Apache flink 1.7 and Beyond
Download as PPTX, PDF11 likes2,012 views

This document discusses Apache Flink version 1.7 and beyond. It summarizes key features of Flink 1.7 including contributions from 112 contributors and over 1,000 commits. It also discusses upcoming features in Flink 1.8 such as support for state schema evolution, dynamic scaling, unifying batch and streaming, an extendable scheduler, and end-to-end SQL-only pipelines. The document encourages participation in the Flink community.























































Ad
More Related Content
What's hot (20)
Similar to Apache flink 1.7 and Beyond (20)


















Ad
More from Till Rohrmann (11)











Ad
Recently uploaded (20)




















Apache flink 1.7 and Beyond
- 1. Apache Flink® 1.7 and Beyond 公司:data Artisans 职位:Engineering Lead 演讲者:Till Rohrmann @stsffap 1
- 2. 2 Original creators of Apache Flink® dA Platform Stream Processing for the Enterprise
- 3. 3 What is Apache Flink? Batch Processing process static and historic data Data Stream Processing realtime results from data streams Event-driven Applications data-driven actions and services Stateful Computations Over Data Streams
- 4. Flink 1.7: What happened so far? 4
- 5. • Contributors: 112 • Resolved issues: 430 • Commits: 970 • Changes LOC: +103824/-63124 5 Flink 1.7.0 in Numbers
- 6. • E.g. changing requirements, new algorithms, better serializers, bug fixes, etc. • Expensive to restart application from scratch (maintain state) 6 Flink Applications Need to Evolve
- 7. • Support for changing state schema • Adding/Removing fields • Changing type of fields • Currently fully supported when using Avro types 7 State Schema Evolution “Upgrading Stateful Flink Streaming Applications: State of the Union” by Tzu-Li Tai Today @ 5:20 pm Room 2
- 8. 8 Converting Currencies 7:12pm 9:37am 8:45am € 1 $ 1.13 CN¥ 7.8
- 9. 9 Temporal Tables and Joins 13 11 7 Currency Rate Time CN¥ 7.8 3 CN¥ 7.89 5 CN¥ 7.75 915 14 12 7 4
- 10. 10 SQL for Pattern Analysis SELECT * from ?
- 11. 11 MATCH_RECOGNIZESELECT * FROM TaxiRides MATCH_RECOGNIZE ( PARTITION BY driverId ORDER BY rideTime MEASURES S.rideId as sRideId AFTER MATCH SKIP PAST LAST ROW PATTERN (S M{2,} E) DEFINE S AS S.isStart = true, M AS M.rideId <> S.rideId, E AS E.isStart = false AND E.rideId = S.rideId )
- 12. • ElasticSearch 6 Table Sink • Support for views in SQL Client • More built-in functions: TO_BASE64, LOG2, REPLACE, COSH,… 12 More SQL Improvements “Flink Streaming SQL 2018” by Piotr Nowojski Today @ 4:00 pm Room 2
- 13. • Scala 2.12 Support • Exactly-once S3 StreamingFileSink • Kafka 2.0 connector • Versioned REST API • Removal of legacy mode 13 Other Notable Features
- 14. Flink 1.8+: What is happening next? 14
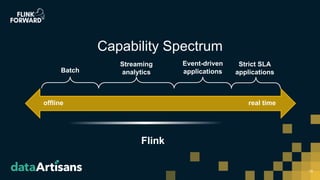
- 15. 15 Capability Spectrum offline real time Batch Event-driven applications Streaming analytics Strict SLA applications Flink
- 16. • Deploying Flink applications should be as easy as starting a process • Bundle application code and Flink into a single image • Process connects to other application processes and figures out its role • Removing the cluster out of the equation 16 Flink as a Library P1 P2 P3 P4 New process
- 17. • Active mode • Flink is aware of underlying cluster framework • Flink allocate resources • E.g. existing YARN and Mesos integration • Reactive mode • Flink is oblivious to its runtime environment • External system allocates and releases resources • Flink scales with respect to available resources • Relevant for environments: Kubernetes, Docker, as a library 17 Reactive vs. Active
- 18. 18 Dynamic Scaling • Latency • Throughput • Resource utilization • Connector signals
- 19. • No fundamental difference between batch and stream processing • Batch allows optimizations because data is bounded and ”complete” • Batch and streaming still separately treated from task level upwards • Working toward a single runtime for batch and streaming workloads 19 Batch-Streaming Unification
- 20. • Lazy scheduling (batch case) • Deploy tasks starting from the sources • Whenever data is produced start consumers • Scheduling of idling tasks resource under-utilization 20 Flink Scheduler src src join join src build side build side prob e side probe side
- 21. • More efficient scheduling by taking dependencies into account • E.g. probe side is only scheduled after build side has been processed 21 Batch Scheduler src src join join src build side build side prob e side probe side (1) (2) (2) (3)
- 22. • Make Flink’s scheduler extendable & pluggable • Scheduler considers dependencies and reacts to signals from ExecutionGraph • Specialized scheduler for different use cases 22 Extendable Scheduler Scheduler Streaming Scheduler Batch Scheduler Speculative Scheduler
- 23. • Tasks own produced result partitions • Containers cannot be freed until result is consumed • One implementation for streaming and batch loads 23 Flink’s Shuffle Service Result partitionContainer
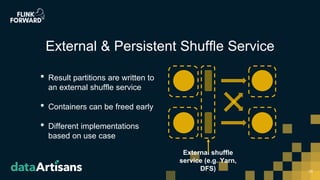
- 24. • Result partitions are written to an external shuffle service • Containers can be freed early • Different implementations based on use case 24 External & Persistent Shuffle Service External shuffle service (e.g. Yarn, DFS)
- 25. • Support for external catalogs (Confluent Schema Registry, Hive Meta Store) • Data definition language (DDL) 25 End-to-end SQL Only Pipelines Hive Meta Store Table Source Table Sink Output schema information Input schema information SQL Query
- 26. • Flink 1.7.0 added many new features around SQL, connectors and state evolution • A lot of new features in the pipeline • Join the community! • Subscribe to mailing lists • Participate in Flink development • Become active 26 TL;DL
- 27. 谢谢 THANKS 27
Editor's Notes
- #7: State evolution was missing piece to properly evolve Flink applications (topology changes were already possible) State evolution is particularly important for users who have amassed a lot of state which they cannot discard/recompute because it would be too expensive Evolving the state is a cheap solution by adding/removing fields to capture new features
- #8: State schema evolution is currently supported when using Avro types Limited by what Avro supports wrt schema changes In the future, state transformations are conceivable Mapping state to a completely different type A => B Dedicated talk available
- #9: Example to motivate temporal tables and temporal joins: Converting currencies of buys and sales which are executed in different currencies Stream A are the incoming buys/sales, when they happened, in which currency they were executed and the amount of transferred money Stream B are the currency rates Goal join buys/sales with the latest currency rate to calculate exact costs/income in some given currency
- #10: Temporal tables are tables which have an additional time/version column The table can contain multiple entries for the same key originating from different times Temporal table allows to join with latest row for a given key wrt some timestamp Perfect for joining buys/sales with their respective currency rate for conversion
- #11: How do you use SQL if you want to extract temporal patterns (e.g. you want to find out how many of your warehouse orders have not been processed correctly) Easy to do with complex event processing which has been developed for this purpose CEP allows you to define patterns via a regular expression like language which can then be extracted from your data For example, let’s assume we have a stream of taxi ride events (passenger X starts ride, passenger Y stops ride) We want to find rides where the taxi picks up two other passengers after the first passenger starts its ride How do we express this with SQL?
- #12: MATCH_RECOGNIZE comes to our rescue MATCH_RECOGNIZE allows to define temporal patterns in your query Support for this key word was added with Flink 1.7 which is also compliant to SQL:2016 Purple defines the pattern: First a start event where a passenger X enters the taxi, then two events where another ride starts (new passengers enter the taxi) and last the event where passenger X leaves the taxi The events of the purple pattern are defined in the DEFINE clause Passengers are identified by the rideId
- #13: Many more SQL improvements where added with Flink 1.7.0 SQL views define virtual tables from a SQL query Refer to dedicated talk by Piotr
- #14: Scala 2.12 is now supported Users can now use newer Scala version and more powerful Scala 2.12 ecosystem The StreamingFileSink which has been added in 1.6.0 now also supports writing to S3 with exactly once processing guarantees Flink has now a Kafka 2.0 connector being able to read from Kafka 2.0 Flink’s REST API is versioned No more breaking changes for third party integrations which use the REST API The legacy mode has been removed Flip-6 only
- #16: If we look at the capability spectrum, Flink shines most in the domain of streaming analytics, continuous processing, event driven applications and with some limitations in batch However, in order to process batch workloads as good as streaming only workloads Flink needs still to improve a bit (e.g. scheduling, dynamic memory management, persistent intermediate results, …) The same applies for the near real-time applications which have low latency SLAs (Flink needs to recover faster in order to fulfill the SLAs, auto-scaling, …) The goal is for Flink to become the primary choice when trying to solve a problem from any of these domains Flink 1.8 will take some incremental steps to extend Flink’s capability spectrum
- #17: More and more people use Flink to develop event-driven applications These applications should be as easy to deploy as starting a local application Atm users need to manage a Flink cluster to deploy an application to The job mode has eased the situation a bit but you still need to operate a cluster Idea: Completely remove the cluster out of the equation by by bundling Flink and application code into one image A process started from this image will automatically connect to the other Flink processes and form a cluster on its own User only needs to start and stop processes that’s all
- #18: In order to make deployment as easy as just described, the community is working on a new execution mode The existing execution mode is the active mode In the active mode, Flink is aware of its underlying resource manager and can talk to it in order to allocate/free resources (e.g. Yarn, Mesos) The community is currently working on adding support for running Flink in active mode on Kubernetes (needs to implement a KubernetesResourceManager) The reactive mode differs in the sense that Flink does not know about its runtime environment Thus, Flink cannot allocate/free resources. Allocation/Freeing needs to be done by an external process New resources (TaskManagers) once started will join the cluster and Flink will automatically make use of these new resources Depending on the job requirements Flink will automatically scale up/down the job wrt to the available resources
- #19: Enable auto-scaling Based on some metrics and wrt to the available resources Flink will decide when and how to rescale a Flink job The community will add a RescalingPolicy interface which allows the operators to define when to signal a rescaling request Flink will make sure that all resources are used efficiently The reactive mode will enable dynamic scaling also in container environments where an external system controls the resources
- #20: A long sought-after goal is the unification of batch and stream processing There are no fundamental differences between batch and stream processing which would prevent the unification Atm Flink handles batch and streaming on the API level separately (exception is the Table API) Big parts of the runtime are shared by batch and streaming workloads (network stack, distributed components) However from the Task level upwards (StreamTask, StreamOperator, BatchTask) there are still separate code paths for batch and streaming Flink 1.8 will help paving the way for a truly unified runtime for batch and streaming workloads
- #21: Scheduling of batch jobs is currently sub-optimal Flink uses lazy scheduling starting from the sources Depending on the intermediate result type it schedules the consumers either when the first data has been produced or when the intermediate result has been completed Often different branches have dependencies and should be scheduled accordingly hash-join has a build and probe side, the build side needs to be processed before the probe side is consumed No need to schedule the probe side operators Atm, these dependencies are not respected which leads to resource under-utilization
- #22: Better scheduling would be by taking dependencies into account First schedule build side Second schedule probe side and build side of second join operator Last schedule probe side of second join operator
- #23: In order to support different schedulers, the community is currently working on making the scheduler extendable and pluggable Schedulers will receive topology (including operators dependencies) and signals from the ExecutionGraph (e.g. task finished, data available, etc) Based on these signals the scheduler can make scheduling decisions Specialized schedulers for different use cases conceivable (e.g. streaming scheduler which schedules all operators vs. batch scheduler which schedules the topology stage by stage)
- #24: Another way to improve Flink’s batch capabilities is to make Flink’s shuffle service pluggable Atm Flink’s shuffle service is coupled to the lifetime of the TaskManager The shuffle service either keeps results in memory or spills to disk (depending on the exchange mode) The problem is that results are bound to the lifetime of the TaskManager and, thus, it is not possible to release containers after tasks have finished Moreover, there is only one shuffle service implementation which has to work for streaming and batch workloads
- #25: Idea is to make the shuffle service pluggable so that an external and persistent shuffle service can be supplied Such a shuffle service allows to decouple the result partitions from the underlying containers and, thus, containers can be released earlier Possible shuffle service implementations could be based on persisting results to DFS or implemeting a Yarn based shuffle service Making the shuffle service pluggable will make Flink more flexible wrt supported use cases
- #26: Two important features to allow users to define end-to-end SQL only pipelines (without writing any (Java/Scala) code) are in the making Support for external catalogs to easily read from and write to SQL tables Examples: Hive meta store for batch SQL jobs or the confluent schema registry for streaming SQL Prerequisite is that the SQL sources/sinks have been registered at the catalog If this has not happened, then support for a data definition language (DDL) could be helpful With the DDL it will be possible to define SQL tables using a SQL query (schema + meta information) These two features will simplify the usage of SQL with Flink tremendously