Data Applications and Infrastructure at LinkedIn__HadoopSummit2010
98 likes7,797 views

The document discusses LinkedIn's data infrastructure and applications, highlighting their data-centric engineering approach and the importance of relevance in data products. Key technologies and systems, including Hadoop jobs, machine learning models, and various tools for managing data deployment and processing, are identified. It emphasizes the need for efficient operations management, data accessibility, and the evolving nature of data product teams within LinkedIn.




















Data Applications and Infrastructure at LinkedIn__HadoopSummit2010
- 1. Data Applications and Infrastructure at LinkedIn Jay Kreps LinkedIn
- 2. Plan `whoami` Data products Data infrastructure
- 3. Data-centric engineering at LinkedIn LinkedIn’s Search Network & Analytics team Domain: Derived data Products Search People you may know Social graph services Job matching Collaborative filtering Infrastructure
- 4. People You May Know
- 6. People You May Know 120 billion relationships scored...every day 82 hadoop jobs (not counting ETL) Around 16TB of intermediate data Machine learning model to predict probability of connection Bloom filter's for approximate filtering joins (10x perf improvement) About ~5 test algorithms per week 2 engineers
- 7. Relevance Products You must fly entirely by the instruments Scale and relevance very closely linked More is often better Iteration time is essential UI matters, really We threw out custom non-hadoop code that was faster Opportunity to work directly on the business
- 8. Infrastructure as an Ecosystem Isolated infrastructure team is usually a bad solution Too isolated from the problems Data product team has crushing problems This area is extremely immature People should want to use it Treat it like a product Either make money off it or give it away Open source is a great solution Custom software should be the best
- 9. Open Source Zoie – Faceted Search Bobo – Real-time search indexing Decomposer – Very large matrix decomposition routines (now in Mahout) Norbert – Partition aware cluster management & RPC Voldemort – Key/Value storage Kamikaze – Compression package Sensei – Distributed search Azkaban – Hadoop workflow
- 10. Azkaban workflow = cron + make
- 11. Azkaban workflow:hadoop :: web framework:webapp
- 12. Azkaban
- 13. Azkaban Examples Example job source: Example workflow UI
- 14. Workflow
- 15. Azkaban 82 jobs running every day just for PYMK ...need to run in the right order … need to restart from failure … need to enforce dependencies GUI is important for operations alerting, resource locking, config management, etc deployable zip files of code represent a job flow everyone works independently, releases/deploys independently simple text files for config (but can use GUI in a pinch) aggregate logs, run times restart from point of failure
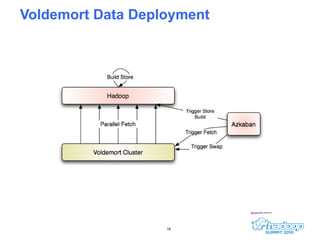
- 16. Data Deployment How do you get your multi-billion edge probabilistic relationship graph to the live website to serve queries?
- 17. Voldemort LinkedIn had many prior passes at this problem, all bad MySQL Oracle Etc. Fully distributed, partitioned, decentralized key-value storage Supports pluggable storage engines Online/offline cycle Is this a good fit?
- 19. Voldemort Data Deployment Building a multi TB lookup structure is really, really hard work...it is a batch operation Solution: build this structure in hadoop Tradeoff: build time vs lookup time Minimal perfect hashing requires only 2.5 bits per key, but is slow to build Sorted indexes are a fast, simple alternative Build is a no-op map/reduce (just sorting) Data load will saturate the network even for small cluster Voldemort gives failover load balancing monitoring remote access partitioning
- 20. Voldemort Data Deployment If data takes 24 hours to generate, it may take 24 hours to fix Need a faster rollback strategy Cold disk space is cheap Store the live copy Store the copy currently being updated Store N backup copies “ Atomic” swap Cache needs to start warm I/O network throttling to limit impact of deployment Our prod latency is < 3 ms from the client side 900GB store takes ~1:30 to build on 45 node dev cluster
- 21. Questions?
Editor's Notes
- #2: This is the Title slide. Please use the name of the presentation that was used in the abstract submission.
- #3: This is the agenda slide. There is only one of these in the deck.
- #4: Why linkedin cares about derived data Why it is hard
- #5: Talk about what you can do
- #7: if you get bad results, I claim you are in an unsuccessful test! Still a small percentage of the quadrillion possible relationships (pairwise is hard)
- #8: What we learned
- #11: Azk is a workflow scheduler? What is workflow?
- #14: Samurai rule Logic is in jobs, not job descriptor Jobs are independent Work – viz, polish
- #22: This is the final slide; generally for questions at the end of the talk. Please post your contact information here.