



























































Ad
More Related Content
What's hot (20)
Similar to Apache doris (incubating) introduction (20)


















Ad
Recently uploaded (20)




















Ad
Apache doris (incubating) introduction
- 1. Apache Doris (incubating) A simple and single tightly coupled OLAP system [email protected]
- 2. About me I’m Reed, an Apache committer, come from China I’m working for Baidu Inc., China‘s Google as a senior software engineer and core developer of Doris. 10+ year experience in software development, and 5- year experience in managing a team. Once worked for Naver, South Korea's largest web search engine and Qihoo 360, China's largest internet security company.
- 3. Overview 2 ARCHITECTURE – Key techniques 3 FEATURES – Features and functions 4 STORAGE – Data storage model 1 INTRODUCTION – What is Doris
- 4. Overview 2 ARCHITECTURE – Key techniques 3 FEATURES – Features and functions 4 STORAGE – Data storage model 1 INTRODUCTION – What is Doris
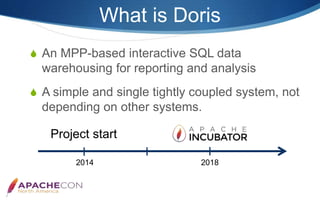
- 5. What is Doris An MPP-based interactive SQL data warehousing for reporting and analysis A simple and single tightly coupled system, not depending on other systems. 2014 Project start 2018
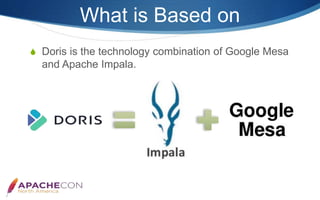
- 6. What is Based on Doris is the technology combination of Google Mesa and Apache Impala.
- 7. Used in Baidu Inc. 1000+ 200+ 1PB Deployed machines Business lines Maximum in one cluster
- 9. User case – JD.com -- Provided by JD.com
- 10. Why Doris by JD Google’s Mesa theory with Baidu's engineering practice Compatible MySQL protocol High concurrency and high QPS support Convenient operation and maintenance with clear structure -- Provided by JD.com
- 11. Overview 3 FEATURES – Features and functions 4 STORAGE – Data storage model 1 INTRODUCTION – What is Doris 2 ARCHITECTURE – Key techniques
- 13. Frontend and Backend consists of query coordinator and catalog manager stores the data and executes the query fragments Sending query fragments to BE Executing query fragments & send result to FE Catalog Doris' implementation consists of two daemons: frontend (FE) and backend (BE).
- 14. Key Technology Doris = Aggregate Data Model Versioned Data Management Prefix Index Online Schema Change ... Query Engine ... File Format Indexes Compression Encoding ... Google Mesa + Apache Impala + Apache ORCFile
- 15. Overview 2 ARCHITECTURE – Key techniques 4 STORAGE – Data storage model 1 INTRODUCTION – What is Doris 3 FEATURES – Features and functions
- 19. Two-Level Partitioning 1. The Range partitioning 2. The hash partitioning User can specify a column (usually the time series column) range of values for the data partition. User can also specify one or more columns and a number of buckets to do the hash partitioning.
- 20. Two-Level Partitioning CREATE TABLE IF NOT EXISTS example_db.expamle_tbl ( `user_id` LARGEINT NOT NULL COMMENT "user id", `date` DATE NOT NULL COMMENT "date and time", ... /* Omit other columns */ ) AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`) PARTITION BY RANGE(`date`) ( PARTITION `p201801` VALUES LESS THAN ("2018-02-01"), PARTITION `p201802` VALUES LESS THAN ("2018-03-01"), PARTITION `p201803` VALUES LESS THAN ("2018-04-01") ) DISTRIBUTED BY HASH(`user_id`) BUCKETS 16 ... /* Omitted other information */ ;
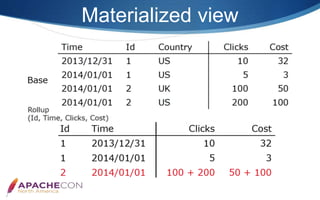
- 23. Materialized view ALTER TABLE expamle_tbl ADD ROLLUP rollup_cost(user_id, cost); SHOW ALTER TABLE ROLLUP; EXPLAIN SELECT user_id, sum(cost) FROM expamle_tbl GROUP BY user_id; +-----------------------------------------+ | Explain String | +-----------------------------------------+ | PLAN FRAGMENT 0 | ... | 1:AGGREGATE (update serialize) | ... | 0:OlapScanNode | | TABLE: expamle_tbl | | rollup: rollup_cost | ...
- 24. Columnar storage
- 25. Overview 2 ARCHITECTURE – Key techniques 3 FEATURES – Features and functions 1 INTRODUCTION – What is Doris 4 STORAGE – Data storage model
- 26. Data Model In Mesa, a table schema specifies key space K for table and corresponding value space V. Doris combines Mesa‘s data model and ORC File / Parquet storage technology The table schema specifies the aggregation function F : V ×V → V
- 27. Data Model
- 28. Types of Model 01 03 02 DUPLICATE KEY SUM, REPLACE, MAX and MIN UNIQUE KEY AGGREGATE KEY
- 29. Aggregate key model CREATE TABLE IF NOT EXISTS example_db.expamle_tbl ( `user_id` LARGEINT NOT NULL COMMENT "user ID", `date` DATE NOT NULL COMMENT "date and time", `city` VARCHAR(20) COMMENT "the city user lives", `age` SMALLINT COMMENT "age of user", `sex` TINYINT COMMENT "sex of user", `last_visit_date` DATETIME REPLACE COMMENT "the date last visited", `cost` BIGINT SUM DEFAULT "0" COMMENT "total cost", `max_dwell_time` INT MAX DEFAULT "0" COMMENT "maximum dwell time", `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "minimum dwell time" ) AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`) ... /* Omitted the information of Partition and Distribution */ ;
- 30. Duplicate key model CREATE TABLE IF NOT EXISTS example_db.expamle_tb2 ( `timestamp` DATETIME NOT NULL COMMENT "log time", `type` INT NOT NULL COMMENT "log type", `error_code` INT COMMENT "error code", `error_msg` VARCHAR(1024) COMMENT "error message", `op_id` BIGINT COMMENT "operator ID", `op_time` DATETIME COMMENT "operation time" ) DUPLICATE KEY(`timestamp`, `type`) ... /* Omitted the information of Partition and Distribution */ ;
- 31. Unique key model CREATE TABLE IF NOT EXISTS example_db.expamle_tb3 ( `user_id` LARGEINT NOT NULL COMMENT "user id", `username` VARCHAR(50) NOT NULL COMMENT ”user name", `city` VARCHAR(20) COMMENT "the city user lives", `age` SMALLINT COMMENT "age of user", `sex` TINYINT COMMENT "sex of user", `phone` LARGEINT COMMENT "phone number", `address` VARCHAR(500) COMMENT "address of user", `register_time` DATETIME COMMENT "registered time" ) UNIQUE KEY(`user_id`, `user_name`) ... /* Omitted the information of Partition and Distribution */ ;
- 32. Contact us • Official website and source code • http://doris.apache.org • https://github.com/apache/incubator-doris • E-Mail • [email protected] • Document • http://doris.incubator.apache.org/documentation/en/
- 33. Thank you
Editor's Notes
- #2: Hello, I‘m very happy to have this opportunity to share Apache Doris with you. Thank you so much for coming. thank you! Today my topic is “Apache Doris (incubating) —— A simple and single tightly coupled OLAP system”
- #3: Well, firstly, please let me make a self-introduction. I’m Reed, an Apache committer, come from China I’m working for Baidu Inc., China‘s Google as a senior software engineer and core developer of Doris. I have more than ten years experience in software development, and I have 5-year experience in managing a team. I once worked for Naver, South Korea's largest web search engine and Qihoo 360, China's largest internet security company.
- #4: There are four parts of this topic, firstly, I will make an introduction for Doris. Secondly, I will explain the architecture and key techniques. thirdly, I will list the features and functions of Doris. Lastly, I will let you know what is the data storage model of Doris.
- #5: 1. The introduction, what is Doris.
- #6: Doris is an MPP-based interactive SQL data warehousing for reporting and analysis. It was originally start by Baidu Inc in two thousand fourteen. and It was contributed to the Apache foundation by Baidu in July two thousand eighteen, and is currently in its incubation phase. Unlike other popular SQL-on-Hadoop systems, Doris is designed to be a simple and single tightly coupled system, not depending on other systems. Doris not only provides high concurrent, low latency and point query performance, but also provides high throughput['θrʊ'pʊt] queries of ad-hoc analysis. Doris not only provides batch data loading, but also provides real-time stream data loading. Doris also provides high availability, reliability, fault tolerance, and scalability. The simplicity (of developing, deploying and using) and meeting many data serving requirements in single system are the main feature of Doris.
- #7: Generally speaking, Doris is the technology combination of Google Mesa and Apache Impala. Mesa is a highly scalable analytic data storage system that stores critical measurement data related to Google’s Internet advertising business. Mesa is designed to satisfy complex and challenging set of users' and systems' requirements, including near real-time data ingestion and query ability, as well as high availability, reliability, fault tolerance, and scalability for large data and query volumes. Impala is a modern, open-source MPP SQL engine architected from the ground up for the Hadoop data processing environment. Mesa can satisfy the needs of many of our storage requirements, however Mesa itself does not provide a SQL query engine; Impala is a very well MPP SQL query engine, but the lack of a perfect distributed storage engine in that time. So in the end we chose the combination of these two technologies.
- #8: Doris has been used in Baidu for more than 1000 machines, and 200 business lines including Baidu Fengchao and Baidu Statistics. The maximum single business data volume exceeds one PB. meanwhile, it has also been highly recognized in Baidu's public cloud and toB business.
- #9: Since the open source, more than ten companies including Sina Weibo, Sohu, Meituan, lianjia, Guazi, ipinyou, jingdong, sichuan airlines, goldwind, Shanghai electric, xiaommi and etc. have used Doris in their online businesses.
- #10: Take JD.com for example. JD.com is one of the biggest e-commerce platforms in China. In two thousand eighteen, JD Group's market transaction volume was close to 1.7 trillion yuan. JD created the famous six eighteen shopping festival. In the store celebration month, JD will launch a series of large-scale promotional activities. For JD.com, advertising is one of its important business, especially during six-eighteen each year. In this year‘s six-eighteen festival, Doris shows that its strong stable and efficient performance according to the advertising platform team of JD.com who applied Doris to their system.
- #11: Why JD.com decided to use Doris in their online business, there are four causes according to JD.com. 1. Google Mesa theory with Baidu‘s engineering practice. And Doris has entered the Apache Foundation incubation, the future is expected, and subsequent development and maintenance is guaranteed. 2. Perfect feature support, standard MySQL protocol. Many existing peripheral MySQL function modules can be used, and the overall use is very convenient. And the user migration cost of the original MySQL database is very low. 3. High concurrency and high QPS support. Because the core code is all implemented in C++, performance is better than other languages. On the other hand, good design also guarantees that Apache Doris performs better than other open source products when dealing with high concurrency. 4. Convenient operation and maintenance with clear structure. Only FE and BE modules with fewer external dependencies. You can concentrate on maintaining the Doris system. The work of other ETLs can be handled by the business department, freeing up manpower.
- #12: 2. The ARCHITECTURE and Key techniques of Doris.
- #13: Doris‘ implementation consists of two daemons: frontend (FE) and backend (BE). It is so simple that just has two processes: FE and BE. Users can use any client that compatible MySQL protocol to connect FE daemon. Of course, users can use Native C API, JDBC, ODBC, PHP, Python, Perl, Ruby and etc.. to connect FE daemon. A typical Doris cluster generally composes of several frontend daemons and dozens to hundreds of backend daemons.
- #14: Frontend daemon consists of query coordinator and catalog manager. Query coordinator is responsible for receiving user‘s sql queries, compiling queries and managing queries execution. Catalog manager is responsible for managing metadata such as databases, tables, partitions, replicas and etc. Several frontend daemons could be deployed to guarantee fault-tolerance, and load balancing. Backend daemon stores the data and executes the query fragments. Many backend daemons could also be deployed to provide scalability and fault-tolerance. Clients can use MySQL-related tools to connect any frontend daemon to submit SQL query. The frontend receives the query and compiles it into query plans executable by the backends. Then frontend sends the query plan fragments to backend. Backends will build a query execution DAG. Data is fetched and pipelined into the DAG. The final result response is sent to client via frontend.
- #15: As I said before, generally speaking, Doris is the technologies combination of Google mesa and impala, also Apache ORCFile. actually, we developed a distributed storage engine based on Google Mesa and Apache ORCFile. To be more exact, the techniques learned from Mesa include aggreate data model, versioned data management, prefix index, online schema change and etc.. For In data format, indexes, compression encoding, we refer to Apache ORCFile. Unlike Mesa, the storage engine of Doris does not rely on any distributed file system. We also deeply integrate this storage engine with Impala query engine. Query compiling, query execution coordination and catalog management of storage engine are integrated to be frontend daemon; query execution and data storage are integrated to be backend daemon. With this integration, we implemented a single, full-featured, high performance MPP database, as well as maintaining the simplicity. As I said before, the simplicity (of developing, deploying and using) and meeting many data serving requirements in single system are the main feature of Doris.
- #16: 3. Features and functions
- #17: As an OLAP system, Doris can ingest data from local files, real-time data come from Kafka and HDFS files, and when these data enters Doris, they can been pre-aggregated. MySQL compatible networking protocol is implemented in Doris‘ frontend. The main cause of using MySQL compatible protocol as following: Firstly, SQL interface is preferred for engineers; Secondly, compatibility with MySQL protocol makes the integrating with current existing BI software, such as Tableau, easier; Lastly, rich MySQL client libraries and tools reduce our development costs, but also reduces the user's using cost.
- #18: The Frontends of Doris can be configured to three kinds of roles: leader, follower and observer. Through a voting protocol, follower frontends firstly elect a leader frontend. All the write requests of metadata are forwarded to the leader, then the leader writes the operation into the replicated log file. If the new log entry will be replicated to at least quorum followers successfully, the leader commits the operation into memory, and responses the write request. Followers always replay the replicated logs to apply them into their memory metadata. If the leader crashes, a new leader will be elected from the leftover followers. Leader and follower mainly solve the problem of write availability and partly solve the problem of read scalability. Leader replicates log stream to observers asynchronously. Observers don't involve leader election. The replicated-state-machine is implemented based on BerkeleyDB java version (in brief BDB-JE). BDB-JE has achieved high availability by implementing a Paxos-like consensus algorithm. We use BDB-JE to implement Doris' log replication and leader election. In-memory catalog storage has three functional modules: real-time memory data structures, memory checkpoints on local disk and an operation relay log. When modifying catalog, the mutation operation is written into the log file firstly. Then, the mutation operation is applied into the memory data structures. Periodically, a thread does the checkpoint that dumps memory data structure image into local disk. Checkpoint mechanism enables the fast startup of frontend and reduces the disk storage occupancy. Actually, in-memory catalog also simplifies the implementation of multiple frontends.
- #19: In FE, the query come from client will be translated to the distributed query plan, that is distribution of query fragments. These query fragments will be sent to each Backend node to execute. The distribution of query fragment execution takes minimizing data movement and maximizing scan locality as the main goal. Because Doris is designed to provide interactive analysis, so the average execution time of queries is short. Considering this, we adopt query re-execution to meet the fault tolerance of query execution.
- #20: Like most of the distributed database system, data in Doris is horizontally[,hɑrə'zɑntli] partitioned. However, a single level partitioning rule (hash partitioning or range partitioning) may not be a good solution to all scenarios[sə'nærɪos]. For example, there is a user-based fact table that stores rows of the form (date, userid, metric). Choosing only hash partitioning by column userid may lead to uneven[ʌn'ivən] distribution of data, when one user’s data is very large. If choosing range partitioning according to column date, it will also lead to uneven distribution of data due to the likely data explosion in a certain period of time. Therefore we support the two-level partitioning rule. The first level is range partitioning. User can specify a column (usually the time series column) range of values for the data partition. In one partition, the user can also specify one or more columns and a number of buckets to do the hash partitioning. User can combine with different partitioning rules to better divide the data.
- #21: In one partition, the user can also specify one or more columns and a number of buckets to do the hash partitioning. User can combine with different partitioning rules to better divide the data. Three benefits are gained by using the two-level partitioning mechanism. Firstly, old and new data could be separated, and stored on different storage mediums; Secondly, storage engine of backend can reduce the consumption of IO and CPU for unnecessary data merging, because the data in some partitions is no longer be updated; Lastly, every partition‘s buckets number can be different and adjusted according to the change of data size.
- #22: To achieve high update throughput, Doris only applies updates in batches at the smallest frequency of every minute. Each update batch specifies an increased version number and generates a delta data file, commits the version when updates of quorum replicas are complete. You can query all committed data using the committed version, and the uncommitted version would not be used in query. All update versions are strictly be in increasing order. If an update contains more than one table, the versions of these tables are committed atomically [ə'tɑmɪkly]. The MVCC mechanism allows Doris to guarantee multiple table atomic updates and query consistency. In addition, Doris uses compaction policies to merge delta files to reduce delta number, also reduce the cost of delta merging during query for higher performance.
- #23: Mesa also supports creating materialized rollups, which contain a column subset of schema to gain better aggregation effect. Rollup is a materialized view that contains a column subset of schema in Doris. A table may contain multiple rollups with columns in different order. According to sort key index and column covering of the rollups, Doris can select the best rollup for different query. Because most rollups only contain a few columns, the size of aggregated data is typically much smaller and query performance can greatly be improved. All the rollups in the same table are updated atomically. Because rollups are materialized, users should make a trade-off between query latency and storage space when using them.
- #24: We can create materialized view, namely rollup by alter table statement actually. After created, we can view by show alter table statement. If we want to know if the rollup take effect, we can use explain statement to view its query plan. and from query plan, we can see the rollup table name.
- #25: The storage engine of Doris use columnar storage technology. Compared with the row-oriented database, column-oriented organization is more efficient when an aggregate needs to be computed over many rows but only for a small subset of all columns of data, because reading that smaller subset of data can be faster than reading whole row data. And columnar storage is also space-friendly due to the high compression ratio of each column. Further, column support block-level storage technology such as min/max index and bloom filter index. Query executor can filter out a lot of blocks that do not meet the predicate, to further improve the query performance.
- #26: 4. STORAGE – Data storage model
- #27: Doris combines Google Mesa's data model and ORCFile / Parquet storage technology. Data in Mesa is inherently multi-dimensional fact table. These facts in table typically consist of two types of attributes: dimensional attributes (which we call keys) and measure attributes (which we call values). The table schema also specifies the aggregation function F: V ×V → V which is used to aggregate the values corresponding to the same key.
- #28: To achieve high update throughput, Mesa loads data in batch. Each batch of data will be converted to a delta file. Mesa uses MVCC approach to manage these delta files, and so to enforce update atomicity.
- #29: Like traditional databases, Doris stores structured data represented as tables. Each table has a well defined schema consisting of a finite number of columns. User can create three types of table to meet different needs in interactive query scenarios. Aggregate key, duplicate key and unique key. Data in all three types of table are sorted by KEY.
- #30: Type one, the aggregate key model. we can define this model by specify the key words of Aggregate key, red words in here. According to Mesa‘s data model, all columns of a table can be divided into two parts: key and value, The columns name list in the parentheses[pə‘rɛnθəsɪz] are the key, and the rest of columns are values, such as last visit date, cost, max dwell time and min dwell time. we can define the aggregation functions for values, such as SUM, MIN, MAX, REPLACE, and this function will aggregate the corresponding value by key.
- #31: Next, the type two, the duplicate key model. we can define this model by specify the key words of duplicate key, red words in here. Like the aggregate key, the columns name list in the parentheses[pə‘rɛnθəsɪz] are the key, and the rest of columns are values, such as error code, error message, op id and op time. In this type, Doris will only keep one row for the data which has duplicate key.
- #32: Next, the type three, the unique key model. we can define this model by specify the key words of unique key, red words in here. Like the aggregate key, the columns name list in the parentheses[pə‘rɛnθəsɪz] are the key, and the rest of columns are values, such as city, age and etc. In this type, Doris will replace the data which are the same key, actually, this mode completely equally the aggregate key which only define replace function.
- #33: At last, I show you that how to contact us, the official website and source code in github; the email and document.
- #34: Thank you!