Apache Flink & Graph Processing
4 likes1,818 views

This document discusses batch and stream graph processing with Apache Flink. It provides an overview of distributed graph processing and Flink's graph processing APIs, Gelly for batch graph processing and Gelly-Stream for continuous graph processing on data streams. It describes how Gelly and Gelly-Stream allow for processing large and dynamic graphs in a distributed fashion using Flink's dataflow engine.


































![Hello, Gelly!
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Edge<Long, NullValue>> edges = getEdgesDataSet(env);
Graph<Long, Long, NullValue> graph = Graph.fromDataSet(edges, env);
DataSet<Vertex<Long, Long>> verticesWithMinIds = graph.run(
new ConnectedComponents(maxIterations));
val env = ExecutionEnvironment.getExecutionEnvironment
val edges: DataSet[Edge[Long, NullValue]] = getEdgesDataSet(env)
val graph = Graph.fromDataSet(edges, env)
val components = graph.run(new ConnectedComponents(maxIterations))
Java
Scala](https://image.slidesharecdn.com/euyhp0oaqu6qqdkv5rjj-signature-6fe544449570fe865ee69576788443e9f2a460c054bc487b931c5a8fc4ae1047-poli-161108090811/85/Apache-Flink-Graph-Processing-36-320.jpg)


![Example: subGraph
val graph: Graph[Long, Long, Long] = ...
// keep only vertices with positive values
// and only edges with negative values
val subGraph = graph.subgraph(
vertex => vertex.getValue > 0,
edge => edge.getValue < 0
)](https://image.slidesharecdn.com/euyhp0oaqu6qqdkv5rjj-signature-6fe544449570fe865ee69576788443e9f2a460c054bc487b931c5a8fc4ae1047-poli-161108090811/85/Apache-Flink-Graph-Processing-39-320.jpg)

























































Apache Flink & Graph Processing
- 1. Batch & Stream Graph Processing with Apache Flink Vasia Kalavri [email protected] @vkalavri Apache Flink Meetup London October 5th, 2016
- 2. 2 Graphs capture relationships between data items connections, interactions, purchases, dependencies, friendships, etc. Recommenders Social networks Bioinformatics Web search
- 3. Outline • Distributed Graph Processing 101 • Gelly: Batch Graph Processing with Apache Flink • BREAK! • Gelly-Stream: Continuous Graph Processing with Apache Flink
- 4. Apache Flink • An open-source, distributed data analysis framework • True streaming at its core • Streaming & Batch API 4 Historic data Kafka, RabbitMQ, ... HDFS, JDBC, ... Event logs ETL, Graphs, Machine Learning Relational, … Low latency, windowing, aggregations, ...
- 5. WHEN DO YOU NEED DISTRIBUTED GRAPH PROCESSING?
- 6. MY GRAPH IS SO BIG, IT DOESN’T FIT IN A SINGLE MACHINE Big Data Ninja MISCONCEPTION #1
- 8. NAIVE WHO(M)-T0-FOLLOW ▸ Naive Who(m) to Follow: ▸ compute a friends-of-friends list per user ▸ exclude existing friends ▸ rank by common connections
- 9. DON’T JUST CONSIDER YOUR INPUT GRAPH SIZE. INTERMEDIATE DATA MATTERS TOO!
- 10. DISTRIBUTED PROCESSING IS ALWAYS FASTER THAN SINGLE-NODE Data Science Rockstar MISCONCEPTION #2
- 13. GRAPHS DON’T APPEAR OUT OF THIN AIR Expectation…
- 14. GRAPHS DON’T APPEAR OUT OF THIN AIR Reality!
- 15. WHEN DO YOU NEED DISTRIBUTED GRAPH PROCESSING? ▸ When you do have really big graphs ▸ When the intermediate data is big ▸ When your data is already distributed ▸ When you want to build end-to-end graph pipelines
- 16. HOW DO WE EXPRESS A DISTRIBUTED GRAPH ANALYSIS TASK?
- 17. RECENT DISTRIBUTED GRAPH PROCESSING HISTORY 2004 MapReduce Pegasus 2009 Pregel 2010 Signal-Collect PowerGraph 2012 Iterative value propagation Giraph++ 2013 Graph Traversals NScale 2014 Ego-network analysis Arabesque 2015 Pattern Matching Tinkerpop
- 18. PREGEL: THINK LIKE A VERTEX 1 5 4 3 2 1 3, 4 2 1, 4 5 3 ...
- 19. PREGEL: SUPERSTEPS (Vi+1, outbox) <— compute(Vi, inbox) 1 3, 4 2 1, 4 5 3 .. 1 3, 4 2 1, 4 5 3 .. Superstep i Superstep i+1
- 20. PAGERANK: THE WORD COUNT OF GRAPH PROCESSING VertexID Out-degree Transition Probability 1 2 1/2 2 2 1/2 3 0 - 4 3 1/3 5 1 1 1 5 4 3 2
- 21. PAGERANK: THE WORD COUNT OF GRAPH PROCESSING VertexID Out-degree Transition Probability 1 2 1/2 2 2 1/2 3 0 - 4 3 1/3 5 1 1 PR(3) = 0.5*PR(1) + 0.33*PR(4) + PR(5) 1 5 4 3 2
- 22. 1 5 4 3 2 PAGERANK: THE WORD COUNT OF GRAPH PROCESSING VertexID Out-degree Transition Probability 1 2 1/2 2 2 1/2 3 0 - 4 3 1/3 5 1 1 PR(3) = 0.5*PR(1) + 0.33*PR(4) + PR(5)
- 23. PAGERANK: THE WORD COUNT OF GRAPH PROCESSING VertexID Out-degree Transition Probability 1 2 1/2 2 2 1/2 3 0 - 4 3 1/3 5 1 1 PR(3) = 0.5*PR(1) + 0.33*PR(4) + PR(5) 1 5 4 3 2
- 24. PAGERANK: THE WORD COUNT OF GRAPH PROCESSING VertexID Out-degree Transition Probability 1 2 1/2 2 2 1/2 3 0 - 4 3 1/3 5 1 1 PR(3) = 0.5*PR(1) + 0.33*PR(4) + PR(5) 1 5 4 3 2
- 25. PREGEL EXAMPLE: PAGERANK void compute(messages): sum = 0.0 for (m <- messages) do sum = sum + m end for setValue(0.15/numVertices() + 0.85*sum) for (edge <- getOutEdges()) do sendMessageTo( edge.target(), getValue()/numEdges) end for sum up received messages update vertex rank distribute rank to neighbors
- 26. SIGNAL-COLLECT outbox <— signal(Vi) 1 3, 4 2 1, 4 5 3 .. 1 3, 4 2 1, 4 5 3 .. Superstep i Vi+1 <— collect(inbox) 1 3, 4 2 1, 4 5 3 .. Signal Collect Superstep i+1
- 27. SIGNAL-COLLECT EXAMPLE: PAGERANK void signal(): for (edge <- getOutEdges()) do sendMessageTo( edge.target(), getValue()/numEdges) end for void collect(messages): sum = 0.0 for (m <- messages) do sum = sum + m end for setValue(0.15/numVertices() + 0.85*sum) distribute rank to neighbors sum up messages update vertex rank
- 28. GATHER-SUM-APPLY (POWERGRAPH) 1 ... ... Gather Sum 1 2 5 ... Apply 3 1 5 5 3 1 ... Gather 3 1 5 5 3 Superstep i Superstep i+1
- 29. GSA EXAMPLE: PAGERANK double gather(source, edge, target): return target.value() / target.numEdges() double sum(rank1, rank2): return rank1 + rank2 double apply(sum, currentRank): return 0.15 + 0.85*sum compute partial rank combine partial ranks update rank
- 30. PREGEL VS. SIGNAL-COLLECT VS. GSA Update Function Properties Update Function Logic Communication Scope Communication Logic Pregel arbitrary arbitrary any vertex arbitrary Signal-Collect arbitrary based on received messages any vertex based on vertex state GSA associative & commutative based on neighbors’ values neighborhood based on vertex state
- 31. CAN WE HAVE IT ALL? ▸ Data pipeline integration: built on top of an efficient distributed processing engine ▸ Graph ETL: high-level API with abstractions and methods to transform graphs ▸ Familiar programming model: support popular programming abstractions
- 32. Gelly the Apache Flink Graph API
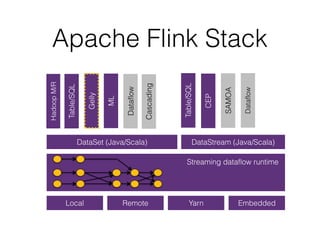
- 33. Apache Flink Stack Gelly Table/SQL ML SAMOA DataSet (Java/Scala) DataStream (Java/Scala) HadoopM/R Local Remote Yarn Embedded Dataflow Dataflow Table/SQL Cascading Streaming dataflow runtime CEP
- 34. Meet Gelly • Java & Scala Graph APIs on top of Flink’s DataSet API Flink Core Scala API (batch and streaming) Java API (batch and streaming) FlinkML GellyTable API ... Transformations and Utilities Iterative Graph Processing Graph Library 34
- 35. Gelly is NOT • a graph database • a specialized graph processor 35
- 36. Hello, Gelly! ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); DataSet<Edge<Long, NullValue>> edges = getEdgesDataSet(env); Graph<Long, Long, NullValue> graph = Graph.fromDataSet(edges, env); DataSet<Vertex<Long, Long>> verticesWithMinIds = graph.run( new ConnectedComponents(maxIterations)); val env = ExecutionEnvironment.getExecutionEnvironment val edges: DataSet[Edge[Long, NullValue]] = getEdgesDataSet(env) val graph = Graph.fromDataSet(edges, env) val components = graph.run(new ConnectedComponents(maxIterations)) Java Scala
- 37. Graph Methods Graph Properties getVertexIds getEdgeIds numberOfVertices numberOfEdges getDegrees Mutations add vertex/edge remove vertex/edge Transformations map, filter, join subgraph, union, difference reverse, undirected getTriplets Generators R-Mat (power-law) Grid Star Complete …
- 38. Example: mapVertices // increment each vertex value by one val graph = Graph.fromDataSet(...) // increment each vertex value by one val updatedGraph = graph.mapVertices(v => v.getValue + 1) 4 2 8 5 5 3 1 7 4 5
- 39. Example: subGraph val graph: Graph[Long, Long, Long] = ... // keep only vertices with positive values // and only edges with negative values val subGraph = graph.subgraph( vertex => vertex.getValue > 0, edge => edge.getValue < 0 )
- 40. Neighborhood Methods Apply a reduce function to the 1st-hop neighborhood of each vertex in parallel graph.reduceOnNeighbors( new MinValue, EdgeDirection.OUT)
- 41. What makes Gelly unique? • Batch graph processing on top of a streaming dataflow engine • Built for end-to-end analytics • Support for multiple iteration abstractions • Graph algorithm building blocks • A large open-source library of graph algorithms
- 42. Why streaming dataflow? • Batch engines materialize data… even if they don’t have to • the graph is always loaded and materialized in memory, even if not needed, e.g. mapping, filtering, transformation • Communication and computation overlap • We can do continuous graph processing (more after the break!)
- 43. End-to-end analytics • Graphs don’t appear out of thin air… • We need to support pre- and post-processing • Gelly can be easily mixed with the DataSet API: pre-processing, graph analysis, and post- processing in the same Flink program
- 44. Iterative Graph Processing • Gelly offers iterative graph processing abstractions on top of Flink’s Delta iterations • vertex-centric • scatter-gather • gather-sum-apply • partition-centric*
- 45. Flink Iteration Operators Input Iterative Update Function Result Replace Workset Iterative Update Function Result Solution Set State
- 46. Optimization • the runtime is aware of the iterative execution • no scheduling overhead between iterations • caching and state maintenance are handled automatically Push work “out of the loop” Maintain state as indexCache Loop-invariant Data
- 47. Vertex-Centric SSSP final class SSSPComputeFunction extends ComputeFunction { override def compute(vertex: Vertex, messages: MessageIterator) = { var minDistance = if (vertex.getId == srcId) 0 else Double.MaxValue while (messages.hasNext) { val msg = messages.next if (msg < minDistance) minDistance = msg } if (vertex.getValue > minDistance) { setNewVertexValue(minDistance) for (edge: Edge <- getEdges) sendMessageTo(edge.getTarget, vertex.getValue + edge.getValue) }
- 48. Algorithms building blocks • Allow operator re-use across graph algorithms when processing the same input with a similar configuration
- 49. Library of Algorithms • PageRank • Single Source Shortest Paths • Label Propagation • Weakly Connected Components • Community Detection • Triangle Count & Enumeration • Local and Global Clustering Coefficient • HITS • Jaccard & Adamic-Adar Similarity • Graph Summarization • val ranks = inputGraph.run(new PageRank(0.85, 20))
- 51. Can’t we block them? proxy Tracker Tracker Ad Server Legitimate site
- 52. • not frequently updated • not sure who or based on what criteria URLs are blacklisted • miss “hidden” trackers or dual-role nodes • blocking requires manual matching against the list • can you buy your way into the whitelist? Available Solutions Crowd-sourced “black lists” of tracker URLs: - AdBlock, DoNotTrack, EasyPrivacy
- 53. DataSet • 6 months (Nov 2014 - April 2015) of augmented Apache logs from a web proxy • 80m requests, 2m distinct URLs, 3k users
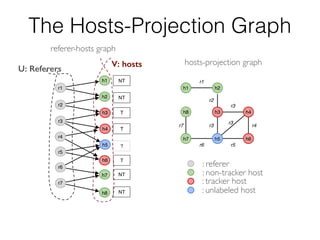
- 54. h2 h3 h4 h5 h6 h8 h7 h1 h3 h4 h5 h6 h1 h2 h7 h8 r1 r2 r3 r5 r6 r7 NT NT T T ? T NT NT r4 r1 r2 r3 r3 r3 r4 r5r6 r7 hosts-projection graph : referer : non-tracker host : tracker host : unlabeled host The Hosts-Projection Graph U: Referers referer-hosts graph V: hosts
- 55. Classification via Label Propagation non-tracker tracker unlabeled 55
- 56. Data Pipeline raw logs cleaned logs 1: logs pre- processing 2: bipartite graph creation 3: largest connected component extraction 4: hosts- projection graph creation 5: community detection google-analytics.com: T bscored-research.com: T facebook.com: NT github.com: NT cdn.cxense.com: NT ... 6: results DataSet API Gelly DataSet API
- 57. Feeling Gelly? • Gelly Guide https://ci.apache.org/projects/flink/flink-docs-master/libs/ gelly_guide.html • To Petascale and Beyond @Flink Forward ‘16 http://flink-forward.org/kb_sessions/to-petascale-and-beyond-apache- flink-in-the-clouds/ • Web Tracker Detection @Flink Forward ’15 https://www.youtube.com/watch?v=ZBCXXiDr3TU paper: Kalavri, Vasiliki, et al. "Like a pack of wolves: Community structure of web trackers." International Conference on Passive and Active Network Measurement, 2016.
- 58. Gelly-Stream single-pass stream graph processing with Flink
- 59. Real Graphs are dynamic Graphs are created from events happening in real-time
- 61. How we’ve done graph processing so far 1. Load: read the graph from disk and partition it in memory
- 62. 2. Compute: read and mutate the graph state How we’ve done graph processing so far 1. Load: read the graph from disk and partition it in memory
- 63. 3. Store: write the final graph state back to disk How we’ve done graph processing so far 2. Compute: read and mutate the graph state 1. Load: read the graph from disk and partition it in memory
- 64. What’s wrong with this model? • It is slow • wait until the computation is over before you see any result • pre-processing and partitioning • It is expensive • lots of memory and CPU required in order to scale • It requires re-computation for graph changes • no efficient way to deal with updates
- 65. Can we do graph processing on streams? • Maintain the dynamic graph structure • Provide up-to-date results with low latency • Compute on fresh state only
- 66. Single-pass graph streaming • Each event is an edge addition • Maintain only a graph summary • Recent events are grouped in graph windows
- 68. Graph Summaries • spanners for distance estimation • sparsifiers for cut estimation • sketches for homomorphic properties graph summary algorithm algorithm~R1 R2
- 74. 54 76 86 42 31 52 Stream Connected Components Graph Summary: Disjoint Set (Union-Find) • Only store component IDs and vertex IDs
- 78. 54 76 86 42 43 87 41 31 52 1 3 Cid = 1 2 5 Cid = 2 4 6 7 Cid = 6
- 79. 54 76 86 42 43 87 41 31 52 1 3 Cid = 1 2 5 Cid = 2 4 6 7 Cid = 6 8
- 80. 54 76 86 42 43 87 41 52 1 3 Cid = 1 2 5 Cid = 2 4 6 7 Cid = 6 8
- 81. 54 76 86 42 43 87 41 6 7 Cid = 6 8 1 3 Cid = 1 2 5 Cid = 2 4
- 84. Stream Connected Components with Flink DataStream<DisjointSet> cc = edgeStream .keyBy(0) .timeWindow(Time.of(100, TimeUnit.MILLISECONDS)) .fold(new DisjointSet(), new UpdateCC()) .flatMap(new Merger()) .setParallelism(1);
- 85. Stream Connected Components with Flink DataStream<DisjointSet> cc = edgeStream .keyBy(0) .timeWindow(Time.of(100, TimeUnit.MILLISECONDS)) .fold(new DisjointSet(), new UpdateCC()) .flatMap(new Merger()) .setParallelism(1); Partition the edge stream
- 86. Stream Connected Components with Flink DataStream<DisjointSet> cc = edgeStream .keyBy(0) .timeWindow(Time.of(100, TimeUnit.MILLISECONDS)) .fold(new DisjointSet(), new UpdateCC()) .flatMap(new Merger()) .setParallelism(1); Define the merging frequency
- 87. Stream Connected Components with Flink DataStream<DisjointSet> cc = edgeStream .keyBy(0) .timeWindow(Time.of(100, TimeUnit.MILLISECONDS)) .fold(new DisjointSet(), new UpdateCC()) .flatMap(new Merger()) .setParallelism(1); merge locally
- 88. Stream Connected Components with Flink DataStream<DisjointSet> cc = edgeStream .keyBy(0) .timeWindow(Time.of(100, TimeUnit.MILLISECONDS)) .fold(new DisjointSet(), new UpdateCC()) .flatMap(new Merger()) .setParallelism(1); merge globally
- 89. Gelly on Streams DataStreamDataSet Distributed Dataflow Deployment Gelly Gelly-Stream • Static Graphs • Multi-Pass Algorithms • Full Computations • Dynamic Graphs • Single-Pass Algorithms • Approximate Computations DataStream
- 90. Introducing Gelly-Stream Gelly-Stream enriches the DataStream API with two new additional ADTs: • GraphStream: • A representation of a data stream of edges. • Edges can have state (e.g. weights). • Supports property streams, transformations and aggregations. • GraphWindow: • A “time-slice” of a graph stream. • It enables neighborhood aggregations
- 91. GraphStream Operations .getEdges() .getVertices() .numberOfVertices() .numberOfEdges() .getDegrees() .inDegrees() .outDegrees() GraphStream -> DataStream .mapEdges(); .distinct(); .filterVertices(); .filterEdges(); .reverse(); .undirected(); .union(); GraphStream -> GraphStream Property Streams Transformations
- 92. Graph Stream Aggregations result aggregate property streamgraph stream (window) fold combine fold reduce local summaries global summary edges agg global aggregates can be persistent or transient graphStream.aggregate( new MyGraphAggregation(window, fold, combine, transform))
- 93. Slicing Graph Streams graphStream.slice(Time.of(1, MINUTE)); 11:40 11:41 11:42 11:43
- 94. Aggregating Slices graphStream.slice(Time.of(1, MINUTE), direction) .reduceOnEdges(); .foldNeighbors(); .applyOnNeighbors(); • Slicing collocates edges by vertex information • Neighborhood aggregations on sliced graphs source target Aggregations
- 95. Finding Matches Nearby graphStream.filterVertices(GraphGeeks()) .slice(Time.of(15, MINUTE), EdgeDirection.IN) .applyOnNeighbors(FindPairs()) slice GraphStream :: graph geek check-ins wendy checked_in soap_bar steve checked_in soap_bar tom checked_in joe’s_grill sandra checked_in soap_bar rafa checked_in joe’s_grill wendy steve sandra soap bar tom rafa joe’s grill FindPairs {wendy, steve} {steve, sandra} {wendy, sandra} {tom, rafa} GraphWindow :: user-place
- 96. Feeling Gelly? • Gelly Guide https://ci.apache.org/projects/flink/flink-docs-master/libs/ gelly_guide.html • Gelly-Stream Repository https://github.com/vasia/gelly-streaming • Gelly-Stream talk @FOSDEM16 https://fosdem.org/2016/schedule/event/graph_processing_apache_flink/ • Related Papers http://www.citeulike.org/user/vasiakalavri/tag/graph-streaming
- 97. Batch & Stream Graph Processing with Apache Flink Vasia Kalavri [email protected] @vkalavri Apache Flink Meetup London October 5th, 2016