Adtech x Scala x Performance tuning
4 likes2,483 views

Scala Days 2015 San Francisco Un-conference 2015-03-19 http://event.scaladays.org/scaladays-sanfran-2015





















































![[info] Benchmark Mode Samples Score Score error Units
[info] c.g.m.u.ContainsBench.listContains thrpt 3 41.033 25.573 ops/s
[info] c.g.m.u.ContainsBench.setContains thrpt 3 6.810 1.569 ops/s
Micro Benchmark: sbt-jmh
Result (excerpted)
By default, throughput score
will be displayed.
(larger is better)
http://mogproject.blogspot.jp/2014/10/micro-benchmark-in-scala-using-sbt-jmh.html](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01/85/Adtech-x-Scala-x-Performance-tuning-56-320.jpg)

![def f(xs: List[Int], acc: List[Int] = Nil): List[Int] = {
if (xs.length < 4) {
(xs.sum :: acc).reverse
} else {
val (y, ys) = xs.splitAt(4)
f(ys, y.sum :: acc)
}
}
Horrible and True Story pt.2
Group by 4 elements of List[Int], then
calculate each sum respectively
scala> f((1 to 10).toList)
res1: List[Int] = List(10, 26, 19)
Example](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01/85/Adtech-x-Scala-x-Performance-tuning-58-320.jpg)


![Horrible and True Story pt.2
For your information, the following one-liner does
same work using built-in method
scala> (1 to 10).grouped(4).map(_.sum).toList
res2: List[Int] = List(10, 26, 19)](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01/85/Adtech-x-Scala-x-Performance-tuning-61-320.jpg)





![Result example (excerpted)
ab - Apache Bench
Benchmarking example.com (be patient)
Completed 1200 requests
Completed 2400 requests
(略)
Completed 10800 requests
Completed 12000 requests
Finished 12000 requests
(略)
Concurrency Level: 200
Time taken for tests: 7.365 seconds
Complete requests: 12000
Failed requests: 0
Write errors: 0
Total transferred: 166583579 bytes
HTML transferred: 160331058 bytes
Requests per second: 1629.31 [#/sec] (mean)
Time per request: 122.751 [ms] (mean)
Time per request: 0.614 [ms] (mean, across all concurrent requests)
Transfer rate: 22087.90 [Kbytes/sec] received
(略)
Percentage of the requests served within a certain time (ms)
50% 116
66% 138
75% 146
80% 150
90% 161
95% 170
98% 185
99% 208
100% 308 (longest request)
Requests per second
= QPS](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01/85/Adtech-x-Scala-x-Performance-tuning-67-320.jpg)










![SLF4J + Profiler
Output example
Example:
Log the result of the profiler when
timeout occurs
Profiler
+ Profiler [BASIC]
|-- elapsed time [A] 220.487 milliseconds.
|-- elapsed time [B] 2499.866 milliseconds.
|-- elapsed time [OTHER] 3300.745 milliseconds.
|-- Total [BASIC] 6022.568 milliseconds.](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01/85/Adtech-x-Scala-x-Performance-tuning-78-320.jpg)



!["Yosuke Mizutani - Kanagawa, Japan | about.me" - http://about.me/mogproject
"mog project" - http://mogproject.blogspot.jp/
"DSS Tech Blog - Demand Side Science ㈱ の技術ブログ" - http://demand-side-
science.jp/blog/
"FunctionalNews - 関数型言語ニュースサイト" - http://functional-news.com/
"『ザ・アドテクノロジー』∼データマーケティングの基礎からアトリビューション
の概念まで∼ / 翔泳社 新刊のご紹介" - http://markezine.jp/book/adtechnology/
"オプト、ダイナミック・クリエイティブツール「unis」の提供開始 ∼ パーソナラ
イズ化された広告を自動生成し、広告効果の最大化を目指す ∼ | インターネット広
告代理店 オプト" - http://www.opt.ne.jp/news/pr/detail/id=2492
"The Scala Programming Language" - http://www.scala-lang.org/
"Finagle" - https://twitter.github.io/finagle/
"Play Framework - Build Modern & Scalable Web Apps with Java and Scala" -
https://www.playframework.com/
"nginx" - http://nginx.org/ja/
"Fluentd | Open Source Data Collector" - http://www.fluentd.org/
"Javaパフォーマンスチューニング(1):Javaパフォーマンスチューニングのルー
ル (1/2) - @IT" - http://www.atmarkit.co.jp/ait/articles/0501/29/news011.html
"パレートの法則 - Wikipedia" - http://ja.wikipedia.org/wiki/パレートの法則
"Teach Yourself Programming in Ten Years" - http://norvig.com/21-
days.html#answers
"企業が作る国際ネットワーク最前線 - [4]いまさら聞けない国際ネットワークの
基礎知識:ITpro" - http://itpro.nikkeibp.co.jp/article/COLUMN/20100119/
343461/
"Coursera" - https://www.coursera.org/course/reactive
"アースマラソン - Wikipedia" - http://ja.wikipedia.org/wiki/アースマラソン
"Hard disk drive - Wikipedia, the free encyclopedia" - http://en.wikipedia.org/
wiki/Hard_disk_drive
"Everything I ever learned about JVM performance tuning @twitter(Attila
Szegedi).pdf" - http://www.beyondlinux.com/files/pub/qconhangzhou2011/
Everything%20I%20ever%20learned%20about%20JVM%20performance
%20tuning%20@twitter%28Attila%20Szegedi%29.pdf
"Amazon.co.jp: C++ Coding Standards―101のルール、ガイドライン、ベストプ
ラクティス (C++ in-depth series): ハーブ サッター, アンドレイ アレキサンドレス
ク, 浜田 光之, Herb Sutter, Andrei Alexandrescu, 浜田 真理: 本" - http://
www.amazon.co.jp/gp/product/4894716860
"UNIX哲学 - Wikipedia" - http://ja.wikipedia.org/wiki/UNIX哲学
"ktoso/sbt-jmh" - https://github.com/ktoso/sbt-jmh
"ScalaBlitz | ScalaBlitz" - http://scala-blitz.github.io/
"Parleys.com - Lightning-Fast Standard Collections With ScalaBlitz by Dmitry
Petrashko" - https://parleys.com/play/53a7d2c6e4b0543940d9e549/chapter0/
about
"mog project: Micro Benchmark in Scala - Using sbt-jmh" - http://
mogproject.blogspot.jp/2014/10/micro-benchmark-in-scala-using-sbt-jmh.html
"Gatling Project, Stress Tool" - http://gatling.io/
"WEB+DB PRESS Vol.83|技術評論社" - http://gihyo.jp/magazine/wdpress/
archive/2014/vol83
"「Javaの鉱脈」でGatlingの記事を書きました — さにあらず" - http://
blog.satotaichi.info/gatling-is-awesome-loadtester
"Garbage Collection Tuning in the Java HotSpot™ Virtual Machine" - http://
www.oracle.com/technetwork/server-storage/ts-4887-159080.pdf
"SLF4J extensions" - http://www.slf4j.org/extensions.html
"Graphite Documentation — Graphite 0.10.0 documentation" - http://
graphite.readthedocs.org/en/latest/
"Grafana - Graphite and InfluxDB Dashboard and graph composer" - http://
grafana.org/
"Grafana - Grafana Play Home" - http://play.grafana.org/#/dashboard/db/
grafana-play-home
"不動産関係に使える 無料画像一覧" - http://free-realestate.org/information/
list.html
"AI・EPSの無料イラストレーター素材なら無料イラスト素材.com" - http://www.無
料イラスト素材.com/
"大体いい感じになるKeynoteテンプレート「Azusa」作った - MEMOGRAPHIX" -
http://memo.sanographix.net/post/82160791768
References](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01/85/Adtech-x-Scala-x-Performance-tuning-83-320.jpg)
![[214]유연하고 확장성 있는 빅데이터 처리](https://cdn.slidesharecdn.com/ss_thumbnails/214-171017023620-thumbnail.jpg?width=560&fit=bounds)





![[262] netflix 빅데이터 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/226netflix-150915054913-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)












![[212]big models without big data using domain specific deep networks in data-...](https://cdn.slidesharecdn.com/ss_thumbnails/212bigmodelswithoutbigdatausingdomain-specificdeepnetworksindata-scarcesettings-171017003514-thumbnail.jpg?width=560&fit=bounds)










Ad
More Related Content
What's hot (20)
Viewers also liked (8)






Ad
Similar to Adtech x Scala x Performance tuning (20)




















Ad
Recently uploaded (20)





![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)














Adtech x Scala x Performance tuning
- 1. × ∼ Best Practice for Better Performance ∼ Scala Days 2015 San Francisco Un-conference 2015-03-19 @mogproject Ad Tech Performance Tuning Scala ×
- 2. Agenda About Demand Side Science Introduction to Performance Tuning Best Practice in Development Japanese language version here: http://www.slideshare.net/mogproject/scala-41799241
- 3. Yosuke Mizutani (@mogproject) Joined Demand Side Science in April 2013 (thanks to Scala Conference in Japan 2013) Full-stack engineer (want to be…) Background: 9-year infrastructure engineer About Me
- 8. Nov 2012 Established Demand Side Science Inc. Brief History of DSS Demand × Side Science×
- 9. 2013 Developed private DSP package fractale Brief History of DSS Demand × Side Platform×
- 10. Advertiser’s side of realtime ads bidding (RTB) What is DSP Supply Side Platform
- 11. Dec 2013 Moved into the group of Opt, the e-marketing agency Oct 2014 Released dynamic creative tool unis Brief History of DSS × ×
- 12. unis is a third-party ad server which creates dynamic and/or personalized ads under the rules. http://www.opt.ne.jp/news/pr/detail/id=2492 unis items on sale most popular items fixed items re-targeting
- 13. With venture mind + advantage of Opt group … Future of DSS Demand × Side Science×
- 14. We will create various products based on Science! Future of DSS ??? × ??? Science×
- 15. For everyone’s … Future of DSS Marketer × Publisher Consumer×
- 16. happiness! Future of DSS Win × Win Win×
- 17. We DSS and Scala Adopt Scala × for all products from the day of establishment ×
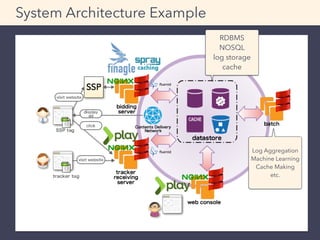
- 18. System Architecture Example RDBMS NOSQL log storage cache Log Aggregation Machine Learning Cache Making etc.
- 19. Today, I will not talk about JavaScript tuning. System Architecture Example
- 20. Agenda About Demand Side Science Introduction to Performance Tuning Best Practice in Development
- 21. Resolve an issue Reduce infrastructure cost (e.g. Amazon Web Services) Motivations
- 22. Application goes wrong with high load Bad latency under the specific condition Slow batch execution than expectations Slow development tools Resolve an Issue
- 23. Very important especially in ad tech industry Cost tends to go bigger and bigger High traffic Need to response in few milli seconds Big database, big log data Business requires Benefit from mass delivery > Infra Investment Reduce Infrastructure Cost
- 24. You need to care about cost (≒ engineer’s time) and risk (possibility to cause new trouble) for performance tuning itself. Don’t lose you goal Scaling up/out of Infra can be the best solution, naively Don’t want to be perfect
- 25. We iterate Basic of Performance Tuning Measure metrics × Find bottleneck Try with hypothesis× Don't take erratic steps.
- 26. http://en.wikipedia.org/wiki/Pareto_principle “80% of a program’s processing time come from 20% of the code” — Pareto Principle
- 27. ※CAUTION: This is my own impression Bottle Neck in My Experience others 1% Network 4% JVM parameter 5% Library 5% OS 10% Scala 10% Async・Thread 15% Database (RDBMS/NOSQL) 50%
- 28. What is I/O Memory × Disk Network×
- 29. Approximate timing for various operations http://norvig.com/21-days.html#answers execute typical instruction 1/1,000,000,000 sec = 1 nanosec fetch from L1 cache memory 0.5 nanosec branch misprediction 5 nanosec fetch from L2 cache memory 7 nanosec Mutex lock/unlock 25 nanosec fetch from main memory 100 nanosec send 2K bytes over 1Gbps network 20,000 nanosec read 1MB sequentially from memory 250,000 nanosec fetch from new disk location (seek) 8,000,000 nanosec read 1MB sequentially from disk 20,000,000 nanosec send packet US to Europe and back 150 milliseconds = 150,000,000 nanosec
- 30. If Typical Instruction Takes 1 second… https://www.coursera.org/course/reactive week3-2 execute typical instruction 1 second fetch from L1 cache memory 0.5 seconds branch misprediction 5 seconds fetch from L2 cache memory 7 seconds Mutex lock/unlock ½ minute fetch from main memory 1½ minute send 2K bytes over 1Gbps network 5½ hours read 1MB sequentially from memory 3 days fetch from new disk location (seek) 13 weeks read 1MB sequentially from disk 6½ months send packet US to Europe and back 5 years
- 31. A batch reads 1,000,000 files of 10KB from disk for each time. Data size: 10KB × 1,000,000 ≒ 10GB Horrible and True Story
- 32. Assuming 1,000,000 seeks are needed, Estimated time: 8ms × 106 + 20ms × 10,000 ≒ 8,200 sec ≒ 2.5 h If there is one file of 10GB and only one seek is needed, Estimated time: 8ms × 1 + 20ms × 10,000 ≒ 200 sec ≒ 3.5 min Horrible and True Story
- 33. Have Respect for the Disk Head http://en.wikipedia.org/wiki/Hard_disk_drive
- 34. JVM Trade-offs JVM Performance Triangle Memory Footprint ↓ Throughput ↑ Latency ↓ longest pause time for Full GC
- 35. In the other words… JVM Performance Triangle Compactness Throughput Responsiveness
- 36. C × T × R = a JVM Performance Triangle Tuning: vary C, T, R for fixed a Optimization: increase a Reference: Everything I ever learned about JVM performance tuning @twitter by Attila Szegedi http://www.beyondlinux.com/files/pub/qconhangzhou2011/Everything%20I%20ever%20learned %20about%20JVM%20performance%20tuning%20@twitter%28Attila%20Szegedi%29.pdf
- 37. Agenda About Demand Side Science Introduction to Performance Tuning Best Practice in Development
- 38. 1. Requirement Definition / Feasibility 2. Basic Design 3. Detailed Design 4. Building Infrastructure / Coding 5. System Testing 6. System Operation / Maintenance Development Process Only topics related to performance will be covered.
- 39. Make the agreement with stakeholders about performance requirement Requirement Definition / Feasibility How many user IDs internet users in Japan: 100 million unique browsers: 200 ~ x00 million will increase? data expiration cycle? type of devices / browsers? opt-out rate?
- 40. Requirement Definition / Feasibility Number of deliver requests for ads Number of impressions per month In case 1 billion / month => mean: 400 QPS (Query Per Second) => if peak rate = 250%, then 1,000 QPS For RTB, bid rate? win rate? Goal response time? Content size? Plans for increasing? How about Cookie Sync?
- 41. Requirement Definition / Feasibility Number of receiving trackers Timing of firing tracker Click rate? Conversion(*) rate? * A conversion occurs when the user performs the specific action that the advertiser has defined as the campaign goal. e.g. buying a product in an online store
- 42. Requirement Definition / Feasibility Requirement for aggregation Indicates to be aggregated Is unique counting needed? Any exception rules? Who and when secondary processing by ad agency? Update interval Storage period
- 43. Requirement Definition / Feasibility Hard limit by business side Sales plan Christmas selling? Annual sales target? Total budget
- 44. The most important thing is to provide numbers, although it is extremely difficult to approximate precisely in the turbulent world of ad tech. Requirement Definition / Feasibility Architecture design needs assumed value Performance testing needs numeric goal
- 45. Architecture design Choose framework Web framework Choose database RDBMS NOSQL Basic Design
- 46. Threading model design Reduce blocking Future based Callback & function composition Actor based Message passing Thread pool design We can’t know the appropriate thread pool size unless we complete performance testing in production. Basic Design
- 47. Database design Access pattern / Number of lookup Data size per one record Create model of distribution when the size is not constant Number of records Rate of growth / retention period Memory usage At first, measure the performance of the database itself Detailed Design
- 48. Log design Consider compression ratio for disk usage Cache design Some software needs the double of capacity for processing backup (e.g. Redis) Detailed Design
- 49. Simplicity and clarity come first “It is far, far easier to make a correct program fast than it is to make a fast program correct” — C++ Coding Standards: 101 Rules, Guidelines, and Best Practices (C ++ in-depth series) Building Infrastructure / Coding
- 50. — Donald Knuth “Premature optimization is the root of all evil.”
- 51. — Jon Bentley “On the other hand, we cannot ignore efficiency”
- 52. Avoid the algorithm which is worse than linear as possible Measure, don’t guess http://en.wikipedia.org/wiki/Unix_philosophy Building Infrastructure / Coding
- 53. SBT Plugin for running OpenJDK JMH (Java Microbenchmark Harness: Benchmark tool for Java) https://github.com/ktoso/sbt-jmh Micro Benchmark: sbt-jmh
- 54. addSbtPlugin("pl.project13.scala" % "sbt-jmh" % "0.1.6") Micro Benchmark: sbt-jmh plugins.sbt jmhSettings build.sbt import org.openjdk.jmh.annotations.Benchmark class YourBench { @Benchmark def yourFunc(): Unit = ??? // write code to measure } YourBench.scala Just put an annotation
- 55. > run -i 3 -wi 3 -f 1 -t 1 Micro Benchmark: sbt-jmh Run benchmark in the sbt console Number of measurement iterations to do Number of warmup iterations to do How many times to forks a single benchmark Number of worker threads to run with
- 56. [info] Benchmark Mode Samples Score Score error Units [info] c.g.m.u.ContainsBench.listContains thrpt 3 41.033 25.573 ops/s [info] c.g.m.u.ContainsBench.setContains thrpt 3 6.810 1.569 ops/s Micro Benchmark: sbt-jmh Result (excerpted) By default, throughput score will be displayed. (larger is better) http://mogproject.blogspot.jp/2014/10/micro-benchmark-in-scala-using-sbt-jmh.html
- 57. Scala Optimization Example Use Scala collection correctly Prefer recursion to function call by Prof. Martin Odersky in Scala Matsuri 2014 Try optimization libraries
- 58. def f(xs: List[Int], acc: List[Int] = Nil): List[Int] = { if (xs.length < 4) { (xs.sum :: acc).reverse } else { val (y, ys) = xs.splitAt(4) f(ys, y.sum :: acc) } } Horrible and True Story pt.2 Group by 4 elements of List[Int], then calculate each sum respectively scala> f((1 to 10).toList) res1: List[Int] = List(10, 26, 19) Example
- 59. Horrible and True Story pt.2 List#length takes time proportional to the length of the sequence When the length of the parameter xs is n, time complexity of List#length is O(n) Implemented in LinearSeqOptimized#length https://github.com/scala/scala/blob/v2.11.4/src/library/scala/collection/ LinearSeqOptimized.scala#L35-43
- 60. Horrible and True Story pt.2 In function f, xs.length will be evaluated n / 4 + 1 times, so number of execution of f is also proportional to n Therefore, time complexity of function f is O(n2) It becomes too slow with big n
- 61. Horrible and True Story pt.2 For your information, the following one-liner does same work using built-in method scala> (1 to 10).grouped(4).map(_.sum).toList res2: List[Int] = List(10, 26, 19)
- 62. ScalaBlitz
- 63. Library for optimising Scala collection (by using macro) http://scala-blitz.github.io/ Presentation in Scala Days 2014 https://parleys.com/play/ 53a7d2c6e4b0543940d9e549/chapter0/ about ScalaBlitz
- 64. System feature testing Interface testing Performance testing Reliability testing Security testing Operation testing System Testing
- 65. Simple load testing Scenario load testing mixed load with typical user operations Aging test (continuously running test) Performance Testing
- 66. Apache attached Simple benchmark tool http://httpd.apache.org/docs/2.2/programs/ab.html Adequate for naive requirements Latest version recommended (Amazon Linux pre-installed version’s bug made me sick) Example ab - Apache Bench ab -C <CookieName=Value> -n <NumberOfRequests> -c <Concurrency> “<URL>“
- 67. Result example (excerpted) ab - Apache Bench Benchmarking example.com (be patient) Completed 1200 requests Completed 2400 requests (略) Completed 10800 requests Completed 12000 requests Finished 12000 requests (略) Concurrency Level: 200 Time taken for tests: 7.365 seconds Complete requests: 12000 Failed requests: 0 Write errors: 0 Total transferred: 166583579 bytes HTML transferred: 160331058 bytes Requests per second: 1629.31 [#/sec] (mean) Time per request: 122.751 [ms] (mean) Time per request: 0.614 [ms] (mean, across all concurrent requests) Transfer rate: 22087.90 [Kbytes/sec] received (略) Percentage of the requests served within a certain time (ms) 50% 116 66% 138 75% 146 80% 150 90% 161 95% 170 98% 185 99% 208 100% 308 (longest request) Requests per second = QPS
- 68. Load testing tool written in Scala http://gatling.io Gatling
- 69. An era of Apache JMeter has finished Say good bye to scenario making with GUI With Gatling, You load write scenario with Scala DSL Gatling
- 70. Care for the resource of stressor side Resource of server (or PC) Network router (CPU) can be bottleneck Don’t tune two or more parameters at one time Leave change log and log files Days for Testing and Tuning
- 71. System Operation / Maintenance Logging × Anomaly Detection Trends Visualization×
- 72. Day-to-day logging and monitoring Application log GC log Profiler Anomaly detection from several metrics Server resource (CPU, memory, disk, etc.) abnormal response code Latency Trends visualization from several metrics System Operation / Maintenance
- 73. GC log Add JVM options as follows JVM Settings -verbose:gc -Xloggc:<PathToTheLog> -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M
- 74. — Real customer “If someone doesn’t enable GC logging in production, I shoot them! http://www.oracle.com/technetwork/server-storage/ts-4887-159080.pdf p55
- 75. JMX (Java Management eXtensions) Add JVM options as follows JVM Settings -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=<PORT NUMBER> -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
- 76. stdout / stderr Should redirect to file Should NOT throw away to /dev/null Result of thread dump (kill - 3 <PROCESS_ID>) will be written here JVM Settings
- 77. SLF4J + Profiler http://www.slf4j.org/extensions.html Coding example Profiler import org.slf4j.profiler.Profiler val profiler: Profiler = new Profiler(this.getClass.getSimpleName) profiler.start(“A”) doA() profiler.start(“B”) doB() profiler.stop() logger.warn(profiler.toString)
- 78. SLF4J + Profiler Output example Example: Log the result of the profiler when timeout occurs Profiler + Profiler [BASIC] |-- elapsed time [A] 220.487 milliseconds. |-- elapsed time [B] 2499.866 milliseconds. |-- elapsed time [OTHER] 3300.745 milliseconds. |-- Total [BASIC] 6022.568 milliseconds.
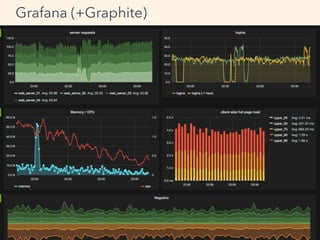
- 79. For catching trends, not for anomaly detection Operation is also necessary not to look over the sign of change Not only for infrastructure /application, but business indicates Who uses the console? System user System administrator Application developer Business manager Trends Visualization
- 81. Graphite - http://graphite.readthedocs.org Manage and visualize numeric time-series data Grafana - http://grafana.org/ Visualize Graphite data more stylish (or Kibana-like) Grafana (+Graphite)
- 82. × ∼ Best Practice for Better Performance ∼ Scala Days 2015 San Francisco Un-conference 2015-03-19 @mogproject Thank very much! you ×
- 83. "Yosuke Mizutani - Kanagawa, Japan | about.me" - http://about.me/mogproject "mog project" - http://mogproject.blogspot.jp/ "DSS Tech Blog - Demand Side Science ㈱ の技術ブログ" - http://demand-side- science.jp/blog/ "FunctionalNews - 関数型言語ニュースサイト" - http://functional-news.com/ "『ザ・アドテクノロジー』∼データマーケティングの基礎からアトリビューション の概念まで∼ / 翔泳社 新刊のご紹介" - http://markezine.jp/book/adtechnology/ "オプト、ダイナミック・クリエイティブツール「unis」の提供開始 ∼ パーソナラ イズ化された広告を自動生成し、広告効果の最大化を目指す ∼ | インターネット広 告代理店 オプト" - http://www.opt.ne.jp/news/pr/detail/id=2492 "The Scala Programming Language" - http://www.scala-lang.org/ "Finagle" - https://twitter.github.io/finagle/ "Play Framework - Build Modern & Scalable Web Apps with Java and Scala" - https://www.playframework.com/ "nginx" - http://nginx.org/ja/ "Fluentd | Open Source Data Collector" - http://www.fluentd.org/ "Javaパフォーマンスチューニング(1):Javaパフォーマンスチューニングのルー ル (1/2) - @IT" - http://www.atmarkit.co.jp/ait/articles/0501/29/news011.html "パレートの法則 - Wikipedia" - http://ja.wikipedia.org/wiki/パレートの法則 "Teach Yourself Programming in Ten Years" - http://norvig.com/21- days.html#answers "企業が作る国際ネットワーク最前線 - [4]いまさら聞けない国際ネットワークの 基礎知識:ITpro" - http://itpro.nikkeibp.co.jp/article/COLUMN/20100119/ 343461/ "Coursera" - https://www.coursera.org/course/reactive "アースマラソン - Wikipedia" - http://ja.wikipedia.org/wiki/アースマラソン "Hard disk drive - Wikipedia, the free encyclopedia" - http://en.wikipedia.org/ wiki/Hard_disk_drive "Everything I ever learned about JVM performance tuning @twitter(Attila Szegedi).pdf" - http://www.beyondlinux.com/files/pub/qconhangzhou2011/ Everything%20I%20ever%20learned%20about%20JVM%20performance %20tuning%20@twitter%28Attila%20Szegedi%29.pdf "Amazon.co.jp: C++ Coding Standards―101のルール、ガイドライン、ベストプ ラクティス (C++ in-depth series): ハーブ サッター, アンドレイ アレキサンドレス ク, 浜田 光之, Herb Sutter, Andrei Alexandrescu, 浜田 真理: 本" - http:// www.amazon.co.jp/gp/product/4894716860 "UNIX哲学 - Wikipedia" - http://ja.wikipedia.org/wiki/UNIX哲学 "ktoso/sbt-jmh" - https://github.com/ktoso/sbt-jmh "ScalaBlitz | ScalaBlitz" - http://scala-blitz.github.io/ "Parleys.com - Lightning-Fast Standard Collections With ScalaBlitz by Dmitry Petrashko" - https://parleys.com/play/53a7d2c6e4b0543940d9e549/chapter0/ about "mog project: Micro Benchmark in Scala - Using sbt-jmh" - http:// mogproject.blogspot.jp/2014/10/micro-benchmark-in-scala-using-sbt-jmh.html "Gatling Project, Stress Tool" - http://gatling.io/ "WEB+DB PRESS Vol.83|技術評論社" - http://gihyo.jp/magazine/wdpress/ archive/2014/vol83 "「Javaの鉱脈」でGatlingの記事を書きました — さにあらず" - http:// blog.satotaichi.info/gatling-is-awesome-loadtester "Garbage Collection Tuning in the Java HotSpot™ Virtual Machine" - http:// www.oracle.com/technetwork/server-storage/ts-4887-159080.pdf "SLF4J extensions" - http://www.slf4j.org/extensions.html "Graphite Documentation — Graphite 0.10.0 documentation" - http:// graphite.readthedocs.org/en/latest/ "Grafana - Graphite and InfluxDB Dashboard and graph composer" - http:// grafana.org/ "Grafana - Grafana Play Home" - http://play.grafana.org/#/dashboard/db/ grafana-play-home "不動産関係に使える 無料画像一覧" - http://free-realestate.org/information/ list.html "AI・EPSの無料イラストレーター素材なら無料イラスト素材.com" - http://www.無 料イラスト素材.com/ "大体いい感じになるKeynoteテンプレート「Azusa」作った - MEMOGRAPHIX" - http://memo.sanographix.net/post/82160791768 References