TA, Telenor, Tellabs, UPRC, Verizon UK, Virtela, Virtual Open Systems, Vodafone Group, Yokogawa, ZTE Participants ADVA, AEPONYX, Affirmed Networks, ARM, Brocade, Cavium, CenturyLink, China Mobile, Ciena, CIMI, Colt, Connectem, ConteXtream, Cyan, DELL, DESS, Dialogic, Embrane, EMC, EnterpriseWeb, EANTC, Everything Everywhere, F5 Networks, Genband Ireland, IDT Canada, Infinera, Intune Networks, IP Infusion, Ixia, KDDI, Lancaster U, Layer123, LSI, Mellanox, Metaswitch, Mojatatu, Netronome, Netsocket, Noviflow, Openwave Mobility, Overture, PeerApp, Plexxi, PMC Sierra, Qosmos, RAD Data, Red Hat, Radware, Saisei Networks, SCILD Communications, Shenick, SingTel Optus, SK Telecom, Softbank Telecom, Sunbay, Symantec, Tail-f, Tekelec, Telco Systems, Telstra, Tieto Sweden, Tilera, Ulticom, Visionael, VMware, Windstream, Wiretap Ventures, 6WIND Working and expert groups • Architecture of the Virtualisation Infrastructure (INF) • Management & Orchestration (MANO) • Performance & Portability Expert Group (PER) • Reliability & Availability (REL) • Security Expert Group (SEC) • Software Architecture (SWA)
- 62. SDNFV Slide 64 NFV architecture VNF VNF VNF NFV infrastructure NFV Orchestrator hypervisor VM VM VM NFV hardware compute storage networking special purpose net partitioner VNP VNP VNP NFV OS VM image
- 63. SDNFV Slide 65 Hype and Doubts
- 64. SDNFV Slide 66 Are SDN and NFV really solutions ? Many in the industry seem to think so • VMware acquired Nicira for $1.26 billion • Cisco acquired Cariden for $141M and Meraki for $1.2B • Juniper acquired Contrail for $176m • In the OpenDaylight consortium many competitors, including – Brocade, Cisco, Citrix, Ericsson, IBM, Juniper, Microsoft , Redhat – NEC, Vmware – Adva, Arista, Ciena, Cyan, Dell, Fujitsu, Guavus, HP, Huawei, Inocybe, Intel, Nuage, Pantheon, Plexxi, Plumgrid, RADware, Versa are working together and donating their work as Open Source There have PoCs showing that showing that NFV is just around the corner The reasoning is : • general purpose CPUs can not economically perform the required network function right now • but, because of Moore’s law they will be able to do so soon
- 65. SDNFV Slide 67 Doubts On the other hand there are some very good reasons that may lead us to doubt that SDN and NFV will ever completely replace all networking technologies The four most important (in my opinion) are : 1. Moore’s law vs. Butter’s law (NFV) 2. Consequences of SDN layer violations 3. CAP theorem tradeoffs (SDN) 4. Scalability of SDN
- 66. SDNFV Slide 68 Moore’s law vs. Butter’s law Moore’s law is being interpreted to state computation power is doubling per unit price about every two years However, this reasoning neglects Butter’s Law that states optical transmission speeds are doubling every nine months So, if we can’t economically perform the function in NFV now we may be able to perform it at today’s data-rates next year But we certainly won’t be able to perform it at the required data-rates ! The driving bandwidth will increase faster than Moore’s law, due to • increased penetration of terminals (cellphones, laptops) • increased number of data-hungry apps on each terminal
- 67. SDNFV Slide 69 SDN layer violations SDN’s main tenet is that packet forwarding is a computational problem • receive packet • observe fields • apply algorithm(classification, decision logic) • optionally edit packet • forward or discard packet In principle an SDN switch could do any computation on any fields for example forwarding could depend on an arbitrary function of packet fields (MAC addresses, IP addresses, TCP ports, L7 fields, …) While conventional network elements are limited to their own scope Ethernet switches look at MAC addresses + VLAN, but not IP and above routers look at IP addresses, but not at MAC or L4 and above MPLS LSRs look at top of MPLS stack A layer violation occurs when a NE observes / modifies a field outside its scope (e.g., DPI, NATs, ECMP peaking under MPLS stack, 1588 TCs, …)
- 68. SDNFV Slide 70 Consequences of layer violations Client/server (G.80x) layering enables Service Providers • to serve a higher-layer SP • to be served by a lower-layer SP Layer violations may lead to security breaches, such as : • billing avoidance • misrouting or loss of information • information theft • session highjacking • information tampering Layer respect is often automatically enforced by network element functionality A fully programmable SDN forwarding element creates layer violations these may have unwanted consequences, due to : • programming bugs • malicious use
- 69. SDNFV Slide 71 The CAP Theorem There are three desirable characteristics of a distributed computational system 1. Consistency (get the same answer no matter which computational element responds) 2. Availability (get an answer without unnecessary delay) 3. Partition tolerance (get an answer even if there a malfunctions in the system) The CAP (Brewer’s) theorem states that you can have any 2 of these, but not all 3 ! SDN teaches us that routing/forwarding packets is a computational problem so a network is a distributed computational system So networks can have at most 2 of these characteristics Which characteristics do we need, and which can we forgo ?
- 70. SDNFV Slide 72 CAP: the SP Network Choice SPs pay dearly for lack of service not only in lost revenues, but in SLA violation penalties SP networks are designed for1 : • high availability (five nines) and • high partition tolerance (50 millisecond restoration times) So, consistency must suffer • black-holed packets (compensated by TTL fields, CV testing, etc.) • eventual consistency (but steady state may never be reached) This is a conscious decision on the part of the SP The precise trade-off is maintained by a judicious combination of centralized management and distributed control planes 1 This applies to services that have already been configured. When commissioning a new service Availability is sacrificed instead which is why service set-up is often a lengthy process.
- 71. SDNFV Slide 73 CAP: the SDN Choice SDN has emphasized consistency (perhaps natural for software proponents) So such SDNs must forgo either availability or partition tolerance (or both) Either alternative may rule out use of SDN in SP networks Relying solely on a single1 centralized controller (which in communications parlance is a pure management system) may lead to more efficient bandwidth utilization but means giving up partition tolerance However, there are no specific mechanisms to attain availability either ! Automatic protection switching needs to be performed quickly which can not be handled by a remote controller alone2 1 Using multiple collocated controllers does not protect against connectivity failures. Using multiple non-collocated controllers requires synchronization, which can lead to low availability. 2 There are solutions, such as triggering preconfigured back-up paths, but present SDN protocols do not support conditional forwarding very well.
- 72. SDNFV Slide 74 Scalability In centralized protocols (e.g., NMS, PCE, SS7, OpenFlow) all network elements talk with a centralized management system (AKA Godbox) that collects information, makes decisions, and configures elements In distributed protocols (e.g., STP, routing protocols) each network element talks to its neighbors and makes local decisions based currently available information Distributed protocols are great at discovering connectivity but are not best for more general optimization Distributed protocols scale without limit but may take a long time to completely converge (only eventual consistency) Centralized protocols can readily solve complex network optimization problems but as the number of network elements increases the centralized element becomes overloaded Dividing up the centralized element based on clustering network elements is the first step towards a distributed system (BGP works this way) We will return to scaling issues in the context of OpenFlow
- 74. SDNFV Slide 76 Open Networking Foundation In 2011 the responsibility for OpenFlow was handed over to the ONF ONF is both an SDO and a foundation for advancement of SDN ONF objectives • to create standards to support an OpenFlow ecosystem • to position SDN/OF as the future or networking and support its adoption • raise awareness, help members succeed • educate members and non-members (vendors and operators) ONF methods • establish common vocabulary • produce shared collateral • appearances • industry common use cases The ONF Inherited OF 1.0 and 1.1 and standardized OF 1.2, 1.3.x, 1.4.x It has also standardized of-config 1.0, 1.1, 1.2, of-notifications-framework-1.0 OF produces Open interfaces but not Open Source and does not hold IPR but no license charges to all members, no protection for non-members
- 75. SDNFV Slide 77 ONF structure Management Structure • Board of Directors (no vendors allowed) • Executive Director (presently Dan Pitt, employee, reports to board) • Technical Advisory Group (makes recommendations not decisions, reports to board) • Working Groups (chartered by board, chair appointed by board) • Council of Chairs (chaired by executive director, forwards draft standards to board) ONF Board members • Dan Pitt Executive Director • Nick McKeown Stanford University • Scott Shenker UC Berkeley and ICSI • Deutsche Telecom AG • Facebook • Goldman Sachs • Google • Microsoft • NTT Communications • Verizon • Yahoo run giant data centers
- 76. SDNFV Slide 78 ONF groups Working Groups • Architecture and Framework • Forwarding Abstraction • Northbound Interface (new) • Optical Transport (new) • Wireless and Mobile (new) • Configuration and Management • Testing and Interoperability • Extensibility • Migration • Market Education • Hybrid - closed Discussion Groups • Carrier grade SDN • Security • L4-7 • Skills Certification • Wireless Transport • Japanese
- 77. SDNFV Slide 79 ONF members 6WIND,A10 Networks,Active Broadband Networks,ADVA Optical,ALU/Nuage,Aricent Group,Arista, Big Switch Networks,Broadcom,Brocade, Centec Networks,Ceragon,China Mobile (US Research Center),Ciena,Cisco,Citrix,CohesiveFT,Colt,Coriant,Cyan, Dell/Force10,Deutsche Telekom, Ericsson,ETRI,Extreme Networks,F5 / LineRate Systems, Facebook,Freescale,Fujitsu, Gigamon,Goldman Sachs,Google, Hitachi,HP,Huawei,IBM,Infinera,Infoblox / FlowForwarding, Intel,Intune Networks,IP Infusion,Ixia, Juniper Networks, KDDI,KEMP Technologies,Korea Telecom, Lancope,Level 3 Communications,LSI,Luxoft, Marvell,MediaTek,Mellanox,Metaswitch Networks, Microsoft,Midokura, NCL,NEC,Netgear,Netronome,NetScout Systems,NSN,NoviFlow,NTT Communications, Optelian,Oracle,Orange,Overture Networks, PICA8,Plexxi Inc.,Procera Networks, Qosmos, Rackspace,Radware,Riverbed Technology, Samsung, SK Telecom,Spirent,Sunbay,Swisscom, Tail-f Systems,Tallac,Tekelec,Telecom Italia,Telefónica, Tellabs,Tencent, Texas Instruments,Thales,Tilera,TorreyPoint,Transmode,Turk Telekom/Argela,TW Telecom, Vello Systems,Verisign,Verizon,Virtela,VMware/Nicira, Xpliant, Yahoo, ZTE Corporation
- 78. SDNFV Slide 80 OpenFlow The OpenFlow specifications describe • the southbound protocol between OF controller and OF switches • the operation of the OF switch The OpenFlow specifications do not define • the northbound interface from OF controller to applications • how to boot the network • how an E2E path is set up by touching multiple OF switches • how to configure or maintain an OF switch (see of-config) The OF-CONFIG specification defines a configuration and management protocol between OF configuration point and OF capable switch • configures which OpenFlow controller(s) to use • configures queues and ports • remotely changes port status (e.g., up/down) • configures certificates • switch capability discovery • configuration of tunnel types (IP-in-GRE, VxLAN ) OF switch OF switch OF switch OF capable switch OFOFOF OF-CONFIG NB for Open vSwitch OVSDB (RFC 7047) can also be used
- 79. SDNFV Slide 81 OF matching The basic entity in OpenFlow is the flow A flow is a sequence of packets that are forwarded through the network in the same way Packets are classified as belonging to flows based on match fields (switch ingress port, packet headers, metadata) detailed in a flow table (list of match criteria) Only a finite set of match fields is presently defined and an even smaller set that must be supported The matching operation is exact match with certain fields allowing bit-masking Since OF 1.1 the matching proceeds in a pipeline Note: this limited type of matching is too primitive to support a complete NFV solution (it is even too primitive to support IP forwarding, let alone NAT, firewall ,or IDS!) However, the assumption is that DPI is performed by the network application and all the relevant packets will be easy to match
- 80. SDNFV Slide 82 OF flow table The flow table is populated only by the controller The incoming packet is matched by comparing to match fields For simplicity, matching is exact match to a static set of fields If matched, actions are performed and counters are updated Entries have priorities and the highest priority match succeeds Actions include editing, metering, and forwarding match fields actions counters match fields actions counters match fields actions counters actions counters flow entry flow miss entry
- 81. SDNFV Slide 83 OpenFlow 1.3 basic match fields • Switch input port • Physical input port • Metadata • Ethernet DA • Ethernet SA • EtherType • VLAN id • VLAN priority • IP DSCP • IP ECN • IP protocol • IPv4 SA • IPv4 DA • IPv6 SA • IPv6 DA • TCP source port • TCP destination port • UDP source port • UDP destination port • SCTP source port • SCTP destination port • ICMP type • ICMP code • ARP opcode • ARP source IPv4 address • ARP target IPv4 address • ARP source HW address • ARP target HW address • IPv6 Flow Label • ICMPv6 type • ICMPv6 code • Target address for IPv6 ND • Source link-layer for ND • Target link-layer for ND • IPv6 Extension Header pseudo-field • MPLS label • MPLS BoS bit • PBB I-SID • Logical Port Metadata (GRE, MPLS, VxLAN) bold match fields MUST be supported
- 82. SDNFV Slide 84 OpenFlow Switch Operation There are two different kinds of OpenFlow compliant switches • OF-only all forwarding is based on OpenFlow • OF-hybrid supports conventional and OpenFlow forwarding Hybrid switches will use some mechanism (e.g., VLAN ID ) to differentiate between packets to be forwarded by conventional processing and those that are handled by OF The switch first has to classify an incoming packet as • conventional forwarding • OF protocol packet from controller • packet to be sent to flow table(s) OF forwarding is accomplished by a flow table or since 1.1 flow tables An OpenFlow compliant switch must contain at least one flow table OF also collects PM statistics (counters) and has basic rate-limiting (metering) capabilities An OF switch can not usually react by itself to network events but there is a group mechanism that can be used for limited reaction to events
- 83. SDNFV Slide 85 OF 1.1+ pipeline Each OF flow table can match multiple fields So a single table may require ingress port = P and source MAC address = SM and destination MAC address = DM and VLAN ID = VID and EtherType = ET and source IP address = SI and destination IP address = DI and IP protocol number = P and source TCP port = ST and destination TCP port = DT This kind of exact match of many fields is expensive in software but can readily implemented via TCAMs OF 1.0 had only a single flow table which led to overly limited hardware implementations since practical TCAMs are limited to several thousand entries OF 1.1 introduced multiple tables for scalability ingress port Eth DA Eth SA VID ET IP pro TCP SP IP SA IP DA TCP DP
- 84. SDNFV Slide 86 OF 1.1+ flow table operation Table matching • each flow table is ordered by priority • highest priority match is used (match can be made “negative” using drop action) • matching is exact match with certain fields allowing bit masking • table may specify ANY to wildcard the field • fields matched may have been modified in a previous step Although the pipeline was introduced for scalability it gives more expressibility to OF matching syntax (although no additional semantics) In addition to the verbose if (field1=value1) AND (field2=value2) then … if (field1=value3) AND (field2=value4) then … it is now possible to accommodate if (field1=value1) then if (field2=value2) then … else if (field2=value4) then … flow table 0 packet in flow table 1 … flow table n action set packet out
- 85. SDNFV Slide 87 Unmatched packets What happens when no match is found in the flow table ? A flow table may contain a flow miss entry to catch unmatched packets The flow miss entry must be inserted by the controller just like any other entry it is defined as wildcard on all fields, and lowest priority The flow miss entry may be configured to : – discard packet – forward to subsequent table – forward (OF-encapsulated) packet to controller – use “normal” (conventional) forwarding (for OF-hybrid switches) If there is no flow miss entry the packet is by default discarded but this behavior may be changed via of-config
- 86. SDNFV Slide 88 OF switch ports The ports of an OpenFlow switch can be physical or logical The following ports are defined : • physical ports (connected to switch hardware interface) • logical ports connected to tunnels (tunnel ID and physical port are reported to controller) • ALL output port (packet sent to all ports except input and blocked ports) • CONTROLLER packet from or to controller • TABLE represents start of pipeline • IN_PORT output port which represents the packet’s input port • ANY wildcard port • LOCAL optional – switch local stack for connection over network • NORMAL optional port sends packet for conventional processing (hybrid switches only) • FLOOD output port sends packet for conventional flooding
- 87. SDNFV Slide 89 Instructions Each flow entry contains an instruction set to be executed upon match Instructions include • Metering : rate limit the flow (may result in packet being dropped) • Apply-Actions : causes actions in action list to be executed immediately (may result in packet modification) • Write-Actions / Clear-Actions : changes action set associated with packet which are performed when pipeline processing is over • Write-Metadata : writes metadata into metadata field associated with packet • Goto-Table : indicates the next flow table in the pipeline if the match was found in flow table k then goto-table m must obey m > k
- 88. SDNFV Slide 90 Actions OF enables performing actions on packets • output packet to a specified port • drop packet (if no actions are specified) • apply group bucket actions (to be explained later) • overwrite packet header fields • copy or decrement TTL value • push or pop push MPLS label or VLAN tag • set QoS queue (into which packet will be placed before forwarding) Action lists are performed immediately upon match • actions are accumulatively performed in the order specified in the list • particular action types may be performed multiple times • further pipeline processing is on modified packet Action sets are performed at the end of pipeline processing • actions are performed in order specified in OF specification • actions can only be performed once mandatory to support optional to support
- 89. SDNFV Slide 91 Meters OF is not very strong in QoS features, but does have a metering mechanism A flow entry can specify a meter, and the meter measures and limits the aggregate rate of all flows to which it is attached The meter can be used directly for simple rate-limiting (by discarding) or can be combined with DSCSP remarking for DiffServ mapping Each meter can have several meter bands if the meter rate surpasses a meter band, the configured action takes place Possible actions are • drop • increase DSCP drop precedence
- 90. SDNFV Slide 92 OpenFlow statistics OF switches maintain counters for every • flow table • flow entry • port • queue • group • group bucket • meter • meter band Counters are unsigned and wrap around without overflow indication Counters may count received/transmitted packets, bytes, or durations See table 5 of the OF specification for the list of mandatory and optional counters
- 91. SDNFV Slide 93 Flow removal and expiry Flows may be explicitly deleted by the controller at any time However, flows may be configured with finite lifetimes and are automatically removed upon expiry Each flow entry has two timeouts • hard_timeout : if non-zero, the flow times out after X seconds • idle_timeout : if non-zero, the flow times out after not receiving a packet for X seconds When a flow is removed for any reason, there is flag which requires the switch to inform the controller • that the flow has been removed • the reason for its removal (expiry/delete) • the lifetime of the flow • statistics of the flow
- 92. SDNFV Slide 94 Groups Groups enable performing some set of actions on multiple flows thus common actions can be modified once, instead of per flow Groups also enable additional functionalities, such as • replicating packets for multicast • load balancing • protection switch Group operations are defined in group table Group tables provide functionality not available in flow table While flow tables enable dropping or forwarding to one port group tables enable (via group type) forwarding to : • a random port from a group of ports (load-balancing) • the first live port in a group of ports (for failover) • all ports in a group of ports (packet replicated for multicasting) Action buckets are triggered by type: • All execute all buckets in group • Indirect execute one defined bucket • Select (optional) execute a bucket (via round-robin, or hash algorithm) • Fast failover (optional) execute the first live bucket ID type counters action buckets
- 93. SDNFV Slide 95 Slicings Network slicing Network can be divided into isolated slices each with different behavior each controlled by different controller Thus the same switches can treat different packets in completely different ways (for example, L2 switch some packets, L3 route others) Bandwidth slicing OpenFlow supports multiple queues per output port in order to provide some minimum data bandwidth per flow This is called slicing since it provides a slice of the bandwidth to each queue Queues may be configured to have : • given length • minimal/maximal bandwidth • other properties
- 94. SDNFV Slide 96 OpenFlow protocol packet format OpenFlow Ethernet header IP header (20B) TCP header with destination port 6633 (20B) Version (1B) 0x01/2/3/4 Type (1B) Length (2B) Transaction ID (4B) Type-specific information OF runs over TCP (optionally SSL for secure operation) using port 6633 and is specified by C structs OF is a very low-level specification (assembly-language-like)
- 95. SDNFV Slide 97 OpenFlow messages The OF protocol was built to be minimal and powerful (like x86 instruction set ) and indeed it is low-level assembly language-like There are 3 types of OpenFlow messages : OF controller to switch • populates flow tables which SDN switch uses to forward • request statistics OF switch to controller (asynchronous messages) • packet/byte counters for defined flows • sends packets not matching a defined flow Symmetric messages • hellos (startup) • echoes (heartbeats, measure control path latency) • experimental messages for extensions
- 96. SDNFV Slide 98 OpenFlow message types Symmetric messages 0 HELLO 1 ERROR 2 ECHO_REQUEST 3 ECHO_REPLY 4 EXPERIMENTER Switch configuration 5 FEATURES_REQUEST 6 FEATURES_REPLY 7 GET_CONFIG_REQUEST 8 GET_CONFIG_REPLY 9 SET_CONFIG Asynchronous messages 10 PACKET_IN = 10 11 FLOW_REMOVED = 11 12 PORT_STATUS = 12 Controller command messages 13 PACKET_OUT 14 FLOW_MOD 15 GROUP_MOD 16 PORT_MOD 17 TABLE_MOD Multipart messages 18 MULTIPART_REQUEST 19 MULTIPART_REPLY Barrier messages 20 BARRIER_REQUEST 21 BARRIER_REPLY Queue Configuration messages 22 QUEUE_GET_CONFIG_REQUEST 23 QUEUE_GET_CONFIG_REPLY Controller role change request messages 24 ROLE_REQUEST 25 ROLE_REPLY Asynchronous message configuration 26 GET_ASYNC_REQUEST 27 GET_ASYNC_REPLY 28 SET_ASYNC Meters and rate limiters configuration 29 METER_MOD Interestingly, OF uses a protocol version and TLVs for extensibility These are 2 generic control plane mechanisms, of the type that SDN claims don’t exist …
- 97. SDNFV Slide 99 Session setup and maintenance An OF switch may contain default flow entries to use before connecting with a controller The switch will boot into a special failure mode An OF switch is usually pre-configured with the IP address of a controller An OF switch may establish communication with multiple controllers in order to improve reliability or scalability. The hand-over is managed by the controllers. OF is best run over a secure connection (TLS/SSL), but can be run over unprotected TCP Hello messages are exchanged between switch and controller upon startup hellos contain version number and optionally other data Echo_Request and Echo_reply are used to verify connection liveliness and optionally to measure its latency or bandwidth Experimenter messages are for experimentation with new OF features If a session is interrupted by connection failure the OF switch continues operation with the current configuration Upon re-establishing connection the controller may delete all flow entries
- 98. SDNFV Slide 100 Bootstrapping How does the OF controller communicate with OF switches before OF has set up the network ? The OF specification explicitly avoids this question • one may assume conventional IP forwarding to pre-exist • one can use spanning tree algorithm with controller as root, once switch discovers controller it sends topology information How are flows initially configured ? The specification allows two methods • proactive (push) flows are set up without first receiving packets • reactively (pull) flows are only set up after a packet has been received A network may mix the two methods Service Providers may prefer proactive configuration while enterprises may prefer reactive
- 99. SDNFV Slide 101 Barrier message In general an OD switch does not explicitly acknowledge receipt or execution of OF controller messages Also, switches may arbitrarily reorder messages to maximize performance When the order in which the switch executes messages is important or an explicit acknowledgement is required the controller can send a Barrier_Request message Upon receiving a barrier request the switch must finish processing all previously received messages before executing any new messages Once all old messages have been executed the switch sends a Barrier_Reply message back to the controller
- 100. SDNFV Slide 102 Scaling Can OF architecture scale to large networks ? Switch flows Single TCAM-based table can handle 1000s of flows With multiple tables, or use of switch fabric and memory for basic matching, this grows to 100s of thousands of flows per switch Controller based on commercial server can handle • a single server processor can handle 100Gbps = 150 Mpps which is enough to control many 1000s of switches • a single server can handle 1000s to 10,000s of TCP connections So there is a limitation of about 10K switches per controller The obvious solution is slicing to use multiple controllers, but – this is not (yet) specified in the OF specifications – it is not clear how to avoid coordination since end-to-end paths need to be set up
- 101. SDNFV Slide 103 What’s new in OF 1.4 ? • New TCP port number 6653 (obsoletes 6633 and 976) • More use of TLVs for extensibility • Support for optical ports • New error codes, change notifications, and more descriptive reasons • Mechanisms for handling tables becoming too full (vacancy event warning threshold passed, eviction to eliminate low-importance entries) • More support for multiple controllers (monitor changes caused by other controllers, event for controller master role changes) • Bundling mechanism to apply multiple OF messages as a single operation • Synchronized tables (two tables with same entries for dual access) • New PB UCA field
- 102. SDNFV Slide 104 Alternatives to OpenFlow
- 103. SDNFV Slide 105 OpenFlow Alternatives Any protocol that can configure forwarding elements can be considered an SDN southbound interface Indeed many protocols other than OpenFlow have been so used • netconf (YANG) • ForCES • I2RS • SNMP • CLI scripts • PCEP • Router APIs • BGP • LISP (RFC 6830) We will discuss a few of the less known options
- 104. SDNFV Slide 106 ForCES background A Network Element (e.g., router) has both control and forwarding elements These elements conventionally • are co-located inside a physical box • look like a single entity to the outside world • communicate over internal interfaces (buses) • communicate using proprietary mechanisms Forwarding and Control Element Separation IETF WG standardizes a framework and information exchange between : • Control Elements (usually software running control/signaling protocols) • Forwarding Elements (usually hardware performing forwarding) made of Logical Function Blocks (classifier, scheduler, shaper, IP LPM, MPLS stack processing, …) The ForCES framework and protocol enable • CEs and FEs to be logically or physically separated • standardized protocol for communications between CEs and FEs • communications over IP (or other protocols) not just proprietary backplane • complex forwarding processing due to multiple LFBs per FE
- 105. SDNFV Slide 107 To learn more ForCES is developed in the IETF The following are the most important references for our purposes : • RFC 3654 ForCES requirements • RFC 3746 ForCES framework • RFC 5810 ForCES protocols • RFC 5811 ForCES SCTP-Based Transport Mapping Layer • RFC 5812 ForCES Forwarding Element Model • RFC 6956 ForCES LFB library • draft-wang-forces-compare-openflow-forces
- 106. SDNFV Slide 108 Why ForCES ? In any case NEs are composed of CEs (typical CPU + software) and FEs (typically ASIC or network processors) the ForCES architecture doesn’t change this but clarifies, standardizes, and simplifies NE design ForCES is a new NE architecture the network stays the same (routing protocols, topology, …) so it is an evolutionary improvement in networkingThe logical separation enables to separate the development of CEs and FEs (thus accelerating innovation) CEs and FEs can be separated at • blade level (in which case ForCES protocol replaces proprietary I/F) or • box level (which is a new option enabled by ForCES)
- 107. SDNFV Slide 109 ForCES and SDN ? ForCES changes the architecture of an NE, not of the network The CE(s) and FE(s) continue to look like a single NE to the outside world So what does this have to do with SDN ? CE manages (inquire/configure/add/remove/modify) LFBs through the ForCES protocol When one or more CEs (which can be considered SDN controllers) control remote FE(s) (which can be considered NEs) this can be used to achieve SDN And the ForCES protocol can be an alternative to OpenFlow !
- 108. SDNFV Slide 110 ForCES Architecture A CE may control multiple FEs and an FE may be controlled by multiple CEs CE and FE managers determine their associations (and capabilities) and may be simply init files The ForCES protocol runs on the Fp interface between CEs and FEs CE → FE is a master/slave relationship FEs can redirect packets to CE (e.g., router alert) CEs and FEs can dynamically join/leave NE FE FE CE CE FpFp Fi CE manager FE manager Fc Ff … … Fr Fp NE
- 109. SDNFV Slide 111 LFBs Each LFB has conceptual input/output port(s), and performs a well-defined function e.g., input packet, modify packet, generate metadata, output packet LFBs belong to classes (formally modeled using XML syntax) and there can be several LFBs of the same class in an FE An FE is fully described by • FE-level attributes (e.g., capabilities) • LFBs it contains • LFB interconnect topology RFC 6956 gives a library of useful standard LFBs, including : • Ethernet processing (EtherPHYCop, EtherMACIn, EtherClassifier, EtherEncap, EtherMACOut) • IP packet validation (IPv4Validator, IPv6Validator) • IP forwarding (IPv4UcastLPM, IPv4NextHop, IPv6UcastLPM ,IPv6NextHop) • CE – FE redirection (RedirectIn, RedirectOut) • General purpose (BasicMetadataDispatch, GenericScheduler) Other generic LFBs handle QoS (shaping/policing), filtering(ACLs), DPI, security (encryption), PM (IPFLOW, PSAMP), and pure control/configuration entities EtherPHYCop EtherMACIn EtherMACOut
- 110. SDNFV Slide 112 ForCES Protocol The ForCES protocol consists of 2 layers • Transport Mapping Layer (may be TCP/UDP or SCTP or …) • Presentation Layer (TLV-based CE-FE messaging) and has 2 phases • Pre-association phase • Post-association phase (once CEs and FEs know their associations) – association setup stage • FE attempts to join previously configured CE • if granted – capabilities exchange • CE sends initial configuration – established stage (until association is torn down or connectivity is lost) Messages: • Association (setup, setup response, teardown) • Configuration (config, config response) • Query (query, query response) • Event notification • Packet redirect • Heartbeat
- 111. SDNFV Slide 113 ForCES protocol example CE FE Heartbeats Association Setup Stage Established Stage ……
- 112. SDNFV Slide 114 ForCES vs. OpenFlow Both ForCES and OpenFlow assume separation of control and data planes but ForCES assumes that both are present in an NE while OpenFlow assumes a pure forwarding SDN switch Both protocols enable configuration of forwarding elements but OpenFlow replaces routing protocols with centralized knowledge while ForCES assumes CEs participate in routing protocols Both protocols are extensible by using TLVs ForCES has nested TLVs, while OpenFlow is less extensible OF runs only over TCP/IP while ForCES can run over alternative TMLs An OpenFlow switch consists of a sequence of matching tables and a group table tables are built on a TCAM concept and don’t directly enable LPM, tries, range match, regular expressions, etc. while ForCES allows arbitrary (real router) LFBs with arbitrary topology and is thus capable of much more complex processing (NAT, ACLs, …) Both architectures enable internal exchange of metadata
- 113. SDNFV Slide 115 I2RS Almost all NEs have some kind of CLI interface, a MIB interface, and many have some API or programmatic interface but these are mostly vendor-specific Interface To the Routing System is an IETF WG is tasked to define a programmatic, asynchronous, fast, interactive interface to the RS allowing information, policies, and operational parameters to be written to and read from the RS With I2RS routing protocols still perform most tasks but software network applications can rapidly modify routing parameters based on policy, network events, ToD, application priorities, topology, … I2RS will enable applications to • request and receive (e.g., topology) information from the RS • subscribe to targeted information streams or filtered/thresholded events • customize network behavior (while leveraging existing RS) I2RS interacts with the RIB (not with the FIB) and coexists with existing configuration and management interfaces
- 114. SDNFV Slide 116 I2RS architecture App client App App App client App client Agent 1 Routing Element 1 Routing and Signaling Local Config Dynamic System State Static System State Agent 2 Routing Element 2 Routing and Signaling Local Config Dynamic System State Static System State client can provide access to a single or multiple apps client can be local or remote to app client can access single or multiple agents I2RS protocol
- 115. SDNFV Slide 117 I2RS and SDN ? I2RS is based on the existing routing infrastructure So what does this have to do with SDN ? Routing processes are usually co-located with local forwarding elements but may not be When not co-located, the RS compute routes and paths for data packets and the forwarding is carried out somewhere else Once again, this is essentially SDN but a kind of hybrid SDN (working in parallel with routing protocols) Typical apps using the I2RS interface will be management applications enabling user applications with specific demands on network behavior For example - I2RS may be used to solve service chaining problems I2RS may also be used as a migration path to full SDN an SDN controller can use I2RS protocol to – learn topology – directly program the RIB (for routers supporting I2RS) – indirectly program the RIB using routing protocols
- 116. SDNFV Slide 118 PCE PCE is an IETF WG that develops an architecture for computation of MPLS/GMPLS p2p and p2mp Traffic Engineered LSPs PCE held BOFs in 2004, and was chartered as a WG in 2005 The PCE architecture defines: • Path Computational Element – a computational element capable of computing a path (TE-LSP) obeying constraints based on the network graph • Path Computation Client – requests the PCE to perform path computation • PCE Protocol - runs between PCC and PCE The PCE may be a NE or an external server, but in any case • participates in the IGP routing protocol • builds the Traffic Engineering Database The PCE is assumed to be • omniscient – it knows the entire network topology (graph) • computationally strong – it can perform difficult optimizations For further information see RFCs 4655, 4657, 4674, 4927, 5088, 5089, 5376, 5394, 5440, 5441, …
- 117. SDNFV Slide 119 PCEP PCE(s) to be used by PCC can be statically configured, or discovered through extensions to OSPF or IS-IS PCEP runs over TCP (even open and keepalives) using port 4189 A PCEP session is opened between PCC and PCE • capabilities are advertised • parameters are negotiated PCEP messaging is a based on the request/reply model PCEP messages : • Open initiates PCEP session • Keepalive maintains session • PCReq PCC → PCE request for path computation request details required bandwidth and other metrics • PCRep PCE → PCC reply (negative or list of computed paths) • PCNtf sent by PCE or PCC to notify of an event (e.g., PCE overloaded) • PCErr indication of protocol error • Close message to close PCEP session
- 118. SDNFV Slide 120 PCE and SDN ? PCE is an old add-on to the MPLS/GMPLS architecture that enables configuration of TE LSPs What does that have to do with SDN ? An MPLS-TE network can be considered to be an SDN • MPLS LSRs are built with full separation of control and forwarding planes • LSR performs exact match on a single field in the packet header • LSR processing is simple – stack operation and forward • without routing protocols (e.g., MPLS-TP) all paths are configured from a central site PCEP can be considered the earliest SDN southbound protocol • PCE is an SDN controller plus the application logic for path computation (one mechanism - Backward Recursive Path Computation – is specified) • PCE provides end-to-end paths (when requested) • PCC installs a received path specification
- 119. SDNFV Slide 121 Segment routing Cisco has developed a method for explicitly specifying paths Variants are defined for MPLS and for IPv6 Segment routing is similar to source routing but does not require option headers or any special forwarding processing In the MPLS version, a large number (up to 20) of labels are prepended These labels specify each link along the path Each LSR reads the label and pops it off the stack This behavior is implementable in existing LSRs and only requires routing protocol changes (to advertise labels for links) Segment routing solves the function chaining problem
- 120. SDNFV Slide 122 Segment routing vs. SDN SDN offers a solution to function chaining but with SDN (e.g., OpenFlow) misconfigurations can impact existing traffic and are not limited to the present flow So a minor programming error can bring down a network and deliberate attacks are even worse! With segment routing, the impact of any misconfiguration is limited to that flow and does not affect pre-existing services. Thus segment routing is a safer alternative to SDN for function chaining !
- 121. SDNFV Slide 123 ALTO Applications do not have access to (topology, preference, …) information available in the routing system Application-Layer Traffic Optimization is an IETF WG that specifies how (peer-to-peer) applications can gain such access An advantage of peer-to-peer is redundancy in information sources but present systems have insufficient information to select among peers Currently ALTO is used to provide information for Content Delivery Networks The ALTO service provides abstract topology maps of a network ALTO • defines a standard topology format • uses RESTful design • uses JSON encoding for requests and responses ALTO provides a northbound interface from the network to applications
- 122. SDNFV Slide 124 Other SDN languages OpenFlow is a very low-level SDN protocol • it defines the interface to a single SDN switch • its constructs are hardware-driven (essentially configuring TCAMs) • direct use of OpenFlow is very error-prone • OpenFlow has no software-engineering mechanisms – order is critical, subroutines are not possible But there are alternatives Frenetic if OpenFlow is like assembly language, frenetic is more like C and it compiles to OpenFlow Pyretic and Pyretic is like Python Procera a declarative language based on functional reactive programming Contrail (and now Open-Contrail) is another declarative SDN approach Onyx a distributed SDN platform
- 123. SDNFV Slide 125 OpenDaylight ODL merits a session of its own
- 124. SDNFV Slide 126 OpenStack OpenStack is an Infrastructure as a Service (IaaS) cloud computing platform (Cloud Operating System) It provides means to control/administer compute, storage, network, and virtualization technologies Managed by the OpenStack foundation, and all Open Source (Apache License) OpenStack is actually a set of projects: • Compute (Nova) similar to Amazon Web Service Elastic Compute Cloud EC2 • Object Storage (Swift) similar to AWS Simple Storage Service S3 • Image Service (Glance) • Identity (Keystone) • Dashboard (Horizon) • Networking (Neutron ex-Quantum) manage virtual (overlay) networks • Block Storage (Cinder) • Telemetry (Ceilometer) monitoring, metering , collection of measurements • Orchestration (Heat)