Accelerating analytics on the Sensor and IoT Data.
Download as PPTX, PDF4 likes3,731 views

Informix Warehouse Accelerator (IWA) has helped traditional data warehousing performance to improve dramatically. Now, IWA accelerates analytics over the sensor data stored in relational and timeseries data.

















![1 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …]
2 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …]
3 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …]
4 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …]
… …
•Each row contains all the data for a single meter, data append to end of the row
•Data is not indexed, only the meter ID column is indexed
•Data on disk is clustered by meter id and kept ordered by time
•Meter IDs stored once rather than with every record
•Timestamps are not stored on disk, instead are calculated by position in series
•Missing intervals are marked with a placeholder
Smart_Meters Sensor table
Table grows
Meter_id Timeseries(mysensor)
Same Table using Informix TimeSeries Schema
(logical view)
Index
Create row type mysensor(ts datetime year to fraction(5),
value1 int, value2 float, …..valuen int);](https://image.slidesharecdn.com/b13-accelerating-analytics-sensor-data-v1-140502174652-phpapp02/85/Accelerating-analytics-on-the-Sensor-and-IoT-Data-18-320.jpg)



![Virtual Table Interface makes Time Series
data appear Relational
mtr_id Series
(int) timeseries(mtr_data)
SM_vt
1 Tue Value 1
1 Wed Value 1
... ...
3 Mon Value 1
3 Tue Value 1
3 Wed Value 1
... ... ... ...
1 Mon Value 1 Value 2
col_1 col_2datemtr_id
Smart_meter
...
...
...
...
...
...
...
...
TimeSeries Table TimeSeries Virtual Table
Execute procedure tscreatevirtualtable
[(Mon, v1, ...)(Tue,v1…)]
(‘SM_vt’, ‘Smart_meter’);
8
7
6
5
4
3
2
1
[(Mon, v1, ...)(Tue,v1…)]
[(Mon, v1, ...)(Tue,v1…)]
[(Mon, v1, ...)(Tue,v1…)]
[(Mon, v1, ...)(Tue,v1…)]
[(Mon, v1, ...)(Tue,v1…)]
[(Mon, v1, ...)(Tue,v1…)]
[(Mon, v1, ...)(Tue,v1…)]
...
Value 2
Value 2
Value 2
Value 2
Value 2
...](https://image.slidesharecdn.com/b13-accelerating-analytics-sensor-data-v1-140502174652-phpapp02/85/Accelerating-analytics-on-the-Sensor-and-IoT-Data-22-320.jpg)





![Timeseries on JSON
CREATE ROW TYPE info( stime datetime year to fraction(5), jdata bson);
CREATE TABLE iotdata(id int primary key, tsdata
timeseries(info) );
INSERT INTO iotdata VALUES(472,'origin(2014-04-23
00:00:00.00000), …, regular,[({“temp":78, “wind":7.2,
“loc":“Miami-1 "})]');
INSERT INTO iotdata values(384,'origin(2014-04-21
00:00:00.00000), …, regular,[({“sleep": 380, “steps":7423,
“name":"Joe "})]');
SELECT GetFirstElem(tsdata,0)::row(timestamp datetime year to
fraction(5), jdata json) FRONM tj;
(expression) ROW('2014-04-21 00:00:00.00000','{“temp":78,“wind":7.2,“loc":“Miami-1"}')
(expression) ROW('2014-04-21 00:00:00.00000','{“sleep":380,“steps":7423,“name":"Joe "}')](https://image.slidesharecdn.com/b13-accelerating-analytics-sensor-data-v1-140502174652-phpapp02/85/Accelerating-analytics-on-the-Sensor-and-IoT-Data-28-320.jpg)

![Informix REST API
•REpresentational State Transfer
http://<hostname>[:<port#>]/<db>/<collection>
•Integrated into Informix
•GET /demo/people?sort={age:-1}&fields={_id:0,lastName:0}
RESPONSE: [{"firstName":"Anakin","age":49},
{"firstName":"Padme","age":47},
{"firstName":"Luke","age":31},
{"firstName":"Leia","age":31}]
GET /stores_demo/ts_data_v?query={loc_esi_id:"4727354321046021"}](https://image.slidesharecdn.com/b13-accelerating-analytics-sensor-data-v1-140502174652-phpapp02/85/Accelerating-analytics-on-the-Sensor-and-IoT-Data-30-320.jpg)













































Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Accelerating analytics on the Sensor and IoT Data. (20)
![Samantha Wang [InfluxData] | Best Practices on How to Transform Your Data Usi...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdaysnorthamerica2020-201005185945-thumbnail.jpg?width=560&fit=bounds)














![[WSO2Con EU 2017] Streaming Analytics Patterns for Your Digital Enterprise](https://cdn.slidesharecdn.com/ss_thumbnails/lgqvq0vzqhygnya85esl-signature-6abac760590306a9c092f3ba66249d9a805ee6b52c9eb804a80eabb33b95c5ef-poli-171106133401-thumbnail.jpg?width=560&fit=bounds)




Ad
More from Keshav Murthy (20)




















Recently uploaded (20)







![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)












Accelerating analytics on the Sensor and IoT Data.
- 1. Accelerating Analytics for sensor (IoT) data Keshav Murthy Architect, IBM Informix [email protected] 1
- 2. 2 Explosion of mobile devices – gaming and social apps Advertising: serving ads and real-time bidding Social networking, online communities E-commerce, social commerce Machine data and real-time operational decisions Smart Devices Internet of Things Internet of Things
- 3. 3 Explosion of mobile devices – gaming and social apps Advertising: serving ads and real-time bidding Social networking, online communities E-commerce, social commerce Machine data and real-time operational decisions Smart Devices Internet of Data, really Internet of Things SQL SQL, {JSON}, Spatial {JSON}, TimeSeries SQL, {JSON} Simple, {JSON}, Timeseries SQL, {JSON}
- 4. 4 IoT Applications – IBM Reference Architecture Gateway Operational Zone Warehouse/Mart Analytics Services and Contents Shared Operational Information Rule Engine ETL Real-Time Data Store Hadoop Video Analytics Big Data Explorer Analytic Tools Connected Device Analyzed Data MapReduce HDFS/GPFS Device Management : Predictive Maintenance Traffic Optimization Driving Behavior Incident Analysis Infotainment Service Raw Data Summarized Data Notification Analytic Report B2C/B2B Portal Admin Console Operator Console LocalIntelligence NetworkSupport Stream Processing ETL RDB DataMart SOE Data Video Management Asset Data Management Master Data Management Reference Data Hub Video Data .. Environment Data, etc. Other Data Local Database
- 5. 5 IoT Applications – IBM Reference Architecture Gateway Operational Zone Warehouse/Mart Analytics Services and Contents Shared Operational Information Rule Engine ETL Real-Time Data Store Hadoop Video Analytics Big Data Explorer Analytic Tools Connected Device Analyzed Data MapReduce HDFS/GPFS Device Management : Predictive Maintenance Traffic Optimization Driving Behavior Incident Analysis Infotainment Service Raw Data Summarized Data Notification Analytic Report B2C/B2B Portal Admin Console Operator Console LocalIntelligence NetworkSupport Stream Processing ETL RDB DataMart SOE Data Video Management Asset Data Management Master Data Management Reference Data Hub Video Data .. Environment Data, etc. Other Data Local Database Scenarios for Informix
- 6. © 2014 IBM Corporation6 IBM Cloud: Think it. Build it. Tap into it.IoT Solutions, an architecture. Collection of data for all sensors Data from other kinds of sensors Consumer / Business Sensors in the home Informix TimeSeries Service NoSQL, Relational, Timeseries & Spatial storage & analytics Informix Warehouse Accelerator SPSS/Cognos MessageSight / MQTT SoftLayer / BlueMix BigInsights Gateways for data consolidation Infosphere Streams (no gateway) = IBM products = IBM Informix Relational Database In-memory analytics Predictive analytics and dashboard Cloud infrastructure Hadoop Publish / Subscribe Real-time analytics
- 7. • Individual Car Recognition in the parking zone •Composite sensors to transmit license image • Picture,location,weight,color,etc •Cloud service to recognize the car plate number •Gateway is the orchestrator: collection, sync, service
- 8. Myriad of devices for gateways: Intel Galileo, ARM based boards. Shaspa embedded Informix into its stack for sensor data mgmt. IBM Informix developer edition. Download Now: http://www-03.ibm.com/software/products/en/infodeveedit
- 10. IBM Bluemix: TimeSeries Service
- 11. IBM Bluemix: IoT Service IBM Bluemix: IBM Internet of things Service
- 12. 12 SQL {NoSQL:JSON} Define Schema first Write the program first Relational Key-value, Document, column family, graph and text Changing schema is hard Assumes dynamic schema Scale-up Scale-out ACID consistency BASE consistency Transactions No Transactions SQL Proprietary API; Sometimes has the “spirit” of SQL
- 13. 13 SQL Timeseries Define Schema first Create Timeseries Row Type Relational Timeseries Optimized with projection to relational; Often used with Spatial data Changing schema is hard Changing schema is hard; Flexible with Timeseries({JSON}) Scale-up Scale-up & Scale-out ACID consistency ACID consistency SQL SQL extensions; Relational projection.
- 14. Data Management: devices to Cloud Enterprise replication + Flexible Grid App Server JDBC App Server Mongo Driver Listener Informix/1 Primary Informix/1 SDS/HDR Informix/1 RSS Informix/2 Primary Informix/2 SDS/HDR Informix/2 RSS Informix/3 Primary Informix/3 SDS/HDR Informix/3 RSS Informix/4 Primary Informix/4 SDS/HDR Informix/4 RSS Informix/5 Primary Informix/5 SDS/HDR Informix/5 RSS Informix/6 Primary Informix/6 SDS/HDR Informix/6 RSS Mongo API Node.JS Express.JS AngularJS REST APIs NoSQL SQLCloud Informix warehouse Accelerator
- 15. Informix: All Together Now! 15 SQL Tables JSON Collections TimeSeries MQ Series SQL APIs JDBC, ODBC Informix IWA – BLU ACCELERATION GENBSON: SQL to {BSON} MongoDB Drivers TEXT SEARCH SPATIAL TIME SERIES {BSON}
- 16. SQL API Mongo API (NoSQL) Relational Table JSON Collections Standard ODBC, JDBC, .NET, OData, etc. Language SQL. Mongo APIs for Java, Javascript, C++, C#,... Direct SQL Access. Dynamic Views Row types Mongo APIs for Java, Javascript, C++, C#,... JSON CollectionsJSON Collections Standard SQL/ext JDBC/ODBC JSON Support Virtual Table JSON support TimeseriesJSON Collections TimeseriesRelational Table JSON Timeseries Spatial Text Standard SQL JDBC/ODBC JSON Support JSON Support Hybrid Access: SQL, JSON, Timeseries & Spatial
- 17. 1 1-1-11 12:00 Value 1 Value 2 …….. Value N 2 1-1-11 12:00 Value 1 Value 2 …….. Value N 3 1-1-11 12:00 Value 1 Value 2 …….. Value N … … … … …….. … 1 1-1-11 12:15 Value 1 Value 2 …….. Value N 2 1-1-11 12:15 Value 1 Value 2 …….. Value N 3 1-1-11 12:15 Value 1 Value 2 …….. Value N … … … … …….. … Relational Schema: Smart Meters Sensor Smart_Meters Table •Each row contains one record = billions of rows in the table •All data is indexed for efficient lookups •Data is appended to the end of the table as it arrives •Meter ID’s stored in every record •No concept of a missing row TableGrows KWH Voltage ColNTimeMeter_id Index all columns
- 18. 1 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …] 2 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …] 3 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …] 4 [(1-1-11 12:00, value 1, value 2, …, value N), (1-1-11 12:15, value 1, value 2, …, value N), …] … … •Each row contains all the data for a single meter, data append to end of the row •Data is not indexed, only the meter ID column is indexed •Data on disk is clustered by meter id and kept ordered by time •Meter IDs stored once rather than with every record •Timestamps are not stored on disk, instead are calculated by position in series •Missing intervals are marked with a placeholder Smart_Meters Sensor table Table grows Meter_id Timeseries(mysensor) Same Table using Informix TimeSeries Schema (logical view) Index Create row type mysensor(ts datetime year to fraction(5), value1 int, value2 float, …..valuen int);
- 19. Physical View of Informix TimeSeries Data Container1 Container2 Container3 meter_id vee_interval_ts 1 2 3 4 5 7 8 (int) timeseries(mysensor) 6 Each Container typically placed on a separate disk vee_interval_table Table
- 20. Accessing TimeSeries •Access through standard tabular view –Virtual Table Interface (VTI) –Makes TimeSeries look like a standard relational table •SQL Interface –100+ functions •Customized functions –Written in Stored Procedure Language (SPL), “C”, Java –65+ “C” functions
- 21. TimeSeries SQL Interface •TimeSeries data is usually accessed through user defined routines (UDR’s) from SQL, some of these are: –Clip() – Access a subset of data from a time series –LastElem(), FirstElem() - return the last (first) element in the time series –Apply() – Filter out time series rows and apply functions to those that remain –AggregateBy() – Rollup time series data to be hourly/daily/yearly or custom intervals –SetContainerName() - move a time series from one container to another. –Transpose() – Make a time series appear to be a table –MovingAvg() – Create a time series of the moving average –Plus nearly 100 other functions…
- 22. Virtual Table Interface makes Time Series data appear Relational mtr_id Series (int) timeseries(mtr_data) SM_vt 1 Tue Value 1 1 Wed Value 1 ... ... 3 Mon Value 1 3 Tue Value 1 3 Wed Value 1 ... ... ... ... 1 Mon Value 1 Value 2 col_1 col_2datemtr_id Smart_meter ... ... ... ... ... ... ... ... TimeSeries Table TimeSeries Virtual Table Execute procedure tscreatevirtualtable [(Mon, v1, ...)(Tue,v1…)] (‘SM_vt’, ‘Smart_meter’); 8 7 6 5 4 3 2 1 [(Mon, v1, ...)(Tue,v1…)] [(Mon, v1, ...)(Tue,v1…)] [(Mon, v1, ...)(Tue,v1…)] [(Mon, v1, ...)(Tue,v1…)] [(Mon, v1, ...)(Tue,v1…)] [(Mon, v1, ...)(Tue,v1…)] [(Mon, v1, ...)(Tue,v1…)] ... Value 2 Value 2 Value 2 Value 2 Value 2 ...
- 23. select min(tstamp), max(tstamp) from ts_data_v; select first 3 state,avg(value) average from ts_data_v v, customer_ts_data l, customer c where v.loc_esi_id = l.loc_esi_id and l.customer_num = c.customer_num group by 1 order by 2 desc; Querying on the VTI Table
- 24. IoT - Devices Informix Timeseries Tables Timeseries VTI Tables DataLoader JSON Data Files MiddlewareProcessing JSON Managing Variety: Data flow for IoT Data IoT - Devices
- 25. Managing Variety: IoT Model Makeover Before: CREATE ROW TYPE mysensor (ts DATETIME YEAR TO FRACTION(5), tag1 FLOAT, tag2 FLOAT, tag3 FLOAT, tag5 FLOAT,tag6 FLOAT,tag6 FLOAT,tag7 FLOAT,tag8 FLOAT, tag9 FLOAT,tag10 FLOAT,tag11 FLOAT,tag12 FLOAT,tag13 FLOAT,tag15 FLOAT,tag16 FLOAT,tag17 FLOAT,tag18 FLOAT,tag19 FLOAT,tag20 FLOAT,tag21 FLOAT,tag22 FLOAT,tag23 FLOAT,tag24 FLOAT,tag26 FLOAT,tag27 FLOAT,tag28 FLOAT,tag …. tag147 FLOAT,tag148 FLOAT,tag149 FLOAT,tag150 FLOAT); AFTER: CREATE ROW TYPE mysensor (stime DATETIME YEAR TO FRACTION(5), jdata BSON)
- 26. Informix Timeseries Tables Timeseries VTI Tables IoT - Devices DataLoader JSON Data Files MiddlewareProcessing JSON type id Usage Timeseries(IFXTSBSON) “XA” 12 (2014-01-01 01:21:000, {x:1,y:2}), (2014-02-02 01:23:000, {x:3, y:5, z:42}) “XB” 48 (2014-01-01 01:21:000, {c:1,d:”ACND”}), (2014-04-02 01:23:000, {c:92,d:”MCBS”, e:42}) “XC” 23 (2015-01-01 01:21:000, {p:1,q:2}), (2015-03-02 01:23:000, {p:3, y:5, z:42}), Managing Variety using Timeseries(JSON) Data IoT - Devices
- 27. Informix Timeseries Tables Timeseries VTI Tables Timeseries{JSON} => VTI-Table{JSON} type id Timeseries(IFXJSTYPE) “XA” 12 (2014-01-01 01:21:000, {x:1,y:2}), (2014-02-02 01:23:000, {x:3, y:5, z:42}) “XB” 48 (2014-01-01 01:21:000, {c:1,d:”ACND”}), (2014-04-02 01:23:000, {c:92,d:”MCBS”, e:42}) “XC” 23 (2015-01-01 01:21:000, {p:1,q:2}), (2015-03-02 01:23:000, {p:3, y:5, z:42}), type id Timestamp “XA” 12 2014-01-01 01:21:000 “XA” 12 2014-02-02 01:23:000 “XB” 48 2014-01-01 01:21:000 “XB” 48 2014-04-02 01:23:000 “XC” 23 2015-01-01 01:21:000 “XC” 23 2015-03-02 01:23:000 BSON/JSON {x:1,y:2} {x:3, y:5, z:42} {c:1,d:”ACND”} {c:92,d:”MCBS”, e:42} {p:1,q:2} {p:3, y:5, z:42}
- 28. Timeseries on JSON CREATE ROW TYPE info( stime datetime year to fraction(5), jdata bson); CREATE TABLE iotdata(id int primary key, tsdata timeseries(info) ); INSERT INTO iotdata VALUES(472,'origin(2014-04-23 00:00:00.00000), …, regular,[({“temp":78, “wind":7.2, “loc":“Miami-1 "})]'); INSERT INTO iotdata values(384,'origin(2014-04-21 00:00:00.00000), …, regular,[({“sleep": 380, “steps":7423, “name":"Joe "})]'); SELECT GetFirstElem(tsdata,0)::row(timestamp datetime year to fraction(5), jdata json) FRONM tj; (expression) ROW('2014-04-21 00:00:00.00000','{“temp":78,“wind":7.2,“loc":“Miami-1"}') (expression) ROW('2014-04-21 00:00:00.00000','{“sleep":380,“steps":7423,“name":"Joe "}')
- 29. Timeseries on JSON Execute procedure TSCreateVirtualTab(…); -- Equivalent relational schema CREATE TABLE iotvti(id INT PRIMARY KEY, stime DATETIME YEAR TO FRACTION(5)), jdata BSON); SELECT id, jdata.temp::int, jdata.loc.city.zip::varchar(32) FROM iotvti WHERE jdata.temp > 75; db.iotvti.find({“jdata.temp”:{$gt:75}, {jdata:1}, {jdata:1}); {“temp":78, “wind":7.2, “loc":“Miami-1 "}
- 30. Informix REST API •REpresentational State Transfer http://<hostname>[:<port#>]/<db>/<collection> •Integrated into Informix •GET /demo/people?sort={age:-1}&fields={_id:0,lastName:0} RESPONSE: [{"firstName":"Anakin","age":49}, {"firstName":"Padme","age":47}, {"firstName":"Luke","age":31}, {"firstName":"Leia","age":31}] GET /stores_demo/ts_data_v?query={loc_esi_id:"4727354321046021"}
- 31. Available Methods Method Path Description POST / Create a new database POST /db Create a new collection POST /db/collection Creates a new document GET / Database listing GET /db Collection listing GET /db/collection Query the collection DELETE / Drop all databases DELETE /db Drop a database DELETE /db/collection Drop a collection DELETE /db/collection?query={...} Delete documents that satisfy the query from a collection PUT /db/collection Update a document INFORMIX REST API
- 32. ODBC, JDBC connections Informix Dynamic Server Tables Tables Relational Tables and views JSON Collections {Customer} partners SQL & BI Applications {Orders} CRM Inventory Tables Timeseries Tables {mobile/devices} Analytics
- 33. Informix Database Server Informix warehouse Accelerator BI Applications Step 1. Install, configure, start Informix Step 2. Install, configure, start Accelerator Step 3. Connect Studio to Informix & add accelerator Step 4. Design, validate, Deploy Data mart Step 5. Load data to accelerator Ready for Queries IBM Smart Analytics Studio Step 1 Step 2 Step 3 Step 4 Step 5 Ready Informix Ultimate Warehouse edition
- 34. 34 INTEL/IWA: Breakthrough technologies for performance 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1. Large memory support 64-bit computing; System X with MAX5 supports up to 6TB on a single SMP box; Up to 640GB on each node of blade center. IWA: Compress large dataset and keep it in memory; totally avoid IO. 7. Multi-core, multi-node environment Nehalem has 8 cores and Westmere 10 cores. This trend is expected to continue. IWA: Parallelize the scan, join, group operations. Keep copies of dimensions to avoid cross-node synchronization. 4. Virtualization Performance Lower overhead: Core micro-architecture enhancements, EPT, VPID, and End-to-End HW assist IWA: Helps informix and IWA to seemlessly run and perform in virtualized environment. 5. Hyperthreading 2x logical processors; increases processor throughput and overall performance of threaded software. IWA: Does not exploit this since the software is written to avoid pipeline flushing. 3. Frequency Partitioning IWA: Enabler for the effective parallel access of the compressed data for scanning. Horizontal and Vertical Partition Elimination. 2. Large on-chip Cache L1 cache 64KB per core, L2 cache is 256KB per core and L3 cache is about 4-12 MB. Additional Translation lookaside buffer (TLB). IWA: New algorithms to avoid pipeline flushing and cache hash tables in L2/L3 cache 6. Single Instruction Multiple Data Specialized instructions for manipulating 128-bit data simultaneously. IWA: Compresses the data into deep columnar fashion optimized to exploit SIMD. Used in parallel predicate evaluation in scans.
- 35. 35 Informix Primary Informix warehouse Accelerator BI Applications Step 1. Install, configure, start Informix Step 2. Install, configure, start Accelerator Step 3. Connect Studio to Informix & add accelerator Step 4. Design, validate, Deploy Data mart from Primary, SDS, HDR, RSS Step 5. Add IWA to sqlhosts Load data to Accelerator from any node. Ready for Queries IBM Smart Analytics Studio Step 1 Step 3 Step 4 Step 5 Ready Informix Warehouse Accelerator – 11.70.FC5. MACH11 Support Informix SDS1 Informix SDS2 Informix HDR Secondary Informix RSS Step 2
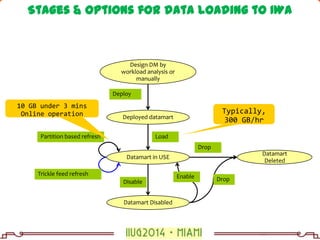
- 36. Design DM by workload analysis or manually Deployed datamart Datamart Deleted Datamart in USE Datamart Disabled Partition based refresh Trickle feed refresh Deploy Load Drop Disable Enable Drop Typically, 300 GB/hr 10 GB under 3 mins Online operation Stages & Options for data loading to IWA
- 37. IWA 1st Release On SMP SMB: IGWE Scale out: IWA on Blade ServerWorkload Analysis Tool More Locales Data Currency IWA: Roadmap Partition Refresh MACH11 support Solaris on Intel Automatic data refresh Union queries Derived tables OAT Integration SQL/OLAP for IWA Timeseries Acceleration 11.7xC2 11.7xC5 12.1xC1 11.7xC3 11.7xC4 2012 IIUG 2013 IIUG TS Data Refresh improvements; Quicker to analysis 12.10.xC2 12.10.xC3 View sup Synonym NoSQL
- 38. Informix Dynamic Server Tables Tables Relational Tables and views JSON Collections {Customer} partners SQL & BI Applications {Orders} CRM Inventory Tables Timeseries Tables {Orders} Text index (BTS) spatial indices Informix Warehouse Accelerator – In-Memory Query Engine ODBC, JDBC connections SQL Apps/Tools MongoDB Drivers NoSQL Apps/Tools
- 39. IWA: Complex Data Analysis Informix Database Server Informix Warehouse Accelerator BI Applications Informix Database Server Factdim1 Dim4 - View dim3 dim2 dim2Informix IoT ApplicationsLoB Apps IoT Applications BI Applications Mobile Apps Informix
- 40. IWA: sensor Data Analysis Informix Database Server Informix Warehouse Accelerator Informix Database Server SQL Table SQL View SQL Table SQL Table SQL TableInformix LoB Apps IoT Applications BI Applications Mobile Apps Informix Timeseries {JSON} {JSON} Cognos SQL Table
- 41. ODBC, JDBC connections Informix Dynamic Server Tables Tables Relational Tables and views JSON Collections {Customer} partners SQL & BI Applications {Orders} CRM Inventory Tables Timeseries Tables {mobile/devices} Analytics Informix warehouse Accelerator
- 42. Create the TS VTI Table TSCreateVirtualTab(); Create Data mart Ifx_TSDW_setCalendar() Ifx_TSDW_CreateWindow( ) Ifx_TSDW_updatePartition( ) Datamart in USE Timeseries data mart Deploy & load Mart; ifx_TSDW_moveWindows()
- 43. insert into calendartable (c_name, c_calendar) values ('2010monthly', 'startdate(2010-01-01 00:00:00.00000), pattstart(2010-01-01 00:00:00.00000), pattern({1 on},month)'); execute function ifx_TSDW_setCalendar('my_accel', 'my_mart', 'my_owner', 'my_table', '2010monthly'); ifx_TSDW_createWindow('my_accel', 'my_mart', 'my_owner', 'my_table', 0, 3); ifx_TSDW_createWindow('my_accel', 'my_mart', 'my_owner', 'my_table', 12, 15); ifx_TSDW_createWindow('my_accel', 'my_mart', 'my_owner', 'my_table', 24, 27); or, by using time stamps to identiy the virtual partitions ifx_TSDW_createWindow('my_accel', 'my_mart', 'my_owner', 'my_table',’2010-01'::datetime year to month, '2010-04'::datetime year to ifx_TSDW_createWindow('my_accel', 'my_mart', 'my_owner', 'my_table','2011-01'::datetime year to month, '2011-04'::datetime year to ifx_TSDW_createWindow('my_accel', 'my_mart', 'my_owner', 'my_table','2012-01'::datetime year to month, '2012-04'::datetime year to time 201220112010 TSVTdata onaccelerator, partitioned monthly time 201220112010
- 44. execute function ifx_TSDW_updatePartition ( 'demo_dwa','demo_mart','informix','ts_data_v', '2011-02'::datetime year to month); execute function ifx_TSDW_dropWindow ( 'demo_dwa','demo_mart','informix','ts_data_v', '2011-02'::datetime year to month);
- 45. Informix TimeSeries: Key Strengths • What is a Time Series? – A logically connected set of records ordered by time • Informix Performance – Time series queries run 60 times or more faster than relational only – Performs operations hard or impossible to run in standard SQL – Data loaders tuned to handle time series data • Informix Space Savings – Saves at least 50% over standard relational layout – Timeseries(JSON) handles variety of sensor data optimally • Informix Flexibility – Develop proprietary algorithms to run inside the database – Join time series, relational, and spatial data in the same query • Informix Ease-of-Use – Integrates easily with any ODBC/JDBC based tools and applications – Conceptually closer to how users think of time series • Informix Warehouse Accelerator – Load standard SQL data types – Exploit VTI projection of timeseries to integrate with tools like Cognos – Use window management procedures to load specific
- 46. Informix: All Together Now! 46 SQL Tables JSON Collections TimeSeries MQ Series SQL APIs JDBC, ODBC Informix IWA – BLU ACCELERATION GENBSON: SQL to {BSON} MongoDB Drivers TEXT SEARCH SPATIAL TIME SERIES {BSON}
- 47. THANK YOU Keshav Murthy rkeshav @ us . ibm . com