[CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation
Download as PPTX, PDF8 likes2,044 views

2020年7月4日 第三回 全日本コンピュータビジョン勉強会 CVPR2020読み会@オンライン(前編) 3D Packing for Self-Supervised Monocular Depth Estimation





![Mobility Technologies Co., Ltd.
Tutorial on Monocular Depth Estimation @ CVPR2020
6
■ 単眼カメラ映像からのデプス推定に関するチュートリアル
■ Stereo supervision
■ Monocular supervision
■ Understanding single image depth estimation
■ Auxiliary supervision
■ Learning single image depth estimation in the wild
■ Mobile depth estimation
■ スライドおよび講演ビデオが公開 [link]](https://image.slidesharecdn.com/202007043dpackingforself-supervisedmonoculardepthestimation-200704035538/85/CVPR2020-CV-3D-Packing-for-Self-Supervised-Monocular-Depth-Estimation-6-320.jpg)


































![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=560&fit=bounds)
![[第2回3D勉強会 研究紹介] Neural 3D Mesh Renderer (CVPR 2018)](https://cdn.slidesharecdn.com/ss_thumbnails/201807263dv-180728060959-thumbnail.jpg?width=560&fit=bounds)
![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=560&fit=bounds)




![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...](https://cdn.slidesharecdn.com/ss_thumbnails/deeplabv3-180309001425-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields](https://cdn.slidesharecdn.com/ss_thumbnails/realtimemultipersonposeestimation1-170907054459-thumbnail.jpg?width=560&fit=bounds)


![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=560&fit=bounds)



![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=560&fit=bounds)
![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=560&fit=bounds)







Ad
More Related Content
What's hot (20)
Similar to [CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation (20)





![[DL輪読会]An Image is Worth 16x16 Words: Transformers for Image Recognition at S...](https://cdn.slidesharecdn.com/ss_thumbnails/dl10161-201016015214-thumbnail.jpg?width=560&fit=bounds)












Ad
More from Kazuyuki Miyazawa (11)











Ad
[CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation
- 1. Mobility Technologies Co., Ltd. 2020年7月4日 全日本コンピュータビジョン勉強会 3D Packing for Self-Supervised Monocular Depth Estimation 株式会社Mobility Technologies 宮澤 一之
- 2. Mobility Technologies Co., Ltd. 宮澤 一之 AI技術開発部 グループリーダー 株式会社Mobility Technologies 経歴 2019年4月〜2020年3月 AI研究開発エンジニア@DeNA 2010年4月〜2019年3月 主任研究員@三菱電機 2010年3月 博士(情報科学)@東北大学 自己紹介 2 @kzykmyzw
- 3. Mobility Technologies Co., Ltd. 紹介論文 3 CVPR2020 Open Access GitHub
- 4. Mobility Technologies Co., Ltd.4 Unsupervised CNN: Geometry to the Rescue MonoDepth SfMLearner SfM-Net vid2depth Deep-VO-Feat GeoNet LEGO MonoDepth2 Every Pixel Counts Depth from Videos in the Wild Depth Depth + Egomotion Depth + Egomotion + Object Motion Depth + Egomotion + Object Motion + Camera Intrinsic struct2depth (extended) struct2depth SfMLearner++ Every Pixel Counts++ SceneNet 2016 2017 2018 2019 2020 Explainability Monocular Depth Estimation Visualization of CNN for mono-Depth Estimation How do NNs see depth in single images? Uncertainty of Self supervised mono- Depth Estimation PackNet-SfM SuperDepth SC-SfMLearner DualNetworks
- 5. Mobility Technologies Co., Ltd.5 Unsupervised CNN: Geometry to the Rescue MonoDepth SfMLearner SfM-Net vid2depth Deep-VO-Feat GeoNet LEGO MonoDepth2 Every Pixel Counts Depth from Videos in the Wild Depth Depth + Egomotion Depth + Egomotion + Object Motion Depth + Egomotion + Object Motion + Camera Intrinsic struct2depth (extended) struct2depth SfMLearner++ Every Pixel Counts++ SceneNet 2016 2017 2018 2019 2020 Explainability Monocular Depth Estimation Visualization of CNN for mono-Depth Estimation How do NNs see depth in single images? Uncertainty of Self supervised mono- Depth Estimation PackNet-SfM SuperDepth SC-SfMLearner DualNetworks
- 6. Mobility Technologies Co., Ltd. Tutorial on Monocular Depth Estimation @ CVPR2020 6 ■ 単眼カメラ映像からのデプス推定に関するチュートリアル ■ Stereo supervision ■ Monocular supervision ■ Understanding single image depth estimation ■ Auxiliary supervision ■ Learning single image depth estimation in the wild ■ Mobile depth estimation ■ スライドおよび講演ビデオが公開 [link]
- 7. Mobility Technologies Co., Ltd. ■ 単眼映像を使った教師なし学習によるデプスとエゴモーション推定の先駆け ■ 別視点画像を生成する処理を微分可能にし、学習プロセスに組み込み SfMLearner 7 Tinghui Zhou, et al., “Unsupervised Learning of Depth and Ego-Motion from Video,” CVPR2017
- 8. Mobility Technologies Co., Ltd. SfMLearner 8 Depth CNN:ターゲット画像からデプスマップを生成 Tinghui Zhou, et al., “Unsupervised Learning of Depth and Ego-Motion from Video,” CVPR2017
- 9. Mobility Technologies Co., Ltd. SfMLearner 9 Pose CNN:ソース画像とターゲット画像間の相対的なカメラ運動を推定 Tinghui Zhou, et al., “Unsupervised Learning of Depth and Ego-Motion from Video,” CVPR2017
- 10. Mobility Technologies Co., Ltd. View Synthesis as Supervision 10 I1 IN It Is View Synthesis Objective学習用映像 画素 ターゲット画像 ソース画像をターゲット画像の視点にワープした画像 ■ 推定したデプスとカメラ運動を使ってソース画像をターゲット画像の視点にワ ープさせることで新たな画像を生成 ■ ターゲット画像と生成画像の誤差をロスとすることで教師なしで学習
- 11. Mobility Technologies Co., Ltd. SfMLearnerによるデプス推定結果 11 デプスの解像度が低い
- 12. Mobility Technologies Co., Ltd. 紹介論文 12
- 13. Mobility Technologies Co., Ltd. ■ Main contribution ■ 高解像度なデプス推定を実現するためのアーキテクチャPackNetを提案 ■ packing/unpackingにより画像が持つ空間情報を最大限活用しつつリアルタイム処理を実現 ■ Second contribution ■ 単眼デプス推定におけるスケールの不定性という課題を解決 ■ 車やロボット、スマホから得られる速度情報を利用したロスを導入 ■ Third contribution ■ 最大250mの長距離LiDARにより収集した新たなデータセットを公開 ■ アメリカに加え日本でもデータを取集 Contributions 13
- 14. Mobility Technologies Co., Ltd. PackNet-SfM 14
- 15. Mobility Technologies Co., Ltd. target image It set of source images Is ∈ IS (実装では It-1, It+1) estimated depth Dt synthesized target image It 目的関数 15 ^ ^
- 16. Mobility Technologies Co., Ltd. target image It set of source images Is ∈ IS (実装では It-1, It+1) estimated depth Dt synthesized target image It Appearance Matching Loss 16 ^ ^ オクルージョンの影響を軽減するためそれぞれのソー ス画像に対して求めたロスの画素ごとの最小値を採用 推定したデプスによりソース画像をターゲット画像と 一致するようにワープさせた際の誤差(ワープ画像と ターゲット画像間のSSIMとL1ロスの重み付き和)
- 17. Mobility Technologies Co., Ltd. target image It set of source images Is ∈ IS (実装では It-1, It+1) estimated depth Dt synthesized target image It Appearance Matching Loss 17 ^ ^ ワープ対象領域外を 除外するマスク ワープによって逆に誤差が大きくなる領域を除外する マスク(静止シーンやカメラと等速で運動する物体を 除外するため)
- 18. Mobility Technologies Co., Ltd. target image It set of source images Is ∈ IS (実装では It-1, It+1) estimated depth Dt synthesized target image It Depth Smoothness Loss 18 ^ ^ テクスチャの少ない領域では滑らかなデプスとな るように制御するためのロス(画素勾配が小さい 場合にデプス勾配が大きくなるとペナルティも大 きくなる) 画素勾配 デプス勾配
- 19. Mobility Technologies Co., Ltd. ■ Main contribution ■ 高解像度なデプス推定を実現するためのアーキテクチャPackNetを提案 ■ packing/unpackingにより画像が持つ空間情報を最大限活用しつつリアルタイム処理を実現 Contributions 19
- 20. Mobility Technologies Co., Ltd. PackNet 20 画像 It デプス Dt Conv2D Packing Residual Block Unpacking ^
- 21. Mobility Technologies Co., Ltd. Packing 21
- 22. Mobility Technologies Co., Ltd. Packing 22 Ci x H x W 4Ci x H/2 x W/2 D x 4Ci x H/2 x W/2 4DCi x H/2 x W/2 Co x H/2 x W/2 ■ poolingを使わず空間情報の損失を回避 ■ 空間方向 → チャネル方向変換+Conv3D ■ 逆順にすることでunpacking
- 23. Mobility Technologies Co., Ltd. ■ 入力画像を再構成するencoder-decoderを学習 ■ poolingとバイリニア補間によるアップサンプルでは再構成画像がぼやける ■ packing/unpackingを利用した場合はほぼ完全に入力画像を再構成可能 Packingの効果 23 入力画像 Max Pooling + Bilinear Upsample Pack + Unpack
- 24. Mobility Technologies Co., Ltd. ■ Second contribution ■ 単眼デプス推定におけるスケールの不定性という課題を解決 ■ 車やロボット、スマホから得られる速度情報を利用したロスを導入 Contributions 24
- 25. Mobility Technologies Co., Ltd. ■ 推定するフレーム間の並進ベクトルの絶対値にロスを定義 ■ 車両の速度を教師信号として利用し、速度と時刻から算出したフレーム間の移 動量を真値として与える Velocity Supervision Loss 25 target image It source image Is tt → s ^ フレーム間の並進ベクトル 速度 フレーム間の時刻差
- 26. Mobility Technologies Co., Ltd. Experiments 26 ■ KITTI ■ train / val / eval:39,810 / 4,424 / 697フレーム ■ 5フレーム分のLiDAR点群を集約し真値デプスマップをrefine:652フレーム ■ NuScenes ■ KITTIで学習したモデルで推論することで汎化性能を評価:6,019フレーム ■ CityScapes ■ KITTIでの学習前にpretrainingとして利用:88,250フレーム ■ KITTIと同パラメータで20エポック学習 ■ DDAD ■ 長距離LiDARを用いて独自にデータセットを構築 ■ train / eval:17,050 / 4,150フレーム
- 27. Mobility Technologies Co., Ltd. ■ Third contribution ■ 最大250mの長距離LiDARにより収集した新たなデータセットを公開 ■ アメリカに加え日本でもデータを取集 Contributions 27 https://github.com/TRI-ML/DDAD
- 28. Mobility Technologies Co., Ltd. DDAD (Dense Depth for Autonomous Driving) 28 ■ カメラ6台(1936 x 1216)+ デプスマップ(train/val = 17,050/4,150 frames) ■ デプスはLuminar社製のLuminar-H2で取得しており最大250m(従来は約80m) ■ アメリカ(ベイエリア、デトロイト、アナーバー)と日本(東京、お台場)で収集 https://github.com/TRI-ML/DDAD
- 29. Mobility Technologies Co., Ltd. ■ ResNetベースの従来手法Monodepth2とデプスマップ(640 x 384)の精度を比較 ■ 複数の評価尺度の全てにおいてPackNet-SfMはMonodepth2を上回る ■ 距離ごとの精度比較では遠方になるほどPackNet-SfMが優勢となる DDADにおけるデプス推定精度 29 *1 *2 *3 *4 *5 *1 Absolute relative difference *2 Squared relative difference *3 Root Mean Squared Error (linear) *4 Root Mean Squared Error (log) *5 Inlier ratio (pred / ground truth < 1.25)
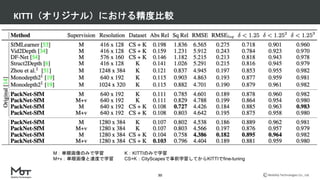
- 30. Mobility Technologies Co., Ltd. KITTI(オリジナル)における精度比較 30 M:単眼画像のみで学習 M+v:単眼画像と速度で学習 K:KITTIのみで学習 CS+K:CityScapesで事前学習してからKITTIでfine-tuning
- 31. Mobility Technologies Co., Ltd. KITTI(オリジナル)における精度比較 31 M:単眼画像のみで学習 M+v:単眼画像と速度で学習 K:KITTIのみで学習 CS+K:CityScapesで事前学習してからKITTIでfine-tuning データ投入で精度改善
- 32. Mobility Technologies Co., Ltd. KITTI(オリジナル)における精度比較 32 M:単眼画像のみで学習 M+v:単眼画像と速度で学習 K:KITTIのみで学習 CS+K:CityScapesで事前学習してからKITTIでfine-tuning デプス高解像度化で精度改善
- 33. Mobility Technologies Co., Ltd. KITTI(高精度版*)における比較 33 *5フレーム分の結果を集約することで真値を高精度化 D:真値デプスで教師あり学習
- 34. Mobility Technologies Co., Ltd. KITTI(高精度版*)における比較 34 *5フレーム分の結果を集約することで真値を高精度化 D:真値デプスで教師あり学習
- 35. Mobility Technologies Co., Ltd. 各手法によるデプスマップの比較 35
- 36. Mobility Technologies Co., Ltd. ■ パラメータ数を増やしていった場合、ResNetは約70Mで改善が頭打ち ■ PackNetはパラメータ数を増やすことでコンスタントに性能が改善していく ■ デプスマップを高解像化することによる改善効果もPackNetの方が顕著 パラメータ数と精度の関係 36 MR: 640 x 192 HR: 1280 x 384 60ms on Titan V100 (< 30ms using TensorRT)
- 37. Mobility Technologies Co., Ltd. ■ packing/unpackingおよびConv3Dの導入による性能改善が顕著 ■ ResNetベースの手法はImageNetによるpretrainingの効果が大きいのに対し、 PackNetはフルスクラッチでの学習でより高い精度を達成 Ablation Study 37 ImageNet pretraining → ImageNet pretraining → packing/unpackingを 畳み込みのストライド とアップサンプリング に置き換え → Conv3Dのフィルタ 数を増加(D=0は Conv3D未使用)
- 38. Mobility Technologies Co., Ltd. ■ CityScapesとKITTIで学習したモデルを使ってNuScenesに対する性能を評価 ■ ImageNetでpretrainingしたResNetベースの手法よりも高い汎化性能 未知データに対する汎化性能 38
- 39. Mobility Technologies Co., Ltd. ■ ロスに対する工夫などが多かった従来手法に対し、新しいアーキテクチャを提 案することで高解像度なデプスマップ生成を実現 ■ packing/unpackingとConv3Dにより空間方向の情報を最大限活用 ■ 容易に取得可能なカメラの移動速度を教師信号とすることでスケールの不定性 という単眼デプス推定における根本的な問題を解決 ■ 次世代LiDARを使った長距離デプス(〜250m)データセットを独自に構築 まとめ 39 2017201820192020