Ambari hadoop-ops-meetup-2013-09-19.final
3 likes1,676 views

Sumit Mohanty's talk from #lspe http://www.meetup.com/SF-Bay-Area-Large-Scale-Production-Engineering/events/129859402/


















































Ad
More Related Content
What's hot (18)
Viewers also liked (20)
















Ad
Similar to Ambari hadoop-ops-meetup-2013-09-19.final (20)




















Ad
More from Chris Westin (20)




















Recently uploaded (20)




















Ambari hadoop-ops-meetup-2013-09-19.final
- 1. Managing Your Hadoop Clusters with Apache Ambari September 19, 2013 Sumit Mohanty @ Hortonworks
- 2. Hello! • Sumit Mohanty –Committer / PPMC member, Apache Ambari –Member of Technical Staff @ Hortonworks –[email protected] Page 2
- 3. Today, We’ll Go Over… • Intro • Features • Demo • Architecture • Futures • Q & A Page 3
- 4. Ambari: Enterprise Hadoop Operations Ambari is an open source framework for provisioning, managing and monitoring Apache Hadoop clusters HADOOP Storage & Process at Scale AMBARI PROVISION MANAGE MONITOR AMBARI WEB Page 4
- 5. Apache Ambari – 100% Open Source! • Active community • 50+ Contributors / 30+ Committers • 170+ Ambari User Group Members • Steady progress/release cycle Page 5 Release Version Release Date JIRAs Resolved 0.9.0 Sep 2012 402 1.2.0 Feb 2013 441 1.2.1 Mar 2013 134 1.2.2 Apr 2013 106 1.2.3 Jun 2013 515 1.2.4 Jul 2013 113 1.2.5 Sep 2013 350 1.4.x Oct 2013 580+ Current Release Today’s Demo
- 6. Features Today Provisioning: Simplified deployment across platforms Managing: Consistent controls across the Stack Monitoring: Visibility into key cluster metrics - Single pane of glass for Hadoop & System status - Pre-configured metrics & alerts - Single point for cluster operations - Customize w/o dealing with Hadoop complexities - Advanced configurations and host controls - Wizard-driven cluster install experience - Deploy 10s,100s or 1000s of Hadoop servers - Cloud, virtual and physical environments Page 6
- 7. New Features • Add slaves components to hosts • Stop/Start All Services • Enable Kerberos Security • Enable NameNode HA • Host Status Filtering Page 7
- 8. New Features • Provision, manage and monitoring Hadoop 2.0 Stack • HDFS2, YARN, MR2 • HBase –New Heatmaps specific to Region Servers Page 8
- 9. New Features • Ambari supports Postgres, Oracle • Configure Hive and Oozie to use MySQL or Oracle • Ambari + Redhat GlusterFS Integration • Deploy / manage cluster with dist. file system other than HDFS –HCFS: GlusterFS as first implementation –Pluggability with other HCFS’s Page 9
- 10. Demo Page 10
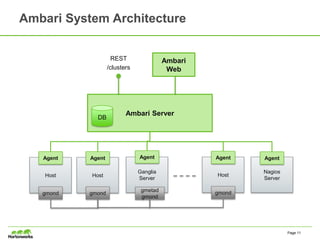
- 11. Ambari System Architecture Ambari Server Host Agent gmond Host Agent gmond Ganglia Server Agent Host Agent gmondgmetad gmond Ambari Web DB REST /clusters Nagios Server Agent Page 11
- 12. Ambari Architecture Page 12 DB Orchestrator SPI REST API Request Dispatcher Ambari Web Ambari Server Metrics AuthProvider /clusters /services /hosts /workflows/jobs /users, … User Store java RDBMS javascript RDBM S AD/ LDAP REST API for integration Auth Provider Cluster Configurations Web Client 100% REST Ambari Agents ganglia nagios Alerts Pluggable Service Providersfalcon Data Mgmt jmx python puppet
- 13. Ambari Futures Extend core capabilities to include the critical tasks associated with provisioning and operating Hadoop clusters. Cluster Operations Enable insight into job performance and reduce the burden on specialized Hadoop skills and knowledge. Job Diagnostics Expose integration and customization points so Hadoop can interoperate with existing operational tooling. Extensible Platform Make Hadoop easier to manage Page 13
- 14. Beyond 1.4 • Ambari Python CLI • Delete Hosts • Add Services • Improved Configuration Mgmt with host-level overrides • Log Aggregation • Rack awareness • Manage Full Stack HA • Customizable Metric Graphs and Heatmaps • Capacity Scheduler Usage Reporting • Job Diagnostics Improvements • Ambari Server HA • Finer-grain Ambari user roles • Cluster Manifest (cluster takeover) • New Services: Accumulo, Falcon, Flume, Knox, Storm, … • HDFS Mirroring/Rebalance • HBase Compaction Page 14
- 15. Host Group Configuration Controls • Set custom configuration properties at the host level for one or more hosts • Important for handing “heterogeneous” clusters • AMBARI-1509 and AMBARI-1370 HEAPSIZE= 1024 HEAPSIZE= 2048 Page 15
- 16. Ambari + Accumulo Integration • Using Ambari to deploy / manage cluster with Accumulo –Google Summer of Code project –See AMBARI-1930 MapReduce Hive Distributed File System HBasePig Page 16
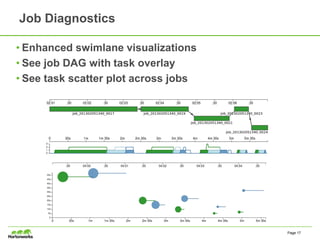
- 17. Job Diagnostics • Enhanced swimlane visualizations • See job DAG with task overlay • See task scatter plot across jobs Page 17
- 18. Stack Definitions • Design Goals –Ambari should be able to support choice of Hadoop stacks –Ambari should enable adding new components to an existing stack • Define which Services are available (services) • Define where to get the packages (repos) S S S SStack B repos services S S S SStack A repos services S S S S Stack C extends Stack B repos services S S+ Page 18
- 19. Cluster Blueprints • Perform “Headless Install” • Export blueprint from cluster • Boot wizard with blueprint • Save wizard as blueprint BLUEPRINT <stack> <host> <service> <component> <config> Ambari Server MANIFEST <host> <meta> <configs> <configs> <config> Blueprint Page 19
- 20. APIs, APIs, and More APIs • Consistent front-end REST API • Service Provider plugin architecture “ZERO TOUCH” INSTALLS “LIGHTS OUT” WORKFLOWS “BRING MY OWN” SCENARIOS Blueprint ClusterAmbari Alarm Decom Inform Custom Provider Page 20
- 21. Get Involved! • Project Website – http://incubator.apache.org/ambari/ • Check out Ambari – Quick Start Guide – https://cwiki.apache.org/confluence/display/AMBARI/Quick+Start+Guide • Mailing Lists – [email protected] – [email protected] • IRC Chanel – @apacheambari • Upcoming Meet-up, Sep 25 (Wednesday) – http://www.meetup.com/Apache-Ambari-User-Group/ Page 21