A Gentle Introduction to Microsoft SSAS
9 likes12,805 views

This document provides an overview of Analysis Services and how to create an OLAP cube. It discusses why data is stored in cubes rather than tables, including better query performance, efficient storage and calculations. It then outlines the steps to create an Analysis Services project, define data sources and dimensions, create and process the cube, and optimize query performance through partitioning and pre-aggregating data.




































![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=560&fit=bounds)




























Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to A Gentle Introduction to Microsoft SSAS (20)




















Ad
A Gentle Introduction to Microsoft SSAS
- 2. Analysis Services Overview Part of the Business Intelligence Development Studio • Included with the SQL Server License • Special version of Visual Studio • Microsoft’s application for creating multidimensional OLAP databases which are queried with the MDX language • Microsoft’s powerful data mining platform. Includes sophisticated algorithms that can operate on relational or OLAP data • This presentation demonstrates the creation of an OLAP database, also called a cube 2
- 3. Why Store Data in a Cube? Analysis services, like the SQL Server relational database, is a platform for storing data. But unlike the relational database, it does not store data in tables–it is stored in other types of structures comprising a cube. Why store data in cubes instead of tables? There are a number of reasons: • better query performance • fast, optimized aggregations calculations • more efficient storage of data through its simplified read-oriented design • richer calculation possibilities, supporting stored measures, calculated measures, and key performance indicators (KPI) • an easier to understand data model for the end user. OLAP data is engineered to provide dimensional data views, hierarchical browsing, attribute-based breakouts and filtering. And OLAP data does not require or even use table joins! 3
- 4. Creating an Analysis Services (OLAP) Database Creating an analysis services database consists of creating the database structure, then populating those structures with data from external data sources. The structures comprising an OLAP cube include: • Dimensions and their associated elements – Hierarchies – Attributes • Measures and their associated elements – Stored Measures – Calculated Measures – Measure Groups – Key Performance Measures (KPI) – Measure Profiles 4
- 5. Development Steps 1. Create Analysis Services Project 2. Create Data Source 3. Create Data Source View 4. Create cube object definitions 5. Deploy definitions to OLAP server and load in data 6. Specify partitions and aggregations 5
- 6. Open BIDS and create a new Analysis Services Project… 6
- 7. Create a data source and a data source view In the data source you identify the relational data warehouse (DW) that hosts the source data and provide the connection information. In the data source view, you specify which the tables in the DW you want to use to supply data to the cube. If the DW has been designed using the classic star schema or snowflake approaches, the SSAS cube wizard can examine the DW’s structure and derive a cube definition from it, making your job easier. When the initial design from the wizard is complete you can go back and make modifications, for example, you can add or modify hierarchies and attribute relationships. Once you have the cube design you want, you load the data in. 7
- 8. In this illustration, all tables from the star schema DW are used, only the sysdiagrams table (which holds the database diagram data) remains unselected. 8
- 9. Once you have defined the data source view, you can inspect the schema. By right clicking on a table, you can browse the data and define derived columns. But at this point, we still have no OLAP database. The creation of the OLAP database begins with creating a cube. 9
- 10. Creating the Cube Structure 1. With the data source view in place, you are now ready to create the cube. Right click on the cubes folder and select “New Cube.” This launches the cube wizard. 2. Make sure the wizard has correctly identified which are dimension and which are fact tables and tell it which table contains the data for the time dimension. 10
- 11. Setting the Time Dimension Parameters Time is a unique dimension with inherent assumptions about how it should work. You identify the time dimension as such so that the MDX functions (such as PrevMember and ParallelPeriod) specific to it will work. You also tell which of the source data columns map to well known time concepts such as years, quarters, and months. 11
- 12. After defining the time properties, the wizard displays the measures that it defined. Here you can select which ones you want to keep. I am keeping all of them in this illustration. The “Fact Units Count” measure counts the number of records in the source table. This information is used in optimizing the aggregation process. In the Review New Dimensions panel the dimensions that were created along with their hierarchies and attributes are displayed. 12
- 13. A cube has now been defined. This panel lets you review the data model (UDM) that has been created. 13
- 14. Completing the wizard, you give the cube a name. 14
- 15. The solution browser on the right side of the screen now shows the cube and dimensions that were defined. These objects can be modified by clicking on them. 15
- 16. Click on the Product dimension to observe that no hierarchy was defined by the wizard. I will create a hierarchy for it. 16
- 17. A new hierarchy is created by dragging the an aggregate attribute into the center panel. I use Category Code and Dim Product to form the hierarchy; Category and Item provide the labels the user will see (they are mapped to the name Property). Next I define attributes between these hierarchy levels. This is so the aggregation process adds the data from the level directly beneath it instead of always going to the leaf level, which would be a less efficient process entailing significantly more calculations. 17
- 18. In the case of the time dimension, there is an additional step. We want the months to display in chronological order, not alphabetical order, so we assign a value to the dimension’s OrderByAttribute property. The data source has a column called CHRON_ORDER that contains this ordering information. 18
- 19. The information entered to define the hierarchies and attributes is stored in XML files. The database doesn’t actually know what you have done yet. You must “process” the dimension. This brings that information into the OLAP database, which it then uses to create its internal structures. 19
- 20. Once a dimension has been processed, you can inspect it in the browser pane to verify the hierarchy has the expected structure. Note that the months show in chronological order. 20
- 21. After all the elements have been defined and the cube has been completely processed, you can inspect the data in the SSAS data browser. 21
- 23. The cube has been defined and created. The leaf level data from the data warehouse was loaded. We inspected the data in the multidimensional data browser. We can tweak the physical design of the cube to improve scalability and query performance. Three primary mechanisms for doing this are: •Selecting ROLAP/HOLAP/MOLAP data storage options •Partitioning •Pre-aggregating MOLAP is probably the most commonly used data storage option and is the default. It means all the data will be stored in the multidimensional data cube. The illustration one the succeeding slides will used MOLAP. At the opposite end of the spectrum, is ROLAP where all data comes from relational data tables. With ROLAP, the SSAS database is only providing metadata structures for presenting information in the dimensional style. You can expect performance to be much slower. This mode is used in situations where the source data is not static, changes frequently and you want the reports to reflect those changes immediately. HOLAP is a hybrid approach where all the aggregate data is in the SSAS database except the leaf level data which resides in relational tables. When the volume of data is very large, it can helpful to chop the data store into pieces, or partitions. Storage mode is selectable per partition. This example uses a small amount of data and only one partition will be employed. 23
- 24. Aggregates are summary level data that are computed from the leaf level data that was loaded from the source. Often the aggregates are totals and subtotals, but other summary statistics such as averages or maximum values can also be used. Pre-calculating and storing the aggregate values normally improves query performance (at the cost of the storage space and time required to compute them.) The default is to do no pre- aggregates. You can see this from the partitions panel shown below. The data display shown earlier from the SSAS data browser included many aggregate data values. Those aggregates were all calculated on the fly. You can pre-calculate all aggregates or only some of them. If you are going to pre-calculate only some, there are different strategies that can be employed to determined which are chosen for calculation. You’ll see this ahead. 24
- 25. Let’s go through the aggregations process. Click the “Design Aggregations” hyperlink to bring up the wizard. In the first panel of the wizard, push the count button to compute the statistics that are used to drive the aggregation optimization process. 25
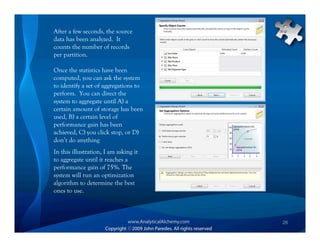
- 26. After a few seconds, the source data has been analyzed. It counts the number of records per partition. Once the statistics have been computed, you can ask the system to identify a set of aggregations to perform. You can direct the system to aggregate until A) a certain amount of storage has been used, B) a certain level of performance gain has been achieved, C) you click stop, or D) don’t do anything In this illustration, I am asking it to aggregate until it reaches a performance gain of 75%. The system will run an optimization algorithm to determine the best ones to use. 26
- 27. The system generates a chart telling what percent (of the total possible number of) aggregations it has identified and what level of performance gain would be achieved by computing them. At the completion of that step, the wizard has identified which aggregations to compute. You may elect to have it compute them now or you can defer the calculations till later. (They could take a while.) 27
- 28. Selecting “Deploy and Process now” and pushing Finish, you arrive at this screen. Push the RUN button to perform the calculations. When it finishes, you get a message heralding the successful completion of the deployment. The information under the Aggregations tab will be updated. 28
- 29. Creating Derived Measures and KPIs
- 30. Different Kinds of Reporting Data Thus far, all the measures that have been constructed have been displays of stored data or aggregates either stored or calculated on the fly. There are other kinds information that can be made available to an end user. • Calculated measures – Percents – Shares – Differences • Key Performance Indicators (KPIs) Calculated measures are calculated on the fly using MDX expressions. KPI’s are measures with associated goals and graphics. I will show an example of both. 30
- 31. In this example, I create a calculated measure that gives difference between the data value at a given time and its value the previous time period. The calculation is defined from the Calculations tab. It is given a name and an MDX expression. In this example I make use of the PrevMember function. 31
- 32. Displaying the Units measure and the Units Increase measure side-by- side demonstrates that the calculated measure correctly computes the difference between the current value and the one a month ago. In the next series of slides I will use this calculated measure to construct a KPI. 32
- 33. What is a Key Performance Indicator? (KPI) Every KPI starts life off as a measure, presumably, a measure that is an indicator of company performance. With each KPI, we assume that the company has established a target value – goal – of what that indicator should be. For instance, sales revenue might be a performance indicator. The goal might be to sell at least $100,000 in a given quarter. The KPI will calculate the difference between the goal and the actual result. We assume the company can assess those differences declaring them as either good, so-so, or bad. For instance, the company may say, revenue > 100,000 is good, 90,000 to 100,000 is so-so, and revenue less than 90,000 is bad. This brings us to an essential distinguishing feature of the KPI: a graphical icon, known as an indicator that is displayed to communicate the status of the KPI to the end user. That graphic might be a happy face to show good, a neutral face to show so-so, and a frowning face to show bad. Traffic lights with green, amber, and red are often used. The choice of graphics is up to the client. Setting up a KPI in Analysis Services entails computing a value of status. The difference between the indicator and the goal is calculated, and the differences that are “good” are mapped to the number 1, so-so to 0 and bad to -1. That number is the KPI’s status. Optionally, you can define a trend for the KPI. The trend shows if, over time, the performance measure has been moving upwards or downwards. 33
- 34. KPI Summary • Begin with a measure indicating company performance • Have goals associated with that performance measure • Translate the difference between performance and goal into its status with values of 1, 0, -1 (corresponding to good, so-so, and bad) • Display the status of the performance measure to the user as a graphic 34
- 35. You define KPIs from the KPI tab of the Cube browser. In this simple illustration, our calculated measure, “Units difference” is the performance indicator, and the goal is a constant value of 180. MDX expressions can be used to provide more complex goal statements. 35
- 36. Once you have defined the KPI, it may be inspected in the browser tab of the KPI tab. Here you see the performance metric has a value of 179, just under the target value. This is “so-so” and you see the neutral face showing. 36