






![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=560&fit=bounds)



![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=560&fit=bounds)










![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=560&fit=bounds)



Ad
More Related Content
What's hot (20)
Similar to 20180427 arXivtimes 勉強会: Cascade R-CNN: Delving into High Quality Object Detection (20)










![[DL輪読会]Differentiable Mapping Networks: Learning Structured Map Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/differentiablemappingnetworks-200707033539-thumbnail.jpg?width=560&fit=bounds)




![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=560&fit=bounds)


Ad
20180427 arXivtimes 勉強会: Cascade R-CNN: Delving into High Quality Object Detection
- 1. 〒163-0515 東京都新宿区西新宿1-26-2 新宿野村ビル15F TEL:03-5909-7510 FAX:03-5909-7569 www.albert2005.co.jp/ 清水 駿介 2018/04/23 arXivtimes 勉強会
- 2. Copyright(C) ALBERT Inc. All Rights Reserved. 1 概要 • 従来: Anchor→Region Proposal Network→Detector (2-stage 系) Anchor→ → → → → → → → → → → Detector (1-stage 系) • コレ: Anchor→Region Proposal Network→Detector→Detector→Detector 高い IoU (Intersection over Union = boxp ∩ boxt / boxp ∪ boxt ) を実現! そもそも detector って?(Fast R-CNN 以降を前提) • 粗いボックス予測とボックスがある位置にだいたい対応する特徴量マップを受 け取って、より正確なボックス予測とクラス予測を行う • N 種類のオブジェクトがある場合、背景含めて N+1 クラスの予測となる • 位置が少しでもずれてたら背景だ、とやってるとロクに学習できないため、位 置ズレに甘くする(IoU=0.5)ことが多く、高精度な位置検出はつらい
- 3. Copyright(C) ALBERT Inc. All Rights Reserved. 2 出力例(non maximum suppression なし) • 最初の detector は IoU=0.5 以上ならブツ があると学習する • 次の detector には IoU=0.6 以上を要求 • 最後の detector は IoU=0.7 よ • ピッタシ囲えてない ボックスさんが消される 論文 Figure 1 を引用
- 4. Copyright(C) ALBERT Inc. All Rights Reserved. 3 複数の detector を使う理由 • 一つの detector があらゆる IoU に対して最高性能を出すことはない • 低い IoU でも合格にしていると、高い IoU での位置予測はできない • 高い IoU のみ合格にしていると、低い IoU で取りあえず検出、が困難 • 位置予測精度が高い detector は、ボックス位置の事前情報にも高精度を要求 • ハズレの割合が極端に多いとクラス分類器がまともにに学習しない • Focal loss を使ったり、YOLO 系のように物体があるかどうかの 2 クラ ス分類と N クラス分類を分離したりで、ある程度の対処はできるが → IoU の閾値が異なる複数の detector を用意し、閾値が低い detector が 出すボックスを次の detector に投入(IoU が上がっていく様子はFig. 4 参照)
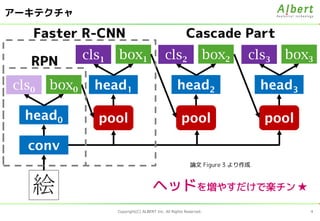
- 5. Copyright(C) ALBERT Inc. All Rights Reserved. 4 アーキテクチャ conv 絵 pool box1cls1 head1box0cls0 head0 pool box2cls2 head2 pool box3cls3 head3 RPN Faster R-CNN Cascade Part 論文 Figure 3 より作成 ヘッドを増やすだけで楽チン ★
- 6. Copyright(C) ALBERT Inc. All Rights Reserved. 5 ネットワーク構成 Feature Pyramid Network 解説の神画像があり、わたしの言うことがなかった https://medium.com/@jonathan_hui/understanding-feature-pyramid-networks-for- object-detection-fpn-45b227b9106c conv head0 head1 ResNet の右側にあるのは全部 256 channels 7x7 マップを適当な解像度の P 層から切出す (この論文ではROI Align が利用されている) 1024 フィルタの FC→ReLU 過度に凝らないシンプルな構成
- 7. Copyright(C) ALBERT Inc. All Rights Reserved. 6 ロス関数・学習など詳細 • 著者実装 (Caffe): https://github.com/zhaoweicai/cascade-rcnn • 𝐿𝑙𝑜𝑐 = 𝑠𝑚𝑜𝑜𝑡ℎ 𝐿1 Δ 𝒈, 𝒃 , 𝑤ℎ𝑒𝑟𝑒 Δ 𝒈, 𝒃 = 𝛿 𝑥, 𝛿 𝑦, 𝛿 𝑤, 𝛿ℎ , 𝛿 𝑥 = 𝑔 𝑥 − 𝑏 𝑥 𝑏 𝑤 , 𝛿 𝑦 = 𝑔 𝑦 − 𝑏 𝑦 𝑏ℎ , 𝛿 𝑤 = log 𝑔 𝑤 𝑏 𝑤 , 𝑎𝑛𝑑 𝛿ℎ = log 𝑔ℎ 𝑏ℎ . さらに Δ を batch normalizationする。RPN, detector 両方ともコレ。 • 𝐿 𝑐𝑙𝑠はクロスエントロピー。RPN は 2 クラス、detector は N+1 クラス。 • RPN は物体にアンカーが IoU>0.7 で被るか IoU 最大かであれば当たり。 • 3 人の detector たちはそれぞれ IoU 0.5, 0.6, 0.7 以上でボックスが物 体に被るなら物体のクラスを言い当て、然らずんば背景。 • 8 GPU に画像 1 枚ずつ。当然 CNN の batch normalization は凍結。 • 180k iters on COCO2015 (~43 epochs)
- 8. Copyright(C) ALBERT Inc. All Rights Reserved. 7 ベンチマーク結果 • FPN+ w/ ResNet-101 で最高性能、これの test-dev の結果が正式なもの • FPN+ は Feature Pyramid Network に ROI Align を導入したもの • すべてのテストで cascade により大きな速度低下を起こさず高性能を実現 • (個人的推測)特に大きいオブジェクトに有効なのは一段では受容野が狭いから?