12-Step Program for Scaling Web Applications on PostgreSQL
119 likes69,153 views

The document discusses scaling a web application called Wanelo that is built on PostgreSQL. It describes 12 steps for incrementally scaling the application as traffic increases. The first steps involve adding more caching, optimizing SQL queries, and upgrading hardware. Further steps include replicating reads to additional PostgreSQL servers, using alternative data stores like Redis where appropriate, moving write-heavy tables out of PostgreSQL, and tuning PostgreSQL and the underlying filesystem. The goal is to scale the application while maintaining PostgreSQL as the primary database.


































































































12-Step Program for Scaling Web Applications on PostgreSQL
- 1. Proprietary and WHILE THE OLD PRESENTATION IS STILL AVAILABLE AFTER THIS SLIDE, I THINK YOU SHOULD SEE THE NEW ONE INSTEAD! PLEASE CLICK ON THE LINK: http://bit.ly/1MXxlBL WARNING: There is a more recent and updated version of this talk available on slideshare, it’s called: “FROM OBVIOUS TO INGENIOUS: INCREMENTALLY SCALING WEB APPLICATIONS ON POSTGRESQL” presented at
- 2. Proprietary and Confidential Konstantin Gredeskoul CTO, Wanelo.com 12-Step Program for Scaling Web Applications on PostgreSQL @kig @kigster
- 3. Proprietary and And why should you care? What does it mean, to scale on top of PostgreSQL?
- 4. Proprietary and Scaling means supporting more work load concurrently, where work is often interchanged with users But why on PostgreSQL? Because NoNoSQL is hawt! (again)
- 5. Proprietary and Relational databases are great at supporting constant change in software They are not as great in “pure scaling”, like RIAK or Cassandra So the choice critically depends on what you are trying to build
- 6. Proprietary and Large majority of web applications are represented extremely well by the relational model So if I need to build a new product or a service, my default choice would be PostgreSQL for critical data, + whatever else as needed
- 7. Proprietary and This presentation is a walk-through filled with practical solutions It’s based on a story of scaling wanelo.com to sustain 10s of thousand concurrent users, 3k req/sec Not Twitter/Facebook scale, but still… So let’s explore the application to learn a bit about wanelo for our scalability journey
- 8. Proprietary and Founded in 2010, Wanelo (“wah-nee-loh,” from Want, Need, Love) is a community and a social network for all of the world's shopping. Wanelo is a home to 12M products, millions of users, 200K+ stores, and products on Wanelo have been saved into collections over 2B times
- 9. • move fast with product development • scale as needed, stay ahead of the curve • keep overall costs low • but spend where it matters • automate everything • avoid reinventing the wheel • learn as we go • remain in control of our infrastructure Early on we wanted to:
- 10. Heroku or Not? Proprietary and Assuming we want full control of our application layer, places like Heroku aren’t a great fit But Heroku can be a great place to start. It all depends on the size and complexity of the app we are building. Ours would have been cost prohibitive.
- 11. Foundations of web apps Proprietary and • app server (we use unicorn) • scalable web server in front (we use nginx) • database (we use postgresql) • hosting environment (we use Joyent Cloud) • deployment tools (capistrano) • server configuration tools (we use chef) • programming language + framework (RoR) • many others, such as monitoring, alerting
- 12. Let’s review… Basic Web App Proprietary and /var/pgsql/data incoming http PostgreSQL Server /home/user/app/current/public nginx Unicorn / Passenger Ruby VM N x Unicorns Ruby VM • no redundancy, no caching (yet) • can only process N concurrent requests • nginx will serve static assets, deal with slow clients • web sessions probably in the DB or cookie
- 13. First optimizations: cheap early on, well worth it Proprietary and • Personalization via AJAX, so controller actions can be cached entirely using caches_action • Page returned unpersonalized, additional AJAX request loads personalization
- 14. A few more basic performance tweaks that go a long way Proprietary and • Install 2+ memcached servers for caching and use Dalli gem to connect to it for redundancy • Switch to memcached-based web sessions. Use sessions sparingly, assume transient nature • Setup CDN for asset_host and any user generated content. We use fastly.com • Redis is also an option, but I prefer memcached for redundancy
- 15. Proprietary and browser PostgreSQL Server /home/user/app/current/public nginx Unicorn / Passenger Ruby VM N x Unicorns Ruby VM memcachedCDN cache images, JS Caching goes a long way… • geo distribute and cache your UGC and CSS/JS assets • cache html and serialize objects in memcached • can increase TTL to alleviate load, if traffic spikes
- 16. Proprietary and Adding basic redundancy • Multiple app servers require haproxy between nginx and unicorn • Multiple long-running tasks (such as posting to Facebook or Twitter) require background job processing framework • Multiple load balancers require DNS round robin and short TTL (dyn.com)
- 17. Proprietary and PostgreSQL Unicorn / Passenger Ruby VM (times N) haproxy incoming http DNS round robin or failover / HA solution nginx memcached redis CDN cache images, JS Load Balancers App Servers single DB Object Store User Generated Content Sidekiq / Resque Background WorkersData stores Transient to Permanent this architecture can horizontally scale up as far the database at it’s center every other component can be scaled by adding more of it, to handle more traffic
- 18. Proprietary and As long as we can scale the data store on the backend, we can scale the app! Mostly :) At some point we may hit a limit on TCP/IP network throughput, # of connections, but this is at a whole another scale level
- 19. The traffic keeps climbing…
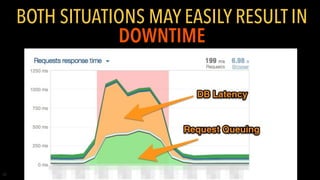
- 20. Performance limits are near Proprietary and • First signs of performance problems start creeping up • Symptoms of read scalability problems • Pages load slowly or timeout • Users are getting 503 Service Unavailable • Database is slammed (very high CPU or read IO) • Symptoms of write scalability problems • Database write IO is maxed out, CPU is not • Update operations are waiting on each other, piling up • Application “locks up”, timeouts • Replicas are not catching up • Some pages load (cached?), some don’t
- 21. Proprietary and Both situations may easily result in downtime
- 22. Proprietary and Even though we achieved 99.99% uptime in 2013, in 2014 we had a couple short downtimes caused by overloaded replica that lasted around 5 minutes. But users quickly notice…
- 23. Proprietary and
- 24. Proprietary and Perhaps not :)
- 25. Proprietary and Common patterns for scaling high traffic web applications, based on wanelo.com 12-Step Program for curing your dependency on slow application latency
- 26. Proprietary and • For small / fast HTTP services, 10-12ms or lower • If your app is high traffic (100K+ RPM) I recommend 80ms or lower What’s a good latency?
- 27. Proprietary and • RubyVM (30ms) + Garbage collection (6ms) is CPU burn, easy to scale by adding more app servers • Web services + Solr (25ms), memcached (15ms), database (6ms) are all waiting on IO CPU burn vs Waiting on IO?
- 28. Proprietary and Step 1: Add More Cache!
- 29. Moar Cache!!! Proprietary and •Anything that can be cached, should be •Cache hit = many database hits avoided •Hit rate of 17% still saves DB hits •We can cache many types of things… •Cache is cheap and fast (memcached)
- 30. Cache many types of things Proprietary and • caches_action in controllers is very effective • fragment caches of reusable widgets • we use gem Compositor for JSON API. We cache serialized object fragments, grab them from memcached using multi_get and merge them • Shopify open sourced IdentityCache, which caches AR models, so you can Product.fetch(id) https://github.com/wanelo/compositor https://github.com/Shopify/identity_cache
- 31. But Caching has it’s issues Proprietary and • Expiring cache is not easy • CacheSweepers in Rails help • We found ourselves doing 4000 memcached deletes in a single request! • Could defer expiring caches to background jobs, or use TTL if possible • But we can cache even outside of our app: we cache JSON API responses using CDN (fastly.com)
- 32. Proprietary and Step 2: Optimize SQL
- 33. SQL Optimization • Find slow SQL (>100ms) and either remove it, cache the hell out of it, or fix/rewrite the query • Enable slow query log in postgresql.conf: log_min_duration_statement = 80 log_temp_files = 0 • pg_stat_statements is an invaluable contrib module:
- 34. Fixing Slow Query Proprietary and Run explain plan to understand how DB runs the query Are there adequate indexes for the query? Is the database using appropriate index? Has the table been recently analyzed? Can a complex join be simplified into a subselect? Can this query use an index-only scan? Can “order by” column be added to the index? pg_stat_user_indexes and pg_stat_user_tables for seq scans, unused indexes, cache info
- 35. SQL Optimization, ctd Proprietary and • Instrumentation software such as NewRelic shows slow queries, with explain plans, and time consuming transactions
- 37. Proprietary and One day, I noticed lots of temp files created in the postgres.log
- 38. Proprietary and Let’s run this query… This join takes a whole second to return :(
- 39. Proprietary and • Follows table…
- 40. Proprietary and • Stories table…
- 41. Proprietary and So our index is partial, only on state = ‘active’ So this query is a full table scan… But there state isn’t used in the query, a bug? Let’s add state = ‘active’ It was meant to be there anyway
- 42. Proprietary and After adding extra condition IO drops significantly:
- 43. Proprietary and Step 3: Upgrade Hardware and RAM
- 44. Hardware + RAM Proprietary and • Sounds obvious, but better or faster hardware is an obvious choice when scaling out • Large RAM will be used as file system cache • On Joyent’s SmartOS ARC FS cache is very effective • shared_buffers should be set to 25% of RAM or 12GB, whichever is smaller • Using fast SSD disk array can make a huge difference • Joyent’s native 16-disk RAID managed by ZFS instead of controller provides excellent performance
- 45. Hardware in the cloud Proprietary and • SSD offerings from Joyent and AWS • Joyents “max” SSD node $12.9/hr • AWS “max” SSD node $6.8/hr
- 46. So who’s better? Proprietary and • JOYENT • 16 SSD drives: RAID10 + 2 • SSD Make: DCS3700 • CPU: E5-2690 2.9GHz • AWS • 8 SSD drives • SSD Make: ? • CPU: E5-2670 2.6Ghz Perhaps you get what you pay for after all….
- 47. Proprietary and Step 4: Scale Reads by Replication
- 48. Scale Reads by Replication Proprietary and • postgresql.conf (both master & replica) • These settings have been tuned for SmartOS and our application requirements (thanks PGExperts!)
- 49. How to distribute reads? Proprietary and • Some people have success using this setup for reads: app haproxy pgBouncer replica pgBouncer replica • I’d like to try this method eventually, but we choose to deal with distributing read traffic at the application level • We tried many ruby-based solutions that claimed to do this well, but many weren’t production ready
- 50. Proprietary and • Makara is a ruby gem from TaskRabbit that we ported from MySQL to PostgreSQL for sending reads to replicas • Was the simplest library to understand, and port to PG • Worked in the multi-threaded environment of Sidekiq Background Workers • automatically retries if replica goes down • load balances with weights • Was running in production
- 51. Special considerations Proprietary and • Application must be tuned to support eventual consistency. Data may not yet be on replica! • Must explicitly force fetch from the master DB when it’s critical (i.e. after a user account’s creation) • We often use below pattern of first trying the fetch, if nothing found retry on master db
- 52. Replicas can specialize Proprietary and • Background Workers can use dedicated replica not shared with the app servers, to optimize hit rate for file system cache (ARC) on both replicas PostgreSQL Master Unicorn / Passenger Ruby VM (times N) App Servers Sidekiq / Resque Background Workers PostgreSQL Replica 1 PostgreSQL Replica 2 PostgreSQL Replica 3 ARC cache warm with queries from web traffic ARC cache warm with background job queries
- 53. Big heavy reads go there Proprietary and • Long heavy queries should run by the background jobs against a dedicated replica, to isolate their effect on web traffic PostgreSQL Master Sidekiq / Resque Background Workers PostgreSQL Replica 1 • Each type of load will produce a unique set of data cached by the file system
- 54. Proprietary and Step 5: Use more appropriate tools
- 55. Leveraging other tools Proprietary and Not every type of data is well suited for storing in a relational DB, even though initially it may be convenient • Redis is a great data store for transient or semi- persistent data with list, hash or set semantics • We use it for ActivityFeed by precomputing each feed at write time. But we can regenerate it if the data is lost from Redis • We use twemproxy in front of Redis which provides automatic horizontal sharding and connection pooling. • We run clusters of 256 redis shards across many virtual zones; sharded redis instances use many cores, instead of one • Solr is great for full text search, and deep paginated sorted lists, such as trending, or related products
- 56. Proprietary and True story: applying WAL logs on replicas creates significant disk write load But we still have single master DB taking all the writes… Replicas are unable to both serve live traffic and catch up on replication. They fall behind. Back to PostgreSQL
- 57. Proprietary and When replicas fall behind, application generates errors, unable to find data it expects
- 58. Proprietary and Step 6: Move write-heavy tables out: Replace with non-DB solutions
- 59. Move event log out Proprietary and • We were appending all user events into this table • We were generating millions of rows per day! • We solved it by replacing user event recording system to use rsyslog, appending to ASCII files • We discovered from pg_stat_user_tables top table by write volume was user_events It’s cheap, reliable and scalable We now use Joyent’s Manta to analyze this data in parallel. Manta is an object store + native compute on
- 60. Proprietary and For more information about how we migrated user events to a file-based append-only log, and analyze it with Manta, please read http://wanelo.ly/event-collection
- 61. Proprietary and Step 7: Tune PostgreSQL and your Filesystem
- 62. Tuning ZFS Proprietary and • Problem: zones (virtual hosts) with “write problems” appeared to be writing 16 times more data to disk, compared to what virtual file system reports • vfsstat says 8Mb/sec write volume • So what’s going on? • iostat says 128Mb/sec is actually written to disk
- 63. Proprietary and • Turns out default ZFS block size is 128Kb, and PostgreSQL page size is 8Kb. • Every small write that touched a page, had to write 128Kb of a ZFS block to the disk Tuning Filesystem • This may be good for huge sequential writes, but not for random access, lots of tiny writes
- 64. Proprietary and • Solution: Joyent changed ZFS block size for our zone, iostat write volume dropped to 8Mb/sec • We also added commit_delay Tuning ZFS & PgSQL
- 65. Proprietary and • Many such settings are pre-defined in our open-source Chef cookbook for installing PostgreSQL from sources Installing and Configuring PG • https://github.com/wanelo-chef/postgres • It installs PG in eg /opt/local/postgresql-9.3.2 • It configures it’s data in /var/pgsql/data93 • It allows seamless and safe upgrades of minor or major versions of PostgreSQL, never overwriting binaries
- 66. Additional resources online Proprietary and • Josh Berkus’s “5 steps to PostgreSQL Performance” on SlideShare is fantastic • PostgreSQL wiki pages on performance tuning are excellent • Run pgBench to determine and compare performance of systems http://www.slideshare.net/PGExperts/five-steps-perform2013 http://wiki.postgresql.org/wiki/Performance_Optimization http://wiki.postgresql.org/wiki/Tuning_Your_PostgreSQL_Server
- 67. Proprietary and Step 8: Buffer and serialize frequent updates
- 68. Counters, counters… Proprietary and • Problem: products.saves_count is incremented every time someone saves a product (by 1) • At 100s of inserts/sec, that’s a lot of updates How can we reduce number of writes and lock contention? • Worse: 100s of concurrent requests trying to obtain a row level lock on the same popular product
- 69. Buffering and serializing Proprietary and • Sidekiq background job framework has two inter-related features: • scheduling in the future (say 10 minutes ahead) • UniqueJob extension • Once every 10 minutes popular products are updated by adding a value stored in Redis to the database value, and resetting Redis value to 0 • We increment a counter in redis, and enqueue a job that says “update product in 10 minutes”
- 70. Buffering explained Proprietary and Save Product Save Product Save Product 1. enqueue update request for product with a delay PostgreSQL Update Request already on the queue 3. Process Job Redis Cache 2. increment counter 4. Read & Reset to 0 5. Update Product
- 71. Buffering conclusions Proprietary and • If not, to achieve read consistency, we can display the count as database value + redis value at read time • If we show objects from the database, they might be sometimes behind on the counter. It might be ok…
- 72. Proprietary and Step 9: Optimize DB schema
- 73. MVCC does copy on write Proprietary and • Problem: PostgreSQL rewrites the row for most updates (some exceptions exist, ie non-indexed column, a counter, timestamp) • But we often index these so we can sort by them • Rails and Hibernate’s partial updates are not helping • Are we updating User on each request? • So updates can become expensive on wide tables
- 74. Schema tricks Proprietary and • Solution: split wide tables into several 1-1 tables to reduce update impact • Much less vacuuming required when smaller tables are frequently updated
- 75. Proprietary and Don’t update anything on each request :) id email encrypted_password reset_password_token reset_password_sent_at remember_created_at sign_in_count current_sign_in_at last_sign_in_at current_sign_in_ip last_sign_in_ip confirmation_token confirmed_at confirmation_sent_at unconfirmed_email failed_attempts unlock_token locked_at authentication_token created_at updated_at username avatar state followers_count saves_count collections_count stores_count following_count stories_count Users id email created_at username avatar state Users user_id encrypted_password reset_password_token reset_password_sent_at remember_created_at sign_in_count current_sign_in_at last_sign_in_at current_sign_in_ip last_sign_in_ip confirmation_token confirmed_at confirmation_sent_at unconfirmed_email failed_attempts unlock_token locked_at authentication_token updated_at UserLogins user_id followers_count saves_count collections_count stores_count following_count stories_count UserCounts refactor
- 76. Proprietary and Step 10: Shard Busy Tables Vertically
- 77. Vertical sharding Proprietary and • Heavy tables with too many writes, can be moved into their own separate database • For us it was saves: now @ 2B+ rows • At hundreds of inserts per second, and 4 indexes, we were feeling the pain • It turns out moving a single table (in Rails) out is a not a huge effort: it took our team 3 days
- 78. Vertical sharding - how to Proprietary and • Update code to point to the new database • Implement any dynamic Rails association methods as real methods with 2 fetches • ie. save.products becomes a method on Save model, lookup up Products by IDs • Update development and test setup with two primary databases and fix all the tests
- 79. Proprietary and Web App PostgreSQL Master (Main Schema) PostgreSQL Replica (Main Schema) Vertically Sharded Database PostgreSQL Master (Split Table) Here the application connects to main master DB + replicas, and a single dedicated DB for the busy table we moved
- 80. Vertical sharding, deploying Proprietary and Drop in write IO on the main DB after splitting off the high IO table into a dedicated compute node
- 81. Proprietary and For a complete and more detailed account of our vertical sharding effort, please read our blog post: http://wanelo.ly/vertical-sharding
- 82. Proprietary and Step 11: Wrap busy tables with services
- 83. Splitting off services Proprietary and • Vertical Sharding is a great precursor to a micro-services architecture • New service: Sinatra, client and server libs, updated tests & development, CI, deployment without changing db schema • 2-3 weeks a pair of engineers level of effort • We already have Saves in another database, let’s migrate it to a light-weight HTTP service
- 84. Adapter pattern to the rescue Proprietary and Main App Unicorn w/ Rails PostgreSQL HTTP Client Adapter Service App Unicorn w/Sinatra Native Client Adaptor • We used Adapter pattern to write two client adapters: native and HTTP, so we can use the lib, but not yet switch to HTTP
- 85. Services conclusions Proprietary and • Now we can independently scale service backend, in particular reads by using replicas • This prepares us for the next inevitable step: horizontal sharding • At a cost of added request latency, lots of extra code, extra runtime infrastructure, and 2 weeks of work • Do this only if you absolutely have to
- 86. Proprietary and Step 12: Shard Services Backend Horizontally
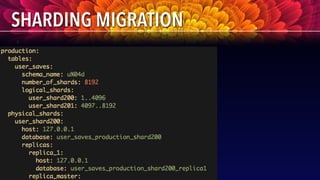
- 87. Horizontal sharding in ruby Proprietary and • We wanted to stick with PostgreSQL for critical data such as saves • Really liked Instagram’s approach with schemas • Built our own schema-based sharding in ruby, on top of Sequel gem, and open sourced it • It supports mapping of physical to logical shards, and connection pooling https://github.com/wanelo/sequel-schema-sharding
- 88. Schema design for sharding Proprietary and https://github.com/wanelo/sequel-schema-sharding user_id product_id collection_id created_at index__on_user_id_and_collection_id UserSaves Sharded by user_id product_id user_id updated_at index__on_product_id_and_user_id index__on_product_id_and_updated_at ProductSaves Sharded by product_id We needed two lookups, by user_id and by product_id hence we needed two tables, independently sharded Since saves is a join table between user, product, collection, we did not need unique ID generated Composite base62 encoded ID: fpua-1BrV-1kKEt
- 89. Spreading your shards Proprietary and • We split saves into 8192 logical shards, distributed across 8 PostgreSQL databases • Running on 8 virtual zones spanning 2 physical SSD servers, 4 per compute node • Each database has 1024 schemas (twice, because we sharded saves into two tables) https://github.com/wanelo/sequel-schema-sharding 2 x 32-core 256GB RAM 16-drive SSD RAID10+2 PostgreSQL 9.3 1 3 4 2
- 90. Proprietary and Sample configuration of shard mapping to physical nodes with read replicas, supported by the library
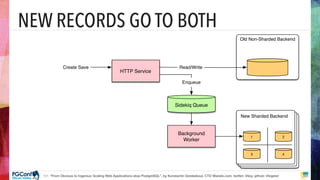
- 91. Proprietary and How can we migrate the data from old non- sharded backend to the new sharded backend without a long downtime?
- 92. New records go to both Proprietary and HTTP Service Old Non-Sharded Backend New Sharded Backend 1 3 4 2 Read/Write Background Worker Enqueue Sidekiq Queue Create Save
- 93. Proprietary and HTTP Service Old Non-Sharded Backend New Sharded Backend 1 3 4 2 Read/Write Background Worker Enqueue Sidekiq Queue Create Save Migration Script Migrate old rows We migrated several times before we got this right…
- 94. Proprietary and Swap old and new backends HTTP Service Old Non-Sharded Backend New Sharded Backend 1 3 4 2Read/Write Background Worker Enqueue Sidekiq Queue Create Save
- 95. Horizontal sharding conclusions Proprietary and • This is the final destination of any scalable architecture: just add more boxes • Pretty sure we can now scale to 1,000, or 10,000 inserts/second by scaling out • Took 2 months of 2 engineers, including migration, but zero downtime. It’s an advanced level effort and our engineers really nailed this. https://github.com/wanelo/sequel-schema-sharding
- 96. Putting it all together Proprietary and • This infrastructure complexity is not free • It requires new automation, monitoring, graphing, maintenance and upgrades, and brings with it a new source of bugs • In addition, micro-services can be “owned” by small teams in the future, achieving organizational autonomy • But the advantages are clear when scaling is one of the requirements
- 97. Proprietary and Systems Diagram incoming http requests 8-core 8GB zones haproxy nginx Fastly CDN cache images, JS Load Balancers Amazon S3 Product Images User Profile Pictures 32-core 256GB 16-drive SSD RAID10+2 Supermicro "Richmond" SSD Make: Intel DCS3700, CPU: Intel E5-2690, 2.9GHz PostgreSQL 9.2 Master Primary Database Schema 4-core 16GB zones memcached User and Product Saves, Horizontally Sharded, Replicated 32-core 256GB RAM 16-drive SSD RAID10+2 PostgreSQL 9.3 1 3 4 2 Read Replicas (non SSD) 2 4 2 1 Read Replica (SSD) PostgreSQL Async Replicas 32-core 32GB high-CPU instances Unicorn Main Web/API App, Ruby 2.0 Unicorn Saves Service haproxy pgbouncer iPhone, Android, Desktop clients Makara distributes DB load across 3 replicas and 1 master MemCached Cluster Redis Clusters for various custom user feeds, such as product feed 1-core 1GB zones twemproxy Redis Proxy Cluster 16GB high-mem 4-core zones 32 redis instances per server redis-001 redis-256 8GB High CPU zones Solr Replica 8GB High CPU zone Solr Master App Servers + Admin Servers Cluster of MemCached Servers is accessed via Dali fault tolerant library one or more can go down Apache Solr Clusters 32-core 32GB high-CPU instances Sidekiq Background Worker Unicorn Saves Service haproxy pgbouncer to DBs Solr Reads Solr Updates Background Worker Nodes redis Redis Sidekiq Jobs Queue / Bus
- 98. Systems Status: Dashboard Monitoring & Graphing with Circonus, NewRelic, statsd, nagios
- 99. Backend Stack & Key Vendors Proprietary and ■ MRI Ruby, jRuby, Sinatra, Ruby on Rails ■ PostgreSQL, Solr, redis, twemproxy memcached, nginx, haproxy, pgbouncer ■ Joyent Cloud, SmartOS, Manta Object Store ZFS, ARC Cache, superb IO, SMF, Zones, dTrace, humans ■ DNSMadeEasy, MessageBus, Chef, SiftScience ■ LeanPlum, MixPanel, Graphite analytics, A/B Testing ■ AWS S3 + Fastly CDN for user / product images ■ Circonus, NewRelic, statsd, Boundary, PagerDuty, nagios:trending / monitoring / alerting
- 100. Proprietary and We are hiring! DevOps, Ruby, Scalability, iOS & Android Talk to me after the presentation if you are interested in working on real scalability problems, and on a product used and loved by millions :) http://wanelo.com/about/play Or email [email protected]
- 101. Thanks! github.com/wanelo github.com/wanelo-chef wanelo technical blog (srsly awsm) building.wanelo.com Proprietary and @kig @kig @kigster