1075: .NETからCUDAを使うひとつの方法
3 likes•5,124 views

2015年9月18日開催 GTC Japan 2015 講演資料 エヌビディアCUDAアンバサダー επιστημη CUDAを使ったWindowsアプリケーション作成の手法のひとつ、C++/CLI native-wrapper をご紹介します。C#/VB等による.NETアプリケーションでCUDAを利用するにはmanagedとnativeとの仲介役を必要とします。本セッションではCUDAを使ったnative-C++関数をC++/CLIでwrapすることで、C#(Windows Forms)によるUIからCUDAを呼び出すからくりを、デモをまじえて解説します。




![サンプル : SAXPY
Y[i] = alpha * X[i] + Y[i] (i = 0..N-1)
C# / Windows Forms app.
絵ヅラはC#, 計算はCUDA
C++/CLIが両者を仲介](https://image.slidesharecdn.com/1075-150913124432-lva1-app6891/85/1075-NET-CUDA-6-320.jpg)



![SAXPY DEVICE/HOST CODE
__global__ void kernel_saxpy(float alpha, const float* x, float* y,
unsigned int size) {
unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
if ( i < size ) { y[i] = alpha * x[i] + y[i]; } // Saxpy!
}
__host__ void device_saxpy(float alpha, const float* x, float* y,
unsigned int size) {
unsigned int block = 256U; unsigned int grid = (size + block -1U)/block;
kernel_saxpy<<<grid,block>>>(alpha, x, y, size);
}
※ device-code および それを呼び出すhost-codeは ~.cu に記述します](https://image.slidesharecdn.com/1075-150913124432-lva1-app6891/85/1075-NET-CUDA-11-320.jpg)
![REF CLASS SAXPY : ~.h public部
namespace CUDA {
public ref class Saxpy {
private:
…
public:
Saxpy(); // コンストラクタ
~Saxpy(); // デストラクタ
!Saxpy(); // ファイナライザ
void calculate(float alpha, cli::array<float>^ x, cli::array<float>^ y);
};
} ※ C++/CLI: cli::array<float>^ は C#: float[] に相当します](https://image.slidesharecdn.com/1075-150913124432-lva1-app6891/85/1075-NET-CUDA-12-320.jpg)
![REF CLASS SAXPY : ~.h private部
namespace CUDA {
public ref class Saxpy {
private:
float* dx_; // device-memory X[]
float* dy_; // device-memory Y[]
size_t bsize_; // dx_/dy_の大きさ(bytes)
void allocate(size_t new_bsize); // dx_/dy_を確保する
void deallocate() { // dx_/dy_を解放する
cudaFree(dx_); dx_ = nullptr;
cudaFree(dy_); dy_ = nullptr;
}
…
}
※利用者(C#,VB)に成り代わって device-memory を確保/解放します](https://image.slidesharecdn.com/1075-150913124432-lva1-app6891/85/1075-NET-CUDA-13-320.jpg)


![namespace CUDA {
void Saxpy::calculate(float alpha, array<float>^ x, array<float>^ y) {
unsigned int size = x->Length; if ( size != y->Length ) return;
allocate((size_t)(size*sizeof(float)));
// host → device
pin_ptr<float> hx = &x[0];
cudaMemcpy(dx_, hx, size*sizeof(float), cudaMemcpyHostToDevice);
pin_ptr<float> hy = &y[0];
cudaMemcpy(dy_, hy, size*sizeof(float), cudaMemcpyHostToDevice);
// kernel-call
device_saxpy(alpha, dx_, dy_, size);
// device → host
cudaMemcpy(hy, dy_, size*sizeof(float), cudaMemcpyDeviceToHost);
}
}
※ pin_ptr<float> でピン留めします](https://image.slidesharecdn.com/1075-150913124432-lva1-app6891/85/1075-NET-CUDA-16-320.jpg)

![HOW TO USE IN C# : ~.cs
public partial class Form1 : Form {
private CUDA.Saxpy saxpy = new CUDA.Saxpy(); // 作って
private void btnCalc_Click(object sender, EventArgs e) {
if ( lstX.Items.Count != lstY.Items.Count ) return;
float[] x = …;
float[] y = …;
float alpha = …;
saxpy.calculate(alpha, x, y); // 呼ぶ!
…
}
※ インスタンスを生成(new)し、メソッドを呼び出すだけ](https://image.slidesharecdn.com/1075-150913124432-lva1-app6891/85/1075-NET-CUDA-18-320.jpg)





1075: .NETからCUDAを使うひとつの方法
- 1. .NET から CUDA を使うひとつの方法 C++/CLI による WRAPPER のつくりかた episthmh [email protected] Microsoft MVP for Visual C++ Jan.2004~ NVIDIA CUDA Ambassador for Apr.2015~ 2015-1075 Hall-B1 16:20~
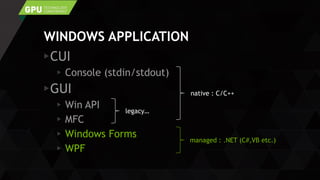
- 2. WINDOWS APPLICATION CUI Console (stdin/stdout) GUI Win API MFC Windows Forms WPF native : C/C++ managed : .NET (C#,VB etc.) legacy…
- 3. MANAGED は直接 CUDA を呼べない… host memory device memory PCI-bus CLR managed app.
- 4. MANAGED と NATIVE の仲介役 host memory device memory PCI-bus CLR managed app. native assembly call
- 6. サンプル : SAXPY Y[i] = alpha * X[i] + Y[i] (i = 0..N-1) C# / Windows Forms app. 絵ヅラはC#, 計算はCUDA C++/CLIが両者を仲介
- 7. WRAPPERのつくりかた 1: CLR クラスライブラリ
- 8. WRAPPERのつくりかた 2: ビルド カスタマイズ ※ C++/CLI プロジェクト内で デバイス・コード(~.cu) をコンパイルできます
- 9. WRAPPERのつくりかた 3: CUDA RUNTIME
- 10. WRAPPERのつくりかた 4: 64BIT PLATFORM ※ CUDA 7.0 以降、多くのCUDAライブラリは 64bit-only です
- 11. SAXPY DEVICE/HOST CODE __global__ void kernel_saxpy(float alpha, const float* x, float* y, unsigned int size) { unsigned int i = blockDim.x * blockIdx.x + threadIdx.x; if ( i < size ) { y[i] = alpha * x[i] + y[i]; } // Saxpy! } __host__ void device_saxpy(float alpha, const float* x, float* y, unsigned int size) { unsigned int block = 256U; unsigned int grid = (size + block -1U)/block; kernel_saxpy<<<grid,block>>>(alpha, x, y, size); } ※ device-code および それを呼び出すhost-codeは ~.cu に記述します
- 12. REF CLASS SAXPY : ~.h public部 namespace CUDA { public ref class Saxpy { private: … public: Saxpy(); // コンストラクタ ~Saxpy(); // デストラクタ !Saxpy(); // ファイナライザ void calculate(float alpha, cli::array<float>^ x, cli::array<float>^ y); }; } ※ C++/CLI: cli::array<float>^ は C#: float[] に相当します
- 13. REF CLASS SAXPY : ~.h private部 namespace CUDA { public ref class Saxpy { private: float* dx_; // device-memory X[] float* dy_; // device-memory Y[] size_t bsize_; // dx_/dy_の大きさ(bytes) void allocate(size_t new_bsize); // dx_/dy_を確保する void deallocate() { // dx_/dy_を解放する cudaFree(dx_); dx_ = nullptr; cudaFree(dy_); dy_ = nullptr; } … } ※利用者(C#,VB)に成り代わって device-memory を確保/解放します
- 14. namespace CUDA { Saxpy::Saxpy() : dx_(nullptr), dy_(nullptr), bsize_(0U) {} Saxpy::~Saxpy() { this->!Saxpy(); } // 明示的にファイナライザを呼ぶ Saxpy::!Saxpy() { deallocate(); } // device-mem. を解放する … } ※ ファイナライザ : !クラス名() をお忘れなく REF CLASS SAXPY : ~.cpp
- 15. namespace CUDA { void Saxpy::allocate(size_t new_bsize) { // 足りないときは一旦解放し、再確保 if ( bsize_ < new_bsize ) { deallocate(); bsize_ = new_bsize; float* ptr; cudaMalloc(&ptr, bsize_); dx_ = ptr; cudaMalloc(&ptr, bsize_); dy_ = ptr; } } } ※ cudaMalloc(&dx_, bsize_) とは書けません
- 16. namespace CUDA { void Saxpy::calculate(float alpha, array<float>^ x, array<float>^ y) { unsigned int size = x->Length; if ( size != y->Length ) return; allocate((size_t)(size*sizeof(float))); // host → device pin_ptr<float> hx = &x[0]; cudaMemcpy(dx_, hx, size*sizeof(float), cudaMemcpyHostToDevice); pin_ptr<float> hy = &y[0]; cudaMemcpy(dy_, hy, size*sizeof(float), cudaMemcpyHostToDevice); // kernel-call device_saxpy(alpha, dx_, dy_, size); // device → host cudaMemcpy(hy, dy_, size*sizeof(float), cudaMemcpyDeviceToHost); } } ※ pin_ptr<float> でピン留めします
- 17. HOW TO USE IN .NET ※ 参照設定をお忘れなく
- 18. HOW TO USE IN C# : ~.cs public partial class Form1 : Form { private CUDA.Saxpy saxpy = new CUDA.Saxpy(); // 作って private void btnCalc_Click(object sender, EventArgs e) { if ( lstX.Items.Count != lstY.Items.Count ) return; float[] x = …; float[] y = …; float alpha = …; saxpy.calculate(alpha, x, y); // 呼ぶ! … } ※ インスタンスを生成(new)し、メソッドを呼び出すだけ
- 20. namespace CUDA { public ref class SepiaConverter { public: SepiaConverter(); ~SepiaConverter(); !SepiaConverter(); // image(元画像)をcolor_にコピーし、モノクロ化 void LoadImage(System::IntPtr image, int width, int height, int stride); // モノクロ画像を色調変換し、imageにコピー void ConvertSepia(System::IntPtr image, float u, float v); … }; } ※ System::IntPtr が void* に相当します
- 21. namespace CUDA { void SepiaConverter::ConvertSepia(System::IntPtr image, float u, float v) { // 色調変換し、結果を color_ に … // 結果をコピー size_t bsize = height_ * stride_; void* ptr = static_cast<void*>(image); cudaMemcpy(ptr, color_, bsize, cudaMemcpyDeviceToHost); } } ※ System::IntPtr は void* にキャストできます
- 22. // セピア変換 private CUDA.SepiaConverter converter_; // C++/CLIで作ったwrapper private void convert_sepia(float u, float v) { // Bitmapを生成し、 LockBitsで固定 var bmp = new Bitmap(幅, 高さ); var data = bmp.LockBits(new Rectangle(0,0,bmp.Width,bmp.Height), ImageLockMode.WriteOnly, PixelFormat.Format32bppRgb); // 色調変換 converter_.ConvertSepia(data.Scan0, u, v); bmp.UnlockBits(data); picOutput.Image = bmp; picOutput.Invalidate(); } ※ IntPtr BitmapData.Scan0 が画像の先頭アドレスです