Apache hadoop, hdfs and map reduce Overview
1 like976 views

This document provides an overview of Apache Hadoop, HDFS, and MapReduce. It describes how Hadoop uses a distributed file system (HDFS) to store large amounts of data across commodity hardware. It also explains how MapReduce allows distributed processing of that data by allocating map and reduce tasks across nodes. Key components discussed include the HDFS architecture with NameNodes and DataNodes, data replication for fault tolerance, and how the MapReduce engine works with a JobTracker and TaskTrackers to parallelize jobs.























![Prepare and Submit job
public class WordCountJob {
public static void main(String[] args) throws Exception{
JobConf conf = new JobConf(WordCount.class);
// specify input and output dirs
FileInputFormat.addInputPath(conf, new Path("input"));
FileOutputFormat.addOutputPath(conf, new Path("output"));
// specify output types
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
//InputFormat and OutputFormat
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
conf.setMapperClass(WordCountMapper.class); // specify a mapper
conf.setReducerClass(WordCountReducer.class); // specify a reducer
conf.setCombinerClass(WordCountReducer.class);
conf.setNumberOfReducer(2); //Number of reducer
JobClient.runJob(conf); // Submit the job to Job Tracker
}}](https://image.slidesharecdn.com/apachehadoophdfsandmapreduceoverview-140706125521-phpapp01/85/Apache-hadoop-hdfs-and-map-reduce-Overview-25-320.jpg)

































Ad
More Related Content
What's hot (18)
Similar to Apache hadoop, hdfs and map reduce Overview (20)
















Ad
Recently uploaded (20)




















Ad
Apache hadoop, hdfs and map reduce Overview
- 1. Apache Hadoop, HDFS and MapReduce Overview Nisanth Simon
- 2. Agenda Motivation behind Hadoop − A different approach to Distributed computing − Map Reduce paradigm- in general Hadoop Overview − Hadoop distributed file system − Map Reduce Engine − Map Reduce Framework Walk thru First MR job
- 3. Data Explosion Modern systems has to deal with far more data than in the past. Many organizations are generating data at a rate of terabytes per day. Facebook – over 15Pb of data eBay – over 5Pb of data Telecom Industry
- 4. Hardware improvements through the years... CPU Speeds: − 1990 - 44 MIPS at 40 MHz − 2000 - 3,561 MIPS at 1.2 GHz − 2010 - 147,600 MIPS at 3.3 GHz RAM Memory − 1990 – 640K conventional memory (256K extended memory recommended) − 2000 – 64MB memory − 2010 - 8-32GB (and more) Disk Capacity − 1990 – 20MB − 2000 - 1GB − 2010 – 1TB Disk Latency (speed of reads and writes) – not much improvement in last 7-10 years, currently around 70 – 80MB / sec
- 5. How long it will take to read 1TB of data? 1TB (at 80Mb / sec): − 1 disk - 3.4 hours − 10 disks - 20 min − 100 disks - 2 min − 1000 disks - 12 sec Distributed Data Processing is the answer!
- 6. Distributed computing is not new HPC and Grid computing − Move data to computation- Network bandwidth becomes a bottleneck; compute nodes idle Works well for compute intensive jobs − Exchanging data requires synchronization– very tricky − Scalability is programmer’s responsibility Will require change in job implementation Hadoop’s approach − Move computation to data- data locality, conserves network bandwidth − Shared nothing Architecture- no dependencies between tasks − Communication between nodes in frameworks responsibility − Designed for scalability Adding increased load to a system should not cause outright failure, but a graceful decline Increasing resources should support a proportional increase in load capacity Without modifying the job implementation
- 7. Map Reduce Paradigm Calculate the number of occurrences of each word in this book − Hadoop: The Definitive Guide, Third Edition 623 Pages
- 8. Apache A scalable fault-tolerant distributed system for data storage and processing (open source under the Apache license). − Meant for heterogeneous commodity hardware Inspired by Google technologies − MapReduce − Google file system Originally built to address scalability problems of Nutch, an open source Web search technology − Developed by Douglass Read Cutting (Doug cutting) Core Hadoop has two main systems: − Hadoop Distributed File System: self-healing high-bandwidth clustered storage. − MapReduce: distributed fault-tolerant resource management and scheduling coupled with a scalable data programming abstraction.
- 9. Hadoop Distributed File System (HDFS) Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets.
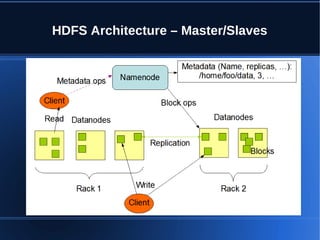
- 10. HDFS Architecture – Master/Slaves
- 11. Data Replication
- 12. NameNode(Master) Manages the file system namespace − Maintains file system tree and meta data for all files/directories in the tree Maps blocks to DataNodes, filenames, etc − Two persistent files (namespace image and edit log) plus additional in-memory data Safemode - Read only state, no modification to HDFS allowed − Single point of failure. Name node loss renders file system inaccessible Hadoop V1 has no built-in failover mechanism for NameNode − Coordinates access to DataNodes but data never goes on NameNode Centralizes and manages file system metadata in memory − Metadata size limited to available RAM of NameNode. − Bias toward modest number of large files, not large number of small files (where metadata can grow too sizeable) − NameNode will crash if it runs out of RAM
- 13. DataNode (Slave) • Files on HDFS are chopped into blocks and stored on DataNodes • Size of blocks is configurable • Different blocks from the same file are stored on different DataNodes if possible • Performs block creation, deletions, and replication as instructed by NameNode • Serves read and write requests to clients
- 14. HDFS user interfacesHDFS user interfaces • HDFS Web UI for NameNode and DataNodes • NameNode front page is at http://localhost:50070 (default configuration of a Hadoop in pseudo-distributed mode) • Distributed File System Browser (read only) • Display basic cluster statistics • Hadoop shell commands • $HADOOP_HOME/bin/hadoop dfs –ls /user/biadmin • $HADOOP_HOME/bin/hadoop dfs –chown hdfs:biadmin /user/hdfs • $HADOOP_HOME/bin/hadoop dfsadmin –report • Programmatic interface • HDFS Java API: http://hadoop.apache.org/core/docs/current/api/ • C wrapper over java APIs
- 15. HDFS Commands Download the Airline Dataset – stat-computing.org/dataexpo/2009/1987.csv.bz2 • Creating a directory in HDFS – hadoop fs –mkdir /user/hadoop/dir1 – hadoop fs -mkdir hdfs://nn1.example.com/user/hadoop/dir hdfs://nn2.example.com/user/hadoop/dir • Delete a directory in HDFS – hadoop fs -rm hdfs://nn.example.com/file – hadoop fs -rmr /user/hadoop/dir – hadoop fs -rmr hdfs://nn.example.com/user/hadoop/dir • List a directory – hadoop fs -ls /user/hadoop/file1
- 16. HDFS Commands Copy a file to HDFS file – hadoop fs -put localfile /user/hadoop/hadoopfile – hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir – hadoop fs -put localfile hdfs://nn.example.com/hadoop/hadoopfile • Copy file in HDFS – hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 • Copy from Local File system to HDFS – hadoop fs -copyFromLocal /opt/1987.csv • Copy from HDFS to Local File System – hadoop fs –copyToLocal /user/nis/1987.csv /opt/res.csv • Display a content of a file – hadoop fs –cat /user/nis/1987.csv
- 17. Hadoop MapReduce Engine • Framework which enables writing applications to process multi-terabyte of data in-parallel on large clusters (thousands of nodes) of commodity hardware • A clean abstraction for programmers • No need to deal with internals of large scale computing • Implement just Mapper and Reducer functions- most of the times • Implement in the language you comfortable with – Java (assembly language for Hadoop) – With hadoop streaming, you can run any shell utility as mapper and reducer – Hadoop pipes to support implementation of mapper and reducer in C++. • Automatic parallelization & distribution • Divides the job into tasks (map and reduce task) • Schedules submitted jobs • Schedules tasks as close to data as possible • Monitors task progress • Fault-tolerance • Re-execute failed or slow task instances.
- 18. MapReduce Architecture- Master/Slaves • Single master (JobTracker) controls job execution on multiple slaves (TaskTrackers). • JobTracker • Accepts MapReduce jobs submitted by clients • Pushes map and reduce tasks out to TaskTracker nodes • Keeps the work as physically close to data as possible • Monitors tasks and TaskTracker status • TaskTracker • Runs map and reduce tasks; Reports status to JobTracker • Manages storage and transmission of intermediate output JobTracker TaskTracker TaskTracker TaskTrackerTaskTracker JobClient clusterMaster node Slave node 1
- 19. Map Reduce Family • Job – A MapReduce job is a unit of work that the client wants to perform. It consists of the input data, output location the MapReduce program, and configuration information. • Task – Hadoop runs the job by dividing it into tasks, of which there are two types: map tasks and reduce tasks. • Task Attempt – A particular instance of an attempt to execute a task on a machine • Input Split - Hadoop divides the input to a MapReduce job into fixed-size pieces called inputsplits, or just splits. • Default split size == Block size for the input • Number of map task == no of splits of job’s input
- 20. Map Reduce Family… • Record – the unit of data from an input split, on which Map task runs the user defined mapper function. • InputFormat - Hadoop can process many different types of data formats, from flat text files to databases. This guy help’s hadoop in dividing job’s input into Splits and interpret records from a split. • File based InputFormat • Text Input Format • Binary Input Format • DataBase InputFormat • OutputFormat – This guy helps hadoop writing job’s output to specified output location. There are corresponding output formats for each Inputformat.
- 21. How data flows in a map reduce job
- 22. Some more members … • Partitioner - Partitioner partitions the key space. • Determines the destination Reducer task for intermediate map output. • Number of partitions is equal to Number of Reduce task. • HashPartitioner used by default • Uses key.hashCode() to return partition num • Combiner – Reduces the data transferred between MAP and REDUCE tasks • Takes outputs of multiple MAP functions and combines it into single input to REDUCE function • Example • Map task output - (BB, 1), (Apple,1), (Android,1), (Apple,1), (iOS,1),(iOS,1),(RHEL,1), (Windows,1),(BB,1) • Combiner output – (BB,2),(Apple,2),(MicroSoft,1),(iOS,2),(RHEL,1),(Windows,1)
- 23. Word Count Mapper public static class WordCountMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer itr = new StringTokenizer(line); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); output.collect(word, one); } } }
- 24. Word count Reducer public static class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } }
- 25. Prepare and Submit job public class WordCountJob { public static void main(String[] args) throws Exception{ JobConf conf = new JobConf(WordCount.class); // specify input and output dirs FileInputFormat.addInputPath(conf, new Path("input")); FileOutputFormat.addOutputPath(conf, new Path("output")); // specify output types conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); //InputFormat and OutputFormat conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); conf.setMapperClass(WordCountMapper.class); // specify a mapper conf.setReducerClass(WordCountReducer.class); // specify a reducer conf.setCombinerClass(WordCountReducer.class); conf.setNumberOfReducer(2); //Number of reducer JobClient.runJob(conf); // Submit the job to Job Tracker }}
- 26. Complete Picture TaskTrackers (compute nodes) and DataNodes co- locate = high aggregate bandwidth across cluster
- 27. Hadoop Ecosystem
- 28. Thank You