
![Overview - BERT?
1P
• Bi-directional Encoder Representations from Transformers (BERT)[1] is a language model
based on fine pre-trained word representation using bi-directional Transformer [2]
• Fine pre-trained BERT language model + transfer learning → NLP application!
….
James Marshall "Jimi" Hendrix
was an American rock guitarist,
singer, and songwriter.
….
Who is Jimi Hendrix?
Pre-trained BERT
1 classification layer
"Jimi" Hendrix was an American rock guitarist, singer, and
songwriter.
[1] Jacob et al., 2018, arxiv [2] Ashish et al., 2017, arXiv [3] Rajpurkar et al., 2016, arXiv
SQuAD v1.1 dataset leaderboard [3]](https://image.slidesharecdn.com/temp-200511072541/85/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-2-320.jpg)

![Introduction – Word Embedding
• Word embedding is a language modeling where words or phrases from the un-
labeled large corpus are mapped to vectors of real numbers
• Skip-gram word embedding model vectorizing a word using target words to
predict the surrounding words
3P
“Duct tape may works anywhere”
“duct”
“may”
“tape”
“work”
“anywhere”
Word One-hot-vector
“duct” [1, 0, 0, 0, 0]
“tape” [0, 1, 0, 0, 0]
“may” [0, 0, 1, 0, 0]
“work” [0, 0, 0, 1, 0]
“anywhere” [0, 0, 0, 0, 1]](https://image.slidesharecdn.com/temp-200511072541/85/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-4-320.jpg)





![Introduction – Transformer [1]
9P
• Transformer architecture
[1] Ashish et al., 2017, arXiv](https://image.slidesharecdn.com/temp-200511072541/85/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-10-320.jpg)





![Methods
• Corpus data for pre-train word embedding
• BooksCorpus (800M words)
• English Wikipedia (2,500M words without lists, tables and headers)
• 30,000 token vocabulary
• Data preprocessing for pre-train word embedding
• A word is separated as WordPiece [1-2] tokenizing
He likes playing → He likes play ##ing
• Make a ‘token sequence’ which two sentences packed together for pre-training
• ‘Token sequence’ with two sentences is constructed by pair of two sentences
15P
Example of two sentences token sequence
Classification
label token
Next sentence or Random chosen sentence (50%)
[1] Sennrich et al., 2016, ACL [2] Kudo, 2018, ACL](https://image.slidesharecdn.com/temp-200511072541/85/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-16-320.jpg)
![Methods
• Data preprocessing for pre-train word embedding
• Masked language model (MLM) masked some percentage of the input tokens at random
16P
Original token sequence
Randomly chosen token (15%)
Masking
[MASK]
Randomly replacing
hairy
Unchanging
80% 10% 10%
Example of two sentences token sequence
[MASK]](https://image.slidesharecdn.com/temp-200511072541/85/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-17-320.jpg)
![Methods
• The input embeddings is the sum of token embeddings, the segmentation embeddings
and the position embeddings
17P
[MASK]
512. . .
= IsNext or NotNext](https://image.slidesharecdn.com/temp-200511072541/85/BERT-Pre-training-of-Deep-Bidirectional-Transformers-for-Language-Understanding-18-320.jpg)







BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 1. 2018.11.15. AI Labs NL.K team 김성현 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 2. Overview - BERT? 1P • Bi-directional Encoder Representations from Transformers (BERT)[1] is a language model based on fine pre-trained word representation using bi-directional Transformer [2] • Fine pre-trained BERT language model + transfer learning → NLP application! …. James Marshall "Jimi" Hendrix was an American rock guitarist, singer, and songwriter. …. Who is Jimi Hendrix? Pre-trained BERT 1 classification layer "Jimi" Hendrix was an American rock guitarist, singer, and songwriter. [1] Jacob et al., 2018, arxiv [2] Ashish et al., 2017, arXiv [3] Rajpurkar et al., 2016, arXiv SQuAD v1.1 dataset leaderboard [3]
- 3. Introduction – Language Model • How to encode and decode the natural language? → Language model 2P Encoder Decoder 0101101001011 1111001011011 Machine translation Named entity TTS MRC STT POS tagging James Marshall "Jimi" Hendrix was an American rock guitarist, singer, and songwriter. Although his mainstream career spanned only four years, … Who is Jimi Hendrix? "Jimi" Hendrix was an American rock guitarist, singer, and songwriter. Language model
- 4. Introduction – Word Embedding • Word embedding is a language modeling where words or phrases from the un- labeled large corpus are mapped to vectors of real numbers • Skip-gram word embedding model vectorizing a word using target words to predict the surrounding words 3P “Duct tape may works anywhere” “duct” “may” “tape” “work” “anywhere” Word One-hot-vector “duct” [1, 0, 0, 0, 0] “tape” [0, 1, 0, 0, 0] “may” [0, 0, 1, 0, 0] “work” [0, 0, 0, 1, 0] “anywhere” [0, 0, 0, 0, 1]
- 5. Introduction – Word Embedding • Visualization of word embedding: https://ronxin.github.io/wevi/ 4P • However, word embedding algorithm could not represent ‘context’ of natural language
- 6. Introduction – Markov Model • Markov model represents the context of natural language • Bi-gram language model could calculate the probability of sentence based on the Markov chain 5P I don’t like rabbits turtles snails I 0 0.33 0.66 0 0 0 don’t 0 0 1.0 0 0 0 like 0 0 0 0.33 0.33 0.33 rabbits 0 0 0 0 0 0 turtles 0 0 0 0 0 0 snails 0 0 0 0 0 0 “I like rabbits” “I like turtles” “I don’t like snails” 0.66 * 0.33 = 0.22 0.66 * 0.33 = 0.22 0.33 * 1.0 * 0.33 = 0.11
- 7. Introduction – Recurrent Neural Network • Recurrent neural network (RNN) contains a node with directed cycle 6P Current step input Predicted next step output Current step hidden layer Previous step hidden layer One-hot-vector Basic RNN model architecture An example to predict the next character • However, RNN compute the target output in consecutive order • Distance dependency problem
- 8. soft max Introduction – Attention Mechanism • Attention is motivated by how we pay attention to different regions of an image or correlate words in one sentence 7P Hidden state Key Query Value
- 9. Introduction – Attention Mechanism • Attention for neural machine translation (NMT) https://distill.pub/2016/augmented-rnns/#attentional-interfaces 8P • Attention for speech to text (STT)
- 10. Introduction – Transformer [1] 9P • Transformer architecture [1] Ashish et al., 2017, arXiv
- 11. Introduction – Transformer 10P • Transformer architecture
- 12. Introduction – Transformer 11P • Transformer architecture
- 13. Introduction – Transformer 12P • Transformer architecture To predict next word and minimize the difference between label and output
- 14. Research Aims • To improve Transformer based language model by proposing BERT • To show that the fine-turning based language model based on pre-trained representations achieves state-of-the-art performance on many natural language processing task 13P
- 15. Input embedding layer Transformer layer Contextual representation of token Methods • Model architecture 14P BertBASE BertLARGE Transformer layer 12 24 Hidden state size 768 1024 Self-attention head 12 16 Total 110M 340M
- 16. Methods • Corpus data for pre-train word embedding • BooksCorpus (800M words) • English Wikipedia (2,500M words without lists, tables and headers) • 30,000 token vocabulary • Data preprocessing for pre-train word embedding • A word is separated as WordPiece [1-2] tokenizing He likes playing → He likes play ##ing • Make a ‘token sequence’ which two sentences packed together for pre-training • ‘Token sequence’ with two sentences is constructed by pair of two sentences 15P Example of two sentences token sequence Classification label token Next sentence or Random chosen sentence (50%) [1] Sennrich et al., 2016, ACL [2] Kudo, 2018, ACL
- 17. Methods • Data preprocessing for pre-train word embedding • Masked language model (MLM) masked some percentage of the input tokens at random 16P Original token sequence Randomly chosen token (15%) Masking [MASK] Randomly replacing hairy Unchanging 80% 10% 10% Example of two sentences token sequence [MASK]
- 18. Methods • The input embeddings is the sum of token embeddings, the segmentation embeddings and the position embeddings 17P [MASK] 512. . . = IsNext or NotNext
- 19. Methods • Training options • Train batch size: 256 sequences (256 sequences * 512 tokens = 128,000 tokens/batch) • Steps: 1M • Epoch: 40 epochs • Adam learning rate: 1e-4 • Weight decay: 0.01 • Drop out probability: 0.1 • Activation function: GELU • Environmental setup • BERTBASE: 4 Cloud TPUs (16 TPU chips total) • BERTLARGE: 16 Cloud TPUs (64 TPU chips total) ≈ 72 P100 GPU • Training time: 4 days 18P
- 20. Methods • Experiments (total 11 NLP task) • GLUE datasets ‒ MNLI: Multi-Genre Natural Language Inference ‒ To predict whether second sentence is an entailment, contradiction or neutral ‒ QQP: Quora Question Pairs ‒ To predict two questions are semantically equivalent ‒ QNLI: Question Natural Language Inference ‒ Question and Answering datasets ‒ SST-2: The Stanford Sentiment Treebank ‒ Single-sentence classification task from movie reviews with human annotations of their sentiment ‒ CoLA: The Corpus of Linguistic Acceptability ‒ Single-sentence classification to predict whether an English sentence is linguistically acceptable or not ‒ STS-B: The Semantic Textual Similarity Benchmark ‒ News headlines dataset with annotated score from 1 to 5 denoting how similar the two sentences are in terms of semantic meaning ‒ MRPC: Microsoft Research Paraphrase Corpus ‒ Online news sources with human annotations for whether the sentences in the pair the semantically equivalent ‒ RTE: Recognizing Textual Entailment ‒ Similar to MNLI, but with much less training data ‒ WNLI: Winograd NLI ‒ Small natural language inference dataset to predict sentence class • SQuAD v1.1 • CoNLL 2003 Named Entity Recognition datasets • SWAG: Situations With Adversarial Generations ‒ To decide among four choices the most plausible continuation sentence 19P
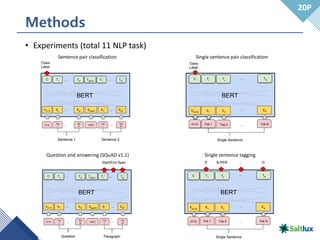
- 21. Methods • Experiments (total 11 NLP task) 20P Sentence pair classification Single sentence pair classification Question and answering (SQuAD v1.1) Single sentence tagging
- 22. Results • GLUE test results 21P • SQuAD v1.1
- 23. Results • Named Entity Recognition (CoNLL-2003) 22P • SWAG
- 24. Conclussion • BERT is undoubtedly a breakthrough in the use of machine learning for natural language processing • Bi-directional Transformer architecture enhances the natural language processing performance 23P
- 25. Discussion • English SQuAD v1.1 test 24P • Korean BERT training BERT En vocabulary BERT Ko vocabulary BERT Korean model
- 26. 감사합니다