A Fast and Dirty Intro to NetworkX (and D3)
Download as PPTX, PDF97 likes45,336 views

Using the python lib NetworkX to calculate stats on a Twitter network, and then display the results in several D3.js visualizations. Links to demos and source files. I'm @arnicas and live at www.ghostweather.com.






![Example Code from NetworkX
def calculate_degree_centrality(graph):
g = graph
dc = nx.degree_centrality(g)
nx.set_node_attributes(g,'degree_cent',dc)
degcent_sorted = sorted(dc.items(), key=itemgetter(1), reverse=True)
for key,value in degcent_sorted[0:10]:
print "Highest degree Centrality:", key, value
return graph, dc
Highest degree Centrality: flowingdata 0.848447961047
Highest degree Centrality: datavis 0.837492391966
Highest degree Centrality: infosthetics 0.828971393792
Highest degree Centrality: infobeautiful 0.653682288497
Highest degree Centrality: blprnt 0.567255021302
Highest degree Centrality: ben_fry 0.536822884967
Highest degree Centrality: moritz_stefaner 0.529519172246
Highest degree Centrality: eagereyes 0.524041387705
Highest degree Centrality: mslima 0.503956177724
Highest degree Centrality: VizWorld 0.503956177724
There are similar functions for
other stats in my code outline.
Lynn Cherny,
3/18/2012
lynn@ghostweather.com](https://image.slidesharecdn.com/networkxlcherny-120318190630-phpapp01/85/A-Fast-and-Dirty-Intro-to-NetworkX-and-D3-7-320.jpg)




![Community Detection Algorithms
E.g., the Louvain method, implemented in a lib that works
with NetworkX
def find_partition(graph):
# from http://perso.crans.org/aynaud/communities/
g = graph
partition = community.best_partition( g )
print "Partitions found: ", len(set(partition.values()))
print "Partition for node Arnicas: ", partition["arnicas"]
nx.set_node_attributes(g,'partition',partition)
return g, partition
http://en.wikipedia.org/wiki/File:Network_Community_Structure.png
Lynn Cherny,
3/18/2012
lynn@ghostweather.com](https://image.slidesharecdn.com/networkxlcherny-120318190630-phpapp01/85/A-Fast-and-Dirty-Intro-to-NetworkX-and-D3-13-320.jpg)
![Dump Partition Number by Node
def write_node_attributes(graph, attributes):
# utility function to let you print the node + various attributes in a csv format
if type(attributes) is not list:
attributes = [attributes]
for node in graph.nodes():
vals = [str(dict[node]) for dict in [nx.get_node_attributes(graph,x) for x in attributes]]
print node, ",", ",".join(vals)
Lynn Cherny,
3/18/2012
lynn@ghostweather.com](https://image.slidesharecdn.com/networkxlcherny-120318190630-phpapp01/85/A-Fast-and-Dirty-Intro-to-NetworkX-and-D3-14-320.jpg)


![Saving a Subset…
For most of my visualization demos, I used a subset of
the full dataset. I sorted the 1644 nodes by eigenvector
centrality score and then saved only the top 100.
Code from my networkx_functs.py file:
eigen_sorted = sorted(eigen.items(), key=itemgetter(1), reverse=True)
for key, val in eigen_sorted[0:5]:
print “Highest eigenvector centrality nodes:", key, val
# for trimming the dataset, you want it reverse sorted, with low values on top.
eigen_sorted = sorted(eigen.items(), key=itemgetter(1), reverse=False)
small_graph = trim_nodes_by_attribute_for_remaining_number(undir_g, eigen_sorted, 100)
print nx.info(small_graph)
#save as json for use in javascript - small graph, and full graph if you want
save_to_jsonfile(path+outputjsonfile, small_graph)
Lynn Cherny,
3/18/2012
lynn@ghostweather.com](https://image.slidesharecdn.com/networkxlcherny-120318190630-phpapp01/85/A-Fast-and-Dirty-Intro-to-NetworkX-and-D3-17-320.jpg)

![Gotchas to be aware of here
If you don’t use the “DiGraph” (directed graph) class in
NetworkX, you will lose some links. This changes some
visuals.
Your json links are based on index of the node. If/when
you do filtering in JSON based on, say, UI controls, you
need to redo your indexing on your links!
[e.g., See my code in demo full_fonts.html]
Lynn Cherny,
3/18/2012
lynn@ghostweather.com](https://image.slidesharecdn.com/networkxlcherny-120318190630-phpapp01/85/A-Fast-and-Dirty-Intro-to-NetworkX-and-D3-19-320.jpg)
























































Ad
More Related Content
What's hot (20)
Similar to A Fast and Dirty Intro to NetworkX (and D3) (20)


















Ad
More from Lynn Cherny (10)










Ad
Recently uploaded (20)




















A Fast and Dirty Intro to NetworkX (and D3)
- 1. A Fast-and-Dirty Intro * to NetworkX (and D3) Lynn Cherny *And, hopefully, practical
- 2. Plan The Problem: Hairballs. NetworkX – one tool Stats on networks (and getting them from NetworkX) Visualizing networks – some options D3 demos of several Lots of Links for Learning More Lynn Cherny, 3/18/2012 [email protected]
- 3. The Problem: Moritz Stefaner’s Dataset on Twitter “Infovis” Folks See http://well-formed-data.net/archives/642/the-vizosphere 3/18/2012
- 4. Intro to NetworkX A Python Library for Network / Graph analysis and teaching, housed and documented well at: http://networkx.lanl.gov/index.html Lynn Cherny, 3/18/2012 [email protected]
- 5. Aside on My Overall Code Strategy 1. Read in edgelist to NetworkX / (or read in JSON) 2. Convert to NetworkX graph object 3. Calculate stats & save values as node attributes in the graph (Verify it’s done with various inspections of the objects) 4. Write out JSON of nodes, edges and their attributes to use elsewhere 5. Move to D3 to visualize. Reduce the problem: send 6. Go back to 1 and restart to revise stats. fewer nodes to JSON; or filter visible nodes in UI/vis Lynn Cherny, 3/18/2012 [email protected]
- 6. Degree (Centrality) http://mlg.ucd.ie/files/summer/tutorial.pdf
- 7. Example Code from NetworkX def calculate_degree_centrality(graph): g = graph dc = nx.degree_centrality(g) nx.set_node_attributes(g,'degree_cent',dc) degcent_sorted = sorted(dc.items(), key=itemgetter(1), reverse=True) for key,value in degcent_sorted[0:10]: print "Highest degree Centrality:", key, value return graph, dc Highest degree Centrality: flowingdata 0.848447961047 Highest degree Centrality: datavis 0.837492391966 Highest degree Centrality: infosthetics 0.828971393792 Highest degree Centrality: infobeautiful 0.653682288497 Highest degree Centrality: blprnt 0.567255021302 Highest degree Centrality: ben_fry 0.536822884967 Highest degree Centrality: moritz_stefaner 0.529519172246 Highest degree Centrality: eagereyes 0.524041387705 Highest degree Centrality: mslima 0.503956177724 Highest degree Centrality: VizWorld 0.503956177724 There are similar functions for other stats in my code outline. Lynn Cherny, 3/18/2012 [email protected]
- 8. Betweenness A measure of connectedness between (sub)components of the graph http://en.wikipedia.org/wiki/Centrality#Betweenness_centrality Lynn Cherny, 3/18/2012 [email protected]
- 9. Betweenness (Centrality) http://mlg.ucd.ie/files/summer/tutorial.pdf
- 10. Eigenvector Centrality http://mlg.ucd.ie/files/summer/tutorial.pdf Lynn Cherny, 3/18/2012 [email protected]
- 11. Use Multiple Stats… Drew Conway’s recent post on central leaders in China: See also the excellent article by Valid Krebs in First Monday on terrorist networks, using other network metrics in conjunction. Lynn Cherny, 3/18/2012 [email protected]
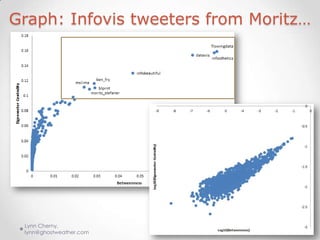
- 12. Graph: Infovis tweeters from Moritz… Lynn Cherny, 3/18/2012 [email protected]
- 13. Community Detection Algorithms E.g., the Louvain method, implemented in a lib that works with NetworkX def find_partition(graph): # from http://perso.crans.org/aynaud/communities/ g = graph partition = community.best_partition( g ) print "Partitions found: ", len(set(partition.values())) print "Partition for node Arnicas: ", partition["arnicas"] nx.set_node_attributes(g,'partition',partition) return g, partition http://en.wikipedia.org/wiki/File:Network_Community_Structure.png Lynn Cherny, 3/18/2012 [email protected]
- 14. Dump Partition Number by Node def write_node_attributes(graph, attributes): # utility function to let you print the node + various attributes in a csv format if type(attributes) is not list: attributes = [attributes] for node in graph.nodes(): vals = [str(dict[node]) for dict in [nx.get_node_attributes(graph,x) for x in attributes]] print node, ",", ",".join(vals) Lynn Cherny, 3/18/2012 [email protected]
- 15. Get Yer Stats, Visualize. Repeat. Lynn Cherny, 3/18/2012 [email protected]
- 16. Aside: NetworkX I/O utility functions Input -- List of edge pairs in txt file (e.g., “a b”) Networkx.read_edgelist converts a file of node pairs to a graph: def read_in_edges(filename): g_orig = nx.read_edgelist(filename, create_using=nx.DiGraph()) print "Read in edgelist file ", filename print nx.info(g_orig) return g_orig Input or Output -- JSON NetworkX.readwrite.json_graph.node_link_data def save_to_jsonfile(filename, graph): g = graph g_json = json_graph.node_link_data(g) json.dump(g_json, open(filename,'w')) NetworkX.readwrite.json_graph.load def read_json_file(filename): graph = json_graph.load(open(filename)) print "Read in file ", filename print nx.info(data) return graph Lynn Cherny, 3/18/2012 [email protected]
- 17. Saving a Subset… For most of my visualization demos, I used a subset of the full dataset. I sorted the 1644 nodes by eigenvector centrality score and then saved only the top 100. Code from my networkx_functs.py file: eigen_sorted = sorted(eigen.items(), key=itemgetter(1), reverse=True) for key, val in eigen_sorted[0:5]: print “Highest eigenvector centrality nodes:", key, val # for trimming the dataset, you want it reverse sorted, with low values on top. eigen_sorted = sorted(eigen.items(), key=itemgetter(1), reverse=False) small_graph = trim_nodes_by_attribute_for_remaining_number(undir_g, eigen_sorted, 100) print nx.info(small_graph) #save as json for use in javascript - small graph, and full graph if you want save_to_jsonfile(path+outputjsonfile, small_graph) Lynn Cherny, 3/18/2012 [email protected]
- 18. Dump JSON of a graph (after my NetworkX calcs) Works with all D3 examples I’ll show… Lynn Cherny, 3/18/2012 [email protected]
- 19. Gotchas to be aware of here If you don’t use the “DiGraph” (directed graph) class in NetworkX, you will lose some links. This changes some visuals. Your json links are based on index of the node. If/when you do filtering in JSON based on, say, UI controls, you need to redo your indexing on your links! [e.g., See my code in demo full_fonts.html] Lynn Cherny, 3/18/2012 [email protected]
- 20. Visualizing Networks NetworkX isn’t really for vis – can use graphViz and other layouts for static pics. Use Gephi to explore and calculate stats, too. See my blog post and slideshare with UI screencaps of Gephi, using this same data set! Apart from the hairball, there are other methods to visualize graphs: − See Robert Kosara’s post: http://eagereyes.org/techniques/graphs-hairball − Lane Harrison’s post: http://blog.visual.ly/network-visualizations/ − MS Lima’s book Visual Complexity Like many big data problems, use multiple stats and multiple methods to explore! Lynn Cherny, 3/18/2012 [email protected]
- 21. D3.js by Mike Bostock D3 allows creation of interactive visualizations… Adjacency Matrix Chord Diagram Networks Lynn Cherny, 3/18/2012 [email protected]
- 22. Aside on Data Set Size Adjacency matrix only holds a small number of nodes at a time – I used 88 of the top 100 selected by eigenvector centrality for this demo. Chord diagrams are simplified reps of a dataset – comparing the relations between the top 100 by eigenvector centrality vs. the whole 1644 nodes set reveals a most interesting insight! Interactive network vis is limited by browser performance – and complexity of hairballs. If you want it to be interactive (live) and not a static image, you probably need to reduce your data before or after loading. Lynn Cherny, 3/18/2012 [email protected]
- 23. Adjacency Matrix Square matrix of nodes; cells constitute edge count. http://mathworld.wolfram.com/AdjacencyMatrix.html Demo adjacency.html Lynn Cherny, 3/18/2012 [email protected]
- 24. What did this show? Be sure to change the sort order on the right side: The largest partition represented is the orange partition, when you sort by partition (= subcommunity) Some partitions (colors) have very few representatives in the matrix of the top 88. We can suppose these partitions are not composed of people with the highest eigenvector centrality scores. Node VizWorld is near or at the top in all the sort-by- attribute methods offered, and is in the red partition, not orange. Lynn Cherny, 3/18/2012 [email protected]
- 25. Chord Diagram: Summarize Top 100 nodes by Relations eigenvector centrality, chords by target: Not representative of full network… Interesting! Lynn Cherny, Demo 3/18/2012 [email protected]
- 26. Redo Chord Diagram With All Data… The demo allows you to swap json files to see the change. Lynn Cherny, 3/18/2012 [email protected]
- 27. Insights from Comparing Them The top 100 nodes by eigenvector centrality are mostly the orange partition. The green partition, however, is the largest group in the unfiltered set (the whole 1644 nodes). − Notice how few green and purple partition members “make” the top eigencentric list: You can see supporting evidence of the orange eigenvector centrality by looking at how many people link to them from other partitions. Change the target/source radio button on the demo to see this in action. Lynn Cherny, 3/18/2012 [email protected]
- 28. Handling with Graph Rendering… Typical Nodes/Edges, with sizing/coloring – slow, still a hairball, not much visible useful info. Avoid this simplistic vis method if you can… Note this takes a little while to calm down! Demo redballs Alternate, slightly better: Names, color by Partition, UI options and edges on click. Demo force_fonts Lynn Cherny, 3/18/2012 [email protected]
- 29. Viewing the top scoring subset only…. Even with a small subset and partition clustering, showing all the links is a visual mess… So only show them on demand. Lynn Cherny, 3/18/2012 [email protected]
- 30. Design Tweaks Made To Make It (More) Useful Add a click-action to − Fade out nodes unrelated to clicked node − Show lines indicating who they follow − Show the names (unlinked) of who follows them Add a tooltip showing on-screen degree (i.e., following and followed-by numbers for the subset) Heavily adjusted layout to separate clusters visually (lots of trial and error, see following slides) Add stats on the sidebar showing some numbers, to allow you to compare, for instance, onscreen degree vs. degree in the whole set of 1644 nodes: Lynn Cherny, 3/18/2012 [email protected]
- 31. Creating the subset in JS instead of NetworkX To create the union of the top N by each attribute, I shortcutted and used underscore.js’s union function: Then you need to update your links by filtering for the links referring to the subset of nodes, and fix the indices! Lynn Cherny, 3/18/2012 [email protected]
- 32. Insights from Subset The most “readable” view is with fonts sized by “Betweenness” because of the large discrepancies: Note that these look familiar from the Adjacency Matrix view! Lynn Cherny, 3/18/2012 [email protected]
- 33. How to “read” the layout Nodes that drift towards the middle are linked to more partition colors and nodes in the visible subset. Tooltips show the following/follower relations for the subset only. Nodes towards the fringes are less linked in general inside this subset. Itoworld, on the edge: Lynn Cherny, 3/18/2012 [email protected]
- 34. Interesting Oddities wattenberg is in the orange partition, but within the top HansRosling N nodes, follows no one follows* mostly but is followed by green: quite a few of the visible subset: In general, the top N of the green partition Ditto follow each nytgraphics: other. They’re the artists! * This data set is from mid-2011! Lynn Cherny, 3/18/2012 [email protected]
- 35. Accomplishing the layout in D3 Lots of screwing with the foci locations to move the nodes to and force settings: Moving them: Lynn Cherny, [email protected]
- 36. Wrap up with an aside from a Frank van Ham Talk http://bit.ly/s6udpy
- 37. Reminder(s) The map is not the territory. Just cuz social media software tools allow links between people doesn’t mean they reflect the true – or complete – social network of relationships. (Also, this data set is no doubt out of date with respect to current follower relations!) Lynn Cherny, 3/18/2012 [email protected]
- 38. A Bunch of Links (In the non-network sense) Lynn Cherny, 3/18/2012 [email protected]
- 39. General Network Primer Material MIT OpenCourseware on Networks, Complexity, Applications (many references!) Frank van Ham’s slides from a recent datavis meetup CRAN R code/links for handling graphs/networks Chapter 10 of Rajaraman & Ullman and book on Data Mining of Massive Datasets Graph Theory with Applications by Bondy and Murty Intro to Social Network Methods by Hanneman and Riddle Networks, Crowds, and Markets by Easley and Kleinberg My lists of sna / networks papers on delicious Lynn Cherny, 3/18/2012 [email protected]
- 40. NetworkX Info/Tutorials NetworkX site docs/tutorial: http://networkx.lanl.gov/tutorial/index.html UC Dublin web science summer school data sets, slides, references: http://mlg.ucd.ie/summer Stanford basic intro tutorial: http://www.stanford.edu/class/cs224w/nx_tutorial/nx_tuto rial.pdf Lynn Cherny, 3/18/2012 [email protected]
- 41. D3 Example Links (for networks) D3.js – Mike Bostock Super Useful force attributes explanation from Jim Vallandingham D3 Demo Talk Slides with embedded code by MBostock Chicago Lobbyists by Manning Mobile Patent Suits by Mbostock Rollover selective highlight code by Manning D3 Adjacency Matrix by Mbostock Chord diagram: http://bost.ocks.org/mike/uberdata/ My giant, growing list of D3 links on delicious Lynn Cherny, 3/18/2012 [email protected]
- 42. Community Detection (a couple) Overlapping Community Detection in Networks: State of the Art and Comparative Study by Jierui Xie, Stephen Kelley, Boleslaw K. Szymanski Empirical Comparison of Algorithms for Network Community Detection by Leskovec, Lang, Mahoney Lynn Cherny, 3/18/2012 [email protected]
- 43. Sources of “Canned” Network Data Koblenz Network Collection CMU’s CASOS INSNA.org’s member datasets Lynn Cherny, 3/18/2012 [email protected]
- 44. Blog Post and Links Zip file of slides, networkx code, and edgelist: − http://www.ghostweather.com/essays/talks/networkx/source.zip Blog post with links and more text: − http://blogger.ghostweather.com/2012/03/digging-into-networkx-and-d3.html Lynn Cherny, 3/18/2012 [email protected]
- 45. Lynn Cherny [email protected] @arnicas http://www.ghostweather.com Lynn Cherny, 3/18/2012 [email protected]