Accelerated Spark on Azure: Seamless and Scalable Hardware Offloads in the Cloud with Yuval Degani and Evan Burness
3 likes901 views

Microsoft Azure’s advanced compute and network infrastructure allows Spark to run in the cloud without compromising on performance. With the growing arsenal of hardware offloads available on cloud VMs, owning and maintaining bleeding edge hardware is no longer a prerequisite for accelerated compute. In this talk, we will demonstrate how hardware accelerations in Azure can be utilized to speed-up Spark jobs seamlessly, with the aid of RDMA (Remote Direct Memory Access) support in the VM. We will demonstrate use cases of benchmarks and real-world applications, that achieve impressive performance improvements with minimal configuration.
















































































Ad
More Related Content
What's hot (20)
Similar to Accelerated Spark on Azure: Seamless and Scalable Hardware Offloads in the Cloud with Yuval Degani and Evan Burness (20)


















Ad
More from Databricks (20)




















Ad
Recently uploaded (20)




















Accelerated Spark on Azure: Seamless and Scalable Hardware Offloads in the Cloud with Yuval Degani and Evan Burness
- 1. Accelerated Spark on Azure: Seamless and Scalable Hardware Offloads in the Cloud Yuval Degani, Mellanox Technologies Evan Burness, Microsoft Azure #HWCSAIS18
- 2. • End-to-end designer and supplier of interconnect solutions: network adapters, switches, system-on-a-chip, cables, silicon and software • 10-400 Gb/s Ethernet and InfiniBand Storage Front / Backend Server / Compute Switch / Gateway 56/100/200G InfiniBand 10/25/40/50/ 100/200/400GbE Virtual Protocol Interconnect 56/100/200G InfiniBand 10/25/40/50/ 100/200/400GbE Virtual Protocol Interconnect #HWCSAIS18 2
- 3. • RDMA capable network, powered by Mellanox • H-series (Intel CPUs with FDR InfiniBand) • NC-series (Nvidia GPUs with FDR InfiniBand) • Only major Cloud provider with RDMA • Run simulation and AI workloads at large-scale • Dozens of RDMA clusters around the world #HWCSAIS18 3
- 4. Why are we here? • Azure hardware accelerated networks will soon support general-purpose RDMA (on top of SR-IOV) • SparkRDMA Shuffle Plugin (appeared at Spark Summit Europe 2017) can now be used in the cloud, providing instant speedups for Spark jobs #HWCSAIS18 4
- 5. What’s RDMA? • Remote Direct Memory Access – Read/write from/to remote memory locations • Zero-copy • Direct hardware interface – bypasses the kernel and TCP/IP in IO path • Flow control and reliability is offloaded in hardware • Sub-microsecond latency • Supported on almost all mid-range/high- end network adapters Java app buffer OS Sockets TCP/IP Driver Network Adapter RDMA Socket Context switch #HWCSAIS18 5
- 6. RDMA on Azure • No need for buying expensive hardware • Lowest latency on the Cloud (~2.5 uSec) • Pre-built OS images for easy deployment • K80, P100, and V100 GPUs with InfiniBand • Other uses cases for RDMA on Azure: #HWCSAIS18 6
- 7. RDMA on Azure Azure accelerated networking is build on top of SR-IOV (Single Root Input/Output Virtualization) hardware support provided by Mellanox ConnectX network cards 7#HWCSAIS18
- 8. Spark’s Shuffle Internals Under the hood #HWCSAIS18 8
- 12. Spark’s Shuffle Basics Map MapReduce Map Map Map Map Input Map output #HWCSAIS18 9
- 13. Spark’s Shuffle Basics Map MapReduce Map Map Map Map Input Map output File File File File File #HWCSAIS18 9
- 14. Spark’s Shuffle Basics Map MapReduce Map Map Map Map Input Map output File File File File File Driver #HWCSAIS18 9
- 15. Spark’s Shuffle Basics Map Reduce task MapReduce Map Map Map Map Input Map output File File File File File Driver Reduce task Reduce task Reduce task Reduce task #HWCSAIS18 9
- 16. Spark’s Shuffle Basics Map Reduce task MapReduce Map Map Map Map Input Map output File File File File File Driver Reduce task Reduce task Reduce task Reduce task Fetch blocks Fetch blocks Fetch blocks Fetch blocks Fetch blocks #HWCSAIS18 9
- 17. Spark’s Shuffle Basics Map Reduce task MapReduce Map Map Map Map Input Map output File File File File File Driver Reduce task Reduce task Reduce task Reduce task Fetch blocks Fetch blocks Fetch blocks Fetch blocks Fetch blocks #HWCSAIS18 9
- 18. Spark’s Shuffle Basics Map Reduce task MapReduce Map Map Map Map Input Map output File File File File File Driver Reduce task Reduce task Reduce task Reduce task Fetch blocks Fetch blocks Fetch blocks Fetch blocks Fetch blocks #HWCSAIS18 9
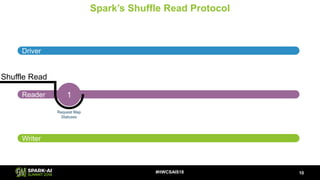
- 19. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer
- 20. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer
- 21. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 Request Map Statuses
- 22. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 2 Request Map Statuses Send back Map Statuses
- 23. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 2 3 Request Map Statuses Send back Map Statuses Group block locations by writer
- 24. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 2 3 4 Request Map Statuses Send back Map Statuses Request blocks from writers Group block locations by writer
- 25. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 2 3 4 5 Request Map Statuses Send back Map Statuses Request blocks from writers Locate blocks, and setup as stream Group block locations by writer
- 26. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 2 3 4 5 6 Request Map Statuses Send back Map Statuses Request blocks from writers Locate blocks, and setup as stream Request blocks from stream, one by one Group block locations by writer
- 27. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 2 3 7 4 5 6 Request Map Statuses Send back Map Statuses Request blocks from writers Locate blocks, and setup as stream Request blocks from stream, one by one Group block locations by writer Locate block, send back
- 28. Spark’s Shuffle Read Protocol 10#HWCSAIS18 Shuffle Read Driver Reader Writer 1 2 3 7 4 5 6 Request Map Statuses Send back Map Statuses Request blocks from writers Locate blocks, and setup as stream Request blocks from stream, one by one Group block locations by writer Locate block, send back 8 Block data is now ready
- 29. The Cost of Shuffling • Shuffling is very expensive in terms of CPU, RAM, disk and network IOs • Spark users try to avoid shuffles as much as they can • Speedy shuffles can relieve developers of such concerns, and simplify applications #HWCSAIS18 11
- 30. SparkRDMA Shuffle Plugin Accelerating Shuffle with RDMA #HWCSAIS18 12
- 31. SparkRDMA • Dedicated session at Spark Summit Europe 2017: Accelerating Shuffle: A Tailor-Made RDMA Solution for Apache Spark • Open-source and free to use: https://github.com/Mellanox/SparkRDMA • Supports any RDMA-capable device – Ethernet (RoCE – RDMA over Converged Ethernet) – InfiniBand #HWCSAIS18 13
- 32. SparkRDMA - Design Notes • Entire Shuffle-related communication is done with RDMA – RPC messaging for meta-data transfers – Block transfers • SparkRDMA is an independent plugin – Implements the ShuffleManager interface – No changes to Spark’s code – use with any existing Spark installation • Reuses Spark facilities – Maximize reliability – Minimize impact on the data • No functionality loss of any kind, SparkRDMA supports: – Compression – Spilling to disk – Recovery from failed map or reduce tasks 14#HWCSAIS18 SortShuffleManager RdmaShuffleManager
- 33. Shuffle Read Driver Reader Writer #HWCSAIS18 15 Shuffle Read Protocol – Standard vs. RDMA
- 34. Shuffle Read Driver Reader Writer 1 2 3 7 4 5 6 Request Map Statuses Send back Map Statuses Request blocks from writers Locate blocks, and setup as stream Request blocks from stream, one by one Group block locations by writer Locate block, send back 8 Block data is now ready #HWCSAIS18 15 Shuffle Read Protocol – Standard vs. RDMA
- 35. Shuffle Read Driver Reader Writer 1 2 3 Request Map Statuses Send back Map Statuses Group block locations by writer #HWCSAIS18 15 Shuffle Read Protocol – Standard vs. RDMA
- 36. Shuffle Read Driver Reader Writer 1 2 3 4 Request Map Statuses Send back Map Statuses Group block locations by writer RDMA-Read blocks from writers #HWCSAIS18 15 Shuffle Read Protocol – Standard vs. RDMA
- 37. Shuffle Read Driver Reader Writer 1 2 3 4 Request Map Statuses Send back Map Statuses Group block locations by writer RDMA-Read blocks from writers No-op on writer HW offloads transfers #HWCSAIS18 15 Shuffle Read Protocol – Standard vs. RDMA
- 38. Shuffle Read Driver Reader Writer 1 2 3 4 Request Map Statuses Send back Map Statuses Group block locations by writer RDMA-Read blocks from writers No-op on writer HW offloads transfers 5 Block data is now ready #HWCSAIS18 15 Shuffle Read Protocol – Standard vs. RDMA
- 39. Shuffle Read Driver Reader Writer 1 2 3 7 4 5 6 Request Map Statuses Send back Map Statuses Request blocks from writers Locate blocks, and setup as stream Request blocks from stream, one by one Group block locations by writer Locate block, send back 8 Block data is now ready Shuffle Read Driver Reader Writer 1 2 3 4 6 Request Map Statuses Send back Map Statuses Group block locations by writer RDMA-Read blocks from writers No-op on writer HW offloads transfers 5 Block data is now ready StandardRDMA 16
- 40. StandardRDMA Reader Writer 7 4 5 6 Request blocks from writers Request blocks from stream, one by one Locate block, send back 8 Block data is now ready Reader Writer 4 6 RDMA-Read blocks from writers No-op on writer HW offloads transfers 5 Block data is now ready Locate blocks, and setup as stream 16
- 41. StandardRDMA Server-side: 0 CPU Shuffle transfers are not blocked by GC in executor No buffering Client-side: Instant transfers Reduced messaging Direct, unblocked access to remote blocks Reader Writer 7 4 5 6 Request blocks from writers Request blocks from stream, one by one Locate block, send back 8 Block data is now ready Reader Writer 4 6 RDMA-Read blocks from writers No-op on writer HW offloads transfers 5 Block data is now ready Locate blocks, and setup as stream 16
- 42. Benefits • Substantial improvements in: – Block transfer times: latency and total transfer time – Memory consumption and management – CPU utilization • Easy to deploy and configure: – Packed into a single JAR file – Plugin is enabled through a simple configuration handle – Allows finer tuning with a set of configuration handles • Configuration and deployment are on a per-job basis: – Can be deployed incrementally – May be limited to Shuffle-intensive jobs #HWCSAIS18 17
- 44. Demo Testbed • Hardware: – 8 Azure “h16mr” VM instances – Intel Haswell E5-2667 V3 – InfiniBand FDR (56Gb/s) – 224GiB RAM – 2000GiB SSD for temporary storage • Workload: – HiBench TeraSort – Size: “gigantic” (320GB) • Ubuntu 16.04 • HDFS on Hadoop 2.7.4 – No replication • Spark 2.2.0 – 1 Master – 7 Workers – 16 active Spark cores on each node, 112 total #HWCSAIS18 19
- 46. TeraSort - Performance Results RDMA Standard 0 100 200 300 400 500 600 700 seconds #HWCSAIS18 21
- 49. 0 Shuffle Read Time 24#HWCSAIS18 StandardRDMA
- 50. Recap • SR-IOV+RDMA comes to Azure H and N-series in Fall 2018 • Support for all major MPI – MVAPICH, OpenMPI, Intel MPI, Platform MPI, etc. • General-purpose RDMA support – Support for SparkRDMA, Caffe2, TensorFlow or any other RDMA application • Be on the lookout for more at SC’18 ! #HWCSAIS18 25
- 51. Thank you.