An Intro to Elasticsearch and Kibana
Download as PPTX, PDF1 like3,250 views

Visualize some of Austin's open source data using Elasticsearch with Kibana. ObjectRocket's Steve Croce presented this talk on 10/13/17 at the DBaaS event in Austin, TX.












































Ad
More Related Content
What's hot (20)
Similar to An Intro to Elasticsearch and Kibana (20)


















Ad
Recently uploaded (20)




















Ad
An Intro to Elasticsearch and Kibana
- 1. www.objectrocket.com An Intro to Elasticsearch and Kibana Visualizing Austin’s Data
- 2. www.objectrocket.com You Know, for Search What is Elasticsearch: A distributed, real-time, document store / search engine It easily scales to hundreds of servers and TBs of data Data is searchable as it is added Less strict schema or SQL-like rigidity. Very JSONified Best full text search capabilities of any technology in this space ● In Top 10 Databases by DB-Engines ● Used by customers across industries: Facebook, Uber, Tinder, Yelp, ebay, Dell, Cisco, The Home Depot, etc. ● WHY? ○ Easy to Bootstrap ○ Multiple Use Cases ○ Community / Ecosystem ○ Compatibility / JSON RESTful
- 3. www.objectrocket.com X-Pack ($$$) Security Alerting Monitoring Graph Machine Learning Kibana (FOSS) GUI Data Visualization Dashboards Elasticsearch (FOSS) Storage Indexing Search Cluster Management Logstash (FOSS) Extract / Transform / Load - and More The Elastic Stack / Ecosystem Beats (FOSS) Lightweights apps to ship data FOSS = Free Open Source Software FileBeat MetricBeat HeartBeat PacketBeat WinlogBeat Curator (FOSS) Index maintenance
- 4. www.objectrocket.com Where can you use it? ● Mongo / CouchDB / MySQL / PostgreSQL / Kafka shop? ○ Use Elasticsearch/Kibana to visualize your data ○ Logstash + jdbc input plugin can sync from any compatible DB ○ Try our MongoDB->Elasticsearch connector (Beta) ● Hadoop shop? ○ Use Elasticsearch to add search and viz to your Hadoop data ○ Elasticsearch-Hadoop and other tools can make this easier ● Has servers of any kind shop? ○ Use Elasticsearch for log and metrics analysis and visualization ○ Filebeat / Winlogbeat make log ingest easy ○ Metricbeat / Packetbeat / Heartbeat for metrics management
- 5. www.objectrocket.com Sample Datasets for today Austin Restaurant Inspections (2013-2017) Sourced from data.austintexas.gov Rideaustin data (June 2016 - April 2017) Sourced from data.world
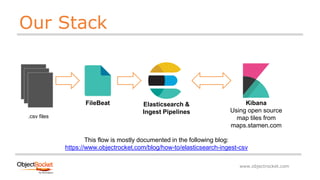
- 6. www.objectrocket.com Our Stack FileBeat Elasticsearch & Ingest Pipelines .csv files Kibana Using open source map tiles from maps.stamen.com This flow is mostly documented in the following blog: https://www.objectrocket.com/blog/how-to/elasticsearch-ingest-csv
- 7. www.objectrocket.com Document Example Meta-Fields ● _index : What index is it in ● _type: document type ● _id: Unique document identifier ● _score: Computed relevance to search Document “Body” ● Holds whatever fields you create ● Data type is defined by mapping ● Data types include ○ Simple: booleans, numerics, dates ○ Geographic: points and shapes ○ Text: analyzed and non-analyzed ○ Special: IPs, range, percolator
- 8. www.objectrocket.com 8 API Query Structure API Endpoint Query Filter Bucket Aggregation Metric Aggregation
- 14. www.objectrocket.com Rideaustin - ABIA Pick-ups/Drop-offs <Pickups Dropoffs>
- 15. www.objectrocket.com Rideaustin - Driver Metrics