

![Sub Capaian Pembelajaran
● Mampu mengidentifikasi jenis data dan teknik-teknik
mempersiapkan data agar sesuai untuk diaplikasikan dengan
pendekatan data mining tertentu [C2,A3]](https://image.slidesharecdn.com/13datapreprocessinginpython-240613010148-435ec60c/85/13_Data-Preprocessing-in-Python-pptx-1-pdf-3-320.jpg)




















![7- Feature Scaling
Normalization vs. Standardization
The two most discussed scaling methods are Normalization and Standardization. Normalization typically means rescales the values into a
range of [0,1]. Standardization typically means rescales data to have a mean of 0 and a standard deviation of 1 (unit variance).](https://image.slidesharecdn.com/13datapreprocessinginpython-240613010148-435ec60c/85/13_Data-Preprocessing-in-Python-pptx-1-pdf-26-320.jpg)






























Ad
More Related Content
Similar to 13_Data Preprocessing in Python.pptx (1).pdf (20)
Recently uploaded (20)


















Ad
13_Data Preprocessing in Python.pptx (1).pdf
- 1. Data Preprocessing Using Python 14620313 DATA MINING
- 2. Universitas 17 Agustus 1945 Teknik Informatika PENGAMPU Dr. Fajar Astuti Hermawati, S.Kom.,M.Kom. Bagus Hardiansyah, S.Kom.,M.Si Ir. Sugiono, MT Naufal Abdillah, S.Kom., M.Kom. Siti Mutrofin, S.Kom., M.Kom.
- 3. Sub Capaian Pembelajaran ● Mampu mengidentifikasi jenis data dan teknik-teknik mempersiapkan data agar sesuai untuk diaplikasikan dengan pendekatan data mining tertentu [C2,A3]
- 4. Indikator ● 2.3 Ketepatan mengidentifikasi konsep dan melakukan data preprocessing agar sesuai dengan teknik data mining
- 5. Outline ● Data Preprocessing Using Python
- 6. 1- Acquire the dataset ● Acquiring the dataset is the first step in data preprocessing in machine learning. To build and develop Machine Learning models, you must first acquire the relevant dataset. This dataset will be comprised of data gathered from multiple and disparate sources which are then combined in a proper format to form a dataset. Dataset formats differ according to use cases. For instance, a business dataset will be entirely different from a medical dataset. While a business dataset will contain relevant industry and business data, a medical dataset will include healthcare-related data.
- 7. 2- Import all the crucial libraries ● The predefined Python libraries can perform specific data preprocessing jobs. Importing all the crucial libraries is the second step in data preprocessing in machine learning.
- 8. 3- Import the dataset ● In this step, you need to import the dataset/s that you have gathered for the ML project at hand. Importing the dataset is one of the important steps in data preprocessing in machine learning.
- 9. 4- Identifying and handling the missing values ● In data preprocessing, it is pivotal to identify and correctly handle the missing values, failing to do this, you might draw inaccurate and faulty conclusions and inferences from the data. Needless to say, this will hamper your ML project. some typical reasons why data is missing: ● A. User forgot to fill in a field. ● B. Data was lost while transferring manually from a legacy database. ● C. There was a programming error. ● D. Users chose not to fill out a field tied to their beliefs about how the results would be used or interpreted. ● Basically, there are two ways to handle missing data: ● Deleting a particular row – In this method, you remove a specific row that has a null value for a feature or a particular column where more than 75% of the values are missing. However, this method is not 100% efficient, and it is recommended that you use it only when the dataset has adequate samples. You must ensure that after deleting the data, there remains no addition of bias. Calculating the mean – This method is useful for features having numeric data like age, salary, year, etc. Here, you can calculate the mean, median, or mode of a particular feature or column or row that contains a missing value and replace the result for the missing value. This method can add variance to the dataset, and any loss of data can be efficiently negated. Hence, it yields better results compared to the first method (omission of rows/columns). Another way of approximation is through the deviation of neighbouring values. However, this works best for linear data.
- 10. 4- Identifying and handling the missing values
- 11. 4- Identifying and handling the missing values ● Solution 1 : Dropna
- 12. 4- Identifying and handling the missing values ● Solution 1 : Dropna
- 13. 4- Identifying and handling the missing values ● Solution 2 : Fillna
- 14. 4- Identifying and handling the missing values ● Solution 3 : SciKit Learn
- 15. 5- Encoding the categorical data Categorical data refers to the information that has specific categories within the dataset. In the dataset cited above, there are two categorical variables – country and purchased. Machine Learning models are primarily based on mathematical equations. Thus, you can intuitively understand that keeping the categorical data in the equation will cause certain issues since you would only need numbers in the equations.
- 16. 5- Encoding the categorical data Solution 1 : ColumnTransformer
- 17. 5- Encoding the categorical data Solution 2 : Pd.get_dummies()
- 18. 5- Encoding the categorical data Solution 3 : Label Encoder
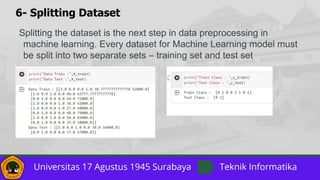
- 19. 6- Splitting Dataset Splitting the dataset is the next step in data preprocessing in machine learning. Every dataset for Machine Learning model must be split into two separate sets – training set and test set
- 20. 7- Feature Scaling ● Feature scaling marks the end of the data preprocessing in Machine Learning. It is a method to standardize the independent variables of a dataset within a specific range. In other words, feature scaling limits the range of variables so that you can compare them on common grounds. Another reason why feature scaling is applied is that few algorithms like gradient descent converge much faster with feature scaling than without it
- 21. 7- Feature Scaling ● Why Feature Scaling? Most of the times, your dataset will contain features highly varying in magnitudes, units and range. But since, most of the machine learning algorithms use Eucledian distance between two data points in their computations, this is a problem.If left alone, these algorithms only take in the magnitude of features neglecting the units. The results would vary greatly between different units, 5kg and 5000gms. The features with high magnitudes will weigh in a lot more in the distance calculations than features with low magnitudes.
- 22. 7- Feature Scaling ● Min Max Scaler? MinMax Scaler shrinks the data within the given range, usually of 0 to 1. It transforms data by scaling features to a given range. It scales the values to a specific value range without changing the shape of the original distribution.
- 23. 7- Feature Scaling ● Min Max Scaler
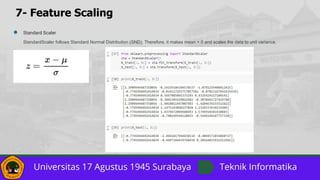
- 24. 7- Feature Scaling ● Standard Scaler StandardScaler follows Standard Normal Distribution (SND). Therefore, it makes mean = 0 and scales the data to unit variance.
- 25. 7- Feature Scaling When to Use Feature Scalling? k-nearest neighbors with an Euclidean distance measure is sensitive to magnitudes and hence should be scaled for all features to weigh in equally. Scaling is critical, while performing Principal Component Analysis(PCA). PCA tries to get the features with maximum variance and the variance is high for high magnitude features. This skews the PCA towards high magnitude features. We can speed up gradient descent by scaling. This is because θ will descend quickly on small ranges and slowly on large ranges, and so will oscillate inefficiently down to the optimum when the variables are very uneven. Tree based models are not distance based models and can handle varying ranges of features. Hence, Scaling is not required while modelling trees. Algorithms like Linear Discriminant Analysis(LDA), Naive Bayes are by design equipped to handle this and gives weights to the features accordingly. Performing a features scaling in these algorithms may not have much effect.
- 26. 7- Feature Scaling Normalization vs. Standardization The two most discussed scaling methods are Normalization and Standardization. Normalization typically means rescales the values into a range of [0,1]. Standardization typically means rescales data to have a mean of 0 and a standard deviation of 1 (unit variance).