Apache Hadoop: DFS and Map Reduce
1 like1,758 views

This is part of an introductory course to Big Data Tools for Artificial Intelligence. These slides introduce students to Apache Hadoop, DFS, and Map Reduce.





















![Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image
Map Reduce example: word count
this class is about big
data and artificial
intelligence
[this, class, is, about, big,
data, and, artificial,
intelligence]
Tokenize
(this,1), (class,1), (is,1),
(about,1), (big,1), (class, 1),
(is, 1), (about 1), (big, 1),
(data, 1), (and, 1), (artificial,1),
(intelligence, 1)
Prepare (key,value)
pairs
MAP TASK
Raw
chunk
Ready to shuffle](https://image.slidesharecdn.com/apachehadoop-150209143551-conversion-gate01/85/Apache-Hadoop-DFS-and-Map-Reduce-23-320.jpg)








![Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image
public static void main(String[] args) throws
Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path
(args[0]));
FileOutputFormat.setOutputPath(job, new Path
(args[1]));
System.exit(job.waitForCompletion(true) ? 0 :
1);
}
}
Map Reduce job in Hadoop](https://image.slidesharecdn.com/apachehadoop-150209143551-conversion-gate01/85/Apache-Hadoop-DFS-and-Map-Reduce-32-320.jpg)

































Ad
More Related Content
What's hot (20)
Viewers also liked (8)






Ad
Similar to Apache Hadoop: DFS and Map Reduce (20)




















Ad
Recently uploaded (20)




















Apache Hadoop: DFS and Map Reduce
- 1. Apache Hadoop DFS and Map Reduce Víctor Sánchez Anguix Universitat Politècnica de València MSc. In Artificial Intelligence, Pattern Recognition, and Digital Image Course 2014/2015
- 2. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Who has not heard about Hadoop?
- 3. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image
- 4. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Who knows exactly what is Hadoop?
- 5. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Being simplistic: What is Apache Hadoop? DFS Map Reduce
- 6. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Google publishes paper about GFS (2003). http://research.google.com/archive/gfs.html ➢ Distributed data among cluster of computers ➢ Fault tolerant ➢ Highly scalable with commodity hardware A bit of history: Distributed File System (DFS)
- 7. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Google publishes paper about MR (2004). http://research.google. com/archive/mapreduce.html ➢ Algorithm for processing distributed data in parallel ➢ Simple in concept, extremely useful in practice A bit of history: Map Reduce (MR)
- 8. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Doug Cutting and Mike Caffarella → Apache Nutch ➢ Doug Cutting goes to Yahoo ➢ Yahoo implements Apache Hadoop A bit of history: Hadoop is born
- 9. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Framework for distributed computing ➢ Still based on DFS and MR ➢ It is the main actor in Big Data ➢ Last major release: Apache Hadoop 2.6.0 (Nov 2014) http://hadoop.apache.org/ Apache Hadoop now
- 10. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image DFS architecture
- 11. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Interacting with Hadoop DFS: creating dirs ➢ Examples: hdfs dfs -mkdir data hdfs dfs -mkdir results
- 12. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Interacting with Hadoop DFS: uploading files ➢ Examples: hdfs dfs -put datasets/students.tsv data/students.tsv hdfs dfs -put datasets/grades.tsv data/grades.tsv
- 13. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Interacting with Hadoop DFS: listing ➢ Examples: hdfs dfs -ls data Found 2 items -rw-r--r-- 3 sanguix supergroup 450 2015-02-09 10:50 data/grades.tsv -rw-r--r-- 3 sanguix supergroup 194 2015-02-09 10:45 data/students.tsv
- 14. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Interacting with Hadoop DFS: get a file ➢ Examples: hdfs dfs -get data/students.tsv hdfs dfs -get data/grades.tsv
- 15. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Interacting with Hadoop DFS: deleting files ➢ Examples: hdfs dfs -rm data/students.tsv hdfs dfs -rm data/grades.tsv
- 16. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Interacting with Hadoop DFS: space use info ➢ Examples: hdfs dfs -df -h Filesystem Size Used Available Use% hdfs://localhost 1.5 T 12 K 491.6 G 0%
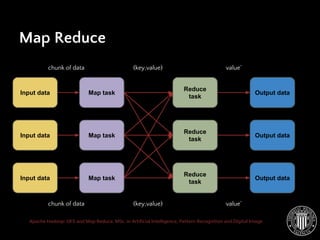
- 17. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map Reduce: Overview Input data Input data Input data Map task Map task Map task Reduce task Reduce task Reduce task Output data Output data Output data chunk of data (key,value) value’ chunk of data (key,value) value’
- 18. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map: Transform data to (key, value) Input data Input data Input data Map task Map task Map task chunk of data chunk of data
- 19. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Shuffle: Send (key, values) Reduce task Reduce task Reduce task (key,value) (key,value) Map task Map task Map task
- 20. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Reduce: Aggregating (key,values) Reduce task Reduce task Reduce task Output data Output data Output data value’ value’
- 21. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map Reduce Input data Input data Input data Map task Map task Map task Reduce task Reduce task Reduce task Output data Output data Output data chunk of data (key,value) value’ chunk of data (key,value) value’
- 22. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map Reduce example: word count CHUNK 1 this class is about big data and artificial intelligence CHUNK 2 there is nothing big about this example CHUNK 3 I am a big artificial intelligence enthusiast ➢ The file is divided in chunks to be processed in parallel ➢ Data is sent untransformed to map nodes
- 23. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map Reduce example: word count this class is about big data and artificial intelligence [this, class, is, about, big, data, and, artificial, intelligence] Tokenize (this,1), (class,1), (is,1), (about,1), (big,1), (class, 1), (is, 1), (about 1), (big, 1), (data, 1), (and, 1), (artificial,1), (intelligence, 1) Prepare (key,value) pairs MAP TASK Raw chunk Ready to shuffle
- 24. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map Reduce example: word countMap Reduce example: word count (big,1) (big,1) (big,1) (big,3) Sum REDUCE TASK From shuffle Output
- 25. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Exercise: Matrix power row column value 1 1 3.2 2 3 4.3 3 3 5.1 1 3 0.1
- 26. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map Reduce variants: No reduce Input data Input data Input data Map task Map task Map task Output data Output data Output data chunk of data (key,value) chunk of data (key,value)
- 27. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Map Reduce variants: chaining Input data Input data Input data Map task Map task Map task Reduce task Reduce task Reduce task Output data Output data Output data Map task Map task Map task Reduce task Reduce task Reduce task Output data Output data Output data
- 28. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Maps are executed in parallel ➢ Reducers do not start until all maps are finished ➢ Output is not finished until all reducers are finished ➢ Bottleneck: Unbalanced map/reduce taks ○ Change key distribution ○ Increase reduces for increasing parallelism Map Reduce: bottlenecks
- 29. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Hadoop is implemented in Java ➢ It is possible to program jobs formed by maps and reduces in Java ➢ We won’t go deep in these matters (bear with me!) Map Reduce in Hadoop
- 30. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image http://hadoop.apache.org/ Hadoop architecture
- 31. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer (value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } Map Reduce job in Hadoop public static class IntSumReducer extends Reducer<Text,IntWritable,Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } ...
- 32. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path (args[0])); FileOutputFormat.setOutputPath(job, new Path (args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } Map Reduce job in Hadoop
- 33. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ Compiling javac -cp opt/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar: opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar -d WordCount source/hadoop/WordCount.java jar -cvf WordCount.jar -C WordCount/ . ➢ Submitting hadoop jar WordCount.jar es.upv.dsic.iarfid.haia.WordCount /user/your_username/data/students.tsv /user/your_username/wc Compiling and submitting a MR job
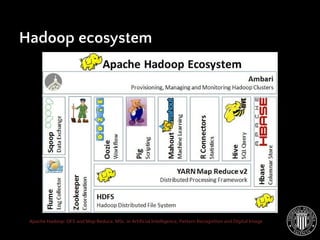
- 34. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image Hadoop ecosystem
- 35. Apache Hadoop: DFS and Map Reduce. MSc. in Artificial Intelligence, Pattern Recognition and Digital Image ➢ http://hadoop.apache.org ➢ Hadoop in Practice. Alex Holmes. Ed. Manning Publications ➢ Hadoop: The Definitive Guide. Tom White. Ed. O’Reilly. ➢ StackOverflow Extra information
- 36. Apache Hadoop DFS and Map Reduce Víctor Sánchez Anguix Universitat Politècnica de València MSc. In Artificial Intelligence, Pattern Recognition, and Digital Image Course 2014/2015