Accelerating NLP with Dask on Saturn Cloud: A case study with CORD-19

Python has a great ecosystem of tools for natural language processing (NLP) pipelines, but challenges arise when data sizes and computational complexity grows. Best case, a pipeline is left to run overnight or even over several days. Worst case, certain analyses or computations are just not possible. Dask is a Python-native parallel processing tool that enables Python users to easily scale their code across a cluster of machines. This talk presents an example of an NLP entity extraction pipeline using SciSpacy with Dask for parallelization, which was built and executed on Saturn Cloud. Saturn Cloud is an end-to-end data science and machine learning platform that provides an easy interface for Python environments and Dask clusters, removing many barriers to accessing parallel computing. This pipeline extracts named entities from the CORD-19 dataset, using trained models from the SciSpaCy project, and makes them available for downstream tasks in the form of structured Parquet files. We will provide an introduction to Dask and Saturn Cloud, then walk through the NLP code.





























































![[Webinar] Scientific Computation and Data Visualization with Ruby](https://cdn.slidesharecdn.com/ss_thumbnails/srijantalk-160630120551-thumbnail.jpg?width=560&fit=bounds)






More Related Content
What's hot (20)
Similar to Accelerating NLP with Dask on Saturn Cloud: A case study with CORD-19 (20)







![[Conf42-KubeNative] Building Real-time Pulsar Apps on K8](https://cdn.slidesharecdn.com/ss_thumbnails/conf42-kubenativebuildingreal-timepulsarappsonk8-221020170511-4aa526ec-thumbnail.jpg?width=560&fit=bounds)










More from Sujit Pal (20)




















Recently uploaded (20)




















Accelerating NLP with Dask on Saturn Cloud: A case study with CORD-19
- 1. Saturn Cloud Accelerating NLP with Dask on Saturn Cloud Elsevier Labs Online Lecture November 2020 1
- 2. Hi! Speakers Aaron Richter Senior Data Scientist @ Saturn Cloud [email protected] @rikturr Sujit Pal Technology Research Director @ Elsevier [email protected] @palsujit 2
- 3. Check out the blog post! 🔗 How Elsevier Accelerated COVID-19 research using Dask on Saturn Cloud 3
- 4. Saturn Cloud Data science with Python 4
- 5. Data science with Python 5
- 6. Saturn Cloud What is Dask? 6
- 7. Dask ● Parallel computing for Python people ● Anaconda, ~2015 ● Built in Python; Python API ● Mature, scientific computing communities ● Low-level task library ● High-level libraries for DataFrames, arrays, ML ● Integrates with PyData ecosystem ● Runs on laptop, scales to clusters https://dask.org/ 7
- 8. Dask What does it do? https://docs.dask.org/en/latest/user-interfaces.html ● Parallel machine learning (scikit) ● Parallel dataframes (pandas) ● Parallel arrays (numpy) ● Parallel anything else 8
- 9. What does it do? Arrays and Dataframes https://docs.dask.org/en/latest/array.html https://docs.dask.org/en/latest/dataframe.html 9
- 10. What does it do? Anything else! https://docs.dask.org/en/latest/delayed.html 10
- 11. What does it do? Anything else! https://dask.org/ 11
- 12. Getting up to Speed with Dask https://youtu.be/S_ncqocDcBA 12
- 13. Spark vs. Dask ● Written in Scala with Python API ● All-in-one tool ○ Requires re-write to migrate from PyData code ● Programming model not suited for complex operations (multi-dim arrays, machine learning) ● 100% Python ● Built to extend and interact with PyData ecosystem ● High-level interfaces for DataFrames, (multi-dim) Arrays, and ML ● Native integration with RAPIDS for GPU-acceleration
- 14. 14
- 15. How can I run Dask clusters? ● Manual setup ● SSH ● HPC: MPI, SLURM, SGE, TORQUE, LSF, DRMAA, PBS ● Kubernetes (Docker, Helm) ● Hadoop/YARN ● Cloud provider: AWS or Azure 🔗 https://docs.dask.org/en/latest/setup.html 15
- 16. Saturn Cloud 16
- 17. ● Fast setup ● Enterprise secure ● Pythonic parallelism ● Rapidly scale PyData ● Multi-GPU computing ● The future of HPC ● Workflow orchestration ● Flow insight and mgmt Bringing together the fastest hardware + OSS Saturn Cloud
- 18. ● Saturn manages all infrastructure ● Hosted: Run within our cloud ● Enterprise: Run within your AWS account Saturn Cloud to the rescue! Taking the DevOps out of Data Science 18
- 19. ● Images ● Jupyter server ● Dask Cluster ● Deployments Saturn Cloud Core features 19
- 20. 20
- 21. Saturn Cloud Extracting Entities from CORD-19 21
- 22. Genesis 22
- 23. Genesis 23 ● Based on one of the many COVID-19 initiatives (COVID- KG) ● Original intent: extract entities from CORD-19 dataset for relationship mining.
- 24. Genesis 24 ● Based on one of the many COVID-19 initiatives (COVID- KG) ● Original intent: extract entities from CORD-19 dataset for relationship mining.● CORD-19 dataset open sourced by AllenAI. ● SciSpacy provided Language models trained on Biomedical text, and... ● Pre-trained Named Entity Recognition (and linking) models.
- 25. Genesis 25 ● Based on one of the many COVID-19 initiatives (COVID- KG) ● Original intent: extract entities from CORD-19 dataset for relationship mining.● CORD-19 dataset open sourced by AllenAI. ● SciSpacy provided Language models trained on Biomedical text, and... ● Pre-trained Named Entity Recognition (and linking) models. ● Dask based distributed computing platform ● Opportunity to evaluate.
- 26. Goals ● Create standoff entity annotations for CORD-19, modeled after CAT (Content Analytics Toolbench) from Labs. ● Automated entity recognition using pre-trained SciSpaCy models, where each model recognizes a different subset of entity classes, e.g. DNA, Gene, Protein, Chemical, Organism, Disease, etc. ● Output is structured as Parquet files, consumable via Dask or Spark. ● Share output dataset with community. 26
- 27. CORD-19 Dataset ● Started mid March 2020 with ~40k articles released weekly. ● By Sept/Oct 2020 ~200k articles released daily, growing everyday. ● Each release contains: ○ Metadata file (CSV) ○ Set of articles (JSON) 27
- 28. SciSpaCy NER(L) models ● Medium English LM for sentence splitting. ● 4 NER models ● 5 NERL models using LM’s candidate entity generator and trained entity linking models. 28
- 29. Full Pipeline ● Read metadata.csv ● Parse each JSON file into paragraphs. ● Split paragraphs into sentences. ● Extract entities from sentences using a NER(L) model.. 29
- 30. Embarrassing Parallelism ● Pipeline is embarrassingly parallel. ● Parse files to paragraphs has no dependencies (i.e., perfectly parallel) ● ... ● ... 30
- 31. Embarrassing Parallelism ● Pipeline is embarrassingly parallel ● ... ● Split paragraphs to sentences needs sentence splitter model assigned per partition. ● Load only models that you need. ● … ● ... 31
- 32. Embarrassing Parallelism ● Pipeline is embarrassingly parallel. ● … ● ... ● Extract entities from sentence needs NER model, assign lazily to worker per partition. ● Use nlp.pipe and batching to exploit multithreading. ● ... 32
- 33. Embarrassing Parallelism ● Pipeline is embarrassingly parallel. ● … ● ... ● Extract and link entities from sentence needs Language Model, Entity Linker, etc. assign eagerly per worker after cluster creation. 33
- 34. Parquet Dask / Spark interop ● Output of paragraph, sentence, and entities are in Parquet format. ● Things to keep in mind for Spark interoperability when writing from Dask. ○ Column data types must be declared explicitly on the Dask end. ○ Column names should be specified when saving (“hidden” columns visible in Spark). ○ Explicit re-partitioning may be necessary when saving on Dask. 34
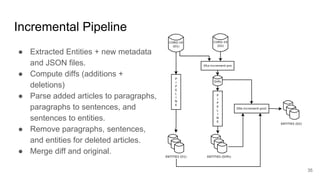
- 35. Incremental Pipeline ● Extracted Entities + new metadata and JSON files. ● Compute diffs (additions + deletions) ● Parse added articles to paragraphs, paragraphs to sentences, and sentences to entities. ● Remove paragraphs, sentences, and entities for deleted articles. ● Merge diff and original. 35
- 36. Deliverables ● Code ○ Set of Jupyter notebooks deployed on Saturn Cloud -- sujitpal/saturn-scispacy ● Data ○ Dataframes in Parquet format (approx 70 GB, 35 for Sep 2020, 35 for Oct 2020). ○ Publicly available on s3://els-saturn-scispacy/cord19-scispacy-entities (requester pays). ○ Available within ELS on Databricks under “/mnt/els/covid-19” -- “/mnt/els/covid-19/saturn- scispacy/annotations-pq-full-20200928” 36
- 37. Output formats 1 paragraph dataframe (3.4M paragraphs), 1 sentence dataframe (17.1M sentences), and 9 entity dataframes (total 805.4M entities). 37
- 38. Utility ● Envisioned usage similar to that for CAT annotations using AnnotationQuery, but for biomedical entities on biomedical data. ● Query dataset using DataFrame API to create interesting micro-datasets datasets potentially spanning across different NER(L) models. Example: ○ Human Phenotypes Annotations from HPO co-occurring in same sentence with Disease Annotations from UMLS or BC5CDR. ○ Gene annotations co-occurring in same sentence with Cancer annotations (both from BioNLP). ● Annotations can be features for Topic Modeling or Categorization. 38
- 39. Additional Resources ● Labs Blog post -- How Elsevier Accelerated COVID-19 research using Dask on Saturn Cloud ● Confluence page -- Dataset of Entity Annotations for CORD-19 ● Book -- Data Science with Python and Dask by Jesse C. Daniel (also available on Percipio) ● Dask online documentation ● Saturn Cloud documentations ● Cloud deployments using Dask ● Query interface example -- AnnotationQuery. 39
Editor's Notes
- #6: Q’s to ask: what other packages do you frequently use? Things that you always import with each notebook/script
- #8: Goal: flexible parallel computing for Python ecosystem. Compatible with lots of packages Generally, if you do something in Python, you can probably make it faster pretty easily with Dask (minimal re-write) Click link, scroll to “powered by Dask”
- #13: Ok so that was Dask, we got another tool to talk about
- #14: Took over big data world post-Hadoop. Still carries Hadoop residue. There is a machine learning library, but is pretty slow (and why re-learn new library, when scikit-learn has more algorithms, plus you already know it) I worked with Spark for years, but always dropped back to PyData after I was done cleaning data Also not great for monitoring/debugging
- #16: If you already have a cluster with one of these mangement tools, you’re good to go Cloud provider - AWS can’t get GPUs
- #19: Contrary to popular belief, this is not zach galifinakis (its robert redford) Show Saturn UI